Embed Size (px)
Citation preview

• A medida que aumenta la complejidad de nuestro mundo, se hace cada vez más difícil tomar decisiones inteligentes y bien documentadas. Con frecuencia tales decisiones deben tomarse con mucho menos que un conocimiento adecuado y experimentando una gran incertidumbre. Sin embargo, las soluciones a estos problemas son esenciales para nuestro bienestar e incluso para nuestra supervivencia final. Continuamente estamos recibiendo presiones debido a problemas económicos angustiosos como inflación galopante, el sistema tributario engorroso y oscilaciones excesivas en el ciclo empresarial. Todo nuestro tejido económico y social esta amenazado por la contaminación ambiental, la deuda publica onerosa, la tasa de criminalidad que siempre va en aumento y las impredecibles tasas de interés.
• Si estas condiciones parecen ser características del estilo de vida actual, no debe olvidarse que problemas de esta naturaleza contribuyeron a la caída de la antigua Roma más que la invasión de las hordas de bárbaros provenientes del norte. Un período de éxito en este planeta, relativamente corto, no es garantía de una supervivencia futura. A menos que puedan encontrarse soluciones viables a estos apremiantes problemas.
Introducción

• Induce en el estudiante actitudes y habilidades que le permiten cursar satisfactoriamente las asignaturas propias de su formación profesional.
• Proporciona al estudiante los fundamentos que le permiten enfrentar con éxito problemas que requieren capacidad analítica y de innovación.
• Una sólida formación en ciencias básicas es necesaria para la comprensión de los fenómenos relacionados con las tecnologías.
• Al ser capaz de solucionar problemas y tomar decisiones.
Objetivos
• http://thales.cica.es/rd/Recursos/rd97/UnidadesDidacticas/53-1-u-indice.html
• www.aulafacil.com
• www.cortland.edu/flteach/stats/
• www.monografias.com
• www.bioestadistica.uma.es/libro/
• www.ucm.es/BUCM/est/
ESTADÍSTICA
DESCRIPTIVA PROBABILIISTICA INFERENCIAL
CONCEPTOS BÁSICOS
CUADRO DE FRECUENCIAS
MEDIDAS DE TENDENCIA CENTRAL
MEDIDAS DE DISPERSIÓN
OTRAS MEDIDAS
HISTOGRAMA Y POLIGONO DE FRECUENCIAS
INTRODUCCION
CONJUNTOS
AXIOMAS Y TEOREMAS
PROBABILIDADES
ANALISIS COMBINATORIO
MUESTREO
TAMAÑO DE LA MUESTRA
TECNICAS DE MUESTREO
REGRESIÓN Y CORRELACIÓN
VARIABLES ALEATORIAS
DISTRIBUCIONES DE PROBABILIDAD

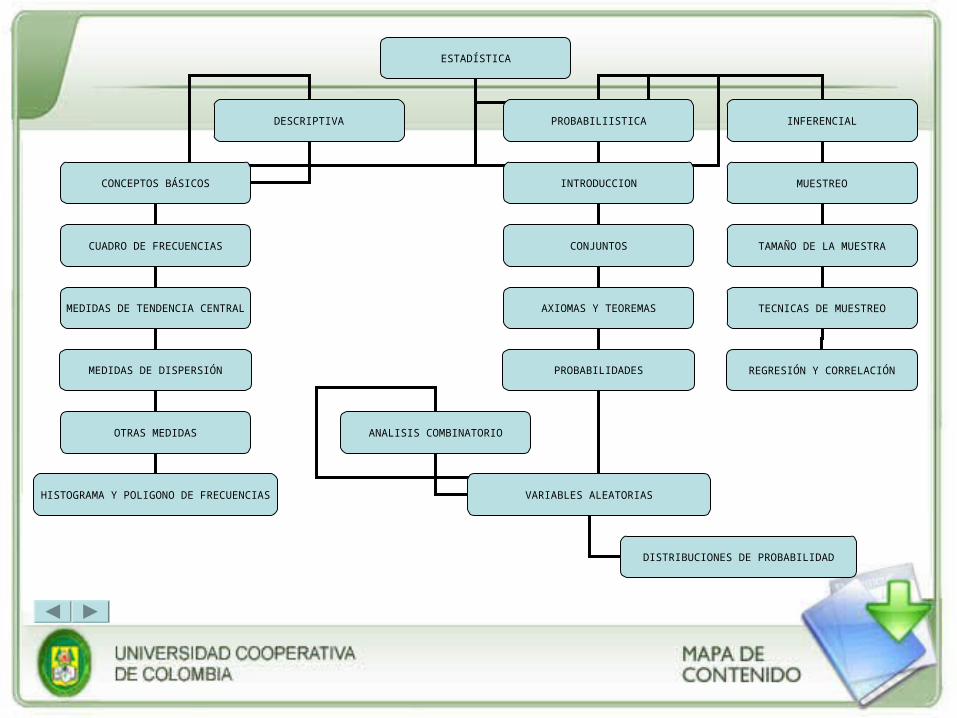
• Unidad 1: Estadística Descriptiva.
• Unidad 2: Introducción a la Probabilidad.
• Unidad 3: Variables Aleatorias.
• Unidad 4: Distribuciones de Probabilidad.
• Unidad 5: Muestreo y Técnicas de Muestreo.
• Unidad 6: Regresión y Correlación.
Contenido
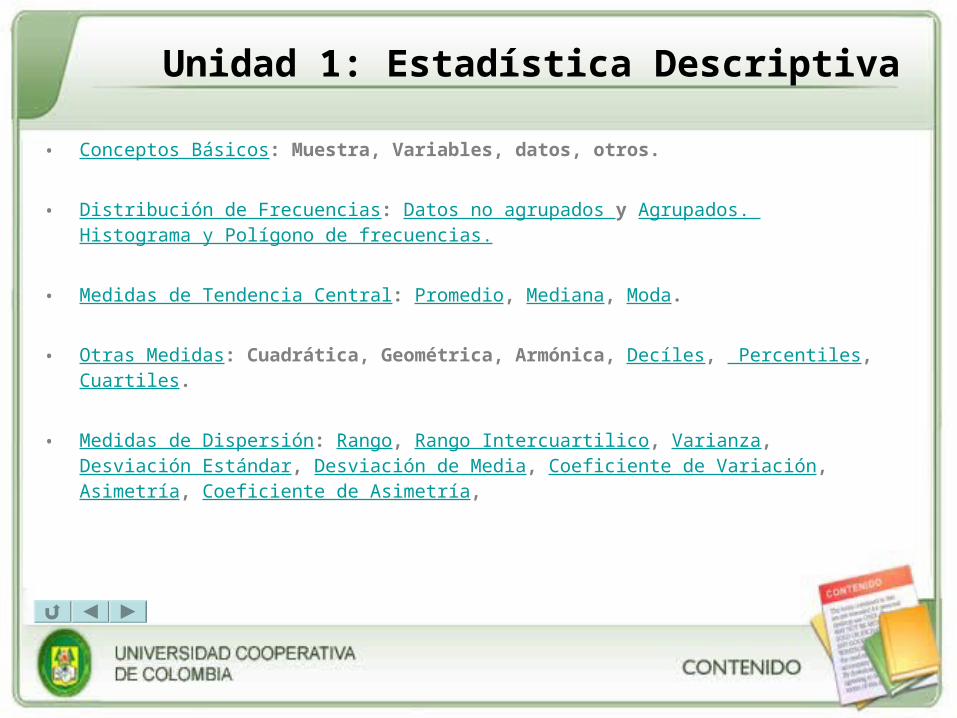
• Conceptos Básicos: Muestra, Variables, datos, otros.
• Distribución de Frecuencias: Datos no agrupados y Agrupados. Histograma y Polígono de frecuencias.
• Medidas de Tendencia Central: Promedio, Mediana, Moda.
• Otras Medidas: Cuadrática, Geométrica, Armónica, Decíles, Percentiles, Cuartiles.
• Medidas de Dispersión: Rango, Rango Intercuartilico, Varianza, Desviación Estándar, Desviación de Media, Coeficiente de Variación, Asimetría, Coeficiente de Asimetría,
Unidad 1: Estadística Descriptiva

1. Conceptos Básicos
• Cuando escuchamos la palabra Estadística inmediatamente nos imaginamos promedios, índices, tasas, entre otros. Esta rama de la Estadística que utiliza números para describir hechos recibe el nombre de Estadística Descriptiva, la cual consiste en organizar, resumir y simplificar, en términos generales información que es bastante compleja.
• Otra rama de la Estadística estudia la Probabilidad de gran utilidad cuando interviene el azar. Juego como los dados o cartas, o el lanzamiento de monedas, etc. En los deportes.
• La inferencia constituye una tercera rama de la Estadística. Consiste en el análisis e interpretación de una muestra de datos (Muestreo).
• En pocas palabras, existen tres áreas muy relacionadas de interés en estadística: La descripción y resumen de datos, la teoría de la probabilidad y el análisis e interpretación de los datos de una muestra.
• En conclusión la estadística estudia los métodos científicos para recoger, organizar y analizar datos, así como para sacar conclusiones validas y tomar decisiones razonables basadas en tal análisis

• Población Estadística: Es el Conjunto de unidades individuales tales como personas, animales o cosas acerca de los cuales se desea obtener alguna información. A las unidades individuales la llamaremos unidades elementales.
• Ejemplo: Supongamos de deseamos hacer un estudio sobre el nivel académico de los estudiantes de sistemas. La población estará formada por todos lo estudiantes matriculados en la facultad. Cada estudiante será una unidad elemental.
• Pero seguramente, nuestra población de trabajo no sea el conjunto de los estudiantes como tales sino el conjunto de observaciones hechas a los mismos, como por ejemplo: promedio crédito, el numero total de créditos tomados en el semestre, el numero total de horas que dedica semanalmente al estudio, el sexo, etc.
• El conjunto de observaciones hechas a las unidades elementales también constituyen una población estadística y generalmente es la población objeto de interés para el estadístico.

• Dato: cada observación hecha a una unidad elemental constituye un dato y es el conjunto de datos la materia prima con la que trabaja el estadístico.
• Los datos se obtienen por medio de encuestas, cuestionarios, entrevistas, test, experimentos, etc.
• Se usa un cuestionario cuando se desea información de hechos. Si se buscan opiniones mas que hechos, es útil el empleo de un formulario de opiniones o de una escala de opiniones. La entrevista es, en cierto sentido, un tipo verbal de cuestionario.
• Como sistema de recolección de datos, los test se hallan entre los instrumentos mas útiles de la investigación.
• En el experimento, el investigador puede ejercer control sobre algunos de los factores que puedan afectar las características de interés de la población objeto de estudio.
• Una Muestra, es una parte o subconjunto de la población. La Muestra debe escogerse en forma tal que represente hasta donde sea posible la característica o características de interés para el investigador, de la población objeto estudio. El procedimiento mediante el cual se obtienen las muestras se llama Muestreo.

• Una Variables es una característica que va a ser estudiada en una población. Una variable es estadística, si puede ser escrita como una pregunta cuyas respuestas puedan ser tabuladas o clasificadas dentro de determinados rangos
• Una Variable es cuantitativa, si la característica que se va a estudiar se puede medir en una escala numérica: Es discreta si toma valores enteros y continua si toma valores en números reales.
• Una variable cualitativa, si en la característica se busca conocer gustos, preferencias u opiniones. Una variable cualitativa es estadística, cuando es posible clasificar datos obtenidos en clases bien definidas, entre las cuales, quien suministra la información pueda elegir una de ellas.

2. Distribución de Frecuencias
• Al resumir grandes colecciones de datos, es útil distribuirlos en clases o categorías y determinar el número de individuos que pertenecen a cada clase, llamado Frecuencia de Clase. Una disposición tabular de los datos por clases junto con las correspondientes frecuencias de clase, se llama Distribución de Frecuencias (o tabla de frecuencias).
En la estadística descriptiva hay dos formas de organizar y analizar los datos:
1. Distribución de frecuencias para datos no agrupados.
2. Cuadro de intervalos o clases para datos agrupados.
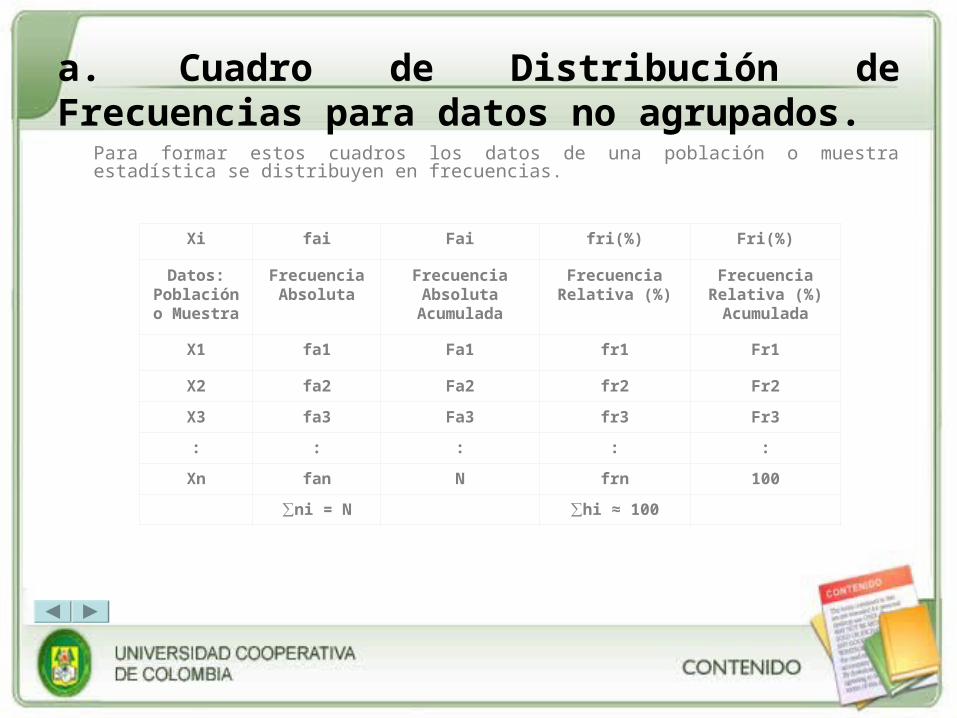
a. Cuadro de Distribución de Frecuencias para datos no agrupados.
Para formar estos cuadros los datos de una población o muestra estadística se distribuyen en frecuencias.
Xi fai Fai fri(%) Fri(%)
Datos: Población o
Muestra
Frecuencia Absoluta
Frecuencia Absoluta
Acumulada
Frecuencia Relativa (%)
Frecuencia Relativa (%) Acumulada
X1 fa1 Fa1 fr1 Fr1
X2 fa2 Fa2 fr2 Fr2
X3 fa3 Fa3 fr3 Fr3
: : : : :
Xn fan N frn 100
∑ni = N ∑hi ≈ 100
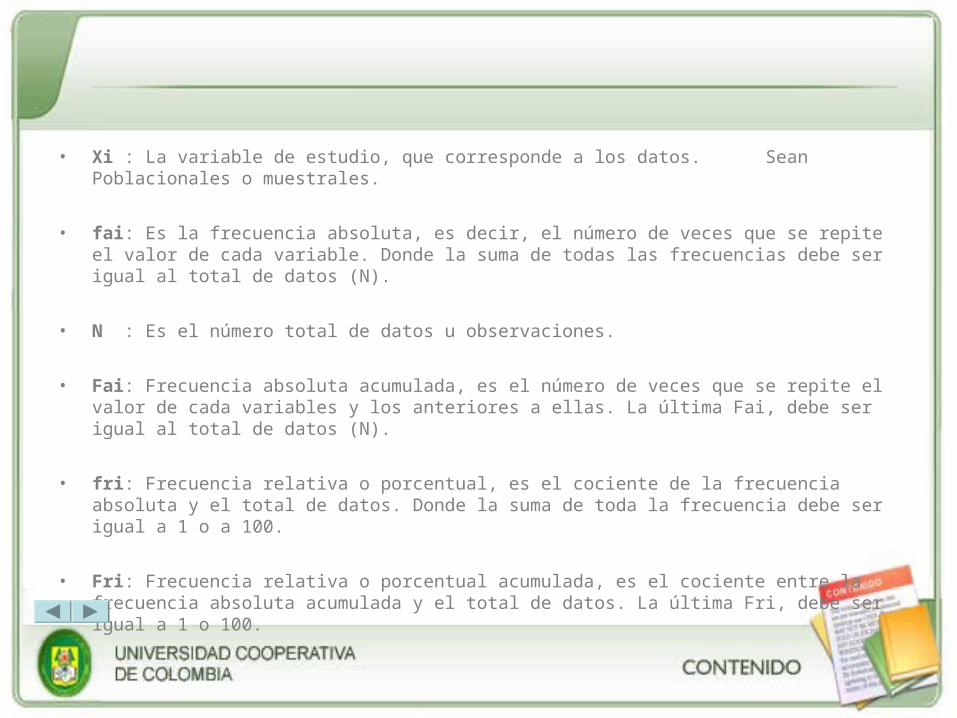
• Xi : La variable de estudio, que corresponde a los datos. Sean Poblacionales o muestrales.
• fai: Es la frecuencia absoluta, es decir, el número de veces que se repite el valor de cada variable. Donde la suma de todas las frecuencias debe ser igual al total de datos (N).
• N : Es el número total de datos u observaciones.
• Fai: Frecuencia absoluta acumulada, es el número de veces que se repite el valor de cada variables y los anteriores a ellas. La última Fai, debe ser igual al total de datos (N).
• fri: Frecuencia relativa o porcentual, es el cociente de la frecuencia absoluta y el total de datos. Donde la suma de toda la frecuencia debe ser igual a 1 o a 100.
• Fri: Frecuencia relativa o porcentual acumulada, es el cociente entre la frecuencia absoluta acumulada y el total de datos. La última Fri, debe ser igual a 1 o 100.
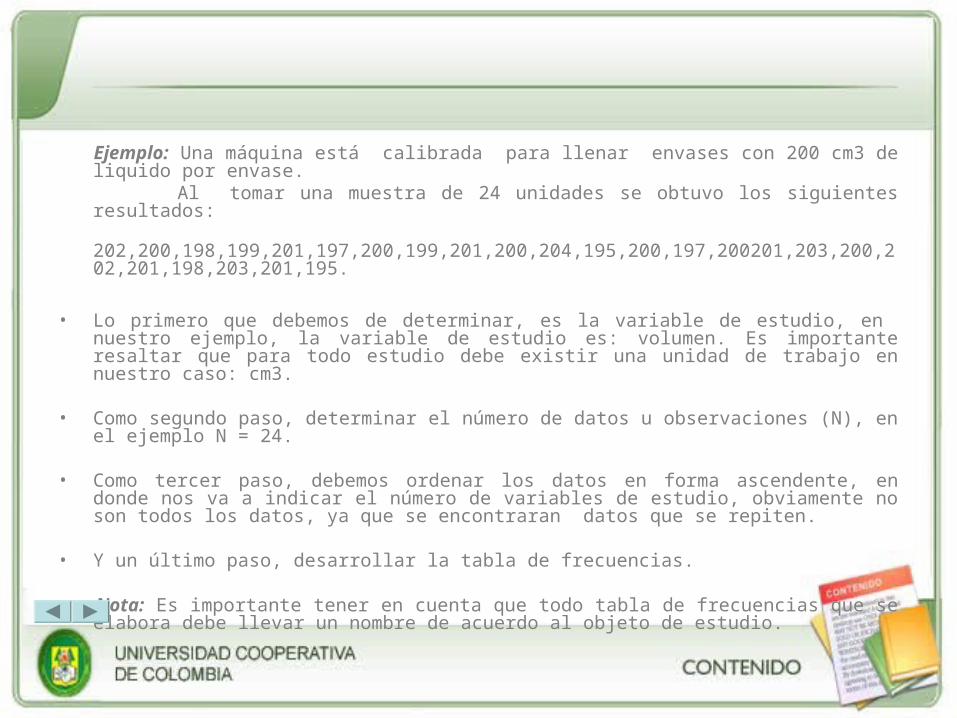
Ejemplo: Una máquina está calibrada para llenar envases con 200 cm3 de liquido por envase. Al tomar una muestra de 24 unidades se obtuvo los siguientes resultados:
202,200,198,199,201,197,200,199,201,200,204,195,200,197,200201,203,200,202,201,198,203,201,195.
• Lo primero que debemos de determinar, es la variable de estudio, en nuestro ejemplo, la variable de estudio es: volumen. Es importante resaltar que para todo estudio debe existir una unidad de trabajo en nuestro caso: cm3.
• Como segundo paso, determinar el número de datos u observaciones (N), en el ejemplo N = 24.
• Como tercer paso, debemos ordenar los datos en forma ascendente, en donde nos va a indicar el número de variables de estudio, obviamente no son todos los datos, ya que se encontraran datos que se repiten.
• Y un último paso, desarrollar la tabla de frecuencias. Nota: Es importante tener en cuenta que todo tabla de frecuencias que se elabora debe llevar
un nombre de acuerdo al objeto de estudio.
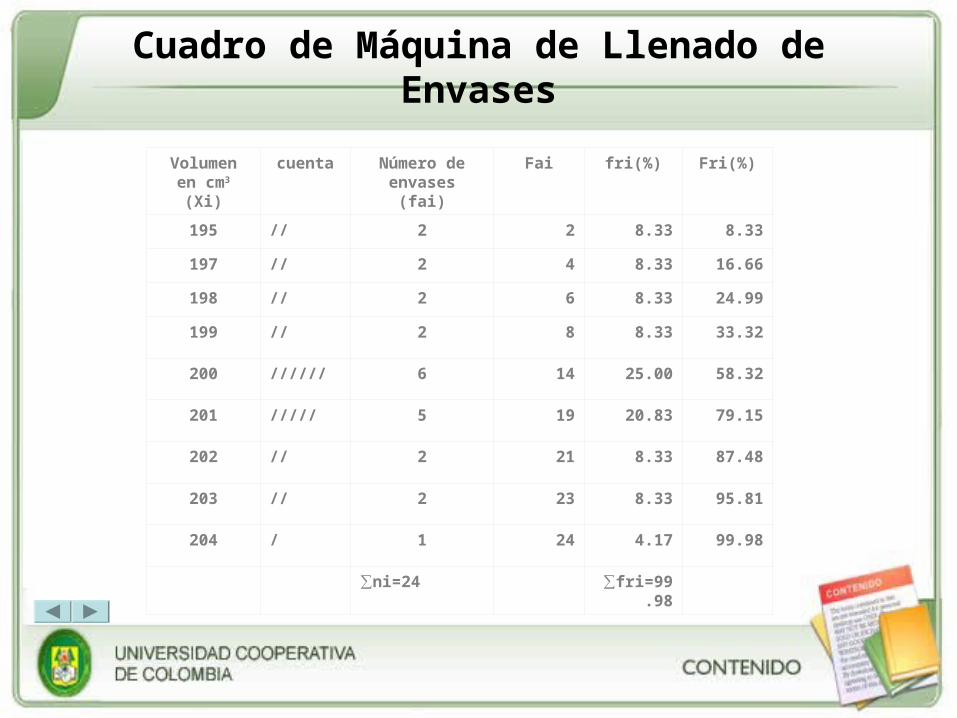
Cuadro de Máquina de Llenado de Envases
Volumen en cm3 (Xi)
cuenta Número de envases (fai)
Fai fri(%) Fri(%)
195 // 2 2 8.33 8.33
197 // 2 4 8.33 16.66
198 // 2 6 8.33 24.99
199 // 2 8 8.33 33.32
200 ////// 6 14 25.00 58.32
201 ///// 5 19 20.83 79.15
202 // 2 21 8.33 87.48
203 // 2 23 8.33 95.81
204 / 1 24 4.17 99.98
∑ni=24 ∑fri=99.98

• Ahora se puede ver fácilmente, que en 6 de los 24 envases, están llenas con 200 cm3.
• Cuando se elabora el cuadro de frecuencias nos permite ver la información con mayor claridad y así tomar las decisiones y conclusiones pertinentes.
• Como se puede observar en el cuadro, la suma de la frecuencia relativa, fri, da aproximadamente igual a 100, aunque lo ideal es que de 100 exacto, para ello debemos utilizar las herramientas pertinente para que ocurra esto. Entre las herramientas está el uso de la calculadora y por supuesto el uso de una hoja de cálculo, en nuestro curso Excel.

b. Cuadro de Intervalos o Clases para datos agrupados.• Es otra forma de organizar los datos. Se utilizan cuando hay demasiados valores de la variable
y por tanto los datos se agrupan en rangos de valores llamados intervalos o clases.
Pasos para distribuir Intervalos o Clases:
1. Ordene de menor a mayor los datos con su respectiva frecuencia absoluta, como se hace en la tabla de distribución de frecuencias.
2. Determine el valor máximo de la variable (Xmáx) y el valor mínimo de la variable (Xmín).3. Obtenga el número de intervalos (I) o clases que van a conformar el cuadro. Para esto emplee
la fórmula Struges así: I = 1 + 3.33*logN.Como el número de intervalos es un número entero, se aproxima por el entero próximo cuando el decimal sea mayor de 0.7, de lo contrario por el entero inferior.
4. Hallar el rango, R, así: R = Xmáx – Xmín.5. Determine la amplitud (A) o ancho que van a conformar los intervalos. Esta amplitud será
constante para todas las clases. Así: A = R/I.6. Conformar cuadro de intervalos o clases con sus respectivas frecuencias como en el gráfico.
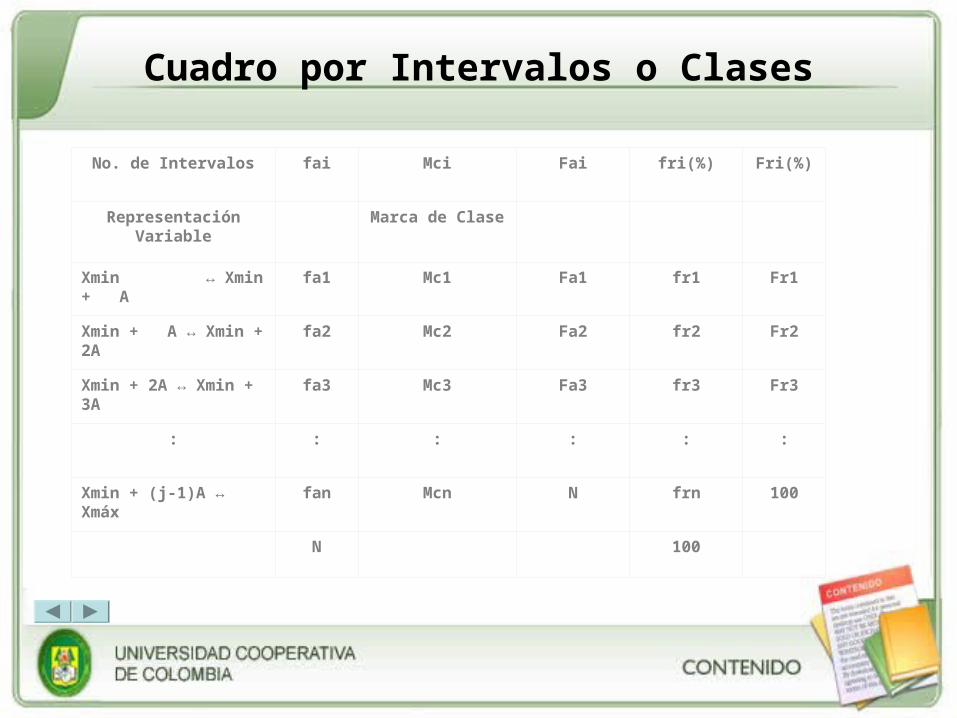
Cuadro por Intervalos o Clases
No. de Intervalos fai Mci Fai fri(%) Fri(%)
Representación Variable
Marca de Clase
Xmin ↔ Xmin + A fa1 Mc1 Fa1 fr1 Fr1
Xmin + A ↔ Xmin + 2A fa2 Mc2 Fa2 fr2 Fr2
Xmin + 2A ↔ Xmin + 3A fa3 Mc3 Fa3 fr3 Fr3
: : : : : :
Xmin + (j-1)A ↔ Xmáx fan Mcn N frn 100
N 100
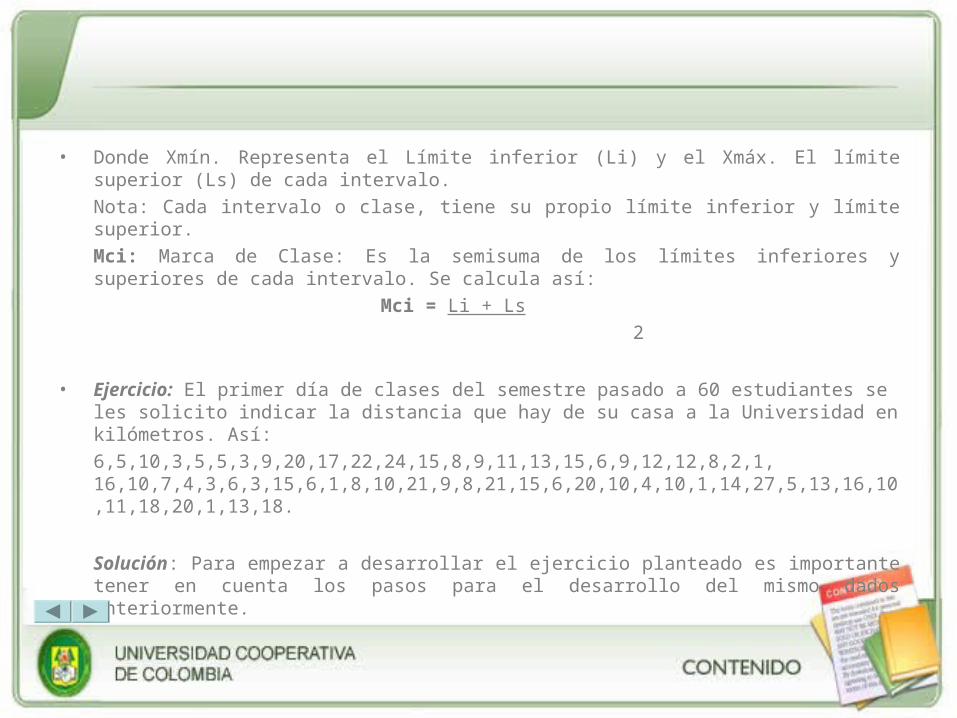
• Donde Xmín. Representa el Límite inferior (Li) y el Xmáx. El límite superior (Ls) de cada intervalo.
Nota: Cada intervalo o clase, tiene su propio límite inferior y límite superior.
Mci: Marca de Clase: Es la semisuma de los límites inferiores y superiores de cada intervalo. Se calcula así:
Mci = Li + Ls
2
• Ejercicio: El primer día de clases del semestre pasado a 60 estudiantes se les solicito indicar la distancia que hay de su casa a la Universidad en kilómetros. Así:
6,5,10,3,5,5,3,9,20,17,22,24,15,8,9,11,13,15,6,9,12,12,8,2,1, 16,10,7,4,3,6,3,15,6,1,8,10,21,9,8,21,15,6,20,10,4,10,1,14,27,5,13,16,10,11,18,20,1,13,18.
Solución: Para empezar a desarrollar el ejercicio planteado es importante tener en cuenta los pasos para el desarrollo del mismo dados anteriormente.
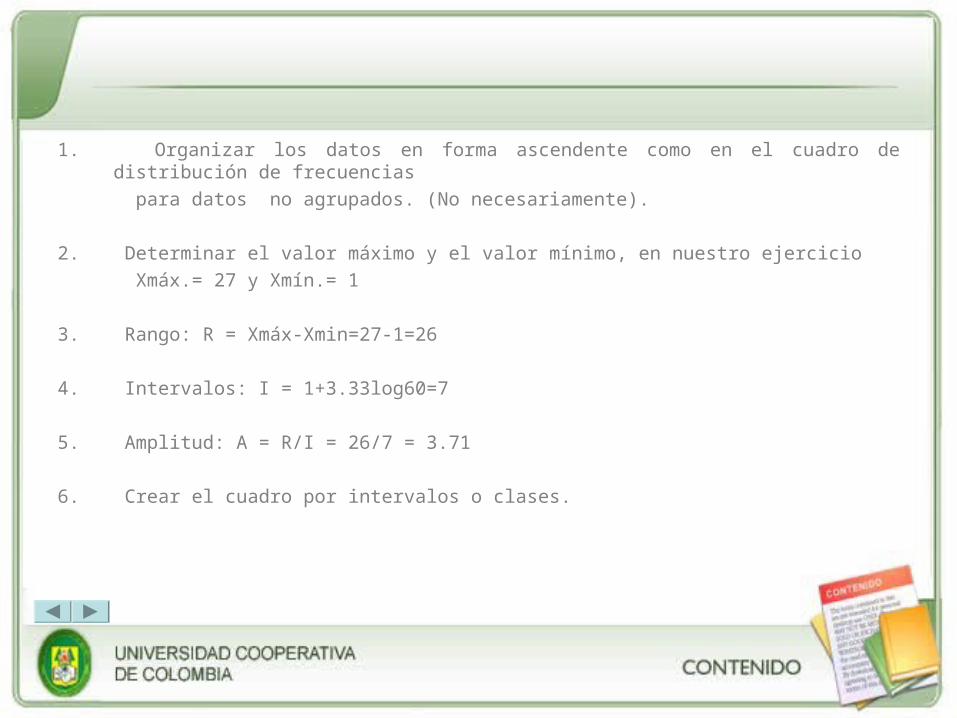
1. Organizar los datos en forma ascendente como en el cuadro de distribución de frecuencias
para datos no agrupados. (No necesariamente).
2. Determinar el valor máximo y el valor mínimo, en nuestro ejercicio
Xmáx.= 27 y Xmín.= 1
3. Rango: R = Xmáx-Xmin=27-1=26
4. Intervalos: I = 1+3.33log60=7
5. Amplitud: A = R/I = 26/7 = 3.71
6. Crear el cuadro por intervalos o clases.
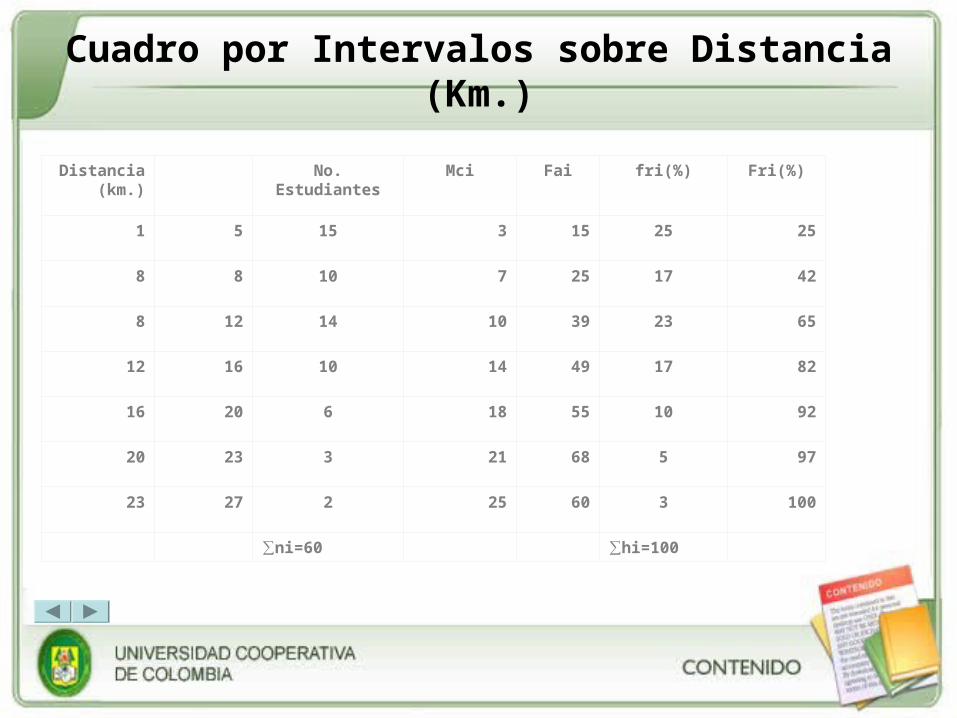
Cuadro por Intervalos sobre Distancia (Km.)
Distancia (km.)
No. Estudiantes Mci Fai fri(%) Fri(%)
1 5 15 3 15 25 25
8 8 10 7 25 17 42
8 12 14 10 39 23 65
12 16 10 14 49 17 82
16 20 6 18 55 10 92
20 23 3 21 68 5 97
23 27 2 25 60 3 100
∑ni=60 ∑hi=100

3. Medidas de Tendencia Central
• Son aquellas que concentran todos los valores de una población o muestra en un solo valor, es decir, constituyen el centro de gravedad de todos los valores de la variable.
Se dividen en dos grupos:
1. Promedio de Cómputos: Aquellos que para poderlos obtener intervienen todos los valores de la variable. La medía aritmética o promedio, la media cuadrática, la media armónica y la media geométrica.
2. Promedio de Posición: Se caracteriza porque para obtenerlos no intervienen todos los valores de la variable, sino que depende de la posición que ocupen dentro de la serie de datos. La mediana y la moda.

a. Media Aritmética o Promedio (Xm)
Es la más utilizada de todas las medidas de tendencia central, ya que representa todos los valores de la
variable en una sola. La media aritmética de cierto número de cantidades es la suma de sus valores
dividido por el total de datos u observaciones. Se define como:
1. Datos no agrupados:
Xm = ∑(Xi*fai)/N si es poblacional
Xm = ∑(Xi*fai)/N-1 si es muestral
2. Datos Agrupados:
Xm = ∑(Mci*fai)/N si es poblacional
Xm = ∑(Mci*fai)/N-1 si es muestral
Propiedades de la Media Aritmética:
1. En toda distribución la suma de las desviaciones, de cada uno de los valores de la variable respecto a la media es cero. Si Xi es una de las variables, su desviación respecto a Xm es la diferencia X – Xm. La suma de estas diferencias es 0.
∑(Xi - Xm) = 0
2. La suma de los cuadrados de las desviaciones respecto a la media es siempre menor que la suma de los cuadrados de las desviaciones con respecto a cualquier valor.
∑(Xi - Xm)2 < ∑(Xi – Otro valor)

Con base en el ejemplo de la máquina de llenado de envases y del ejercicio de la distancia en kilómetros a la universidad, calcular la respectiva media aritmética.
1. Datos no agrupados (máquina de llenado de envases) Xm = ∑(Xi*fai)/N-1 si es muestral
Volumen en Cm3 (Xi) No. Envases (fai) Xi*fai
195 2 390
197 2 394
198 2 396
199 2 398
200 6 1200
201 5 1005
202 2 404
203 2 406
204 1 204
∑ni=24 ∑(Xi*fai) = 4797
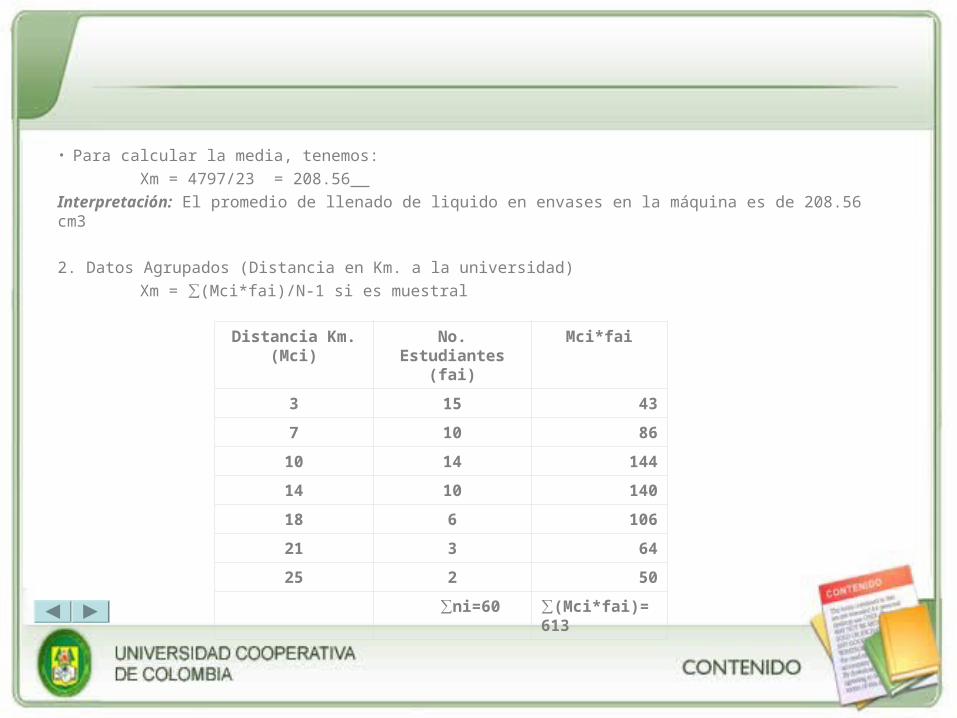
• Para calcular la media, tenemos:
Xm = 4797/23 = 208.56
Interpretación: El promedio de llenado de liquido en envases en la máquina es de 208.56 cm3
2. Datos Agrupados (Distancia en Km. a la universidad)
Xm = ∑(Mci*fai)/N-1 si es muestral
Distancia Km. (Mci)
No. Estudiantes (fai)
Mci*fai
3 15 43
7 10 86
10 14 144
14 10 140
18 6 106
21 3 64
25 2 50
∑ni=60 ∑(Mci*fai)=613

Para calcular la media, obtenemos:
Xm = 613 = 10.22
Interpretación: El promedio de distancia de la casa a la universidad de los 60 estudiantes es de 10.22 Km.
Nota: Es muy importante tener en cuenta, que para utilizar cualquiera de los tipos de distribución de frecuencias, sea de datos agrupados o no agrupados, normalmente se recomienda utilizar el de datos no agrupados cuando hablamos mas o menos de 30 datos, siempre y cuando los datos u observaciones no sean muy dispersos, de lo contrario se recomienda el de datos agrupados.
Cuando se interpretan los datos, que es muy diferente a concluir, sólo se debe tener en cuenta sólo el enunciado, es decir, no se le debe agregar o quitar información con base en el planteamiento del problema.

b. Mediana (Me)
Es un promedio de posición y se caracteriza por que su valor divide a la serie aproximadamente en dos partes iguales.
• Cálculo de la Mediana (Me):
1. Para datos no agrupados:
a. Cuando N es impar la mediana es el valor de la variable que ocupa la posición i + 1, dentro de la serie de datos. Donde i se calcula como:
i = (N-1)/2
b. Cuando N es par la mediana es el valor de la variable que ocupa la posición i, donde
i = N/2
Nota: Para obtener la posición (i), nos vamos a vasar en la frecuencia absoluta acumulada (Fai), y el valor de la variable correspondiente a la Fai, será el valor de la mediana.
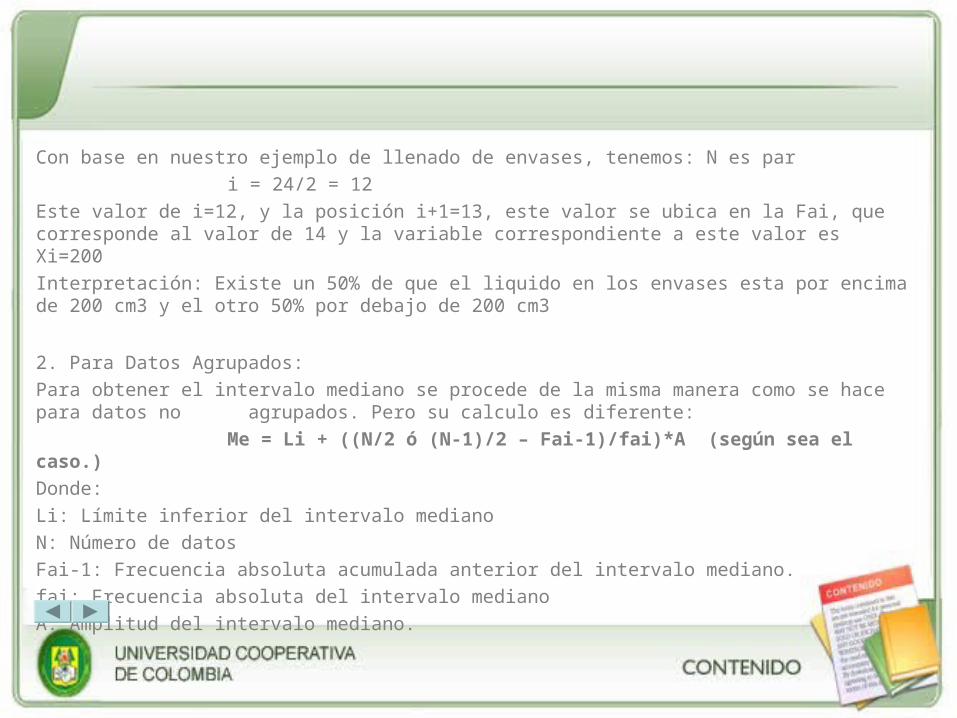
Con base en nuestro ejemplo de llenado de envases, tenemos: N es par
i = 24/2 = 12
Este valor de i=12, y la posición i+1=13, este valor se ubica en la Fai, que corresponde al valor de 14 y la variable correspondiente a este valor es Xi=200
Interpretación: Existe un 50% de que el liquido en los envases esta por encima de 200 cm3 y el otro 50% por debajo de 200 cm3
2. Para Datos Agrupados:
Para obtener el intervalo mediano se procede de la misma manera como se hace para datos no agrupados. Pero su calculo es diferente:
Me = Li + ((N/2 ó (N-1)/2 – Fai-1)/fai)*A (según sea el caso.)
Donde:
Li: Límite inferior del intervalo mediano
N: Número de datos
Fai-1: Frecuencia absoluta acumulada anterior del intervalo mediano.
fai: Frecuencia absoluta del intervalo mediano
A: Amplitud del intervalo mediano.

Con base en el ejercicio de la distancia en Km a la universidad, tenemos:
N es par
i = N/2 = 60/2 = 30. Este valor de i=30 lo ubico en la Fai. En nuestro ejercicio, lo contiene 39 y el intervalo mediano correspondiente es entre 8 y 12.
Li = 8
Fai-1 = 25
fai = 14
N/2 = 30
A = 3.71
Me = 8 +((30-25)/14)*3.71 = 9.3
Interpretación: Existe un 50% de estudiantes que viven a una distancia de la universidad por encima de 9.3 Km. Y el otro 50% por debajo de 9.3 Km.

c. La Moda (Mo)
La moda, como su nombre lo indica, es el valor de la variable que ocurre con mayor frecuencia, para datos no agrupados. Para datos agrupados, es la marca de clase que tenga la mayor frecuencia absoluta. La moda puede ser multimodal.
Con base en el ejemplo del llenado de envases y la distancia en km. a la universidad, tenemos:
1. Datos no agrupados (llenado de envases):
Mo = 200
2. Datos agrupados (distancia km. a la universidad)
Mo = 3
d. Otras Medidas de Tendencia Central
• Se le deja al estudiante para su investigación

5. Medidas de Dispersión
Las medidas de tendencia central son de un gran valor representativo para una masa de observaciones. Pero el valor de esas medidas dependerá de cuan variable sea la masa de información. Por eso se establecen medidas que tratan de explicar la dispersión de los datos y son: la varianza, la desviación estándar, el coeficiente de variación, el error estándar y los límites de confianza, entre otros. Una medida de dispersión conveniente deberá tomar en consideración todos los datos de la serie sopesando cada dato por su distancia al centro de la distribución.
a. Rango: R : Xmáx. – Xmín
La medida de dispersión más simple (y menos útil) es el rango. Su desventaja es que considera sólo dos de los cientos de observaciones que hay en un conjunto de datos. El resto de las observaciones se ignoran.
b. Varianza y Desviación Estándar
La desviación estándar y la varianza son medidas de variación absoluta, es decir, mide la cantidad real de variación presente en un conjunto de datos. La desviación estándar refleja que tan homogéneos (si la mayoría de los estudiantes respondió en forma similar) o heterogéneos (si hay estudiantes que respondan muy bien, otros mal y otros regular) son los datos. Se espera que la desviación estándar sea baja (cercana a cero).
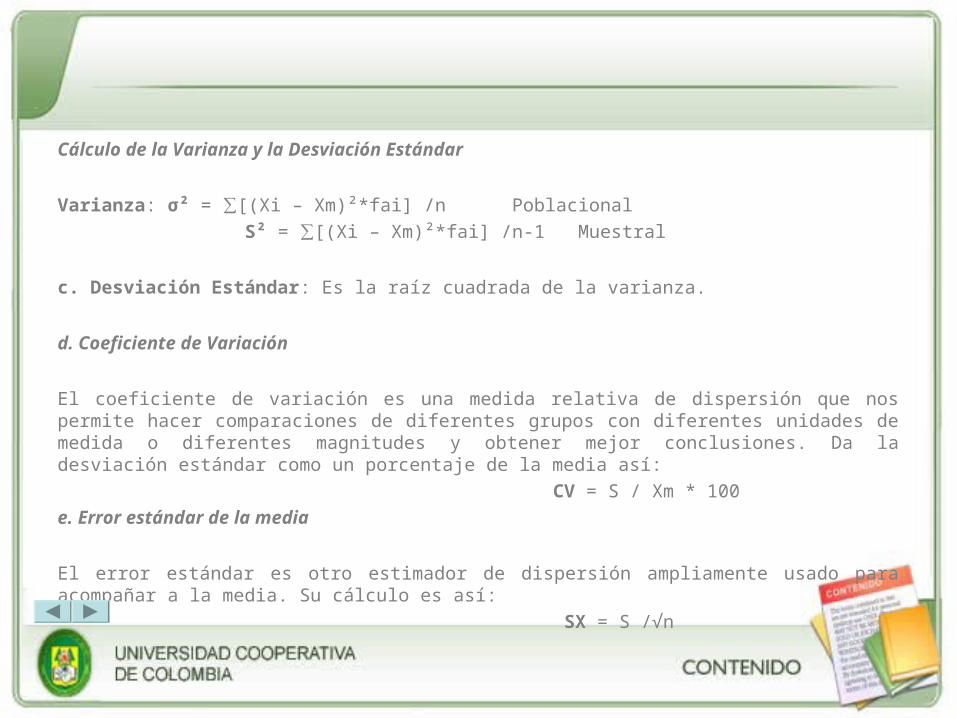
Cálculo de la Varianza y la Desviación Estándar
Varianza: σ² = ∑[(Xi – Xm)²*fai] /n Poblacional
S² = ∑[(Xi – Xm)²*fai] /n-1 Muestral
c. Desviación Estándar: Es la raíz cuadrada de la varianza.
d. Coeficiente de Variación
El coeficiente de variación es una medida relativa de dispersión que nos permite hacer comparaciones de diferentes grupos con diferentes unidades de medida o diferentes magnitudes y obtener mejor conclusiones. Da la desviación estándar como un porcentaje de la media así:
CV = S / Xm * 100
e. Error estándar de la media
El error estándar es otro estimador de dispersión ampliamente usado para acompañar a la media. Su cálculo es así:
SX = S /√n
f. Límites de Confianza
Los límites de confianza también se pueden calcular para establecer el intervalo dentro del cual es posible que se encuentre la media. Para esto se toma el error estándar, se multiplica por el valor tabular t de student con n-1 grados de libertad y se le suma y se le resta a la media.
Lc = Xm ± t * SXm
g. Rango Intercuartílico: Mide la dispersión con respecto a la mediana. Ri = Q3 – Q1
h. Desviación Media: DM = ∑│Xi - Xm│*fai
i. Asimetría: mide si la curva tiene una forma simétrica, es decir, si respecto al centro de la misma (centro de simetría) los segmentos de curva que quedan a derecha e izquierda son similares. El concepto de asimetría se refiere a si la curva que forman los valores de la serie presenta la misma forma a izquierda y derecha de un valor central (media aritmética).
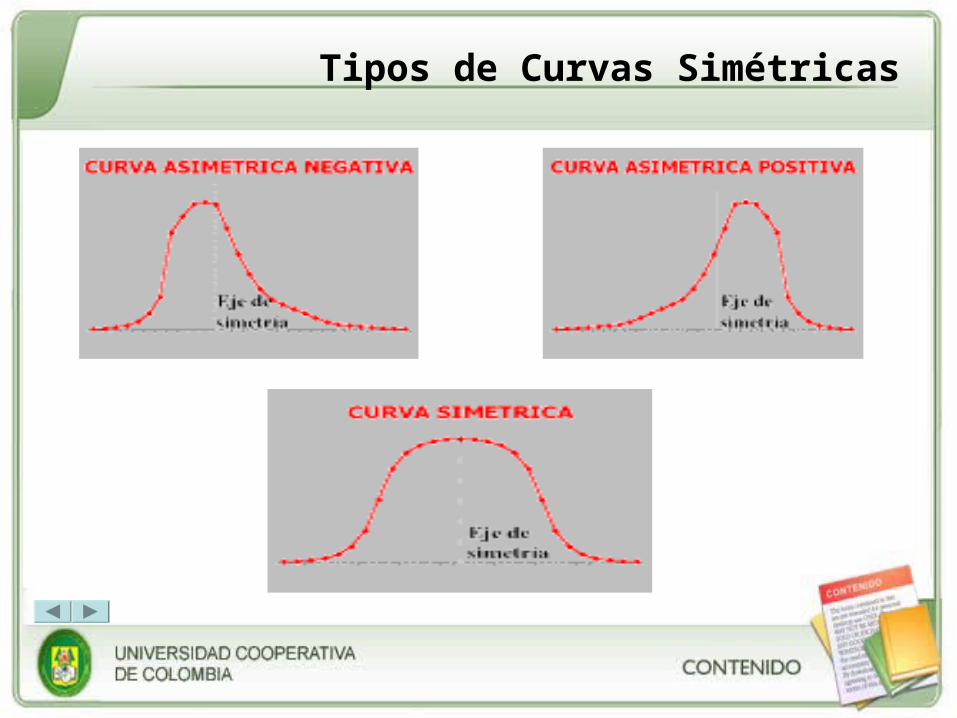
Tipos de Curvas Simétricas
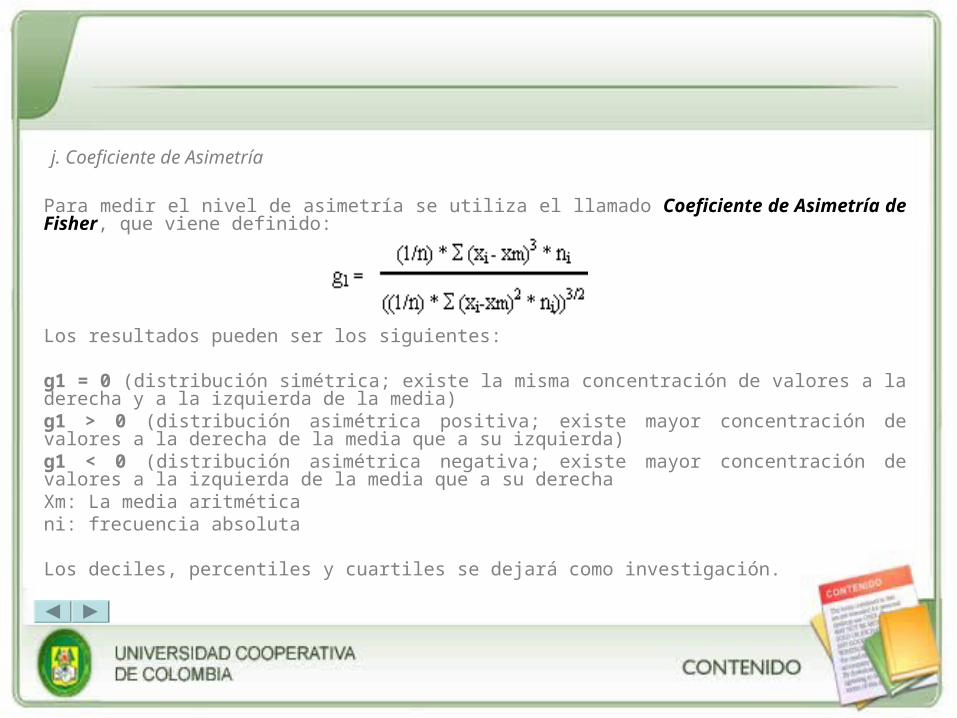
Para medir el nivel de asimetría se utiliza el llamado Coeficiente de Asimetría de Fisher, que viene definido:
Los resultados pueden ser los siguientes:
g1 = 0 (distribución simétrica; existe la misma concentración de valores a la derecha y a la izquierda de la media)
g1 > 0 (distribución asimétrica positiva; existe mayor concentración de valores a la derecha de la media que a su izquierda)
g1 < 0 (distribución asimétrica negativa; existe mayor concentración de valores a la izquierda de la media que a su derecha
Xm: La media aritmética
ni: frecuencia absoluta
Los deciles, percentiles y cuartiles se dejará como investigación.
j. Coeficiente de Asimetría
Para medir el nivel de asimetría se utiliza el llamado Coeficiente de Asimetría de Fisher, que viene definido:
Los resultados pueden ser los siguientes:
g1 = 0 (distribución simétrica; existe la misma concentración de valores a la derecha y a la izquierda de la media) g1 > 0 (distribución asimétrica positiva; existe mayor concentración de valores a la derecha de la media que a su izquierda)g1 < 0 (distribución asimétrica negativa; existe mayor concentración de valores a la izquierda de la media que a su derechaXm: La media aritméticani: frecuencia absoluta
Los deciles, percentiles y cuartiles se dejará como investigación.

6. Histograma y Polígono de frecuencia
El histograma de frecuencias es utilizado para datos agrupados únicamente. Se caracteriza porque los intervalos de clase se representan en barras, generalmente verticales, el ancho o amplitud de cada barra es igual al tamaño o amplitud del intervalo. La altura de cada barra esta determinada por la frecuencia absoluta de cada intervalo (fai).
El polígono de frecuencia es el resultado de unir los puntos medios de cada barra o intervalo, es decir, de unir las marcas de clase de cada intervalo. Un polígono de frecuencia se debe cerrar una marca de clase antes y una marca de clase después.
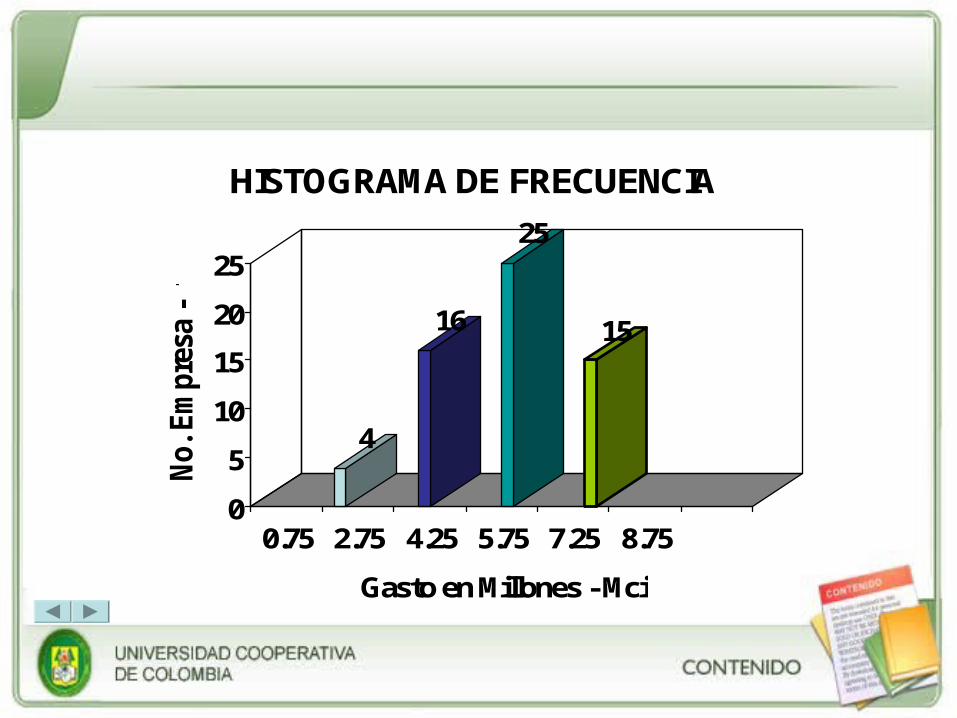
4
16
25
15
0
5
10
15
20
25
No
. E
mp
resa
-
fai
0.75 2.75 4.25 5.75 7.25 8.75
Gasto en Millones - Mci
HISTOGRAMA DE FRECUENCIA
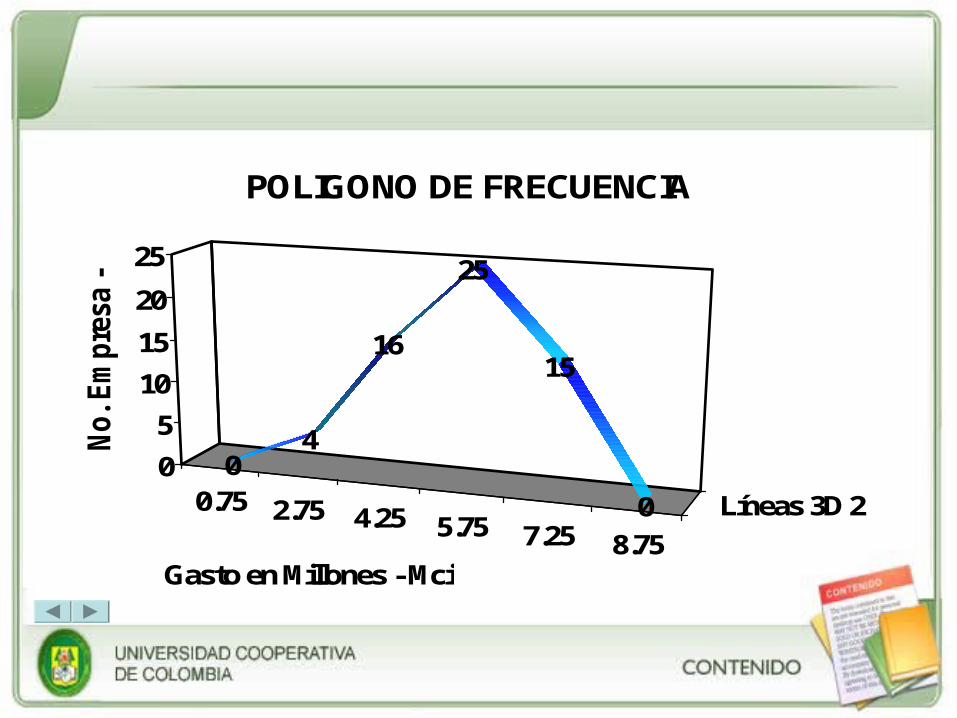
0.75 2.75 4.25 5.75 7.25 8.75
Líneas 3D 2
04
16
25
15
0
0
5
10
15
20
25
No
. E
mp
resa
- f
ai
Gasto en Millones - Mci
POLIGONO DE FRECUENCIA
Unidad 2: Introducción a la probabilidad
• Introducción
• Teoría de Conjuntos
• Espacio Muestral
• Axiomas
• Teoremas
• Probabilidad Condicional
• Teorema de Bayes
• Independencia
• Análisis Combinatorio

1. Introducción
En la actualidad la teoría de la probabilidad ocupa un lugar importante en muchos asuntos de negocios. Los seguros y prácticas actuariales se basan firmemente en los principios de la teoría de la probabilidad. Las pólizas de seguros de vida dependen de las tablas de mortalidad, las cuales a su vez se basan en las probabilidades de muerte en edades especificas. Otras tasas de seguros tales como seguros de bienes raíces y de automóviles se determinan de manera similar. La probabilidad también juega un papel importante en la estimación del número de unidades defectuosas en un proceso de fabricación, la probabilidad de recibir pagos sobre cuentas por cobrar y las ventas potenciales de un nuevo producto. Incluso los apostadores profesionales en eventos deportivos deben tener una comprensión sólida de la teoría de la probabilidad.
Sin importar en cuenta la profesión que se haya elegido, algo sí es seguro: en algún momento se han de tomar decisiones.
Todo esfuerzo por reducir el nivel de incertidumbre en el proceso de toma de decisiones incrementará enormemente la probabilidad de que se tomen decisiones más inteligentes y bien informadas.

2. Teoría de Conjuntos
Un conjunto es un conjunto de objetos, sean números aeroplanos. Un objeto que pertenece a determinado conjunto se conoce como elemento de ese conjunto. Por lo general, se utilizan las primeras letras del alfabeto en mayúsculas, para denotar los conjuntos y las últimas letras del alfabeto en minúsculas, para denotar los elementos del conjunto.
Para especificar que ciertos elementos pertenecen a un conjunto dado, se emplean llaves {} o se hará un listado de todos los elementos, o se usará el método de la regla.
Definición 1: Dos conjuntos A y B, son iguales si, y sólo si cada elemento que pertenece a A también pertenece a B y viceversa. Es decir, dos conjuntos son iguales si ambos tienen los mismos elementos sin importar el orden ni el número de veces que un elemento aparezca en la lista.
Definición 2: A es subconjunto de B, denotado como A c B si y sólo si cada elemento que pertenece a A también pertenece a B.
Nota: Otra definición a la igualdad de conjuntos diciendo que
A = B ó B = A si y sólo sí A c B y B c A

Álgebra de Conjuntos
Definición 1: La unión de A y B, denotado como AUB es el conjunto formado por todos los elementos que pertenecen a A ó a B ó ambos, es decir:
AUB = {x/x є A o x є B}
Nota: La operación es conmutativa ya que AUB y BUA son conjuntos idénticos y es asociativa, ya que (AUB)UC = AU(BUC).
Definición 2: La intersección de A y B denotada por A∩B es el conjunto constituido por todos los elementos que pertenecen tanto a A como a B; es decir:
A∩B = {x/x є A y x є B}
Nota: La operación de intersección también es conmutativa y asociativa, así:
A∩B = B∩A Conmutativa
A∩(B∩C) = (A∩B)∩C Asociativa
También se nota que: A∩B c B y A∩B c A

Existen dos leyes distributivas que ligan las operaciones de la unión y la intersección, estas son:
1. A∩(BUC) = (A∩B)U(A∩C)
2. AU(B∩C) = (AUB)∩(AUC)
Definición 3: El complemento de A denotado como Ā con respecto a un conjunto universal (U) dado, es el conjunto de todos los elementos que le faltan a A para ser igual al conjunto universal
Ā = {x/x є A}
Se dejará al estudiante la investigación correspondiente a los diagramas de Venn.

3. Espacio Muestral
Definición 1: Un experimento es cualquier operación cuyo resultado no puede predecirse con exactitud.
Definición 2: El espacio muestral (S) de un experimento es el conjunto de todos los resultados posibles del experimento.
Definición 3: Un evento es un subconjunto del espacio muestral. Cada subconjunto es un evento.
Definición 4: Un evento ocurre si cada uno de sus elementos es el resultado del experimento
Ejemplos:
Se lanza un dado. El experimento consiste en lanzar el dado.
S = {x/x = 1,2,3,4,5,6}
Se elige al azar una carta de una baraja de 52 cartas. El experimento consiste en seleccionar la carta.
S = {x/x = 1,2,3,…..52}
Se selecciona al azar un estudiante entre el estudiantado de una universidad. El experimento consiste en seleccionar un estudiante.
S = {Lista de todos los estudiantes matriculados}

4. Axiomas de Probabilidad
Considerado formalmente, una función de probabilidad es una función conjunto cuyo valor es real y que se define de acuerdo a todos los subconjuntos del espacio muestral (S); el valor que se le asocia al subconjunto A que se denota como P(A). La asignación de probabilidad debe satisfacer tres reglas (para que pueda llamarse función de probabilidad a la función conjunto).
Uno de los métodos más utilizados es aplicando la Regla de Laplace: define la probabilidad de un suceso como el cociente entre casos favorables y casos posibles.
P(A) = No. Casos favorables ⁄ No. casos posibles
Reglas:
1. P(S) = 1
2. 0 ≤ P(A) ≤ 1, para todo A c S
3. P(A1UA2UA3U….) = P(A1)+P(A2)+P(A3)+… si Ai∩Aj = Ǿ, para todo i ≠ j.

5. Teoremas
1. P(Ǿ) = 0
2. P(Ā) = 1 – P(A)
3. P(AUB) = P(A) + P(B) - P(A∩B)
4. P(Ā∩B) = P(B) - P(A∩B)
5. P(A∩B) = P(A) - P(A∩B)
6. P(Ā∩B) = 1 – P(AUB)
7. P(ĀUB) = P(Ā) + P(B) – P(Ā∩B)
Nota: Para cualquier experimento, el espacio muestral (S) toma el papel del conjunto universal; por tanto, cualquier complemento a lo que se haga referencia se tomará con respecto a S.

6. Probabilidad Condicional
Con frecuencia se desea determinar la probabilidad de algún evento, dado que antes otro evento ya haya ocurrido. Lógicamente, esta es llamada probabilidad condicional. Se denota como P(A/B) y se lee la “probabilidad de A dado B”. Es la probabilidad de que el evento A ocurra, dado que o a condición de que el evento B ya haya ocurrido.
La probabilidad condicional se utiliza comúnmente en el planteamiento de un negocio para revisar la probabilidad de algún evento dado sobre el cual se ha recolectado información adicional. Por ejemplo, se puede estimar la probabilidad de que se haga una venta (S) a un cliente antiguo de P(S) = 0.80. Sin embargo, si se sabe posteriormente que este cliente ahora está comprando a alguien de la competencia, se puede revisar la probabilidad de que se haga una venta, dado que el comprador (C) ha presentado una oferta P(S/C) = 0.30
P(A/B) = P(A∩B) / P(B), si P(B) > 0

7. Teorema de Bayes
El Teorema de Bayes viene a seguir el proceso inverso al Teorema de la probabilidad total.
Teorema de la probabilidad total: a partir de las probabilidades del suceso A deducimos la probabilidad del suceso B.
Teorema de Bayes: a partir de que ha ocurrido el suceso B deducimos las probabilidades del suceso A.
La fórmula del Teorema de Bayes es:
P(Ai/B) = [P(Ai)*P(B/Ai)] / ∑P(Ai) * P(B/Ai)

8. Independencia
Es posible definir y tener interés en eventos A y B tales que si se sabe que si ha ocurrido A, entonces se tiene la certeza de que también ha ocurrido B. En tales casos, ciertamente hay un grado de dependencia entre A y B. También es posible tener dos eventos A y B, en los que no se sabe si B ha ocurrido o no, aunque se sepa que A haya ocurrido. A esta clase de eventos se les conoce como independientes (o estadísticamente independientes).
Definición 1: Dos eventos A y B son independientes si y sólo si P(A∩B) = P(A)*P(B), conocida como la regla de la multiplicación.
Para que dos sucesos sean independientes tienen que verificar al menos una de las siguientes condiciones:
P(B/A) = P(B) es decir, que la probabilidad de que se de el suceso B, condicionada a que previamente se haya dado el suceso A, es exactamente igual a la probabilidad de B.
P(A/B) = P(A) es decir, que la probabilidad de que se de el suceso A, condicionada a que previamente se haya dado el suceso B, es exactamente igual a la probabilidad de A.

Si los eventos son dependientes, entonces, por definición, se debe considerar el primer evento al determinar la probabilidad del segundo. Es decir, la probabilidad del evento B depende de la condición que A ya haya ocurrido. Se necesita del principio de probabilidad condicional.
Definición 2: Dos eventos A y B son dependientes si, y sólo si:
P(A∩B) = P(A)*P(B/A) conocida como laregla de la multiplicación.
Definición 3: Dos eventos A y B no son mutuamente excluyentes, si pueden ocurrir en forma simultanea.
P(AUB) = P(A) +P(B) – P(A∩B) la regla de la adición
Definición 4: Se dice que dos eventos A y B son mutuamente excluyentes, sino pueden ocurrir en forma simultanea, es decir, si y sólo si A∩B = Ǿ
Con frecuencia se confunden las definiciones de independencia y de mutua exclusividad, probablemente debido a que en el lenguaje cotidiano se usa la palabra independiente para expresar “que no tiene nada que ver con”. Esta frase puede interpretarse como que dos eventos no pueden ocurrir al mismo tiempo, lo cual se acaba de definir como mutuamente excluyentes.

9. Técnicas de Conteo y/o Análisis Combinatorio
El análisis combinatorio es una parte de la matemática que estudia las técnicas de enumeración de los distintos arreglos de los elementos de un grupo o conjunto. Un arreglo puede distinguirse de otro por las siguientes características:
• El número de elementos
• La clase o naturaleza de los elementos.
• El orden de colocación de los mismos.
Dado un grupo de “m” elementos, puede ocurrir:
• Que los elementos sean distintos; en este caso, a los grupos se les denomina Agrupaciones Simples.
• Que los elementos sean iguales; en este caso, a los grupos se les denomina Agrupaciones con Repetición.
Considerando la naturaleza de los elementos (que sean iguales o distintos), las agrupaciones recibirán el nombre de variaciones, permutaciones y combinaciones.
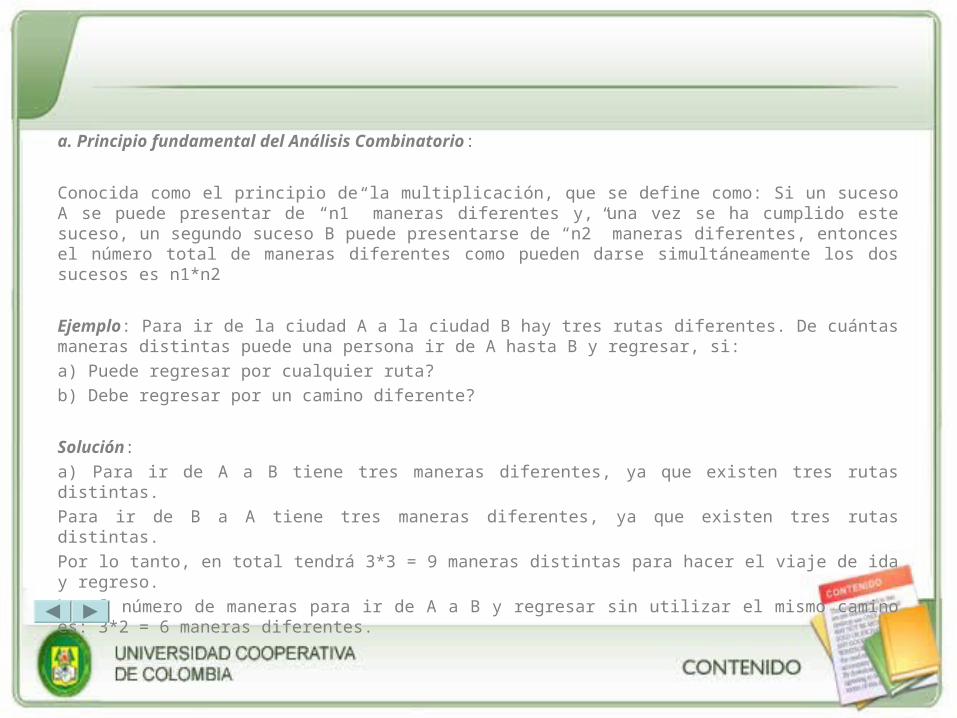
a. Principio fundamental del Análisis Combinatorio:
Conocida como el principio de la multiplicación, que se define como: Si un suceso A se puede presentar de “n1” maneras diferentes y, una vez se ha cumplido este suceso, un segundo suceso B puede presentarse de “n2” maneras diferentes, entonces el número total de maneras diferentes como pueden darse simultáneamente los dos sucesos es n1*n2
Ejemplo: Para ir de la ciudad A a la ciudad B hay tres rutas diferentes. De cuántas maneras distintas puede una persona ir de A hasta B y regresar, si:
a) Puede regresar por cualquier ruta?
b) Debe regresar por un camino diferente?
Solución:
a) Para ir de A a B tiene tres maneras diferentes, ya que existen tres rutas distintas.
Para ir de B a A tiene tres maneras diferentes, ya que existen tres rutas distintas.
Por lo tanto, en total tendrá 3*3 = 9 maneras distintas para hacer el viaje de ida y regreso.
b) El número de maneras para ir de A a B y regresar sin utilizar el mismo camino es: 3*2 = 6 maneras diferentes.
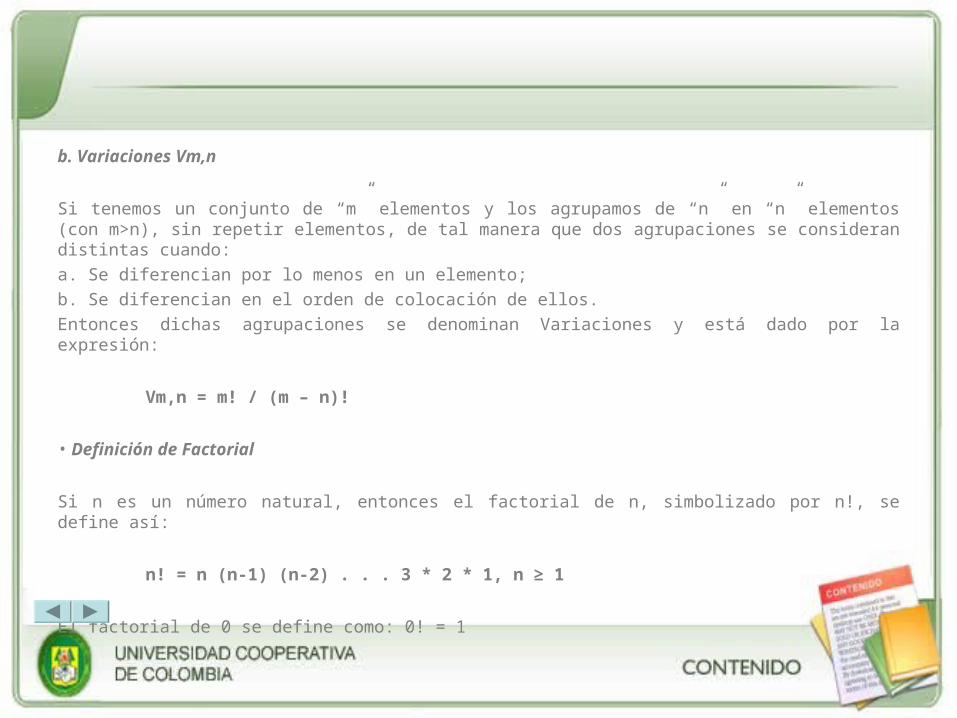
b. Variaciones Vm,n
Si tenemos un conjunto de “m” elementos y los agrupamos de “n” en “n” elementos (con m>n), sin repetir elementos, de tal manera que dos agrupaciones se consideran distintas cuando:
a. Se diferencian por lo menos en un elemento;
b. Se diferencian en el orden de colocación de ellos.
Entonces dichas agrupaciones se denominan Variaciones y está dado por la expresión:
Vm,n = m! / (m – n)!
• Definición de Factorial
Si n es un número natural, entonces el factorial de n, simbolizado por n!, se define así:
n! = n (n-1) (n-2) . . . 3 * 2 * 1, n ≥ 1
El factorial de 0 se define como: 0! = 1

Ejemplo: Un estudiante que ingresa a la universidad debe tomar cursos en las áreas de: matemáticas, humanidades, sociales y lenguas modernas. Si puede elegir entre tres cursos de matemáticas, dos de lenguas modernas, cuatro de sociales y 3 de humanidades. De cuántas maneras puede hacer su programa de estudio si:
a) Debe tomar un curso en cada área?
b) Únicamente puede tomar un curso en matemáticas, uno en lenguas modernas y uno en humanidades?
» Solución:
a) En matemáticas debe tomar un curso entre tres posibles.
V3,1 = 3! / 2! = 3
En lenguas modernas debe elegir un curso entre dos disponibles
V2,1 = 2! / 1! = 2
En sociales debe elegir uno entre cuatro disponibles
V4,1 = 4! / 3! = 4
En humanidades, de tres cursos disponibles, debe elegir uno
V3,1 = 3! / 2! = 3
Ahora bien, las posibles formas de organizar su programa de estudio tomando un curso encada área son: V3,1 *V2,1* V4,1* V3,1 = 3 * 2 * 4 * 3 = 72 formas diferentes.

b) Como no debe tener ningún curso de sociales, entonces su programa de estudio puede organizarlo así:
V3,1 *V2,1* V3,1 = 3 * 2 * 3 = 18 formas diferentes.
c. Permutaciones Pm
Las variaciones que pueden hacerse en un conjunto de “m” elementos, cuando los elementos se agrupan de “n” en “n” (con m = n) se denominan Permutaciones de “m” elementos.
De la definición se concluye que dadas dos ó más permutaciones del mismo orden, ellas difieren sólo en el orden de colocación de los elementos. Está dado por la expresión:
Vm,m = Pm = m! / (m – m)! = m! / 0! = m!
Ejemplo: De cuántas maneras pueden sentarse tres damas y dos caballeros en una fila de cinco asientos, de modo que: a) puede hacerlo en cualquier sitio; b) las damas y los caballeros no se separan.
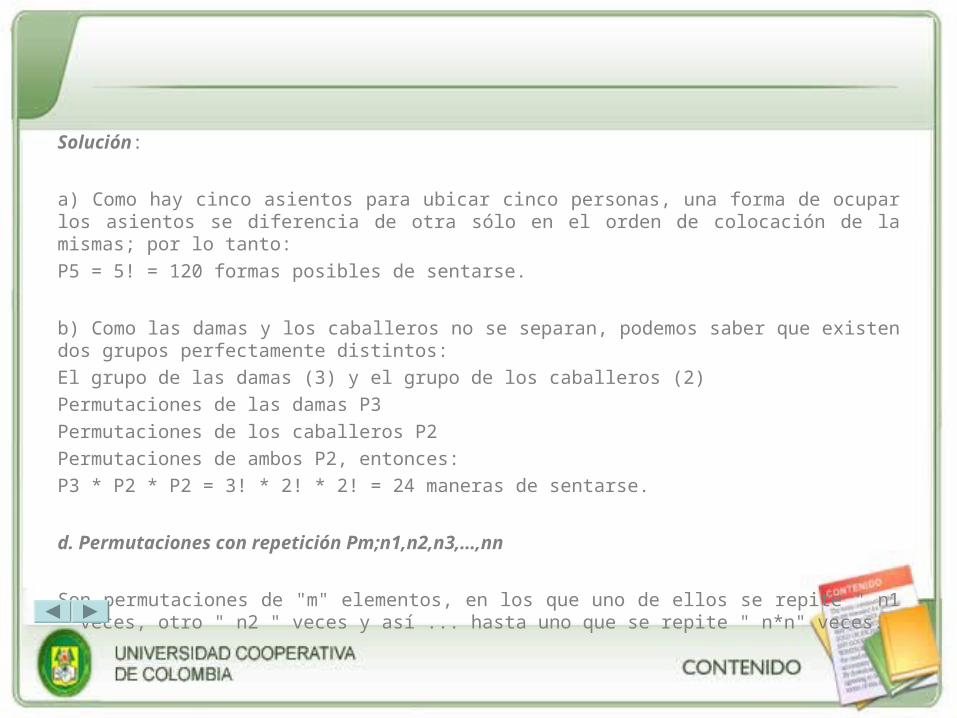
Solución:
a) Como hay cinco asientos para ubicar cinco personas, una forma de ocupar los asientos se diferencia de otra sólo en el orden de colocación de la mismas; por lo tanto:
P5 = 5! = 120 formas posibles de sentarse.
b) Como las damas y los caballeros no se separan, podemos saber que existen dos grupos perfectamente distintos:
El grupo de las damas (3) y el grupo de los caballeros (2)
Permutaciones de las damas P3
Permutaciones de los caballeros P2
Permutaciones de ambos P2, entonces:
P3 * P2 * P2 = 3! * 2! * 2! = 24 maneras de sentarse.
d. Permutaciones con repetición Pm;n1,n2,n3,…,nn
Son permutaciones de "m" elementos, en los que uno de ellos se repite " n1 " veces, otro " n2 " veces y así ... hasta uno que se repite " n*n" veces.
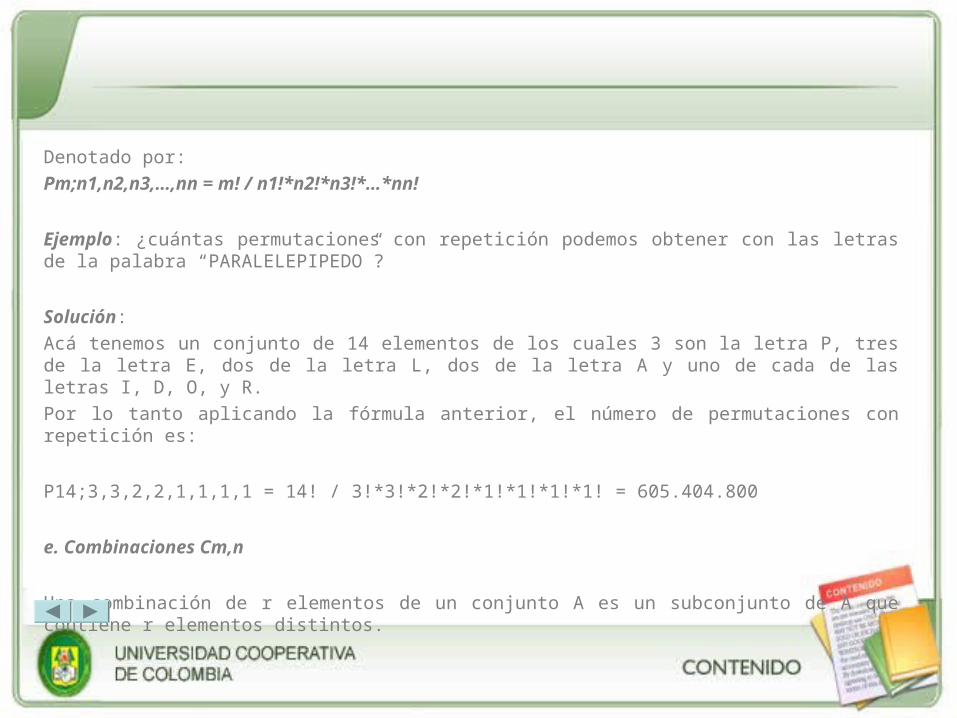
Denotado por:
Pm;n1,n2,n3,…,nn = m! / n1!*n2!*n3!*…*nn!
Ejemplo: ¿cuántas permutaciones con repetición podemos obtener con las letras de la palabra “PARALELEPIPEDO”?
Solución:
Acá tenemos un conjunto de 14 elementos de los cuales 3 son la letra P, tres de la letra E, dos de la letra L, dos de la letra A y uno de cada de las letras I, D, O, y R.
Por lo tanto aplicando la fórmula anterior, el número de permutaciones con repetición es:
P14;3,3,2,2,1,1,1,1 = 14! / 3!*3!*2!*2!*1!*1!*1!*1! = 605.404.800
e. Combinaciones Cm,n
Una combinación de r elementos de un conjunto A es un subconjunto de A que contiene r elementos distintos.

El número de combinaciones de “r” elementos que se pueden obtener de un conjunto de “n” elementos está dado por:
Cm,n = Vm,n / n! = m! / n!(m-r)!
Ejemplo: Si se toman 12 libros, cuántas maneras puede hacerse una selección de 6?
Solución:
m = 12 libros
n = selección de 6. No interesa el orden y no hay repetición.
C12,6 = 12! / 6!(12-6)! = 12! / 6!*6! = 924 selecciones.

UNIDAD 3:VARIABLES ALEATORIAS
• Definición
• Tipos de Variables Aleatorias
• Distribución de Probabilidad
• Media y Varianza de una Distribución Discreta
• Desigualdad de Chebishev

1. Definición
Una variable aleatoria es una variable cuyo valor es el resultado de un evento aleatorio. Se supone que se lanza una moneda tres veces y se anota el número de caras que se obtienen. Los posibles resultados son 0 caras, 1 cara, 2 caras, o 3 caras. La variable aleatoria es el número de caras que se obtienen, y los posibles resultados son los valores de la variable aleatoria. Como segundo ejemplo, los pesos de envío del agua mineral en contenedores oscilaban aleatoriamente entre 10 a 25 libras. Los pesos reales de los contenedores, en libra, son los valores de la variable aleatoria “peso”.
Tal y como lo sugieren estos ejemplos, la variables aleatorias pueden ser de dos tipos: discretas o continuas.

Una Variable Aleatoria Discreta puede asumir sólo ciertos valores, con frecuencia números enteros, y resulta principalmente del conteo. El número de caras en el experimento del lanzamiento de la moneda es un ejemplo de variable aleatoria discreta.
Los valores de la variable aleatoria se restringen sólo a ciertos números: 0, 1, 2 y 3. El resultado del lanzamiento de un dado, el número de camiones que llegan por hora al puerto de carga, y el número de clientes que están en fila para sacar sus libros favoritos, son otros ejemplos de variables aleatorias discretas.
Una Variable Aleatoria Continua resulta principalmente de la medición y puede tomar cualquier valor, al menos dentro de un rango dado. Los pesos del agua mineral es un ejemplo, debido a que los contenedores pueden tomar cualquier valor entre 10 y 25 libras. Otros ejemplos de variables aleatorias continuas incluyen la estatura de los clientes en una tienda de ropa, los ingresos de los empleados en un centro comercial local y el tiempo transcurrido entre la llegada de cada cliente a la biblioteca. En cada caso, la variable aleatoria puede medirse con cualquier valor, incluyendo fracciones de la unidad. Aunque las unidades monetarias no pueden dividirse en un número continuo o infinito de subdivisiones (el dólar puede subdividirse sólo 100 veces), comúnmente se tratan como distribuciones continuas de probabilidad.
2. Tipos de Variables Aleatorias

3. Distribución de Probabilidad
Una distribución de probabilidad es un despliegue de todos los posibles resultados de un experimento junto con las probabilidades de cada resultado. Se puede determinar que la probabilidad de lanzar una moneda tres veces y de obtener: 1) O caras es 1/8; 2) 1 cara es 3/8; 3) 2 caras es 3/8 y 4) 3 caras es 1/8. Esta distribución de probabilidad de se presenta en la tabla 1 la cual muestra todos los resultados posibles y sus probabilidades. Vale la pena destacar que las probabilidades suman 1. La misma información puede mostrarse gráficamente.
Resultado (caras) Xi
Probabilidad P(Xi)
0 1/8
1 3/8
2 3/8
3 1/8
1
Tabla 1 Distribución discreta de Probabilidad.
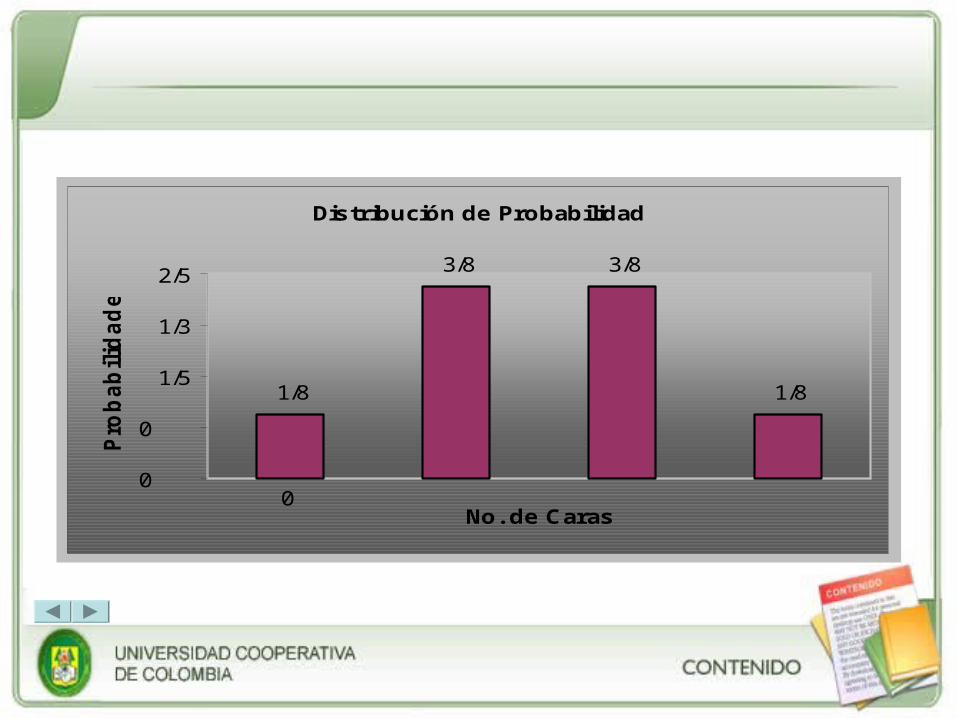
Distribución de Probabilidad
1/81/8
3/8 3/8
0
0
1/5
1/3
2/5
No. de Caras
Pro
bab
ilid
ad
es
0 1 2 3

4. Media y Varianza de las Distribuciones DiscretasLa media aritmética de una distribución de probabilidad discreta se llama el valor esperado E(x) y se halla multiplicando cada resultado posible por su probabilidad y sumando los resultados, tal y como se muestra en la fórmula:
μ = E(X) = ∑[Xi*P(Xi)]
El valor esperado de una variable aleatoria discreta es la media ponderada de todos los posibles resultados en las cuales los pesos son las probabilidades respectivas de tales resultados.
Con base en el ejemplo del lanzamiento la moneda tres veces, el valor esperado es:
E(X) = 0*1/8 + 1*3/8 + 2*3/8 + 3*1/8 = 1.5.
Interpretación: Significa que si se promedian los resultados del lanzamiento de la moneda 3 veces, se obtendrá 1.5

• La varianza de una distribución de probabilidad discreta es el promedio de las desviaciones al cuadrado con respecto de la media. La varianza puede escribirse como:
σ² = ∑[(Xi – μ)² * P(Xi)]
Esta fórmula mide la diferencia entre cada uno de los resultados y su media.
• La desviación estándar (σ) es la raíz cuadrada de la varianza y tiene la misma interpretación. Miden la dispersión de los resultados alrededor de su media. La varianza se expresa en unidades al cuadrado, pero la desviación estándar se expresa en las mismas unidades que la variable aleatoria y por ende tiene una interpretación más racional.
En nuestro ejemplo:
σ² = (0-1.5)²*1/8 + (1-1.5)²*3/8 + (2-1.5)²*3/8 + (3-1.5)²*1/8 = 0.75
σ = √0.75 = 0.87.

5. Desigualdad de Chebishev
Para calcular la probabilidad de un suceso en términos de una variable aleatoria X es necesario conocer la distribución de la variable aleatoria. La desigualdad de Chebishev provee una cota que no depende de la distribución sino sólo de la varianza de X, para el cálculo de la probabilidad de un tipo de sucesos. Una de sus formas provee además una interpretación de la varianza.
Definición: Sea X una variable aleatoria con media y varianza σ² < , entonces
P(│Xi - μ│> ε) ≤ σ²/ ε², para todo ε>0, ε = cota
• No se pide nada sobre la distribución de X, salvo que la varianza tiene que ser finita.
• La desigualdad nos muestra que cuanto más pequeño sea σ² tanto más pequeña será la probabilidad de que X esté lejos de μ.
•La cota que provee la desigualdad de Chebishev puede ser, no informativa, por ejemplo, si σ² .
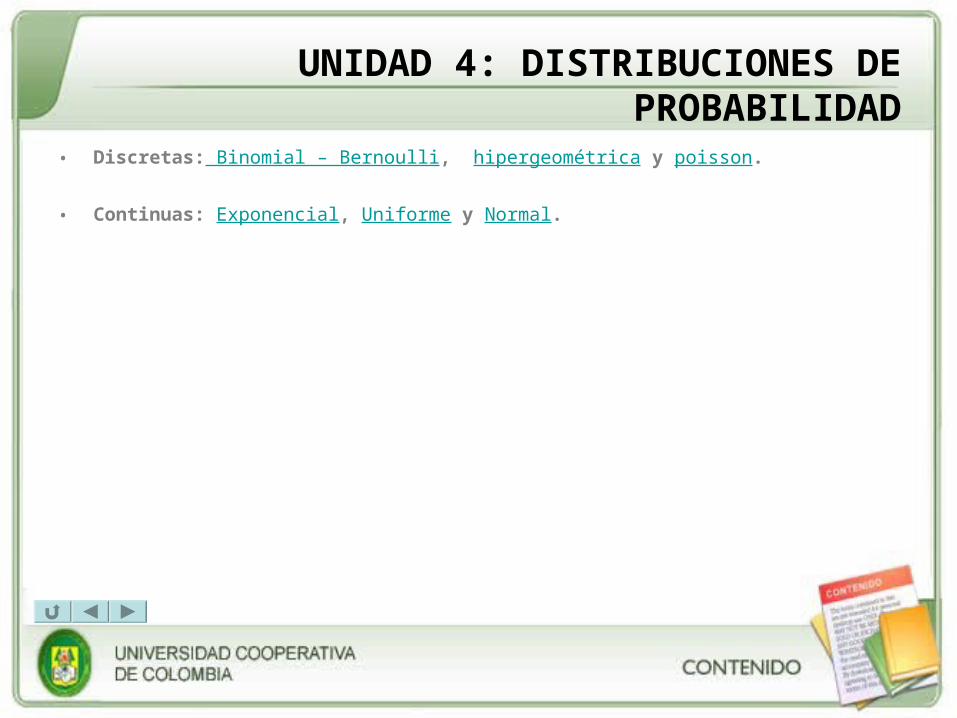
UNIDAD 4: DISTRIBUCIONES DE PROBABILIDAD
• Discretas: Binomial – Bernoulli, hipergeométrica y poisson.
• Continuas: Exponencial, Uniforme y Normal.

a. Distribución Binomial (Bernoulli)
Primero mencionaremos algunos ejemplos de las variables aleatorias. El hombre que dispara un rifle a un blanco desea saber la distancia que hay entre el punto de impacto de la bala en el blanco y en el centro del mismo. Por su parte el Jockey se interesa en el tiempo total transcurrido desde que su caballo sale del arrancadero hasta que llegue a la meta. Se llama variable aleatoria a aquella cuyo valor esta determinado por el resultado de un experimento. La definición formal de variable aleatoria es la siguiente:
Definición 1: Una variable aleatoria X es una función de valor real de los elementos de un espacio muestral S.
Antes de dar las definiciones de estas dos variables aleatorias, se definirá primero la prueba de Bernoulli
Definición 2: Una prueba de Bernoulli es un experimento que tiene dos resultados posibles, a los cuales se les llama éxito y fracaso.
En general se denota S = {e, f} al espacio muestral para una prueba de Bernoulli.
1. Distribuciones Discretas

Ejemplos de prueba de Bernoulli:
• Se lanza al aire una moneda (cara o sello)
• El vuelo de un proyectil (da en el blanco o no)
• El aprovechamiento de un estudiante en determinado curso (aprueba o reprueba)
• El desempeño de un equipo de atletismo (gana o no gana)
Se puede considerar como prueba de Bernoulli a cualquier mecanismo de azar cuyos resultados se pueden agrupar en dos clases:
La notación es: P(e) = P Probabilidad de éxito
P(f) = 1- P Probabilidad de fracaso
• Definición 3: Sea X el número total de éxitos en las n pruebas independientes y repetidas de Bernoulli con probabilidad P de éxito en una prueba dada. A X se le llama variable aleatoria Binomial con parámetros n y P.
El rango de la variable aleatoria X lo constituyen los enteros 0,1,2,…, n; por tanto, X es una variable aleatoria discreta y como tal debe tener una función de probabilidad . La función de probabilidad se satisface si se conocen los valores de n y P.

La función de probabilidad de obtiene como sigue:
Teorema 1: Si X es una Binomial con parámetros n y P, entonces
Px(X) = Cn,x * px * qn-x , x = 0, 1, 2, …., n
• Ejemplo: La probabilidad de que un jugador de baloncesto anote un tiro libre es de ¾ , y sus tiros son independientes. Suponiendo que puede hacer 5 tiros libres en un juego. Cuál es la probabilidad de que acierte en todos?; de que falle en todos?
•Solución:
La función de probabilidad esta dada por:
Px(X) = C5,x * (3/4)x * (1/4)5-x , x = 0,1,2,3,4,5
Que acierte en todos los tiros
Px(5) = C5,5 * (3/4)5 * (1/4)0 = 0.237
Que falle en todos los tiros
Px(0) = C5,0 * (3/4)0 * (1/4)5 = 0.000976

•La Media y Varianza de una Distribución Binomial
Antes se mostró como determinar la media y varianza de una distribución discreta. Sin embargo, si sólo hay dos resultados posibles, como en la distribución Binomial la media y la varianza pueden determinarse fácilmente.
•Media: μ = E(X) = n*p
•Varianza: σ² = n*p*q
Con base en nuestro ejemplo anterior tenemos:
•μ = E(X) = 5*3/4 = 3.75
•σ² = 5 * ¾ * ¼ = 0.9375
•σ = √0.9375 = 0.968

b. La Distribución Hipergeométrica
Como se acaba de explicar, la distribución binomial es apropiada sólo si la probabilidad de un éxito permanece constante para cada intento. Esto ocurre si el muestreo se realiza con reemplazo o de una población finita ( o muy grande). Sin embargo, si la población es pequeña y ocurre el muestreo sin reemplazo, la probabilidad de un éxito variará. Si la probabilidad de un éxito no es constante, la distribución hipergeométrica es de especial utilidad. La función de probabilidad para la distribución hipergeométrica es:
Px(X) = Cr,x * CN-r, n-x / CN,n
En donde: N = Es el tamaño de la población
n = Es el tamaño de la muestra
r = Es el número de éxitos en la población
x = Es el número de éxitos en la muestra
Si se selecciona una muestra sin reemplazo de una población finita conocida y contiene una proporción relativamente grande de la población, de manera que la probabilidad de éxito sea perceptiblemente alterada de una selección a la siguiente, debe utilizarse la distribución hipergeométrica.

Ejemplo: Supongamos que en un establo de carreras hay 10 caballos y 4 de ellos tienen una enfermedad contagiosa. Cuál es la probabilidad de seleccionar una muestra de 3 en la cual hay 2 caballos enfermos?
Solución:
N = 10, n = 3, r = 4, x = 2
Px(X=2) = C4,2 * C10-4,3-2 / C10,3 = 6 * 6 / 120 = 0.30
Existe un 30% de probabilidad de seleccionar tres caballos de carrera, dos de los cuales están enfermos.
c. La Distribución de Poisson
Una variable aleatoria discreta de gran utilidad en la medición de la frecuencia relativa de un evento sobre alguna unidad de tiempo o espacio. Con frecuencia se utiliza para describir el número de llegadas de clientes por hora, el número de accidentes industriales cada mes, el número de conexiones eléctricas defectuosas por milla de cableado en un sistema eléctrico de una ciudad, o el número de máquinas que se dañan y esperan ser reparadas.

La distribución de Poisson ideada por el matemático francés Simeon Poisson, la distribución de Poisson mide la probabilidad de un evento aleatorio sobre algún intervalo de tiempo o espacio.
Son necesarios dos supuestos para la aplicación de la distribución de Poisson:
• La probabilidad de ocurrencia del evento es constante para dos intervalos cualquiera de tiempo o espacio.
• La ocurrencia del evento en un intervalo es independiente de la ocurrencia de otro intervalo cualquiera.
Dado estos supuestos, la función de probabilidad de Poisson puede expresarse como:
Px(X) = μx * ℮-μ / x!
Donde: x = es el número de veces que ocurre el evento
μ = es el número promedio de ocurrencia por unidad de
tiempo o espacio.
℮ ≈ 2.71828, la base del logaritmo natural.

Ejemplo: Una compañía de pavimentación local obtuvo un contrato con obras públicas para hacer mantenimiento a las vías de un gran centro urbano. Las vías recientemente pavimentadas por esta compañía mostraron un promedio de dos defectos por milla, después de haber sido utilizadas durante un año. Si el municipio sigue con esta compañía de pavimentación. ¿Cuál es la probabilidad de que presenten 3 defectos en cualquier milla de vía después de haber tenido tráfico durante un año?
Solución:
μ = 2
x = 3
Px(x = 3) = 23 * 2.71828-2 / 3! = 0.1804
Existe un 18.04% de probabilidad de encontrar 3 defectos en cualquier milla de vía después de haber tenido tráfico durante un año.

2. Distribuciones Continuas
a. La Distribución Exponencial
Como se acaba de observar, la distribución de Poisson es una distribución discreta que mide el número de ocurrencias sobre algún intervalo de tiempo o espacio. Describe por ejemplo, el número de clientes que pueden llegar durante algún período determinado. Por el contrario, la distribución exponencial es una distribución continua. Mide el paso del tiempo entre tales ocurrencias. Mientras que la distribución de Poisson describe las tasas de llegada (de personas, camiones, llamadas telefónicas, etc.) dentro de algún período dado, la distribución exponencial estima el lapso entre tales arribos. Si el número de ocurrencias tiene distribución Poisson, el lapso entre las ocurrencias estará distribuido exponencialmente.
La probabilidad de que el lapso sea menor que o igual a cierta cantidad x es:
P(X ≤ x) = 1 - ℮-μt
En donde: t = es el lapso de tiempo
℮ = es la base del logaritmo natural
μ = es la tasa promedio de ocurrencia
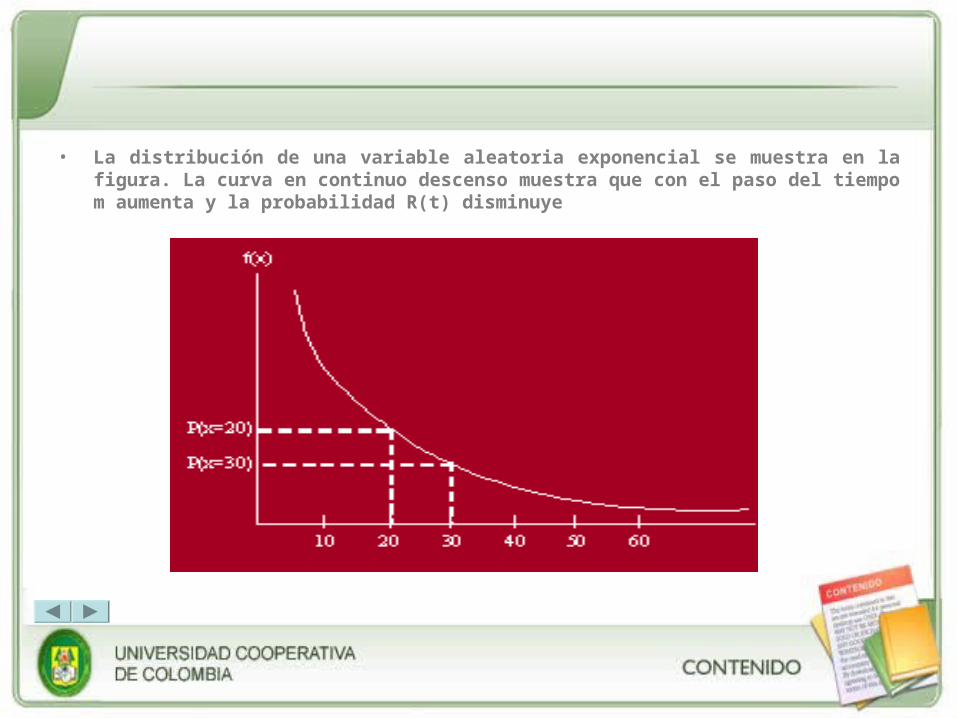
• La distribución de una variable aleatoria exponencial se muestra en la figura. La curva en continuo descenso muestra que con el paso del tiempo m aumenta y la probabilidad R(t) disminuye
Ejemplo: Aerotaxis programa sus taxis para que lleguen al aeropuerto José María Córdoba en una distribución Poisson con una tasa promedio de llegada de 12 por hora. Usted acaba de aterrizar en el aeropuerto y debe llegar al centro a cerrar un negocio. Cuál es la probabilidad de que usted tenga que esperar máximo 5 minutos para conseguir un taxi? Su jefe es un tirano que no tolerará el retraso, de manera que si la probabilidad de que pase otro taxi dentro de 5 minutos es menor al 50% usted alquilará un carro para el viaje a la oficina.
Solución:
Asumiendo lo peor, que el último taxi acaba de irse, usted debe determinar P(X ≤ 5 minutos). Debido a que μ = 12 por 60 minutos, usted debe determinar a qué porcentaje son 5 minutos de 60:
5/60 = 1/12.
Por tanto, t = 1/12 y P(X ≤ 5) = 1 - ℮-(12)(1/12) = 1- ℮-1 = 0.6321
Interpretación: Usted puede relajarse y esperar el taxi, hay una probabilidad de 63.21% (> 50%) de que llegue uno dentro de 5 minutos.
b. La Distribución Uniforme
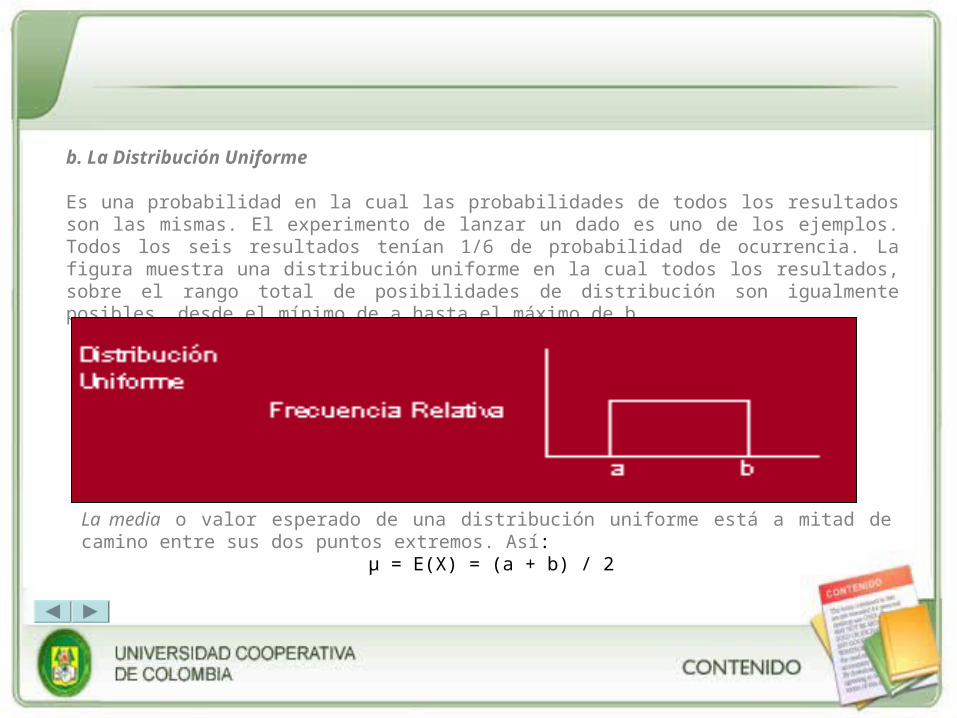
Es una probabilidad en la cual las probabilidades de todos los resultados son las mismas. El experimento de lanzar un dado es uno de los ejemplos. Todos los seis resultados tenían 1/6 de probabilidad de ocurrencia. La figura muestra una distribución uniforme en la cual todos los resultados, sobre el rango total de posibilidades de distribución son igualmente posibles, desde el mínimo de a hasta el máximo de b.
La media o valor esperado de una distribución uniforme está a mitad de camino entre sus dos puntos extremos. Así:
μ = E(X) = (a + b) / 2

La varianza es:
σ² = (b – a)² / 12
El área total bajo la curva, como en el caso de todas las distribuciones de probabilidad, debe ser igual a 1 o 100%. Debido a que el área es la altura por el ancho, la altura es:
Altura = Área / Ancho
Y por tanto
Altura = 1 / (b – a), en donde b – a es el ancho o rango de la distribución.
Ejemplo: Suponga que los contenidos de las latas de 16 onzas de fruta enlatada producida por La Constancia oscila entre 14.5 y 17.5 onzas y se ajusta a una distribución uniforme. Eso se muestra en la figura.
μ = (14.5 + 17.5) / 2 = 16 onzas
σ² = (17.5 – 14.5)² / 12 = 0.75
σ = 0.87
Altura = 1 / (17.5 – 14.5) = 1/3

Grafica de Distribución Uniforme de Productos Enlatados
Asuma que La Constancia desea saber la probabilidad de que una sola lata pese entre 16 y 17.2 onzas. Este valor está dado por el área dentro de ese rango tal y como se muestra en la figura. La probabilidad de que una observación única esté comprendida dentro de dos valores X1 y X2 es:
P(X1 ≤ X ≤ X2) = (X1 - X2) / rango
Para la lata de La Constancia, se tiene:
P( 16 < X < 17.2) = (17.2 – 16) / (17.5 – 14.5) = 0.40
c. La Distribución Normal
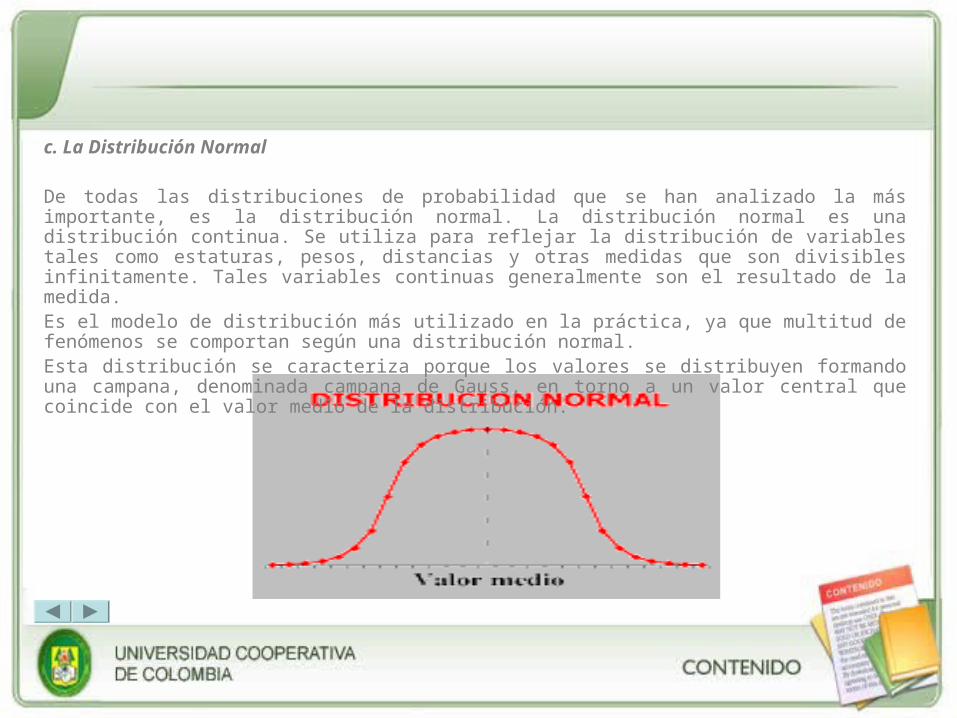
De todas las distribuciones de probabilidad que se han analizado la más importante, es la distribución normal. La distribución normal es una distribución continua. Se utiliza para reflejar la distribución de variables tales como estaturas, pesos, distancias y otras medidas que son divisibles infinitamente. Tales variables continuas generalmente son el resultado de la medida.Es el modelo de distribución más utilizado en la práctica, ya que multitud de fenómenos se comportan según una distribución normal.Esta distribución se caracteriza porque los valores se distribuyen formando una campana, denominada campana de Gauss, en torno a un valor central que coincide con el valor medio de la distribución.

De acuerdo al gráfico un 50% de los valores están a la derecha de este valor medio y otro 50% a la izquierda.
La forma y posición de una distribución normal están determinadas por dos parámetros: su media μ y su desviación estándar σ.
μ = es el valor medio de la distribución y es precisamente donde se sitúa el centro de la curva (de la campana de Gauss).
σ = es la desviación estándar. Indica si los valores están más o menos alejados del valor medio: si la desviación estándar es baja los valores están próximos a la media; si es alta, entonces los valores son muy dispersos.
1. La Regla Empírica
La regla empírica dice que si se incluyen todas las observaciones que están a una desviación estándar de la media (tanto por debajo como por encima) estas serán el 68.3% del área bajo la curva; si esta a dos desviaciones de la media del 95.5% y si esta a tres desviaciones será del 99.7%.

2. La Desviación Normal
Puede existir un número infinito de distribuciones normales posibles, cada una con su propia media y desviación estándar. Ya que obviamente no se puede analizar un número tan grande de posibilidades, es necesario convertir todas estas distribuciones normales a una forma estándar. Esta conversión a la distribución normal estándar se efectúa con la fórmula de conversión ( o fórmula Z).
Desviación Normal: Z =( Xi – μ ) / σ
Ejemplo: Un gran fabricante de ropas, desea estudiar en la estatura de las personas. El fabricante reconoció que el público estaba en constante cambio en su tamaño físico y proporciones. En un esfuerzo por producir ropa de mejor ajuste, la gerencia sintió que necesitaba un análisis completo de las tendencias actuales en los tamaños de moda. De acuerdo a sus clientes potenciales, encontrarían que las estaturas están distribuidas normalmente alrededor de una media de 67 pulgadas y con una desviación estándar de 2 pulgadas.

Con base en el ejemplo anterior calcular la desviación normal de las siguientes estaturas: 63, 67 y 70 pulgadas.
Z = (63 – 67) / 2 = - 2 Quere decir que esta a 2 desviaciones por debajo de la media.
Z = (67 – 67) / 2 = 0 Quiere decir que esta a 0 desviaciones de la media.
Z = (70 – 67) / 2 = 1.5 Quiere decir que esta 1.5 desviaciones por encima de la media.
Si un cliente tiene una desviación normal de -1.5 por debajo de la media. Cuánto mide el cliente?
-1.5 = (Xi – 67) / 2
-3 = Xi – 67
Xi = 64 pulgadas.
•Entonces, el valor de Z es el número de desviaciones a las que una observación está por encima o por debajo de la media.

3. Cálculo de Probabilidades con la Desviación Normal
Estandarizar una distribución normal permite determinar más fácilmente la probabilidad de que ocurra ciento evento.
El fabricante de ropas puede hallar la probabilidad de que un solo cliente tenga entre 67 y 69 pulgadas de estatura, es decir, P(67 ≤ Xi ≤ 69), simplemente hallando el área bajo la curva normal entre 67 y 69 pulgadas. Es decir, si se conoce el área se conoce la probabilidad.
El área relacionada con un valor de Z puede hallarse en la Tabla. Se desea saber el área que esta entre 67 y 69 pulgadas.
Z = (67 – 67) / 2 = 0 y Z = (69 – 67) / 2 = 1
Entonces, P(67 ≤ Xi ≤ 69) = P(0 < Z < 1) = P(Z ≥ 0) + P(Z ≤ 1).
En la tabla se halla el valor de Z = 0 y se encontrará 0 y el valor de Z = 1 y será de 0.3413. Es decir, el 34.13% del área que está bajo la curva esta entre 67 y 69 pulgadas. Hay un 34.13% de probabilidad de que un cliente seleccionado mida entre 67 y 69 pulgadas.
Aunque la tabla muestra solamente el área desde la media hasta algún valor por encima o por debajo de ella, otras probabilidades pueden hallarse fácilmente. Suponiendo que el fabricante de ropa debe determinar la probabilidad de que un cliente mida más de 69 pulgadas, es decir, P(Xi > 69).
Ya se ha establecido que el 34.13% de todos los clientes miden entre 67 y 69 pulgadas. Además también se sabe que el 50% de todos los clientes esta por encima de la media de 67. Esto deja 0.5000 – 0.3413 = 0.1587 en el área de la cola que va más alla de 1. Hay un 15.87% de probabilidad que un cliente escogido aleatoriamente mida más de 69 pulgadas.
Vale la pena notar que entre mayor sea el valor de Z, menor será el área en la cola de la distribución.

4. Aproximación Normal a la Distribución Binomial
La distribución binomial involucra una serie de n ensayos que puede producir un éxito p o un fracaso q = 1 – p. Las respuestas pueden hallarse a menudo en la tabla binomial o utilizando la fórmula de la binomial. Sin embargo, si n es demasiado grande, puede exceder los valores de cualquier tabla y la fórmula puede ser excesivamente engorrosa. La solución puede hallarse con el uso de la distribución normal para aproximar la distribución binomial. Esta aproximación se considera lo suficientemente precisa si np ≥ 5 y npq ≥ 5 y si p está proximo a 0.5.
Se considera que un sindicato laboral en el cual el 40% de los miembros está a favor de una huelga. Si se seleccionan 15 miembros de manera aleatoria. Cuál es la probabilidad de que 10 apoyen la huelga?
Calculamos: μ = 15 * 0.4 = 6 y σ = √15*0.4*0.6 = 1.897
Debido a que existe un número infinito de valores posibles en una distribución normal ( o en cualquier distribución continua), la probabilidad de que la variable aleatoria se exactamente igual a algún valor específico como 10, es cero.

Cuando se utiliza una distribución continua para estimar una variable aleatoria discreta, es necesario un leve ajuste. Este ajuste, llamado Factor de Corrección de Continuidad es convertir, ese valor discreto en forma continua. Es decir, restar 0.5 y sumar 0.5 a ese valor.
P(9.5 ≤ Xi ≤ 10.5) = P(1.85 ≤ Z ≤ 2.37) = P(Z ≤ 2.37) – P(Z ≥ 1.85)
= 0.4911 – 0.4678
= 0.0233
Z = 1.85, Área = 0.4678
Z = 2.37, Área = 0.4911
Sólo el 2.33% de los 10 miembros apoyen la huelga.
UNIDAD 5: MUESTREO Y TECNICAS DE MUESTREO
• Definición: Muestras aleatorias, errores en el muestreo, error muestral y distribuciones muestrales.
• Tamaño de la Muestra.
• Técnicas de Muestreo: Aleatoria Simple, Estratificado, Por Conglomerados, y Sistemático.

1. Definición
Uno de los propósitos de la estadística inferencial es estimar las características poblacionales desconocidas, examinando la información obtenida de una muestra, de una población. El punto de interés es la muestra, la cual debe ser representativa de la población objeto de estudio.
Se seguirán ciertos procedimientos de selección para asegurar de que las muestras reflejen observaciones a la población de la que proceden, ya que sólo se pueden hacer observaciones probabilísticas sobre una población cuando se usan muestras representativas de la misma.
Una población esta conformada por la totalidad de las observaciones en los cuales se tiene cierta observación.
Una muestra es un subconjunto de observaciones seleccionadas de una población.
a. Muestras Aleatorias
Cuando nos interesa estudiar las características de poblaciones grandes, se utilizan muestras por muchas razones; una enumeración completa de la población, llamada censo, puede ser económicamente costoso, o no se cuenta con el tiempo suficiente.

A continuación se verá algunos usos del muestreo en diversos campos:
•Política: Las muestras de las opiniones de los votantes se usan para que los candidatos midan la opinión pública y el apoyo en las elecciones.
•Educación: Las muestras de las calificaciones de los exámenes de estudiantes se usan para determinar la eficiencia de una técnica o programa de enseñanza.
•Industria: Muestras de los productos de una línea de ensamble sirve para controlar la calidad.
•Medicina: Muestras de medid de azúcar en la sangre de pacientes diabéticos prueban la eficacia de una técnica o de un fármaco nuevo.
•Agricultura: Las muestras de maíz cosechado en una parcela proyectan en la producción los efectos de un fertilizante nuevo.
•Gobierno: Una muestra de opiniones de los votantes se usaría para determinar los criterios del público sobre cuestiones relacionadas con el bienestar y la seguridad nacional.

b. Errores en el Muestreo
Cuando se utilizan valores muestrales, o estadísticos para estimar valores poblacionales, o parámetros, puede ocurrir dos tipos generales de errores: el error muestral y el error no muestral.
El error muestral se refiere a la variación natural existente entre muestras tomadas de la misma población.
Cuando una muestra no es una copia exacta de la población; aún si se han tenido gran cuidado para asegurar que dos muestras del mismo tamaño sean representativas de una cierta población, no esperaríamos que las dos sean idénticas en todos sus detalles. El error muestral es un concepto importante que ayudará a entender mejor la naturaleza de la estadística inferencial.
Los errores que surgen al tomar muestras no pueden clasificarse como errores muestrales y se denominan errores no muestrales.
El sesgo de las muestras es un tipo de error no muestral. El sesgo muestral se refiere a una tendencia sistemática inherente a a un método de muestreo que da estimaciones de un parámetro que son, en promedio, menores (sesgo negativo), o mayores (sesgo positivo) que el parámetro real.
El sesgo muestral puede suprimirse, o minimizarse, usando la aleatorización.
La aleatorización se refiere a cualquier proceso de selección de una muestra de la población en el que la selección es imparcial o no está sesgada; una muestra elegida con procedimientos aleatorios se llama muestra aleatoria.
Los tipos más comunes de técnicas de muestreo aleatorios son el muestreo aleatorio simple, el muestreo estratificado, el muestreo por conglomerados y el muestreo sistemático.
c. Error Muestral
Cualquier medida conlleva algún error. Si se usa la media para medir, estimar, la media poblacional μ, entonces la media muestral, como medida, conlleva algún error. Por ejemplo, supongamos que se ha obtenido una muestra aleatoria de tamaño 25 de una población con media μ = 15: si la media de la muestra es X = 12, entonces a la diferencia observada X- μ = -3 se le denomina el error muestral.
Una media muestral Xm puede pensarse como la suma de dos cantidades, la media poblacional μ y el error muestral; si e denota el error muestral, entonces:
X = μ + e
Ejemplo: Se toman muestras de tamaño 2 de una población consistente en tres valores 2, 4, y 6, para simular una población “grande” de manera que el muestreo pueda realizarse un gran número de veces, supondremos que éste se hace con reemplazo, es decir, el número elegido se reemplaza antes de seleccionar el siguiente, además, se seleccionan muestras ordenadas. En una muestra ordenada, el orden en que se selccionan las observaciones es importante, por tanto, la muestra ordenada (2,4) es distinta de la muestra ordenada (4,2). En la muestra (4,2), se seleccionó primero 4 y después 2.

Muestras Ordenadas X e = X - μ
(2,2) 2 2 – 4 = - 2
(2,4) 3 3 – 4 = - 1
(2,6) 4 4 – 4 = 0
(4,2) 3 3 – 4 = - 1
(4,4) 4 4 – 4 = 0
(4,6) 5 5 – 4 = 1
(6,2) 4 4 – 4 = 0
(6,4) 5 5 – 4 = 1
(6,6) 6 6 – 4 = 2
La siguiente tabla contiene una lista de todas las muestras ordenadas de tamaño 2 que es posible seleccionar con reemplazo y también contiene las medias muestrales y los correspondientes errores muestrales. La media poblacional es igual a
μ = (2 + 4 + 6)/3 = 4.

Nótese las interesantes relaciones siguientes contenidas en la tabla.
La media de la colección de medias muestrales es 4, la media de la población de la que se extrae las muestras. Sí μx denota la media de todas las medias muestrales entonces tenemos:
μx = (3 + 4 + 3 + 4 + 5 + 5 + 2 + 4 + 6)/9 = 4
La suma de los errores muestrales es cero.
e1 + e2 + e3 + . . . + e9 = (-2)+(-1)+0+(-1)+0+1+0+1+2 = 0
En consecuencia, si X se usa para medir, estimar, la media poblacional μ, el promedio de todos los errores muestrales es cero.
d. Distribuciones Muestrales
Las muestras aleatorias obtenidas de una población son, por naturaleza propia, impredecibles. No se esperaría que dos muestras aleatorias del mismo tamaño y tomadas de la misma población tenga la misma media muestral o que sean completamente parecidas; puede esperarse que cualquier estadístico, como la media muestral, calculado a partir de las medias en una muestra aleatoria, cambie su valor de una muestra a otra.

•Por ello, se quiere estudiar la distribución de todos los valores posibles de un estadístico. Tales distribuciones serán muy importantes en el estudio de la estadística inferencial, porque las inferencias sobre las poblaciones se harán usando estadísticas muestrales. Como el análisis de las distribuciones asociadas con los estadísticos muestrales, podremos juzgar la confiabilidad de un estadístico muestral como un instrumento para hacer inferencias sobre un parámetro poblacional desconocido.
•Como los valores de un estadístico, tal como X, varían de una muestra aleatoria a otra, se le puede considerar como una variable aleatoria con su correspondiente distribución de frecuencias.
•La distribución de frecuencia de un estadístico muestral se denomina distribución muestral. En general, la distribución muestral de un estadístico es de todos sus valores posibles calculados a partir de muestras del mismo tamaño.
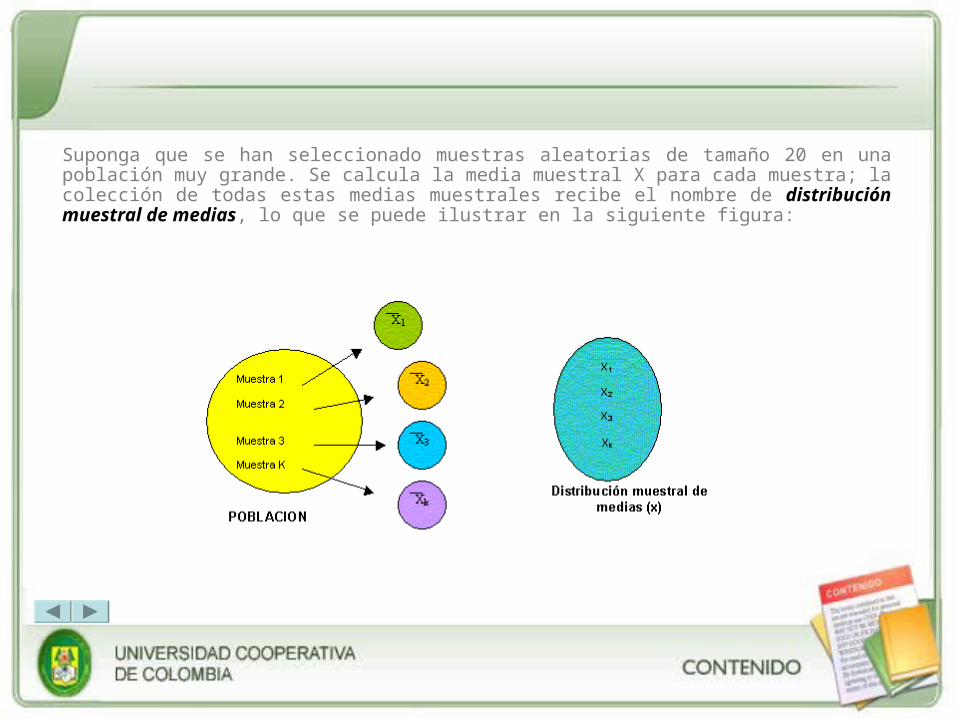
Suponga que se han seleccionado muestras aleatorias de tamaño 20 en una población muy grande. Se calcula la media muestral X para cada muestra; la colección de todas estas medias muestrales recibe el nombre de distribución muestral de medias, lo que se puede ilustrar en la siguiente figura:
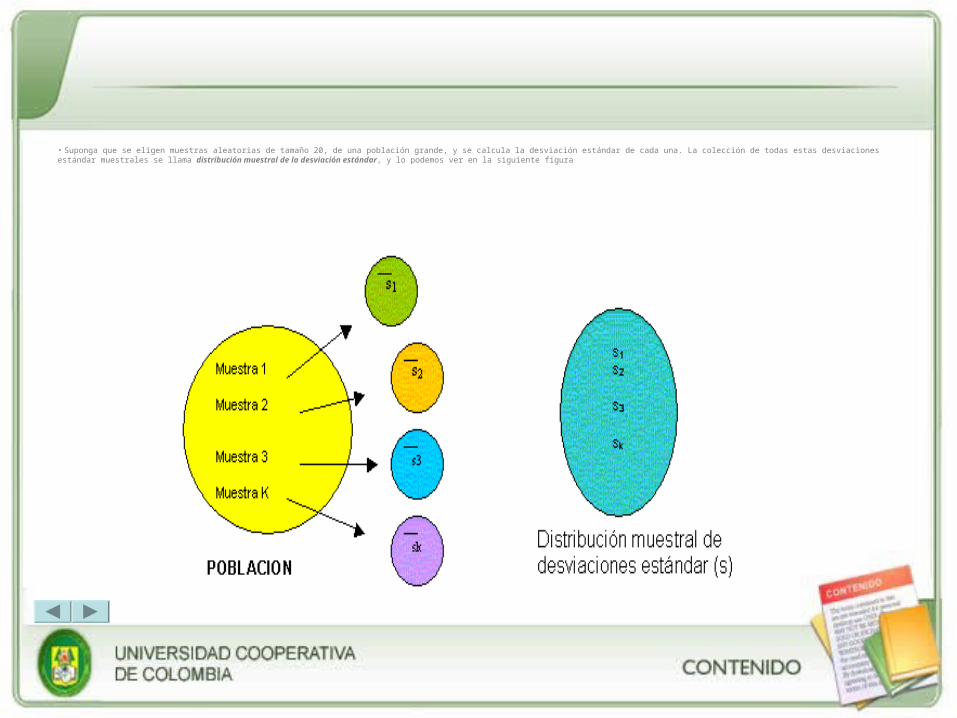
• Suponga que se eligen muestras aleatorias de tamaño 20, de una población grande, y se calcula la desviación estándar de cada una. La colección de todas estas desviaciones estándar muestrales se llama distribución muestral de la desviación estándar, y lo podemos ver en la siguiente figura

Ejemplo: Se eligen muestras ordenadas de tamaño 2, con reemplazo, de la población de valores 0, 2, 4 y 6. Encuentre:
μ, la media poblacional.
σ, la desviación estándar poblacional.
μx, la media de la distribución muestral de medias.
σx, la desviación estándar de la distribución muestral de medias.
Además, grafique las frecuencias para la población y para la distribución muestral de medias.
Solución:
a. La media poblacional es: μ = (0 + 2 + 4 + 6)/4 = 3
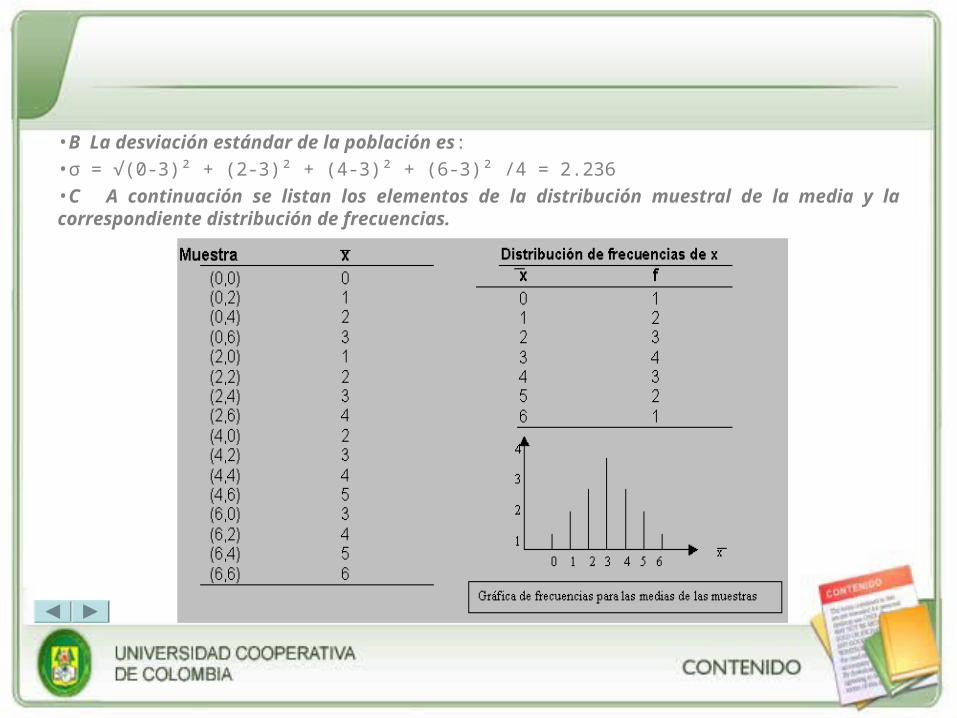
•B La desviación estándar de la población es:
•σ = √(0-3)² + (2-3)² + (4-3)² + (6-3)² /4 = 2.236
•C A continuación se listan los elementos de la distribución muestral de la media y la correspondiente distribución de frecuencias.

La media de la distribución muestral de medias es:
μx = ∑f(Xm) / ∑f = (0)(1)+(1)(2)+(2)(3)+(3)(4)+…+(6)(1)/16 = 3
d. La desviación estándar de la distribución muestral de medias es:
σx = √∑(Xm - μx )²*f / ∑f
σx = √(0-3)²*1+(1-3)²*2+(2-3)²*3+(3-3)²*4+….+(6-3)²*1)/16 = 1.58
De aquí podemos deducir que: σx = σ /√n = 2.236 /√4 = 1.58
Como para cualquier variable aleatoria, la distribución muestral de medias tiene una media o valor esperado, una varianza y una desviación estándar, se puede que la distribución muestral de medias tiene una media igual a la media poblacional. Esto es:
μx = E(Xm) = μ = 3
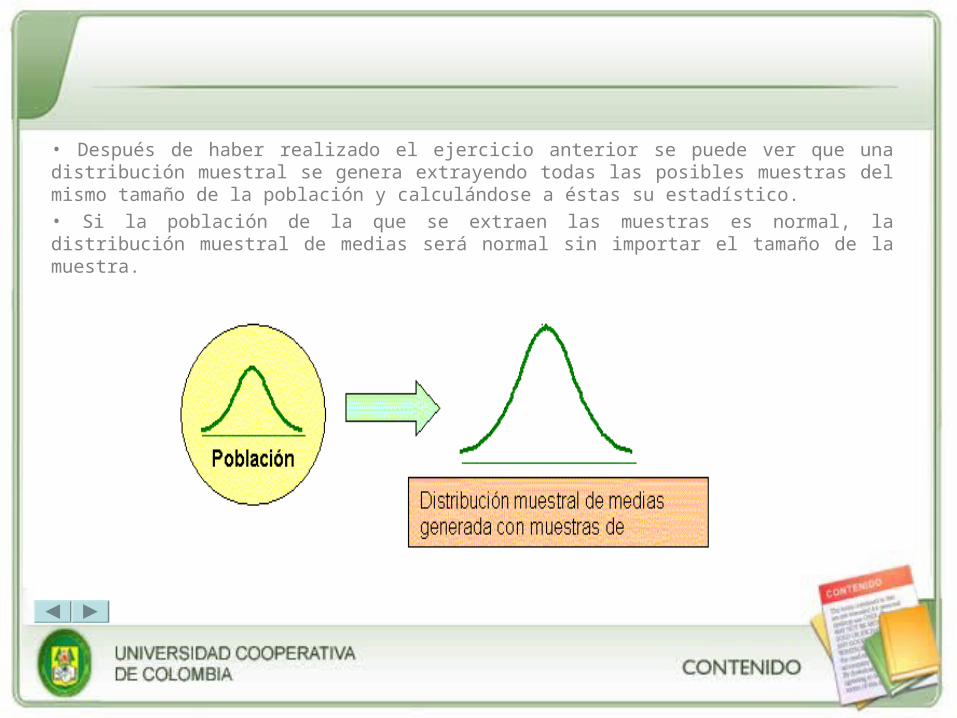
• Después de haber realizado el ejercicio anterior se puede ver que una distribución muestral se genera extrayendo todas las posibles muestras del mismo tamaño de la población y calculándose a éstas su estadístico.
• Si la población de la que se extraen las muestras es normal, la distribución muestral de medias será normal sin importar el tamaño de la muestra.
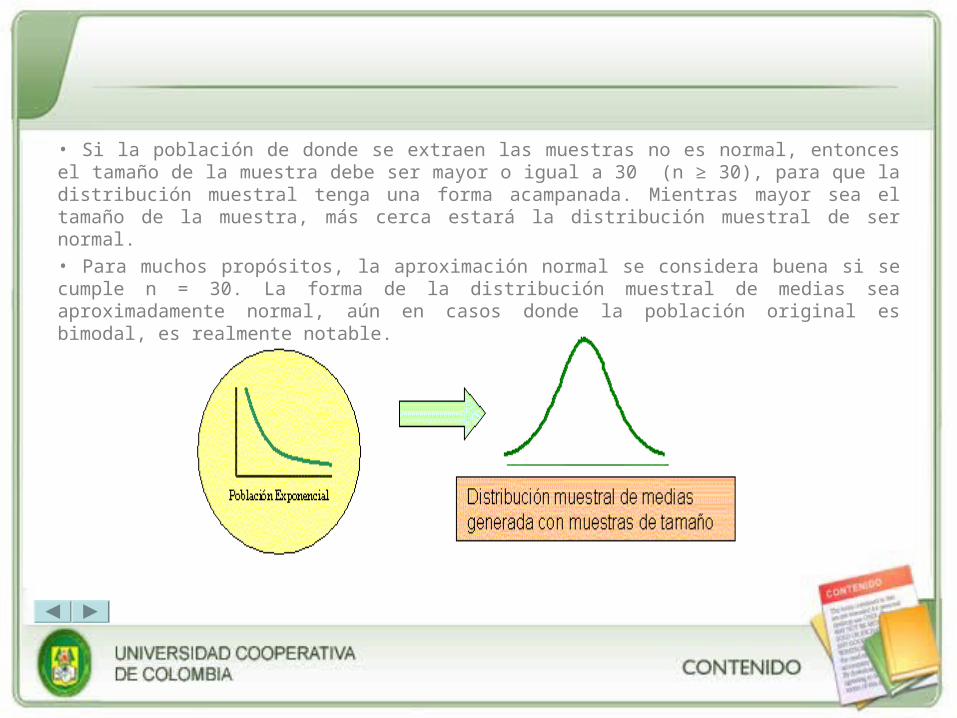
• Si la población de donde se extraen las muestras no es normal, entonces el tamaño de la muestra debe ser mayor o igual a 30 (n ≥ 30), para que la distribución muestral tenga una forma acampanada. Mientras mayor sea el tamaño de la muestra, más cerca estará la distribución muestral de ser normal.
• Para muchos propósitos, la aproximación normal se considera buena si se cumple n = 30. La forma de la distribución muestral de medias sea aproximadamente normal, aún en casos donde la población original es bimodal, es realmente notable.

2. Tamaño de la Muestra
Cuando se hace una muestra, uno debe preguntarse: dado que una población es de N, ¿cuál es el menor número de unidades muestrales (personas, organizaciones, capítulos de telenovelas, etc.), que necesito para conformar una muestra (n) que me asegure un error estándar menor de 0.01?
La solución a esta pregunta pretende encontrar la probabilidad de ocurrencia de μx y que mi estimado de μx se acerque a μ, el valor real de la población. Sí establecemos el error estándar y fijamos 0.01, se sugiere que esta fluctuación promedio del estimado μx con respecto a los valores reales de la población μ, no sea > 0.01, es decir que de 100 casos, 99 veces mi predicción sea correcta y que el valor de μx se sitúe en un intervalo de confianza que comprenda el valor de μ.
Resumiendo para una determinada varianza σ² de x, ¿qué tan grande debe ser mi muestra? Esto puede determinarse en dos pasos:
2. Tamaño provisional de la muestra = n´ = σx² / σ²
Donde: σx² = Varianza de la muestra
σ² = Varianza de la población

Este tamaño provisional de la muestra se corrige después con otros datos, ajustándose si se conoce el tamaño de la población, N.
2. Tamaño de la muestra = n = n´ / (1 + n´ / N)
Ejemplo: Para un estudio de directores generales consideramos a “todos aquellos directores generales de empresas industriales y comerciales que tienen un capital social superior a 30 millones de dólares, con ventas superiores a los 100 millones de dólares y/o con más de 300 personas empleadas”. Con estas características se preciso que la población era de N = 1176 dierctores generales ya que en 1176 empresas reunían las mencionadas características. ¿Cuál es entonces el número de directores generales ,n, que se tienen que entrevistar, para tener un error estándar de 0.015, y dado que la población total es de 1176?
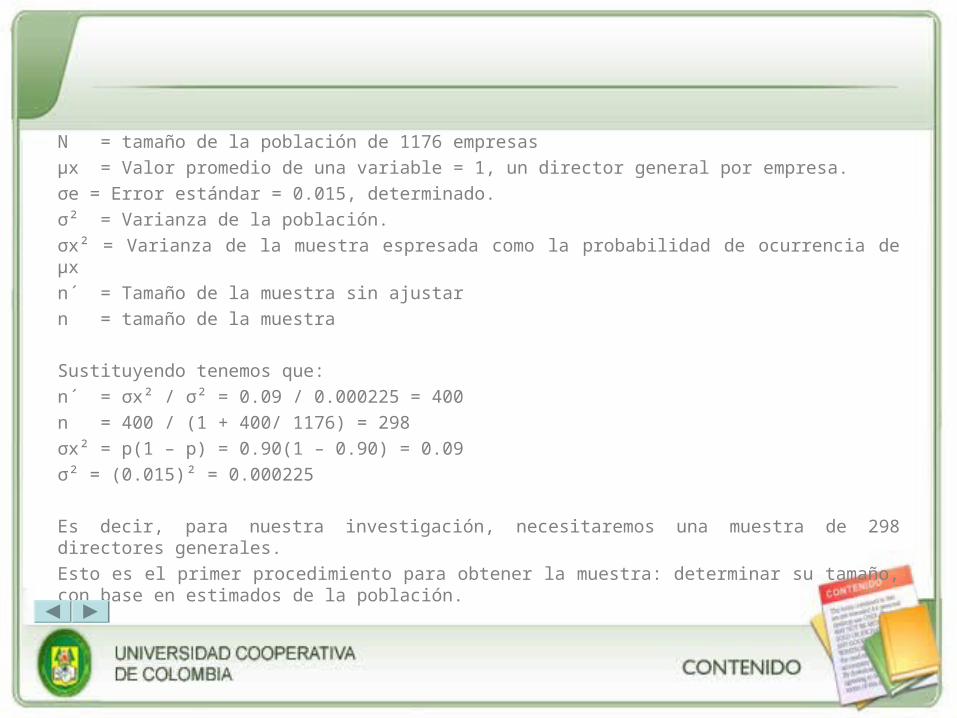
N = tamaño de la población de 1176 empresas
μx = Valor promedio de una variable = 1, un director general por empresa.
σe = Error estándar = 0.015, determinado.
σ² = Varianza de la población.
σx² = Varianza de la muestra espresada como la probabilidad de ocurrencia de μx
n´ = Tamaño de la muestra sin ajustar
n = tamaño de la muestra
Sustituyendo tenemos que:
n´ = σx² / σ² = 0.09 / 0.000225 = 400
n = 400 / (1 + 400/ 1176) = 298
σx² = p(1 – p) = 0.90(1 – 0.90) = 0.09
σ² = (0.015)² = 0.000225
Es decir, para nuestra investigación, necesitaremos una muestra de 298 directores generales.
Esto es el primer procedimiento para obtener la muestra: determinar su tamaño, con base en estimados de la población.

3. Técnicas de Muestreo
a. Muestreo Aleatorio Simple
Si una muestra aleatoria se elige de tal forma que todos los elementos de la población tengan la misma probabilidad de ser seleccionados, la llamamos muestra aleatoria simple.
Ejemplo: Suponga que nos interesa elegir una muestra aleatoria de 5 estudiantes en un grupo de estadística de 20 alumnos. C20,5 da el número total de formas de elegir una muestra no ordenada y este resultado es 15,504 maneras diferentes de tomar la muestra. Si listamos las 15,504 en pedazos de papel, una tarea engorrosa, luego los colocamos en un recipiente y después los revolvemos, entonces podremos tener una muestra aleatoria de 5 si seleccionamos un trozo de papel con cinco nombres. Un procedimiento más simple para elegir una muestra aleatoria sería escribir cado uno de los 20 nombres en pedazos separados de papel, colocarlos en un recipiente, revolverlos y después extraer cinco papeles al mismo tiempo.

Otro método para obtener una muestra aleatoria de 5 estudiantes en un grupo de 20 utiliza una tabla de números aleatorios. Se puede construir usando una calculadora o una computadora. También se puede prescindir de estas y hacer la tabla escribiendo diez dígitos de 0 a 9 en tiras de papel, las colocamos en un recipiente y lo revolvemos, de ahí, la primera tira seleccionada determina el primer número de la tabla, se regresa al recipiente y después de revolver otra vez se selecciona la segunda tira que determina el segundo número de la tabla; el proceso continua hasta obtener una tabla de dígitos aleatorios con tantos números como se desee.
Hay muchas situaciones en las cuales el muestreo aleatorio simple es poco práctico, imposible o no deseado; aunque sería deseable usar muestras aleatorias simples para las encuestas nacionales de opinión sobre productos o sobre elecciones presidenciales, seria muy costoso o demorado.
b. El Muestreo Estratificado
El muestreo estratificado requiere de separar a la población según que no se aíslen llamados estratos, y de elegir después una muestra aleatoria simple en cada estrato. La información de las muestras aleatorias simples de cada estrato constituiría una muestra global.
Ejemplo: Suponga que nos interesa obtener una muestra de las opiniones de los profesores de una gran universidad. Puede ser difícil una muestra con todos los profesores, así que supongamos que elegimos una muestra aleatoria de cada colegio, o departamento académico; los estratos vendrían a ser los colegios, o departamentos académicos.
c. EL Muestreo Por Conglomerados
El muestreo por conglomerado requiere elegir una muestra aleatoria simple de unidades heterogéneas entre sí de la población llamadas conglomerados.

Cada elemento de la población pertenece exactamente a un conglomerado, y los elementos dentro de cada conglomerado son usualmente heterogéneos o disímiles.
Ejemplo: Suponga que una compañía de servicio de televisión por cable está pensando en abrir una sucursal en una ciudad grande; la compañía planea realizar un estudio para determinar el porcentaje de familias que utilizarían sus servicios, como no es práctico preguntar en cada casa, la empresa decide seleccionar una parte de la ciudad al azar, la cual forma un conglomerado.
En el muestreo por conglomerados, éstos se forman para representar, tan fielmente como sea posible, a toda la población: entonces se usa una muestra aleatoria simple de conglomerados para estudiarla. Los estudios de instituciones sociales como iglesias, hospitales, escuelas y prisiones se realizan, generalmente, con base en el muestreo por conglomerados.

d. El Muestreo Sistemático
El muestreo sistemático es una técnica de muestreo que requiere de una selección aleatoria inicial de observaciones seguida de otra selección de observaciones obtenida usando algún sistema o regla.
Ejemplo: Para obtener una muestra de suscriptores telefónicos en una ciudad grande, puede obtenerse una muestra aleatoria de los números de las páginas del directorio telefónico; al elegir el vigésimo nombre de cada página obtendríamos un muestreo sistemático, también podemos escoger un nombre de la primera página del directorio y después seleccionar cada nombre del lugar número cien a partir del ya seleccionado. Por ejemplo, podríamos seleccionar un número al azar entre los primeros 100; supongamos que el elegido es el 40, entonces seleccionamos los nombres del directorio que corresponden a los números 40, 140, 240, 340 y así sucesivamente.

UNIDAD 6: REGRESION Y CORRELACION
• Introducción.
• Determinación del Modelo de Regresión Lineal Simple.
• Mínimos Cuadrados: La recta del mejor ajuste.
• Error estándar de la estimación.
• Medidas de variación en la regresión y la correlación.
• Estimaciones del intervalo de confianza para predecir μyx
• Inferencia acerca de los parámetros de la población en regresión y correlación

1. Introducción
La regresión y la correlación son las dos herramientas estadísticas mas poderosas y versátiles que se pueden utilizar para solucionar problemas comunes en los negocios. Muchos estudios se basan en la creencia de que se puede identificar y cuantificar alguna relación funcional entre dos o mas variables. Se dice que una variable depende de la otra. Se puede decir que Y depende de X en donde Y y X son dos variables cualquiera. Esto se puede escribir así: Y = f(X)
Debido a que Y depende de X, Y es la variable dependiente y X es la variable independiente. Es importante identificar cual es la variable dependiente y cual es la variable independiente en el modelo de regresión. Esto depende de la lógica y de lo que el estadístico intente medir. El decano de la Universidad de sea analizar la relación entre las notas de los estudiantes y el tiempo que pasan estudiando. Se recolectaron datos sobre ambas variables. Es lógico presumir que las notas dependen de la cantidad y calidad de tiempo que los estudiantes pasan con sus libros. Por tanto, “notas” es la variable dependiente y “tiempo” la variable independiente.

Variable dependiente, es la variable que se desea explicar o predecir; también se le denomina regresando o variable de respuesta. La variable independiente X se utiliza para explicar Y.
Variable independiente, también se le denomina variable explicativa o regresor.
Se debe diferenciar entre la regresión simple y la regresión múltiple. En la regresión simple, se establece que Y es una función de solo una variable independiente. Con frecuencia se le denomina regresión bivariada porque solo hay dos variables, una dependiente y una independiente, y la regresión simple se representa con la formula Y = f(X). En un modelo de regresión múltiple, Y es una función de dos o mas variables independientes. Un modelo de regresión con n variables independientes se puede expresar así:
Y = f(X1, X2, X3, …,Xn)
En donde X1, X2, X3, …,Xn, son variables independientes que permiten explicar Y.

2. Determinación del Modelo de Regresión Lineal Simple
Solo son necesarios dos puntos para dibujar la línea recta que representa esta relación lineal. La ecuación de una recta puede expresarse como :
Ecuación de la recta: Y = b1X + b0
En donde b0 es el intercepto y b1 es la pendiente de la recta. Por ejemplo se tiene que Y = 2X + 5 entonces la recta intercepta el eje vertical en 5.
Las relaciones entre variables son o deterministicas o estocásticas (aleatorias). Una relación deterministica puede expresarse mediante la formula que convierte la velocidad expresada en millas por hora (mph) a kilómetros por hora (kph). Ya que una milla es aproximadamente igual a 1.6 kilómetros, este modelo es 1 mph = 1.6 kph. Por tanto, una velocidad de 5 mph = 5 (1.6) kph = 8 kph. Este es un modelo deterministico porque la relación es exacta y no hay error (salvo la aproximación).
Infortunadamente, muy pocas relaciones en el mundo de los negocios son así de exactas.

Se dice que un modelo es estocástico, por la presencia de la variación aleatoria y puede expresarse como
Un modelo lineal Y = β1X + β0 + ε
La formula es la relación poblacional (o verdadera) según la cual se hace regresión de Y sobre X. Además β1X + β0 es la porción deterministica de la relación, mientras que ε representa el carácter aleatorio que muestra la variable dependiente y por tanto denota el termino del error en la expresión. Los parámetros β1 y β0, lo mismo que la mayoría de los parámetros, permanecerán desconocidos y se pueden estimar solo con los datos muestrales. Esto se expresa así :
Un modelo lineal con base
En datos muestrales Y = b1X + b0 + e
En donde los valores b1 y b0 son estimaciones de β1 y β0 , respectivamente, y e es el termino aleatorio. Habitualmente se le denomina residual cuando se utilizan datos muestrales, e reconoce que no todas las observaciones caen exactamente en una línea recta.

Si se supiera el valor exacto de e, se podría calcular de manera precisa Y. Sin embargo, debido a que es aleatoria, Y solo puede estimarse. El modelo de regresión por ende toma la forma de :
El modelo de regresión estimada Ŷ = b1X + b0
En donde Ŷ es el valor estimado de Y, y b1 y b0 , son el intercepto y la pendiente de la recta de regresión estimada. Es decir, Ŷ simplemente es el valor estimado con base en el modelo de regresión.
3. Mínimos cuadrados: La recta del mejor ajuste
El propósito del análisis de regresión es determinar una recta que se ajuste a los datos muestrales mejor que cualquier otra recta que pueda dibujarse. Para ilustrarlo, se asume que Orthoplan, recolecta datos sobre los gastos publicitarios y los ingresos por ventas de 5 meses en millones de pesos, como se muestra en la tabla.
Mes Ventas $ Publicidad $
X Y XY X² Y²
1 450 50 22.500 202.500 2.500
2 380 40 15.200 144.400 1.600
3 540 65 35.100 291.600 4.225
4 500 55 27.500 250.000 3.025
5 420 45 18.900 176.400 2.025
2.290 255 119.200 1.064.900 13.375
VENTAS ORTHOPLAN
Un procedimiento matemático utilizado para estimar b1 y b0 se denomina mínimos cuadrados ordinarios (MCO), que producirá una recta que se extiende por el centro del diagrama de dispersión aproximándose a todos los puntos de datos más que cualquier otra recta.
Utilizando el modelo de regresión estimada: Ŷ = b1X + b0, calculamos b1 y b0, así:
b1 = [n∑XiYi) – (∑Xi)(∑Yi)] / [n∑Xi² - (∑Xi)²]
b0 = Ym – b1Xm
De tal manera que:
b1 = [5(119.200) – (2.290)(255)] / [5(1.064.900) – (2.290)²]
b1 = 0.1499
b0 = 51 – (0.1499)(458) = -17.65
Por tanto, la ecuación para la mejor línea recta para estos datos es:
Ŷ = 0.1499X -17.65
La pendiente b1 se cálculo como + 0.1499. Este valor significa que, para cada aumento de una unidad en X, el valor de Y aumenta en 0.1499 unidades. En este problema de gastos publicitarios, por cada aumento de US$1000 en ventas, el costo de publicidad aumentará en US$149.9. Se puede considerar que esta pendiente representa la parte variable del gasto en publicidad, la cual varia según las ventas. La interpretación de b0 con el eje Y se calculó que era de (US$17.65). La intercepción con el eje Y representa el valor de Y cuando X es igual a 0.
La ecuación de regresión que se ha ajustado a los datos, se puede utilizar ahora para predecir el valor de Y para un valor dado de X. Por ejemplo, el contador querría predecir el costo promedio de gastos de publicidad con unas ventas de US$540. El costo Ŷ predicho se puede determinar al sustituir X = 540 en la ecuación Ŷ = 0.1499X -17.65 porque X representa las ventas en miles de dólares:
Ŷ = 0.1499(540) – 17.65 = 63.30
Dado que Y representa miles de dólares, el gasto promedio predicho es de US$63.30 para ventas en miles de dólares de US$540.

4. Error Estándar de la Estimación
Aunque el método de los mínimos cuadrados da por resultado una línea que ajusta en los datos con la mínima cantidad de variación, la ecuación de regresión no es perfecta para las predicciones, sobre todo cuando se toman las muestras de la población, excepto si todos los datos observados caen en la línea de regresión predicha. Así como no se puede esperar que todos los valores de los datos estén ubicados exactamente en su media aritmética, en la misma forma tampoco se puede esperar que todos los puntos de los datos caigan exactamente en la línea de regresión. Por tanto, la línea de regresión sirve sólo para predicción para predicción aproximada de un valor Y, para un valor dado X. Entonces se necesita desarrollar un estadístico que mida la variabilidad en los valores reales de Y, Yi, a partir de los valores predichos de Y, Ŷi, una medida de variabilidad en torno a la línea de regresión se llama el error estándar de la estimación. La variabilidad en torno a la recta de regresión se ilustra en la siguiente gráfica de los gastos publicitarios.
Se puede ver en la gráfica que, aunque la recta de regresión predicha cae cerca de muchos de los valores de Y, hay valores en cima de la recta de regresión así como debajo de ella, de modo que:
∑(Yi – Ŷi) = 0
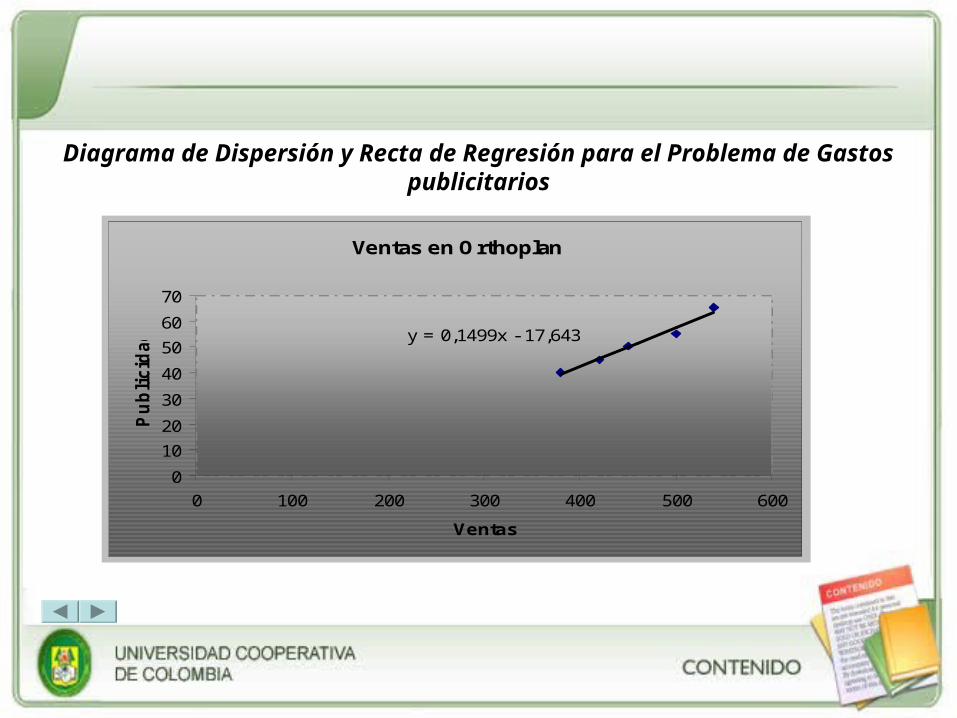
Diagrama de Dispersión y Recta de Regresión para el Problema de Gastos publicitarios
Ventas en Orthoplan
y = 0,1499x - 17,643
0
10
20
30
40
50
60
70
0 100 200 300 400 500 600
Ventas
Pu
bli
cid
ad

El error estándar de la estimación, dado por el símbolo Sxy se define:
Sxy = √ ∑(Yi – Ŷi)² / n -2
En donde: Yi = valor real de Y para un Xi dado
Ŷi = valor estimado de Y para un Xi dado
El cálculo del error estándar de la estimación con el uso de la ecuación anterior requeriría el cálculo del valor estimado de Y por cada valor de X en la muestra. Sin embargo el cálculo se simplificaría utilizando la siguiente fórmula:
• Sxy = √(∑Yi² - b0∑Yi – b1∑XiYi) / n – 2
•Para el problema de gastos publicitarios, se ha determinado que:
Sxy = 2.557 o Sxy = 2557
El error estándar de la estimación, igual a US$2557, representa una medida de la variación en torno a la recta ajustada de regresión. Se mide en unidad de la variable Y. La interpretación del error estándar de la estimación , entonces, es análogo al de la desviación estándar. Así como la desviación estándar mide la variabilidad en torno a la media aritmética, el error estándar de estimación mide la variabilidad en torno a la recta ajustada de regresión.

5. Medidas de Variación en La Regresión y La CorrelaciónA fin de poder determinar qué tan bien predice la variable independiente a la variable dependiente en el modelo estadístico, se necesita desarrollar varias medidas de variación. La primera medida, la variación total, es una medida de la variación de los valores de Y en torno a su media, Ym. La variación total se puede dividir en dos componentes. En un problema de regresión, la variación total en Y, se puede subdividir en variación explicada, o sea, la que es atribuible a la relación entre X y Y y la variación no explicada, atribuible a factores que no sean la relación entre X y Y.
La variación explicada representa la diferencia entre Ym y Ŷi. La variación no explicada representa la parte de la variación en Y que no se explica con la regresión y está basada en la diferencia entre Yi y Ŷi. Estas medidas de variación se pueden representar como sigue:
Variación Total = Variación Explicada + Variación no explicada

En donde:
• Variación Total =∑(Yi – Ym)² = ∑Yi² - (∑Yi)² / n
• Variación no Explicada = ∑(Yi – Ŷ)² = ∑Yi² - b0∑Yi – b1∑XiYi
• Variación Explicada = ∑(Ŷ – Ym)² = b0∑Yi + b1∑XiYi - (∑Yi)² /n
En nuestro ejemplo de gastos publicitarios, tenemos:
• Variación no explicada = 13375+(17.65)(255)–(0.1499)(119200)
= 7.67
• Variación total = 13375 – (255)²/5 = 370
• Variación explicada = Variación total – Variación no explicada
= 370 – 7.67
= 362.33
El coeficiente de determinación r², se puede definir como:
r² = Variación explicada / Variación total
Es decir, el coeficiente de determinación mide la proporción de variación que se explica con la variable independiente para el modelo de regresión. Para el problema de gastos publicitarios:
r² = 362.33 / 370 = 0.9793
Esto se puede interpretar que el 97.93% de la variación en los gastos de publicidad entre un mes y otr0, se puede explicar por la variabilidad en las ventas de cada mes. Este es un ejemplo en el cual hay una relación lineal muy fuerte entre las dos variables, por que el uso de un modelo de regresión ha reducido en un 97.93% la variabilidad en la predicción de los gatos publicitarios.

6. Correlación
El análisis de correlación, por contraste con el de regresión, se utiliza para medir la fuerza de la asociación entre las variables. Por ejemplo, en la encuesta del director se podría determinar la correlación entre las estaturas y los pesos de los estudiantes. En este caso, el objetivo no es utilizar una variable para predecir la otra, sino solo medir la fuerza de la asociación entre las dos variables.
La fuerza de una relación entre dos variables se suele medir con el coeficiente ρ de correlación cuyos valores van desde -1 para la correlación negativa perfecta hasta +1 para la correlación positiva perfecta.
Para problemas orientados a la correlación, el coeficiente de correlación (r) de la muestra, se puede obtener de un modo fácil con la siguiente ecuación:
r = √r²
En la regresión lineal simple, r toma el signo de b1 . Si b1 es positivo, r es positivo. Si b1 es negativo, r es negativo. Si b1 es 0, r es cero.

En el problema de gastos publicitarios, como r² = 0.9793 y la pendiente b1 es positiva, el coeficiente de correlación se calcula como + 0.9895. La cercanía del coeficiente de correlación con +1, implica una asociación muy fuerte entre las ventas y los gastos de publicidad .
Para muchas aplicaciones, en particular en las ciencias sociales, al investigador solo le interesa medir la asociación y la covariacion entre las variables y no usar una variable para predecir otra.
Si se efectúa el análisis de correlación en un grupo de datos, el coeficiente r de correlación de la muestra se puede calcular directamente con el uso de la siguiente formula:
∑ XiYi - (∑X) (∑iYi) / n
r = ________________________________
√ ∑ Xi² - (∑Xi )² / n √ ∑Yi² - (∑Yi )² / n
En el problema de gastos publicitarios tenemos:
r = 0.9880. Es una correlación casi perfecta ya que se acerca a +1.

7. Estimaciones del intervalo de confianza para predecir μyx
En el comentario del análisis de regresión y de correlación en las secciones anteriores de este capitulo, se ha destacado el uso de estos métodos solo con fines descriptivos. Se ha utilizado el método de los mínimos cuadrados para determinar los coeficientes de regresión y predecir el valor de Y a partir de un valor dado de X. Además, se ha comentado el error estándar de la estimación junto con los coeficientes de correlación y de determinación. De todos modos, como por lo general se muestra entre poblaciones grandes, a menudo interesa hacer inferencias en cuanto a la relación entre las variables de la totalidad de la población con base en los resultados de la muestra. En este capitulo se describirán, entonces, métodos para hacer inferencias predictivas entorno a la media de Y.
Ahora se puede desarrollar una estimación de intervalo de confianza para hacer inferencias en cuanto al valor predicho de Y.

Estimación de intervalo de confianza de la media de Yμyx para una X dada
Ŷi ± tn-2 Syx √ 1/n + (Xi - Xm)² / ∑Xi² - (∑Xi)² / n
En donde: Ŷi = Valor predicho de Y; Ŷi = b1X + b0
Syx = Error estándar de la estimación
n = Tamaño de la muestra
Xi = Valor dado de X
Un examen de la ecuación indica que el ancho del intervalo de confianza depende de varios factores. Para un nivel dado de confianza, el aumento en la variación alrededor de la recta de regresión, medida con el error estándar de la estimación, da por resultado un intervalo mas ancho. Pero, como seria de esperar, el tamaño aumentado de la muestra reduce el ancho del intervalo. Así mismo, el ancho del intervalo varia también con diferentes valores de X. Cuando se predice Y para los valores de X cercanos a Xm, el intervalo es mucho mas estrecho que para las predicciones de valores de X mas distantes de la media.
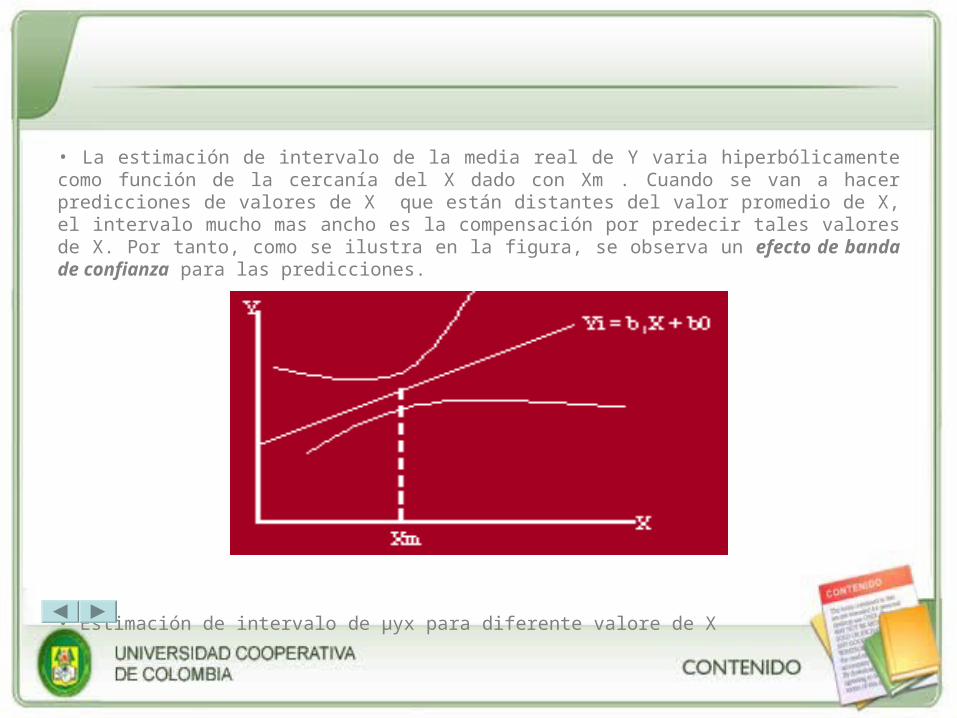
• La estimación de intervalo de la media real de Y varia hiperbólicamente como función de la cercanía del X dado con Xm . Cuando se van a hacer predicciones de valores de X que están distantes del valor promedio de X, el intervalo mucho mas ancho es la compensación por predecir tales valores de X. Por tanto, como se ilustra en la figura, se observa un efecto de banda de confianza para las predicciones.
• Estimación de intervalo de μyx para diferente valore de X

Una vez presentada la ecuación, se puede desarrollar estimaciones del intervalo de confianza para el problema que se ha venido comentando. En el problema de gastos publicitarios, si se desea una estimación del intervalo con 95% de confianza del costo promedio real para la publicidad con ventas de US$540, se calcula lo siguiente:
Ŷ = 0.1499X -17.65
Y para Xi = 540, Ŷi = 63.30. Además, Xm = 458, Syx = 2.557
∑Xi = 2.290, ∑Xi² = 1.064.900, t3 = 2.35
Por tanto,
63.30 ± 2.35(2.557) √1/5 + (540-458)² / 1064900 – (540)²/5
63.30 ± 2.7317
60.57 ≤ μyx ≤ 66.03
Por tanto, se estima que el gasto promedio real de publicidad es entre US$ 60.570 y US$ 66.030 para ventas de US$ 540. Se tiene 95% de confianza en que este intervalo estima correctamente el gasto real de gastos de publicidad

8. Inferencia acerca de los parámetros de la población en regresión y correlaciónEn la sección anterior se utilizo la inferencia estadística para desarrollar una estimación del intervalo de confianza para μyx, el valor de la media real de Y. En esta sección, se utilizara la inferencia estadística para sacar conclusiones en cuanto a la pendiente β1 de la población y el coeficiente ρ de correlación de la población.
Se puede determinar si existe o no una relación significativa entre las variables X y Y al probar si β1 (la pendiente real) es o no igual a cero. Si se rechaza esta hipótesis, se puede llegar a la conclusión de que hay pruebas de una relación lineal. Por tanto, las hipótesis nula y alternativa se podrian expresar como sigue:
H0 : β1 = 0 (No hay relación)
H1 : β1 ≠ 0 (Hay relación)
Y el estadístico de la prueba esta dado por:
tn-2 = b1 / Sb1
En donde: Sb1 = Syx / √ ∑Xi² - (∑Xi)² / n
Al volver al problema de gastos publicitarios, se probara si los resultados de la muestra permiten o no concluir que existe o no una relación significativa entre la publicidad y las ventas al nivel de significación de 0.01.
b1 = 0.1499, n=5, Syx = 2.557, ∑Xi = 2290, ∑Xi² = 1064900.
Por tanto, para probar la existencia de una relación con un nivel de significación de 0.01 se tiene :
Sb1 = 0.02016 y tn-2 = 7.433
Ahora, como 7.433 > 5.841, se rechaza H0
Entonces, la conclusión a que se llego es rechazar la hipótesis nula y decir que hay una relación significativa entre la publicidad y las ventas.
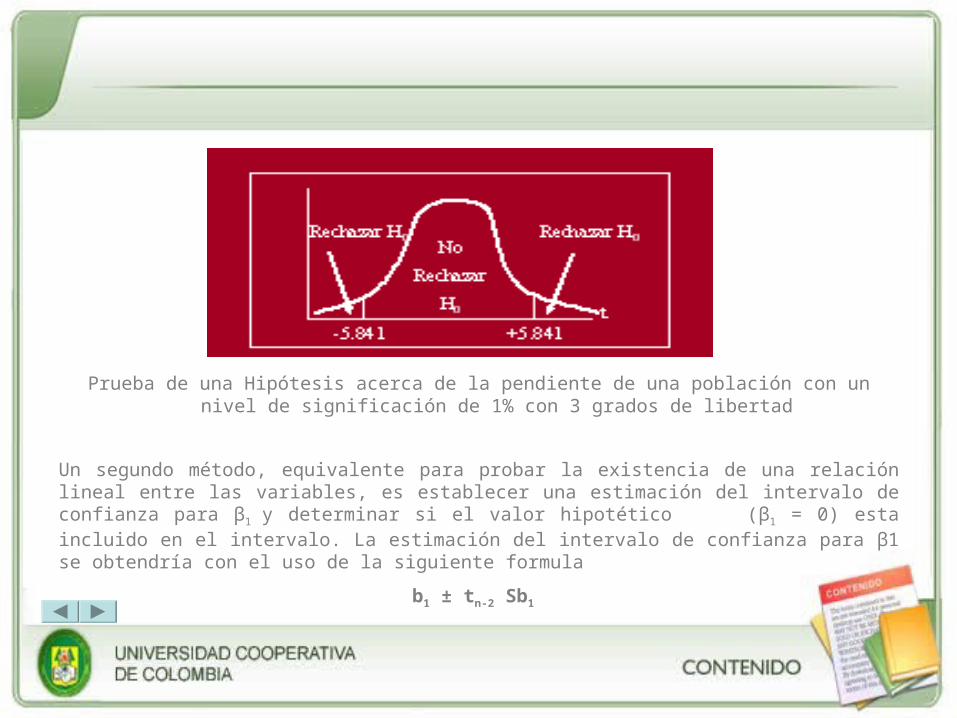
Prueba de una Hipótesis acerca de la pendiente de una población con un nivel de significación de 1% con 3 grados de libertad
Un segundo método, equivalente para probar la existencia de una relación lineal entre las variables, es establecer una estimación del intervalo de confianza para β1 y determinar si el valor hipotético (β1 = 0) esta incluido en el intervalo. La estimación del intervalo de confianza para β1 se obtendría con el uso de la siguiente formula
b1 ± tn-2 Sb1

Si se deseo una estimación del intervalo con 99% de confianza, se tendría
b1 = 0.1499, t3 = 5.841 y Sb1 = 0.02016.
Entonces,
0.1499 ± (5.841)(0.02016) = 0.1499 ± 0.1177
0.03214 ≤ β1 ≤ 0.2676
Con la ecuación se estima, con 99% de confianza, que la pendiente real es entre +0.03214 y +0.2676. Como estos valores son superiores a cero se puede llegar a la conclusión de que hay una relación positiva significativa entre la publicidad y las ventas. Por el contrario, si el intervalo hubiera incluido cero, no se habría determinado la relación

• Un tercer método para examinar la existencia de una relación lineal entre dos variables incluye el coeficiente r de correlación de la muestra. La existencia de una relación entre X y Y que se probo con el uso de la ecuación tn-2 = b1 / Sb1, se podría probar en términos del coeficiente de correlación con resultados equivalentes. La prueba de la existencia de una relación lineal entre dos variables, es la misma que determinar si hay o no alguna correlación significativa entre ellas. Se plantea la hipótesis de que el coeficiente ρ de correlación de población es igual a cero. Entonces, la hipótesis nula y alternativa serian
H0 : ρ = 0 (No hay correlación)
H1 : ρ ≠ 0 (Hay correlación)
El estadístico para la prueba para determinar la existencia de la correlación se da con la ecuación
tn-2 = r / √(1-r²) / n-2
La demostración se hará por parte del estudiante.





























