Embed Size (px)
Citation preview

Doctorado en Informática
Métodos y Técnicas de Minería de Datos
Metodología Experimental
Juan José Rodríguez Diez

Cuestiones
• Qué medimos.
? En principio, tasa de acierto/error.
• Qué experimentos hacemos.
? Como repartimos los datos en entrenamiento / test
• Cómo comparamos.
? Tests estadísticos.
Metodología Experimental JJRD 2/61

Evaluación
• Cómo de bueno es prediciendo el modelo que hemos aprendido.
• El error en el conjunto de entrenamiento no es un buen indicador del errorsobre datos nuevos.
? Almacenar los datos sería el clasificador óptimo.
• Rendimiento futuro sobre nuevos datos.
• Conjunto independiente de los datos de entrenamiento: datos de test.
• Normalmente solo se dispone de un conjunto de datos etiquetado.
• Si tenemos muchos datos etiquetados, dividir en entrenamiento y test.
• A menudo los datos etiquetados son limitados.
? Técnicas más sofisticadas.
Metodología Experimental JJRD 3/61

Aspectos de la Evaluación
• Fiabilidad de las diferencias estimadas en el rendimiento.
• Elección de la medidas del rendimiento.
? Número de clasificaciones correctas.
? Precisión de las estimaciones de probabilidad.
? Error en predicción numérica.
• Costes asignados a distintos tipos de error.
? En muchas aplicaciones prácticas.
Metodología Experimental JJRD 4/61

Entrenamiento y Test
• En clasificación la medida natural del rendimiento es la tasade error.
? Acierto: la clase se predice correctamente.
? Error: la clase se predice incorrectamente.
? Tasa de error: proporción del número de errores cometidossobre todo el conjunto de ejemplos.
• Error de resubstitución: tasa de error obtenida sobre el con-junto de entrenamiento.
? Inevitablemente optimista.
Metodología Experimental JJRD 5/61

Entrenamiento y Test (II)
• Conjunto de test: ejemplos independientes que no se han usado de nin-gún modo en la construcción del clasificador.
? Tampoco se pueden usar en preprocesamientos.
? Suposición: los datos de entrenamiento y test son muestras represen-tativas de un mismo problema subyacente.
• Los conjuntos de entrenamiento y test podrían ser de distinta naturaleza.
? Por ejemplo, clasificador construido sobre datos de clientes de dos ciu-dades diferentes.
∗ Estimar el rendimiento del clasificador obtenido en la primera ciudadsobre cualquier otra, utilizar la segunda ciudad para el conjunto detest.
Metodología Experimental JJRD 6/61

Ajuste de Parámetros
• Los datos de test no se pueden usar de ningún modo para crear el clasifi-cador.
• Algunos métodos trabajan en dos etapas:
? Construcción de la estructura básica.
? Optimizar los valores de los parámetros.
• Los datos de test no se pueden usar para el ajuste de párametros.
• Seleccionar entre varios métodos.
• Usar tres conjuntos independientes: entrenamiento, validación y test.
? Los de validación se usan para optimizar los parámetros o seleccionar.
Metodología Experimental JJRD 7/61

Aprovechando los Datos
• Una vez que la evaluación se ha completado, se pueden usartodos los datos disponibles para construir el clasificador final.
• Normalmente, cuanto más grande sea el conjunto de entre-namiento mejor será el clasificador (mejoras cada vez máspequeñas).
• Cuanto más grande sea el conjunto de test, más precisa serála estimación del error.
• Holdout: dividir los datos originales en entrenamiento y test.
? Dilema: idealmente, ambos conjuntos deberían ser gran-des.∗ Buen clasificador o buena estimación del error
Metodología Experimental JJRD 8/61

Predicción del Rendimiento
• Si la estimación de la tasa de error es del 25 %, cómo de cercaestamos a la tasa de error real.
? Depende del tamaño del conjunto de test.
• La predicción se puede considerar como lanzar una monedatrucada.
? Acierto o error en vez de cara o cruz.
• Sucesión de eventos independientes, proceso de Bernoulli.
? Intervalos de confianza para la verdadera proporción sub-yacente.
Metodología Experimental JJRD 9/61

Intervalos de Confianza
• Podemos decir, p está en un determinado intervalo con unadeterminada confianza especificada.
• Ejemplo: S = 750 aciertos en N = 1000 intentos.
? Tasa de acierto estimada: 75%.
? Con una confianza del 80%, p está en [73.2, 76.7]
• Otro ejemplo: S = 75 aciertos en N = 100 intentos.
? Tasa de acierto estimada: 75%.
? Con una confianza del 80%, p está en [69.1, 80.1]
Metodología Experimental JJRD 10/61

Media y varianza
• Media y varianza para un intento Bernouilli: p, p(1− p).
• Tasa de acierto esperada: f = S/N.
• Media y varianza para f: p, p(1− p)/N.
• Para valores de N suficientemente grandes, f sigue una distribución Nor-mal.
• Intervalo de confianza [−z ≤ X ≤ z] del c% para una variable con media 0
Pr[−z ≤ X ≤ z] = c
• Para una distribución simétrica:
Pr[−z ≤ X ≤ z] = 1− 2× Pr[X ≥ z]
Metodología Experimental JJRD 11/61

Límites de Confianza
[WF05]
Pr[X ≥ z] z
0.1 % 3.09
0.5 % 2.58
1 % 2.33
5 % 1.65
10 % 1.28
20 % 0.84
40 % 0.25
• Entonces: Pr[−1.65 ≤ X ≤ 1.65] = 90%.
• Para poder usar esto se necesita transformar la variable f para que tengamedia cero y varianza uno.
Metodología Experimental JJRD 12/61

Transformación de f
• Valor transformado para f:
f− p√p(1− p)/N
? Restamos la media, dividimos por la desviación estándar.
• Ecuación resultante:
Pr
[−z ≤ f− p√
p(1− p)/N≤ z
]= c
• Resolviendo para p:
p =
(f+
z2
2N± z√f
N−f2
N+z2
4N2
)/
(1+
z2
N
)Metodología Experimental JJRD 13/61

Ejemplos
• f = 75%, N = 1000, c = 80% (de modo que z = 1.28).
p ∈ [0.732, 0.767]
• f = 75%, N = 100, c = 80% (de modo que z = 1.28).
p ∈ [0.691, 0.801]
• La suposición de que la distribución es normal solo es válidapara N grande (i.e., N > 100).
Metodología Experimental JJRD 14/61

Estimación por “holdout”
• Si la cantidad de datos es limitada.
• Holdout: reserva una cantidad para test, el resto para entrena-miento.
? E.g., un tercio para test.
• Problema: las muestras podrían no ser representativas.
? E.g., una clase podría no estar presente.
• Estratificación: asegura que cada clase está representadacon aproximadamente las mismas proporciones en los dossubconjuntos.
Metodología Experimental JJRD 15/61

Holdout repetido
• Más fiable si repetimos el proceso varias veces con diferentesmuestras.
? En cada iteración se selecciona aleatoriamente una propor-ción para entrenamiento (posiblemente con estratificación).
? Las tasas de error de las diferentes iteraciones se prome-dian para obtener la tasa de error global.
• No es óptimo, los diferentes conjuntos de test se solapan.
? Cómo prevenir el solapamiento.
Metodología Experimental JJRD 16/61

Validación Cruzada
• Evita el solapamiento de los conjuntos de test.
? Primer paso: repartir los datos en k subconjuntos del mismotamaño.
? Segundo paso: usar cada subconjunto como test, el restopara entrenamiento.
• k-fold cross-validation.
• A menudo los subconjuntos se estratifican antes de realizar lavalidación cruzada.
• Se promedian las tasas de error.
Metodología Experimental JJRD 17/61

Validación Cruzada (II)
• Estándar: 10 fold stratified cross validation.
? Apoyado por experimentación exhaustiva.
• La estratificación reduce la varianza del estimador.
• Ni la estratificación ni la división tienen que ser exactas.
• Validación cruzada repetida.
? Para paliar la influencia de la partición aleatoria.
? E.g.: 10× 10, 5× 2. . .
Metodología Experimental JJRD 18/61

Dejar Uno Fuera
• Leave one out (LOO).
• Validación cruzada con tantos grupos como ejemplos.
• Ventajas:
? Cantidad máxima de datos para entrenamiento.
? Determinista.
• Inconveniente: muy costoso computacionalmente.
? Excepciones, e.g., vecino más cercano.
Metodología Experimental JJRD 19/61

Dejar Uno Fuera (II)
• No es posible estratificar.
? El conjunto de test solo tiene un ejemplo.
• Ejemplo artificial: conjunto completamente aleatorio con elmismo número de ejemplos de las dos clases.
? Mejor clasificador: predecir la mayoría.
? Sobre un conjunto nuevo de datos, acierto del 50 %.
? De acuerdo a LOO, 100 % de error.
Metodología Experimental JJRD 20/61

Bootstrap
• Muestreo con reemplazamiento.
? Un mismo ejemplo puede ser seleccionado varias veces.
• Métodos de aprendizaje que son sensibles a cuantas vecesaparece un valor.
• Obtener n elementos con reemplazamiento de un conjunto den elementos.
? Conjunto de entrenamiento.
∗ En el fondo no es un conjunto. . .
• Los ejemplos no seleccionados irán al conjunto de test.
Metodología Experimental JJRD 21/61

0.632 bootstrap
• Un ejemplo concreto tiene una probabilidad 1− 1/n de no serseleccionado.
• La probabilidad de acabar en el conjunto de test es(1−
1
n
)n≈ e−1 ≈ 0.368
• El conjunto de entrenamiento contendrá aproximadamente el63.2 % de los ejemplos.
Metodología Experimental JJRD 22/61

Estimación del error con bootstrap
• Evaluar sobre los datos de test: excesivamente pesimista.
? Entrenado con solo el 63 % de los ejemplos.
• Para compensar: 0.632× etest + 0.368× etrain
• Repetir varias veces con diferentes muestras, promediar losresultados.
• Para conjuntos de datos muy pequeños.
• Mismo conjunto artificial. Si se memoriza: 0% de error en en-trenamiento. Error: 0.632× 0.5
Metodología Experimental JJRD 23/61

Comparaciones
• 2 métodos.
? 1 conjunto.
∗ 1 ejecución. McNemar.∗ Varias ejecuciones. Test t pareado (remuestreado co-
rregido).
? Varios conjuntos. Test de signo sobre el número de victo-rias.
• Más de 2 métodos, varios conjuntos. Friedman.
? Todos contra todos. Nemenyi.
? Uno contra todos. Bonferroni-Dunn.Metodología Experimental JJRD 24/61

Test de McNemar• Dos métodos, un conjunto, una ejecución.
• Entrenamiento R y Test T
• Entrenar algoritmos A y B sobre R
• Notación: nij es el numero de ejemplos clasificados de modo i (0 mal, 1 bien) porA y de modo j por B
n00 n01
n10 n11
• Hipótesis nula, los dos algoritmos tienen la misma tasa de error: n10 = n01
• El estadístico (|n01−n10|−1)2
n01+n10se distribuye aproximadamente como una χ2 con 1
grado de libertad
• Si la hipótesis nula es correcta, la probabilidad que esta cantidad sea mayor queχ21,0.95 = 3.841459 es menor que 0.05
[Die98]Metodología Experimental JJRD 25/61

McNemar (Exacto)
• Distribución binomial, probabilidad de s exitos en n intentos:
n!
s!(n− s)!psqn−s
• Si no se esperan diferencias entre algoritmos, p = q = 0.5
• n = n01 + n10, m = max(n01, n10)
• La probabilidad de estos resultados es
n∑s=m
n!
s!(n− s)!0.5n
Metodología Experimental JJRD 26/61

2 Mét., 1 Conj, Varias Ejecuciones
• Evaluar los dos con validación cruzada, comparar.
? Para ciertas aplicaciones, puede ser suficiente.
? La diferencia puede deberse a que tenemos estimaciones del error.
? Repetir la validación cruzada.
• Demostrar convincentemente que un método en particular funciona mejor.
• Se quiere demostrar que un método A es mejor que B en un dominio par-ticular.
? Para un tamaño determinado del conjunto de entrenamiento.
? En promedio, sobre todos los posibles conjuntos de entrenamiento.
Metodología Experimental JJRD 27/61

2 Mét., 1 Conj, Varias Ejecuciones (II)
• Supongamos que hay una cantidad infinita de datos en el do-minio.
? Obtener muchas muestras (conjuntos de datos) del tamañoespecificado.
? Obtener una estimación por validación cruzada para cadaconjunto y método.
? Comprobar si la precisión media del métodoA es mejor quela del método B.
∗ Significativamente.
Metodología Experimental JJRD 28/61

Test t de Student
• En la práctica, los datos son limitados y tenemos un númerolimitado de estimaciones para calcular la media.
• Este test no indica si las medias de dos muestras son signifi-cativamente diferentes.
• Nuestras muestras son las estimaciones obtenidas por valida-ción cruzada para diferentes conjuntos de datos del dominio.
• Test pareado, porque las muestras individuales están parea-das.
? Usar las mismas validaciones cruzadas para los dos méto-dos.
Metodología Experimental JJRD 29/61

Distribución de las Medias
• Notación: x1, . . . xk, y1, . . . yk.
• Si hay suficientes ejemplos, la media de un conjunto de ejemplos tienedistribución normal
? Con independencia de la distribución de los propios ejemplos.
• Sean µx y µx los valor verdaderos de las media.
• No conocemos la varianza de las medias.
? Estimaciones: σ2x/k, σ2y/k.
• Entonces x−µx√σ2
x/ky y−µy√
σ2y/k
tienen aproximadamente una distribución normal,
con media 0 y varianza 1.
Metodología Experimental JJRD 30/61

Distribución de Student
• Para muestras pequeñas (k < 100), la media sigue una distri-bución de Student con k− 1 grados de libertad.
? Si más de 100, muy similar a la Normal.
• Ejemplo, para k = 10.
? 10 validaciones cruzadas. 9 grados de libertad.
Pr[X ≥ z] 0.1 % 0.5 % 1 % 5 % 10 % 20 %
z 4.30 3.25 2.82 1.83 1.38 0.88
Metodología Experimental JJRD 31/61

Distribución de las Diferencias
• di = xi − yi, observaciones pareadas
• La media de las diferencias es la diferencia de las medias.d = x− y
? También tiene una distribución de Student con k− 1 gradosde libertad.
• Hipótesis nula: las medias son iguales, la diferencia es nula
• Variable t-estadístico (media 0, varianza 1):
t =d√σ2d/k
Metodología Experimental JJRD 32/61

Test de Student: Método
• Seleccionar un nivel de confianza (típicamente, 1 ó 5 %).
? Si la diferencia es significativa con un nivel α%, hay unaprobabilidad de (100 − α) % de que las medias verdaderasdifieran.
• Dividir el nivel por dos porque el test tiene dos colas.
• Determinar, a partir de la tabla, el valor de z que se correspon-de con α/2.
• Si el valor de t es mayor que z o menor que −z, rechazar lahipótesis nula (hay una diferencia significativa).
Metodología Experimental JJRD 33/61

Observaciones no Pareadas
• Si las observaciones no están pareadas.
• Incluso se puede tener un número diferente de repeticiones (ky j).
• Test regular (no pareado) de Student.
? Grados de libertad: mın(k, j) − 1.
• Estimación de la varianza de la diferencia de las medias:
σ2xk
+σ2y
j
Metodología Experimental JJRD 34/61

Estimaciones Dependientes
• Suponíamos que teníamos datos suficientes como para crear varios con-juntos de datos del mismo tamaño.
• Si no es el caso, necesidad de reutilizar los datos.
? E.g., validaciones cruzadas sobre los mismos datos con distintas parti-ciones aleatorias.
• Las muestras son dependientes.
? Diferencias insignificantes pueden convertirse en significantes.
• Heurística: test t remuestreado corregido [NB03].
? Suponemos holdout repetido, n1 ejemplos de entrenamiento, n2 de test.
? Nuevo estadístico:
t =d√(
1k
+ n2
n1
)σ2d
Metodología Experimental JJRD 35/61

Comparación sobre varios Dominios• [Dem06]
• Distintos conjuntos de datos (de distintos dominios).
• Caso particular: dos métodos.
• Test t pareado para cada conjunto.
? Resultados de significancia individuales.
• Un único t-test pareado con los resultados de cada conjunto.
? Los resultados en distintos conjuntos de datos no son com-parables.
? Se necesita una muestra suficientemente grande (≈ 30) odistribución normal.
Metodología Experimental JJRD 36/61

Número de Victorias: Test de Signo
• Contar el número de conjuntos para el que cada método gana.
• Si los dos métodos son equivalentes, cada uno debería ganar en la mitadde los conjuntos.
• Distribución binomial.
conjuntos 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
α =0.05 5 6 7 7 8 9 9 10 10 11 12 12 13 13 14 15 15 16 17 18 18
α =0.10 5 6 6 7 7 8 9 9 10 10 11 12 12 13 13 14 14 15 16 16 17
• Un clasificador es significativamente mejor que otro si tiene mejores resul-tados para al menos el número de conjuntos en la tabla.
? Los empates se reparten.
• Para más conjuntos de datos: N/2+ 1.96√N/2 (significancia: 5 %).
? Aproximadamente, N/2+√N
Metodología Experimental JJRD 37/61

Varios Clasificadores
• Ranking para cada conjunto de datos.
• Se ordenan los métodos de mejor a peor.
• A cada método se le asigna un número con su posición. El mejor el 1, elsegundo el 2. . .
• Si hay empates, valores promedios.
? E.g, si 4 métodos tienen el mejor resultado, se les asigna el valor 2.5.
• Para cada método, promediar sus posiciones.
• Ordenar de acuerdo a este ranking promedio.
• A partir de estos rankings se pueden realizar diversos tests estadísticos.
Metodología Experimental JJRD 38/61
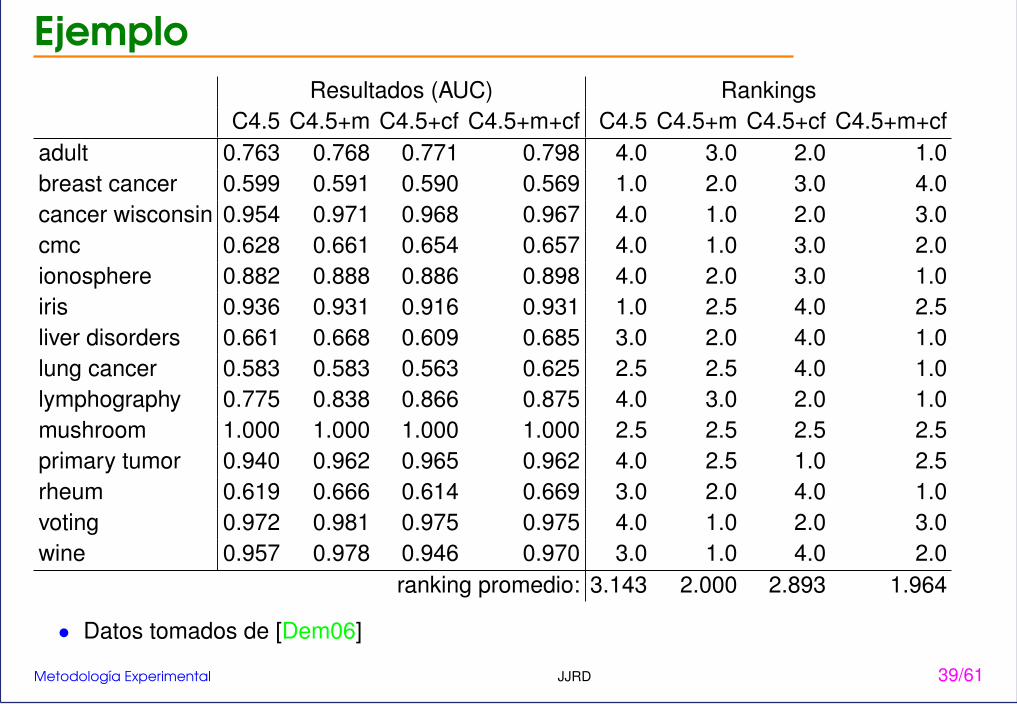
EjemploResultados (AUC) Rankings
C4.5 C4.5+m C4.5+cf C4.5+m+cf C4.5 C4.5+m C4.5+cf C4.5+m+cfadult 0.763 0.768 0.771 0.798 4.0 3.0 2.0 1.0breast cancer 0.599 0.591 0.590 0.569 1.0 2.0 3.0 4.0cancer wisconsin 0.954 0.971 0.968 0.967 4.0 1.0 2.0 3.0cmc 0.628 0.661 0.654 0.657 4.0 1.0 3.0 2.0ionosphere 0.882 0.888 0.886 0.898 4.0 2.0 3.0 1.0iris 0.936 0.931 0.916 0.931 1.0 2.5 4.0 2.5liver disorders 0.661 0.668 0.609 0.685 3.0 2.0 4.0 1.0lung cancer 0.583 0.583 0.563 0.625 2.5 2.5 4.0 1.0lymphography 0.775 0.838 0.866 0.875 4.0 3.0 2.0 1.0mushroom 1.000 1.000 1.000 1.000 2.5 2.5 2.5 2.5primary tumor 0.940 0.962 0.965 0.962 4.0 2.5 1.0 2.5rheum 0.619 0.666 0.614 0.669 3.0 2.0 4.0 1.0voting 0.972 0.981 0.975 0.975 4.0 1.0 2.0 3.0wine 0.957 0.978 0.946 0.970 3.0 1.0 4.0 2.0
ranking promedio: 3.143 2.000 2.893 1.964
• Datos tomados de [Dem06]
Metodología Experimental JJRD 39/61

Tests sobre los Rankings
• Test de Friedman. Hipótesis nula: los métodos son equivalentes, los ran-kings promedios deberían ser equivalentes.
• Estadístico de Friedman (N conjuntos de datos, kmétodos, Rj ranking pro-medio del método j)
χ2F =12N
k(k+ 1)
[∑j
R2j −k(k+ 1)2
4
]
• Distribución χ2 con k− 1 grados de libertad.
• Según Iman y Davenport, este test es demasiado conservador, estadísticoalternativo:
FF =(N− 1)χ2F
N(k− 1) − χ2F
• Distribución F con k− 1 y (k− 1)(N− 1) grados de libertad.
Metodología Experimental JJRD 40/61

Tests sobre los Rankings (II)
• Si se rechaza la hipótesis nula, se puede proceder con un test “post-hoc”.
• Test de Nemenyi.
? Dos métodos son significativamente diferentes si sus rankings prome-
dios difieren al menos en CD = qα
√k(k+1)6N
Clasificadores 2 3 4 5 6 7 8 9 10
q0.05 1.960 2.343 2.569 2.728 2.850 2.949 3.031 3.102 3.164
q0.10 1.645 2.052 2.291 2.459 2.589 2.693 2.780 2.855 2.920
• Test de Bonferroni-Dunn, cuándo se compara solo con un clasificador decontrol.Clasificadores 2 3 4 5 6 7 8 9 10
q0.05 1.960 2.241 2.394 2.498 2.576 2.638 2.690 2.724 2.773
q0.10 1.645 1.960 2.128 2.241 2.326 2.394 2.450 2.498 2.539
Metodología Experimental JJRD 41/61

Ejemplo
• Para los resultados anteriores, X2F = 9.28
• FF = 3.69.
• Distribucion F con k − 1 = 3 y (k − 1)(N − 1) = 39 grados delibertad.
? Valor crítico para α = 0.05, es 2.85. Rechazamos la hipóte-sis nula.
? http://www.itl.nist.gov/div898/handbook/eda/
section3/eda3673.htm
? En la hoja de cálculo: =DISTR.F.INV(0,05;3;39) ó=DISTR.F(3,69;3;39)
Metodología Experimental JJRD 42/61
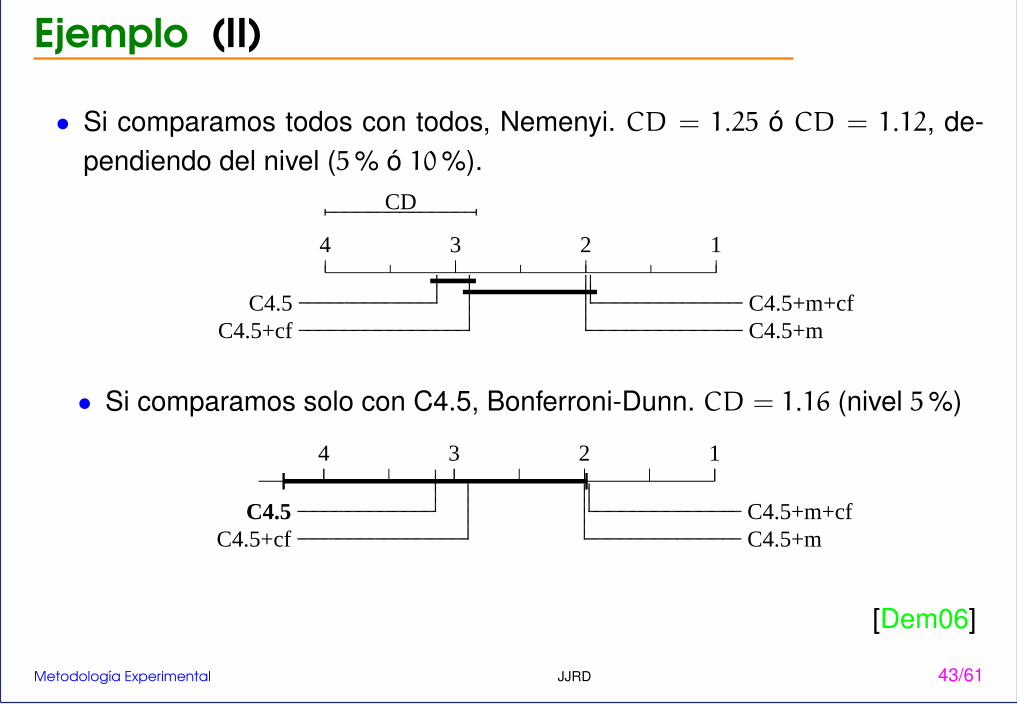
Ejemplo (II)
• Si comparamos todos con todos, Nemenyi. CD = 1.25 ó CD = 1.12, de-pendiendo del nivel (5% ó 10%).
4 3 2 1......................................................................................................................................................................................C4.5
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
...........................................................................................................................................................................................C4.5+cf
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
............................................................................................................................................................................ C4.5+m
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
....................................................................................................................................................................... C4.5+m+cf
......................................................................................................................................................................
.
.
.
.
.
.
.
.
.
.
.
.
.
.CD
• Si comparamos solo con C4.5, Bonferroni-Dunn. CD = 1.16 (nivel 5%)
4 3 2 1......................................................................................................................................................................................C4.5
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
...........................................................................................................................................................................................C4.5+cf
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
............................................................................................................................................................................ C4.5+m
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
....................................................................................................................................................................... C4.5+m+cf
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
[Dem06]
Metodología Experimental JJRD 43/61

Regresión• Mismas estrategias: conjunto de test independientes, validación cruzadas,
test de significancia. . .
• Diferencia: medidas del error.
• Valores reales: a1, a2, . . . an.
• Valores predichos: p1, p2, . . . pn.
• Más popular: error cuadrático medio.
(p1 − a1)2 + . . .+ (pn − an)
2
n
? Fácil de manipular matemáticamente.
• Error absoluto medio.
|p1 − a1| + . . .+ |pn − an|
n
Metodología Experimental JJRD 44/61

Mejora de la Media
• Cuánto mejora el método a predecir el valor medio.
• Error cuadrático relativo.
(p1 − a1)2 + . . .+ (pn − an)
2
(a− a1)2 + . . .+ (a− an)2
? a es el valor medio en el conjunto de entrenamiento.
• Error absoluto relativo.
|p1 − a1| + . . .+ |pn − an|
|a− a1| + . . .+ |a− an|
• A menudo la selección del método no depende de la medida.
Metodología Experimental JJRD 45/61

Predicción de Probabilidades• Hasta ahora la medida del rendimiento era la tasa de acierto.
• También denominada función de pérdida 0-1.
? La pérdida es 0 si se acierta, 1 si se falla.
• Muchos clasificadores son capaces de asignar una probabili-dad a cada predicción.
• Para ciertas aplicaciones, podríamos comprobar la precisiónde las estimaciones de probabilidad.
? Podría ser mejor acertar con 0.99 que con 0.51.
• A veces la predicción puede ser entrada para otros procesos.
? E.g., análisis humano.Metodología Experimental JJRD 46/61

Función de pérdida cuadrática
• p1 . . . pk son las estimaciones de probabilidad para un ejemplo.
• c es el índice de la clase verdadera.
• a1 . . . ak = 0, savo ac = 1.
• Pérdida cuadrática:∑j
(pj − aj)2 =
∑j 6=c
p2j + (pc − 1)2 = 1− 2pc +∑j
p2j
• Sumar la pérdida de cada ejemplo.
Metodología Experimental JJRD 47/61

Función de Pérdida de Información
• − log2 pc
• Representa el número de bits necesarios para comunicar laclase verdadera.
• Sean p∗1 . . . p∗k las probabilidades reales de las clases.
• El valor esperado para la función de pérdida es
−p∗1 log2 p1 − . . .− p∗k log2 pk
• Problema: si se asigna una probabilidad 0 a un evento queocurre, pérdida infinita.
Metodología Experimental JJRD 48/61

Discusión
• Qué función elegir.
• Ambas promueven la honestidad.
• La función de pérdida cuadrática tiene en cuenta las estima-ciones de probabilidad de todas las clases para el ejemplo.
• La función de pérdida de información solo se fija en la proba-bilidad asignada a la clase verdadera.
• La pérdida cuadrática está acotada, 1+∑
j p2j , como mucho 2.
• La pérdida de información puede ser infinita.
Metodología Experimental JJRD 49/61

Sobre la Precisión
• No siempre es adecuado utilizar la precisión (el error) paracomparar métodos.
• Suposiciones:
? Los costes de los errores son los mismos.
? Distribución de clases conocida a priori.
• Ejemplos: fraudes, créditos, inseminación de ganado, diagno-sis. . .
• Para dos clases: (ciertos, falsos) (positivos, negativos).
Metodología Experimental JJRD 50/61

Sobre la Precisión (II)
• Matriz de confusión.
clase real
positivo negativo
clase sí cierto positivo falso positivo
predicha no falso negativo cierto negativo
• Precisión: TP+TNP+N
• Tasa de ciertos positivos: tp = TPP
• Tasa de falsos positivos: fp = FPN
Metodología Experimental JJRD 51/61

Análisis ROC
• Análisis ROC (Receiver Operation Characteristic), origina-do en teoría de la señal y común en diagnosis médica.
• Representación gráfica del rendimiento de clasificadores.
? Especialmente útiles en problemas desesequilibrados osensibles al coste.
• Espacio ROC: pares (fp, tp).
• Relación entre los beneficios (ciertos positivos) y los costes(falsos positivos).
Metodología Experimental JJRD 52/61

Análisis ROC (II)
• Cada clasificador un punto en ese espacio.
• (0, 0) aquellos clasificadors que siempre predicen negativo.
• (1, 1) si siempre predice positivo.
• (0, 1) clasificador perfecto.
• Un clasificador es mejor que otro si está encima y a la izquier-da.
• Predicción aleatoria: en la diagonal.
Metodología Experimental JJRD 53/61

Análisis ROC (III)
Metodología Experimental JJRD 54/61
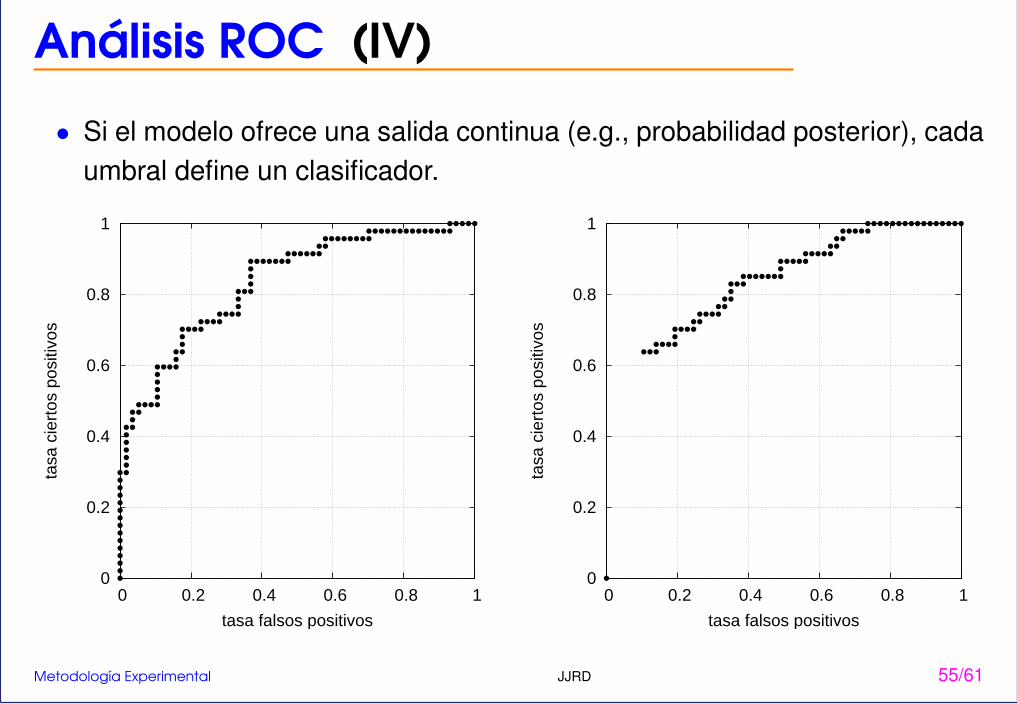
Análisis ROC (IV)
• Si el modelo ofrece una salida continua (e.g., probabilidad posterior), cadaumbral define un clasificador.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
tasa
cie
rtos
pos
itivo
s
tasa falsos positivos
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
tasa
cie
rtos
pos
itivo
s
tasa falsos positivos
Metodología Experimental JJRD 55/61
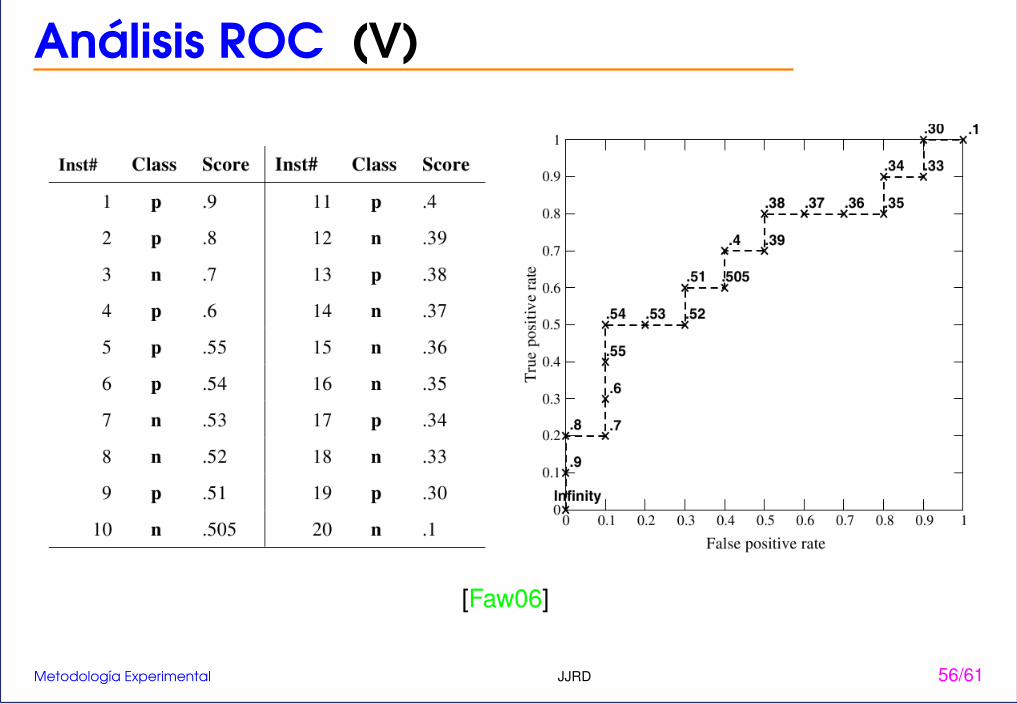
Análisis ROC (V)
[Faw06]
Metodología Experimental JJRD 56/61

Curvas ROC
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Metodología Experimental JJRD 57/61

Curvas ROC (II)
• Curvas ROC: habilidad de los clasificadores para generar buenos valoresnuméricos relativos, aunque no sean buenas probabilidades.
? Que permitan discriminar bien.
• Robustas a cambios en la distribución de clases en el conjunto de test.
• Representación bidimensional del rendimiento.
• Para comparar es mejor tener un único valor numérico.
• Área bajo la curva, AUC.
• Porción del área de un cuadrado unitario, valor entre 0 y 1.
? Debería ser mayor que 0.5.
∗ Un clasificador aleatorio genera la diagonal entre (0,0) y (1,1).
Metodología Experimental JJRD 58/61

Curvas ROC (III)
• El área bajo la curva es equivalente a la probabilidad de queel clasificador asigne un valor superior a una instancia positivaque a una negativa, cuando ambas se seleccionan aleatoria-mente.
? Test de rangos de Wilcoxon.
• Relacionada con el coeficiente de Gini (criterio para construirárboles de decisión), ya que este valor se corresponde con2×AUC−1.
Metodología Experimental JJRD 59/61

Referencias[Dem06] J. Demšar. Statistical comparisons of classifiers over multiple data sets. Journal of
Machine Learning Research, 7:1–30, 2006.
[Die98] Thomas G. Dietterich. Approximate statistical test for comparing supervised clas-sification learning algorithms. Neural Computation, 10(7):1895–1923, 1998.
[Faw06] Tom Fawcett. An introduction to roc analysis. Pattern Recognition Letters,27(8):861–874, June 2006.
[FHOM08] C. Ferri, J. Hernandez-Orallo, and R. Modroiu. An experimental comparison ofperformance measures for classification. Pattern Recognition Letters, September2008.
[GH08] Salvador García and Francisco Herrera. An extension on “statistical comparisons ofclassifiers over multiple data sets” for all pairwise comparisons. Journal of MachineLearning Research, 9:2677–2694, December 2008.
[Mit97] T. Mitchell. Machine Learning. McGraw Hill, 1997.
[NB03] Claude Nadeau and Yoshua Bengio. Inference for the generalization error. MachineLearning, 52(239–281), 2003.
[Sal97] Steven L. Salzberg. On comparing classifiers: Pitfalls toavoid and a recommended

approach. Data Min. Knowl. Discov., 1(3):317–328, 1997.
[WF05] I. H. Witten and E. Frank. Data Mining: Practical Machine Learning Tools andTechniques. Morgan Kaufmann, 2nd edition, 2005.





























