Embed Size (px)
Citation preview

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 1/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
10
PRÓLOGO
La presente obra se diseño principalmente como un texto de referencia para los
estudiantes de Ingeniería de Sistemas e Informática de la Universidad Privada de
Oruro, que necesitan de una guía práctica, proporcionándole información rápida y
objetiva sobre la metodología a seguir en la codificación de programas en C++ y la
Estructura de Datos.
El lenguaje seleccionado en el presente texto es C++ con el editor llamado
“Code::Blocks 10.05”, un lenguaje básico y nada complejo en su comprensión y
utilización.
La Obra presente diversos problemas los mismos que han sido seleccionados no
tanto por su utilidad práctica en el campo de la solución de problemas, sino por la forma y
complejidad que estos despliegan en el proceso de codificación.
El texto cuenta con problemas que van desde lo más básico hasta los más
complejos para que el programador pueda asimilar tanto el diseño de los problemas
codificados en forma gradual y sistemática
El texto también cuenta con un CD interactivo en el cual se encuentran los
problemas codificados y el instalador del Editor “Code::Blocks 10.05”. Para que el
estudiante pueda verificar y comprar que los problemas son exactamente iguales a los
que aparecen en el texto.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 2/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
11
rcia
ESTRUCTUR
11
DE DATOS
11

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 3/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
12
1. DECLARACION DE UNA VARIABLE
Una característica de C++, es la necesidad de declarar las variables que se usarán en un programa.
Esto resulta chocante para los que se aproximan al C++ desde otros lenguajes de programación
en los que las variables de crean automáticamente la primera vez que se usan.
Se trata, es cierto, de una característica de bajo nivel, más cercana al ensamblador que a
lenguajes de alto nivel, pero en realidad una característica muy importante y útil de C++, ya que
ayuda a conseguir códigos más compactos y eficaces, y contribuye a facilitar la depuración y la
detección y corrección de errores y a mantener un estilo de programación elegante.
Uno de los errores más comunes en lenguajes en los que las variables se crean de forma
automática se produce al cometer errores ortográficos. Por ejemplo, en un programa usamos una
variable llamada “ prueba”, y en un punto determinado le asignamos un nuevo valor, pero nos
equivocamos y escribimos “ prubea”. El compilador o intérprete no detecta el error, simplemente
crea una nueva variable, y continúa como si todo estuviese bien.
En C++ esto no puede pasar, ya que antes de usar cualquier variable es necesario declararla, y si
por error usamos una variable que no ha sido declarada, se producirá un error de compilación.
1.1 ¿QUE ES UNA VARIABLE?
Es un nombre que representa el valor de un dato. Es una zona o posición de memoria en la
computadora donde se almacena información. Un objeto de datos que el programador define y
nombra explícitamente en un programa. Una variable simple es un objeto elemental de datos con
nombre. El valor o valores de una variable es modificable por operaciones de asignación; es decir,
el enlace de objeto de datos a valor puede cambiar durante su tiempo de vida. Las operaciones
que se pueden realizar con dos o más valores exigen que éstas sean del mismo tipo de datos. No
se puede sumar una variable carácter a otra numérica y/o viceversa.
1.2 TIPOS DE VARIABLES EN C++
Todos los programas gestionan algunos tipos de información que normalmente se pueden
representar utilizando uno de los ocho (8) tipos de datos básicos de C y C++: texto o char, valores
enteros o int, valores de coma flotante o float, valores en coma flotante de doble precisión o
double (long double), enumerados o enum, sin valor o void, punteros y booleanos.
Int: El tipo de dato int, tiene un tamaño de 32 bits y un rango entre -2.147.483.648 y 2.147.483.647.Este tipo de dato, es usado para números enteros (sin cifras decimales). A continuación alguna de sus
combinaciones con los modificadores:
- short int: Tiene un tamaño de 16 bits y un rango entre -32.768 y 32.767.
- unsigned short int: Tiene un tamaño de 16 bits y un rango entre 0 y 65.535.
- unsigned int: Tiene un tamaño de 32 bits y un rango entre 0 y 4.294.967.295.
- long long int: Tiene un tamaño de 64 bits y un rango entre -9.223.372.775.808 y 9.223.375.775.807.
- unsigned long long int: Tiene un tamaño de 64 bits y un rango entre 0 y 18.446.744.073.709.551.615.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 4/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
13
float: El tipo de dato float, tiene un tamaño de 32 bits, es usado comúnmente en números con 6
o menos cifras decimales. Tiene un rango entre 1.17549 e-38
hasta 3.40282 e+38
.
double: El tipo de dato double, tiene un tamaño de 64 bits, es usado para números de menos de
15 cifras decimales. Tiene un rango entre 2.22507 e-308 hasta 1.79769 e+308.
long double: Tiene un tamaño de 96 bits y una precisión de 18 cifras decimales. Tiene un rango
entre 3.3621 e-4932 hasta 1.18973 e+4932.
bool: El tipo de dato bool, tiene un tamaño de 8 bits y un rango entre 0 y 1, en pocas palabras es
cero o es uno (falso o verdadero). Este tipo de dato, es comúnmente usado en condicionales o
variables al que se le puede asignar las constantes true (verdadero) y false (falso).
char: Esta constituido por caracteres simples, como (a-z / A-Z / 0-9) y cadenas, como “Esto es una
prueba” (normalmente, de 8 bits o un byte por carácter, con un rango de 0 a 255).
Las variables del tipo char, son digamos las variables problema del lenguaje C y C++, puesto que
tienen una gran cantidad de restricciones y complicaciones, bastante molestas. Las variables de
tipo char, en C y C++ son consideradas vectores y como quizá sabrás a los vectores se les debe
declarar un tamaño máximo, entre corchetes “[ ]” lo cual restringe un poco al momento de no
saber que tamaño podría llegar a tener una cadena de caracteres, y aunque hay formas de evadir
esto, es bastante complicado, desde mi punto de vista personal recomiendo las variables de tipo
string para las cadenas de caracteres, estas están incluidas en la librería #include <string.h> y son
bastante fáciles de usar y muy flexibles a diferencia de los char. Muy bien, de igual forma pondré
como se debe declarar un char y más abajo mencionare algunas otras molestias que este tipo de
dato genera, pero explicare como se arreglan.
Muy bien, la sintaxis es la siguiente:
char nombre_char [tamaño_max];
También es válido y solo es válido de esta forma la asignación por medio del signo “=” para un
char y es así:
char char_nombre [tamaño_max] = “cadena”;
Muy bien, como veras aquí lo único que hay extraño es lo del [tamaño_max], pues bien, ahí se
debe poner un numero entero que no cambia es decir constante que nos indica el tamañomáximo que tendrá nuestra cadena de caracteres, si nos pasamos de ese número, tendremos
problemas, así que recomiendo poner números grandes si no se sabe el tamaño que podría tener,
pero bueno, esto nos podría desperdiciar memoria y recursos o todo lo contrario, nos podrían
quedar faltando.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 5/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
14
void: El tipo void, se utiliza para especificar valores que ocupan 0 bits y no tienen valor (este tipo
también se puede utilizar para la creación de punteros genéricos).
puntero: El tipo de dato puntero, no contiene información en el mismo sentido que el resto de
los tipos de datos; en su lugar, cada puntero contiene la dirección de la posición de memoria que
almacena el dato actual.
1.3 ¿CÓMO SE DECLARA UNA VARIABLE EN C++?
El sistema es siempre el mismo, primero se especifica el tipo y a continuación una lista de
variables y finalmente un punto y coma.
La declaración de variables es uno de los tipos de sentencia de C++.
La prueba más clara de esto es que la declaración terminará con un ";".
Sintaxis:
También es posible inicializar las variables dentro de la misma declaración.
Por ejemplo:
Declararía las variables “a, seguir y encontrado”; y además iniciaría los valores de “a y seguir” con
los valores “1234 y true”, respectivamente.
1.4 REGLAS PARA LA DECLARACION DE VARIABLES
Bien pues, ya sabemos que en la programación tenemos que estar muy atentos a la
sintaxis (Estructura de una Palabra), pues es importantísimo, ya que si no está bien escrito un
comando, no va a funcionar esa línea en el código del programa y peor aún, si esa línea está
ligada a las líneas de más adelante pues no funcionará ni ésta ni las de más adelante (Como una
Cadena). Entonces les diré algunas reglas para la declaración de variables, cuando veamos un
lenguaje de programación especifico colocaré la sintaxis de sus comandos ya que las sintaxiscambia (La lógica no, ósea cambian las palabras pero la forma de realizar el ejercicio sigue
siendo la misma), porque cada lenguaje tiene su dialecto. Comencemos:
<tipo> <lista de variables>;
int a = 1234;
bool seguir = true, encontrado;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 6/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
15
Regla 1:
Tener el mismo nombre que una “palabra reservada” del lenguaje.
Explicación: Los lenguajes de programación tienen “palabras reservadas“, ósea que esas palabras
solo pueden ser usadas por el programa, por eso llevan el nombre de “reservadas“ , pues sisupongamos el caso de que un lenguaje de programación “ X ” tiene sus palabras reservadas entre
las cuales está: “ingresar “, entonces eso quiere decir que el usuario NO debe declarar una
variable con el nombre “ingresar “, porque va a tener conflictos más adelante.
Regla 2:
Sólo pueden ser letras, dígitos y el guión bajo ó subguión. Además debe tener no más de 40
caracteres.
Explicación: Pues en los lenguajes de programación hay sintaxis que deben cumplirse al pie de la
letra, entonces dice que las variables solo pueden llevar letras, números y el subguión.
Ejemplo:
La siguiente variable está bien declarada: programando19
La siguiente variable está mal declarada: %&programando-19
Vemos que insertó caracteres especiales, además de que uso el guión normal (no el subguión),
por lo tanto puede que el programa entienda que es una resta, entonces está mal declarado
por sintaxis.
Regla 3:
Deben comenzar por un carácter (letra).
Explicación: Por sintaxis como ya hemos visto, deben cumplir con estas reglas, entonces no se
puede comenzar con un número, ya que se debe comenzar por una letra como dice la regla.
Ejemplo:
La siguiente variable está bien declarada: pasoApaso
La siguiente variable está mal declarada: 89pasos
Regla 4:
Deben iniciar con un carácter (no numero) como vimos en la Regla 3, y también puede comenzar
con un guión bajo (_).

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 7/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
16
Ejemplo:
La siguiente variable está bien declarada: _descuento
La siguiente variable está mal declarada: -descuento
La siguiente variable está mal declarada: descuento-
Regla 5:
No se les pueden asignar espacios en blanco.
Explicación: Las variables no pueden llevar espacios en blanco, solo pueden ser separadas por un
signo dedicado a ser usado como un espacio, el cual es el subguión (_), entonces en una variable
cuando vean un subguión, prácticamente están separando algo (para que no parezca una
ensalada).
Ejemplo:
La siguiente variable está bien declarada: eddy_19
La siguiente variable está mal declarada: eddy 19
Regla 6:
No pueden llevar acento (tilde).
Ejemplo:
La siguiente variable está bien declarada: numero
La siguiente variable está mal declarada: número
Esas son las “Reglas Base“ , para la buena declaración de variables.
1.5 PALABRAS CLAVE DEL C++
En C++, como en cualquier otro lenguaje, existen una serie de palabras clave (keywords) que el
usuario no puede utilizar como identificadores (nombres de variables y/o de funciones). Estas
palabras sirven para indicar al computador que realice una tarea muy determinada (desde
evaluar una comparación, hasta definir el tipo de una variable) y tienen un especial significado
para el compilador. El C++ es un lenguaje muy conciso, con muchas menos palabras clave que
otros lenguajes. A continuación se presenta la lista de las 32 palabras clave del ANSI C, para las
que más adelante se dará detalle de su significado (algunos compiladores añaden otras palabras
clave, propias de cada uno de ellos. Es importante evitarlas como identificadores):
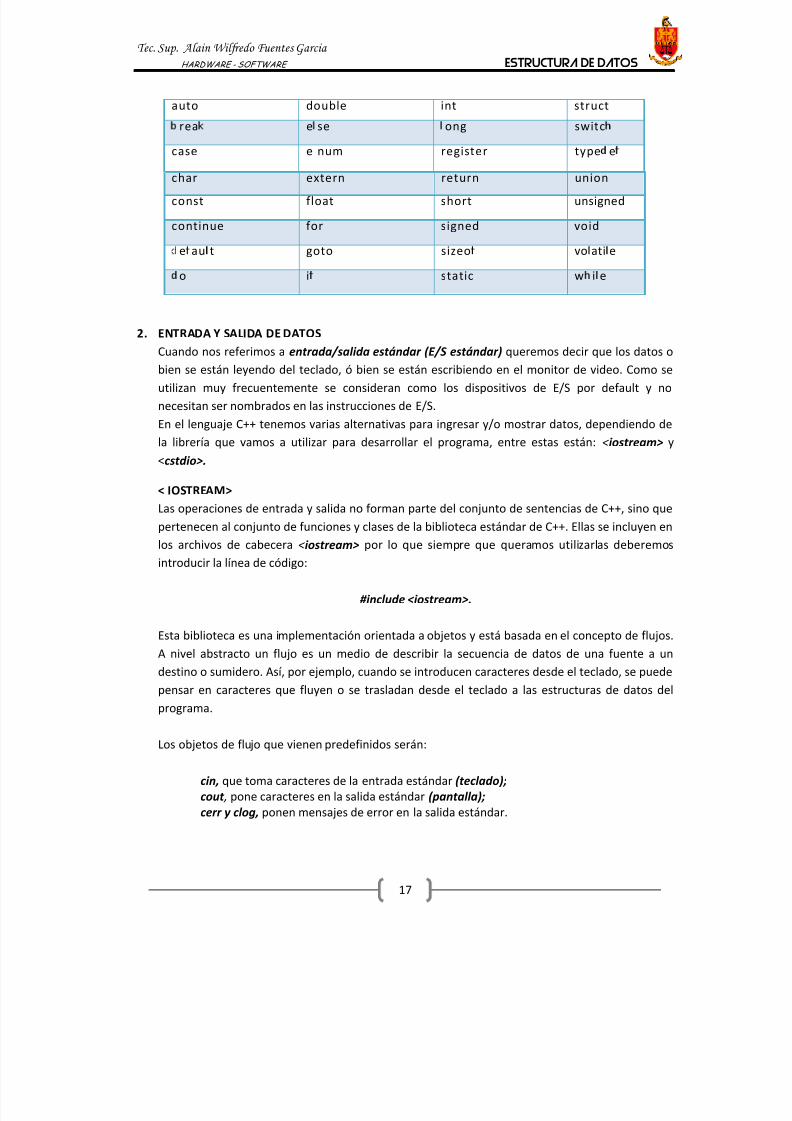
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 8/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
17
auto double int struct
rea e se ong switc
case e num register type e
char extern return union
const float short unsigned
continue for signed void
e au t goto sizeo vo ati e
o i static w i e
2. ENTRADA Y SALIDA DE DATOS
Cuando nos referimos a entrada/salida estándar (E/S estándar) queremos decir que los datos o
bien se están leyendo del teclado, ó bien se están escribiendo en el monitor de video. Como se
utilizan muy frecuentemente se consideran como los dispositivos de E/S por default y no
necesitan ser nombrados en las instrucciones de E/S.
En el lenguaje C++ tenemos varias alternativas para ingresar y/o mostrar datos, dependiendo de
la librería que vamos a utilizar para desarrollar el programa, entre estas están: <iostream> y
<cstdio>.
< IOSTREAM>
Las operaciones de entrada y salida no forman parte del conjunto de sentencias de C++, sino que
pertenecen al conjunto de funciones y clases de la biblioteca estándar de C++. Ellas se incluyen en
los archivos de cabecera <iostream> por lo que siempre que queramos utilizarlas deberemos
introducir la línea de código:
#include <iostream>.
Esta biblioteca es una implementación orientada a objetos y está basada en el concepto de flujos.
A nivel abstracto un flujo es un medio de describir la secuencia de datos de una fuente a un
destino o sumidero. Así, por ejemplo, cuando se introducen caracteres desde el teclado, se puede
pensar en caracteres que fluyen o se trasladan desde el teclado a las estructuras de datos del
programa.
Los objetos de flujo que vienen predefinidos serán:
cin, que toma caracteres de la entrada estándar (teclado);cout , pone caracteres en la salida estándar (pantalla);cerr y clog, ponen mensajes de error en la salida estándar.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 9/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
18
Estos objetos se utilizan mediante los operadores << y >>. El operador << se denomina operador
de inserción; y apunta al objeto donde tiene que enviar la información. Por lo tanto la sintaxis de
cout será:
cout<<variable1<<variable2<<.........<<variableN;
No olvidemos que las cadenas de texto son variables y se ponen entre " " (comillas dobles).
Por su parte >> se denomina operador de extracción, lee información del flujo cin (a la izquierda
del operador) y las almacena en las variables indicadas a la derecha).
La sintaxis sería la siguiente:
cin>>variable1>>variable2>>….....>>variableN;
Un ejemplo de código utilizando ambos objetos podría ser el siguiente:
#include <iostream>
using namespace std;
int main ()
{
int num;
cout<<"Introduce un número: ";
cin>>num;
cout<<"Usted introdujo: "<<num;
return 0;
}
Que mostraría por pantalla la frase "Introduce un número" y posteriormente almacenaría el valorintroducido por teclado en la variable num, para luego mostrar por pantalla la frase “Usted introdujo: “, seguidamente del dato almacenado en la variable num.
3. OPERADORES, EXPRESIONES Y SENTENCIAS.
3.1 OPERADORES.
Un operador es un carácter o grupo de caracteres que actúa sobre una, dos o más variables para
realizar una determinada operación con un determinado resultado. Ejemplos típicos de
operadores son la suma (+), la diferencia (-), el producto (*), etc. Los operadores pueden ser
unarios, binarios y ternarios, según actúen sobre uno, dos o tres operandos, respectivamente. En
C++ existen muchos operadores de diversos tipos (éste es uno de los puntos fuertes del lenguaje),
que se verán a continuación.
3.1.1 OPERADORES ARITMÉTICOS
Los operadores aritméticos son los más sencillos de entender y de utilizar. Todos ellos son
operadores binarios. En C++ se utilizan los cinco operadores siguientes:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 10/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
19
Suma: +
Resta: -
Multiplicación: *
División: /
Modulo: %
Todos estos operadores se pueden aplicar a constantes, variables y expresiones. El resultado es el
que se obtiene de aplicar la operación correspondiente entre los dos operandos. El único
operador que requiere una explicación adicional es el operador modulo %. En realidad su nombre
completo es resto de la división entera. Este operador se aplica solamente a constantes, variables
o expresiones de tipo int. Aclarado esto, su significado es evidente: 23 % 4 es 3, puesto que el
resto de dividir 23 por 4 es 3. Si a % b es cero, a es múltiplo de b.
Como se verá más adelante, una expresión es un conjunto de variables y constantes y también de
otras expresiones más sencillas relacionadas mediante distintos operadores. Un ejemplo de
expresión en la que intervienen operadores aritméticos es el siguiente polinomio de grado 2 en la
variable x:
5.0 + 3.0*x - x*x/2.0
Las expresiones pueden contener paréntesis (...) que agrupan a algunos de sus términos.
Puede haber paréntesis contenidos dentro de otros paréntesis. El significado de los paréntesis
coincide con el habitual en las expresiones matemáticas, con algunas características importantes
que se verán más adelante. En ocasiones, la introducción de espacios en blanco mejora la
legibilidad de las expresiones.
3.1.2 OPERADORES DE ASIGNACIÓN
Los operadores de asignación atribuyen a una variable es decir, depositan en la zona de memoria
correspondiente a dicha variable– el resultado de una expresión o el valor de otra variable (en
realidad, una variable es un caso particular de una expresión).
El operador de asignación más utilizado es el operador de igualdad (=), que no debe ser
confundido con la igualdad matemática. Su forma general es:
nombre_de_variable = expresion;
cuyo funcionamiento es como sigue: se evalúa expresión y el resultado se deposita en
nombre_de_variable, sustituyendo cualquier otro valor que hubiera en esa posición de memoria
anteriormente. Una posible utilización de este operador es como sigue:
variable = variable + 1;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 11/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
20
Desde el punto de vista matemático este ejemplo no tiene sentido (¡Equivale a 0 = 1!), pero sí lo
tiene considerando que en realidad el operador de asignación (=) representa una sustitución; en
efecto, se toma el valor de variable contenido en la memoria, se le suma una unidad y el valor
resultante vuelve a depositarse en memoria en la zona correspondiente al identificador variable,
sustituyendo al valor que había anteriormente. El resultado ha sido incrementar el valor de
variable en una unidad.
Así pues, una variable puede aparecer a la izquierda y a la derecha del operador (=). Sin embargo,
a la izquierda del operador de asignación (=) no puede haber nunca una expresión:
Tiene que ser necesariamente el nombre de una variable. Es incorrecto, por tanto, escribir algo
así como:
a + b = c; // incorrecto
Existen otros cuatro operadores de asignación (+=, -=, *= y /=) formados por los cuatro
operadores aritméticos seguidos por el carácter de igualdad. Estos operadores simplifican algunas
operaciones recurrentes sobre una misma variable. Su forma general es:
variable op= expresion;
Donde “op” representa cualquiera de los operadores (+ - * /). La expresión anterior es
equivalente a:
variable = variable op expresion;
A continuación se presentan algunos ejemplos con estos operadores de asignación:
distancia += 1; equivale a: distancia = distancia + 1;
rango /= 2.0 equivale a: rango = rango /2.0
x *= 3.0 * y - 1.0 equivale a: x = x * (3.0 * y - 1.0)
3.1.3 OPERADORES INCREMENTALES
Los operadores incrementales (++) y (--) son operadores unarios que incrementan o disminuyen
en una unidad el valor de la variable a la que afectan. Estos operadores pueden ir
inmediatamente delante o detrás de la variable. Si preceden a la variable, ésta es incrementada
antes de que el valor de dicha variable sea utilizado en la expresión en la que aparece. Si es la
variable la que precede al operador, la variable es incrementada después de ser utilizada en la
expresión. A continuación se presenta un ejemplo de estos operadores:
i = 2;
j = 2;
m = i++; // después de ejecutarse esta sentencia m=2 e i=3
n = ++j; // después de ejecutarse esta sentencia n=3 y j=3
Estos operadores son muy utilizados. Es importante entender muy bien por qué los resultados m
y n del ejemplo anterior son diferentes.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 12/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
21
3.1.4 OPERADORES RELACIONALES
Este es un apartado especialmente importante para todas aquellas personas sin experiencia en
programación. Una característica imprescindible de cualquier lenguaje de programación es la de
considerar alternativas, esto es, la de proceder de un modo u otro según se cumplan o no ciertas
condiciones. Los operadores relacionales permiten estudiar si se cumplen o no esas condiciones.
Así pues, estos operadores producen un resultado u otro según se cumplan o no algunas
condiciones que se verán a continuación.
En el lenguaje natural, existen varias palabras o formas de indicar si se cumple o no una
determinada condición. En inglés estas formas son (yes, no); (on, off); (true, false), etc. En
Informática se ha hecho bastante general el utilizar la última de las formas citadas: (true, false). Si
una condición se cumple, el resultado es true; en caso contrario, el resultado es false.
En C++ un “0” representa la condición de “false”, y cualquier número distinto de 0 equivale a la
condición “true”. Cuando el resultado de una expresión es true y hay que asignar un valor
concreto distinto de cero, por defecto se toma un valor unidad. Los operadores relacionales de
C++ son los siguientes:
Igual que: ==
Menor que: <
Mayor que: >
Menor o igual que: <=
Mayor o igual que: >=
Distinto que: !=
Todos los operadores relacionales son operadores binarios (tienen dos operandos), y su forma
general es la siguiente:
expresion1 op expresion2
Donde “op” es uno de los operadores (==, <, >, <=, >=, !=). El funcionamiento de estos operadores
es el siguiente: se evalúan expresion1 y expresion2, y se comparan los valores resultantes. Si la
condición representada por el operador relacional se cumple, el resultado es “1” ; si la condición
no se cumple, el resultado es “0”.
A continuación se incluyen algunos ejemplos de estos operadores aplicados a constantes:
(2==1) // Resultado=0 porque la condición no se cumple
(3<=3) // Resultado=1 porque la condición se cumple
(3<3) // Resultado=0 porque la condición no se cumple
(1!=1) // Resultado=0 porque la condición no se cumple
3.1.5 OPERADORES LÓGICOS
Los operadores lógicos son operadores binarios que permiten combinar los resultados de los
operadores relacionales, comprobando que se cumplen simultáneamente varias condiciones, que
se cumple una u otra, etc. El lenguaje C tiene dos operadores lógicos: el operador Y (&&) y el
operador O ( || ). En inglés son los operadores and y or .
Su forma general es la siguiente:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 13/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
22
expresion1 || expresion2
expresion1 && expresion2
El operador && devuelve un “1” si tanto expresion1 como expresion2 son verdaderas (o distintas
de “0” ), y “0” en caso contrario, es decir si una de las dos expresiones o las dos son falsas (iguales
a “0” ); por otra parte, el operador || devuelve “1” si al menos una de las expresiones es cierta. Es
importante tener en cuenta que los compiladores de C++ tratan de optimizar la ejecución de
estas expresiones, lo cual puede tener a veces efectos no deseados. Por ejemplo:
Para que el resultado del operador && sea verdadero, ambas expresiones tienen que ser
verdaderas; si se evalúa expresion1 y es falsa, ya no hace falta evaluar expresion2, y de hecho no
se evalúa. Algo parecido pasa con el operador ||: si expresion1 es verdadera, ya no hace falta
evaluar expresion2.
Los operadores && y || se pueden combinar entre sí –quizás agrupados entre paréntesis, dando
a veces un código de más difícil interpretación. Por ejemplo:
(2==1) || (-1==-1) // el resultado es 1
(2==2) && (3==-1) // el resultado es 0
((2==2) && (3==3)) || (4==0) // el resultado es 1
((6==6) || (8==0)) && ((5==5) && (3==2)) // el resultado es 0
3.1.6 OTROS OPERADORES
Además de los operadores vistos hasta ahora, el lenguaje C dispone de otros operadores. En esta
sección se describen algunos operadores unarios adicionales.
Operador menos (–).
El efecto de este operador en una expresión es cambiar el signo de la variable o expresión que le
sigue. Recuérdese que en C++ no hay constantes numéricas negativas. La forma general de este
operador es:
- expresión
Operador más (+).
Este es un nuevo operador unario introducido en el ANSI C, y que tiene como finalidad la de servir
de complemento al operador (–) visto anteriormente. Se puede anteponer a una variable o
expresión como operador unario, pero en realidad no hace nada.
Operador sizeof( ).
Este es el operador de C con el nombre más largo. Puede parecer una función, pero en realidad es
un operador. La finalidad del operador sizeof( ) es devolver el tamaño, en bytes, del tipo de
variable introducida entre los paréntesis. Recuérdese que este tamaño depende del compilador y
del tipo de computador que se está utilizando, por lo que es necesario disponer de este operador
para producir código portable. Por ejemplo:
var_1 = sizeof(double) // var_1 contiene el tamaño
// de una variable doublé

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 14/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
23
Operador negación lógica (!).
Este operador devuelve un cero (false) si se aplica a un valor distinto de cero (true), y devuelve un
1 (true) si se aplica a un valor cero (false). Su forma general es:
!expresion
Operador coma (,).
Los operandos de este operador son expresiones, y tiene la forma general:
expresion = expresion_1, expresion_2
En este caso, expresion_1 se evalúa primero, y luego se evalúa expresion_2. El resultado global es
el valor de la segunda expresión, es decir de expresion_2. Este es el operador de menos
precedencia de todos los operadores de C++. Como se explicará más adelante, su uso más
frecuente es para introducir expresiones múltiples en la sentencia FOR.
Operadores dirección (&) e indirección (*).
Aunque estos operadores se introduzcan aquí de modo circunstancial, su importancia en el
lenguaje C++ es absolutamente esencial, resultando uno de los puntos más fuertes y quizás más
difíciles de dominar de este lenguaje.
La forma general de estos operadores es la siguiente:
*expresion;
&variable;
El operador dirección & devuelve la dirección de memoria de la variable que le sigue.
Por ejemplo:
variable_1 = &variable_2;
Después de ejecutarse esta instrucción variable_1 contiene la dirección de memoria donde se
guarda el contenido de variable_2. Las variables que almacenan direcciones de otras variables se
denominan punteros (o apuntadores), deben ser declaradas como tales, y tienen su propia
aritmética y modo de funcionar. Se verán con detalle un poco más adelante.
No se puede modificar la dirección de una variable, por lo que no están permitidas operaciones
en las que el operador & figura a la izquierda del operador (=), al estilo de:
&variable_1 = nueva_direccion;
El operador indirección * es el operador complementario del &. Aplicado a una expresión que
represente una dirección de memoria (puntero) permite hallar el contenido o valor almacenado
en esa dirección. Por ejemplo:
variable_3 = *variable_1;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 15/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
24
El contenido de la dirección de memoria representada por la variable de tipo puntero variable_1
se recupera y se asigna a la variable variable_3.
Como ya se ha indicado, las variables puntero y los operadores dirección (&) e indirección (*)
serán explicados con mucho más detalle en una sección posterior.
3.2 EXPRESIONES
Ya han aparecido algunos ejemplos de expresiones del lenguaje C++ en las secciones precedentes.
Una expresión es una combinación de variables y/o constantes, y operadores. La expresión es
equivalente al resultado que proporciona al aplicar sus operadores a sus operandos. Por ejemplo:
1+5 es una expresión formada por dos operandos (1 y 5) y un operador (el +); esta expresión es
equivalente al valor 6, lo cual quiere decir que allí donde esta expresión aparece en el programa,
en el momento de la ejecución es evaluada y sustituida por su resultado. Una expresión puede
estar formada por otras expresiones más sencillas, y puede contener paréntesis de varios niveles
agrupando distintos términos. En C++ existen distintos tipos de expresiones.
3.2.1 EXPRESIONES ARITMÉTICAS
Están formadas por variables y/o constantes, y distintos operadores aritméticos e incrementales
(+, -, *, /, %, ++, --). Como se ha dicho, también se pueden emplear paréntesis de tantos niveles
como se desee, y su interpretación sigue las normas aritméticas convencionales. Por ejemplo, la
solución de la ecuación de segundo grado:
=− ± √ −
Se escribe, en C++ en la forma:
x= (-b + sqrt( (b*b)-(4*a*c) ) ) /(2*a);
Donde, estrictamente hablando, sólo lo que está a la derecha del operador de asignación (=) es
una expresión aritmética. El conjunto de la variable que está a la izquierda del signo (=), el
operador de asignación, la expresión aritmética y el carácter (;) constituyen una sentencia. En la
expresión anterior aparece la llamada a la función de librería sqrt(), que tiene como valor de
retorno la raíz cuadrada de su único argumento. En las expresiones se pueden introducir espacios
en blanco entre operandos y operadores; por ejemplo, la expresión anterior se puede escribir
también de la forma:
x= (-b + sqrt( ( b * b ) - ( 4 * a * c ) ) ) /(2*a);
3.2.2 EXPRESIONES LÓGICAS
Los elementos con los que se forman estas expresiones son valores lógicos; verdaderos (true, o
distintos de 0) y falsos (false, o iguales a 0), y los operadores lógicos ||, && y !. También se

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 16/135

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 17/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
26
3.3.1 SENTENCIAS SIMPLESUna sentencia simple es una expresión de algún tipo terminada con un carácter (;). Un caso típico
son las declaraciones o las sentencias aritméticas. Por ejemplo:
float real;
espacio = espacio_inicial + velocidad * tiempo;
3.3.2 SENTENCIA VACÍA Ó NULAEn algunas ocasiones es necesario introducir en el programa una sentencia que ocupe un lugar, pero que no realice ninguna tarea. A esta sentencia se le denomina sentencia vacía y consta de
un simple carácter (;). Por ejemplo:
;
3.3.3 SENTENCIAS COMPUESTAS O BLOQUESMuchas veces es necesario poner varias sentencias en un lugar del programa donde debería
haber una sola. Esto se realiza por medio de sentencias compuestas. Una sentencia compuesta esun conjunto de declaraciones y de sentencias agrupadas dentro de llaves {...}. También se
conocen con el nombre de bloques. Una sentencia compuesta puede incluir otras sentencias,
simples y compuestas. Un ejemplo de sentencia compuesta es el siguiente:
{ int i = 1, j = 3, k;double masa;masa = 3.0;k = i + j; }
4. CONTROL DEL FLUJO DE EJECUCIÓN
En principio, las sentencias de un programa en C se ejecutan secuencialmente, esto es, cada una a
continuación de la anterior empezando por la primera y acabando por la última. El lenguaje C++
dispone de varias sentencias para modificar este flujo secuencial de la ejecución.
Las más utilizadas se agrupan en dos familias: las bifurcaciones, que permiten elegir entre dos o
más opciones según ciertas condiciones, y los bucles, que permiten ejecutar repetidamente un
conjunto de instrucciones tantas veces como se desee, cambiando o actualizando ciertos valores.
4.1 BIFURCACIONES
4.1.1 OPERADOR CONDICIONALEl operador condicional es un operador con tres operandos (ternario) que tiene la siguiente forma
general:
expresion_1 ? expresion_2 : expresion_3;
Explicación: Se evalúa expresion_1. Si el resultado de dicha evaluación es true (=1), se ejecuta
expresion_2; si el resultado es false (=0), se ejecuta expresion_3.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 18/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
27
4.1.2 SENTENCIA “IF”Esta sentencia de control permite ejecutar o no una sentencia simple o compuesta según se
cumpla o no una determinada condición. Esta sentencia tiene la siguiente forma general:
if (expresion)
sentencia;
Explicación: Se evalúa “ expresion” . Si el resultado es true (=1), se ejecuta sentencia; si el
resultado es false (=0), se salta sentencia y se prosigue en la línea siguiente. Hay que recordar
que sentencia puede ser una sentencia simple o compuesta (bloque { ... }).
EJEMPLO Nº 1Realizar un programa que permita determinar si un número introducido por teclado es positivo.
#include <iostream>
using namespace std;
int main()
{
int num;
cout<<"Introduzca un numero"<<endl;
cin>>num;
if (num>0)
cout<<"Es positivo";
return 0;
}
4.1.3 SENTENCIA “IF ... ELSE”
Esta sentencia permite realizar una bifurcación, ejecutando una parte u otra del programa segúnse cumpla o no una cierta condición. La forma general es la siguiente:
if (expresion)
sentencia_1;
else
sentencia_2;
Explicación: Se evalúa “ expresion” . Si el resultado es true (=1), se ejecuta sentencia_1 y se
prosigue en la línea siguiente a sentencia_2; si el resultado es false (=0), se salta sentencia_1, se
ejecuta sentencia_2 y se prosigue en la línea siguiente. Hay que indicar aquí también que
sentencia_1 y sentencia_2 pueden ser sentencias simples o compuestas (bloques { ... }).
EJEMPLO Nº 2Diseñar un programa para determinar el mayor de dos números introducidos por teclado.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 19/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
28
#include <iostream>
using namespace std;
int main()
{
int num1,num2;cout<<"Introduzca el primer numero"<<endl;
cin>>num1;
cout<<"Introduzca el segundo numero"<<endl;
cin>>num2;
if (num1>num2)
cout<<"l mayor es: "<<num1;
else
cout<<"El mayor es: "<<num2;
return 0;
}
4.1.4 SENTENCIA “IF ... ELSE” MÚLTIPLE Esta sentencia permite realizar una ramificación múltiple, ejecutando una entre varias partes del
programa según se cumpla una entre n condiciones. La forma general es la siguiente:
if (expresion_1)
sentencia_1;
else if (expresion_2)
sentencia_2;
else if (expresion_3)
sentencia_3;
else if (...)
...
else
sentencia_n;
Explicación: Se evalúa expresion_1. Si el resultado es true, se ejecuta sentencia_1. Si el resultado
es false, se salta sentencia_1 y se evalúa expresion_2. Si el resultado es true se ejecuta
sentencia_2, mientras que si es false se evalúa expresion_3 y así sucesivamente. Si ninguna de
las expresiones o condiciones es true se ejecuta expresion_n que es la opción por defecto (puede
ser la sentencia vacía, y en ese caso puede eliminarse junto con la palabra else). Todas las
sentencias pueden ser simples o compuestas. (bloques { ... }).
EJEMPLO Nº 3Establecer si dos números introducidos por teclado son consecutivos, ya sea en forma ascendente
o descendente.
#include <iostream>
using namespace std;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 20/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
29
int main()
{
int num1,num2;
cout<<"Introduzca un primer numero"<<endl;
cin>>num1;
cout<<"Introduzca un segundo numero"<<endl;
cin>>num2;if (num2==(num1+1))
cout<<num1<<" "<<num2<<" Son numeros consecutivos";
else if (num1==(num2+1))
cout<<num1<<" "<<num2<<" Son numeros consecutivos";
else
cout<<num1<<" "<<num2<<" No son numeros consecutivos";
return 0;
}
4.1.5 SENTENCIA “SWITCH”La sentencia que se va a describir a continuación desarrolla una función similar a la de la
sentencia “if ... else” con múltiples ramificaciones, aunque como se puede ver presenta tambiénimportantes diferencias. La forma general de la sentencia switch es la siguiente:
switch (expresion){
case expresion_cte_1: sentencia_1;case expresion_cte_2: sentencia_2;...case expresion_cte_n: sentencia_n;
}
Explicación: Se evalúa expresion y se considera el resultado de dicha evaluación. Si dicho
resultado coincide con el valor constante expresion_cte_1, se ejecuta sentencia_1 seguida de
sentencia_2, sentencia_3, ..., sentencia. Si el resultado coincide con el valor constante
expresion_cte_2, se ejecuta sentencia_2 seguida de sentencia_3, ..., sentencia. En general, se
ejecutan todas aquellas sentencias que están a continuación de la expresion_cte cuyo valor
coincide con el resultado calculado al principio. Si ninguna expresion_cte coincide se ejecuta la
sentencia que está a continuación de default. Si se desea ejecutar únicamente una sentencia_i (y
no todo un conjunto de ellas), basta poner una sentencia break a continuación (en algunos casos
puede utilizarse la sentencia return o la función exit()). El efecto de la sentencia break es dar por
terminada la ejecución de la sentencia switch. Existe también la posibilidad de ejecutar la misma
sentencia_i para varios valores del resultado de expresion, poniendo varios case expresion_cteseguidos.
El siguiente ejemplo ilustra las posibilidades citadas:
switch (expresion){ case expresion_cte_1: sentencia_1;
break;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 21/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
30
case expresion_cte_2: case expresion_cte_3:sentencia_2;break;
default: sentencia_3; }
EJEMPLO Nº 4Realizar un menú con las cuatro operaciones básicas de la aritmética.
#include <iostream>
using namespace std;
int main()
{
int a,b,op;
cout<<"Inserte primer valor: "<<endl;
cin>>a;
cout<<"Inserte segundo valor: "<<endl;
cin>>b;
cout<<endl<<"Seleccione una opción: "<<endl;
cout<<"1.- Sumar"<<endl;
cout<<"2.- Restar"<<endl;
cout<<"3.- Multiplicar"<<endl;
cout<<"4.- Dividir"<<endl;
cout<<"5.- Salir"<<endl;
cout<<endl<<"Opcion: ";
cin>>op;
switch(op)
{
case 1: cout<<"La suma es: "<<a+b;break;case 2: cout<<"La resta es: "<<a-b;break;
case 3: cout<<"El producto es: "<<a*b;break;
case 4: cout<<"La division es: "<<a/b;break;
case 5: break;
}
return 0;
}
4.1.6 SENTENCIAS IF ANIDADASUna sentencia if puede incluir otros if dentro de la parte correspondiente a su sentencia. A estas
sentencias se les llama sentencias anidadas (una dentro de otra). Por ejemplo:
if (a >= b)if (b != 0.0)
c = a/b;
En ocasiones pueden aparecer dificultades de interpretación con sentencias if...else anidadas,
como en el caso siguiente:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 22/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
31
if (a >= b)if (b != 0.0)
c = a/b;else
c = 0.0;
En principio se podría plantear la duda de a cuál de los dos if corresponde la parte else del
programa. Los espacios en blanco las indentaciones de las líneas parecen indicar que la sentencia
que sigue a else corresponde al segundo de los if , y así es en realidad, pues la regla es que el elsepertenece al if más cercano. Sin embargo, no se olvide que el compilador de C++ no considera los
espacios en blanco (aunque sea muy conveniente introducirlos para hacer más claro y legible el
programa), y que si se quisiera que el else perteneciera al primero de los if no bastaría cambiar
los espacios en blanco, sino que habría que utilizar llaves, en la forma:
if (a >= b){
if (b != 0.0)
c = a/b; }else
c = 0.0;
Recuérdese que todas las sentencias if e if...else, equivalen a una única sentencia por la posición
que ocupan en el programa.
EJEMPLO Nº 5Dado tres números enteros determinar cuál de ellos es el número mayor.
#include <iostream>
using namespace std;
int main()
{
int num1,num2,num3;
cout<<"Primer valor"<<endl;
cin>>num1;
cout<<"Segundo valor"<<endl;
cin>>num2;
cout<<"Tercer valor"<<endl;
cin>>num3;
if (num1>num2)
{
if(num1>num3)
cout<<"El mayor es: "<<num1;
else
cout<<"El mayor es: "<<num3;
}
else

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 23/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
32
{
if (num2>num3)
cout<<"El mayor es: "<<num2;
else
cout<<"El mayor es: "<<num3;
}
return 0;}
4.2 BUCLESAdemás de bifurcaciones, en el lenguaje C++ existen también varias sentencias que permiten
repetir una serie de veces la ejecución de unas líneas de código. Esta repetición se realiza, bien un
número determinado de veces, bien hasta que se cumpla una determinada condición de tipo
lógico o aritmético. De modo genérico, a estas sentencias se les denomina bucles. Las tres
construcciones del lenguaje C para realizar bucles son el while, el for y el do...while.
4.2.1 SENTENCIA “WHILE”
Esta sentencia permite ejecutar repetidamente, mientras se cumpla una determinada condición,una sentencia o bloque de sentencias. La forma general es como sigue:
while (expresion_de_control)sentencia;
Explicación: Se evalúa expresion_de_control y si el resultado es false se salta sentencia y se
prosigue la ejecución. Si el resultado es true se ejecuta sentencia y se vuelve a evaluar
expresion_de_control (evidentemente alguna variable de las que intervienen en
expresion_de_control habrá tenido que ser modificada, pues si no el bucle continuaría
indefinidamente). La ejecución de sentencia prosigue hasta que expresion_de_control se hace
false, en cuyo caso la ejecución continúa en la línea siguiente a sentencia. En otras palabras,
sentencia se ejecuta repetidamente mientras expresion_de_control sea true, y se deja deejecutar cuando expresion_de_control se hace false. Obsérvese que en este caso el control para
decidir si se sale o no del bucle está antes de sentencia, por lo que es posible que sentencia no se
llegue a ejecutar ni una sola vez. Todas las sentencias pueden ser simples o compuestas. (bloques{ ... }).
EJEMPLO Nº 6Realizar un programa que suma dos números hasta que los tales sean 0. El programa termina
cuando los datos son 0.
#include<iostream>
using namespace std;
int main()
{
int a, b;
while (cin>>a>>b && a>0 && b>0)
{
cout<<a+b<<endl;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 24/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
33
}
return 0;
}
4.2.2 SENTENCIA “FOR”For es quizás el tipo de bucle más versátil y utilizado del lenguaje C++. Su forma general es la
siguiente:
for (inicialización; expresion_de_control; actualización)
sentencia;
Explicación: Posiblemente la forma más sencilla de explicar la sentencia for sea utilizando la
construcción while que sería equivalente. Dicha construcción es la siguiente:
inicializacion;
while (expresion_de_control)
{
sentencia;
actualizacion;}
Donde sentencia puede ser una única sentencia terminada con (;), otra sentencia de control
ocupando varias líneas (if , while, for , ...), o una sentencia compuesta o un bloque encerrado entre
llaves {...}. Antes de iniciarse el bucle se ejecuta inicialización, que es una o más sentencias que
asignan valores iniciales a ciertas variables o contadores. A continuación se evalúa
expresion_de_control y si es false se prosigue en la sentencia siguiente a la construcción for ; si es
true se ejecutan sentencia y actualización, y se vuelve a evaluar expresion_de_control. El
proceso prosigue hasta que expresion_de_control sea false. La parte de actualizacion sirve para
actualizar variables o incrementar contadores. Un ejemplo típico puede ser el producto escalar de
dos vectores a y b de dimensión n:
for (pe =0.0, i=1; i<=n; i++)
{
pe += a[i]*b[i];
}
Primeramente se inicializa la variable pe a cero y la variable i a 1; el ciclo se repetirá mientras que
i sea menor o igual que n, y al final de cada ciclo el valor de i se incrementará en una unidad. En
total, el bucle se repetirá n veces. La ventaja de la construcción for sobre la construcción whileequivalente está en que en la cabecera de la construcción for se tiene toda la información sobre
cómo se inicializan, controlan y actualizan las variables del bucle.
Obsérvese que la inicialización consta de dos sentencias separadas por el operador (,).
EJEMPLO Nº 7
Diseñar un programa para generar la tabla de multiplicar de cualquier número introducido por
teclado.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 25/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
34
#include <iostream>
using namespace std;
int main()
{
int num;
cout<<"Inserte el numero que desa generar la tabla"<<endl;
cin>>num;
for (int i=1;i<=10;i++)
{
cout<<num<<" * "<<i<<" = "<<num*i<<endl;
}
return 0;
}
4.2.3 SENTENCIA “DO ... WHILE”Esta sentencia funciona de modo análogo a while, con la diferencia de que la evaluación de
expresion_de_control se realiza al final del bucle, después de haber ejecutado al menos una vez
las sentencias entre llaves; éstas se vuelven a ejecutar mientras expresion_de_control sea true.La forma general de esta sentencia es:
do
sentencia;
while(expresion_de_control);
Donde sentencia puede ser una única sentencia o un bloque, y en la que debe observarse que
hay que poner (;) a continuación del paréntesis que encierra a expresion_de_control, entre otros
motivos para que esa línea se distinga de una sentencia while ordinaria.
EJEMPLO Nº 8Realizar un programa que permita determinar la suma de la siguiente seria numérica:
S=2+4+6+8+10+……N;
#include <iostream>
using namespace std;
int main()
{
int n,s=0,t=2,a=1;cout<<"Ultimo termino a generar: "<<endl;
cin>>n;
cout<<endl;
do
{
cout<<t<<'\t';
s+=t;
t+=2;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 26/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
35
if(t-2==n)a=0;
}while (a);
cout<<endl<<endl<<"La suma es: "<<s;
return 0;
}
4.3 GENERACIÓN DE NÚMEROS ALEATORIOS
En C++, existe una función llamada rand(), que genera números aleatorios. El problema que
tiene esta función es que siempre que reinicies el programa, aparecerán los mismos números.
Para evitar esto, hay que darle un número “semilla”, el cual operará como base para la
generación de la secuencia de números. El problema con esto, es que si le damos un número
fijo, volvemos al problema anterior, ya que siempre utilizará la misma base definida y por
ende la secuencia será la misma.
Entonces, lo que necesitamos es darle un número “semilla” dinámico, esto es, que vaya
cambiando cada vez que ejecutemos el programa.
Sabiendo esto, la función que da la semilla a rand() es srand() , que recibe como parámetro (lo
que va entre los paréntesis) el número semilla, que en este caso, será la hora del sistema ensegundos. Así, a menos que el programa se ejecute 2 o más veces en menos de un segundo,
los números cambiarán.
La función para saber la hora actual del sistema es time(NULL).Sabiendo esto, vamos al código. Haremos un generador de números aleatorios, donde la
cantidad de estos, la decidirá el usuario, ingresando esta cantidad por teclado.
Así que lo primero que tenemos que hacer es incluir la librería:
#include<cstdlib>
Luego inicializar los números aleatorios incluyendo esto:
srand(time(NULL));
Solo hay que utilizar además la librería time.h:
#include<time.h>
Luego guardar el número aleatorio en alguna parte:
num=rand();
Eso es básicamente. Para ajustar el rango de número aleatorios podemos hacer varias cosas.
Número aleatorios entre 0 y 50:
num=rand()%51;
Número aleatorios entre 1 y 100:
num=1+rand()%(101-1);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 27/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
36
Número aleatorios entre 250 y 420:
num=250+rand()%(421-250);
De forma general es:
variable = limite_inferior + rand() % (limite_superior +1 - limite_inferior) ;
EJEMPLO Nº 9Realizar un programa que muestre 10 números aleatorios entre 1 y 10:
#include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int num,c;
srand(time(NULL));
for(c=1;c<=10;c++)
{
num=1+rand()%(11-1);//Generando números aleatorio entre 1 y 10
cout<<num<<" ";
}
cin.get();//Espera de tecla
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 28/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
37
PROBLEMAS PROPUESTOS
Con los fundamentos necesarios de C++ que hemos aprendido, ya estás listo para resolver los
siguientes problemas.
1. Diseñar un programa para calcular la suma de dos números A y B2. Calcular el área de un triángulo de base B y altura H
3. Calcular el área de un círculo de radio R
4. Ingresar una nota por teclado y determinar si es de aprobación o reprobación
5. Ingresar un número por teclado y determinar si es PAR o IMPAR
6. Determinar si una persona es "Niño – 1 a 10 años", "Adolescente – 11 a 17 años", "Joven
– 18 a 29 años", "Adulto – 30 a 60 años", "Tercera Edad – 60 a 100 años", de acuerdo a su
edad que es introducida por teclado.
7. Generar Aleatoriamente dos números enteros entre 0 y 100. Determinar cuál es el mayor
de ellos.
8. Introducir tres números por teclado. Determinar cuál es el mayor de los tres
9. Visualizar cuatro operaciones aritméticas de dos números cualesquiera introducidos por
teclado.
10. Ingresar un número cualquiera, determina si es POSITIVO, NEGATIVO ó CERO
11. Generar un numero aleatoriamente entre 1 a 1000 y determinar si es PAR o IMPAR
12. Introducir un número positivo por teclado. Si es negativo o cero rechazarlo, caso
contrario, determinar si el número positivo es par o impar
13. Ingresar un número por teclado y determinar si es múltiplo de 10
14. Ingresar una nota por teclado y determinar su grado de aprovechamiento (0-10) Pésimo,(11-20) Muy Malo, (21-30) Malo, (31-40) regular, (41-50) Bueno, (51-60) Muy Bueno, (61-
70) Excelente
15. Simular un juego con un dado. Si se saca un 1 o un 6 e gana, caso contrario se pierde.
16. Simular un juego con dos dados. Si se saca un siete o un once se gana, caso contrario se
pierde.
17. Visualizar la serie 1,3,5,7,…….n
18. Visualizar la serie 1,4,7,10,13,16……..n
19. Ingresar un número y visualizar su tabla de multiplicar

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 29/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
38
rcia
ESTRUCTUR
38
DE DATOS
38

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 30/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
39
5. INTRODUCCION A LA ESTRUCTURA DE DATOSUna estructura de datos es una colección de datos que pueden ser caracterizados por su
organización y las operaciones que se definen en ella.
Las estructuras de datos son muy importantes en los sistemas de computadoras. Los tipos de
datos más frecuentes utilizados en los diferentes lenguajes de programación son:
Datos Simples Estándar entero (integer)
real (real)
carácter (char)
lógico (boolean)
Definido por el programador
(No estándar)
subrango (subrange)
enumerativo (enumerated)
Datos Estructurados Estáticos arrays (vectores / matrices)
registros (record)
ficheros (archivos)
conjuntos (set)
cadenas (string)Dinámicos listas (pilas / colas)
listas enlazadas
árboles
grafos
5.1 ARRAYS UNIDIMENSIONALES: “VECTORES”Los vectores son una forma de almacenar datos que permiten contener una serie de valores del
mismo tipo, cada uno de los valores contenidos tiene una posición asociada que se usará para
accederlos. Está posición o índice será siempre un número entero positivo.En C++ la cantidad de elementos que podrá contener un vector es fijo, y en principio se define
cuando se declara el vector. Los vectores se pueden declarar de la siguiente forma:
tipo_elemento nombre[largo];
Esto declara la variable nombre como un vector de tipo_elementos que podrá
contener largo cantidad de elementos, y cada uno de estos elemento podrá contener un valor de
tipo tipo_elemento.
Por ejemplo:
double valores[128];
En este ejemplo declaramos un vector de 128 elementos del tipo double, los índices de los
elementos irían entre 0 (para el primer elemento y 127 para el último).De la misma forma que con las otras declaraciones de variables que hemos visto se le puede
asignar un valor iniciar a los elementos.
O también se pueden declarar:
tipo_elemento nombre[largo]={valor_0, valor_1, valor_2};

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 31/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
40
En este caso estamos asignándole valores a los primeros 3 elementos del vector nombre. Notar
que largo debe ser mayor o igual a la cantidad de valores que le estamos asignando al vector, en
el caso de ser la misma cantidad no aporta información, por lo que el lenguaje nos permite
escribir:
tipo_elemento nombre[]={valor_0, valor_1, valor_2};
Que declarará nombre como el vector de largo 3.
Para acceder a un elemento accederemos a través de su posición.
Es decir:
tipo_elemento elemento[largo];...elemento[2] = valor_2;
Asumiendo que tenemos el vector anterior definido estaríamos
guardando valor_2 en elemento[2].
5.2. OPERACIONES CON VECTORES.Un vector, como ya se ha mencionado, es una secuencia ordenada de elementos como:
x[1], x[2],………….., x[n];
El límite inferior no tiene por qué empezar en uno. El vector L.
L[0], L[1], L[2], L[3], L[4], L[5];
Contiene seis elementos, en el que el primer elemento comienza en cero. El vector P, cuyo rango
es 7 y sus límites inferior y superior son -3 y 3, es:
P[-3, P[-2], P[-1], P[0], P[1], P[2], P[3];
Las operaciones que se pueden realizar con vectores durante el proceso de resolución de un
problema son:
Asignación
Lectura / Escritura
Recorrido (Acceso secuencial)
Actualizar (Añadir, borrar, insertar)
Ordenación
Busqueda.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 32/135

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 33/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
42
v[i]=1+rand()%(al-1);
}
cout<<endl;
mostrar();
}
void modificar_posicion()
{
int c,d;
if (v[0]==-1)
{
cout<<"Vector no creado"<<endl;}
else
{
cout<<"Que posicion desea modificar???"<<endl;
cin>>c;
if (c>n)
{
cout<<"Posicion Inexistente"<<endl;
cout<<"Introduzca la posicion del vector de "<<n<<" posiones"<<endl;
cin>>c;
}
cout<<"Introduzca el nuevo valor de la posicion"<<endl;
cin>>d;
}
cout<<"Vector Anterior"<<endl;
mostrar();
v[c-1]=d;
cout<<"Vector Modificado"<<endl;
mostrar();
}
void modificar_global()
{
for(int i=0;i<n;i++)
{
cout<<"Ingrese valores nuevos para la posicion "<<i+1<<endl;
cin>>v[i];
}
cout<<endl;
mostrar();
}
void eliminar_posicion()
{
int e;
if (v[0]==-1)
{
cout<<"Vector no creado"<<endl;
}
else
{
cout<<"Inserte posicion del vector que desea eliminar"<<endl;
cin>>e;
if (e>n)
{cout<<"Posicion Inexistente"<<endl;
cout<<"Introduzca la posicion del vector de "<<n<<" posiones"<<endl;
cin>>e;
}
}
v[e-1]=0;
cout<<endl;
mostrar();
}
void eliminar_global()
{
if (v[0]==-1)
{
cout<<"No existe vector para eliminar, debe crear Vector"<<'\n'<<endl;
system("pause");
system("cls");
}
else
{
cout<<"Usted Elimino Todo el Vector debera volver a crear otro"<<endl<<'\n';
system("pause");
system("cls");
memset(v,-1,sizeof(v));
}
}
void ordenar_ascendente()
{
cout<<"Vector Anterior"<<endl;
for(int i=0;i<n;i++)
{
cout<<v[i]<<'\t';
}
cout<<endl<<'\n';
cout<<"Vector Ordenado Ascendentemente"<<endl;
for (int i=0;i<6;i++)
{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 34/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
43
sort(v,v+n);
}
mostrar();
}
void ordenar_descendente()
{
cout<<"Vector Anterior"<<endl;
for(int i=0;i<n;i++)
{
cout<<v[i]<<'\t';
}cout<<endl<<'\n';
cout<<"Vector Ordenado Descendentemente"<<endl;
for (int i=6;i>=0;i--)
{
sort(v,v+n,greater<int>());
cout<<endl;
}
mostrar();
}
int main()
{
int op;
memset(v,-1,sizeof(v));
while (op!=8)
{
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- CREAR "<<endl;
cout<<'\t'<<" 2.- INSERTAR "<<endl;
cout<<'\t'<<" 3.- MODIFICAR "<<endl;
cout<<'\t'<<" 4.- ELIMINAR "<<endl;
cout<<'\t'<<" 5.- ORDENAR "<<endl;
cout<<'\t'<<" 6.- MOSTRAR "<<endl;
cout<<'\t'<<" 7.- SALIR "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>op;
system("cls");
if (op!=8)
{
switch(op)
{
case 1: crear(); break;
case 2: int b;
if (v[0]==-1)
{
cout<<"El vector no existe"<<endl;
system("pause");
system("cls");
}
else
if (v[0]>0)
{
cout<<"Vetor Lleno"<<endl;system("pause");
system("cls");
}
else
{
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES - INSERTAR "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- POR POSICION "<<endl;
cout<<'\t'<<" 2.- GLOBAL "<<endl;
cout<<'\t'<<" 3.- VOLVER "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>b;
system("cls");
switch(b)
{
case 1: insertar_posicion(); break;
case 2: int h;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES - GLOBAL "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- INSERTAR MANUALMENTE "<<endl;
cout<<'\t'<<" 2.- INSERTAR ALEATORIAMENTE "<<endl;
cout<<'\t'<<" 3.- VOLVER "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>h;
system("cls");
switch(h)
{
case 1: insertar_manual(); break;
case 2: insertar_aleatorio(); break;
case 3: break;
}
break;
case 3: break;
}
}
break;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 35/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
44
case 3: int q;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES - MODIFICAR "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- POR POSICION "<<endl;
cout<<'\t'<<" 2.- GLOBAL "<<endl;
cout<<'\t'<<" 3.- VOLVER "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>q;
system("cls");
switch(q)
{case 1: modificar_posicion(); break;
case 2: modificar_global(); break;
case 3: break;
}
break;
case 4: int o;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES - ELIMINAR "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- POR POSICION "<<endl;
cout<<'\t'<<" 2.- GLOBAL "<<endl;
cout<<'\t'<<" 3.- VOLVER "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>o;
system("cls");
switch(o)
{
case 1: eliminar_posicion(); break;
case 2: eliminar_global(); break;
case 3: break;
}
break;
case 5: int l;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" MENU VECTORES - ORDENAR "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" 1.- ASCENDENTE "<<endl;
cout<<'\t'<<" 2.- DESCENDENTE "<<endl;
cout<<'\t'<<" 3.- VOLVER "<<endl;
cout<<'\t'<<"========================================="<<endl;
cout<<'\t'<<" OPCION: ";cin>>l;
system("cls");
switch(l)
{
case 1: ordenar_ascendente(); break;
case 2: ordenar_descendente(); break;
case 3: break;
}
break;
case 6: mostrar(); break;
case 7: salir(); return 0;
}
}
}
return 0;
}
NOTA:Para el diseño del menú se utilizo la nueva librería de C++ llamada STL, la cual facilita al
programador el ahorro de memoria en el código.
ALGUNAS DIFERENCIAS ENTRE LA LIBRERÍA STL Y LA CLASICA DE C++:
Método de Ordenación con la librería de C++ Clásica:
int aux;
for (int c2=0;c2<n;c2++
{
if(lista[c2]>lista[c2+1])
{
aux=lista[c2];
lista[c2]=lista[c2+1];
lista[c2+1]=aux;
}
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 36/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
45
Método de Ordenación con la librería STL:
int v[10];
for(int i=0;i<10;i++)
{
sort(v,v+10);
}
Llenado de un vector con la librería de C++ Clásica:
int v[10];
for(int i=0;i<10;i++)
{
v[i]=0;
cout<<v[i]<<” ”;
}
Llenado de un vector con la librería STL:
int v[10];
memset(v,0,sizeof(v));
El valor de “0” puede ser remplazado por el valor que se desea llenar en el vector.
5.3. ARRAYS DE VARIAS DIMENCIONES (MATRICES)Los vectores examinados hasta ahora se denominan arrays unidimensionales y en ellos cada
elemento se define o referencia por un índice o subíndice. Estos vectores son elementos de datos
escritos en una secuencia. Sin embargo, existen grupos de datos que son representados mejor en
forma de tabla o matriz con dos o más subíndices. Ejemplos típicos de tablas o matrices son:Tabla de distancias kilométricas entre ciudades, cuadros horarios de trenes o aviones, informes
de ventas periódicas (mes/unidades vendidas o bien mes/ ventas totales), etc. Se pueden definir
tablas o matrices como arrays multidimensionales, cuyos elementos se pueden referenciar por
dos, tres o más subíndices.
5.4. ARRAYS BIDIMENSIONALES (TABLAS/MATRICES)
Una matriz es un vector de vectores o un también llamado “array bidimensional”. La manera de
declarar una matriz en C++ es similar a un vector:
tipo_elemento nombre[filas][columnas];
Las matrices también pueden ser de distintos tipos de datos como: int, char, float, double,etc.
Las matrices en C++ se almacenan al igual que los vectores en posiciones consecutivas de
memoria. Usualmente uno se hace la idea que una matriz es como un tablero. Pero internamente
el manejo es como su definición lo indica, un vector de vectores, es decir, los vectores están uno
detrás de los otros juntos.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 37/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
46
La forma de acceder a los elementos de la matriz es utilizando su nombre e indicando los dos
subíndices que van en los corchetes. Si Coloco int matriz[2][3]=10; estoy asignando al cuarto
elemento de la tercera fila el valor 10. No olvidar que tanto filas como columnas se enumeran a
partir de 0.
Ejemplo:
5.5 PUNTEROSNo, no salgas corriendo todavía. Aunque vamos a empezar con un tema que suele asustar a los
estudiantes de C++, no es algo tan terrible como se cuenta. Como se suele decir de los leones: noson tan fieros como los pintan.
Los punteros proporcionan la mayor parte de la potencia al C++, y marcan la principal diferencia
con otros lenguajes de programación.
Una buena comprensión y un buen dominio de los punteros pondrá en tus manos una
herramienta de gran potencia. Un conocimiento mediocre o incompleto te impedirá desarrollar
programas eficaces.
Por eso le dedicaremos mucha atención y mucho espacio a los punteros. Es muy importante
comprender bien cómo funcionan y cómo se usan.
Creo que todos sabemos lo que es un puntero, fuera del ámbito de la programación. Usamos
punteros para señalar cosas sobre las que queremos llamar la atención, como marcar puntos en
un mapa o detalles en una presentación en pantalla. A menudo, usamos el dedo índice para
señalar direcciones o lugares sobre los que estamos hablando o explicando algo. Cuando un dedo
no es suficiente, podemos usar punteros. Antiguamente esos punteros eran una vara de madera,
pero actualmente se usan punteros laser, aunque la idea es la misma. Un puntero también es el
símbolo que representa la posición del ratón en una pantalla gráfica. Estos punteros también se
usan para señalar objetos: enlaces, opciones de menú, botones, etc. Un puntero sirve, pues, para
apuntar a los objetos a los que nos estamos refiriendo.
Pues en C++ un puntero es exactamente lo mismo. Probablemente habrás notado que a lo largo
del curso nos hemos referido a variables, constantes, etc como objetos. Esto ha sido intencionado
por el siguiente motivo:
C++ está diseñado para la programación orientada a objetos (POO), y en ese paradigma, todas las
entidades que podemos manejar son objetos.
Los punteros en C++ sirven para señalar objetos, y también para manipularlos.
0,0 0,1 0,2 0,3
1,0 1,1 1,2 1,32,0 2,1 2,2 2,33,0 3,1 3,2 3,3
FILA
COLUMNA

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 38/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
47
Para entender qué es un puntero veremos primero cómo se almacenan los datos en un
ordenador.
La memoria de un ordenador está compuesta por unidades básicas llamadas bits. Cada bit sólo
puede tomar dos valores, normalmente denominados alto y bajo, ó 1 y 0. Pero trabajar con bits
no es práctico, y por eso se agrupan.
Cada grupo de 8 bits forma un byte u octeto. En realidad el microprocesador, y por lo tanto
nuestro programa, sólo puede manejar directamente bytes o grupos de dos o cuatro bytes. Para
acceder a los bits hay que acceder antes a los bytes.
Cada byte de la memoria de un ordenador tiene una dirección, llamada dirección de memoria.
Los microprocesadores trabajan con una unidad básica de información, a la que se denomina
palabra (en inglés word ). Dependiendo del tipo de microprocesador una palabra puede estar
compuesta por uno, dos, cuatro, ocho o dieciséis bytes. Hablaremos en estos casos de
plataformas de 8, 16, 32, 64 ó 128 bits. Se habla indistintamente de direcciones de memoria,
aunque las palabras sean de distinta longitud. Cada dirección de memoria contiene siempre
un byte. Lo que sucederá cuando las palabras sean, por ejemplo, de 32 bits es que accederemos a
posiciones de memoria que serán múltiplos de 4.
Por otra parte, la mayor parte de los objetos que usamos en nuestros programas no caben en una
dirección de memoria. La solución utilizada para manejar objetos que ocupen más de un byte es
usar posiciones de memoria correlativas. De este modo, la dirección de un objeto es la dirección
de memoria de la primera posición que contiene ese objeto.
Dicho de otro modo, si para almacenar un objeto se precisan cuatro bytes, y la dirección de
memoria de la primera posición es n, el objeto ocupará las posiciones desde n a n+3, y la
dirección del objeto será, también, n.
Todo esto sucede en el interior de la máquina, y nos importa relativamente poco. Pero podemos
saber qué tipo de plataforma estamos usando averiguando el tamaño del tipo int, y para ello hay
que usar el operador sizeof , por ejemplo:
cout << "Plataforma de " << 8*sizeof(int) << " bits";
Ahora veamos cómo funcionan los punteros. Un puntero es un tipo especial de objeto que
contiene, ni más ni menos que, la dirección de memoria de un objeto. Por supuesto, almacenada
a partir de esa dirección de memoria puede haber cualquier clase de objeto: un char, un int,
un float, un array , una estructura, una función u otro puntero. Seremos nosotros los responsables
de decidir ese contenido, al declarar el puntero.
De hecho, podríamos decir que existen tantos tipos diferentes de punteros como tipos de objetos
puedan ser referenciados mediante punteros. Si tenemos esto en cuenta, los punteros que
apunten a tipos de objetos distintos, serán tipos diferentes. Por ejemplo, no podemos asignar a
un puntero a char el valor de un puntero a int.
Intentemos ver con mayor claridad el funcionamiento de los punteros. Podemos considerar la
memoria del ordenador como un gran array , de modo que podemos acceder a cada celda de
memoria a través de un índice. Podemos considerar que la primera posición del array es la 0 celda
[0].

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 39/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
48
Si usamos una variable para almacenar el índice, por ejemplo:
indice=0, entonces celda[0] == celda[indice].
Finalmente, si prescindimos de la notación de los arrays, podemos ver que el índice se comporta
exactamente igual que un puntero.
El puntero indice podría tener por ejemplo, el valor 3, en ese caso, el valor apuntado
por indice tendría el valor 'val3'.
Las celdas de memoria tienen una existencia física, es decir son algo real y existirán siempre,
independientemente del valor del puntero. Existirán incluso si no existe el puntero.
De forma recíproca, la existencia o no existencia de un puntero no implica la existencia o la
inexistencia del objeto. De la misma forma que el hecho de no señalar a un árbol, no implica la
inexistencia del árbol. Algo más oscuro es si tenemos un puntero para árboles, que no esté
señalando a un árbol. Un puntero de ese tipo no tendría uso si estamos en medio del mar: tener
ese puntero no crea árboles de forma automática cuando señalemos con él. Es un puntero, no
una varita mágica.
Del mismo modo, el valor de la dirección que contiene un puntero no implica que esa dirección
sea válida, en el sentido de que no tiene por qué contener la dirección de un objeto del tipo
especificado por el puntero.
Supongamos que tenemos un mapa en la pared, y supongamos también que existen diferentes
tipos de punteros láser para señalar diferentes tipos de puntos en el mapa (ya sé que esto suena
raro, pero usemos la imaginación). Creamos un puntero para señalar ciudades. Nada más crearlo
(o encenderlo), el puntero señalará a cualquier sitio, podría señalar incluso a un punto fuera del
mapa. En general, daremos por sentado que una vez creado, el puntero no tiene por qué apuntar
a una ciudad, y aunque apunte al mapa, podría estar señalando a un mar o a un río.
Con los punteros en C++ ocurre lo mismo. El valor inicial del puntero, cuando se declara, podría
estar fuera del mapa, es decir, contener direcciones de memoria que no existen. Pero, incluso
señalando a un punto de la memoria, es muy probable que no señale a un objeto del tipo
adecuado. Debemos considerar esto como el caso más probable, y no usar jamás un puntero que
no haya sido inicializado correctamente.
Dentro del array de celdas de memoria existirán zonas que contendrán programas y datos, tanto
del usuario como del propio sistema operativo o de otros programas, el sistema operativo se
encarga de gestionar esa memoria, prohibiendo o protegiendo determinadas zonas.
Pero el propio puntero, como objeto que es, también se almacenará en memoria, y por lo tanto,
también tendrá una dirección de memoria. Cuando declaramos un puntero estaremos reservando
la memoria necesaria para almacenarlo, aunque, como pasa con el resto del los objetos, el
contenido de esa memoria contendrá basura.
En principio, debemos asignar a un puntero, o bien la dirección de un objeto existente, o bien la
de uno creado explícitamente durante la ejecución del programa o un valor conocido que indique
que no señala a ningún objeto, es decir el valor 0. El sistema operativo, cuanto más avanzado es,
mejor suele controlar la memoria. Ese control se traduce en impedir el acceso a determinadas
direcciones reservadas por el sistema.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 40/135

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 41/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
50
Otro detalle importante es que, aunque las tres formas de situar el asterisco en la declaración
son equivalentes, algunas de ellas pueden inducirnos a error, sobre todo si se declaran varios
objetos en la misma línea:
int* x, y;
En este caso, x es un puntero a int, pero y no es más que un objeto de tipo int. Colocar el
asterisco junto al tipo puede que indique más claramente que estamos declarando un
puntero, pero hay que tener en cuenta que sólo afecta al primer objeto declarado, si
quisiéramos declarar ambos objetos como punteros aint tendremos que hacerlo de otro
modo:
int* x, *y;
// O:
int *x, *y;
// O:int* x;
int* y;
5.5.2. OBTENER PUNTEROS A OBJETOS
Los punteros apuntan a objetos, por lo tanto, lo primero que tenemos que saber hacer con
nuestros punteros es asignarles direcciones de memoria válidas de objetos.
Para averiguar la dirección de memoria de cualquier objeto usaremos el operador de
dirección (&), que leeremos como "dirección de".
Por supuesto, los tipos tienen que ser "compatibles", no podemos almacenar la dirección de
un objeto de tipo char en un puntero de tipo int.
Por ejemplo:
int A;
int *pA;
pA = &A;
Según este ejemplo, pA es un puntero a int que apunta a la dirección donde se almacena el
valor del entero A.
5.5.3. OBJETO APUNTADO POR UN PUNTERO
La operación contraria es obtener el objeto referenciado por un puntero, con el fin demanipularlo, ya sea modificando su valor u obteniendo el valor actual.
Para manipular el objeto apuntado por un puntero usaremos el operador de indirección, que
es un asterisco (*).
En C++ es muy habitual que el mismo símbolo se use para varias cosas diferentes, este es el
caso del asterisco, que se usa como operador de multiplicación, para la declaración de
punteros y, como vemos ahora, como operador de indirección.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 42/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
51
Como operador de indirección sólo está permitido usarlo con punteros, y podemos leerlo
como "objeto apuntado por".
Por ejemplo:
int *pEntero;int x = 10;
int y;
pEntero = &y;
*pEntero = x; // (1)
En (1) asignamos al objeto apuntado por pEntero en valor del objeto x . Como pEntero apunta
al objeto y , esta sentencia equivale (según la secuencia del programa), a asignar a y el valor
de x .
5.5.4. DIFERENCIA ENTRE PUNTEROS Y OTROS OBJETOS
Debemos tener muy claro, en el ejemplo anterior, que pEntero es un objeto del tipo "puntero
a int", pero que *pEntero NO es un objeto de tipo int, sino una expresión.
¿Por qué decimos esto?
Pues porque, como pasa con todos los objetos en C++, cuando se declaran sólo se reserva
espacio para almacenarlos, pero no se asigna ningún valor inicial, (recuerda que nuestro
puntero para árboles no crea árbol cada vez que señalemos con él). El contenido del objeto
permanecerá sin cambios, de modo que el valor inicial del puntero será aleatorio e
indeterminado. Debemos suponer que contiene una dirección no válida.
Si pEntero apunta a un objeto de tipo int, *pEntero será el contenido de ese objeto, pero no
olvides que*pEntero es un operador aplicado a un objeto de tipo "puntero a int". Es
decir, *pEntero es una expresión, no un objeto.
Declarar un puntero no creará un objeto del tipo al que apunta. Por ejemplo: int *pEntero; no
crea un objeto de tipo int en memoria. Lo que crea es un objeto que puede contener la
dirección de memoria de un entero.
Podemos decir que existe físicamente un objeto pEntero, y también que ese
objeto puede (aunque esto no es siempre cierto) contener la dirección de un objeto de
tipo int.
Como todos los objetos, los punteros también contienen "basura" cuando son declarados. Es
costumbre dar valores iniciales nulos a los punteros que no apuntan a ningún sitio concreto:
int *pEntero = 0; // También podemos asignar el valor NULL
char *pCaracter = 0;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 43/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
52
NULL es una constante,
"cstdio" o "iostream". Si
asignar a punteros nulos
6. LISTAS ABIERTAS.
6.1. DEFINICIÓN
La forma más simple de e
organizan de modo que cad
puntero del nodo siguiente
En las listas abiertas existe
es un puntero a ese primer
mediante ese único puntero
Cuando el puntero que usa
El nodo típico para construir
En el ejemplo, cada elemen
no hay límite en cuanto a la
6.2. DECLARACIONES DE TIP
Normalmente se definen va
tipos puede tener una form
tipoNodo es el tipo para dec
pNodo es el tipo para declar
Lista es el tipo para declara
misma cosa. En realidad, cu
nodo apuntado.
rcia
ESTRUCTUR
52
que está definida como cero en varios ficheros
n embargo, hay muchos textos que recomiendan
, al menos en C++.
structura dinámica es la lista abierta. En esta fo
a uno apunta al siguiente, y el último no apunta
ale NULL.
n nodo especial: el primero. Normalmente diremo
nodo y llamaremos a ese nodo la cabeza de la li
podemos acceder a toda la lista.
os para acceder a la lista vale NULL, diremos que l
listas tiene esta forma:
struct nodo \{
int dato;
struct nodo *siguiente;
};
o de la lista sólo contiene un dato de tipo entero,
complejidad de los datos a almacenar.
OS PARA MANEJAR LISTAS EN C++
rios tipos que facilitan el manejo de las listas, en
parecida a esta:
typedef struct _nodo \{
int dato;
struct _nodo *siguiente;
} tipoNodo;
typedef tipoNodo *pNodo;
typedef tipoNodo *Lista;
larar nodos, evidentemente.
ar punteros a un nodo.
r listas, como puede verse, un puntero a un nodo
alquier puntero a un nodo es una lista, cuyo pri
Lista enlazada
DE DATOS
52
e cabecera, como
sar el valor 0 para
rma los nodos se
nada, es decir, el
s que nuestra lista
ta. Eso es porque
lista está vacía.
pero en la práctica
, la declaración de
y una lista son la
er elemento es el

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 44/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
53
Es muy importante que nue
ya que si no existe ninguna
podremos liberar el espacio
6.3. OPERACIONES BÁSICAS
Con las listas tendremos un Añadir o ins
Buscar o loc
Borrar elem
Moverse a t
Cada una de estas operaci
insertar un nodo en una list
intermedia.
6.4. INSERTAR ELEMENTOS
Veremos primero los casos
inserción de elementos en u
6.4.1. INSERTAR UN ELEEste es, evidentemente,
y, por supuesto un punt
El proceso es muy simpl
1. nodo->siguiente
2. Lista apunte a n
6.4.2. INSERTAR UN ELE
Podemos considerar el
que en el caso anteri
considerar una lista vací
De nuevo partiremos de
este caso no vacía:
rcia
ESTRUCTUR
53
stro programa nunca pierda el valor del puntero al
copia de ese valor, y se pierde, será imposible ac
de memoria que ocupa.
CON LISTAS
pequeño repertorio de operaciones básicas que sertar elementos.
lizar elementos.
ntos.
avés de una lista, anterior, siguiente, primero.
nes tendrá varios casos especiales, por ejemplo,
vacía, o al principio de una lista no vacía, o la final
EN UNA LISTA ABIERTA
sencillos y finalmente construiremos un algoritm
na lista.
MENTO EN UNA LISTA VACÍA el caso más sencillo. Partiremos de que ya tenemo
ro que apunte a él, además el puntero a la lista val
Lista vacía
, bastará con que:
apunte a NULL.
do.
MENTO EN LA PRIMERA POSICIÓN DE UNA LISTA
Insertar al principio
aso anterior como un caso particular de éste, la
r la lista es una lista vacía, pero siempre pod
a como una lista.
un nodo a insertar, con un puntero que apunte a é
DE DATOS
53
primer elemento,
eder al nodo y no
ueden realizar:
no será lo mismo
, o en una posición
genérico para la
el nodo a insertar
drá NULL:
nica diferencia es
emos, y debemos
l, y de una lista, en

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 45/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
54
El proceso sigue siendo
1. Hacemos que n
2. Hacemos que Li
6.4.3. INSERTAR UN ELE
Este es otro caso especi
El proceso en este caso
1. Necesitamos un
conseguirlo es e
siguiente el valo
2. Hacer que nodo
3. Hacer que ultim
6.4.4. INSERTAR UN ELE
De nuevo podemos co
nodo "anterior" será aq
Suponemos que ya disp
al nodo a continuación d
rcia
ESTRUCTUR
54
Insertado al principio
uy sencillo:
do->siguiente apunte a Lista.
ta apunte a nodo.
MENTO EN LA ÚLTIMA POSICIÓN DE UNA LISTA
l. Para este caso partiremos de una lista no vacía:
Insertar al final
ampoco es excesivamente complicado:
puntero que señale al último elemento de la li
mpezar por el primero y avanzar hasta que el nod
r NULL.
->siguiente sea NULL.
o->siguiente sea nodo.
Insertado al final
MENTO A CONTINUACIÓN DE UN NODO CUALQUI
siderar el caso anterior como un caso particular
el a continuación del cual insertaremos el nuevo n
Insertar dentro
nemos del nuevo nodo a insertar, apuntado por n
el que lo insertaremos.
DE DATOS
54
ta. La manera de
o que tenga como
RA DE UNA LISTA
de este. Ahora el
do:
odo, y un puntero

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 46/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
55
El proceso a seguir será:
1. Hacer que nodo
2. Hacer que anter
6.5. LOCALIZAR ELEMENTOS
Muy a menudo necesitarem
concreto. Las listas abiertas
siguiente, pero no se puede
cualquiera si no se empieza d
Para recorrer una lista proc
como índice:1. Asignamos al puntero ín
2. Abriremos un bucle que
3. Dentro del bucle asignar
Por ejemplo, para mostrar t
bucle en C++:
typed
in
st
} tip
typed
typed
...
pNodo
...
indic
while(
pr
in
}
...
Supongamos que sólo quere
que 100, podemos sustituir e
rcia
ESTRUCTUR
55
->siguiente señale a anterior->siguiente.
ior->siguiente señale a nodo.
Insertado dentro
EN UNA LISTA ABIERTA
os recorrer una lista, ya sea buscando un valor pa
sólo pueden recorrerse en un sentido, ya que ca
obtener, por ejemplo, un puntero al nodo anteri
esde el principio.
ederemos siempre del mismo modo, usaremos u
dice el valor de Lista.
al menos debe tener una condición, que el índice n
emos al índice el valor del nodo siguiente al índice
dos los valores de los nodos de una lista, podemo
f struct _nodo \{
dato;
uct _nodo *siguiente;
Nodo;
f tipoNodo *pNodo;
f tipoNodo *Lista;
indice;
= Lista;
indice) \{
ntf("%d\n", indice->dato);
ice = indice->siguiente;
mos mostrar los valores hasta que encontremos u
l bucle por:
...
ndice = Lista;
hile(indice && indice->dato <= 100) \{
printf("%d\n", indice->dato);
indice = indice->siguiente;
DE DATOS
55
rticular o un nodo
a nodo apunta al
or desde un nodo
n puntero auxiliar
o sea NULL.
actual.
s usar el siguiente
no que sea mayor

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 47/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
56
Si analizamos la condición de
valor es mayor que 100, y al
NULL, si intentamos acceder
En general eso será cierto, n
está dentro de una condició
evalúa una expresión "and",
de las expresiones resulta
evaluará si indice es NULL.
Si hubiéramos escrito la con
importante cuando se trabaj
6.6. ELIMINAR ELEMENTOS EDe nuevo podemos encontra
6.6.1. ELIMINAR EL PRI
Es el caso más simple. P
auxiliar, nodo:1. Hacemos que nodo
2. Asignamos a Lista l
3. Liberamos la memo
Si no guardamos el pun
imposible liberar la me
perderemos el puntero
Si la lista sólo tiene un n
es NULL, y después de
NULL.
De hecho, el proceso q
nodo hasta que la lista e
rcia
ESTRUCTUR
56
}
...
l bucle, tal vez encontremos un posible error: ¿Qu
cancemos el final de la lista?. Podría pensarse que
a indice->dato se producirá un error.
o puede accederse a punteros nulos. Pero en est
y forma parte de una expresión "and". Recorde
e comienza por la izquierda, y la evaluación se aba
alsa, de modo que la expresión "indice->dato
ición al revés, el programa nunca funcionaría bien
con punteros.
N UNA LISTA ABIERTA rnos con varios casos, según la posición del nodo a
ER NODO DE UNA LISTA ABIERTA
Eliminar primer nodo
artiremos de una lista con uno o más nodos, y usa
apunte al primer elemento de la lista, es decir a Lis
dirección del segundo nodo de la lista: Lista->sigui
ria asignada al primer nodo, el que queremos elimi
tero al primer nodo antes de actualizar Lista, des
oria que ocupa. Si liberamos la memoria antes
l segundo nodo.
Primer nodo eliminado
odo, el proceso es también válido, ya que el valor
liminar el primer nodo la lista quedará vacía, y el
ue se suele usar para borrar listas completas es
sté vacía.
DE DATOS
56
é pasaría si ningún
cuando indice sea
e caso, ese acceso
os que cuando se
ndona cuando una
= 100" nunca se
. Esto es algo muy
eliminar.
remos un puntero
ta.
ente.
nar.
ués nos resultaría
e actualizar Lista,
de Lista->siguiente
valor de Lista será
eliminar el primer

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 48/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
57
6.6.2. ELIMINAR UN NO
En todos los demás ca
Supongamos que tene
anterior al que queremo
El proceso es parecido a
1. Hacemos que nodo
2. Ahora, asignamos c
eliminar: anterior->
3. Eliminamos la mem
Si el nodo a eliminar e
pasará a ser el último, y
6.7. MOVERSE A TRAVÉS DE
Sólo hay un modo de movers
Aún así, a veces necesitarem
ahora como acceder a los má
6.7.1. PRIMER ELEMEN
El primer elemento es el
lista. Para obtener un pu
6.7.2. ELEMENTO SIGUI
Supongamos que tenem
obtener un puntero al si
>siguiente.
6.7.3. ELEMENTO ANTEYa hemos dicho que no
puntero al nodo anterio
que el nodo siguiente se
6.7.4. ÚLTIMO ELEMEN
Para obtener un punter
por ejemplo el primero,
rcia
ESTRUCTUR
57
DO CUALQUIERA DE UNA LISTA ABIERTA
sos, eliminar un nodo se puede hacer siempre
os una lista con al menos dos elementos, y u
s eliminar. Y un puntero auxiliar nodo.
Eliminar un nodo
l del caso anterior:
apunte al nodo que queremos borrar.
omo nodo siguiente del nodo anterior, el siguient
siguiente = nodo->siguiente.
oria asociada al nodo que queremos eliminar.
Nodo eliminado
el último, es procedimiento es igualmente válid
anterior->siguiente valdrá NULL.
UNA LISTA ABIERTA
e a través de una lista abierta, hacia delante.
s acceder a determinados elementos de una lista
s corrientes: el primero, el último, el siguiente y el
O DE UNA LISTA
más accesible, ya que es a ese a que apunta el pun
ntero al primer elemento bastará con copiar el pun
NTE A UNO CUALQUIERA
os un puntero nodo que señala a un elemento de u
guiente bastará con asignarle el campo "siguiente"
IOR A UNO CUALQUIERA s posible retroceder en una lista, de modo que par
a uno dado tendremos que partir del primero, e ir
a precisamente nuestro nodo.
O DE UNA LISTA
al último elemento de una lista partiremos de un
y avanzaremos hasta que su nodo siguiente sea NU
DE DATOS
57
del mismo modo.
puntero al nodo
al que queremos
o, ya que anterior
bierta. Veremos
nterior.
tero que define la
tero Lista.
na lista. Para
del nodo, nodo-
a obtener un
avanzando hasta
odo cualquiera,
LL.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 49/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
58
6.7.5. SABER SI UNA LISTA ESTÁ VACÍA
Basta con comparar el puntero Lista con NULL, si Lista vale NULL la lista está vacía.
6.8. BORRAR UNA LISTA COMPLETA
El algoritmo genérico para borrar una lista completa consiste simplemente en borrar el primer
elemento sucesivamente mientras la lista no esté vacía.
6.9. EJEMPLO DE LISTA ABIERTA ORDENADA EN C
Supongamos que queremos construir una lista para almacenar números enteros, pero de modo
que siempre esté ordenada de menor a mayor. Para hacer la prueba añadiremos los valores 20,
10, 40, 30. De este modo tendremos todos los casos posibles. Al comenzar, el primer elemento se
introducirá en una lista vacía, el segundo se insertará en la primera posición, el tercero en la
última, y el último en una posición intermedia.
Insertar un elemento en una lista vacía es equivalente a insertarlo en la primera posición. De
modo que no incluiremos una función para asignar un elemento en una lista vacía, y haremos que
la función para insertar en la primera posición nos sirva para ese caso también.
6.9.1. ALGORITMO DE INSERCIÓN
1. El primer paso es crear un nodo para el dato que vamos a insertar.
2. Si Lista es NULL, o el valor del primer elemento de la lista es mayor que el del nuevo,
insertaremos el nuevo nodo en la primera posición de la lista.
3. En caso contrario, buscaremos el lugar adecuado para la inserción, tenemos un puntero
"anterior". Lo inicializamos con el valor de Lista, y avanzaremos mientras anterior-
>siguiente no sea NULL y el dato que contiene anterior->siguiente sea menor o igual que
el dato que queremos insertar.
4. Ahora ya tenemos anterior señalando al nodo adecuado, así que insertamos el nuevo
nodo a continuación de él.
void Insertar(Lista *lista, int v) \{
pNodo nuevo, anterior;
/* Crear un nodo nuevo */
nuevo = (pNodo)malloc(sizeof(tipoNodo));
nuevo->valor = v;
/* Si la lista está vacía */
if(ListaVacia(*lista) || (*lista)->valor > v) \{
/* Añadimos la lista a continuación del nuevo nodo */
nuevo->siguiente = *lista;
/* Ahora, el comienzo de nuestra lista es en nuevo nodo */*lista = nuevo;
} else \{
/* Buscar el nodo de valor menor a v */
anterior = *lista;
/* Avanzamos hasta el último elemento o hasta que el siguiente tenga
un valor mayor que v */
while(anterior->siguiente && anterior->siguiente->valor <= v)
anterior = anterior->siguiente;
/* Insertamos el nuevo nodo después del nodo anterior */

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 50/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
59
nuevo->siguiente = anterior->siguiente;
anterior->siguiente = nuevo;
}
}
6.9.2. ALGORITMO PARA BORRAR UN ELEMENTO
Después probaremos la función para buscar y borrar, borraremos los elementos 10, 15, 45, 30
y 40, así probaremos los casos de borrar el primero, el último y un caso intermedio o dos
nodos que no existan.
Recordemos que para eliminar un nodo necesitamos disponer de un puntero al nodo
anterior.
1. Lo primero será localizar el nodo a eliminar, si es que existe. Pero sin perder el puntero al
nodo anterior. Partiremos del nodo primero, y del valor NULL para anterior. Y
avanzaremos mientras nodo no sea NULL o mientras que el valor almacenado en nodo
sea menor que el que buscamos.
2. Ahora pueden darse tres casos:
3. Que el nodo sea NULL, esto indica que todos los valores almacenados en la lista son
menores que el que buscamos y el nodo que buscamos no existe. Retornaremos sin
borrar nada.
4. Que el valor almacenado en nodo sea mayor que el que buscamos, en ese caso también
retornaremos sin borrar nada, ya que esto indica que el nodo que buscamos no existe.
5. Que el valor almacenado en el nodo sea igual al que buscamos.
6. De nuevo existen dos casos:
7. Que anterior sea NULL. Esto indicaría que el nodo que queremos borrar es el primero, así
que modificamos el valor de Lista para que apunte al nodo siguiente al que queremos
borrar.
8. Que anterior no sea NULL, el nodo no es el primero, así que asignamos a anterior-
>siguiente la dirección de nodo->siguiente.
9. Después de 7 u 8, liberamos la memoria de nodo.
void Borrar(Lista *lista, int v) \{
pNodo anterior, nodo;
nodo = *lista;
anterior = NULL;
while(nodo && nodo->valor < v) \{
anterior = nodo;nodo = nodo->siguiente;
}
if (!nodo || nodo->valor != v) return;
else \{ /* Borrar el nodo */
if (!anterior) /* Primer elemento */
*lista = nodo->siguiente;
else /* un elemento cualquiera */

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 51/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
60
anterior->siguiente = nodo->siguiente;
free(nodo);
}
}
6.9.3. CODIGO COMPLETO
#include <cstdlib>
#include <cstdio>
typedef struct _nodo \{
int valor;
struct _nodo *siguiente;
} tipoNodo;
typedef tipoNodo *pNodo;
typedef tipoNodo *Lista;
/* Funciones con listas: */
void Insertar(Lista *l, int v);
void Borrar(Lista *l, int v);
int ListaVacia(Lista l);
void BorrarLista(Lista *);
void MostrarLista(Lista l);
int main() \{
Lista lista = NULL;
pNodo p;
Insertar(&lista, 20);
Insertar(&lista, 10);
Insertar(&lista, 40);
Insertar(&lista, 30);
MostrarLista(lista);
Borrar(&lista, 10);
Borrar(&lista, 15);
Borrar(&lista, 45);
Borrar(&lista, 30);
Borrar(&lista, 40);
MostrarLista(lista);
BorrarLista(&lista);
getchar();
return 0;
}
void Insertar(Lista *lista, int v) \{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 52/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
61
pNodo nuevo, anterior;
/* Crear un nodo nuevo */
nuevo = (pNodo)malloc(sizeof(tipoNodo));
nuevo->valor = v;
/* Si la lista está vacía */if(ListaVacia(*lista) || (*lista)->valor > v) \{
/* Añadimos la lista a continuación del nuevo nodo */
nuevo->siguiente = *lista;
/* Ahora, el comienzo de nuestra lista es en nuevo nodo */
*lista = nuevo;
} else \{
/* Buscar el nodo de valor menor a v */
anterior = *lista;
/* Avanzamos hasta el último elemento o hasta que el siguiente tenga
un valor mayor que v */
while(anterior->siguiente && anterior->siguiente->valor <= v)
anterior = anterior->siguiente;
/* Insertamos el nuevo nodo después del nodo anterior */
nuevo->siguiente = anterior->siguiente;
anterior->siguiente = nuevo;
}
}
void Borrar(Lista *lista, int v) \{
pNodo anterior, nodo;
nodo = *lista;
anterior = NULL;
while(nodo && nodo->valor < v) \{
anterior = nodo;
nodo = nodo->siguiente;
}
if(!nodo || nodo->valor != v) return;
else \{ /* Borrar el nodo */
if(!anterior) /* Primer elemento */
*lista = nodo->siguiente;
else /* un elemento cualquiera */
anterior->siguiente = nodo->siguiente;
free(nodo);
}
}
int ListaVacia(Lista lista) \{
return (lista == NULL);
}
void BorrarLista(Lista *lista) \{
pNodo nodo;
while(*lista) \{
nodo = *lista;
*lista = nodo->siguiente;
free(nodo);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 53/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
62
}
}
void MostrarLista(Lista lista) \{
pNodo nodo = lista;
if(ListaVacia(lista)) printf("Lista vacía\n");else \{
while(nodo) \{
printf("%d -> ", nodo->valor);
nodo = nodo->siguiente;
}
printf("\n");
}
}
6.10. EJEMPLO DE LISTA ABIERTA EN C++ USANDO CLASES
Usando clases el programa cambia bastante, aunque los algoritmos son los mismos.
Para empezar, necesitaremos dos clases, una para nodo y otra para lista. Además la clase paranodo debe ser amiga de la clase lista, ya que ésta debe acceder a los miembros privados de nodo.
class nodo \{
public:
nodo(int v, nodo *sig = NULL) \{
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class lista;
};
typedef nodo *pnodo;
class lista \{
public:
lista() \; }
~lista();
void Insertar(int v);
void Borrar(int v);
bool ListaVacia() \; }
void Mostrar();
void Siguiente();
void Primero();
void Ultimo();
bool Actual() \; }
int ValorActual() \
private:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 54/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
63
pnodo primero;
pnodo actual;
};
Hemos hecho que la clase para lista sea algo más completa que la equivalente en C, aprovechando
las prestaciones de las clases. En concreto, hemos añadido funciones para mantener un puntero a
un elemento de la lista y para poder moverse a través de ella.
Los algoritmos para insertar y borrar elementos son los mismos que expusimos para el ejemplo C,
tan sólo cambia el modo de crear y destruir nodos.
6.11. CÓDIGO DEL EJEMPLO COMPLETO
#include <iostream>
using namespace std;
class nodo \{
public:
nodo(int v, nodo *sig = NULL)
\{
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class lista;
};
typedef nodo *pnodo;
class lista \{
public:
lista() \; }
~lista();
void Insertar(int v);
void Borrar(int v);
bool ListaVacia() \; }
void Mostrar();
void Siguiente() \
void Primero() \
void Ultimo() \
bool Actual() \; }int ValorActual() \
private:
pnodo primero;
pnodo actual;
};
lista::~lista() \{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 55/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
64
pnodo aux;
while(primero) \{
aux = primero;
primero = primero->siguiente;
delete aux;
}actual = NULL;
}
void lista::Insertar(int v) \{
pnodo anterior;
// Si la lista está vacía
if(ListaVacia() || primero->valor > v) \{
// Asignamos a lista un nuevo nodo de valor v y
// cuyo siguiente elemento es la lista actual
primero = new nodo(v, primero);
} else \{
// Buscar el nodo de valor menor a v
anterior = primero;
// Avanzamos hasta el último elemento o hasta que el siguiente tenga
// un valor mayor que v
while(anterior->siguiente && anterior->siguiente->valor <= v)
anterior = anterior->siguiente;
// Creamos un nuevo nodo después del nodo anterior, y cuyo siguiente
// es el siguiente del anterior
anterior->siguiente = new nodo(v, anterior->siguiente);
}
}
void lista::Borrar(int v) \{
pnodo anterior, nodo;
nodo = primero;
anterior = NULL;
while(nodo && nodo->valor < v) \{
anterior = nodo;
nodo = nodo->siguiente;
}
if(!nodo || nodo->valor != v) return;
else \{ // Borrar el nodo
if(!anterior) // Primer elemento
primero = nodo->siguiente;
else // un elemento cualquiera
anterior->siguiente = nodo->siguiente;
delete nodo;
}
}
void lista::Mostrar() \{
nodo *aux;
aux = primero;
while(aux) \{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 56/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
65
cout << aux->valor << "-> ";
aux = aux->siguiente;
}
cout << endl;
}
int main() \{lista Lista;
Lista.Insertar(20);
Lista.Insertar(10);
Lista.Insertar(40);
Lista.Insertar(30);
Lista.Mostrar();
cout << "Lista de elementos:" << endl;
Lista.Primero();
while(Lista.Actual()) \{
cout << Lista.ValorActual() << endl;
Lista.Siguiente();
}
Lista.Primero();
cout << "Primero: " << Lista.ValorActual() << endl;
Lista.Ultimo();
cout << "Ultimo: " << Lista.ValorActual() << endl;
Lista.Borrar(10);
Lista.Borrar(15);
Lista.Borrar(45);
Lista.Borrar(30);
Lista.Borrar(40);
Lista.Mostrar();
cin.get();
return 0;
}
7. PILAS
7.1. DEFINICIÓNUna pila es un tipo especial de lista abierta en la que sólo se pueden insertar y eliminar nodos en
uno de los extremos de la lista. Estas operaciones se conocen como "push" y "pop",
respectivamente "empujar" y "tirar". Además, las escrituras de datos siempre son inserciones de
nodos, y las lecturas siempre eliminan el nodo leído.
Estas características implican un comportamiento de lista LIFO (Last In First Out ), el último enentrar es el primero en salir.
El símil del que deriva el nombre de la estructura es una pila de platos. Sólo es posible añadir
platos en la parte superior de la pila, y sólo pueden tomarse del mismo extremo.
El nodo típico para construir pilas es el mismo que vimos en el capítulo anterior para la
construcción de listas:
struct nodo \{
int dato;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 57/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
66
struct nodo *si
};
7.2. DECLARACIONES DE TIP
Los tipos que definiremos
manejar listas, tan sólo cam
typedef stru
int dato;
struct _n
} tipoNodo;
typedef tipo
typedef tipo
tipoNodo es el tipo para dec
pNodo es el tipo para declarPila es el tipo para declarar
Es evidente, a la vista del
importante que nuestro pr
que pasa con las listas abier
Teniendo en cuenta que laslo que consideramos como
pila.
7.3. OPERACIONES BÁSICAS
Las pilas tienen un conjun
"push" y "pop":
Push: Añadir un ele
Pop: Leer y eliminar
7.4. PUSH, INSERTAR ELEMLas operaciones con pilas so
7.4.1. PUSH EN UNA PILA VPartiremos de que ya tene
además el puntero a la pila
rcia
ESTRUCTUR
66
guiente;
OS PARA MANEJAR PILAS EN C++
normalmente para manejar pilas serán casi los
iaremos algunos nombres:
ct _nodo \{
odo *siguiente;
odo *pNodo;
odo *Pila;
larar nodos, evidentemente.
ar punteros a un nodo. ilas.
Pila
ráfico, que una pila es una lista abierta. Así que
grama nunca pierda el valor del puntero al prim
as.
inserciones y borrados en una pila se hacen siempl primer elemento de la lista es en realidad el últi
CON PILAS
o de operaciones muy limitado, sólo permiten l
ento al final de la pila.
un elemento del final de la pila.
NTO n muy simples, no hay casos especiales, salvo que l
CÍA os el nodo a insertar y, por supuesto un punter
aldrá NULL:
DE DATOS
66
mismos que para
sigue siendo muy
er elemento, igual
re en un extremo, o elemento de la
s operaciones de
pila esté vacía.
que apunte a él,

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 58/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
67
El proceso es muy simple, b
1. nodo->siguiente apunte
2. Pila apunte a nodo.
7.4.2. PUSH EN UNA PILA N
Podemos considerar el caso
podemos y debemos trabaja
De nuevo partiremos de un
este caso no vacía:
El proceso sigue siendo muy
1. Hacemos que nodo->sig2. Hacemos que Pila apunt
7.5. POP, LEER Y ELIMINAR
Ahora sólo existe un caso po
Partiremos de una pila con u
rcia
ESTRUCTUR
67
Push en vacía
stará con que:
a NULL.
VACÍA
Push en pila no vacía
anterior como un caso particular de éste, la únic
r con una pila vacía como con una pila normal.
nodo a insertar, con un puntero que apunte a él
Resultado
sencillo:
uiente apunte a Pila. e a nodo.
N ELEMENTO
Pop
sible, ya que sólo podemos leer desde un extremo
no o más nodos, y usaremos un puntero auxiliar, n
Resultado
DE DATOS
67
diferencia es que
, y de una pila, en
de la pila.
odo:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 59/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
68
1. Hacemos que nodo apunte al primer elemento de la pila, es decir a Pila.
2. Asignamos a Pila la dirección del segundo nodo de la pila: Pila->siguiente.
3. Guardamos el contenido del nodo para devolverlo como retorno, recuerda que la operación
pop equivale a leer y borrar.
4. Liberamos la memoria asignada al primer nodo, el que queremos eliminar.
Si la pila sólo tiene un nodo, el proceso sigue siendo válido, ya que el valor de Pila->siguiente es
NULL, y después de eliminar el último nodo la pila quedará vacía, y el valor de Pila será NULL.
7.6 EJEMPLO DE PILA EN C++ USANDO CLASES
Al igual que pasaba con las listas, usando clases el programa cambia bastante. Las clases para
pilas son versiones simplificadas de las mismas clases que usamos para listas.
Para empezar, necesitaremos dos clases, una para nodo y otra para pila. Además la clase para
nodo debe ser amiga de la clase pila, ya que ésta debe acceder a los miembros privados de nodo.
class nodo \{
public:
nodo(int v, nodo *sig = NULL) \{
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class pila;
};
typedef nodo *pnodo;
class pila \{
public:
pila() : ultimo(NULL) \{}
~pila();
void Push(int v);int Pop();
private:
pnodo ultimo;
};

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 60/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
69
7.6.1. CÓDIGO DEL EJEMPLO COMPLETO
#include <iostream>
using namespace std;
class nodo \{
public:nodo(int v, nodo *sig = NULL) \{
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class pila;
};
typedef nodo *pnodo;
class pila \{
public:
pila() : ultimo(NULL) \{}
~pila();
void Push(int v);
int Pop();
private:
pnodo ultimo;
};
pila::~pila() \{
while(ultimo) Pop();
}
void pila::Push(int v) \{
pnodo nuevo;
/* Crear un nodo nuevo */
nuevo = new nodo(v, ultimo);
/* Ahora, el comienzo de nuestra pila es en nuevo nodo */
ultimo = nuevo;
}
int pila::Pop() \{
pnodo nodo; /* variable auxiliar para manipular nodo */
int v; /* variable auxiliar para retorno */
if(!ultimo) return 0; /* Si no hay nodos en la pila retornamos 0 */
/* Nodo apunta al primer elemento de la pila */
nodo = ultimo;
/* Asignamos a pila toda la pila menos el primer elemento */

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 61/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
70
ultimo = nodo->siguiente;
/* Guardamos el valor de retorno */
v = nodo->valor;
/* Borrar el nodo */
delete nodo;
return v;
}
int main() \{
pila Pila;
Pila.Push(20);
cout << "Push(20)" << endl;
Pila.Push(10);
cout << "Push(10)" << endl;
cout << "Pop() = " << Pila.Pop() << endl;
Pila.Push(40);
cout << "Push(40)" << endl;
Pila.Push(30);
cout << "Push(30)" << endl;
cout << "Pop() = " << Pila.Pop() << endl;
cout << "Pop() = " << Pila.Pop() << endl;
Pila.Push(90);
cout << "Push(90)" << endl;
cout << "Pop() = " << Pila.Pop() << endl;
cout << "Pop() = " << Pila.Pop() << endl;
cin.get();
return 0;
}
7.7 EJEMPLO DE PILA EN C++ USANDO PLANTILLAS
Veremos ahora un ejemplo sencillo usando plantillas. Ya que la estructura para pilas es más
sencilla que para listas abiertas, nuestro ejemplo también será más simple.
Seguimos necesitando dos clases, una para nodo y otra para pila. Pero ahora podremos usar esas
clases para construir listas de cualquier tipo de datos.
7.7.1. CÓDIGO DEL EJEMPLO COMPLETOVeremos primero las declaraciones de las dos clases que necesitamos:
template<class TIPO> class pila;
template<class TIPO>
class nodo \{
public:nodo(TIPO v, nodo<TIPO> *sig = NULL) \{
valor = v;
siguiente = sig;
}
private:
TIPO valor;
nodo<TIPO> *siguiente;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 62/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
71
friend class pila<TIPO>;
};
template<class TIPO>
class pila \{
public:
pila() : ultimo(NULL) \{}~pila();
void Push(TIPO v);
TIPO Pop();
private:
nodo<TIPO> *ultimo;
};
La implementación de las funciones es la misma que para el ejemplo de la página anterior.
template<class TIPO>
pila<TIPO>::~pila() \{
while(ultimo) Pop();
}
template<class TIPO>
void pila<TIPO>::Push(TIPO v) \{
nodo<TIPO> *nuevo;
/* Crear un nodo nuevo */
nuevo = new nodo<TIPO>(v, ultimo);
/* Ahora, el comienzo de nuestra pila es en nuevo nodo */
ultimo = nuevo;
}
template<class TIPO>
TIPO pila<TIPO>::Pop() \{
nodo<TIPO> *Nodo; /* variable auxiliar para manipular nodo */
TIPO v; /* variable auxiliar para retorno */
if(!ultimo) return 0; /* Si no hay nodos en la pila retornamos 0 */
/* Nodo apunta al primer elemento de la pila */
Nodo = ultimo;
/* Asignamos a pila toda la pila menos el primer elemento */
ultimo = Nodo->siguiente;
/* Guardamos el valor de retorno */
v = Nodo->valor;
/* Borrar el nodo */
delete Nodo;
return v;
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 63/135

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 64/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
73
nodo<TIPO> *Nodo; /* variable auxiliar para manipular nodo */
TIPO v; /* variable auxiliar para retorno */
if(!ultimo) return 0; /* Si no hay nodos en la pila retornamos 0 */
/* Nodo apunta al primer elemento de la pila */
Nodo = ultimo;
/* Asignamos a pila toda la pila menos el primer elemento */ultimo = Nodo->siguiente;
/* Guardamos el valor de retorno */
v = Nodo->valor;
/* Borrar el nodo */
delete Nodo;
return v;
}
int main() \{
pila<int> iPila;
pila<float> fPila;
pila<double> dPila;
pila<char> cPila;
pila<Cadena> sPila;
// Prueba con <int>
iPila.Push(20);
iPila.Push(10);
cout << iPila.Pop() << ",";
iPila.Push(40);
iPila.Push(30);
cout << iPila.Pop() << ",";
cout << iPila.Pop() << ",";
iPila.Push(90);
cout << iPila.Pop() << ",";
cout << iPila.Pop() << endl;
// Prueba con <float>
fPila.Push(20.01);
fPila.Push(10.02);
cout << fPila.Pop() << ",";
fPila.Push(40.03);
fPila.Push(30.04);
cout << fPila.Pop() << ",";
cout << fPila.Pop() << ",";
fPila.Push(90.05);
cout << fPila.Pop() << ",";
cout << fPila.Pop() << endl;
// Prueba con <double>
dPila.Push(0.0020);
dPila.Push(0.0010);
cout << dPila.Pop() << ",";
dPila.Push(0.0040);
dPila.Push(0.0030);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 65/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
74
cout << dPila.Pop() << ",";
cout << dPila.Pop() << ",";
dPila.Push(0.0090);
cout << dPila.Pop() << ",";
cout << dPila.Pop() << endl;
// Prueba con <Cadena>
cPila.Push('x');
cPila.Push('y');
cout << cPila.Pop() << ",";
cPila.Push('a');
cPila.Push('b');
cout << cPila.Pop() << ",";
cout << cPila.Pop() << ",";
cPila.Push('m');
cout << cPila.Pop() << ",";
cout << cPila.Pop() << endl;
// Prueba con <char *>
sPila.Push("Hola");
sPila.Push("somos");
cout << sPila.Pop() << ",";
sPila.Push("programadores");
sPila.Push("buenos");
cout << sPila.Pop() << ",";
cout << sPila.Pop() << ",";
sPila.Push("!!!!");
cout << sPila.Pop() << ",";
cout << sPila.Pop() << endl;
cin.get();
return 0;
}
8. COLAS
8.1. DEFINICIÓN
Una cola es un tipo especial de lista abierta en la que sólo se pueden insertar nodos en uno de los
extremos de la lista y sólo se pueden eliminar nodos en el otro. Además, como sucede con las
pilas, las escrituras de datos siempre son inserciones de nodos, y las lecturas siempre eliminan el
nodo leído.Este tipo de lista es conocido como lista FIFO (First In First Out), el primero en entrar es el
primero en salir.
El símil cotidiano es una cola para comprar, por ejemplo, las entradas del cine. Los nuevos
compradores sólo pueden colocarse al final de la cola, y sólo el primero de la cola puede comprar
la entrada.
El nodo típico para construir pilas es el mismo que vimos en los capítulos anteriores para la
construcción de listas y pilas:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 66/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
75
struct nodo
int dato;
struct no
};
8.2. DECLARACIONES DE TIP
Los tipos que definiremos
manejar listas y pilas, tan só
typedef struct _nodo
int dato;
struct _nodo *sigu
} tipoNodo;
typedef tipoNodo *pNo
typedef tipoNodo *Col
tipoNodo es el tipo para dec
pNodo es el tipo para declar
Cola es el tipo para declarar
Es evidente, a la vista del
importante que nuestro pr
que pasa con las listas a
deberemos mantener un p
insertemos nuevos nodos.
Teniendo en cuenta que la
distintos, lo más fácil será i
siguiente, y leerlos desde el
cola.
8.3. OPERACIONES BÁSICAS
De nuevo nos encontramos
sólo permiten añadir y leer
Añadir: Inserta
Leer: Lee y elimi
rcia
ESTRUCTUR
75
\{
do *siguiente;
OS PARA MANEJAR COLAS EN C++
normalmente para manejar colas serán casi los
lo cambiaremos algunos nombres:
\{
iente;
do;
a;
larar nodos, evidentemente.
ar punteros a un nodo.
colas.
Cola
ráfico, que una cola es una lista abierta. Así que
grama nunca pierda el valor del puntero al prim
iertas. Además, debido al funcionamiento de l
ntero para el último elemento de la cola, que se
s lecturas y escrituras en una cola se hacen sie
sertar nodos por el final, a continuación del nodo
principio, hay que recordar que leer un nodo impli
CON COLAS
ante una estructura con muy pocas operaciones dis
lementos:
n elemento al final de la cola.
na un elemento del principio de la cola.
DE DATOS
75
mismos que para
sigue siendo muy
er elemento, igual
as colas, también
rá el punto donde
pre en extremos
que no tiene nodo
ca eliminarlo de la
ponibles. Las colas

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 67/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
76
8.4. AÑADIR UN ELEMENTO
Las operaciones con colas s
cola esté vacía.
8.4.1. AÑADIR ELEMENTO E
Partiremos de que ya tene
además los punteros que de
El proceso es muy simple, b
1. Hacer que nodo->siguie
2. Que el puntero primero
3. Y que el puntero último
8.4.2. AÑADIR ELEMENTO E
De nuevo partiremos de un
este caso, al no estar vacía, l
rcia
ESTRUCTUR
76
n muy sencillas, prácticamente no hay casos espe
N UNA COLA VACÍA
Cola vacía
os el nodo a insertar y, por supuesto un punter
finen la cola, primero y último que valdrán NULL:
Elemento encolado
stará con que:
te apunte a NULL.
apunte a nodo.
también apunte a nodo.
N UNA COLA NO VACÍA
Cola no vacía
nodo a insertar, con un puntero que apunte a él,
os punteros primero y último no serán nulos:
Elemento encolado
DE DATOS
76
ciales, salvo que la
que apunte a él,
y de una cola, en

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 68/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
77
El proceso sigue siendo muy
1. Hacemos que nodo->sig
2. Después que ultimo->si
3. Y actualizamos último, h
8.4.3. AÑADIR ELEMENTO EPara generalizar el caso ant
1. Hacemos que nodo->sig
2. Si ultimo no es NULL, ha
3. Y actualizamos último, h
4. Si primero es NULL, sig
también a nodo.
8.5. LEER UN ELEMENTO DE
Ahora también existen dos c
8.5.1. LEER UN ELEMENTO EUsaremos un puntero a un n
1. Hacemos que nodo apu
2. Asignamos a primero la3. Guardamos el contenid
de lectura en colas impli
4. Liberamos la memoria a
rcia
ESTRUCTUR
77
sencillo:
uiente apunte a NULL.
uiente apunte a nodo.
aciendo que apunte a nodo.
N UNA COLA, CASO GENERAL rior, sólo necesitamos añadir una operación:
uiente apunte a NULL.
cemos que ultimo->siguiente apunte a nodo.
aciendo que apunte a nodo.
ifica que la cola estaba vacía, así que haremos q
UNA COLA, IMPLICA ELIMINARLO
asos, que la cola tenga un solo elemento o que ten
N UNA COLA CON MÁS DE UN ELEMENTO odo auxiliar:
Cola con más de un elemento
te al primer elemento de la cola, es decir a primer
dirección del segundo nodo de la pila: primero->sig del nodo para devolverlo como retorno, recuerd
can también borrar.
signada al primer nodo, el que queremos eliminar.
Elemento desencolado
DE DATOS
77
e primero apunte
a más de uno.
.
uiente. que la operación

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 69/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
78
8.5.2. LEER UN ELEMENTO E
También necesitamos un pu
1. Hacemos que nodo apu
2. Asignamos NULL a prim
>siguiente.
3. Guardamos el contenid
de lectura en colas impli
4. Liberamos la memoria a
5. Hacemos que ultimo ap
8.5.3. LEER UN ELEMENTO E
1. Hacemos que nodo apu2. Asignamos a primero la
3. Guardamos el contenid
de lectura en colas impli
4. Liberamos la memoria a
5. Si primero es NULL, hac
la cola vacía.
8.6 EJEMPLO DE COLA EN C
Ya hemos visto que las cola
los casos anteriores, veremoPara empezar, y como sie
Además la clase para nodo
miembros privados de nodo
class nodo \{
public:
nodo(int v, nodo
rcia
ESTRUCTUR
78
N UNA COLA CON UN SOLO ELEMENTO
Cola con un elemento
ntero a un nodo auxiliar:
te al primer elemento de la pila, es decir a primero
Elemento desencolado
ro, que es la dirección del segundo nodo teórico d
del nodo para devolverlo como retorno, recuerd
can también borrar.
signada al primer nodo, el que queremos eliminar.
nte a NULL, ya que la lectura ha dejado la cola vací
N UNA COLA CASO GENERAL
te al primer elemento de la pila, es decir a primero dirección del segundo nodo de la pila: primero->sig
del nodo para devolverlo como retorno, recuerd
can también borrar.
signada al primer nodo, el que queremos eliminar.
mos que ultimo también apunte a NULL, ya que l
+ USANDO CLASES
son casos particulares de listas abiertas, pero más
s ahora un ejemplo de cola usando clases. pre, necesitaremos dos clases, una para nodo
debe ser amiga de la clase cola, ya que ésta d
.
*sig = NULL) \{
DE DATOS
78
.
e la cola: primero-
que la operación
a.
. uiente.
a que la operación
lectura ha dejado
simples. Como en
y otra para cola.
ebe acceder a los

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 70/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
79
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class cola;
};
typedef nodo *pnodo;
class cola \{
public:
cola() : ultimo(NULL), primero(NULL) \{}
cola();
void Anadir(int v);
int Leer();
private:
pnodo primero, ultimo;
};
8.6.1. CÓDIGO DEL EJEMPLO COMPLETO
#include <iostream>
using namespace std;
class nodo \{
public:
nodo(int v, nodo *sig = NULL) \{
valor = v;
siguiente = sig;
}
private:
int valor;
nodo *siguiente;
friend class cola;
};
typedef nodo *pnodo;
class cola \{
public:
cola() : ultimo(NULL), primero(NULL) \{}
~cola();
void Push(int v);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 71/135

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 72/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
81
cout << "Leer: " <<
cout << "Leer: " <<
Cola.Anadir(90);
cout << "Añadir(90)"
cout << "Leer: " <<
cout << "Leer: " <<
cin.get();
return 0;
}
9. ARBOLES
9.1 DEFINICIÓN
Un árbol es una estructura n
También se suele dar una d
dato y varios árboles.
Esto son definiciones simple
Definiremos varios concepto
Nodo hijo: cualquiera d
'L' y 'M' son hijos de 'G'.
Nodo padre: nodo que
padre de 'B', 'C' y 'D'.
Los árboles con los que trab
ser apuntado por otro nod
árboles estén fuertemente j
En cuanto a la posición dent
Nodo raíz: nodo que no
el ejemplo, ese nodo es
Nodo hoja: nodo que no
Nodo rama: aunque e
pertenecen a ninguna d
rcia
ESTRUCTUR
81
ola.Leer() << endl;
ola.Leer() << endl;
<< endl;
ola.Leer() << endl;
ola.Leer() << endl;
o lineal en la que cada nodo puede apuntar a uno
efinición recursiva: un árbol es una estructura en
s. Pero las características que implican no lo son ta
Árbol
s. En relación con otros nodos:
los nodos apuntados por uno de los nodos del ár
contiene un puntero al nodo actual. En el ejem
ajaremos tienen otra característica importante: cad
o, es decir, cada nodo sólo tendrá un padre. Es
rarquizados, y es lo que en realidad les da la apari
ro del árbol:
tiene padre. Este es el nodo que usaremos para ref
el 'A'.
tiene hijos. En el ejemplo hay varios: 'F', 'H', 'I', 'K',
ta definición apenas la usaremos, estos son l
las dos categorías anteriores. En el ejemplo: 'B', 'C
DE DATOS
81
varios nodos.
compuesta por un
to.
bol. En el ejemplo,
lo, el nodo 'A' es
a nodo sólo puede
o hace que estos
ncia de árboles.
erirnos al árbol. En
'L', 'M', 'N' y 'O'.
s nodos que no
', 'D', 'E', 'G' y 'J'.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 73/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
82
Otra característica que normalmente tendrán nuestros árboles es que todos los nodos contengan
el mismo número de punteros, es decir, usaremos la misma estructura para todos los nodos del
árbol. Esto hace que la estructura sea más sencilla, y por lo tanto también los programas para
trabajar con ellos.
Tampoco es necesario que todos los nodos hijos de un nodo concreto existan. Es decir, que
pueden usarse todos, algunos o ninguno de los punteros de cada nodo.
Un árbol en el que en cada nodo o bien todos o ninguno de los hijos existe, se llama árbol
completo.
En una cosa, los árboles se parecen al resto de las estructuras que hemos visto: dado un nodo
cualquiera de la estructura, podemos considerarlo como una estructura independiente. Es decir,
un nodo cualquiera puede ser considerado como la raíz de un árbol completo.
Existen otros conceptos que definen las características del árbol, en relación a su tamaño:
• Orden: es el número potencial de hijos que puede tener cada elemento de árbol. De este
modo, diremos que un árbol en el que cada nodo puede apuntar a otros dos es de orden dos,
si puede apuntar a tres será de orden tres, etc.
• Grado: el número de hijos que tiene el elemento con más hijos dentro del árbol. En el árbol
del ejemplo, el grado es tres, ya que tanto 'A' como 'D' tienen tres hijos, y no existen
elementos con más de tres hijos.
• Nivel: se define para cada elemento del árbol como la distancia a la raíz, medida en nodos. El
nivel de la raíz es cero y el de sus hijos uno. Así sucesivamente. En el ejemplo, el nodo 'D'
tiene nivel 1, el nodo 'G' tiene nivel 2, y el nodo 'N', nivel 3.
• Altura: la altura de un árbol se define como el nivel del nodo de mayor nivel. Como cada
nodo de un árbol puede considerarse a su vez como la raíz de un árbol, también podemos
hablar de altura de ramas. El árbol del ejemplo tiene altura 3, la rama 'B' tiene altura 2, la
rama 'G' tiene altura 1, la 'H' cero, etc.
Los árboles de orden dos son bastante especiales, de hecho les dedicaremos varios capítulos.
Estos árboles se conocen también como árboles binarios.
Frecuentemente, aunque tampoco es estrictamente necesario, para hacer más fácil moverse a
través del árbol, añadiremos un puntero a cada nodo que apunte al nodo padre. De este modo
podremos avanzar en dirección a la raíz, y no sólo hacia las hojas.
Es importante conservar siempre el nodo raíz ya que es el nodo a partir del cual se desarrolla el
árbol, si perdemos este nodo, perderemos el acceso a todo el árbol.
El nodo típico de un árbol difiere de los nodos que hemos visto hasta ahora para listas, aunque
sólo en el número de nodos. Veamos un ejemplo de nodo para crear árboles de orden tres:
struct nodo \{
int dato;
struct nodo *rama1;
struct nodo *rama2;
struct nodo *rama3;
};

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 74/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
83
O generalizando más:
#define ORDEN 5
struct nodo \{
int dato;
struct nodo *rama[
};
9.2 DECLARACIONES DE TIP
Para C++, y basándonos en l
los siguientes tipos:
typedef struct _nodo
int dato;
struct _nodo *rama
} tipoNodo;
typedef tipoNodo *pNo
typedef tipoNodo *Arb
Al igual que hicimos con las
declarar nodos, y un tipo p
Árbol es el tipo para declara
El movimiento a través de
siempre partiendo del nodo
podremos optar por cualqui
En general, intentaremos qu
de cada nodo, los árboles qqué serlo. Un ejemplo de es
operativo. Aunque en este
nodos fichero, podríamos
directorios.
Otro ejemplo podría ser la
dividido en capítulos, y cad
rcia
ESTRUCTUR
83
ORDEN];
S PARA MANEJAR ÁRBOLES EN C++
a declaración de nodo que hemos visto más arriba,
\{
[ORDEN];
do;
ol;
listas que hemos visto hasta ahora, declaramos un
odo para es el tipo para declarar punteros a un nod
r árboles de orden ORDEN .
Árbol
árboles, salvo que implementemos punteros al
raíz hacia un nodo hoja. Cada vez que lleguemo
era de los nodos a los que apunta para avanzar al si
e exista algún significado asociado a cada uno de l
e estamos viendo son abstractos, pero las aplicacitructura en árbol es el sistema de directorios y fich
caso se trata de árboles con nodos de dos tipos,
onsiderar que los nodos hoja son ficheros y lo
tabla de contenido de un libro, por ejemplo de
uno de ellos en subcapítulos. Aunque el libro se
DE DATOS
83
trabajaremos con
ipo tipoNodo para
o.
nodo padre, será
a un nuevo nodo
guiente nodo.
s punteros dentro
nes no tienen por ros de un sistema
nodos directorio y
nodos rama son
ste mismo curso,
algo lineal, como

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 75/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
84
una lista, en el que cada capítulo sigue al anterior, también es posible acceder a cualquier punto
de él a través de la tabla de contenido.
También se suelen organizar en forma de árbol los organigramas de mando en empresas o en el
ejército, y los árboles genealógicos.
9.3 OPERACIONES BÁSICAS CON ÁRBOLES
Salvo que trabajemos con árboles especiales, como los que veremos más adelante, las inserciones
serán siempre en punteros de nodos hoja o en punteros libres de nodos rama. Con estas
estructuras no es tan fácil generalizar, ya que existen muchas variedades de árboles.
De nuevo tenemos casi el mismo repertorio de operaciones de las que disponíamos con las listas:
Añadir o insertar elementos.
Buscar o localizar elementos.
Borrar elementos.
Moverse a través del árbol.
Recorrer el árbol completo.
Los algoritmos de inserción y borrado dependen en gran medida del tipo de árbol que estemos
implementando, de modo que por ahora los pasaremos por alto y nos centraremos más en el
modo de recorrer árboles.
9.4 RECORRIDOS POR ÁRBOLES
El modo evidente de moverse a través de las ramas de un árbol es siguiendo los punteros, del
mismo modo en que nos movíamos a través de las listas.
Esos recorridos dependen en gran medida del tipo y propósito del árbol, pero hay ciertos
recorridos que usaremos frecuentemente. Se trata de aquellos recorridos que incluyen todo el
árbol.
Hay tres formas de recorrer un árbol completo, y las tres se suelen implementar mediante
recursividad. En los tres casos se sigue siempre a partir de cada nodo todas las ramas una por
una.
Supongamos que tenemos un árbol de orden tres, y queremos recorrerlo por completo.
Partiremos del nodo raíz:
RecorrerArbol(raiz);
La función RecorrerArbol , aplicando recursividad, será tan sencilla como invocar de nuevo a la
función RecorrerArbol para cada una de las ramas:
void RecorrerArbol(Arbol a) \{
if(a == NULL) return;
RecorrerArbol(a->rama[0]);
RecorrerArbol(a->rama[1]);
RecorrerArbol(a->rama[2]);
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 76/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
85
Lo que diferencia los distint
momento que elegimos par
una de las ramas.
Los tres tipos son:
9.4.1. PRE-ORDENEn este tipo de recorrido, el
void PreOrden(Arbol a
if(a == NULL) retu
Procesar(dato);
RecorrerArbol(a->r
RecorrerArbol(a->r
RecorrerArbol(a->r}
Si seguimos el árbol del e
mostrarlos por pantalla, obt
9.4.2. IN-ORDENEn este tipo de recorrido,
antes de recorrer la última
cuando existen ORDEN-1 da
dos ramas (este es el caso d
void InOrden(Arbol a)
if(a == NULL) retu
RecorrerArbol(a->r
Procesar(dato);
RecorrerArbol(a->r
RecorrerArbol(a->r
rcia
ESTRUCTUR
85
os métodos de recorrer el árbol no es el sistema
procesar el valor de cada nodo con relación a los
Árbol
valor del nodo se procesa antes de recorrer las ram
) \{
rn;
ama[0]);
ama[1]);
ama[2]);
jemplo en pre-orden, y el proceso de los dato
endremos algo así:
A B E K F C G L M D H I J N O
l valor del nodo se procesa después de recorrer
. Esto tiene más sentido en el caso de árboles b
tos, en cuyo caso procesaremos cada dato entre el
los árboles-b):
\{
rn;
ama[0]);
ama[1]);
ama[2]);
DE DATOS
85
de hacerlo, sino el
recorridos de cada
as:
es sencillamente
la primera rama y
inarios, y también
recorrido de cada

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 77/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
86
}
Si seguimos el árbol del ejemplo en in-orden, y el proceso de los datos es sencillamente
mostrarlos por pantalla, obtendremos algo así:
K E B F A L G M C H D I N J O
9.4.3. POST-ORDENEn este tipo de recorrido, el valor del nodo se procesa después de recorrer todas las ramas:
void PostOrden(Arbol a) \{
if(a == NULL) return;
RecorrerArbol(a->rama[0]);
RecorrerArbol(a->rama[1]);
RecorrerArbol(a->rama[2]);
Procesar(dato);
}
Si seguimos el árbol del ejemplo en post-orden, y el proceso de los datos es sencillamentemostrarlos por pantalla, obtendremos algo así:
K E F B L M G C H I N O J D A
9.5 ELIMINAR NODOS EN UN ÁRBOL
El proceso general es muy sencillo en este caso, pero con una importante limitación, sólo
podemos borrar nodos hoja:
El proceso sería el siguiente:
1. Buscar el nodo padre del que queremos eliminar.
2. Buscar el puntero del nodo padre que apunta al nodo que queremos borrar.
3. Liberar el nodo.4. padre->nodo[i] = NULL;.
Cuando el nodo a borrar no sea un nodo hoja, diremos que hacemos una "poda", y en ese caso
eliminaremos el árbol cuya raíz es el nodo a borrar. Se trata de un procedimiento recursivo,
aplicamos el recorrido Post-Orden, y el proceso será borrar el nodo.
El procedimiento es similar al de borrado de un nodo:
1. Buscar el nodo padre del que queremos eliminar.
2. Buscar el puntero del nodo padre que apunta al nodo que queremos borrar.
3. Podar el árbol cuyo padre es nodo.
4. padre->nodo[i] = NULL;.
En el árbol del ejemplo, para podar la rama 'B', recorreremos el subárbol 'B' en post-orden,eliminando cada nodo cuando se procese, de este modo no perdemos los punteros a las ramas
apuntadas por cada nodo, ya que esas ramas se borrarán antes de eliminar el nodo.
De modo que el orden en que se borrarán los nodos será:
K E F y B

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 78/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
87
9.6 ÁRBOLES ORDENADOS
A partir del siguiente capítu
más interés desde el punto
Un árbol ordenado, en ge
ordenada siguiendo uno de l
En estos árboles es importa
eliminen nodos.
Existen varios tipos de árbol
• árboles binarios de bús
ordenada si se recorren
• árboles AVL: son árbole
para cualquier nodo no
• árboles perfectamente
de nodos de cada rama
AVL también.
• árboles 2-3: son árbole
también equilibrados. T
• árboles-B: caso general
10. ARBOLES BINARIOS DE BUS10.1 DEFINICIÓN
Se trata de árboles de orden
raíz del subárbol izquierdo
raíz del subárbol derecho es
10.2 OPERACIONES EN ABB
El repertorio de operacio
realizábamos sobre otras es
rcia
ESTRUCTUR
87
lo sólo hablaremos de árboles ordenados, ya que
e vista de TAD, y los que tienen más aplicaciones g
neral, es aquel a partir del cual se puede obte
os recorridos posibles del árbol: in-orden, pre-orde
nte que la secuencia se mantenga ordenada aunq
es ordenados, que veremos a continuación:
queda (ABB): son árboles de orden 2 que mantie
en in-orden.
binarios de búsqueda equilibrados, es decir, los ni
ifieren en más de 1.
quilibrados: son árboles binarios de búsqueda en
para cualquier nodo no difieren en más de 1. Son p
s de orden 3, que contienen dos claves en cada
mbién generan secuencias ordenadas al recorrerlo
e árboles 2-3, que para un orden M, contienen M-
UEDA
2 en los que se cumple que para cada nodo, el val
s menor que el valor de la clave del nodo y que
mayor que el valor de la clave del nodo.
Árbol binario de búsqueda
nes que se pueden realizar sobre un ABB es
ructuras de datos, más alguna otra propia de árbol
DE DATOS
87
son los que tienen
enéricas.
er una secuencia
n o post-orden.
ue se añadan o se
en una secuencia
eles de cada rama
los que el número
or lo tanto árboles
nodo y que están
s en in-orden.
1 claves.
or de la clave de la
l valor de la clave
parecido al que
es:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 79/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
88
Buscar un elemento.
Insertar un elemento.
Borrar un elemento.
Movimientos a través del árbol:
Izquierda.
Derecha.
Raíz.
Información:
Comprobar si un árbol está vacío.
Calcular el número de nodos.
Comprobar si el nodo es hoja.
Calcular la altura de un nodo.
Calcular la altura de un árbol.
10.3 BUSCAR UN ELEMENTO
Partiendo siempre del nodo raíz, el modo de buscar un elemento se define de forma recursiva.
• Si el árbol está vacío, terminamos la búsqueda: el elemento no está en el árbol.
• Si el valor del nodo raíz es igual que el del elemento que buscamos, terminamos la búsqueda
con éxito.
• Si el valor del nodo raíz es mayor que el elemento que buscamos, continuaremos la búsqueda
en el árbol izquierdo.
• Si el valor del nodo raíz es menor que el elemento que buscamos, continuaremos la búsqueda
en el árbol derecho.
El valor de retorno de una función de búsqueda en un ABB puede ser un puntero al nodo
encontrado, o NULL, si no se ha encontrado.
10.4 INSERTAR UN ELEMENTO
Para insertar un elemento nos basamos en el algoritmo de búsqueda. Si el elemento está en el
árbol no lo insertaremos. Si no lo está, lo insertaremos a continuación del último nodo visitado.
Necesitamos un puntero auxiliar para conservar una referencia al padre del nodo raíz actual. El
valor inicial para ese puntero es NULL.
Padre = NULL
nodo = Raíz
Bucle: mientras actual no sea un árbol vacío o hasta que se encuentre el elemento.
Si el valor del nodo raíz es mayor que el elemento que buscamos, continuaremos
la búsqueda en el árbol izquierdo: Padre=nodo, nodo=nodo->izquierdo.
Si el valor del nodo raíz es menor que el elemento que buscamos, continuaremos
la búsqueda en el árbol derecho: Padre=nodo, nodo=nodo->derecho.
Si nodo no es NULL, el elemento está en el árbol, por lo tanto salimos.
Si Padre es NULL, el árbol estaba vacío, por lo tanto, el nuevo árbol sólo contendrá el
nuevo elemento, que será la raíz del árbol.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 80/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
89
Si el elemento es menor que el Padre, entonces insertamos el nuevo elemento como un
nuevo árbol izquierdo de Padre.
Si el elemento es mayor que el Padre, entonces insertamos el nuevo elemento como un
nuevo árbol derecho de Padre.
Este modo de actuar asegura que el árbol sigue siendo ABB.
10.5 BORRAR UN ELEMENTO
Para borrar un elemento también nos basamos en el algoritmo de búsqueda. Si el elemento no
está en el árbol no lo podremos borrar. Si está, hay dos casos posibles:
1. Se trata de un nodo hoja: en ese caso lo borraremos directamente.
2. Se trata de un nodo rama: en ese caso no podemos eliminarlo, puesto que perderíamos todos
los elementos del árbol de que el nodo actual es padre. En su lugar buscamos el nodo más a
la izquierda del subárbol derecho, o el más a la derecha del subárbol izquierdo e
intercambiamos sus valores. A continuación eliminamos el nodo hoja.
Necesitamos un puntero auxiliar para conservar una referencia al padre del nodo raíz actual. El
valor inicial para ese puntero es NULL.
Padre = NULL
Si el árbol está vacío: el elemento no está en el árbol, por lo tanto salimos sin eliminar ningún
elemento.
Si el valor del nodo raíz es igual que el del elemento que buscamos, estamos ante uno de los
siguientes casos:
El nodo raíz es un nodo hoja:
Si 'Padre' es NULL, el nodo raíz es el único del árbol, por lo tanto el puntero al
árbol debe ser NULL.
Si raíz es la rama derecha de 'Padre', hacemos que esa rama apunte a NULL.
Si raíz es la rama izquierda de 'Padre', hacemos que esa rama apunte a NULL.
Eliminamos el nodo, y salimos.
El nodo no es un nodo hoja:
Buscamos el 'nodo' más a la izquierda del árbol derecho de raíz o el más a la
derecha del árbol izquierdo. Hay que tener en cuenta que puede que sólo
exista uno de esos árboles. Al mismo tiempo, actualizamos 'Padre' para que
apunte al padre de 'nodo'.
Intercambiamos los elementos de los nodos raíz y 'nodo'.
Borramos el nodo 'nodo'. Esto significa volver a (1), ya que puede suceder
que 'nodo' no sea un nodo hoja. (Ver ejemplo 3)
Si el valor del nodo raíz es mayor que el elemento que buscamos, continuaremos la búsqueda
en el árbol izquierdo.
Si el valor del nodo raíz es menor que el elemento que buscamos, continuaremos la búsqueda
en el árbol derecho.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 81/135
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 82/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
91
1. Localizamos el nodo a b
2. Buscamos el nodo más
árbol derecho no tiene
un caso análogo. Al mis
3. Intercambiamos los ele
4. Ahora tenemos que rep
5. Localizamos de nuevo el
6. Buscamos el nodo más
tiempo que mantenemo
7. Intercambiamos los ele
8. Hacemos que el puntero
9. Borramos el 'nodo'.
rcia
ESTRUCTUR
91
Árbol binario de búsqueda
rrar ('raíz').
la izquierda del árbol derecho de 'raíz', en este c
odos a su izquierda, si optamos por la rama izqui
o tiempo que mantenemos un puntero a 'Padre' a
entos 6 y 12.
tir el bucle para el nodo 6 de nuevo, ya que no po
Borrar con intercambio de nodo rama (1)
nodo a borrar ('raíz').
la izquierda del árbol derecho de 'raíz', en este c
s un puntero a 'Padre' a 'nodo'.
entos 6 y 16.
de 'Padre' que apuntaba a 'nodo', ahora apunte a
DE DATOS
91
so el 12, ya que el
rda, estaremos en
'nodo'.
emos eliminarlo.
so el 16, al mismo
NULL.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 83/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
92
Este modo de actuar asegur
10.6 MOVIMIENTOS A TRA
No hay mucho que contar.
nodo Raíz, este puntero no
Para movernos a través del
puntero los movimientos p
nodo raíz de la rama derech
10.7 INFORMACIÓN
Hay varios parámetros que
darán idea de lo eficientem
10.7.1. COMPROBAR SI UN
Un árbol está vacío si su raíz
10.7.2. CALCULAR EL NÚME
Tenemos dos opciones par
mismo tiempo que se añade
Para contar los nodos pode
orden, pre-orden o post-ord
10.7.3. COMPROBAR SI EL
Esto es muy sencillo, basta
vacíos. Si ambos lo están, se
10.7.4. CALCULAR LA ALTU
No hay un modo directo de
de la raíz. De modo que ten
rcia
ESTRUCTUR
92
Borrar con intercambio de nodo rama (2)
que el árbol sigue siendo ABB.
ÉS DEL ÁRBOL
Nuestra estructura se referenciará siempre medi
ebe perderse nunca.
árbol usaremos punteros auxiliares, de modo qu
sibles serán: moverse al nodo raíz de la rama izq
a o moverse al nodo Raíz del árbol.
podemos calcular o medir dentro de un árbol. Al
nte que está organizado o el modo en que funcion
RBOL ESTÁ VACÍO.
es NULL.
RO DE NODOS.
hacer esto, una es llevar siempre la cuenta de n
n o eliminan elementos. La otra es, sencillamente,
mos recurrir a cualquiera de los tres modos de re
en, como acción sencillamente incrementamos el c
ODO ES HOJA.
con comprobar si tanto el árbol izquierdo como
trata de un nodo hoja.
A DE UN NODO.
hacer esto, ya que no nos es posible recorrer el ár
remos que recurrir a otra técnica para calcular la a
DE DATOS
92
nte un puntero al
e desde cualquier
ierda, moverse al
unos de ellos nos
.
dos en el árbol al
ontarlos.
correr el árbol: in-
ontador.
el derecho están
bol en la dirección
ltura.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 84/135
Tec. Sup. Alain Wilfredo Fuentes G
HARDWARE - SOFTWARE
93
Lo que haremos es buscar
que avancemos un nodo inc
• Empezamos con el nodo
• Si el valor del nodo raíz
y el valor de la altura es
• Incrementamos 'Altura'.
• Si el valor del nodo raíz
en el árbol izquierdo.
• Si el valor del nodo raíz
en el árbol derecho.
10.7.5. CALCULAR LA ALTU
La altura del árbol es la alt
recorrer todo el árbol, de n
cambiemos de nivel increm
lleguemos a un nodo hoja c
si es mayor, actualizamos la
• Iniciamos un recorrido d
• Cada vez que empece
nodo.
• Después de procesar las
que almacena la altura
10.8 ÁRBOLES DEGENERAD
Los árboles binarios de bús
creamos un ABB a partir de
Difícilmente podremos llam
rcia
ESTRUCTUR
93
l elemento del nodo de que queremos averiguar
rementamos la variable que contendrá la altura del
raíz apuntando a Raíz, y la 'Altura' igual a cero.
es igual que el del elemento que buscamos, termin
'Altura'.
s mayor que el elemento que buscamos, continua
s menor que el elemento que buscamos, continua
A DE UN ÁRBOL.
ra del nodo de mayor altura. Para buscar este val
uevo es indiferente el tipo de recorrido que haga
entamos la variable que contiene la altura del no
mpararemos su altura con la variable que contien
altura del árbol.
el árbol en postorden, con la variable de altura igu
os a recorrer una nueva rama, incrementamos
dos ramas, verificamos si la altura del nodo es ma
ctual del árbol, si es así, actualizamos esa variable.
S
queda tienen un gran inconveniente. Por ejemplo
na lista de valores ordenada:
2, 4, 5, 8, 9, 12
r a la estructura resultante un árbol:
Árbol binario de búsqueda degenerado
DE DATOS
93
la altura. Cada vez
nodo.
amos la búsqueda
emos la búsqueda
emos la búsqueda
or tendremos que
os, cada vez que
do actual, cuando
la altura del árbol
l a cero.
la altura para ese
yor que la variable
, supongamos que

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 85/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
94
Esto es lo que llamamos un árbol binario de búsqueda degenerado.
10.9. DECLARACIÓN DE CLASE ARBOL ABB
Declaramos dos clases, una para nodo y otra para ArbolABB, la clase nodo la declararemos como
parte de la clase ArbolABB, de modo que no tendremos que definir relaciones de amistad, y
evitamos que otras clases o funciones tengan acceso a los datos internos de nodo.
class ArbolABB \{
private:
//// Clase local de Lista para Nodo de ArbolBinario:
class Nodo \{
public:
// Constructor:
Nodo(const int dat, Nodo *izq=NULL, Nodo *der=NULL) :
dato(dat), izquierdo(izq), derecho(der) \{}
// Miembros:
int dato;Nodo *izquierdo;
Nodo *derecho;
};
// Punteros de la lista, para cabeza y nodo actual:
Nodo *raíz;
Nodo *actual;
int contador;
int altura;
public:
// Constructor y destructor básicos:
ArbolABB() : raíz(NULL), actual(NULL) \{}
~ArbolABB() \
// Insertar en árbol ordenado:
void Insertar(const int dat);
// Borrar un elemento del árbol:
void Borrar(const int dat);
// Función de búsqueda:
bool Buscar(const int dat);
// Comprobar si el árbol está vacío:
bool Vacio(Nodo *r) \
// Comprobar si es un nodo hoja:
bool EsHoja(Nodo *r) \
// Contar número de nodos:
const int NumeroNodos();
const int AlturaArbol();
// Calcular altura de un int:
int Altura(const int dat);
// Devolver referencia al int del nodo actual:
int &ValorActual() \

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 86/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
95
// Moverse al nodo raíz:
void Raiz() \
// Aplicar una función a cada elemento del árbol:
void InOrden(void (*func)(int&) , Nodo *nodo=NULL, bool r=true);
void PreOrden(void (*func)(int&) , Nodo *nodo=NULL, bool r=true);
void PostOrden(void (*func)(int&) , Nodo *nodo=NULL, bool r=true);
private:
// Funciones auxiliares
void Podar(Nodo* &);
void auxContador(Nodo*);
void auxAltura(Nodo*, int);
};
10.10. DEFINICIÓN DE LAS FUNCIONES MIEMBRO
Las definiciones de la función miembro de la clase no difieren demasiado de las que creamos en
C. Tan solo se han sustituido algunos punteros por referencias, y se usa el tipo bool cuando es
aconsejable.
Por ejemplo, en las funciones de recorrido de árboles, la función invocada acepta ahora una
referencia a un entero, en lugar de un puntero a un entero.
11. GRAFOS
11.1. INTRODUCCIÓN
El origen de la palabra grafo es griego y su significado etimológico es "trazar". Aparece con gran
frecuencia como respuesta a problemas de la vida cotidiana, algunos ejemplos podrían ser los
siguientes: un gráfico de una serie de tareas a realizar indicando su secuenciación (un
organigrama), grafos matemáticos que representan las relaciones binarias, una red de carreteras,
la red de enlaces ferroviarios o aéreos o la red eléctrica de una ciudad, (ver la figura 1). En cadacaso es conveniente representar gráficamente el problema dibujando un grafo como un conjunto
de puntos (nodos o vértices) con líneas conectándolos (arcos).
De aquí se podría deducir que un grafo es básicamente un objeto geométrico aunque en realidad
sea un objeto combinatorio, es decir, un conjunto de puntos y un conjunto de líneas tomado de
entre el conjunto de líneas que une cada par de vértices. Por otro lado, debido a su generalidad y

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 87/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
96
a la gran diversidad de formas que pueden usarse, resulta complejo tratar con todas las ideas
relacionadas con un grafo.
Para facilitar el estudio de este tipo de dato, a continuación se realizará un estudio de la teoría de
grafos desde el punto de vista de las ciencias de la computación, considerando que dicha teoría
es compleja y amplia, aquí sólo se realizará una introducción a la misma, describiéndose el grafo
como un tipo de dato y mostrándose los problemas típicos y los algoritmos que permiten
solucionarlos usando un ordenador.
Los grafos son estructuras de datos no lineales que tienen una naturaleza generalmente
dinámica, u estudio podría dividirse en dos grandes bloques; grafos dirigidos y grafos no dirigidos
(pueden ser considerados un caso particular de los anteriores).
Un ejemplo de grafo dirigido lo constituye la red de aguas de una ciudad ya que cada tubería sólo
admite que el agua la recorra en un único sentido, por el contrario, la red de carreteras de un país
representa en general un grafo no dirigido, puesto que una misma carretera puede ser recorrida
en ambos sentidos. No obstante, podemos dar unas definiciones generales para ambos tipos.
A continuación daremos definiciones de los dos tipos de grafos y de los conceptos que llevan
asociados.
11.2. NOTACIÓN Y CONCEPTOS
Un grafo G es un conjunto en el que hay definida una relación binaria, es decir, G = (V,A) tal que V
es un conjunto de objetos a los que denominaremos vértices o nodos y A⊆ V x V es una relación
binaria a cuyos elementos denominaremos arcos o aristas.
Dados x, y∈ V, puede ocurrir que:
(x, y) ∈ A, en cuyo caso diremos que x e y están unidos mediante un arco y,
(x, y) ∉ A, en cuyo caso diremos que no lo están.
Si las aristas tienen asociada una dirección (las aristas (x,y) y (y,x) no son equivalentes) diremos
que el grafo es dirigido, en otro caso ((x,y)=(y,x)) diremos que el grafo es no dirigido.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 88/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
97
VEAMOS ALGUNOS CONCEPTOS SOBRE GRAFOS:
Diremos que un grafo es completo si A=VxV, o sea, si para cualquier pareja de vértices
existe una arista que los une(en ambos sentidos si el grafo es no dirigido).El número de
aristas será:
Para grafos dirigidos:
Para grafos no dirigidos:
Donde n=|V|.
Un grafo dirigido es simétrico si para toda arista (x, y)
A también aparece la arista (y,
x)
A y es anti simétrico si dada una arista (x, y)
A implica que (y, x)
A.
Tanto a las aristas como a los vértices les puede ser asociada información, a esta
información se le llama etiqueta, si la etiqueta que se asocia es un número se le llama
peso, costo o longitud, un grafo cuyas aristas o vértices tienen pesos asociados recibe elnombre de grafo etiquetado o ponderado.
El número de elementos de V se denomina orden del grafo, un grafo nulo es un grafo de
orden cero.
Se dice que un vértice x es incidente a un vértice y si existe un arco que vaya de x a y ((x,
y)
A), a “ x” se le denomina origen del arco y a “y ” extremo del mismo, de igual forma
se dirá que y es adyacente a x , en el caso de que el grafo sea no dirigido si x es adyacente
(resp. incidente) a y entonces y también es adyacente (resp. incidente) a x .
Se dice que dos arcos son adyacentes cuando tienen un vértice común que es a la vez
origen de uno y extremo del otro.
Se denomina camino (algunos autores lo llaman cadena si se trata de un grafo no
dirigido) en un grafo dirigido a una sucesión de arcos adyacentes:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 89/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
98
C= {(v 1 ,v 2 ),(v 2 ,v 3 ),...,(v n-1 ,v n ), v i V}.
La longitud del camino es el número de arcos que comprende y en el caso en el que el
grafo sea ponderado se calculará como la suma de los pesos de las aristas que lo
constituyen.
Un camino se dice simple cuando todos sus arcos son distintos y se
dice elemental cuando no utiliza un mismo vértice dos veces. Por tanto todo camino
elemental es simple y el recíproco no es cierto.
Un camino se dice Euleriano si es simple y además contiene a todos los arcos del grafo.
Un circuito (o ciclo para grafos no dirigidos) es un camino en el que coinciden los vértices
inicial y final, un circuito se dice simple cuando todos los arcos que lo forman son
distintos y se dice elemental cuando todos los vértices por los que pasa son distintos.
La longitud de un circuito es el número de arcos que lo componen. Un bucle es un
circuito de longitud 1 (están permitidos los arcos de la forma (i, i) y notemos que un grafo
anti simétrico carecería de ellos).
Un circuito elemental que incluye a todos los vértices de un grafo lo llamaremos
circuito Hamiltoniano.
Un grafo se denomina simple si no tiene bucles y no existe más que un camino para unir
dos nodos.
Diremos que un grafo no dirigido es bipartido si el conjunto de sus vértices puede ser
dividido en dos subconjuntos (disjuntos) de tal forma que cualquiera de las aristas que
componen el grafo tiene cada uno de sus extremos en un subconjunto distinto, un grafo
no dirigido será bipartido si y sólo si no contiene ciclos con un número de aristas par.
Dado un grafo G=(V,A),diremos que G'=(V,A
') con A
' ⊂ A es un grafo parcial de G y
un subgráfo de G es todo grafo G '=(V',A') con V'⊆ V y A'⊆ A donde A' será el conjunto
de todas aquellas aristas que unían en el grafo G dos vértices que están en V', se podrían
combinar ambas definiciones dando lugar a lo que llamaremos subgráfo parcial .
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 90/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
99
Se denomina grado de entrada de un vértice x al número de arcos incidentes en él, se
denota δe
(x).
Se denomina grado de salida de un vértice x al número de arcos adyacentes a él, sedenota δs (x).
Para grafos no dirigidos tanto el grado de entrada como el de salida coinciden y hablamos
entonces de grado y lo notamos por δ (x).
A todo grafo no dirigido se puede asociar un grafo denominado dual construido de la
siguiente forma:
G (V, A) ------> G' (V ' , A' )
Donde A' está construido de la siguiente forma: si e1,e2 ∈ a A son adyacentes --> (e1,e2)∈a A' con
e1,e2 ∈a V', en definitiva, para construir un grafo dual se cambian vértices por aristas y viceversa.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 91/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
100
Dado un grafo G, diremos que dos vértices están conectados si entre ambos existe un
camino que los une.
Llamaremos componente conexa a un conjunto de vértices de un grafo tal que entre
cada par de vértices hay al menos un camino y si se añade algún otro vértice esta
condición deja de verificarse. Matemáticamente se puede ver como que la conexión es
una relación de equivalencia que descompone a V en clases de equivalencia, cada uno de
los subgráfos a los que da lugar cada una de esas clases de equivalencia constituiría una
componente conexa. Un grafo diremos que es conexo si sólo existe una componente
conexa que coincide con todo el grafo.
11.3. BÚSQUEDA DE CAMINOS MÍNIMOS EN GRAFOS
Supongamos que tenemos un grafo dirigido sencillo etiquetado G = {V, A} de grado n, V =
{1,..., n} y con etiquetas en los arcos no negativas.
11.3.1. ENTRE UN VÉRTICE Y TODOS LOS DEMÁS VÉRTICES DEL GRAFO
Nos planteamos el problema de dado un vértice determinar el camino de costo mínimo de ese
vértice a todos los demás vértices de V.
Para resolver el problema aplicaremos un algoritmo debido a Dijkstra que esencialmente era a
partir de un conjunto S de vértices (S V) cuya distancia más corta desde el origen es conocida y
en cada paso se agrega un nuevo vértice v a S cuya distancia a su vez desde el origen sea la más
corta posible. Si la suposición que hacíamos de que las etiquetas son siempre no negativas se
cumple, puede comprobarse que siempre es posible encontrar un camino más corto desde el
origen y un vértice v que sólo pase a través de los vértices de S (camino "inherente"). Si se utiliza
además un vector D donde se almacena las longitudes de los caminos inherentes más cortos a
cada vértice, una vez que S incluya a todos los vértices, todos los caminos son inherentes de
forma que D contendrá la distancia más corta del origen a cada vértice.
Notación:
Origen = vértice 1 (obviamente esto no es una condición)
Sea S un vector de n componentes representando el conjunto de vértices cuya distancia
más corta desde el origen ya es conocida.
D es un vector de n componentes donde D [i] indica en cada paso la distancia más corta
entre el origen y el vértice i:
a. bien mediante el camino directo si existe el arco (i,j).

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 92/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
101
b. bien a través de los vértices de S (de los que se conoce su distancia más corta al
origen),
Al final D contendrá el costo del camino mínimo entre el origen y cada vértice.
C es la matriz de costos del grafo. C [1,i] representa el costo del arco (1,i). Si el arco no
existe, se le asigna un valor fuera de rango (∞)
P es un vector de dimensión n a través del cual reconstruiremos el camino más corto del
origen al resto de los vértices. Así P[i] contiene el vértice inmediato anterior a i en el
camino más corto.
Inicialmente es evidente que S = {1} y i D[i] = C[1 i] con P[i] = 1
Con estas premisas el algoritmo de Dijkstra se puede esquematizar así:
Algoritmo Dijkstra ()
1. S = {1}
2. for (i = 2; i<=n; i++ )
{
D[i] = C[I,i]
P[i] = 1
}
3. while ( S ≠ V )
{
elegir w ∈ V-S / D[w] sea mínimo
S= S U{w}
for (cada vértice v V -S)
if (D[v] > D[w] + C[w, v])
{
D[v] = D[w] + C[w, v]
P[v] = w
}
}
Veamos un ejemplo del algoritmo, supongamos que queremos encontrar los caminos mínimos
del vértice 1 al resto en el grafo siguiente:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 93/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
102
En principio:
S= {1}
D [2] = 60; D [3] = 10; D [4] = 100; D [5] = ∞
P[i] = 1 ∀i
ITERACIÓN 1:
V -S = {2,3,4,5} w = 3 -> S = {1,3} -> V -S = {2,4,5}
D [2] = min(D [2] , D [3] + C [3,2]) = min(60, 50) = 50 -> P [2] = 3
D [4] = min(D [4] , D [3] + C [3,4]) = min(100, 40) = 40 -> P [4] = 3
D [5] = min(D [5] , D [3] + C [3,5]) = min (∞,∞) =∞
Así D [2] = 50; D [4] = 40; D [5] = 00; P [2] = 3; P [4] = 3; P [5] = 1
ITERACIÓN 2:
V -S = {2,4,5} w = 4 -> S = {1,3,4} -> V- S = {2,5}
D [2] = min(D [2] , D [4] + C [4,2]) = min(50, 00) = 50 -> P [2] = 3
D [5] = min(D [5] , D [4] + C [4,5]) = min( 00,60) = 60 -> P [5] = 4
Así D [2] = 50; D [5] = 60; p [2] = 3; P [5] = 4

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 94/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
103
ITERACIÓN 3:
V -S = {2,5} w = 2 -> S = {1,3,4,2} -> V- S = {5}
D [5] = min(D [5] , D[2] + C [2,5]) = min(60, 55) = 55 -> P [5] = 2
Así D [5] = 55; P[5] = 2
Finalmente w = 5 -> S = {1,3,4,2,5} -> FIN DEL ALGORITMO
Para reconstruir el camino más corto del origen a cada vértice, se asignan los predecesores en
orden inverso. Por ejemplo, si se quiere conocer el camino desde el origen al vértice S , se, tiene
que:
P [5] = 2-+ P [2] = 3-+ P [3] = 1 siendo por tanto el camino (1,3,2,5) con costo 55 .
Aunque la implementación de este algoritmo es simple si la realizamos en base a una matriz de
adyacencia, en la práctica se utiliza normalmente una implementación en base a listas de
adyacencia. La razón de esta elección es que en la primera la eficiencia es O(n2) para cualquier
grafo; sin embargo la mayoría de los grafos que nos encontramos en la práctica tiene un número
de aristas bastante pequeño (grafos que podemos denominar dispersos o no densos ) y por tanto
el uso de listas de adyacencia se presenta como una solución más eficiente. Para conseguir una
mejor eficiencia en esta implementación del algoritmo de Dijkstra se ha echado mano de una
estructura de datos formada por un APO que tiene como etiqueta los vértices del grafo y como
clave el coste de ir desde el vértice inicial en el problema a ese vértice de tal forma que obtener el
vértice con mínimo coste sería O(log n).
11.3.2. ENTRE CADA PAR DE VÉRTICES DEL GRAFO
En lugar de buscar los caminos mínimos de un vértice a los demás nos podemos plantear buscar
el camino más corto entre cualquier pareja de vértices, es decir, dado un grafo dirigido
etiquetado G = {V, A} en el que las etiquetas son no negativas encontrar el camino de longitud "
más corta entre dos vértices cualesquiera de ese grafo.
Podría pensarse, para resolver el problema, en aplicar el algoritmo de Dijkstra n veces, una por
vértice, pero en lugar de eso, aplicaremos un nuevo algoritmo creado por Floyd que va
encontrando los caminos de forma iterativa.
NOTACIÓN:
V = {1, ..., n} conjunto de vértices.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 95/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
104
A es una matriz de tamaño n x n en la que se calculará en cada Aij la longitud más corta del
camino que va de i a j.
P es una matriz de tamaño n x n que utilizaremos para recuperar los caminos más cortos.
C es una matriz de dimensión n x n conteniendo los costos de los arcos. Si no existe arco de
un vértice i a otro j el correspondiente valor C [i,j] =∞.
Inicialmente A [i,j] = { C[i,j] si i ≠ j, 0 si i = j }.
A continuación se itera sobre A n veces de forma que tras hacer la k iteración A[i,j] tiene un valor
correspondiente a la longitud más pequeña de cualquier camino de i a j que no pase por un
vértice de índice mayor que k, es decir, cualquier vértice intermedio entre i y j (extremos del
camino) ha de ser menor o igual que k. Por tanto en cada iteración k se usará la siguiente
fórmula:
Ak [i,j] = min(Ak-1 [i,j] ,Ak-1 [i,k] +Ak-1l [k,j])3
Es decir, cada Ak [i,j] se obtiene comparando Ak-1 [i,j], el coste de ir de i a j sin pasar por k o
cualquier vértice de índice mayor, con Ak-1 [i,k] +Ak-1 [k,j], el costo de ir primero de i a k y después
de k a j sin pasar por un vértice de índice mayor que k de forma que si el paso por el vértice k
produce un camino i más corto que el indicado por Ak-1 [i,j], se elige ese coste para Ak [i,j] .Así
mismo, cada iteración P [i,j] contendrá el vértice k que permitió al algoritmo de Floyd encontrar el
valor más pequeño de A[i, j] .Inicialmente P[i,j] = 0, puesto que inicialmente el camino más corto
de i a j es el propio arco.
El algoritmo sería el siguiente:
Algoritmo Floyd ()
1. for (i = 1; i <= n; i++ )
for (j = 1; j <=n ; j++)
{
A[i, j]= C[i, j]
P[i, j]= 0}
2. for (i = 1; i <= n; i++)
A[i, i]= 0
3. for (k = 1; k <= n; k++)
for (i = 1; i <= n; i++)

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 96/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
105
for (j = l; j <=n ; j++)
if ((i ≠ j) && (A[i,k]+A[k,j] < A[i, j]))
{
A[i, j]= A[i, k]+A[k, j]
P[i, j]= k
}
Algoritmo recuperar_camino (i, j de tipo vértice)
1. k= P[i, j]
2. if (k ≠ 0)
{
recuperar_camino (i, k)
escribir (k)
recuperar_camino (k, j)
}
Por ejemplo, el camino más corto entre los vértices 2 y 4 se determinaría llamando a:
recuperar-camino (2,4)
k = 3 -> recuperar-camino (2,3) -> 0
[3] recuperar-camino (3,4) -> k = 1 -> recuperar-camino (3,1) -> 0
[1] recuperar-camino (1,4) -> 0
con la que el camino es (2,3,1,4) con costo 12.
11.4. PRIMITIVAS DEL GRAFO
Dentro del TDA Grafo hemos propuesto las siguientes primitivas:
Grafo ( ) -> constructor del grafo, reserva los recursos e inicializa el grafo a vacío.
Nodo LocalizaLabel (const Tbase e) -> localiza la etiqueta, devuelve el nodo asociado a la
etiqueta e.PARÁMETROS: e -> etiqueta asociada al nodo a encontrar.
Bool ExisteArco (nodo o, nodo d) -> nos dice si existe un arco, devuelve true si existe el arco
o false en otro caso.
PARÁMETROS: o -> nodo origen del arco.
d -> nodo destino del arco.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 97/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
106
Int GrafoVacio () -> devuelve 0 si el grafo esta vacio, si no devuelve 1 en otro caso.
Float EtiqArco (nodo o, nodo d) -> devuelve la etiqueta asociada a un arco, es decir el peso
del arco.
PARÁMETROS: o -> nodo origen del arco.
d -> nodo destino del arco.
Void InsertarNodo (const Tbase dato) -> inserta un nodo nuevo en el grafo.
PARÁMETROS: dato -> etiqueta del nuevo nodo.
Void InsertarArco (nodo o, nodo d, int valor) -> inserta un arco entre el nodo o y el d,
asociado al arco le podemos dar un valor o peso.
PARÁMETROS: o -> nodo origen del arco.
d -> nodo destino del arco.
valor -> peso del del arco.
Void BorrarArco (nodo o, nodo d) -> borra el arco existente entre los nodos o y d.
PARÁMETROS: o -> nodo origen del arco.
d -> nodo destino del arco.
Void DesconectarNodo (nodo a_eliminar) -> elimina un nodo del grafo receptor, todos los
arcos que entran o salen del nodo a eliminar tambien desaparecen.
PARÁMETROS: a_eliminar -> nodo a eliminar del grafo.
Void CopiarGrafo (Grafo gr) -> copia el grafo gr en el receptor.
PARÁMETROS: gr -> grafo a copiar.
~Grafo () -> destructor, destruye el grado liberando todos los recursos.
11.5. EJEMPLOS DE USO
IMPRIMIR UN GRAFO
Esta función nos imprime en pantalla el contenido de un grafo con etiquetas enteras.
Grafo<int> g;
Void Imprimir ()
{
nodo n1, n2;
arco a;
int cont = 1;
printf (“Arcos : \n”);
for (n1=g.inicio; n1 != 0; n = n->sig)
{
if (n1->etiqueta != 0)
{
for (a = n1->ady; a != 0; a = a->sig)

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 98/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
107
{
n2 = a->destino;
printf (“%3d -> %3d (%d)”, n1->etiqueta, n2->etiqueta, a->valor);
}
if (cont % 4)
printf (“,”);
else printf (“ \n ”);
cont++;}
}
if ((cont % 4) != 0)
printf (“ \n ”);
}
11.6. IMPLEMENTACIÓN DEL GRAFO
Existen diversas representaciones de naturaleza muy diferente que resultan adecuadas para
manejar un grafo,y en la mayoría de los casos no se puede decir que una sea mejor que otra
siempre ya que cada una puede resultar más adecuada dependiendo del problema concreto al
que se desea aplicar, así,si existe una representación que es peor que otra para todas las
operaciones excepto una es posible que aún así nos decantemos por la primera porque
precisamente esa operación es la única en la que tenemos especial interés en que se realice de
forma eficiente.
A continuación veremos dos de las representaciones más usuales:
11.6.1. MATRIZ DE ADYACENCIA
GRAFOS DIRIGIDOS
G=(V,A) un grafo dirigido con |V|=n .Se define la matriz de adyacencia o booleana asociada a G
como Bnxn con :
b i,j = { 1 si (i,j)
A, 0 en otro caso }
Como se puede ver se asocia cada fila y cada columna a un vértice y los elementos bi,j de la matriz
son 1 si existe el arco (i,j) y 0 en caso contrario.
GRAFOS NO DIRIGIDOS
G=(V,A) un grafo no dirigido con |V|=n .Se define la matriz de adyacencia o booleana asociada a
G como Bnxn con:
b i,i = { 1 si (i,j)
A, 0 en otro caso }
La matriz B es simétrica con 1 en las posiciones ij y ji si existe la arista (i,j).

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 99/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
108
Veamos ahora un ejemplo:
Si el grafo es etiquetado, entonces tanto bi,j como bi,j representan al coste o valor asociado al arco
(i,j) y se suelen denominar matrices de coste. Si el arco (i,j) no pertenece a A entonces se asignabi,j o bi,j un valor que no puede ser utilizado como una etiqueta valida.
La principal ventaja de la matriz de adyacencia es que el orden de eficiencia de las operaciones de
obtención de etiqueta de un arco o ver si dos vértices están conectados son independientes del
número de vértices y de arcos, por el contrario, existen dos grandes inconvenientes:
Es una representación orientada hacia grafos que no modifica el número de sus vértices ya
que una matriz no permite que se le o supriman filas o columnas.
Se puede producir un gran derroche de memoria en grafos poco densos (con gran número de
vértices y escaso número de arcos).
Para evitar estos inconvenientes se introduce otra representación: las listas de adyacencia.
11.6.2. LISTA DE ADYACENCIA
En esta estructura de datos la idea es asociar a cada vértice i del grafo una lista que contenga
todos aquellos vértices j que sean adyacentes a él. De esta forma sólo reservará memoria para los
arcos adyacentes a i y no para todos los posibles arcos que pudieran tener como origen i, el grafo,
por tanto, se representa por medio de un vector de n componentes (si |V|=n) donde cada
componente va a ser una lista de adyacencia correspondiente a cada uno de los vértices del
grafo. Cada elemento de la lista consta de un campo indicando el vértice adyacente. En caso deque el grafo sea etiquetado, habrá que añadir un segundo campo para mostrar el valor de la
etiqueta.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 100/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
109
Veamos un ejemplo a continuación:
Esta representación requiere un espacio proporcional a la suma del número de vértices, más el
número de arcos, y se suele usar cuando el número de arcos es mucho menor que el número de
arcos de un grafo completo. Una desventaja es que puede llevar un tiempo O(n) determinar si
existe un arco del vértice i al vértice j , ya que puede haber n vértices en la lista de adyacencia
asociada al vértice i.
Mediante el uso del vector de listas de adyacencias sólo se reserva memoria para los arcos
existentes en el grafo con el consiguiente ahorro de la misma, sin embargo, no permite que haya
vértices que puedan ser añadidos o suprimidos del grafo, debido a que la dimensión del grafo
debe ser predeterminado y fija.
Para solucionar esto se puede usar una lista de listas de adyacencia, sólo los vértices del grafo
que sean origen de algún arco aparecerán en la lista, de esta forma se pueden añadir y suprimir
arcos sin desperdicio de memoria ya que simplemente habrá que modificar la lista de listas para
reflejar los cambios.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 101/135
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 102/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
111
Vamos a ver la especificación tanto de la función de abstracción como del invariante de la
representación del grafo:
FUNCIÓN DE ABSTRACCIÓN
Dado el objeto del tipo rep r, r = {inicio, nnodos}, el objeto abstracto al que representa es:
g = < r.inicio, r.inicio->sig, r.inicio->sig->sig ..., r.inicio->sig... nnodos...->sig >
INVARIANTE DE REPRESENTACIÓN
0 <= r.nnodos < 5
De manera que la clase Grafo en C++ tendría el siguiente aspecto:
Class Grafo
{
Public:
struct nodo
{
Tbase etiqueta;
int nodo;
struct nodo *sig;
struct arco *ady;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 103/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
112
}
struct arco
{
int valor;
struct nodo *origen;
struct nodo *destino;
struct arco *sig;
}
struct nodo *inicio;
int nnodos;
Grafo ();
nodo LocalizaLabel (const Tbase e);
bool ExisteArco (nodo o, nodo d);
int GrafoVacio ();
float EtiqArco (nodo o, nodo d);
void InsertarNodo (const Tbase dato);
void InsertarArco (nodo o, nodo d, int valor);
void BorrarArco (nodo o, nodo d);
void DesconectarNodo (nodo a_eliminar);
void CopiarGrafo (Grafo gr);
~Grafo();
}
Debemos aclarar un par de cosas sobre la implementación en C++; sólo tenemos miembros
públicos para facilitar el acceso a los mismos de forma rápido, aunque esta no sea la filosofía más
apropiada tratándose de un lenguaje con orientación a objetos, esto se ha hecho así para
simplificar en gran medida tanto las primitivas como el código asociado a ellas ya que en laconfección de este tutorial no hemos tenido tiempo suficiente para hacer una clase Grafo como
dios manda.
Si se quiere hacer una clase grafo donde tengamos miembros privados como inicio y nnodos,
debemos elaborar primitivas que nos devuelvan cada elemento de una estructura nodo y arco en
este caso, serían muchas primitivas pequeñas, luego el resto (las que hemos elegido aquí) habría
que modificarlas en base a las nuevas primitivas elaboradas.
Pasemos ahora a ver la implementación de cada una de las primitivas enunciadas con
anterioridad en C++:
CODIGO EN C++
template <class Tbase>
Grafo<Tbase>::Grafo()
{
inicio = new nodo;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 104/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
113
inicio->etiqueta = 0;
inicio->nodo = 1;
inicio->ady = 0;
inicio->sig = 0;
}
template <class Tbase>
nodo Grafo<Tbase>::LocalizaLabel(const Tbase e)
{
nodo n;
int enc=0;
for (n=this.inicio; n!=0 && !enc; )
{
if (n->etiqueta == e)
enc = 1;
else
n = n->sig;
}
return n;
}
template <class Tbase>
bool Grafo<Tbase>::ExisteArco(nodo o, nodo d)
{
arco a;
a=o->ady;
while (a!=0)
{
if ((a->origen==o) && (a->destino==d))
return true;
else
a = a->sig;
}
return false;
}
template <class Tbase>
int Grafo<Tbase>::GrafoVacio()
{
return(this.inicio == 0);
}
template <class Tbase>
float Grafo<Tbase>::EtiqArco(nodo o, nodo d)
{
arco a;
a=o->ady;
while (a!=0)
{
if ((a->origen == o) && (a->destino == d))
return (a->valor);
else
a = a->sig;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 105/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
114
}
return 0;
}
template <class Tbase>
void Grafo<Tbase>::InsertarNodo(const Tbase dato)
{nodo aux,p;
aux = new nodo;
p=this.inicio;
while(p->sig != 0)
p = p->sig;
aux->etiqueta = dato;
aux->nodo = (p->nodo)+1;
aux->ady = 0;
aux->sig = 0;
p->sig = aux;
(this.nnodos)++;
}
template <class Tbase>
void Grafo<Tbase>::InsertarArco (nodo , nodo d, int valor)
{
arco aux;
aux = new arco;
aux->origen = o;
aux->destino = d;
aux->valor = valor;
aux->sig= o->ady;
o->ady = aux;
}
template <class Tbase>
void Grafo<Tbase>::BorrarArco(nodo o, nodo d)
{
arco a,ant;
int enc=0;
if (o->ady==0)
return;
else
if (o->ady->destino==d)
{
a = o->ady;
o->ady = a->sig;
delete a;
}
else {
ant = o->ady;
a = ant->sig;
while (!enc && (a!=0))
{
if (a->destino==d)

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 106/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
115
enc=1;
else {
a = a->sig;
ant = ant->sig;
}
}
if (a==0)return;
else {
ant->sig = a->sig;
delete a;
}
}
}
template <class Tbase>
Void Grafo<Tbase>::DesconectarNodo(nodo a_eliminar)
{
Grafo g_nd;
nodo n,org,dst,o,d;
arco a;
g_nd = new Grafo;
for (n=this.inicio; n!=0; n=n->sig)
g_nd.InsertarNodo(n->etiqueta);
for (n=this.inicio; n!=0; n=n->sig)
for (a=n->ady; a!=0; a=a->sig)
{
org = a->origen;
dst = a->destino;
o = g_nd.LocalizaLabel(org->etiqueta);
d = g_nd.LocalizaLabel(dst->etiqueta);
if ((org!=a_eliminar) && dst!=a_eliminar))
g_nd.InsertarArco(o,d,a->valor);
}
this.CopiarGrafo(g_nd);
}
template <class Tbase>
Void Grafo<Tbase>::CopiarGrafo(Grafo gr)
{
nodo n,org,dest,o,d;
arco a;
this.Destruir();
this = new Grafo;
for (n=gr.inicio; n!=0; n=n->sig)
this.InsertarNodo(n->etiqueta);
for (n=gr.inicio; n!=0; n=n->sig)
for (a=n->ady; a!=0; a=a->sig)
{
org = a->origen;
dest = a->destino;
o = g_nd.LocalizaLabel(org->etiqueta);
d = g_nd.LocalizaLabel(dest->etiqueta);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 107/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
116
this.InsertarArco(o,d,a->valor);
}
}
template <class Tbase>
Grafo<Tbase>::~Grafo()
{nodo n;
arco aux;
while ((this.inicio)->sig != 0)
{
n = (this.inicio)->sig;
while (n->ady != 0)
{
aux = n->ady;
n->ady = aux->sig;
delete aux;
}
(this.inicio)->sig = n->sig;
delete n;
}
delete (this.inicio);
}
12. MANEJO DE ARCHIVOSAsí como hemos revisado la salida y entrada por pantalla y teclado respectivamente, veremos
ahora la entrada y/o salida de datos utilizando ficheros, lo cual será imprescindible para un gran
número de aplicaciones que deseemos desarrollar.
12.1. FICHEROS
El estándar de C++ contiene varias funciones para la edición de ficheros, estas están definidas enla cabecera #include <cstdio> y por lo general empiezan con la letra f, haciendo referencia a file.
Adicionalmente se agrega un tipo FILE , el cual se usará como apuntador a la información del
fichero. La secuencia que usaremos para realizar operaciones será la siguiente:
Crear un apuntador del tipo FILE *
Abrir el archivo utilizando la función fopen y asignándole el resultado de la llamada a nuestro
apuntador.
Hacer las diversas operaciones (lectura, escritura, etc).
Cerrar el archivo utilizando la función fclose.
12.1.1. FOPENEsta función sirve para abrir y crear ficheros en disco.
El prototipo correspondiente de fopen es:
FILE * fopen (const char *filename, const char *opentype);
Los parámetros de entrada de fopen son:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 108/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
117
filename: una cadena que contiene un nombre de fichero válido.
opentype: especifica el tipo de fichero que se abrirá o se creará.
Una lista de parámetros opentype para la función fopen son:
"r”: Abrir un archivo para lectura, el fichero debe existir.
"w”: abrir un archivo para escritura, se crea si no existe o se sobre escribe si existe.
"a”: abrir un archivo para escritura al final del contenido, si no existe se crea.
"r+”: abrir un archivo para lectura y escritura, el fichero debe existir.
"w+”: crear un archivo para lectura y escritura, se crea si no existe o se sobre escribe si existe.
"r+b ó rb+”: Abre un archivo en modo binario para actualización (lectura y escritura).
"rb”: Abre un archivo en modo binario para lectura.
Adicionalmente hay tipos utilizando "b" (binary) los cuales no serán mostrados por ahora y
que solo se usan en los sistemas operativos que no pertenecen a la familia de Unix.
12.1.2 FCLOSE
Esta función sirve para poder cerrar un fichero que se ha abierto.
El prototipo correspondiente de fclose es:
int fclose (FILE *stream);
Un valor de retorno cero indica que el fichero ha sido correctamente cerrado, si ha habido
algún error, el valor de retorno es la constante EOF.
Un ejemplo pequeño para abrir y cerrar el archivo llamado fichero.in en modo lectura:
#include <iostream>
#include <cstdio>
using namespace std;
int main(int argc, char** argv)
{
FILE *fp;
fp = fopen ( "fichero.in", "r" );
fclose ( fp );
return 0;
}
Como vemos, en el ejemplo se utilizó el opentype "r", que es para la lectura.
Otra cosa importante es que el lenguaje C++ no tiene dentro de sí una estructura para el
manejo de excepciones o de errores, por eso es necesario comprobar que el archivo fue
abierto con éxito "if (fp == NULL)" . Si fopen pudo abrir el archivo con éxito devuelve la
referencia al archivo (FILE *), de lo contrario devuelve NULL y en este caso se deberá revisar
la dirección del archivo o los permisos del mismo. En estos ejemplos solo vamos a dar una
salida con un retorno de 1 que sirve para señalar que el programa termino por un error.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 109/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
118
12.1.3 FEOF
Esta función sirve para determinar si el cursor dentro del archivo encontró el final (end of
file). Existe otra forma de verificar el final del archivo que es comparar el carácter que trae
fgetc del archivo con el macro EOF declarado dentro de <cstdio>, pero este método no ofrece
la misma seguridad (en especial al tratar con los archivos "binarios"). La función feof siempre
devolverá cero (Falso) si no es encontrado EOF en el archivo, de lo contrario regresará un
valor distinto de cero (Verdadero).
El prototipo correspondiente de feof es:
int feof(FILE *fichero);
12.1.4 REWIND
Literalmente significa "rebobinar", sitúa el cursor de lectura/escritura al principio del archivo.
El prototipo correspondiente de rewind es:
void rewind(FILE *fichero);
12.2 LECTURA
Un archivo generalmente debe verse como un string (una cadena de caracteres) que está
guardado en el disco duro. Para trabajar con los archivos existen diferentes formas y diferentes
funciones. Las funciones que podríamos usar para leer un archivo son:
char fgetc(FILE *archivo)
char *fgets(char *buffer, int tamano, FILE *archivo)
size_t fread(void *puntero, size_t tamano, size_t cantidad, FILE *archivo);
int fscanf(FILE *fichero, const char *formato, argumento, ...);
Las primeras dos de estas funciones son muy parecidas entre sí. Pero la tercera, por el número yel tipo de parámetros, nos podemos dar cuenta de que es muy diferente, por eso la trataremos
aparte junto al fwrite que es su contraparte para escritura.
12.2.1 FGETC
Esta función lee un carácter a la vez del archivo que está siendo señalado con el puntero
*archivo. En caso de que la lectura sea exitosa devuelve el carácter leído y en caso de que no
lo sea o de encontrar el final del archivo devuelve EOF.
El prototipo correspondiente de fgetc es:
char fgetc(FILE *archivo);
Esta función se usa generalmente para recorrer archivos de texto. A manera de ejemplo
vamos a suponer que tenemos un archivo de texto llamado "prueba.txt" en el mismo
directorio en que se encuentra la fuente de nuestro programa. Un pequeño programa que lea
ese archivo será:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 110/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
119
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
int main(){
FILE *archivo;
char caracter;
archivo = fopen("prueba.txt","r");
if (archivo == NULL){
printf("\nError de apertura del archivo. \n\n");
}else
{
printf("\nEl contenido del archivo de prueba es \n\n");
while (feof(archivo) == 0)
{
caracter = fgetc(archivo);
printf("%c",caracter);
}
}
fclose(archivo);
return 0;
}
12.2.2 FGETSEsta función está diseñada para leer cadenas de caracteres. Leerá hasta n-1 caracteres o
hasta que lea un cambio de línea '\n' o un final de archivo EOF . En este último caso, el
carácter de cambio de línea '\n' también es leído.
El prototipo correspondiente de fgets es:
char *fgets(char *buffer, int tamaño, FILE *archivo);
El primer parámetro buffer lo hemos llamado así porque es un puntero a un espacio de
memoria del tipo char (podríamos usar un arreglo de char). El segundo parámetro es tamaño
que es el límite en cantidad de caracteres a leer para la función fgets. Y por último el punterodel archivo por supuesto que es la forma en que fgets sabrá a que archivo debe leer.
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 111/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
120
int main()
{
FILE *archivo;
char caracteres[100];
archivo = fopen("prueba.txt","r");
if (archivo == NULL)
exit(1);
printf("\nEl contenido del archivo de prueba es \n\n");
while (feof(archivo) == 0)
{
fgets(caracteres,100,archivo);
printf("%s",caracteres);
}
system("PAUSE");
fclose(archivo);
return 0;
}
Este es el mismo ejemplo de antes con la diferencia de que este hace uso de fgets en lugar de
fgetc. La función fgets se comporta de la siguiente manera, leerá del archivo apuntado por
archivo los caracteres que encuentre y a ponerlos en buffer hasta que lea un carácter menos
que la cantidad de caracteres especificada en tamaño o hasta que encuentre el final de una
línea (‘\n’) o hasta que encuentre el final del archivo (EOF). En este ejemplo no vamos a
profundizar más que para decir que caracteres es un buffer, los por menores serán explicados
en la sección de manejo dinámico de memoria.
El beneficio de esta función es que se puede obtener una línea completa a la vez.
12.2.3 FREAD
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
Esta función lee un bloque de una "stream" de datos. Efectúa la lectura de un arreglo de
elementos "count", cada uno de los cuales tiene un tamaño definido por "size". Luego los
guarda en el bloque de memoria especificado por "ptr". El indicador de posición de la cadena
de caracteres avanza hasta leer la totalidad de bytes. Si esto es exitoso la cantidad de bytes
leídos es (size*count).
PARAMETROS:
ptr : Puntero a un bloque de memoria con un tamaño mínimo de (size*count) bytes.
size : Tamaño en bytes de cada elemento (de los que voy a leer).
count : Número de elementos, los cuales tienen un tamaño "size".
stream: Puntero a objetos FILE, que especifica la cadena de entrada.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 112/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
121
12.2.4 FSCANF
La función fscanf funciona igual que scanf en cuanto a parámetros, pero la entrada se toma
de un fichero en lugar del teclado.
El prototipo correspondiente de fscanf es:
int fscanf(FILE *fichero, const char *formato, argumento, ...);
Podemos ver un ejemplo de su uso, abrimos el documento "fichero.txt" en modo lectura y
leyendo dentro de él.
#include <iostream>
#include <cstdio>
using namespace std;
int main ( int argc, char **argv )
{
FILE *fp;
char buffer[100];
fp = fopen ( "fichero.txt", "r" );
fscanf(fp, "%s" ,&buffer);
printf("%s",buffer);
fclose ( fp );
return 0;
}
12.3 ESCRITURA
Así como podemos leer datos desde un fichero, también se pueden crear y escribir ficheros con la
información que deseamos almacenar, Para trabajar con los archivos existen diferentes formas y
diferentes funciones. Las funciones que podríamos usar para escribir dentro de un archivo son:
int fputc(int caracter, FILE *archivo)
int fputs(const char *buffer, FILE *archivo)
size_t fwrite(void *puntero, size_t tamano, size_t cantidad, FILE *archivo);
int fprintf(FILE *archivo, const char *formato, argumento, ...);
12.3.1 FPUTC
Esta función escribe un carácter a la vez del archivo que está siendo señalado con el puntero
*archivo. El valor de retorno es el carácter escrito, si la operación fue completada con éxito,
en caso contrario será EOF.
El prototipo correspondiente de fputc es:

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 113/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
122
int fputc(int carácter, FILE *archivo);
Mostramos un ejemplo del uso de fputc en un "fichero.txt", se escribirá dentro del fichero
hasta que presionemos la Tecla Enter .
#include <iostream>
#include <cstdio>
using namespace std;
int main ( int argc, char **argv )
{
FILE *fp;
char caracter;
fp = fopen ( "fichero.txt", "r+" );
printf("\nIntrouce un texto al fichero: ");
while((caracter = getchar()) != '\n')
{
printf("%c", fputc(caracter, fp));
}
fclose ( fp );
return 0;
}
12.3.2 FPUTSLa función fputs escribe una cadena en un fichero. No se añade el carácter de retorno de línea
ni el carácter nulo final. El valor de retorno es un número no negativo o EOF en caso de error.
Los parámetros de entrada son la cadena a escribir y un puntero a la estructura FILE del
fichero donde se realizará la escritura.
El prototipo correspondiente de fputs es:
int fputs(const char *buffer, FILE *archivo)
Para ver su funcionamiento mostramos el siguiente ejemplo:
#include <iostream>
#include <cstdio>
using namespace std;
int main ( int argc, char **argv )
{
FILE *fp;
char cadena[] = "Mostrando el uso de fputs en un fichero.\n";

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 114/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
123
fp = fopen ( "fichero.txt", "r+" );
fputs( cadena, fp );
fclose ( fp );
return 0;}
12.3.3 FWRITE
Esta función está pensada para trabajar con registros de longitud constante y forma pareja
con fread . Es capaz de escribir hacia un fichero uno o varios registros de la misma longitud
almacenados a partir de una dirección de memoria determinada. El valor de retorno es el
número de registros escritos, no el número de bytes. Los parámetros son: un puntero a la
zona de memoria de donde se obtendrán los datos a escribir, el tamaño de cada registro, el
número de registros a escribir y un puntero a la estructura FILE del fichero al que se hará la
escritura.
El prototipo correspondiente de fwrite es:
size_t fwrite(void *puntero, size_t tamano, size_t cantidad, FILE *archivo);
Un ejemplo concreto del uso de fwrite con su contraparte fread y usando funciones es:/*
* FicheroCompleto.cpp
*
* Copyright 2012 Alain Wilfredo Fuentes Garcia
* Cel: 60413636
* E-mail: [email protected]>
*
*/
#include <iostream>
#include <cstdio>
using namespace std;
void menu();
void CrearFichero(FILE *Fichero);
void InsertarDatos(FILE *Fichero);
void VerDatos(FILE *Fichero);
struct sRegistro {
char Nombre[25];
int Edad;
float Sueldo;} registro;
int main()
{
int opcion;
int exit = 0;
FILE *fichero;
while (!exit)
{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 115/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
124
menu();
printf("\nOpcion: ");
scanf("%d", &opcion);
switch(opcion)
{
case 1:
CrearFichero(fichero);break;
case 2:
InsertarDatos(fichero);
break;
case 3:
VerDatos(fichero);
break;
case 4:
exit = 1;
break;
default:
printf("\n opcion no valida");
}
}
return 0;
}
void menu()
{
printf("\nMenu:");
printf("\n\t1. Crear fichero");
printf("\n\t2. Insertar datos");
printf("\n\t3. Ver datos");
printf("\n\t4. Salir");
}
void CrearFichero(FILE *Fichero)
{
Fichero = fopen("fichero", "r");
if(!Fichero)
{
Fichero = fopen("fichero", "w");
printf("\nArchivo creado!");
}
else
{
printf("\nEl fichero ya existe!");
}
fclose (Fichero);
return;}
void InsertarDatos(FILE *Fichero)
{
Fichero = fopen("fichero", "a+");
if(Fichero == NULL)
{
printf("\nFichero no existe! \nPor favor creelo");
return;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 116/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
125
}
printf("\nDigita el nombre: ");
scanf("%s", ®istro.Nombre);
printf("\nDigita la edad: ");
scanf("%d", ®istro.Edad);
printf("\nDigita el sueldo: ");
scanf("%f", ®istro.Sueldo);
fwrite(®istro, sizeof(struct sRegistro), 1, Fichero);
fclose(Fichero);
return;
}
void VerDatos(FILE *Fichero)
{
int numero = 1;
Fichero = fopen("fichero", "r");
if(Fichero == NULL)
{
printf("\nFichero no existe! \nPor favor creelo");
return;
}
fread(®istro, sizeof(struct sRegistro), 1, Fichero);
printf("\nNumero \tNombre \tEdad \tSueldo");
while(!feof(Fichero))
{
printf("\n%d \t%s \t%d \t%.2f", numero, registro.Nombre,
registro.Edad, registro.Sueldo);
fread(®istro, sizeof(struct sRegistro), 1, Fichero);
numero++;
}
fclose(Fichero);
return;
}
12.3.4 FPRINTF
La función fprintf funciona igual que printf en cuanto a parámetros, pero la salida se dirige a
un archivo en lugar de a la pantalla.
El prototipo correspondiente de fprintf es:int fprintf(FILE *archivo, const char *formato, argumento, ...);
Podemos ver un ejemplo de su uso, abrimos el documento "fichero.txt" en modo
lectura/escritura y escribimos dentro de él.
#include <iostream>
#include <cstdio>
using namespace std;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 117/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
126
int main ( int argc, char **argv )
{
FILE *fp;
char buffer[100] = "Esto es un texto dentro del fichero.";
fp = fopen ( "fichero.txt", "r+" );
fprintf(fp, buffer);
fprintf(fp, "%s", "\nEsto es otro texto dentro del fichero.");
fclose ( fp );
return 0;
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 118/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
127
SOLUCIONARIO PROBLEMAS PROPUESTOS
1. Diseñar un programa para calcular la suma de dos números A y B
#include <iostream>
using namespace std;
int main()
{
int a,b;
cout<<"Inserte primer valor: ";
cin>>a;
cout<<"Inserte segundo valor: ";
cin>>b;
cout<<endl<<"La Suma es: "<<a+b;
return 0 ;
}
2. Calcular el área de un triángulo de base B y altura H
#include <iostream>
using namespace std;
int main()
{
int b,h;
cout<<"Inserte Base: ";
cin>>b;
cout<<"Inserte Altura: ";
cin>>h;
cout<<"El area del triangulo es: "<<(b*h)/2<<endl;
return 0;
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 119/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
128
3. Calcular el área de un círculo de radio R
#include <iostream>
using namespace std;
int main()
{
int r;
cout<<"Inserte Radio: ";
cin>>r;
cout<<"El area de la circunferencia es:
"<<3.1416*(r*r)<<endl;
return 0;
}
4. Ingresar una nota por teclado y determinar si es de aprobación o reprobación
#include <iostream>
using namespace std;
int main()
{
int nota;
cout<<"LA NOTA MINIMA DE APROBACION ES DE 51"<<endl<<endl;
cout<<"Introduzca Nota: ";cin>>nota;
cout<<endl;
if (nota>=51)
cout<<"Es una nota de aprobacion";
else
cout<<"Es una nota de reprobacion";
return 0;
}
5. Ingresar un número por teclado y determinar si es PAR o IMPAR
#include <iostream>
using namespace std;
int main()
{
int num;
cout<<"Itroduzca un numero: ";

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 120/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
129
cin>>num;
cout<<endl;
if (num % 2==0)
cout<<"El numero introducido es par";
else
cout<<"El numero introducido es impar";
return 0;}
6. Determinar si una persona es "Niño – 1 a 10 años", "Adolescente – 11 a 17 años","Joven – 18 a 29 años", "Adulto – 30 a 60 años", "Tercera Edad – 60 a 100 años", deacuerdo a su edad que es introducida por teclado.
#include <iostream>
using namespace std;
int main()
{
int edad;
cout<<"Introduzca su edad para realizar el analisis: ";
cin>>edad;
cout<<endl;
if (edad <= 10)
cout<<"Es un Niño";
else if (edad <= 17)
cout<<"Es un Adolescente";
else if (edad <= 29)
cout<<"Es un joven";
else if (edad <= 60)
cout<<"Es una persona Adulta";
else if (edad <= 100)
cout<<"Es una persona de la Tercera Edad";
else
cout<<"MUCHAS FELICIDADES!!!";
return 0;
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 121/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
130
7. Generar Aleatoriamente dos números enteros entre 0 y 100. Determinar cuál es elmayor de ellos.
#include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int a,b;
srand(time(NULL));
a=rand()%101;
b=rand()%101;cout<<a<<" "<<b<<" "<<endl;
if (a<b)
cout<<a<<" Es menor";
else if (a>b)
cout<<a<<" Es mayor";
else if (b<a)
cout<<b<<" Es menor";
else
cout<<b<<" Es mayor";
return 0;
}
8. Introducir tres números por teclado. Determinar cuál es el mayor de los tres
#include <iostream>
using namespace std;
int main()
{
int a,b,c;cout<<"Primer valor: ";
cin>>a;
cout<<"Segundo valor: ";
cin>>b;
cout<<"Tercer valor: ";
cin>>c;
cout<<endl;
if (a>b)

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 122/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
131
{
if (a>c)
cout<<"El mayor es: "<<a;
else
cout<<"El mayor es: "<<c;
}
else{
if (b>c)
cout<<"El mayor es: "<<b;
else
cout<<"El mayor es: "<<c;
}
return 0;
}
9. Visualizar cuatro operaciones aritméticas de dos números cualesquiera introducidospor teclado.
#include <iostream>
using namespace std;
int main()
{
int a,b;
cout<<"Inserte primer valor: ";
cin>>a;
cout<<"Inserte segundo valor: ";
cin>>b;
cout<<endl<<endl;
cout<<"La Suma es: "<<a+b<<endl;
cout<<"La Resta es: "<<a-b<<endl;
cout<<"El producto es: "<<a*b<<endl;
cout<<"La division es: "<<a/b<<endl;
return 0;
}
10. Ingresar un número cualquiera, determina si es POSITIVO, NEGATIVO ó CERO
#include <iostream>
using namespace std;
int main()
{
int num;

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 123/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
132
cout<<"Introduzca numero: ";
cin>>num;
if (num==0)
cout<<"Es cero";
else if (num<0)
cout<<"Es un numero negativo";
elsecout<<"Es positivo";
return 0;
}
11. Generar un numero aleatoriamente entre 1 a 1000 y determinar si es PAR o IMPAR
#include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int a;
srand(time(NULL));
a=1+rand()%(1001-1);
cout<<a<<endl<<endl;
if (a%2==0)
cout<<"Es par";else
cout<<"Es impar";
return 0;
}
12. Introducir un número positivo por teclado. Si es negativo o cero rechazarlo, casocontrario, determinar si el número positivo es par o impar
#include <iostream>
using namespace std;
int main()
{
int n;
cout<<"Inserte numero: ";
while (cin>>n && n!=0 && n>0)
{

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 124/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
133
if (n%2==0)
cout<<"Es par"<<endl;
else
cout<<"Es impar"<<endl;
}
return 0;
}
13. Ingresar un número por teclado y determinar si es múltiplo de 10
#include <iostream>
using namespace std;
int main()
{
int n;
cout<<"Inserte numero: ";
cin>>n;
cout<<endl;
if (n%10==0)
cout<<"Es multiplo de 10"<<endl;
else
cout<<"No es multiplo de 10"<<endl;
return 0;
}
14. Ingresar una nota por teclado y determinar su grado de aprovechamiento (0-10)
Pésimo, (11-20) Muy Malo, (21-30) Malo, (31-40) regular, (41-50) Bueno, (51-60) MuyBueno, (61-70) Excelente
#include <iostream>
using namespace std;
int main()
{
int nota;
cout<<"Introduzca su nota para realizar el analisis: ";
cin>>nota;cout<<endl;
if (nota <= 10)
cout<<"Es una nota Pesima";
else if (nota <= 20)
cout<<"Es una nota Muy mala";
else if (nota <= 30)
cout<<"Es una nota Mala";
else if (nota <= 40)

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 125/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
134
cout<<"Es una nota Regular";
else if (nota <= 50)
cout<<"Es una nota Buena";
else if (nota <= 60)
cout<<"Es una nota Muy buena";
else if (nota <= 70)
cout<<"Es una nota Excelente";else
cout<<"No me mientas!!!";
return 0;
}
15. Simular un juego con un dado. Si se saca un 1 o un 6 e gana, caso contrario se pierde.
#include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int d;
srand(time(NULL));
d=1+rand()%(7-1);
cout<<d<<endl;
if(d==1 || d==6)
cout<<"Usted Gano!!!";
else
cout<<"Usted Perdio!!!!";return 0;
}
16. Simular un juego con dos dados. Si se saca un siete o un once se gana, caso contrario sepierde.
#include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int d1,d2;
srand(time(NULL));
d1=1+rand()%(7-1);
d2=1+rand()%(7-1);

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 126/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
135
cout<<"Dado 1: "<<d1<<endl<<"Dado 2: "<<d2<<endl;
if((d1+d2==7)||(d1+d2==11))
cout<<"Usted Gano!!!";
else
cout<<"Usted Perdio!!!!";
return 0;
}
17. Visualizar la serie 1,3,5,7,…….n
#include <iostream>
using namespace std;
int main()
{
int r;
cout<<"Inserte el tamaño de la Serie: ";
cin>>r;
for (int i=1;i<=r;i++)
{
cout<<(i*2)-1<<" ";
}
return 0;
}
18. Visualizar la serie 1,4,7,10,13,16……..n
#include <iostream>
using namespace std;
int main()
{
int r;
cout<<"Inserte el tamaño de la Serie: ";
cin>>r;
for (int i=1;i<=r;i++)
{
cout<<(i*3)-2<<" ";}
return 0;
}

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 127/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
136
19. Ingresar un número y visualizar su tabla de multiplicar
#include <iostream>
using namespace std;
int main()
{
int num;
cout<<"Inserte el numero que desa generar la
tabla"<<endl;
cin>>num;
for (int i=1;i<=10;i++)
{
cout<<num<<" * "<<i<<" = "<<num*i<<endl;
}
return 0;
}
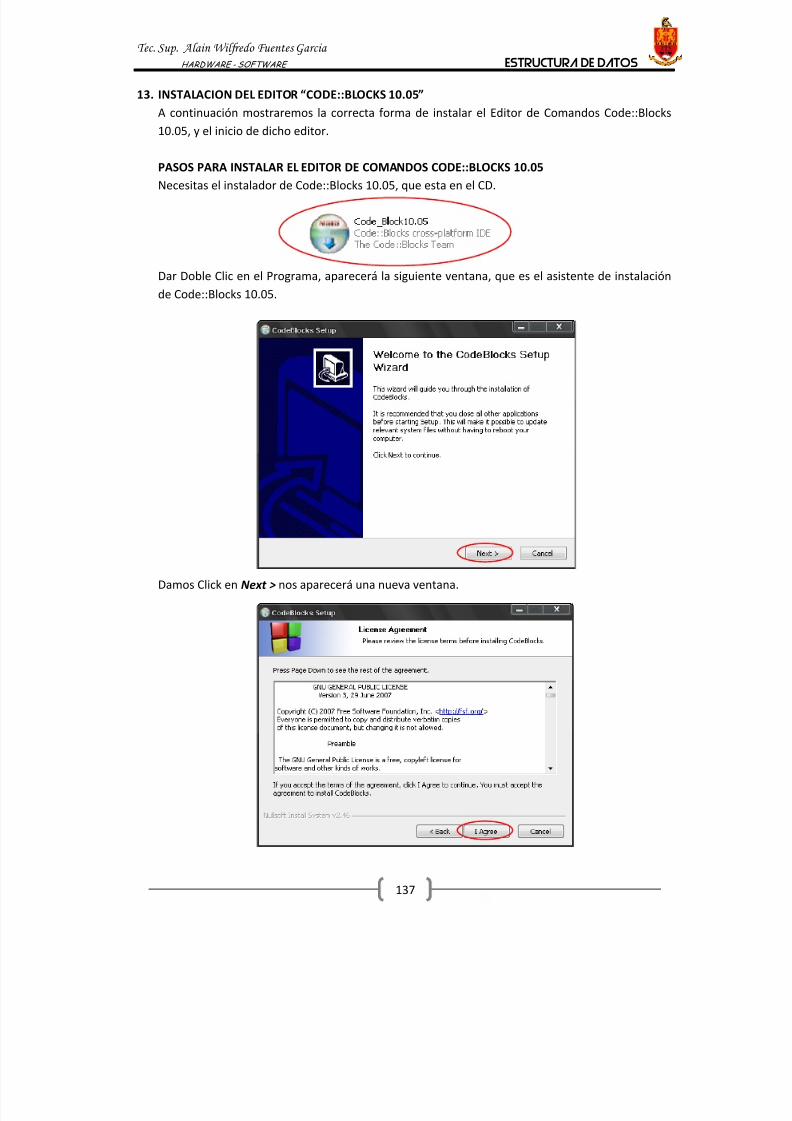
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 128/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
137
13. INSTALACION DEL EDITOR “CODE::BLOCKS 10.05”
A continuación mostraremos la correcta forma de instalar el Editor de Comandos Code::Blocks
10.05, y el inicio de dicho editor.
PASOS PARA INSTALAR EL EDITOR DE COMANDOS CODE::BLOCKS 10.05
Necesitas el instalador de Code::Blocks 10.05, que esta en el CD.
Dar Doble Clic en el Programa, aparecerá la siguiente ventana, que es el asistente de instalación
de Code::Blocks 10.05.
Damos Click en Next > nos aparecerá una nueva ventana.
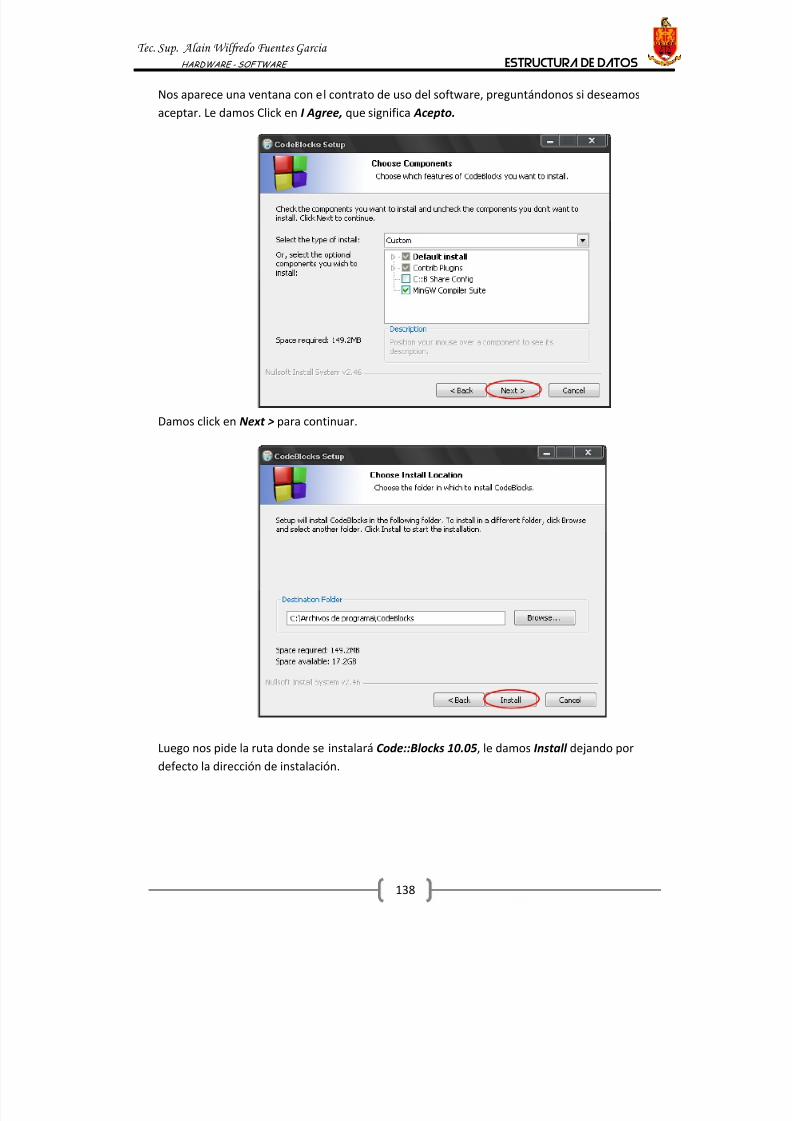
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 129/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
138
Nos aparece una ventana con el contrato de uso del software, preguntándonos si deseamos
aceptar. Le damos Click en I Agree, que significa Acepto.
Damos click en Next > para continuar.
Luego nos pide la ruta donde se instalará Code::Blocks 10.05, le damos Install dejando por
defecto la dirección de instalación.
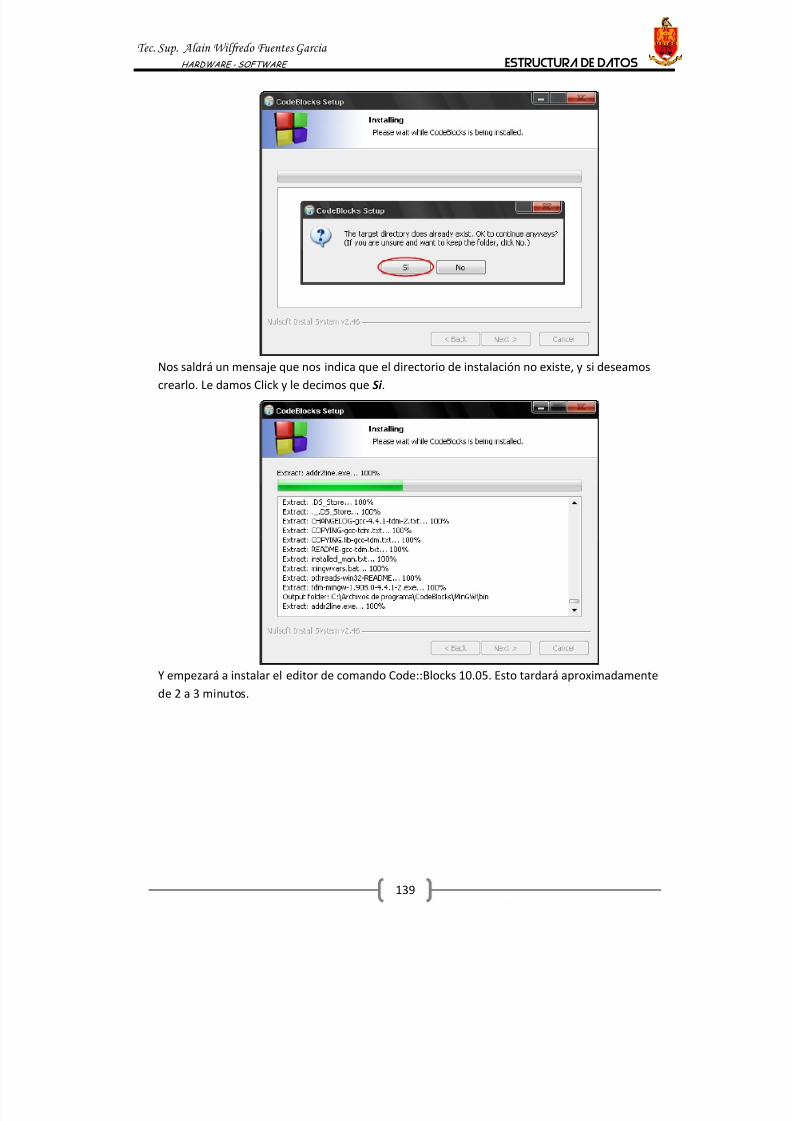
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 130/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
139
Nos saldrá un mensaje que nos indica que el directorio de instalación no existe, y si deseamos
crearlo. Le damos Click y le decimos que Si .
Y empezará a instalar el editor de comando Code::Blocks 10.05. Esto tardará aproximadamente
de 2 a 3 minutos.
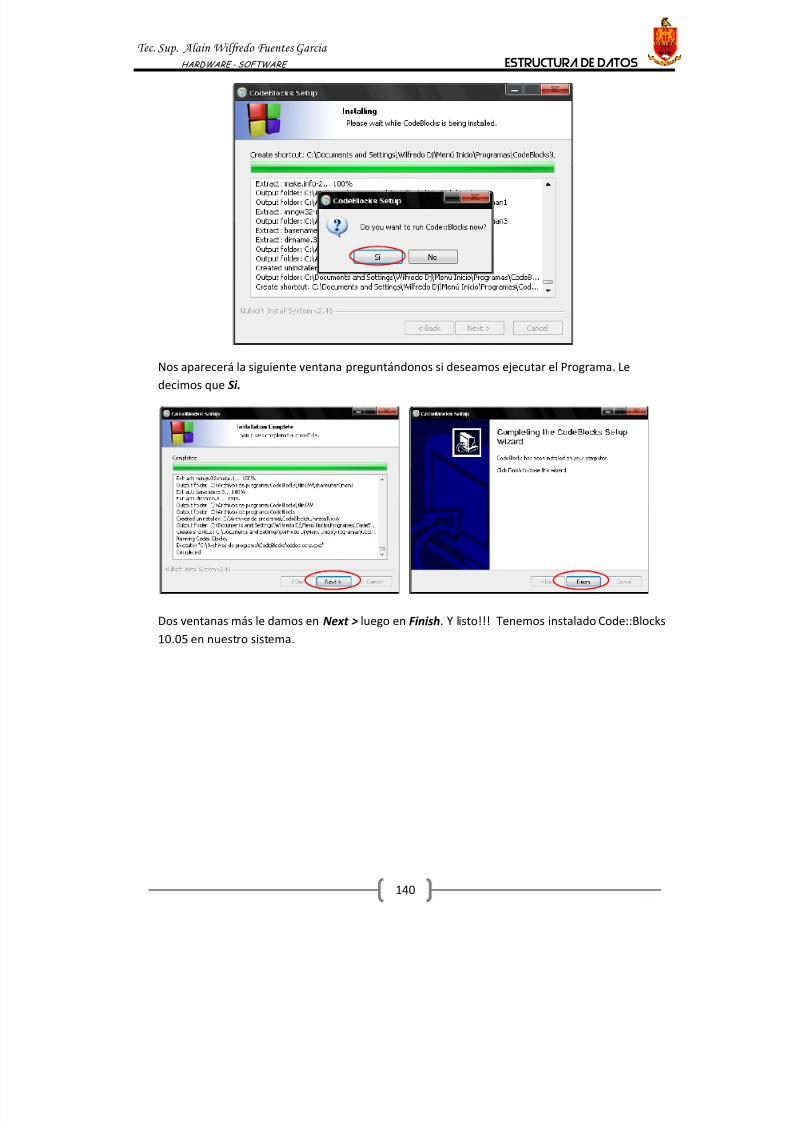
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 131/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
140
Nos aparecerá la siguiente ventana preguntándonos si deseamos ejecutar el Programa. Le
decimos que Si.
Dos ventanas más le damos en Next > luego en Finish. Y listo!!! Tenemos instalado Code::Blocks
10.05 en nuestro sistema.
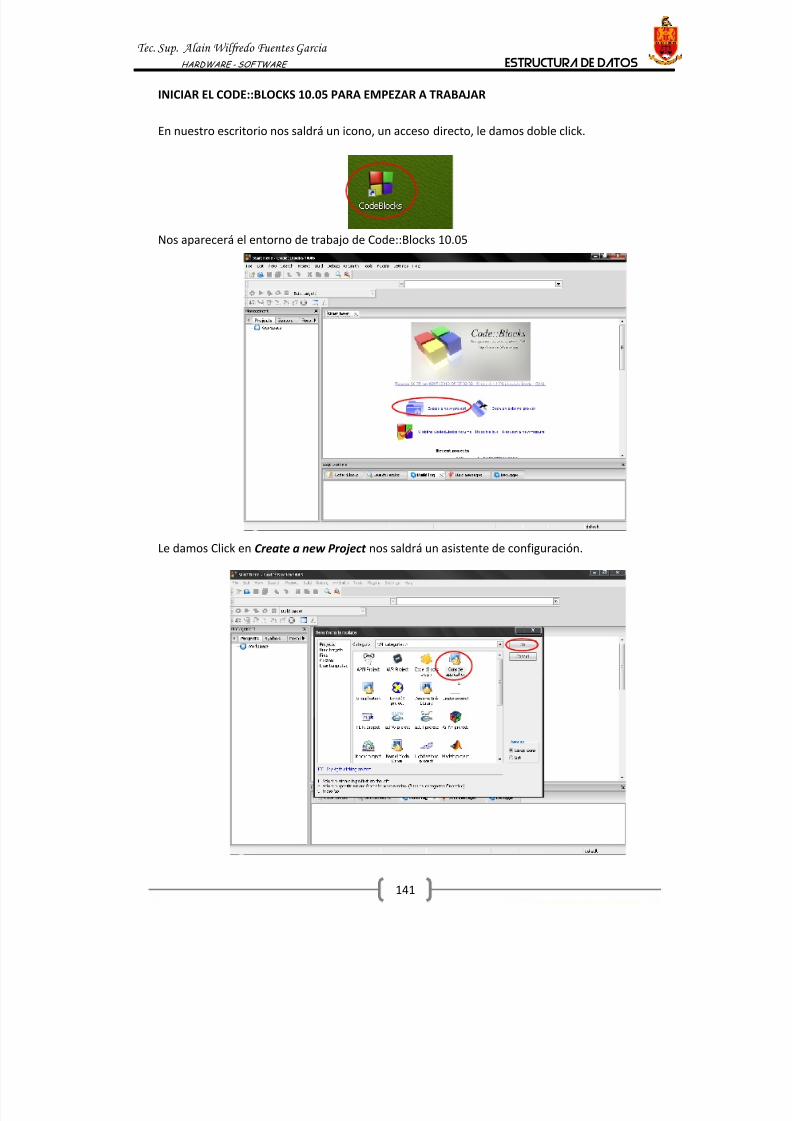
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 132/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
141
INICIAR EL CODE::BLOCKS 10.05 PARA EMPEZAR A TRABAJAR
En nuestro escritorio nos saldrá un icono, un acceso directo, le damos doble click.
Nos aparecerá el entorno de trabajo de Code::Blocks 10.05
Le damos Click en Create a new Project nos saldrá un asistente de configuración.
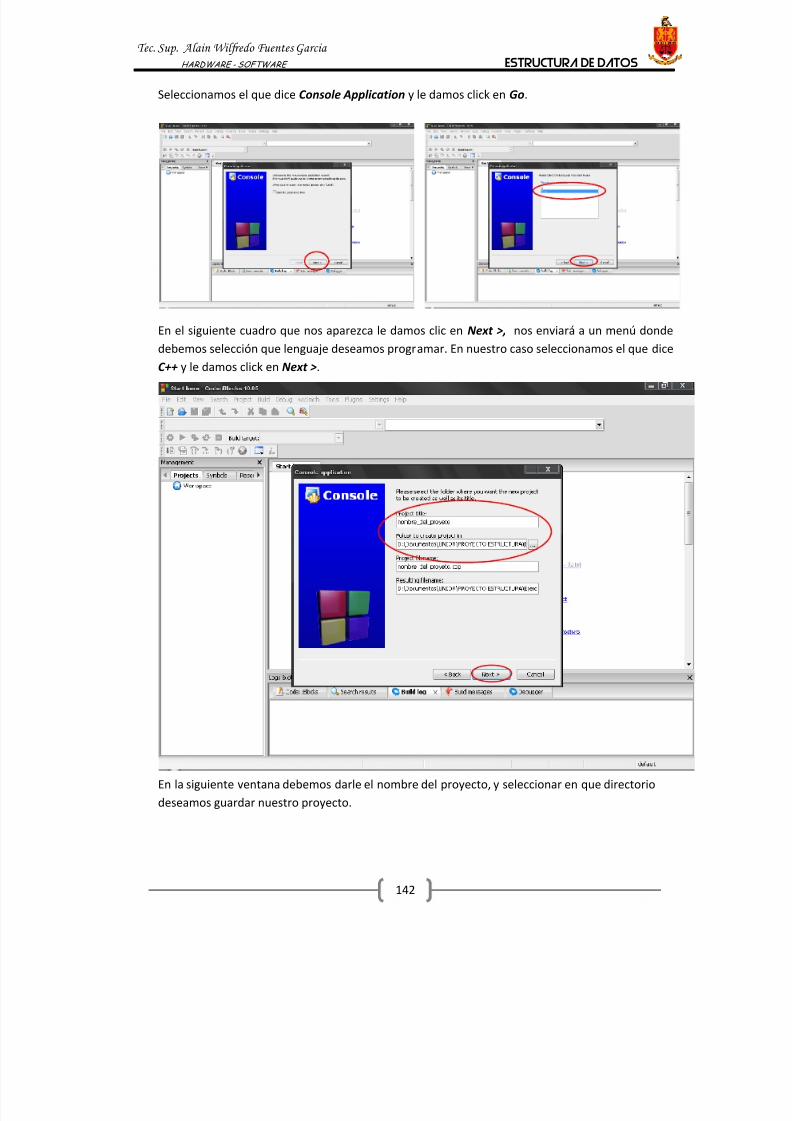
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 133/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
142
Seleccionamos el que dice Console Application y le damos click en Go.
En el siguiente cuadro que nos aparezca le damos clic en Next >, nos enviará a un menú donde
debemos selección que lenguaje deseamos programar. En nuestro caso seleccionamos el que dice
C++ y le damos click en Next >.
En la siguiente ventana debemos darle el nombre del proyecto, y seleccionar en que directorio
deseamos guardar nuestro proyecto.
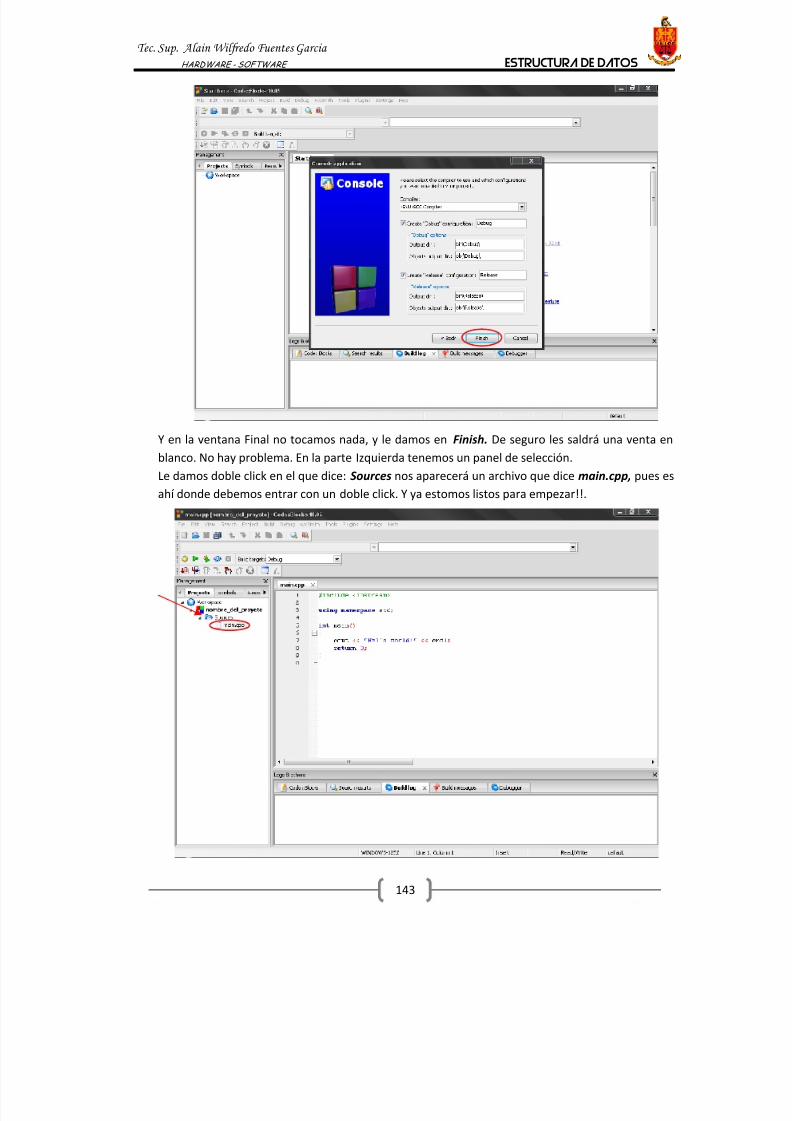
8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 134/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
143
Y en la ventana Final no tocamos nada, y le damos en Finish. De seguro les saldrá una venta en
blanco. No hay problema. En la parte Izquierda tenemos un panel de selección.
Le damos doble click en el que dice: Sources nos aparecerá un archivo que dice main.cpp, pues es
ahí donde debemos entrar con un doble click. Y ya estomos listos para empezar!!.

8/19/2019 Libro - Estructura de Datos
http://slidepdf.com/reader/full/libro-estructura-de-datos 135/135
Tec. Sup. Alain Wilfredo Fuentes Garcia
HARDWARE - SOFTWARE ESTRUCTURA DE DATOS
I LIOGR FI
Luis Joyanes Aguilar Fundamentos de Programación 3ra Edición
Freddy Zambrana Rodriguez Problemas Codificados en Pascal y C++
Rufino Goñi Lasheras Aprenda Lenguaje ANCI C
Deitel & Deitel Como Programas en C++
Jorge Humberto Terán Fundamentos de la Programación
Schaum’s Outline Programming with C++
Addison Wesley Accelerated C++
Sitio Web en Internet http://c.conclase.net









