Embed Size (px)
Citation preview

Monografía Científica
Autores: J. G. Viera Santana, J. Portillo Meniz, D. Rodríguez Esparragón, J. C. Hernández Haddad y J. Castillo Ortiz
Universidad de Las Palmas de Gran Canaria
2007

Monografía Científica © José Guillermo Viera Santana, Jorge Portillo Meniz, Dionisio Rodríguez Esparragón, Juan Carlos Hernández Haddad y Jesús Castillo Ortiz. Las Palmas, 2007.

Índice de contenidos.
Digitalización y compresión de la señal de Televisión
I

Índice de contenidos.
Digitalización y compresión de la señal de Televisión
II
Índice de contenidos
Capítulo I. Introducción. 1
1.1. Reseña histórica. 2
1.2. La TV Digital y sus ventajas. 4
Capítulo II. Introducción a la televisión digital. 6
2.1. Introducción 7
2.2. Muestreo 7
2.2.1. Aliasing 9
2.3. Cuantificación 10
2.4. Codificación 12
2.4.1. Formato de codificación. 13
2.4.1.1 Codificación de las señales compuestas. 13
2.4.1.2. Codificación de componentes. 14
2.5. La norma UER-SMPTE-OIRT. 15
2.5.1. Señales codificadas. 16
2.5.2. La frecuencia de muestreo. 16

Índice de contenidos.
Digitalización y compresión de difusión de la señal de Televisión
III
Capítulo III. Fundamentos de la Compresión de Video MPEG-2. 21
3.1. Introducción. 22
3.2. Entropía y redundancia. 22
3.3. Codificación de Longitud Variable (VLC). 24
3.3.1. Codificación de Huffman. 24
3.3.2. Codificación Run Length. 26
3.4. Compresión MPEG-2. 27
3.5. Redundancia espacial. 27
3.5.1. Codificación espacial. 28
3.5.1.1. La Transformada del Coseno Discreto. 29
3.5.1.2. Cuantificación. 30
3.5.1.3. Codificación por Entropía. 32
3.6. Redundancia temporal. 32
3.6.1. Codificación temporal 33
3.7. Redundancia estadística. 35
3.8. Codificador hibrido DCT/DPCM. 35
3.9. Compensación de Movimiento. 36
3.10. Imágenes en MPEG-2. 38
3.10.1. Imágenes I. 38
3.10.2. Imágenes P. 39
3.10.3. Imágenes B. 39
3.11. Codificación en forma entrelazada o progresiva. 39
3.12. Estructura por cuadro y campo. 40
3.13. Secuencia de imágenes en MPEG-2. 42
3.14. La estructura 4:4:4. 43
3.15. La estructura 4:2:2. 44
3.16. La estructura 4:2:0. 45
Capítulo IV. Procesos en la Compresión de Vídeo MPEG-2. 47
4.1. Introducción. 48
4.2. Procesos en la Compresión de Video MPEG-2. 48
4.3. El proceso DCT (Transformada del Coseno Discreto). 50
4.4. Barrido en Zig Zag. 58
4.5. Diagrama de un Codificador MPEG-2. 59

Índice de contenidos.
Digitalización y compresión de difusión de la señal de Televisión
IV
4.6. Diagrama de un Decodificador MPEG-2 61
Capítulo V. Estándar MPEG-2. 63
5.1. Introducción. 64
5.2. Características principales del estándar de vídeo MPEG-2. 65
5.3. Perfiles y Niveles en MPEG-2. 67
5.4. Codificación MPEG-2 de Audio. 70
5.4.1. Principios de la compresión de audio MPEG. 71
5.4.2. Las capas de la codificación de audio MPEG. 74
5.4.3. Formato general de la trama MPEG de audio. 76
Capítulo VI. Múltiplex y Flujo de Transporte MPEG-2. 78
6.1. Introducción. 79
6.2. Empaquetado PES. (Packetized Elementary Stream). 80
6.2.1. PES- Packet Header. 81
6.3. Múltiplex tipo “PROGRAM STREAM”. 85
6.4. Múltiplex tipo “TRANSPORT STREAM”. 87
6.4.1. Formación del “Transport Stream” 88
6.4.2. “Transport Packet” 89
6.4.2.1. Transport Packet Header. 90
6.5. Tabla de Asociación de Programas (PAT) y Tabla de Mapa de Programas (PMT).
91
6.6. Resumen de la formación del Flujo Transporte. 94
Capítulo VIII. Bibliografía. 97
8.1. Introducción. 98
8.2. Bibliografía. 98
8.3. Direcciones WEB. 99

Capítulo 1. Introducción.
Digitalización y compresión de la señal de Televisión
1
Capítulo I:

Capítulo 1. Introducción.
Digitalización y compresión de la señal de Televisión
2
CAPÍTULO 1. Introducción
1.1. Reseña histórica
Desde hace ya algunas décadas, la tecnología digital se ha ido implantando en
muchos de los campos del mundo de las telecomunicaciones y, el que aún hoy sigue
siendo el principal medio de comunicaciones del mundo, la televisión, no se podía
quedar atrás, ya que son cuantiosas las ventajas que ofrece la llamada Televisión Digital
frente a la tradicional Analógica.
Podemos diferenciar dentro de un esquema general de la televisión, tres campos
a los que la tecnología digital ha afectado de distinta forma y en diferentes etapas:
Producción. Comprende aquellos pasos anteriores a que la señal salga del
estudio (toma de imágenes, grabación, edición, postproducción, etc.)
Transmisión. La señal se traslada desde el estudio (centro de producción) hasta
repetidores primarios.
Difusión. La señal llega al público.
Así pues, la primera etapa en digitalizarse fue, sin lugar a dudas, la de producción,
ya que, por otra parte es la más susceptible a cambios (mientras a los usuarios no se les

Capítulo 1. Introducción.
Digitalización y compresión de la señal de Televisión
3
hiciera cambiar nada y la recepción de señal siguiera siendo analógica, da lo mismo
cómo se cree en el estudio). En cuanto a la transmisión se comenzó por la transmisión
digital del sonido, siendo la difusión (o radiodifusión) la última de las etapas en
convertirse a digital.
También cabe diferenciar entre los diferentes sistemas de transmisión, ya que no
ha ido al mismo ritmo la digitalización en TV vía cable, vía satélite o TV Terrestre, pero
no nos detendremos en el estudio cronológico de implantación, sino en las técnicas
utilizadas para conseguir la viabilidad de estos sistemas. Estos sistemas de trasmisión de
televisión digital quedan englobados para Europa en el proyecto DVB, “Digital Video
Broadcasting” (DVB-C para cable, DVB-S para satélite y DVB-T en el caso de la
terrestre), el cual ha tomado como estándar de codificación digital el MPEG-2 que será
tratado con profundidad más adelante.
De lo que no cabe duda es que el paso a TV Digital se ha convertido en uno de
los acontecimientos más importantes en área tecnológica del comienzo de este milenio.
Los primeros pasos que han permitido que las emisiones de televisión digital
sean una realidad podemos fijarlos allá por el año 1987, cuando se crea el JPEG (Joint
Photographic Experts Group) por parte de la Organización de Estandarización
Internacional (ISO) y por la Comisión Electrotécnica Internacional (IEC) y cuyo
director fue Hiroshi Yoshuda. La finalidad de este grupo de expertos era crear un
estándar que permitiera disminuir la cantidad de espacio de almacenamiento requerido
para las imágenes fijas. Ese mismo año, Leonardo Chiariglione, uno de los asistentes al
encuentro JPEG, propone a Yoshuda la creación de otro grupo que se encargara de
estandarizar la codificación digital de las imágenes en movimiento. Es así como surge el
año siguiente, 1988, Comité Técnico Unido sobre Tecnologías de la Información,
Subcomité 29, Grupo de Trabajo 11 (ISO/IEC JTC1/SC29/WG11), más conocido como
MPEG (Moving Pictures Experts Group), bajo la dirección de Chiariglione y también
bajo la tutela de las organizaciones ISO/IEC. La misión, entonces, de este nuevo grupo,
era el desarrollo de estándares para la representación codificada de imágenes en
movimiento, la información del audio adjunta a ella, y su combinación para la grabación
y lectura en un medio de almacenamiento digital. El equipo comenzó su andadura con
12 miembros y no fue hasta casi cinco años después cuando, en 1993, salió a la luz su

Capítulo 1. Introducción.
Digitalización y compresión de la señal de Televisión
4
primer gran resultado, el MPEG (ó MPEG-1, ya que en el año siguiente saldría el
llamado MPEG-2).
Las diferencias entre estos dos estándares se verán a lo largo del trabajo punto
por punto, pero se puede adelantar que el primero hacía un tratamiento estático de la
imagen (aunque utiliza tanto compresión espacial, dentro de una misma imagen, como
compresión temporal, entre imágenes sucesivas), el cual obtuvo su mayor aplicación en
los CD-I y VCD (CD interactivos y video CD, no en transmisión de imágenes, sino en
su tratamiento y almacenamiento). En cuanto al MPEG-2 se puede decir que en cierta
forma completa a su predecesor y permite aplicaciones con vistas a la televisión, siendo,
de hecho, la elección del proyecto europeo ya mencionado DVB (que se estaba
desarrollando paralelamente) como estándar de codificación. Este proyecto tiene unas
recoge características específicas de cómo transmitir las señales digitales
(modulaciones, etc.) que en ningún momento pasaremos a nombrar aquí, ya que eso es
digno de ser desarrollado en otros trabajos, limitándonos aquí al proceso de
digitalización y compresión anterior a la difusión de la señal.
1.2. La TV Digital y sus ventajas.
En un tema tan en boga como la implantación de la TV digital, no es difícil
encontrar mucha información por diversos medios, pero a veces esa información no está
dada por personas expertas y puede llevar a confusión y ambigüedades.
Hasta el momento en nuestro país, hemos tenido siempre una televisión terrestre
analógica y está previsto el apagón analógico (fin de emisiones de televisión analógicas)
en el año 2010. Otra cuestión son las plataformas digitales que desde 1997 tenemos por
medio de Vía Digital y Canal Satélite Digital (DVB-S). La implantación de estos
sistemas se hace realmente atrayente por una serie de ventajas, de las cuales
mencionamos las más significativas.
Permite transmitir varios programas ocupando el mismo espectro que utiliza la
TV tradicional analógica para la transmisión de uno sólo (el cual ocupa casi

Capítulo 1. Introducción.
Digitalización y compresión de la señal de Televisión
5
todo el canal). Esto es así gracias a la compresión de la señal, que en el caso
analógico era imposible.
Asimismo, permite acompañar la imagen de muchos más canales de sonido
(con la posibilidad, por ejemplo, de recibir distintos idiomas de un mismo
programa).
La definición de la imagen mejora notablemente evitando las interferencias y
pérdidas en la señal durante su transmisión (señal prácticamente exenta de
ruido).
Los servicios Multimedia que se pueden desarrollar son innumerables (acceso a
INTERNET, interoperatividad del usuario, etc.).
Posibilidad de transmisión de múltiples datos auxiliares (el teletexto de los
canales analógicos se nos queda verdaderamente pobre ante de las posibilidades
de información en la TV Digital)
Creación de efectos de 2D y 3D y otros efectos especiales en la imagen
imposibles de imaginar con un sistema analógico.
Realizar múltiples copias de las señales sin degradación alguna (muy útil en los
estudios).
Posibilidad de estandarización a nivel internacional de esta nueva realidad para
una mayor compatibilidad entre países que en la TV analógica (lo cual se ha
conseguido, al menos en la digitalización, aunque no en la transmisión Ej.: el
proyecto DVB está “sólo” vigente en Europa).

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
6
Capítulo II:

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
7
CAPÍTULO 2. Digitalización de la señal de televisión.
2.1. Introducción.
La introducción de la televisión digital permite obtener una notable mejora en la
calidad de la señal de televisión. Se mejora en la calidad de la señal de transmisión, el
tratamiento de la imagen y la multicopia magnética.
La digitalización es el proceso a través del cual se obtiene una señal de
naturaleza digital a partir de una señal analógica. El proceso es el mismo para cualquier
tipo de señal (audio, vídeo, etc...). Esta operación se realiza en tres pasos bien
diferenciados los cuales se detallan a continuación.
2.2. Muestreo.
Con esta operación se consigue obtener niveles de la señal analógica en
intervalos regulares de tiempo, es decir, se toma una muestra. El dispositivo que
muestrea la señal se compone de dos elementos, un circuito que mantiene y genera las
muestras, y un reloj que define los instantes en que las muestras son obtenidas.

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
8
Analíticamente esta operación equivale a multiplicar la señal analógica por un tren de
impulsos, los cuales se modulan en amplitud por la amplitud de la señal analógica.
Esta operación se ilustra detalladamente en el siguiente ejemplo:
Señal analógica: Señal muestreadora (tren de impulsos):
Figura 2.1. Señal a muestrear. Figura 2.2. Señal muestreadora.
Señal muestreada PAM (Pulse Amplitud Modulated):
Figura 2 .3. Señal muestreada.
En el dominio de la frecuencia el muestreo equivale a obtener una réplica del
espectro de la señal analógica ubicado en cada una de las frecuencias múltiplas de la
frecuencia de muestreo:
Figura 2.4. Representación espectral de efecto del muestreo.
)2cos(2
)sen()( wtAwtAte ⋅−⋅=
E (t)
Señal P. A. M.
E (f) S (f)
Bw BwFs Fs2·Fs 2·Fs
S (f)M
S (t)
∑+∞
−∞=
−=n
nTtts )()( δ

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
9
En este proceso aparece un parámetro fundamental que definirá la transmisión
de la señal. Éste es la frecuencia de muestreo.
En la práctica no se pueden utilizar velocidades de muestreo
indiscriminadamente altas, ya que ésta determina la cantidad de información que se
envía por segundo, y por tanto el ancho de banda necesario para su transmisión.
En cualquier canal de transmisión, el costo por Mhz es elevadísimo, resulta pues
fundamental conocer cual es la frecuencia de muestreo mínima para poder enviar la
señal con garantía de su correcta reconstrucción.
Nyquist estudió esta problemática y determinó a partir del análisis del espectro
de la señal muestreada que la frecuencia mínima de muestreo debe ser el doble del
ancho de banda de la señal a muestrear, para poder recuperar de forma íntegramente la
señal original a partir de la señal muestreada.
2.2.1. Aliasing.
El efecto de “aliasing”, se produce cuando se utiliza una frecuencia de muestreo
inferior al doble del ancho de banda de la señal a muestrear, o sea, cuando no se cumple
el Criterio de Nyquist. Este efecto provoca un solapamiento entre los espectros de
muestras consecutivas, impidiendo la recuperación de la señal original
El aliasing es un efecto indeseable, causante de que señales continúas distintas
se tornen indistinguibles cuando se les muestrea digitalmente. Su efecto se traduce en
un solapamiento entre muestras diferentes de la señal. Cuando esto sucede, la señal
original no puede ser reconstruida de forma unívoca a partir de la señal digital.
Figura 2.6. Frecuencia de muestreo ≥ 2 * BW No aliasing
No hay solapamiento entre muestras Figura 2.5. Señal en banda
Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
10
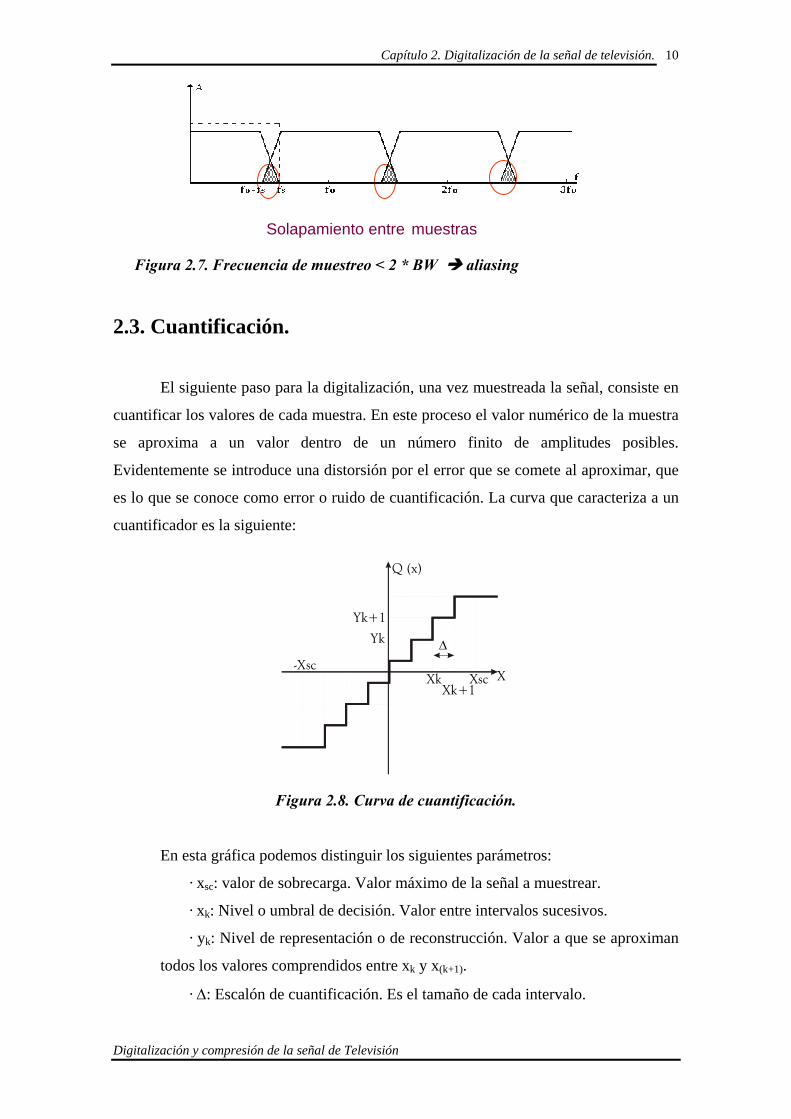
2.3. Cuantificación.
El siguiente paso para la digitalización, una vez muestreada la señal, consiste en
cuantificar los valores de cada muestra. En este proceso el valor numérico de la muestra
se aproxima a un valor dentro de un número finito de amplitudes posibles.
Evidentemente se introduce una distorsión por el error que se comete al aproximar, que
es lo que se conoce como error o ruido de cuantificación. La curva que caracteriza a un
cuantificador es la siguiente:
Figura 2.8. Curva de cuantificación.
En esta gráfica podemos distinguir los siguientes parámetros:
· xsc: valor de sobrecarga. Valor máximo de la señal a muestrear.
· xk: Nivel o umbral de decisión. Valor entre intervalos sucesivos.
· yk: Nivel de representación o de reconstrucción. Valor a que se aproximan
todos los valores comprendidos entre xk y x(k+1).
· ∆: Escalón de cuantificación. Es el tamaño de cada intervalo.
Q (x)
XXsc-Xsc
XkXk+1
Yk
Yk+1
∆
Figura 2.7. Frecuencia de muestreo < 2 * BW aliasing
Solapamiento entre muestras

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
11
Como cada nivel de reconstrucción se va a representar mediante un código
binario, el número de niveles será siempre una potencia de 2, de forma que:
L = 2n es el número de niveles; n = log2·L es el número de bits
Hay un error inherente al proceso de cuantificación que se define como la
diferencia entre la entrada y la salida del cuantificador:
q = x-Q(x) donde qmax = ± ∆/2
Cuando los valores de las muestras a la entrada varían con el tiempo, la
diferencia q(t)=x(t)-Q[x(t)] se conoce como ruido de fondo.
Un parámetro importante en este proceso es la relación señal a ruido (SNR) de
cuantificación que se define como:
Se admite generalmente que un valor aceptable para la relación señal a ruido de
una señal de vídeo es de 45 dB.
La cuantificación puede ser uniforme o no uniforme, con el fin de mantener una
SNR constante, ya que el error que se comete para valores pequeños es mayor que el
que se comete para valores grandes de señal:
Figura 2.9. Curvas de cuantificación uniforme y no uniforme.
qxSNR q 2
2
)( =qxSNR q 2
2
log10)( ⋅=
∆
Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
12
Figura 2.10. Ejemplo de error de cuantificación
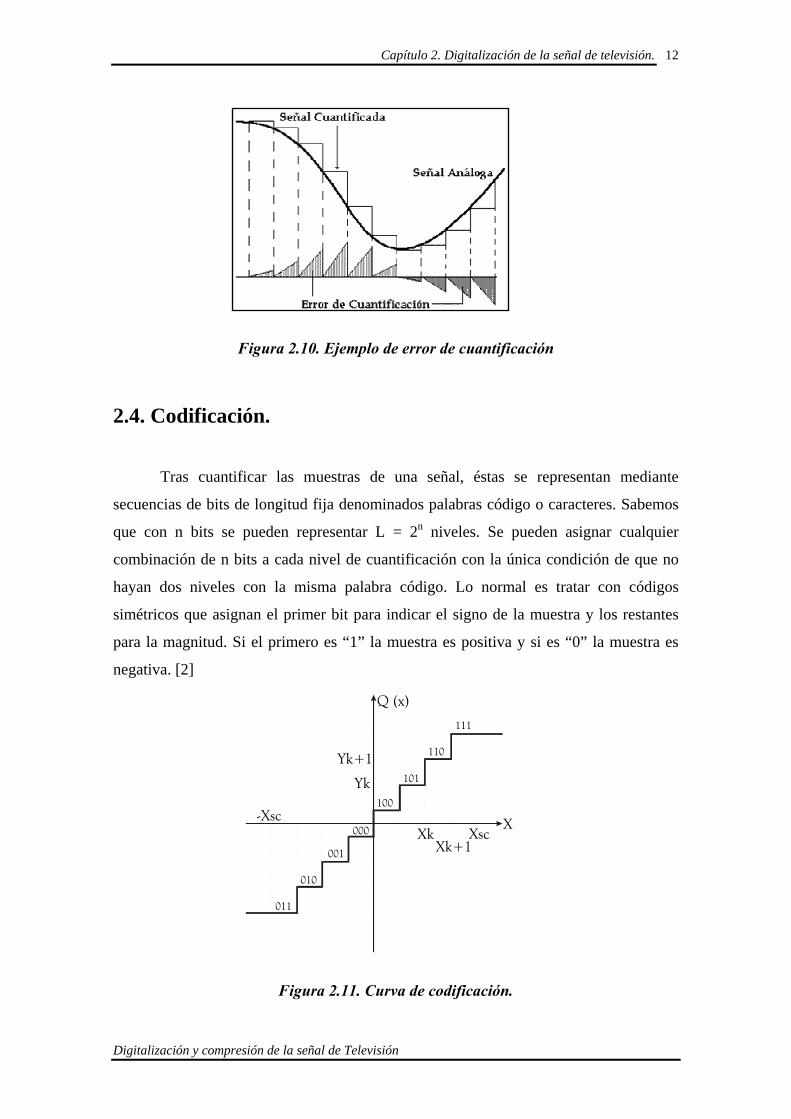
2.4. Codificación.
Tras cuantificar las muestras de una señal, éstas se representan mediante
secuencias de bits de longitud fija denominados palabras código o caracteres. Sabemos
que con n bits se pueden representar L = 2n niveles. Se pueden asignar cualquier
combinación de n bits a cada nivel de cuantificación con la única condición de que no
hayan dos niveles con la misma palabra código. Lo normal es tratar con códigos
simétricos que asignan el primer bit para indicar el signo de la muestra y los restantes
para la magnitud. Si el primero es “1” la muestra es positiva y si es “0” la muestra es
negativa. [2]
Figura 2.11. Curva de codificación.
Q (x)
XXsc
-XscXk
Xk+1
Yk
Yk+1
111
110
101
100
000
001
010
011

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
13
2.4.1. Formato de codificación.
Para nuestro caso particular, señales de televisión, hay dos formatos de
codificación, gozando cada uno de ellos de partidarios y detractores.
2.4.1.1 Codificación de las señales compuestas. Esta solución propone digitalizar las señales compuestas existentes (NTSC,
PAL, SECAM). No se evita el problema de las distintas normas de televisión y el del
intercambio de programas. Tras la conversión digital/analógico obtenemos de nuevo las
señales NTSC, PAL y SECAM. Un segundo problema es que a la hora del montaje de
programas se debe respetar la secuencia de 4 y 8 campos para NTSC y PAL.
La ventaja es que un equipo de este tipo se puede implantar sin la menor
dificultad en los estudios analógicos existentes sin codificar o decodificar la señal
original, pero esto supone sólo una ventaja durante la fase de la transición de los
estudios o equipos de producción analógicos a digitales. Hay dos configuraciones
posibles, según la fase en que nos encontremos:
A. Configuración durante la fase de transición. Pueden ser necesarias
varias conversiones A/D y D/A.
Figura 2.12. Configuración en fase de transición.
NTSC PAL
SECAM FUENTE
DE IMAGEN
CODIFICADOR DAAD
PROCESADO DIGITAL
NTSC,PAL,SECAM
AD DA
NTSC,PAL,SECAM

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
14
B. Situación en un estudio digital completo. Es necesario un único
proceso de conversión A/D y D/A. Cada fuente tiene su propio codificador.
Figura 2.13. Configuración en un estudio digital completo.
2.4.1.2. Codificación de componentes.
Con este método se digitalizan las tres señales, Y, K1(R-Y) y K2 (B.Y) en las
que k representa un factor de multiplicación determinado por las características del
sistema digital.
Las ventajas son, por un lado, que se posibilita la existencia de un método
compatible para los tres sistemas de televisión. Se hace posible el intercambio
internacional de imágenes digitales. La codificación podría realizarse en el extremo de
la cadena de producción, justo antes del emisor. No se necesita más de un codificador
de televisión. Por otra parte, se resuelven todas las dificultades inherentes a la
secuencia de campos PAL y NTSC. La luminancia y crominancia pueden tratarse por
separado sin las consecuencias perturbadoras de la decodificación/codificación y la
pérdida de calidad de las señales.
Durante la fase de transición de los estudios analógicos a digitales, esta
codificación no constituye el método más apropiado. Pero en estudios digitalizados
resulta bastante sencillo.
Las dos configuraciones posibles son:
R
GFUENTE DE
IMAGEN CODIFICADOR DAC ADC
NTSC PAL
SECAM
PROCESADO DIGITAL
NTSC,PAL,SECAM
B

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
15
A. Configuración de tratamiento de señal de televisión durante la
transición a un estudio digital completo. Cada equipo digital precisa de un
codificador y un decodificador.
Figura 2.14. Configuración en fase de transición.
B. Configuración de estudio completamente digitalizado. Precisa de
un solo codificador de televisión al final de la cadena.
Figura 2.15. Configuración en un estudio digital completo.
2.5. La norma UER-SMPTE-OIRT.
Las normas de la televisión digital se fijaron por la ‘Recomendación 601’ y la
‘Memoria 629-2’ del CCIR. Estas fueron aceptadas por la UER, la SMPTE y la OIRT.
Se refiere pues a una norma mundial. En las mismas se especifican las características
principales de la digitalización de la señal de televisión.
DECODIFICADOR DAC ADC NTSC PAL
SECAM
PROCESADO DIGITAL
CODIFICADOR
B-Y
R-Y
YNTSC PAL SECAM
B-Y
R-Y
Y
FUENTE IMAGEN DAC ADC
NTSC PAL
SECAM
PROCESADO DIGITAL
CODIFICADOR
B-Y
R-Y
Y
B-Y
R-Y
Y

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
16
2.5.1. Señales codificadas.
Se trata de un sistema de codificación de componentes, es decir se muestrean la
señal de luminancia Y y las dos señales diferencia de color (R-Y) y (B-Y). Pero para
una saturación al 100% las señales varían entre los valores:
Para reducir esto valores a 1 voltio, es decir, que los valores oscilen entre +0.5 V
y –0.5 V, se calculan los coeficientes KR y KB:
KB = 0.5/0.701 = 0.713
KR = 0.5/0.886 = 0.564
Las señales muestreadas son pues:
Y
0.713 (R-Y)
0.564 (B-Y)
2.5.2. La frecuencia de muestreo.
A la hora de elegir una frecuencia de muestreo fue necesario optar por aquella
que cumpliera tres exigencias:
· Primera exigencia. La frecuencia de muestreo debe ser como mínima el
doble de la mayor frecuencia a transmitir. Como hay normas de televisión en las
que la señal de luminancia se emite con un ancho de banda de 6 Mhz, se hace
preciso para una norma internacional que la frecuencia de muestreo sea por lo
menos de 12 Mhz.
VxVYR 701.0701.0)( −≤≤→−
VxVYB 886.0886.0)( −≤≤→−

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
17
· Segunda exigencia. Para favorecer la uniformidad de las memorias
digitales al almacenar las diferentes líneas de televisión muestreadas, es
preferible que el número de muestras por línea sea idéntico para todas. Esto
significa que la frecuencia de muestreo debe ser un múltiplo entero de la
frecuencia de líneas. Se habla de muestreo ortogonal.
· Tercera exigencia. Para obtener una frecuencia de muestreo universal, ésta
debe ser un múltiplo de todas las frecuencias de línea de los estándares
existentes en el mundo. En este momento existen dos normas distintas: una con
625 líneas y otra con 525 líneas por cuadro lo que corresponde a las frecuencias
respectivas: 15625 Hz y 15734.26573 Hz. El mínimo común múltiplo de estas
frecuencias es 2.25 Mhz. Esta frecuencia es sin duda demasiado baja ya que
tenía que ser superior a 12 Mhz. Un valor adecuado es 6 x 2.25 Mhz = 13.5 Mhz
que corresponde a:
6 x 143 x frecuencia de línea NTSC = 858 x frecuencia de línea NTSC.
Y
6 x 144 x frecuencia de línea PAL = 864 x frecuencia de línea PAL.
Cada píxel de una imagen de televisión se compone de información de luz
(luminancia) e información de color (crominancia).
Si queremos tener la misma información para la señal de luminancia y para cada
componente de la señal de croma, (R-Y) y (B-Y), debemos muestrearlas utilizando la
misma frecuencia 13,5 Mhz.
El muestreo descrito para la luminancia y las señales diferencia de color está
determinado en las recomendaciones de la BT601 y BT635 de la ITU (Unión
Internacional de Telecomunicaciones) y está definido como muestreo 4:4:4. Se eligen
estos números para poder configurar todas las posibilidades de muestreo para todo tipo
de servicios.

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
18
El muestreo 4:4:4 no considera que el ojo humano tiene una sensibilidad menor
al color que a la luminancia. La recomendación 601 prevé otros tipos de muestreo como
el 4:2:2 y submuestreos que aprovechan al máximo la característica antes mencionada,
como 4:1:1 y 4:2:0.
El muestreo 4:2:2, por cada cuatro muestras de luminancia toma dos de cada una
de las señales diferencia de color. Así pues la frecuencia de muestreo se fijó en 13,5
Mhz para la señal de luminancia. Para las señales diferencia de color basta con un ancho
de banda más limitado. Se muestrean a la mitad de la frecuencia de la luminancia, o sea,
6.75 Mhz.
Esto conduce respectivamente en PAL y NTSC a 864 y 858 muestras por línea
para la luminancia y a 432 y 439 para las señales diferencia de color. La estructura de
muestreo es ortogonal.
Esta estructura se repite cada campo y cuadro. Las muestras de las señales
diferencia de color se toman al mismo tiempo que las muestras impares de la
luminancia. La codificación es lineal y se compone de 8 bits por muestra, tanto para la
luminancia como para diferencia de color, lo que corresponde a 256 niveles de
cuantificación. Se toman 220 niveles para la luminancia siendo el nivel 16 el que
corresponde al nivel de negro y el nivel 235 al nivel de blanco. Se utilizan 224 niveles
de cuantificación para las señales diferencia de color con un valor del cero analógico
correspondiente al número digital 128, lo que proporciona como valores extremos 128
±112 o sea entre 240 y 16.
Para evitar una velocidad de muestreo demasiado alta se puede omitir el
muestreo durante la supresión de línea, puesto que la información que se haya en ese
intervalo es idéntica para todas las líneas y es bien conocida. Cabe llamar la atención
sobre el hecho de que la codificación lineal con 8 bits es la forma en la que las señales
tienen que presentarse a la salida de los equipos. Dentro de los mismos el número puede
ser diferente.
El esquema del proceso de muestreo está representado en la siguiente figura:

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
19
Figura 2.16. Esquema del proceso de muestreo.
Las señales analógicas R, G, B, procedentes de la cámara, corregidas en gamma,
corrección debida a la no-linealidad entre los tubos de la cámara y del tubo de rayos
catódicos, son convertidas al formato Y, (R-Y) y (B-Y) (matrizadas), según la fórmula:
Y = 0.299R+0.587G+0.114B
B-Y = -2.299R-0.587G+0.886B
R-Y = 0.701R-0.587G-0.114B
Una vez matrizadas son filtradas con filtros paso bajo. El ancho de banda de
filtrado de la señal de luminancia es 5.75 Mhz y el de las señales de color es de 2.75
Mhz.
Las señales resultantes del proceso de filtrado son muestreadas a una velocidad
de 13.5 Mhz para la señal de luminancia y de 6.75 Mhz (mitad de las muestras) para las
señales diferencia de color.
Si cada muestra de cuantifica con 8 bits (1 byte) la cantidad de información que
se envía será:
13.5 x 8 bits = 108
6.75 x 8 bits = 54
6.75 x 8 bits = 54
_______________
TOTAL = 216 Mbits por segundo.
RGB
A
YUV
MATRIZ
ADC 13,5 MHZ
F.P.B 5,75 MHZ
F.P.B 2,75 MHZ
F.P.B 2,75 MHZ
ADC 6,75 MHZ
ADC 6,75 MHZ
8 BITS
8 BITS
8 BITS
Y
CB
CR
ADC = Conversor analógico digital
R
G
B

Capítulo 2. Digitalización de la señal de televisión.
Digitalización y compresión de la señal de Televisión
20
El muestreo elegido para el estándar de la televisión digital es el submuestreo
4:2:0, ya que el ojo humano no es capaz de identificar una resolución de color mayor.
El flujo binario necesario para enviar una señal codificada según este estándar
será:
13.5 x 8 bits = 108
6.75 x 8 bits = 54
_______________
TOTAL = 162 Mbits por segundo.
Según el criterio de Nyquist, la frecuencia del corte del filtro necesario, y por
tanto el mínimo ancho de banda para su transmisión, será al menos la mitad del flujo
binario, es decir 81 Mhz.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
21
Capítulo III:

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
22
CAPÍTULO 3. Fundamentos de la Compresión de
vídeo MPEG.
3.1. Introducción.
De los valores de flujo binario que se obtiene a la salida del conversor
analógico digital y ancho de banda necesario para su transmisión se deduce a la
necesidad de realizar una compresión. Es imprescindible reducir la tasa binaria
necesaria para enviar la señal de televisión, en primer lugar debido al excesivo ancho de
banda que se necesita para su transmisión, y en segundo lugar a la dificultad que plantea
el tratamiento y almacenamiento de un volumen de información semejante.
Por ello nos centraremos en los fundamentos que toma el MPEG-2 para
establecer una buena compresión.
3.2. Entropía y redundancia.
Todas las imágenes que se puedan imaginar están compuestas por dos partes
fundamentales: entropía y redundancia.
Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
23
La Entropía es la parte de la señal que contiene información útil, ya que la
señal redundante no suma información alguna, aporta una información repetitiva. Un
codificador ideal tendría que ser capaz de delimitar estas áreas y poderlas emitir, así
como un decodificador tendría que recrear una impresión original de la información
obtenida. Mientras nos vamos acercando a los ideales, la complejidad de los
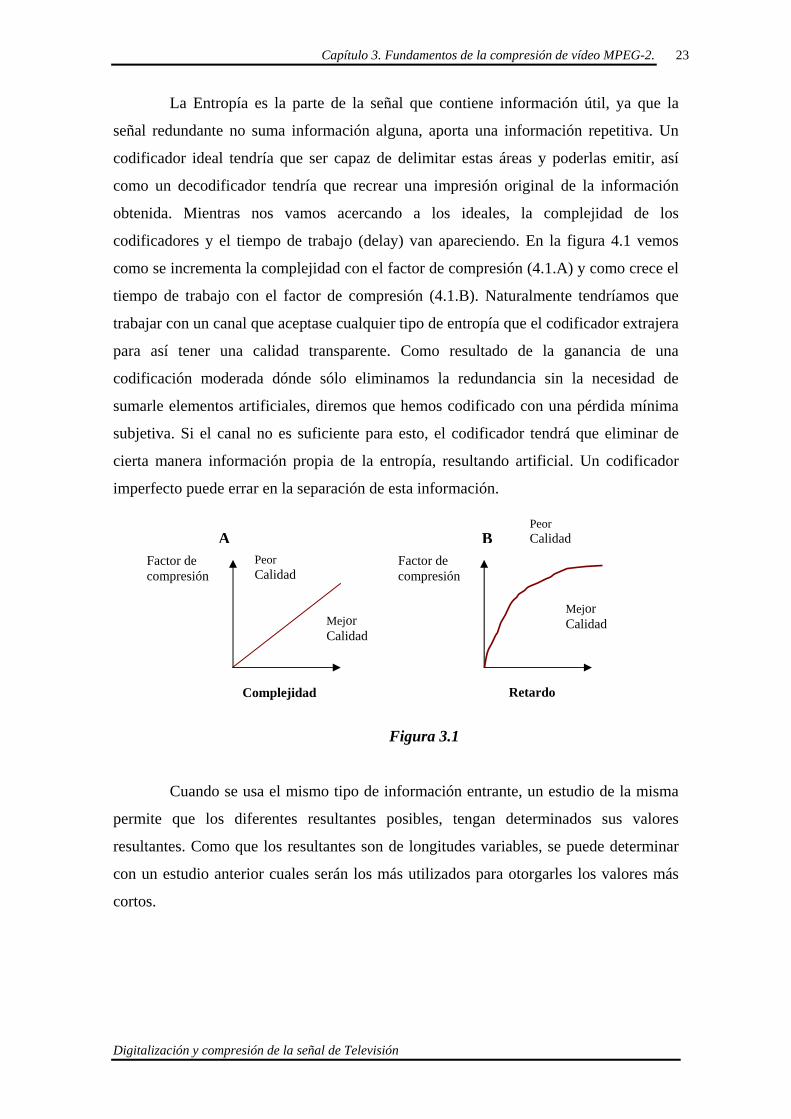
codificadores y el tiempo de trabajo (delay) van apareciendo. En la figura 4.1 vemos
como se incrementa la complejidad con el factor de compresión (4.1.A) y como crece el
tiempo de trabajo con el factor de compresión (4.1.B). Naturalmente tendríamos que
trabajar con un canal que aceptase cualquier tipo de entropía que el codificador extrajera
para así tener una calidad transparente. Como resultado de la ganancia de una
codificación moderada dónde sólo eliminamos la redundancia sin la necesidad de
sumarle elementos artificiales, diremos que hemos codificado con una pérdida mínima
subjetiva. Si el canal no es suficiente para esto, el codificador tendrá que eliminar de
cierta manera información propia de la entropía, resultando artificial. Un codificador
imperfecto puede errar en la separación de esta información.
Figura 3.1
Cuando se usa el mismo tipo de información entrante, un estudio de la misma
permite que los diferentes resultantes posibles, tengan determinados sus valores
resultantes. Como que los resultantes son de longitudes variables, se puede determinar
con un estudio anterior cuales serán los más utilizados para otorgarles los valores más
cortos.
Mejor Calidad
Peor Calidad
Complejidad
Mejor Calidad
PeorCalidad
Retardo
Factor de compresión
Factor de compresión
A B

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
24
3.3. Codificación de longitud variable (VLC).
VLC (“Variable Length Coding”). Esta codificación asigna un número
distinto de bits a las palabras digitales. Así cada dato a codificar no usa el mismo
número de bits y por tanto tiende a dar lugar a un régimen binario no fijo. La asignación
del número de bits a cada palabra se realiza en base al dato que se envía con esa palabra
y a la probabilidad de que aparezca dicho dato.
Los datos más probables, o que más veces se dan, se codifican con palabras de
pocos bits y los menos probables con palabras de más bits. La codificación VLC supone
la existencia de una tabla estandarizada que asocia a cada dato una palabra de una cierta
longitud.
En el caso de MPEG-2, la codificación VLC usada se basa en el método
“HUFFMAN” con un estudio estadístico previo. Además, se realiza para la asignación
de palabras una codificación “run-length” encubierta. Una codificación “run-length”
simplifica la codificación de largas cadenas de ceros. Para ello, codifica un dato
alternativo: “número de ceros consecutivos”, en vez de codificar cada cero como dato
independiente.
Figura 3.2. Codificación VLC.
3.3.1. Codificación Huffman.
Este código es un código óptimo dentro de los códigos de codificación
estadística, ya que es el código de menor longitud media.
IMAGEN FUENTE A CODIFICAR
DATOS DE IMAGEN
VECTORES DE MOVIMIENTOS
ERRORES DE PREDICCIÓN
DCT VLC
VLC
DCT VLC

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
25
La construcción de este código se fundamenta en asignar a cada símbolo del
alfabeto fuente una secuencia de bits cuya longitud esté relacionada de forma directa
con la probabilidad de aparición de ese símbolo. De esta forma, a los símbolos con
mayor frecuencia de aparición se les asignarán las palabras de código de menor
longitud.
En el proceso de construcción de este código, lo primero que se hace es
ordenar el conjunto de símbolos del alfabeto fuente en orden decreciente de
probabilidades de aparición. A continuación se juntan los dos símbolos con menor
probabilidad de aparición en un único símbolo cuya probabilidad será la suma de las
probabilidades de los símbolos que dieron origen a este nuevo símbolo.
Se repite este proceso hasta que sólo tengamos dos símbolos.
A continuación se realiza el proceso de codificación. Primeramente asignamos
un 1 a uno de los dos símbolos que tenemos y un 0 al otro. Posteriormente recorreremos
la estructura que hemos construido hacia atrás de forma que cuando dos símbolos hayan
dado origen a un nuevo símbolo, estos dos símbolos "heredarán" la codificación
asignada a este nuevo símbolo y a continuación se le añadirá un 1 a la codificación de
uno de los símbolos y un 0 a la del otro símbolo.
Figura 3.3. Ejemplo de codificación HUFFMAN.
ValorMuestras
PCMCodificación Probabilidad
de valores
K1
K2
K3
K4
K5
K6
1
00
011
0100
01010
01011
0,4
0,3
0,1
0,1
0,06
0,04
0,4
0,3
0,1
0,1
0,1
0,4
0,3
0,2
0,1
0,4
0,3
0,3
0,6
0,4
0
0
0
0
0
11
1
1
1

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
26
3.3.2. Codificación Run Lenght.
Es tal vez el esquema de compresión sin pérdidas más sencillo, y también uno
de los más ineficaces. Está basado en sustituir la información gráfica de píxeles que se
repiten por el valor del color de uno de ellos y la posición de cada uno de los puntos que
lo utilizan.
Esta técnica es eficiente cuando dentro del fichero gráfico que se va a
comprimir se repite un byte sucesivamente por un número grande de veces. En estos
casos, todos los bytes iguales se sustituyen por dos, el primero de los cuales indica el
número de veces que se repite el segundo.
Existen diferentes formas de implementar RLE, todas ellas patentadas. Una de
ellas, la más ineficiente, es utilizar un carácter, llamado comúnmente DLE, que sirva
para indicar que se ha producido una repetición de un carácter. Otra es utilizando un
carácter "centinela", con un bit que indica si la siguiente información es acerca de una
repetición o son datos sin repetición.
Este método permite obtener un alto nivel de compresión en imágenes que
contengan muchas áreas del mismo color, sin que se produzcan pérdidas de calidad. El
problema surge cuando los colores de la imagen son muy dispares, caso en el que se
pueden obtener archivos de mayor tamaño que los originales.
RLE es el algoritmo utilizado en los formatos gráficos BMP y PCX, aunque
cada uno usa un método distinto de implementación.
Otro ejemplo: se considera una pantalla que contiene texto en negro sobre un
fondo blanco. Habría muchas secuencias de este tipo con píxeles blancos en los

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
27
márgenes vacíos, y otras secuencias de píxeles negros en la zona del texto. Supongamos
una única línea con N representando las zonas en negro y B las de blanco:
BBBBBBBBBBBBNBBBBBBBBBBBBNNNBBBBBBBBBBBBBBBBBBBBBBBBNBBBBBBBBBBB
BBB
Si aplicamos la codificación run-lenght a está línea, obtendríamos lo siguiente:
12BN12B3N24BN14B
3.4. Compresión MPEG-2.
El estándar MPEG además de aprovechar la redundancia espacial intrínseca de
una imagen fija utilizada en la codificación JPEG, aprovecha la redundancia temporal
que aparece en la codificación de imágenes animadas, permitiendo encontrar similitudes
entre las imágenes sucesivas de vídeo.
Debido a que la calidad en la compresión de vídeo en el estándar MPEG-1 era
de baja calidad y no servia para otras aplicaciones, se creo la norma ISO/IEC 13818,
mucho más conocida con el nombre de MPEG-2. Esta norma permite un flujo de
transmisión hasta el orden de los 20 Mbits/s, transportando tanto imagen como sonido.
3.5. Redundancia espacial.
La redundancia espacial ocurre porque en un cuadro individual los
píxeles cercanos (contiguos) tienen un grado de correlación, es decir, son muy parecidos
(por ejemplo, en una imagen que muestre un prado verde bajo un cielo azul, los valores
de los píxeles del prado serán muy parecidos entre ellos y del mismo modo los del
cielo).

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
28
Fig.3.4. Redundancia espacial.
3.5.1 Codificación espacial.
Cuando las imágenes individuales son comprimidas sin referencia a las demás,
el eje del tiempo no entra en el proceso de compresión, esto por lo tanto se denomina
codificación intra (intra=dentro) o codificación espacial. A medida que la codificación
espacial trata cada imagen independientemente, esta puede emplear ciertas técnicas de
compresión desarrolladas para las imágenes fijas.
Un análisis de las imágenes de televisión revela que existe un alto contenido de
frecuencias espaciales debido al detalle en algunas áreas de la imagen, generando una
cantidad pequeña de energía en tales frecuencias. A menudo las imágenes contienen
considerables áreas en donde existen píxeles con un mismo valor espacial. El promedio
de brillo de la imagen se caracteriza por componentes de frecuencia de valor cero.
Simplemente omitiendo los componentes de alta frecuencia de la imagen, esta se vuelve
inaceptable debido a la perdida de definición de la imagen.
Mucho detalle baja redundancia
Poco detalle alta redundancia

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
29
Una disminución en la codificación se puede obtener, tomando como ventaja
que la amplitud de los componentes espaciales disminuye con la frecuencia. Si el
espectro de frecuencia espacial es dividido en subbandas de frecuencia, las bandas de
alta frecuencia se pueden describir en pocos bits, no solamente porque sus amplitudes
son pequeñas sino porque puede ser tolerado más ruido. La Transformada Discreta del
Coseno se usa en MPEG para determinar el dominio de la frecuencia espacial en
imágenes bidimensionales.
Figura 3.5. Proceso de codificación espacial.
3.5.1.3. La Transformada del Coseno Discreto.
DCT (“Discrete Cosine Transform”). La transformada del coseno consiste en
realizar una operación matemática sobre los datos originales de manera que se obtienen
otros datos que se relacionan unívocamente con aquellos (operación inversa “IDCT” sin
pérdidas). Los datos originales para la operación se seleccionan en bloques de NxN
DCT
149 120 79 49 120 94 58 32 78 58 29 9 49 33 9 0
120 59 1 -1 59 15 -2 1 2 -2 1 -1 -1 0 -1 0

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
30
(típico 8x8) formando matrices. Los datos resultantes tienen las siguientes
características:
Igual número de datos y ordenación en bloque NxN.
Datos con valores reales positivos y/o negativos.
Significado “espectral” respecto a datos originales.
Gran cantidad de valores cercanos a cero (muchos más que
en el bloque original).
3.5.1.2. Cuantificación.
El proceso de cuantificación asigna por aproximación un valor a cada
coeficiente de frecuencia dentro de una limitada gama de valores admitidos. El
codificador selecciona una ’’matriz de cuantificación’’ que determina el modo en que
será cuantificado cada uno de los coeficientes del bloque transformado.
Como se sabe, el ojo humano tiene poca sensibilidad para los detalles y por
tanto no es necesario cuantificar con precisión los coeficientes de alta frecuencia de la
transformada, es decir, habrá menos valores admitidos para éstos que para los
coeficientes de frecuencias bajas. Esta operación se realiza dividiendo los coeficientes
por un valor ‘n’ mayor que uno y rodeando el resultado al entero más próximo (en el
campo digital). El factor de ponderación ‘n ‘varia con la posición del coeficiente en el
bloque, correspondiendo a los coeficientes de frecuencias altas, mayores valores de ‘n’.
En consecuencia, gran parte de los coeficientes de la transformada se
cuantifican al valor cero, habrá muy pocos de alta frecuencia distintos de cero y algunos
de baja frecuencia distinto de cero. Un caso especial es el coeficiente que representa el
valor de la componente continua del bloque que normalmente se cuantifica con la
máxima precisión.
La matriz de cuantificación del MPEG que contiene los valores de ’n’ tiene
también en cuenta lo siguiente:

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
31
Si esta procesando información de luminancia o de
crominancia, lo que supone una distinta respuesta del ojo humano.
Si el bloque proviene de una imagen /o tiene una imagen
de predicción, ya que la distribución de las amplitudes de los coeficientes
es distinta.
La situación del bloque dentro de la imagen y el contenido
de la imagen. Algunos bloques tienen que codificarse con mayor
precisión que otros como, por ejemplo, en el caso de un bloque
correspondiente a gradientes muy suaves en donde la pequeñas
imprecisiones son muy apreciables.
Además de esta cuantificación dependiente de la frecuencia, también es posible
reducir el número de niveles de cuantificación necesario para describir los valores de los
coeficientes utilizando una ley de cuantificación no lineal, es decir, dependiente de la
amplitud. Vemos en la figura siguiente que los valores altos de los coeficientes se
codifican con menos precisión que los pequeños. La longitud de la palabra de código a
la salida de la cuantificación se reduce con respecto a la de entrada. Además, todos los
valores de la zona muerta se llevan a cero.
El MPEG permite cambiar los valores de la matriz de cuantificación para cada
bloque DCT cuando se codifican imágenes de gran complejidad. Naturalmente todos los
cambios de la matriz tienen que transmitirse al decodificador.
Figura 3.6. Características de la cuantificación no lineal.
Zona muerta
Entrada
Salida

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
32
3.5.1.3. Codificación por Entropía.
Según el teorema de Shanon, la entropía de una fuente S, donde “pi” es la
probabilidad de que el símbolo “si” ocurra en dicha fuente, es definida por la siguiente
expresión:
H(S)=∑i pi log 21/pi
Por teoría de la información, si los símbolos son distintos, entonces el número
medio de bits necesitados para codificarlos está siempre limitado por el valor de su
entropía.
En una señal codificada en n bits, hay 2n posibles valores para cada muestra (si
la probabilidad de las muestras es igual, su entropía es n).
Los codificadores de entropía se basan en asignar palabras de código de
longitud variable a cada muestra. Asignan palabras cortas a los valores de muestras más
probables, y palabras largas a los valores de muestras menos probables. El modelo de
probabilidad para la asignación de palabras de código, pueden obtenerse o directamente
de los valores de entrada o de suposiciones previas sobre dichos valores. Los dos
mecanismos más utilizados son la codificación Huffman, y la codificación Aritmética.
3.6. Redundancia temporal.
En secuencias de vídeo, hay también una correlación significativa entre
muestras vecinas temporalmente.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
33
Figura 4.7. Redundancia temporal.
3.6.1 Codificación temporal.
También llamada codificación Inter, aprovecha la ventaja que existe cuando las
imágenes sucesivas son similares. En lugar de enviar la información de cada imagen por
separado, el codificador inter envía la diferencia existente entre la imagen previa y la
actual en forma de codificación diferencial. El codificador necesita de una imagen, la
cual fue almacenada con anterioridad para luego ser comparada entre imágenes
sucesivas y de forma similar se requiere de una imagen previamente almacenada para
que el decodificador desarrolle las imágenes siguientes.
Los datos que se generan al hacer la diferencia entre dos imágenes, también se
pueden tratar como una nueva imagen, la cual se debe someter al mismo tratamiento de
transformadas utilizado en la compresión espacial.
Desafortunadamente existe la posibilidad de transmitir errores, si se utiliza una
secuencia ilimitada de imágenes previstas. Por esto es mejor utilizar un número limitado
de imágenes previstas para de este modo garantizar una mejor transmisión de los datos.
En MPEG periódicamente se envía una imagen la cual no ha sido tratada con
algún método de compresión con perdidas y que a su vez es idéntica a la imagen
original, refrescando los datos en la secuencia de transmisión.
Información que no cambia y no se envía
Información que cambia y se envía

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
34
La figura siguiente muestra el recorrido de una imagen original, llamada
imagen I o intra, la cual es enviada entre imágenes que han sido creadas usando una
diferencia entre imágenes, llamada imágenes P o previstas. La imagen I requiere
grandes cantidades de información, mientras que las imágenes P requieren una cantidad
menor. Esto ocasiona que el flujo de transmisión de datos sea variable hasta cuando
llegan a la memoria intermedia, la cual genera a su salida una transmisión de datos de
forma constante. También se puede observar que el preeditor necesita almacenar datos
de menor proporción puesto que su factor de compresión no cambia de una imagen a
otra.
I=Imagen codificada intra P=Imagen codificada diferencialmente
Una secuencia de imágenes que esta constituida por una imagen I y las
siguientes imágenes P hasta el comienzo de otra imagen I, se denomina grupo de
imágenes GOP (Group Of Pictures). Para factores de compresión altos se utiliza un
número grande de imágenes P, haciendo que las GOP aumenten de tamaño
considerablemente; sin embargo un GOP grande evita recuperar eficazmente una
transmisión que ha llegado con errores.
En el caso de objetos en movimiento, puede que su apariencia no cambie
mucho entre imágenes, pero la representación de los bordes si cambia
considerablemente. Esto es de gran ventaja si el efecto de movimiento se representa por
la diferencia entre imágenes, generando una reducción en la codificación de datos. Este
es el objetivo de la compensación de movimiento.
P P B

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
35
Figura 3.8. Proceso de codificación temporal.
3.7. Redundancia estadística.
La redundancia estadística tiene que ver con las limitaciones físicas del ojo
humano, que tiene una limitada respuesta para fijarse en los detalles espaciales y es
menos sensitivo al distinguir detalles en las esquinas o los cambios rápidos. Por tanto, el
proceso de codificación puede ser capaz de minimizar el bit-rate mientras se mantiene
constante la calidad a la que el ojo humano ve la imagen decodificada.
3.8. Codificador híbrido DCT/DPCM.
El codificador híbrido consiste en aplicar una DCT seguido de un PCM
diferencial, es decir, seguido de un codificador diferencial. Este tipo de codificador
pretende evitar generalmente los tipos de redundancia conocidos desde la temporal
hasta la espacial.
Tras dividir la imagen en bloques, se aplica una transformada a cada bloque,
pero luego en vez de enviar los coeficientes de la transformación se envía su diferencia
con una predicción hecha tomando como base los coeficientes de la transformada de
bloques anteriores. El esquema siguiente representa este tipo de codificador.
Área de búsqueda
Imagen de referencia
Imagen a codificar

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
36
Fig. 3.9. Codificador híbrido.
3.9. Compensación de Movimiento.
Esta técnica tiene como objetivo principal eliminar la redundancia temporal
entre las imágenes que componen una secuencia con el fin de aumentar la compresión.
Para eliminar dicha redundancia, la idea inicial que puede ocurrírsenos es
transmitir la diferencia entre un píxel en una posición de un fotograma (imagen) y el
píxel situado en la misma posición pero en el fotograma siguiente. Esto sirve cuando las
imágenes son estáticas. Pero lo normal es tener imágenes dinámicas y por tanto no
podemos implementar lo anterior tal cual, sino que previamente habrá que estimar el
movimiento que ha sufrido un píxel de un objeto de un fotograma al siguiente. Habrá
que calcular el vector de movimiento asociado a cada píxel de la imagen. Al
decodificador se transmite la diferencia y los vectores de movimiento calculados. Si los
vectores están bien calculados la diferencia entre una imagen y la siguiente compensada
será muy pequeña, ya que la escena no cambia bruscamente en un corto intervalo de
tiempo. Se ha ganado pues en compresión.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
37
Los vectores de movimiento representan la translación de las imágenes de los
bloques entre cuadros. Estos vectores se necesitan para la reconstrucción y son
codificados de forma diferencial en el flujo de datos. Se utiliza codificación diferencial
ya que reduce el total de bits requeridos para transmitir la diferencia entre los vectores
de movimiento de los cuadros consecutivos. La eficiencia de la compresión y la calidad
de la reconstrucción de la señal de vídeo dependen de la exactitud en la estimación del
movimiento.
El método para este cálculo no se especifica en el estándar y por lo tanto está
abierto a diferentes implementaciones y diseños, aunque evidentemente existe una
relación directa entre la exactitud de la estimación de movimiento y la complejidad de
su cálculo.
Fig. 3.10. Compensación en movimiento.
Macrobloque
Frame k (P Frame)
Frame J (I Frame)
MV
MH
MV = VECTOR VERTICAL. MH = VECTOR HORIZONTAL.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
38
3.10. Imágenes en MPEG-2.
Una imagen puede ser un cuadro o un campo de una imagen.
Matemáticamente, cada imagen es realmente una unión de los valores que
representan a un píxel: una componente de luminancia y dos de crominancia; es decir,
tres matrices de píxeles. Ya que el ojo humano no es muy sensible a los cambios de la
región cromática comparada con la región de luminancia, las matrices de croma son
decimadas o reducidas en tamaño por un factor de dos en ambas direcciones horizontal
y vertical.
MPEG-2 adicionalmente permite la posibilidad de no decimar o sólo decimar
horizontalmente la componente croma, consiguiente formatos 4:4:4 y 4:2:2
respectivamente.
Las imágenes pueden clasificarse principalmente en tres tipos basados en sus
esquemas de compresión.
I (Intraframes) o intra cuadros.
P (Predictive) o cuadros predecidos.
B (Bi-directional) o cuadros bidireccionales.
3.10.1 Imágenes I.
Se codifican como si fuesen imágenes fijas utilizando la norma JPEG, por
tanto, para decodificar una imagen de este tipo no hacen falta otras imágenes de la
secuencia, sino sólo ella misma. No se considera la redundancia temporal (compresión
intraframe).
Se consigue una moderada compresión explotando únicamente la redundancia
espacial. Una imagen I siempre es un punto de acceso en el flujo de bits de vídeo. Son
las imágenes más grandes.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
39
3.10.2 Imágenes P.
Están codificadas como predicción de la imagen I ó P anterior usando un
mecanismo de compensación de movimiento. Para decodificar una imagen de este tipo
se necesita, además de ella misma, la I ó P anterior. El proceso de codificación aquí
explota tanto la redundancia espacial como la temporal.
3.10.3 Imágenes B.
Se codifican utilizando la I ó P anterior y la I ó P siguiente como referencia
para la compensación y estimación de movimiento. Para decodificarlas hacen falta,
además de ellas mismas, la I ó P anterior y la I ó P siguiente. Estas imágenes consiguen
los niveles de compresión más elevados y por tanto son las más pequeñas.
3.11 Codificación en forma entrelazada o progresiva.
Dependiendo del trabajo a realizar, las imágenes entrelazadas pueden ser
tratadas de manera diferente según la importancia de los movimientos entre los dos
campos de una misma imagen (los casos extremos son, por un lado, cuando se
transmiten películas cinematográficas por televisión "telecine" donde no hay
movimiento entre los dos campos de TV, puesto que proceden de la exploración del
mismo fotograma de la película, y por otro lado, las imágenes de vídeo de
acontecimientos deportivos, donde puede haber importantes movimientos entre los dos
campos de una imagen).
La figura siguiente representa la secuencia temporal de la posición vertical de
las líneas de los campos sucesivos en un sistema entrelazado.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
40
Fig. 3.11. Codificación entrelazada.
Para la codificación Intra de las imágenes entrelazadas, MPEG-2 permite elegir
entre dos estructuras de imágenes llamadas frame (estructura "imagen" o "campo"") o
field (estructura "campo").
3.12 Estructura por cuadro y campo.
Estructura por cuadro: También llamada "progresiva", es apropiada para los
casos donde hay poco movimiento entre dos campos sucesivos. Los bloques y
macrobloques se dividen en la imagen completa y la DCT se efectúa, sobre puntos
verticales que distan 20 ms en el tiempo, lo que no plantea problemas si los dos campos
difieren poco.
Figura 3.12. División de los macrobloques en bloques en modo imagen (frame).

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
41
En este caso, siempre es posible codificar los bloques de mayor animación en
modo inter-campo, es decir, dividiéndoles en un campo.
Estructura por campo: También llamada "entrelazada", es preferible cuando
el movimiento de un campo a otro es importante. En este caso, a fin de evitar un
contenido en frecuencias verticales elevadas que reduciría la eficacia de la compresión
tras efectuar la DCT, la división de los macrobloques se hace considerando cada uno de
los campos como una imagen independiente en el interior del cual se toman los bloques.
Figura 3.13. División de los macrobloques en bloques en modo campo
(field.)
En cuanto a la estimación de movimiento, también hay varios modos previstos:
Un macrobloque puede predecirse en modo "imagen", "campo" o "mixto".
El Modo "Frame"
Un macrobloque formado en el campo impar sirve para predecir el bloque
correspondiente del próximo campo impar, y lo mismo para los bloques del campo par,
por tanto, la predicción se hace sobre un tiempo de 40 ms (2 campos).
El Modo "Field"
La predicción de un bloque se efectúa a partir de un bloque del campo anterior,
entonces aquí, los vectores de movimiento corresponden a un tiempo de 20ms.

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
42
El Modo "Mixto"
Los bloques se predicen a partir de dos bloques que corresponden a dos
campos.
3.13 Secuencia de imágenes en MPEG-2. (GOP).
Las imágenes pueden ser combinadas para producir un GOP (grupo de
imágenes) que comienza con una imagen I. El GOP es la unidad fundamental de
codificación temporal. En el estándar MPEG, el uso de GOP es opcional, pero esta en la
práctica es necesaria. Un GOP puede ser abierto o cerrado. En un GOP cerrado, las
últimas imágenes B requieren de una imagen I para el siguiente GOP por decodificar y
la secuencia de bits puede ser cortada al final de la GOP.
Cuando algunas GOP son combinadas se produce una secuencia de vídeo con
un código de inicio, seguido por un encabezamiento, y luego termina con un código
final.
Los códigos de soporte adicional pueden ser situados al inicio de la secuencia.
La secuencia de soporte especifica el tamaño horizontal y vertical de la imagen, norma
de barrido, la rafa de imágenes, si se usa un barrido progresivo o entrelazado, el perfil,
nivel, velocidad de transferencia de bits, y cuales matrices de cuantificación se usan
para codificar imágenes espaciales y temporales.
Sin la secuencia de soporte de datos, un decodificador no puede comprender el
flujo de bits y por lo tanto no puede comenzar la operación de decodificación correcta.
Figura 3.14. Ejemplo de grupo de imágenes, para M=3, N=12

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
43
Los dos parámetros M y N definen la manera en que las imágenes I, P y B se
encadenan:
M es la distancia (en número de imágenes) entre dos imágenes P (previstas)
sucesiva.
N es la distancia entre dos imágenes I (intra) sucesivas.
Para alcanzar un flujo de vídeo de 1.15 Mbits/s con una calidad satisfactoria, al
tiempo que se mantiene una resolución de acceso aleatorio aceptable (< 0.5 segundos),
los parámetros comúnmente utilizados son M=3 y N= 12 como se muestra en la figura
3.14.
3.14 Estructura 4:4:4.
Este tipo de formato indica que no se ha despreciado ninguna de las muestras
de crominancia y que por lo tanto se utiliza todas.
En este caso de formato de crominancia 4:4:4, al haber las mismas muestras de
luminancia que de crominancia, para un determinado trozo de imagen, a las matrices
correspondientes a Y, CR y CB que define ese trozo de imagen, son de igual dimensión,
tanto vertical como horizontal.
Figura 3.15. Posición de los muestreos en formato 4:4:4.
Si tomamos como ejemplo un trozo de imagen de 16x16 píxeles, que es un
valor muy típico y que servirá para identificar a un macrobloque, a partir de él se
obtiene matrices cuadradas de 8x8, que serán denominadas bloques. Para la señal de
Luminancia
Crominancia

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
44
luminancia se obtendrán cuatro matrices y otras cuatro para cada una de las señales de
crominancia.
3.15 Estructura 4:2:2.
En esta estructura se desprecian la mitad de las muestras de crominancia,
eligiendo una si, otra no, siendo el tratamiento el mismo para todas las líneas. En
sentido vertical, hay columnas en las que en todos los píxeles tienen 3 muestras
(luminancia y dos de crominancia) y hay columnas en las que solo hay muestras de
luminancia.
Para un determinado trozo de imagen, si los datos se adquieren de acuerdo a
este formato, cada una de las matrices de crominancia, en sentido vertical tendrán la
misma dimensión que la matriz de luminancia, pero en sentido horizontal el tamaño de
las matrices de crominancia será la mitad.
Figura 3.16. Posición de los muestreos en formato 4.2.2
Luminancia
Crominancia
16x16
8x8 8x8 8x8 8x8
Crominancia CR
Crominancia CB
Luminancia Y
8x8 8x8 8x8 8x8
8x8 8x8 8x8 8x8

Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
45
Como ejemplo, si se toma un trozo de imagen 16x16 pixels, se obtendrá para
luminancia una matriz de 16 x16, y para cada una de las señales de crominancia una
matriz de 16x 8 pixels. Si se convierten en matrices cuadradas, que es como se trabaja
con ellas, para la señal de luminancia se obtendrán cuatro matrices de 8x8 pixels y para
cada una de las señales de crominancia dos matrices también de 8x8.
3.16 Estructura 4:2:0.
Cuando los datos se obtienen de esa forma, además de despreciar en sentido
horizontal una de cada dos muestras (según se ha visto en el formato 4:2:2) también se
desprecia una de cada dos muestras en sentido vertical.
Puede comprobarse que para un determinado trozo de imagen, la matriz
formada por las muestras de luminancia es de tamaño doble al de cada una de las
matrices de crominancia tanto en fila como en columnas.
Figura 3.17. Posición de los muestreos en formato 4:2:0
16x16 8x8
8x8
8x8
8x8
8x8 8x8 8x8 8x8
Crominancia CR
Crominancia CB
Luminancia Y
Luminancia
Crominancia
Capítulo 3. Fundamentos de la compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
46
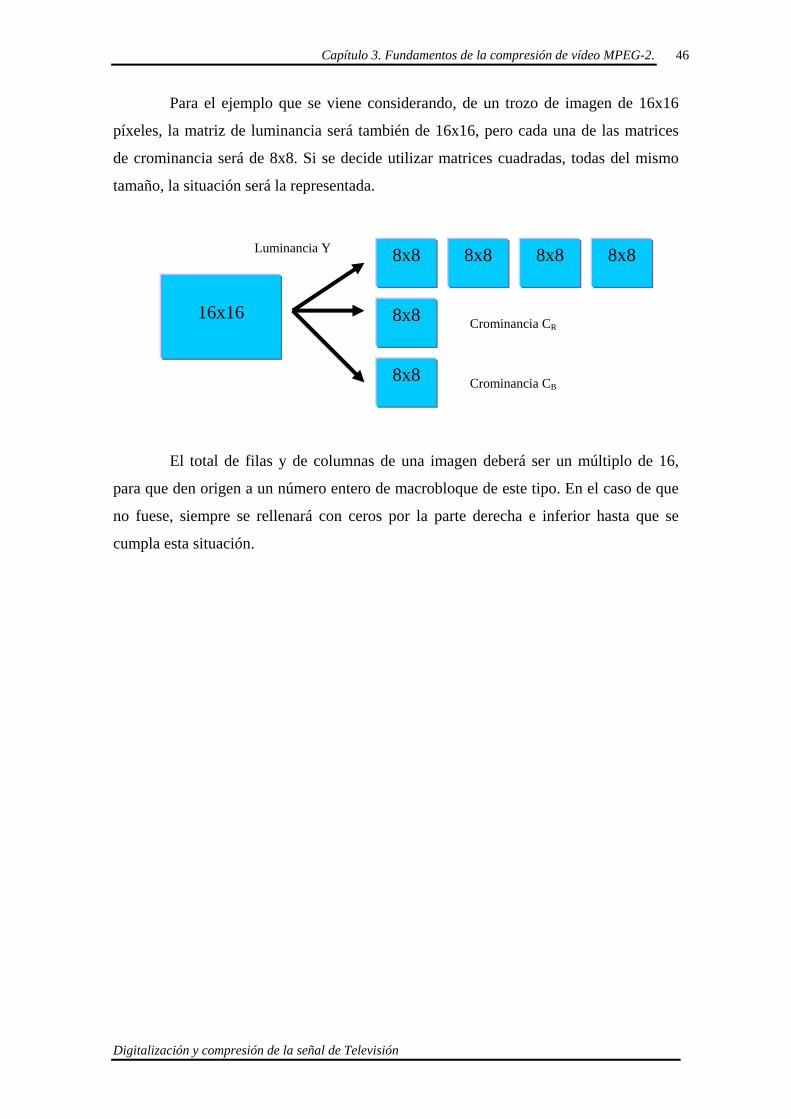
Para el ejemplo que se viene considerando, de un trozo de imagen de 16x16
píxeles, la matriz de luminancia será también de 16x16, pero cada una de las matrices
de crominancia será de 8x8. Si se decide utilizar matrices cuadradas, todas del mismo
tamaño, la situación será la representada.
El total de filas y de columnas de una imagen deberá ser un múltiplo de 16,
para que den origen a un número entero de macrobloque de este tipo. En el caso de que
no fuese, siempre se rellenará con ceros por la parte derecha e inferior hasta que se
cumpla esta situación.
Crominancia CR
Crominancia CB
16x16 8x8
8x8
8x8 8x8 8x8 8x8 Luminancia Y

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
47
Capítulo IV:

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
48
CAPÍTULO 4. Proceso de compresión de vídeo
MPEG-2.
4.1. Introducción. En este capítulo se pretende dar una completa descripción del tratamiento que
da el MPEG-2 a la señal de vídeo.
4.2. Proceso de compresión de vídeo MPEG-2.
En el caso de una imagen de vídeo la variación de los píxeles se produce en las
direcciones horizontal y vertical. Para procesar la imagen se utiliza una función
matemática bidimensional conocida como "Transformada Discreta en Coseno (DCT)".
Esta función se aplica a muestras de la imagen tomadas en "bloques" de 8x8
píxeles y calcula, por cada bloque, los 64 coeficientes que corresponden a las
frecuencias horizontales y verticales del bloque.
La utilidad de la DCT radica en que, en el dominio del tiempo, las amplitudes
de las 64 muestras de cada bloque de 8x8 píxeles suelen tener valores diferentes y de

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
49
elevada cuantía, mientras que muchos de los 64 coeficientes de la función transformada
suelen ser pequeños y muy iguales, y sólo unos pocos tienen un peso relevante. Esto
permite cuantificarlos y codificarlos de una manera eficiente con códigos. Para
optimizar el número de ceros consecutivos, la lectura de los coeficientes se hace en
zigzag y no horizontalmente. Hay que resaltar que la DCT por sí misma no reduce los
datos. Es la naturaleza de la señal de vídeo la que hace que muchos coeficientes valgan
cero, o tengan un valor tan pequeño que el ojo humano no pueda apreciar su efecto.
Una primera reducción de flujo se consigue convirtiendo la señal de entrada
4:2:2 de 10 bits a 4:2:0 y 8 bits. Después se aplica la DCT y se hace una cuantificación
inteligente de los coeficientes para disminuir la redundancia de la señal. Finalmente se
codifica la entropía resultante con códigos de secuencias y de longitud variable. Para
suavizar y limitar el flujo de datos de salida, la cuantificación se hace más o menos
severa mediante una señal de control que llega desde el tampón de salida.
Cuando hay movimiento, la información de un bloque puede variar de un
campo al siguiente. El cálculo de los vectores de movimiento se hace con macrobloques
de 16x16 píxel (4 bloques) e investigando el sentido de los desplazamientos entre
imágenes sucesivas. La codificación Intercuadro trabaja sobre las imágenes aún no
comprimidas y es un proceso sin pérdidas. Partiendo de la imagen actual y sus
correspondientes vectores de movimiento, se calcula y predice la imagen siguiente. Esta
imagen predicha se resta de la actual para obtener una imagen error denominada
"Imagen P" cuyo contenido de información es pequeño y puede comprimirse
fácilmente. Las Imágenes P contienen sólo predicción unidireccional.
MPEG-2 utiliza también imágenes predichas bidireccionalmente, es decir, con
los cuadros anteriores y posteriores. A estas imágenes se las llama "Imágenes B".
Contienen muy poca información pero son muy eficaces para controlar los errores de
movimiento.
La idea básica de las imágenes P y B radica en que se necesita menos
información para mandar los vectores de movimiento que la que se requeriría para
mandar la información comprimida del macrobloque de píxel, con lo que la compresión
resulta más eficiente.

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
50
Las imágenes comprimidas I, P y B se transmiten en grupos de hasta 12 ó 15
imágenes. Cada grupo de imágenes se denomina GOP (Group-of-Pictures), comenzando
con una imagen tipo I, y se extiende hasta la siguiente imagen I. Entre ellas se
transmiten, con un orden preestablecido, las imágenes P y B.
El flujo binario de salida del codificador es un bloque de datos de gran tamaño
organizado según una estructura jerárquica anidada. La jerarquía comienza en el nivel
denominado "secuencia de vídeo" y termina en el nivel correspondiente a los "bloques
de la DCT". Se denomina "Corriente Binaria Elemental (Elementary bit Stream) y
contiene toda la información fundamental de la señal de vídeo codificada.
4.3 El proceso DCT.
La energía de vídeo de la imagen tiene una frecuencia espacial bastante baja,
que varía lentamente con el tiempo. Por tanto una transformada puede concentrar la
energía en muy pocos coeficientes. Para esta transformada la imagen actual se divide en
bloques para decrementar la complejidad. Todos los bloques (8x8) son transformados
de acuerdo con una Transformada Discreta del Coseno (DCT) de dos dimensiones que
puede ser considerada como una DCT unidimensional en las columnas y otra en las
filas. A cada coeficiente se le asocia una función específica de frecuencias horizontales
y verticales, y su valor (después de la transformación) indica la contribución de estas
frecuencias al bloque de la imagen. Sin embargo, la DCT no reduce el número de bits
que se requieren para la representación del bloque. Esta reducción se hace después de
comprobar que la distribución de los coeficientes no sea uniforme. La transformada
concentra la mayor parte de la energía de vídeo en las bajas frecuencias provocando que
la mayoría de los coeficientes sean cero o casi cero. Se consigue la compresión
saltándose todos los coeficientes que están cerca de cero y cuantificando los restantes
(se cuantifican los coeficientes con un número finito de bits pudiendo producirse
pérdidas de compresión).
Las ventajas de la DCT son la gran compactación de coeficientes (el resultado
es normalmente un numero reducido de coeficientes), que se utilizan algoritmos de

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
51
cálculo rápido y que es una transformada real. Las desventajas son la introducción de un
ruido granular (al cuantificar los coeficientes), la pérdida de resolución y el efecto
bloque (al aplicar la DCT sobre bloques y no sobre la imagen global se pueden
independizar los bloques entre sí y se observa la separación que existe entre ellos.
En las siguientes figuras se dará un ejemplo de este proceso que conlleva la
transformada.
Si tenemos una señal como la de la figura siguiente:
Fig. 4.1 Señal recogida para ejemplo.
La forma normal es determinar el brillo de cada uno de los 64 píxeles y
escalarlos dentro de unos limites, normalmente de 0 a 255 (en MPEG se usa un rango de
–256,255) donde 0 significa negro y 255 blanco.
Fig. 4.2 Valores de los 64 píxeles.
120 108 90 75 69 73 82 89
127 115 97 81 75 79 88 95
134 122 105 89 83 87 96 103
137 125 107 92 86 90 99 106
131 119 101 86 80 83 93 100
117 105 87 72 65 69 78 85
100 88 70 55 49 53 62 69
89 77 59 44 38 42 51 58

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
52
También podemos representarlo mediante un diagrama de barras 8x8:
Fig.4.3. Diagrama de barras de esos 64 píxeles.
Normalmente los valores son procesados línea a línea. Esto requiere 64 bits de
almacenaje.
Pero podemos definir todos los 64 valores por solo 5 enteros, aplicando la
fórmula de la DCT:
Donde f(x,y) es el brillo del píxel en la posición [x,y]. El resultado es F, una
matriz 8x8. Siguiendo el ejemplo anterior:

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
53
700 90 100 0 0 0 0 0
90 0 0 0 0 0 0 0
-89 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Fig. 4.4. Matriz una vez realizada la DCT.
Como se puede ver, la mayoría de los valores son 0. Como los valores distintos
de 0 están concentrados en la esquina superior derecha la matriz es transferida al
receptor en orden de escaneado en zigzag:
Esto resulta en: 700 90 90 89 0 100 0 0 0 .... 0. Por supuesto, los ceros no se
transmiten, en su lugar se codifica una señal de final de bloque.
El decodificador puede reconstruir los valores de los píxeles usando la fórmula
de la inversa de la transformada del coseno (IDCT):
Fig. 4.5 Ecuación de la IDCT.
Donde F(u,v) es el valor de la matriz transformada en la posición [u,v].
Los resultados son los valores originales de los píxeles. De esta manera,
podríamos considerar la compresión MPEG como sin perdidas, pero esto no es cierto,

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
54
porque los valores transformados están cuantificados. Están divididos (división entera)
por un cierto valor mayor o igual que 0 debido a que la DCT soporta valores hasta 2047.
Para reducirlos hasta estar al menos bajo la longitud del byte se aplica el valor
de cuantificación 8. El decodificador multiplica los resultados por el mismo valor.
Lógicamente los resultados difieren de los valores originales, pero debido a
algunas propiedades del ojo humano el error no es visible.
En MPEG hay una matriz de cuantificación que define un valor diferente de
cuantificación para cada valor transformado dependiendo de su posición.
El valor de la esquina superior izquierda de la matriz transformada es llamado
valor DC (direct current) y determina la media de brillo en el bloque. El resto de los
valores son llamados valores AC (alternating current) y describen la variación sobre el
valor DC.
Así, supongamos una matriz transformada tal que así:
Fig.4.7 Matriz transformada.
El valor DC seria 700.
El resultado de aplicarle la IDCT seria:
700 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
55
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
87 87 87 87 87 87 87 87
Fig.4.8. Matriz después de la IDCT.
En diagrama de barras:
Fig.4.9. Diagrama de barras de la matriz anterior.
La imagen, pues, es un cuadrado gris.
Si añadimos un valor AC de 100:

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
56
Fig.4.10. Matriz generada por añadir a la matriz anterior un valor de AC de 100.
El resultado de aplicar IDCT sería:
Fig.4.11. A la matriz de la figura 5.10 se le aplica la IDCT.
En diagrama de barras:
Fig.4.12. Diagrama de barras de la matriz anterior.
700 100 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
105 102 97 91 84 78 73 70
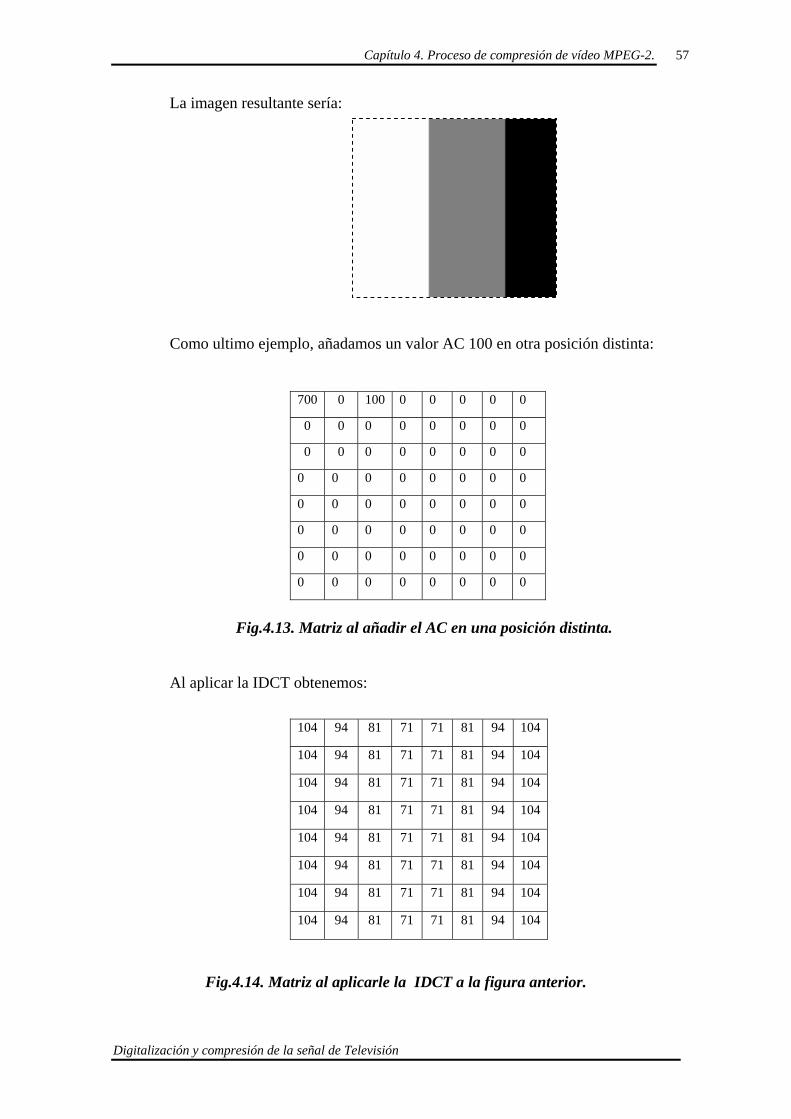
Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
57
La imagen resultante sería:
Como ultimo ejemplo, añadamos un valor AC 100 en otra posición distinta:
Fig.4.13. Matriz al añadir el AC en una posición distinta.
Al aplicar la IDCT obtenemos:
Fig.4.14. Matriz al aplicarle la IDCT a la figura anterior.
700 0 100 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104
104 94 81 71 71 81 94 104

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
58
En diagrama de barras:
Fig.4.15. Diagrama de barras.
La imagen resultante sería:
4.4. Barrido Zig Zag.
Después de realizar la DCT a un bloque de 8x8 píxeles, se nota que
generalmente los coeficientes más significativos de la DCT se encuentran en la parte
superior izquierda de la matriz. Una vez evaluados, los coeficientes de menor valor
pueden ser redondeados a cero. Permitiendo de este modo, una transmisión de datos
más eficiente, debido a que los coeficientes no-cero son enviados primero, seguido de
un código el cual indica que todos los demás números son ceros.

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
59
La exploración es una técnica que aumenta la probabilidad de alcanzar este
resultado, porque ella envía los coeficientes en orden descendente según su
probabilidad. La Figura muestra que en un sistema no-entrelazado, la probabilidad de
hallar coeficientes de mayor peso es más alta en la parte superior izquierda que en la
parte inferior derecha. Aquí una exploración en forma diagonal a 450 es la que se
denomina una exploración en zig-zag, la cual es la mejor secuencia para emplear en este
caso.
Fig. 4.16. Barrido Zigzag.
4. 5. Diagrama de un codificador MPEG-2.
A partir de la imagen digitalizada en formato 4:2:0 (caso del main profile), el
codificador elige para cada imagen su tipo (I, P o B) y si esta debe ser codificada en
modo frame (imagen) o field (campo). El codificador a continuación debe estimar los
vectores de movimiento para cada macrobloque de 16x16 píxeles. El número de
vectores depende del tipo de imagen y del modo de codificación escogido para cada
bloque.
En el caso más general, donde el codificador es capaz de generar imágenes B
(bidireccionales), deberá reordenar las imágenes antes de la codificación y la
transmisión.

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
60
La unidad básica de codificación es el macrobloque, compuesto por 4 bloques
de luminancia de 8x8 píxeles y (en el caso del formato 4:2:0) de 2 bloques de
crominancia (un Cr y un Cb) de 8x8 píxeles que abarcan la misma zona de la imagen.
Todos los macrobloques de la imagen se codifican secuencialmente de
izquierda a derecha y de arriba abajo, eligiéndose un modo de codificación
independiente para cada uno de ellos.
Una vez que se ha elegido el modo de codificación, la predicción con
compensación de movimiento del contenido del bloque se hace a partir de la imagen de
referencia (I o P) pasada (caso de las imágenes P) y eventualmente futura (caso de las
imágenes B). La predicción se elimina de los datos reales del macrobloque, lo que da la
señal de error de predicción.
En una imagen con estructura frame, el codificador deberá elegir entre efectuar
la DCT en modo frame o field. Esto depende principalmente de la amplitud del
movimiento entre los campos de la imagen.
La señal de error se separa inmediatamente en bloques de 8x8, a los que se
aplica la DCT. Cada bloque de coeficientes resultante se cuantifica y barre en zig-zag
para formar una serie de coeficientes. Seguidamente, se codifica la información auxiliar
necesaria para que el decodificador pueda reconstruir el bloque (modo de codificación,
vectores de movimiento, etc.), codificando los coeficientes cuantificados con ayuda de
una tabla VLC (codificación Huffman).
La unidad de control de flujo supervisa el estado de ocupación de la memoria
intermedia de salida, utilizando esta información como retorno para controlar el número
de bits que el codificador generará para los bloques siguientes, jugando principalmente
con los coeficientes de cuantificación. Se obtiene entonces a la salida del codificador un
tren binario completo, ya utilizable para un decodificador.
Para aumentar la calidad de la imagen decodificada, el propio codificador
almacena y decodifica (decuantificacion de los coeficientes después de la DCT inversa)
las imágenes I y P, como referencia para reconstruir otras imágenes obtenidas por

Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
61
predicción con compensación de movimiento en el decodificador, y calcula una señal de
error que se añade a la señal de predicción.
Fig. 4.17. Codificador MPEG-2
4. 6. Diagrama de un decodificador MPEG-2.
Como ya se ha dicho, la decodificación es más sencilla que la codificación, ya
que no tiene que efectuar alguna estimación de movimiento, que es una de las partes
más complejas del codificador.
La memoria intermedia (buffer) de entrada recibe los datos del canal de
transmisión, y el decodificador lee el tren binario hasta encontrar el principio de una
imagen, su tipo (I, P o B) y su estructura (frame o field).
Empieza la decodificación con la primera imagen I, almacenándola en su
memoria, así como la imagen P siguiente, para servir de referencia a las imágenes P o B
que dependen de ella.
Para las imágenes I, la decodificación propiamente dicha consiste en aplicar a
cada bloque la decodificación VLC, la decuantificación de los coeficientes y la
transformación DCT inversa.
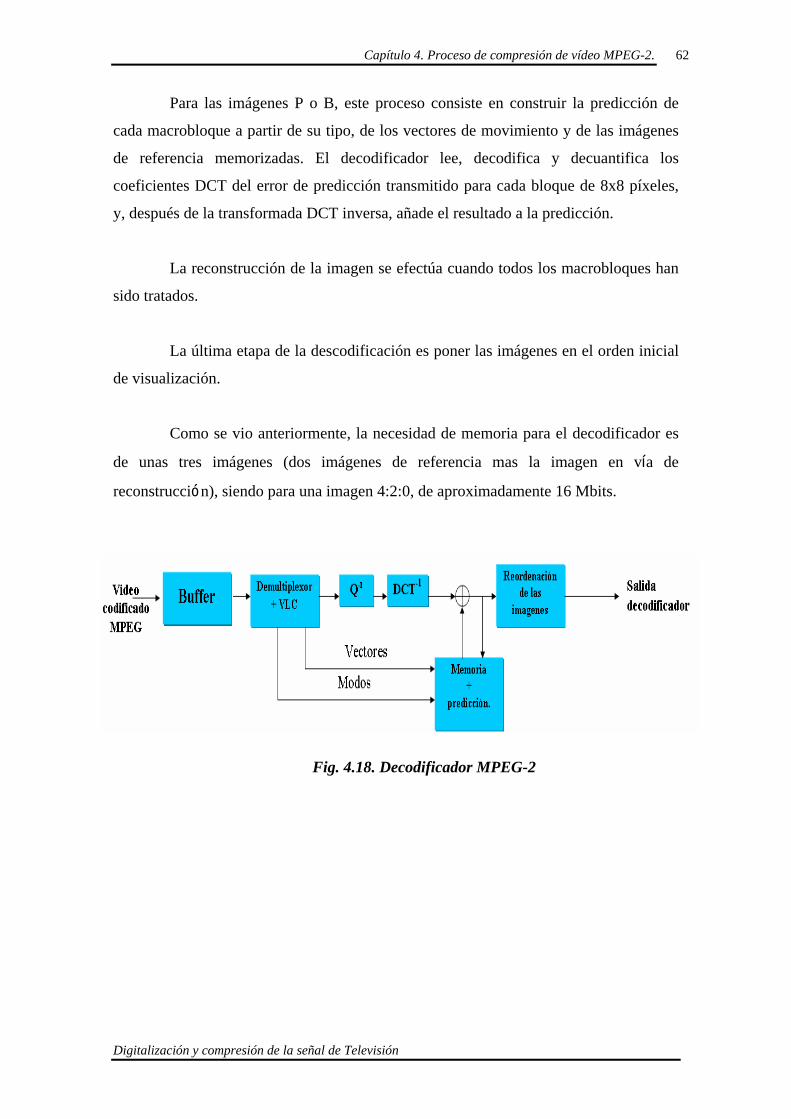
Capítulo 4. Proceso de compresión de vídeo MPEG-2.
Digitalización y compresión de la señal de Televisión
62
Para las imágenes P o B, este proceso consiste en construir la predicción de
cada macrobloque a partir de su tipo, de los vectores de movimiento y de las imágenes
de referencia memorizadas. El decodificador lee, decodifica y decuantifica los
coeficientes DCT del error de predicción transmitido para cada bloque de 8x8 píxeles,
y, después de la transformada DCT inversa, añade el resultado a la predicción.
La reconstrucción de la imagen se efectúa cuando todos los macrobloques han
sido tratados.
La última etapa de la descodificación es poner las imágenes en el orden inicial
de visualización.
Como se vio anteriormente, la necesidad de memoria para el decodificador es
de unas tres imágenes (dos imágenes de referencia mas la imagen en vía de
reconstrucción), siendo para una imagen 4:2:0, de aproximadamente 16 Mbits.
Fig. 4.18. Decodificador MPEG-2

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
63
Capítulo V:

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
64
CAPÍTULO 5. Estándar MPEG-2.
5.1. Introducción.
El Motion Pictures Expert Group (MPEG) es un grupo de trabajo común de la
ISO (International Standars Organitation) y la IEC (International Electrotechnical
Committe). Este grupo, fundado en 1988 desarrolló inicialmente la recomendación
ISO/IEC-11172, conocida como MPEG-1 y posteriormente ha desarrollado la
recomendación ITU-H.262 ó ISO/IEC-13818 conocida como MPEG-2. Ambas
recomendaciones van dirigidas a la codificación de información, con fines muy
concretos en el primer caso (MPEG-1) y con fines más generales en el segundo
(MPEG-2).
Los estándares MPEG contemplan la compresión y descompresión
(recuperación) de imágenes en movimiento y de sonido, y la formación de una
estructura multiplexada de datos en forma de señal digital serie que incluya tanto al
vídeo y al audio, comprimidos como los datos de cualquier otro servicio auxiliar
añadido. Además, contempla la sincronización adecuada durante la reproducción del
vídeo, el audio y los datos entre sí.

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
65
El estándar MPEG-2 intenta servir para un amplio número de aplicaciones
como medios de grabación digitales, difusión de televisión y comunicaciones.
Concretamente, este estándar MPEG-2 es muy flexible ya que no es un método o norma
única, sino que engloba un conjunto de éstas, de entre las que elige la más adecuada a
cada aplicación. El método general es el mismo, pero hay diferencias en los valores
asignados a los parámetros y en las características.
El proceso de codificación MPEG-2 da lugar a una señal digital serie cuya
interpretación no es directa, ni a veces evidente, pero cuyo procesado adecuado en el
decodificador da lugar a la recuperación de las señales de vídeo y audio originales, a la
vez que también se pueden recuperar una serie de datos auxiliares.
Las señales originales que usa el codificador MPEG-2 son señales en banda
base tanto para vídeo como para audio, estando la de vídeo en componentes ( Y, (R-Y)
y (B-Y)) y pudiendo ser de definición estándar o de alta definición. El uso de señales en
banda base analógicas exige la existencia de conversores A/D en el codificador MPEG-
2, lo que enrarece el equipo, por lo que generalmente se considera que la señal banda
base disponible ya está en formato digital, concretamente AES/EBU para audio y vídeo
digital en componentes.
5.2. Características principales del estándar de vídeo
MPEG-2.
Los sistemas de señal digital pueden organizar los datos de una manera directa
fácilmente relacionada con los datos originales o de manera más compleja y
aparentemente caprichosa. En este segundo caso, deben preverse elementos que
permitan identificar dichos datos y la recuperación de las señales originales. Además
debe tenerse en cuenta la problemática derivada de que una señal incluya datos de
diversas señales originales que tenían una relación temporal intrínseca.
Por tanto podemos hacer una división respecto al tipo de datos en base a su
contenido:

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
66
- Datos del sistema (o capa del sistema). Es el conjunto de bits
encargado de información sobre temporización, detalles del método de
compresión usado, método usado para la multiplexación del vídeo, audio y datos
auxiliares; e información para reproducción sincronizada.
- Datos de señal (o capa de compresión). Es el conjunto de bits que
llevan la información útil de imagen, sonido y otros, comprimidos, además de
ciertos parámetros del método de compresión usado.
A la hora de definir el sistema aparecen tres aspectos importantes que
configuran tres fases de organización de datos:
- Elementary Stream (ES). Estos datos pertenecen a la capa de
compresión y corresponden a cada una de las señales que componen un único
programa. Por ejemplo la señal de vídeo comprimida MPEG-2 de un programa o
la señal de audio comprimida del mismo programa. El ES es una señal digital
continúa con un régimen binario concreto. Cualquier otra señal comprimida de
vídeo o audio de otros programas es también una ES.
- Packetized Elementary Stream (PES). La señal ES se divide en
paquetes de longitud no necesariamente fija, a los que se añade su
correspondiente “header” (cabecera) que identifica y sincroniza los datos de
dicho paquete respecto a los otros paquetes obtenidos del mismo ES o de otros,
para lo que incorpora datos a la capa de sistema.
- Program Stream (PS) y Transport Stream (TS). Son las señales
MPEG-2 completas. Consisten en la sucesión de PES correspondientes a un solo
programa o a varios programas (sólo en el caso de TS) multiplexados con
indicación de los detalles de sincronización, de acceso condicional y otros.
La razón de la existencia de dos tipos de estructuras, PS y TS, se debe a que
cada una articula una serie de detalles adicionales a la simple agrupación de PES que las
hace más adecuadas a diversos tipos de aplicaciones.

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
67
El criterio de selección de uno u otro se basa en si se manda un solo programa
o varios y en si el medio de transmisión al que se introduce la señal MPEG-2 va a estar
sometido a errores o no.
Si son varios programas es necesario usar el TS. Si es un único programa
puede usarse el PS o el TS.
Si el medio está sometido a errores (transmisión, grabación,...), la estructura a
usar es la de “Transport Stream”. Si el medio no está sometido a errores (conexiones
cortas o interiores de equipos electrónicos) la agrupación se realiza como “Program
Stream”.
Figura 5.1. Sistema MPEG-2 para 1 programa.
5.3. Niveles y perfiles (“Level@Profile”).
El nivel permite seleccionar el procesado en base a la estructura espacial de
muestras, es decir, en base al número de pixeles y líneas a codificar. Está relacionado
con la resolución de la imagen.
Audio PES
Video PES
E.S. Video
E.S. Audio
MPEG-2 Program Stream
MPEG-2 Transport
Stream
VÍDEO AUDIO
CODIFICADOR DE VÍDEO
CODIFICADOR DE AUDIO
CODIFICADOR DE VÍDEO
CODIFICADOR DE AUDIO
PACK &
MUX PS.
PACK &
MUX T.S.
CAPA DE SISTEMA
CAPA DE COMPRESIÓN
FORMACIÓN DE SEÑALES MPEG-2 (iso/iec-13818)
PROGRAMA

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
68
Los posibles niveles que nos podemos encontrar se muestran en la siguiente tabla:
NIVEL CARACTERÍSTICAS High Muestreo (codificación) de 1920x1152 muestras activas High – 1440 Muestreo (codificación) de 1440x1152 muestras activas. Main Muestreo (codificación) de 720x576 muestras activas. Low Muestreo (codificación) de 352x288 muestras activas.
Tabla 5.1. Tabla de Niveles de MPEG-2.
Solo se codifican las muestras activas indicadas. Las señales originales, según
la norma de muestreo digital usado tendrán muestras activas y no activas. Las no activas
no son codificadas por MPEG-2 y serán regeneradas con nivel de borrado en el
decodificador. Las activas pueden coincidir en número con las usadas por MPEG-2 o no
coincidir. En el primer caso se recuperarán todas las muestras en la decodificación y en
el segundo, las muestras activas originales no codificadas en MPEG-2 serán regeneradas
con nivel de borrado por el decodificador. Para que esto sea posible, uno de los datos de
sistema que se transmiten es el del formato digital original.
Existe una relación directa entre el tipo de señal original y el nivel a elegir. Así,
una señal HDTV usará los niveles “High” o “High-1440”. Una señal SDTV de calidad
usará el nivel “Main” y el nivel “Low” se destina a señales SDTV de calidad
comparable a VHS para aplicaciones de menor calidad.
El perfil establece un juego de “herramientas” y posibilidades en el procesado
que no vienen marcados por la señal original. Mientras que los niveles marcan
claramente su capacidad para cada tipo de señal original, no es así de evidente la
selección de perfiles. Establece la relación de compresión.
En la siguiente tabla se muestran los diferentes perfiles que se han fijado para
la compresión en MPEG-2.
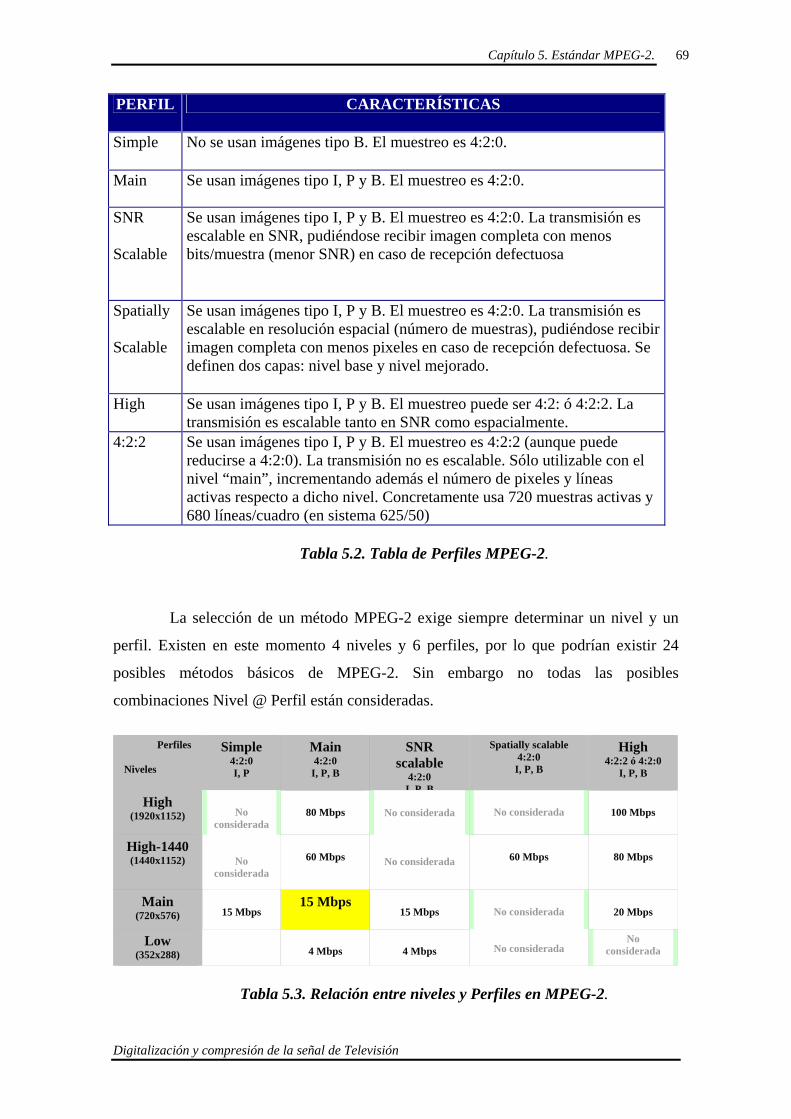
Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
69
PERFIL CARACTERÍSTICAS
Simple No se usan imágenes tipo B. El muestreo es 4:2:0.
Main Se usan imágenes tipo I, P y B. El muestreo es 4:2:0.
SNR Scalable
Se usan imágenes tipo I, P y B. El muestreo es 4:2:0. La transmisión es escalable en SNR, pudiéndose recibir imagen completa con menos bits/muestra (menor SNR) en caso de recepción defectuosa
Spatially Scalable
Se usan imágenes tipo I, P y B. El muestreo es 4:2:0. La transmisión es escalable en resolución espacial (número de muestras), pudiéndose recibir imagen completa con menos pixeles en caso de recepción defectuosa. Se definen dos capas: nivel base y nivel mejorado.
High Se usan imágenes tipo I, P y B. El muestreo puede ser 4:2: ó 4:2:2. La transmisión es escalable tanto en SNR como espacialmente.
4:2:2 Se usan imágenes tipo I, P y B. El muestreo es 4:2:2 (aunque puede reducirse a 4:2:0). La transmisión no es escalable. Sólo utilizable con el nivel “main”, incrementando además el número de pixeles y líneas activas respecto a dicho nivel. Concretamente usa 720 muestras activas y 680 líneas/cuadro (en sistema 625/50)
Tabla 5.2. Tabla de Perfiles MPEG-2.
La selección de un método MPEG-2 exige siempre determinar un nivel y un
perfil. Existen en este momento 4 niveles y 6 perfiles, por lo que podrían existir 24
posibles métodos básicos de MPEG-2. Sin embargo no todas las posibles
combinaciones Nivel @ Perfil están consideradas.
Tabla 5.3. Relación entre niveles y Perfiles en MPEG-2.
Perfiles
Niveles
Simple 4:2:0 I, P
Main 4:2:0 I, P, B
SNR scalable
4:2:0 I P B
Spatially scalable 4:2:0 I, P, B
High 4:2:2 ó 4:2:0
I, P, B
High (1920x1152)
No
considerada
No considerada
80 Mbps
No considerada
No considerada
No considerada
100 Mbps
High-1440 (1440x1152)
60 Mbps
60 Mbps 80 Mbps
Main (720x576)
15 Mbps 15 Mbps
15 Mbps No considerada
No considerada
20 Mbps
Low (352x288)
derada con No
considerada
4 Mbps
4 Mbps No considerada

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
70
En el vídeo de definición estándar, la combinación más usada es el nivel
“Main” con el perfil “Main”.
5.4. Codificación MPEG-2 de Audio.
La utilización del audio digital resulta familiar para todo el mundo desde la
aparición del disco compacto (Compact Disc), a principios de los años 80.
Puesto que su finalidad era obtener una calidad de alta fidelidad, la banda de
paso requerida debía ser de 20 Khz como mínimo, lo que implicaba, pues, una
frecuencia de muestreo superior a los 40 Khz; finalmente se adoptó el valor de 44,1
Khz. También debía garantizar una relación señal a ruido y una respuesta dinámica altas
(superiores a los 80 dB).
La digitalización de una señal analógica (o Pulse Code Modulation, PCM)
introduce sobre el bit de menor peso el llamado ’ruido de cuantificación’
correspondiente a la incertidumbre, que se traduce por una relación señal/ruido de 6 dB
por bit de cuantificación, es decir, 96 dB con la digitalización sobre 16 bits adoptada.
De ello resulta un flujo de 44,1 x 16 x 2 = 1,4 Mbits/seg para una señal estéreo.
Hay otras dos frecuencias de muestreo corrientemente utilizadas: 32 Khz (D2-
MAC, NICAM,...) y 48 Khz (grabación en estudio, casete de audio digital DAT,...). Las
normas MPEG-1 y 2 preveían la posibilidad de utilizar una de las tres frecuencias
anteriores como fuente de las señales de audio muestreadas. Los flujos que ofrecen son
ligeramente distintos, pero siguen siendo del mismo orden de magnitud (de 1 a 1,5
Mbits/seg), es decir, bastante más elevado para ser utilizados tal cual como sonido de
acompañamiento de una imagen codificada con la norma MPEG-1 o MPEG-2. Como
para el vídeo había que hacer frente a la necesidad de comprimir los datos procedentes
de la digitalización de la señal de audio.
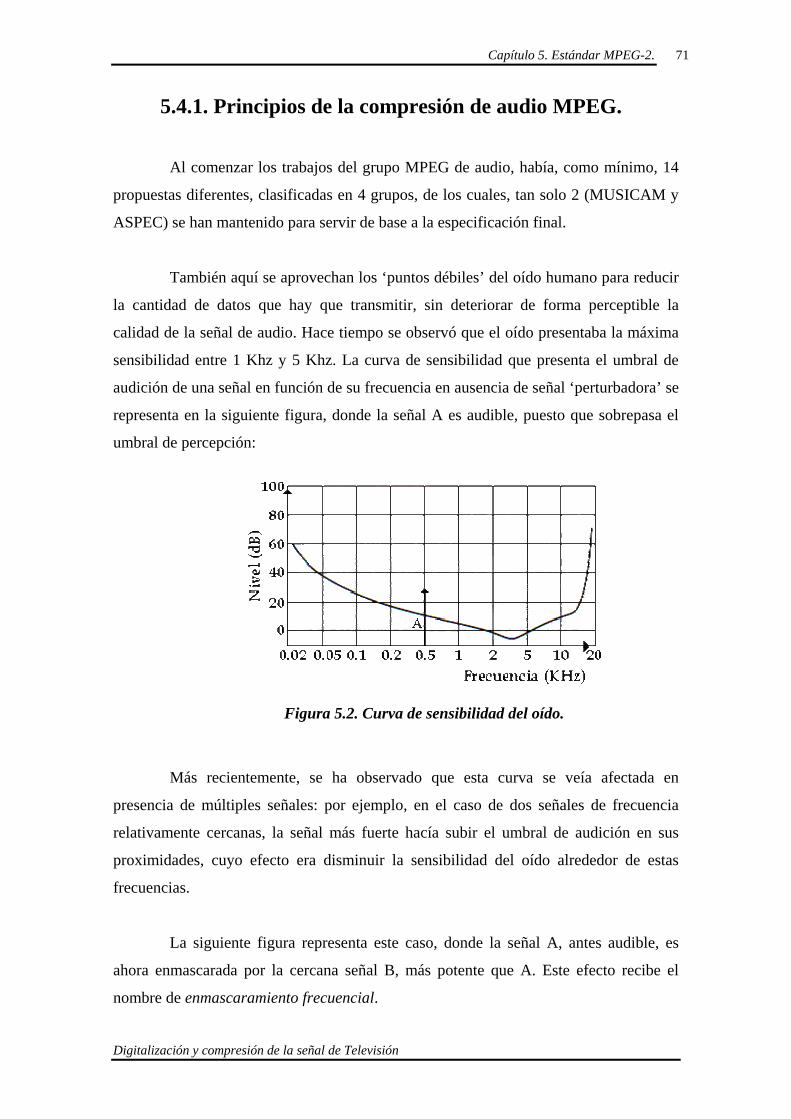
Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
71
5.4.1. Principios de la compresión de audio MPEG.
Al comenzar los trabajos del grupo MPEG de audio, había, como mínimo, 14
propuestas diferentes, clasificadas en 4 grupos, de los cuales, tan solo 2 (MUSICAM y
ASPEC) se han mantenido para servir de base a la especificación final.
También aquí se aprovechan los ‘puntos débiles’ del oído humano para reducir
la cantidad de datos que hay que transmitir, sin deteriorar de forma perceptible la
calidad de la señal de audio. Hace tiempo se observó que el oído presentaba la máxima
sensibilidad entre 1 Khz y 5 Khz. La curva de sensibilidad que presenta el umbral de
audición de una señal en función de su frecuencia en ausencia de señal ‘perturbadora’ se
representa en la siguiente figura, donde la señal A es audible, puesto que sobrepasa el
umbral de percepción:
Figura 5.2. Curva de sensibilidad del oído.
Más recientemente, se ha observado que esta curva se veía afectada en
presencia de múltiples señales: por ejemplo, en el caso de dos señales de frecuencia
relativamente cercanas, la señal más fuerte hacía subir el umbral de audición en sus
proximidades, cuyo efecto era disminuir la sensibilidad del oído alrededor de estas
frecuencias.
La siguiente figura representa este caso, donde la señal A, antes audible, es
ahora enmascarada por la cercana señal B, más potente que A. Este efecto recibe el
nombre de enmascaramiento frecuencial.
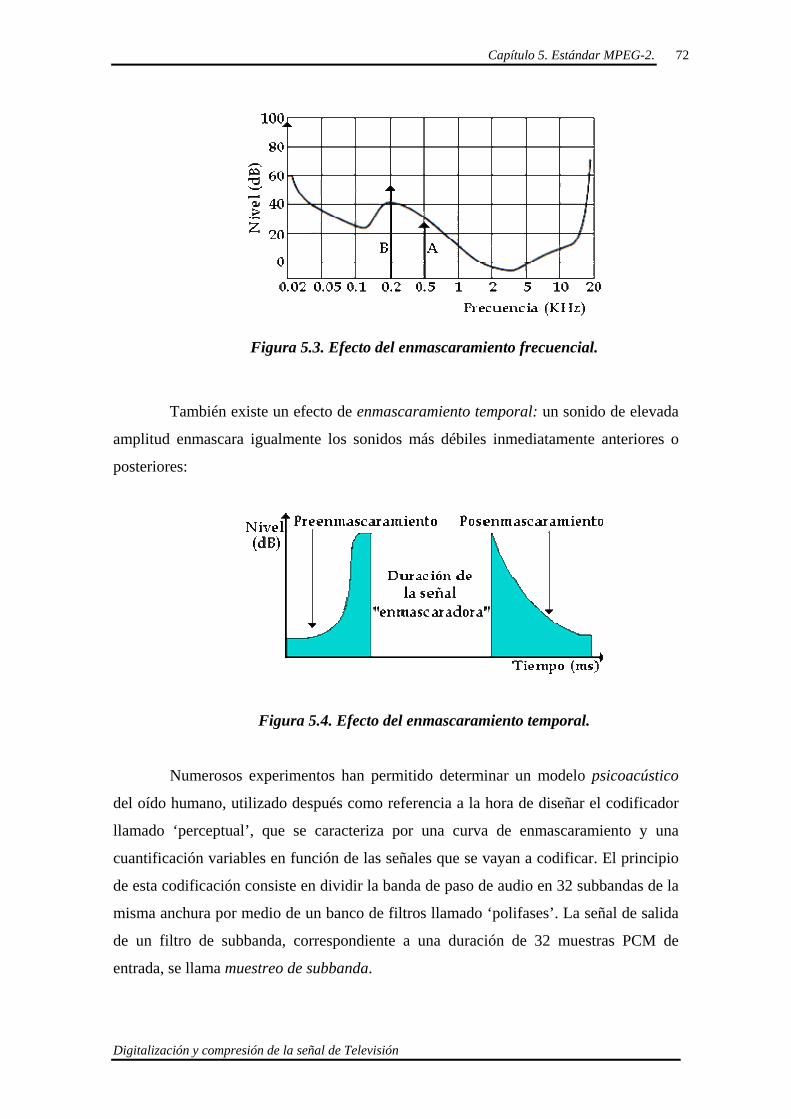
Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
72
Figura 5.3. Efecto del enmascaramiento frecuencial.
También existe un efecto de enmascaramiento temporal: un sonido de elevada
amplitud enmascara igualmente los sonidos más débiles inmediatamente anteriores o
posteriores:
Figura 5.4. Efecto del enmascaramiento temporal.
Numerosos experimentos han permitido determinar un modelo psicoacústico
del oído humano, utilizado después como referencia a la hora de diseñar el codificador
llamado ‘perceptual’, que se caracteriza por una curva de enmascaramiento y una
cuantificación variables en función de las señales que se vayan a codificar. El principio
de esta codificación consiste en dividir la banda de paso de audio en 32 subbandas de la
misma anchura por medio de un banco de filtros llamado ‘polifases’. La señal de salida
de un filtro de subbanda, correspondiente a una duración de 32 muestras PCM de
entrada, se llama muestreo de subbanda.
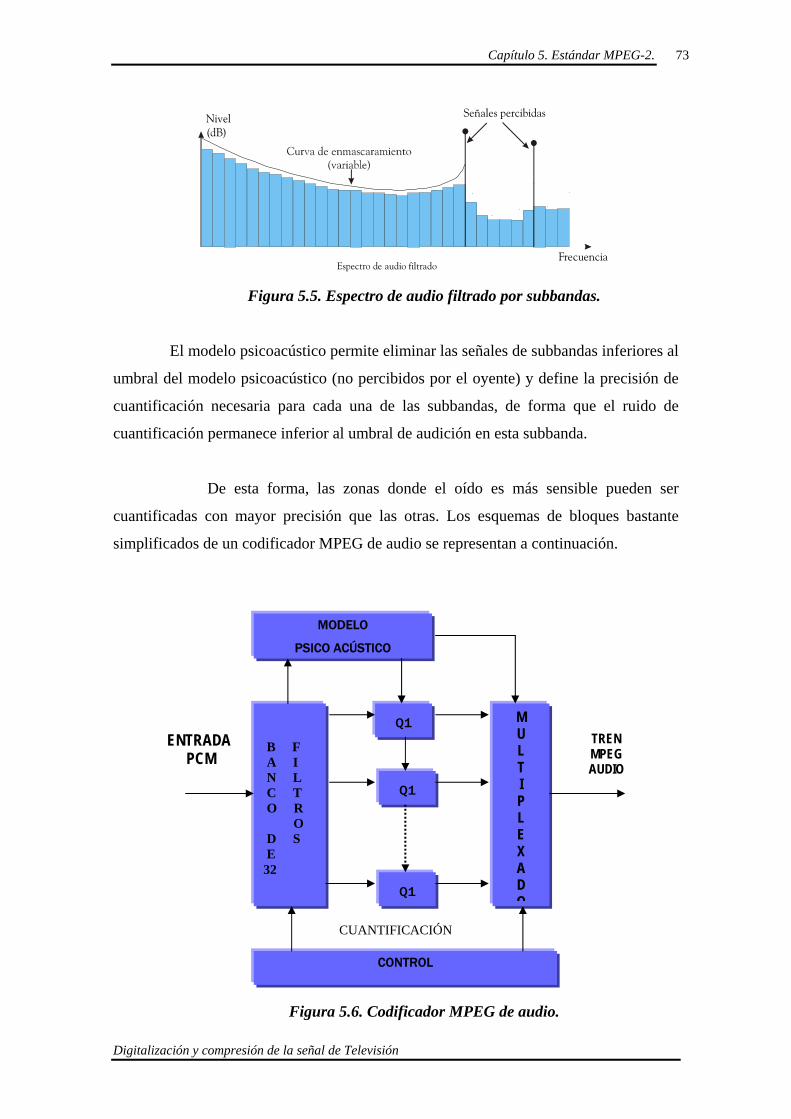
Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
73
Figura 5.5. Espectro de audio filtrado por subbandas.
El modelo psicoacústico permite eliminar las señales de subbandas inferiores al
umbral del modelo psicoacústico (no percibidos por el oyente) y define la precisión de
cuantificación necesaria para cada una de las subbandas, de forma que el ruido de
cuantificación permanece inferior al umbral de audición en esta subbanda.
De esta forma, las zonas donde el oído es más sensible pueden ser
cuantificadas con mayor precisión que las otras. Los esquemas de bloques bastante
simplificados de un codificador MPEG de audio se representan a continuación.
Figura 5.6. Codificador MPEG de audio.
Nivel(dB)
Señales percibidas
Espectro de audio filtradoFrecuencia
B F A I N L C T O R O D S E 32
MODELO
PSICO ACÚSTICO
M U L T I P L E X A D O
Q1
CONTROL
Q1
Q1
ENTRADA PCM
TREN MPEG AUDIO
CUANTIFICACIÓN

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
74
El análisis de la señal para determinar la curva de enmascaramiento y la
cuantificación no se hace para cada muestra PCM, sino en un intervalo de tiempo
llamado trama. En este intervalo, el codificador evalúa también la amplitud de la señal
más elevada para definir un factor de escala (scaling factor) que se codificará sobre 6
bits.
6.4.2. Las capas de la codificación de audio MPEG.
Las normas MPEG de audio definen tres capas (layers) de codificación que se
distinguen por su tasa de compresión para una calidad de audio percibida dada. La
norma de televisión DVB prescribe para el sonido la utilización de las capas I y II de la
especificación MPEG-1 de audio, que prevé cuatro modos principales de transmisión:
·Estéreo. Los canales I y D se codifican de manera
completamente independiente.
·Joint Estéreo. Aprovechamiento de la redundancia entre
los canales izquierdo y derecho a fin de reducir el flujo
·Dual channel. Los dos canales son independientes.
·Mono. Un solo canal de sonido.
La norma MPEG-2 de audio toma lo más esencial de MPEG-1 y prevé además
la posibilidad de extensión ‘multicanal’, que permite la transmisión de sonido por
canales múltiples (por ejemplo ‘Surround sound’, de 5 canales) al tiempo que sigue
siendo compatible con el modo estéreo MPEG-1 básico, lo que permite la evolución
posterior de la especificación DVB.
Los datos suplementarios ‘ancillary data’ se encuentran al final de la trama.
Estos datos son ignorados por un decodificador MPEG-1 de audio estándar, pero si son
tratados por un decodificador MPEG-2 para una extensión complementaria.
La norma MPEG-2 de audio prevé, además, la posibilidad de utilizar
frecuencias de muestreo iguales a la mitad de los valores estándar (16 Khz / 22,05 Khz /
24 Khz), duplicando de esta forma la duración de las tramas y dividiendo el flujo por
dos, a costa, por supuesto, de reducir la banda de paso a la mitad.

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
75
Capa I.
También llamada ‘pre-MUSICAM’, utiliza el algoritmo PASC (Precision
Adaptive Subband Coding), desarrollado por PHILIPS para su casete de audio digital
(DCC). Utiliza una velocidad fija entre las 14 posibles (de 32 a 448 Kbits/seg); la
calidad Hi-Fi necesita 192 Kbits /seg por canal de audio (384 Kbits/seg en estéreo).
Su principal ventaja es la relativa sencillez para la implementación del
codificador y el decodificador. La cuantificación de los coeficientes de subbanda está
definida para toda la duración de la trama por un número de 4 bits, permitiendo una
codificación de 0 a 15 bits para cada subbanda, así como el factor de escala sobre 6 bits.
Capa II.
Su algoritmo se conoce bajo el nombre de MUSICAM, es el estándar adoptado
para la radio (DAB) y televisión (DVB) digitales europeas. Permite obtener una calidad
equivalente con un flujo menor (reducción del 30 % al 50 %) que el de la capa I, a costa
de un incremento moderado de la complejidad tanto del codificador como del
decodificador.
El flujo constante, puede escogerse entre 32 y 192 Kbits/seg por canal, la
calidad subjetiva Hi-Fi se obtiene a partir de 128 Kbits/seg por canal, es decir 256
Kbits/seg en estéreo.
El modelo psicoacústico utilizado es el mismo que para la capa I, pero la trama
tiene el triple de duración, lo que reduce la proporción de bits de ‘sistema’, haciendo
que la cuantificación de los coeficientes de subbanda tenga una resolución decreciente
(cuantificación definida sobre 4 bits para las bandas bajas, 3 bits para las bandas medias
y 2 bits para las bandas más elevadas) en lugar del formato uniforme sobre 4 bits de la
capa I. Por otro lado, 3 muestras de subbanda consecutivas pueden ser eventualmente
reagrupadas en ‘gránulos’ para ser codificadas por un solo coeficiente, de ahí la
reducción del flujo.

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
76
Capa III.
Es de desarrollo más reciente y utiliza un modelo psicoacústico diferente –
llamado ‘modelo 2’-, una codificación Huffman y un análisis de la señal basado en la
DCT en vez de en la codificación en subbandas de las capas I y II. Están permitidos los
dos tipos de codificación joint estéreo.
Permite el flujo variable y una tasa de compresión aproximadamente 2 veces
más elevada que la capa II, a costa de una complejidad claramente mayor del
codificador y del decodificador, así como de un tiempo de codificación/descodificación
más largo. La calidad Hi-Fi se obtiene de los 64 Kbits/seg por canal (128 Kbits/seg en
estéreo).
Esta destinada principalmente a aplicaciones de redes de baja velocidad (por
ejemplo RDSI) y actualmente su utilización no esta prevista en DVB.
Como en el caso de los perfiles y niveles MPEG de vídeo, las capas MPEG de
audio soportan la compatibilidad ascendente entre ellas; es decir, que un decodificador
de capa III descodificará también las capas I y II, y que un decodificador de capa II
descodificara la capa I.
6.4.3. Formato general de la trama MPEG de audio.
La trama constituye la unidad de acceso elemental para una frecuencia de audio
MPEG. Una trama (capa I, II o III), se descompone en 4 partes:
Cabecera de 32 bits (header);
Paridad sobre 16 bits (CRC);
Datos de audio (AUDIO), longitud variable;
Datos auxiliares (AD, ancillary data).

Capítulo 5. Estándar MPEG-2.
Digitalización y compresión de la señal de Televisión
77
Capa I.
La trama MPEG de audio capa I se compone de 384 muestras PCM de audio
de entrada. Como el número de muestras PCM es independiente de la frecuencia de
muestreo, la duración de la trama es inversamente proporcional a la frecuencia de
muestreo. Ésta es de:
12 ms a 32 Khz; 8,7 ms a 44,1 Khz; 8 ms a 48 Khz.
Fig. 5.7. Formato trama MPEG audio Capa I.
Capa II.
La trama se compone en este caso de 12 gránulos de 3 x 32 = 96
muestras de audio PCM, es decir, 36 ms a 32 Khz; 26,1 ms a 44,1 Khz; 24 ms a 48 Khz.
La estructura de la parte de ‘audio’ difiere de la capa I debido a una asignación de bits
más compleja, motivada por la mayor cantidad de opciones de codificación.
Figura 5.8. Formato trama MPEG audio Capa II.

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
78
Capítulo VI:

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
79
CAPÍTULO 6. Múltiplex y Flujo de Transporte
MPEG-2.
6.1. Introducción.
En el conjunto de estándares de TV digital denominado DVB (Digital video
Broadcasting) se especifican los fundamentos de los sistemas para diferentes medios de
transmisión: satélite, cable, difusión terrestre, etc. Cada estándar define los esquemas
decodificación de canal y de modulación para el medio de transmisión de que se trate,
pero en todos los casos la codificación de fuente es una adaptación del estándar
MPEG2.
Más concretamente, la señal de entrada y salida especificada para todos los
sistemas es la denominada “MPEG-2 Transport Stream” (TS) o “Flujo de transporte
MPEG-2".
En este documento se describe la estructura del citado flujo de transporte (TS),
según está definido en el estándar ISO/IEC 13818-1, también se hará referencia al
denominado“MPEG-2 Program Stream” o “Flujo de programa MPEG-2". Este tipo de

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
80
flujo de señal se emplea para almacenamiento y recuperación de información digital en
entornos libres de errores. A diferencia del anterior, que multiplexa varios programas,
éste sólo puede acomodar un programa.
6.2. Empaquetado PES (Packetized Elementary Stream).
Ya en la “Capa de Sistema” nos encontramos con los “Empaquetadores
P.E.S.”, que constituyen el siguiente paso en la generación tanto del múltiplex de
programa como del múltiplex de transporte MPEG-2.
Se trata de convertir cada “Elementary Stream (E.S.)” compuesto
exclusivamente por “Access Units”, en un “Packetised Elementary Stream (P.E.S.)”.
Un P.E.S. está compuesto íntegramente por “PES-Packets”.
Figura 6.1. Conversión de un ES a un PES.
Un “PES-Packet” se compone de una “Cabecera” o “Header” y de una
“Carga Util”o “Payload”.
El “Payload” consiste simplemente en bytes de datos tomados
secuencialmente desde el “Elementary Stream (E.S.)” original. No hay ningún
“Elementary Stream (E.S.)”, compuesto por “unidades de acceso (Access Units)”
“Packetised Elementary Stream (P.E.S.)”, compuesto por “PES-Packets”
PES-PacketPES-Packet
PES-Packet
PES-Packet Payload
“Access “Access “Access A.U
E.S
Conversión de E.S a
P.E.S
P.E.S

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
81
requerimiento para alinear el comienzo de una “Access Unit” y el comienzo de un
“PES-Packet Payload”. Así, una nueva“Access Unit” puede comenzar en cualquier
punto del “Payload” de un “PES - Packet”, y también es posible que varias pequeñas
“Access Unit” estén contenidas en un simple “PES -Packet”.
Los “PES - Packets” pueden ser de longitud variable, limitados normalmente a
64kBytes, aunque la excepción a esta norma se da precisamente en los “Vídeo PES”,
cuando se emplean en un “transport stream”, donde pueden tener longitud indefinida.
Esta flexibilidad en la longitud de los paquetes PES puede ser explotada por los
diseñadores de diferentes maneras: pueden usarse paquetes de longitud fija si interesa, o
por ejemplo pueden ser de longitud variable de forma que siempre coincida el inicio de
una unidad de acceso con el comienzo de la carga útil de cada paquete PES.
6.2.1-. PES- Packet Header.
La figura 6.2 muestra los campos que comprenden la “Cabecera” o “Header”
de un “PES-Packet”. Dicha cabecera tiene longitud variable, e incorpora a su vez datos
para autoinformar de su longitud.
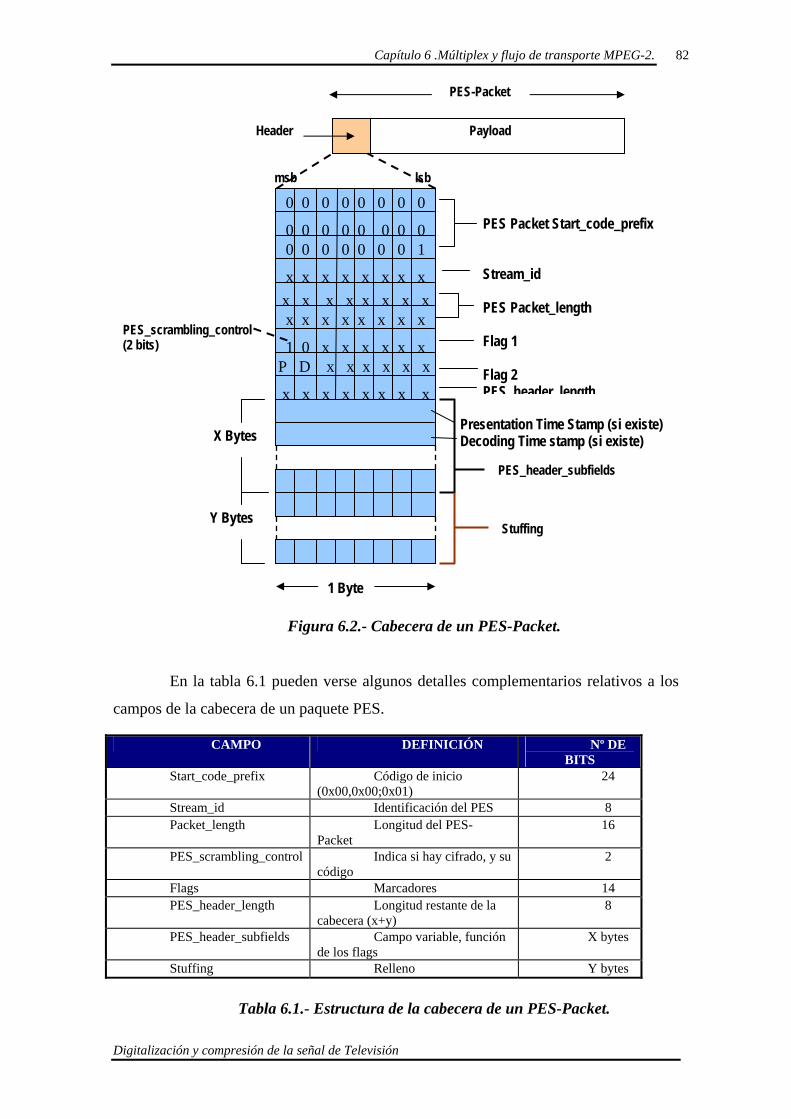
Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
82
Figura 6.2.- Cabecera de un PES-Packet.
En la tabla 6.1 pueden verse algunos detalles complementarios relativos a los
campos de la cabecera de un paquete PES.
Tabla 6.1.- Estructura de la cabecera de un PES-Packet.
CAMPO DEFINICIÓN Nº DE BITS
Start_code_prefix Código de inicio (0x00,0x00;0x01)
24
Stream_id Identificación del PES 8 Packet_length Longitud del PES-
Packet 16
PES_scrambling_control Indica si hay cifrado, y su código
2
Flags Marcadores 14 PES_header_length Longitud restante de la
cabecera (x+y) 8
PES_header_subfields Campo variable, función de los flags
X bytes
Stuffing Relleno Y bytes
msb lsb
PES-Packet
Payload Header
x x x x x x x x
1 0 x x x x x x
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
x x x x x x x x
P D x x x x x x
x x x x x x x x
x x x x x x x x
PES_header_subfields
PES Packet Start_code_prefix Stream_id PES Packet_length Flag 1 Flag 2 PES header length
Presentation Time Stamp (si existe) Decoding Time stamp (si existe)
Stuffing
PES_scrambling_control (2 bits)
X Bytes
Y Bytes
1 Byte

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
83
PES-Packet start code:
Los primeros 4 bytes, es decir: el “PES-packet start code prefix” más el
“Stream_id” constituyen el “PES-Packet start code”. Debe garantizarse que esta
combinación de 32 bits únicamente aparece en el comienzo de la cabecera de un PES-
packet, excepción hecha de los datos de tipo “privado”.
El byte “Stream_id” permite distinguir los PES-packets pertenecientes a los
diferentes Elementary Stream de un mismo Programa. MPEG especifica los valores
permitidos para este campo, disponiéndose de 32 valores para E.S. de audio y de otros
16 valores para E.S. de vídeo.
Flags 1 y 2:
Los bytes “Flag 1" y “Flag 2" son indicadores que muestran la presencia o
ausencia de varios campos opcionales que pueden estar incluidos en la cabecera de un
PES-packet.
Estos campos opcionales llevan información complementaria relativa al PES,
tales como: si está cifrado o no, prioridad relativa, datos de “copyright”, un campo para
identificación de errores en el paquete, etc.
Particularmente importantes son los 2 bits más significativos del “Flag 2",
marcados como P y D en la figura 6.2. Cuando están, estos bits indican respectivamente
la presencia de un campo denominado “Presentation Time Stamp (PTS)” y de otro
campo denominado“Decoding Time Stamp (DTS)” dentro de la cabecera del PES-
packet.
Time Stamps:
Los “Time Stamps” o “marcas de tiempo” son el mecanismo proporcionado
por la “Capa de sistema” de MPEG-2 para asegurar una correcta sincronización en el
decodificador entre “Elementary Streams” que están relacionados. Dichos “Time
Stamps” son valores binarios de 33 bits expresados en unidades de 90kHz.
El más importante de los “Time Stamps” es el “Presentation Time Stamp
(PTS)”.

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
84
Especifica el momento en que una “Unidad de Acceso” debe retirarse del
buffer del decodificador, ser decodificada y seguidamente presentada al espectador.
MPEG supone que todo esto puede realizarse instantáneamente, aunque como en la
práctica lleva algún tiempo, es responsabilidad del diseñador del decodificador resolver
este problema.
En muchos tipos de “Elementary Streams” es suficiente con los PTS, pero en el
caso de Elementary Streams compuestos por vídeo codificado MPEG, puede necesitarse
un segundo tipo de “Time Stamp”, que es el denominado “Decoding Time Stamp
(DTS)”.
Un “DTS” especifica el momento en que una “Unidad de Acceso” debe
retirarse del buffer del decodificador y ser decodificada, pero no presentada al
espectador. En lugar de esto último, la imagen decodificada se almacena temporalmente
para ser presentada más tarde. Tal tratamiento es necesario únicamente para imágenes
de tipo I y P de una secuencia de vídeo codificada MPEG; estas imágenes I y P son las
que por interpolación permiten generar las imágenes de tipo B.
Un “DTS” nunca aparece aislado, sino que debe ir acompañado de un “PTS”,
que es el que informa del momento en que la Unidad de Acceso almacenada
temporalmente debe presentarse al espectador. De esta forma, el PTS siempre será
mayor que su DTS asociado (es decir, posterior en el tiempo), puesto que la
presentación de la imagen al espectador ocurrirá más tarde.
No es necesario ubicar “time stamps” para cada unidad de acceso. El
decodificador normalmente conoce de antemano el ritmo al que las unidades de acceso
tienen que ser decodificadas, siendo suficiente proporcionar ocasionalmente los “time
stamps” simplemente para asegurar el sincronismo del proceso de decodificación a
largo plazo.
El requerimiento especificado en MPEG es que un “time stamp” debe aparecer
al menos cada 0,7 segundos en los PES de vídeo o audio. Por otra parte, si una unidad
de acceso tiene un “time stamp” asociado con ella, entonces ese “time stamp” tiene que
estar codificado en la cabecera del PES-packet en que dicha unidad de acceso comienza.

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
85
PES_header_length:
El “PES header data length field” es el último de los bytes obligatorios de una
cabecera de un PES-packet. Su valor indica el número de bytes opcionales presentes en
la cabecera, hasta que se alcanza el primer byte del “PES-packet payload”.
Hay 25 campos opcionales en una cabecera, que pueden contener por tanto un
total de 200 bits de datos adicionales.
6.3. Múltiplex tipo “PROGRAM STREAM”.
El tipo de múltiplex denominado “Program Stream” o “Flujo de Programa”
se crea a partir de uno o varios PES pertenecientes al mismo Programa Audiovisual, que
deben, compartir obligatoriamente el mismo reloj de referencia.
Este “Program Stream” está compuesto por “packs”, que a su vez
comprenden: una cabecera del pack o “pack-header”, opcionalmente una cabecera de
sistema o “system-header”, y un número indeterminado de PES-packets, tomados de los
Elementary Streams que componen el Programa Audiovisual, en cualquier orden. La
figura 6.2 muestra la estructura de este múltiplex.
Figura 6.3.- Estructura del múltiplex MPEG-2 “Program Stream”
No existe una especificación acerca de la longitud que debe tener cada “pack”
de un “Program Stream”. Únicamente debe aparecer un “pack-header” al menos cada
D
V V V V V V V V V A A D D
Video PES-packet
Opcional “System-header”
Pack-header
Audio PES-packet
Pack-header
Pack-header
V A Data PES-packet
PROGRAM STREAM
“Pack”

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
86
0,7 segundos, puesto que la citada cabecera contiene importante información para la
sincronización: la denominada “Referencia del Reloj de Sistema” o “System Clock
Reference (SCR)”.
En efecto: En un “Program Stream” que puede contener únicamente un
programa audiovisual, el reloj en el multiplexor se llama: “System Clock”. Todas las
Unidades de Acceso de los “Elementary Streams” del programa tienen asignados “time
stamps” basados en este System Clock, que están contenidas en la cabecera de los PES-
packets. A su vez, muestras del “System Clock”, las denominadas “System Clock
Referentes (SCR)” se encuentran codificadas en los campos opcionales de los “pack-
headers” del “Program Stream”. Son números binarios de 42 bits que expresan unidades
de 27MHz.
En el campo opcional “system-header” de un Pack se incluye un sumario de las
características del “Program Stream” tal como: su velocidad binaria máxima, el número
de “Elementary Streams” de vídeo y de audio que lo componen, información
complementaria de temporización, etc. Así, un decodificador puede usar la información
contenida en este “system header” para establecer si es capaz de recuperar la
información del “Program Stream” o no.
El “Program Stream” está concebido para su empleo en entornos libres de
errores, puesto que es bastante vulnerable a ellos. Hay dos razones para esto: En primer
lugar, el “Program Stream” comprende una sucesión de paquetes relativamente largos y
de longitud variable. Como se ha visto, cada paquete comienza con unas cabeceras que
contienen información importante para su recuperación, por lo que cualquier error en
dichas cabeceras puede provocar la pérdida entera del paquete. A su vez, como el
paquete de un “Program Stream” puede contener muchos kilobytes de datos, la pérdida
de un solo paquete puede representar la pérdida o corrupción de una trama de vídeo
completa.
En segundo lugar, la diferente longitud de los paquetes implica que un
decodificador no puede predecir donde termina un paquete y comienza otro, por lo que
se ve obligado a leer e interpretar el campo incluido en la cabecera que informa de la
longitud del paquete. Si este campo que identifica la longitud del paquete se corrompe

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
87
por un error, el decodificador perderá el sincronismo con el flujo de datos, resultando
como mínimo la pérdida de un paquete.
6.4. Múltiplex tipo “TRANSPORT STREAM”. El múltiplex tipo “Transport Stream” está compuesto íntegramente por
“paquetes de transporte” o “transport packets” que tienen siempre una longitud fija de
188 bytes. Cada“paquete de transporte” incluye una “Cabecera” o “Header” (4 bytes)
seguida a veces de un “Campo de Adaptación” o “Adaptation Field” (usado
eventualmente para rellenar el exceso de espacio disponible) y en cualquier caso, de una
“Carga Útil” o “Payload”.
Los paquetes de transporte se forman a partir de los “PES-Packets”
correspondientes a cada “Flujo Elemental” de señal (vídeo, audio, datos, etc.), según se
muestra en la figura 6.4.
Figura 6.4.- División de un “P. E. S.” en una serie de “Transport Packets”
El proceso de formación de los paquetes de transporte está sujeto al
cumplimiento de las dos condiciones fundamentales siguientes:
a). El primer byte de cada PES-Packet debe ser el primer byte del “payload“ de
un transport packet.
Header Payload Adaptation field (usado para rellenar
espacio sobrante)
P.E.S Packets
Transport Packets
“Packetised elementary Stream (P.E.S)”, compuesto por “PES-Packets”

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
88
b). Un transport packet solamente puede contener datos tomados de un PES-
Packet.
Es improbable que un PES-packet rellene las “cargas útiles” de un número
entero de paquetes de transporte de forma exacta. Como se muestra en la figura 6.4, con
frecuencia se dará el caso de que, para no contravenir las dos condiciones anteriores, el
espacio sobrante del último paquete de transporte correspondiente a un PES-packet, se
rellene deliberadamente mediante un “campo de adaptación” de longitud apropiada.
Este despilfarro de espacio puede minimizarse mediante una elección
cuidadosa de la longitud de los PES-packets. En principio, PES-packets muy largos
asegurarían una mayor proporción de paquetes de transporte completamente llenos de
datos útiles. Además de la función de relleno, el Campo de Adaptación se utiliza también
para la transmisión del “Reloj de Referencia del Programa” o “Program Clock
Reference” (PCR).
Estas marcas de tiempo, que permiten sincronizar el reloj del decodificador con
el “Program Clock” del Programa al que pertenecen los paquetes de transporte, deben
aparecer en el “Transport Stream” al menos una vez cada 0,1 segundos.
6.4.1. Formación del “Transport Stream”.
Los paquetes de transporte resultantes del proceso anterior, aplicado a cada uno
de los flujos elementales de señal (vídeo, audio, datos, etc.) pertenecientes a su vez a
varios programas audiovisuales, se disponen secuencialmente para configurar el “Flujo
de Transporte MPEG-2" o “MPEG-2 Transport Stream” (TS).
No existen condiciones en cuanto al orden en que los paquetes de transporte
deben aparecer en el múltiplex tipo TS; tan sólo debe respetarse el orden cronológico de
los paquetes de transporte pertenecientes a un mismo flujo elemental.
Es importante destacar que en el TS, además de los paquetes de transporte
asociados a los flujos elementales de señal, es necesario incorporar paquetes de

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
89
transporte que contienen información sobre el servicio, así como paquetes de transporte
“nulos” que se emplean para absorber eventuales reservas de capacidad del múltiplex.
La figura 6.5 ilustra de forma simplificada el proceso de conformación del
múltiplex “MPEG-2 Transport Stream”.
Figura 6.5.- Conformación del múltiplex “Transport Stream” a partir de un
número prácticamente ilimitado de flujos elementales de señal.
6.4.2. “Transport Packet”. La figura 6.6 ilustra la estructura de un “paquete de transporte” o “transport
packet”.
Figura 6.6. Estructura de un “transport packet”
“Adaptation Field” (Eventual) Payload
1er byte PID (13 Bits)(identificador del paquete de transporte)
4º byte
Sync_byteTransport_error_indicator
Payload_unit_start_indicatorTransport_priority
Transport Packet Header
TRANSPORT PACKET
188 bytes
msb lsb adaptation_field_control continuity_counter
Transport_scrambling_control
0 1 0 0 0 1 1 1
V V A V V D SI
V
A A A A A
V V V V V
SI
SI
SI
SI
SI
D D D D D
N N N N N
Paquete de transporte de video
Paquete de transporte de audio
Paquete de transporte de datos
Paq. de trans. con info de servicioPaquete de transporte nulos
MPEG-2 Transport Stream

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
90
6.4.2.1 Transport Packet Header. A diferencia de los “PES-Packet”, cuya cabecera tiene longitud variable,
la cabecera o “header” de un paquete de transporte tiene siempre una longitud fija de 4
bytes. El formato de esta cabecera puede verse en la figura 6.6 y en la tabla 6.2:
Tabla 6.2.- Estructura de la cabecera de un Paquete TS. De los varios campos que contiene la cabecera de un paquete de transporte, hay
4 que son particularmente importantes:
Sync Byte:
Es el primer byte de la cabecera y siempre tiene el valor 47 (hexadecimal).
Dicho valor no es único dentro de un paquete de transporte y puede ser bastante
frecuente que aparezca en otros campos. Sin embargo, el hecho de que un “sync byte”
aparezca siempre cada 188 bytes dentro de un transport stream hace fácil el proceso de
su localización por los decodificadores para identificar el comienzo de cada paquete de
transporte.
Packet Identifier (PID):
Como se ha explicado, un TS puede contener muchos programas diferentes,
cada uno de los cuales contiene a su vez muchos flujos elementales distribuidos en
paquetes de transporte. El campo de 13 bits “Packet Identifier (PID)” se emplea para
distinguir los paquetes de transporte asociados a un determinado flujo elemental, de
entre todos los demás.
CAMPO DEFINICIÓN Nº DE BITS
Sync_byte Byte de sincronización 0100 0111 (0x47) 8
Transport_error_indicator Identifica un error detectado más atrás 1 Payload_unit_start_indicator Inicio de PES en el paquete de transporte 1
Transport_priority Indicador de prioridad 1 PID Identificador del paquete de transporte 13 Transport_scrambling_control Tipo de cifrado de transporte 2 Adaptation_field_control Control del campo de adaptación en el paquete 2
Continuity_counter Contador de continuidad entre paquetes afines 4

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
91
De los 213 valores posibles para el PID, 17 están reservados para usos
especiales. Esto deja 8.175 posibles valores que pueden asignarse a los diferentes flujos
elementales, por lo que esta cifra representa el máximo número de éstos que un TS
puede contener. Es responsabilidad del multiplexor asegurar que cada flujo elemental
tenga asignado un exclusivo valor de PID de entre todos los posibles. Por lo demás,
MPEG no condiciona la asignación de valores concretos a los diferentes flujos
elementales.
Payload Unit Start Indicator:
Se pone a 1 para indicar que el primer byte del “payload” del paquete de
transporte es también el primer byte de un PES-packet.
Continuity count field:
Se incrementa entre sucesivos paquetes de transporte pertenecientes al mismo
flujo elemental. Esto permite al decodificador detectar la pérdida o ganancia de un
paquete y así poder ocultar los errores que de otra forma podrían presentarse.
6.5. Tabla de Asociación de Programas (PAT) y Tabla de Mapa de Programas (PMT).
Program Association Table (PAT):
Esta tabla, de inclusión obligatoria, es transportada por los paquetes con
PID=0x0000 y contiene una lista completa de todos los programas disponibles en el
Transport Stream. Cada programa aparece junto con el valor del PID de los paquetes
que a su vez contienen la tabla con los datos que identifican a dicho programa (Program
Map Table,PMT).
La PAT debe transmitirse sin cifrar aunque todos los demás programas lo estén.

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
92
Figura 6.7. Representación de una tabla PAT
Como se muestra a modo de ejemplo en la figura 6.7, una sola Program
Map Table (la nº 244) puede contener los detalles de varios programas (los numerados
como 7, 8 y 10).
Conditional Access Table (CAT):
Esta tabla debe estar presente si al menos un programa del múltiplex es de
acceso condicional. Se transporta por los paquetes con PID=0x0001, y proporciona
detalles de los sistemas de cifrado empleados, así como los valores de los PID de los
paquetes de transporte que contienen la información del control de acceso condicional.
Los datos para el acceso condicional se envían en forma de “Entitlement
Management Messages (EMM)”. En estos “EMM” se especifican los niveles de
autorización o los servicios a que pueden acceder determinados decodificadores, y
pueden ir dirigidos a decodificadores individuales o a grupos de ellos.
Paquete de transporte conteniendo la Program Association Table (PAT)
Nº de Valor de PID de la prog. program map table
0 10 1 306 3 1127
18 17 7 244 8 244 10 244 4 17
Network information
table ----- ----------- ----- ----------- ----- ----------- ----- -----------
Program Map Table para el
Prog. Nº 1 ----- ----------- ----- ----------- ----- ----------- ----- -----------
Program Map Table para el
Prog. Nº 3 ----- ----------- ----- ----------- ----- ----------- ----- -----------
PID= 0X0000

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
93
El formato de esta información no está especificado en MPEG-2, puesto que
depende del tipo de sistema de cifrado empleado.
Program Map Table (PMT):
Cada programa audiovisual incluido en un Transport Stream tiene una tabla
PMT asociada con él. Dicha tabla proporciona detalles acerca del programa y de los
flujos elementales que comprende.
Según MPEG-2, las tablas PMT pueden ser transportadas por paquetes con
valores de PID arbitrarios, exceptuando los valores 0x0000, reservado para PAT, y
0x0001 reservado para CAT. Sin embargo, las especificaciones DVB-SI también
restringen el uso de los valores de PID que van desde 0x0002 hasta 0x001F (ver tabla
6.3).
En la figura 6.8 se muestra un ejemplo de tabla PMT. Mediante ella, un
decodificador puede determinar que el flujo elemental codificado de vídeo
correspondiente al programa nº 3 se encuentra en los paquetes de transporte
identificados mediante el PID=726 y que el flujo elemental cuyos paquetes están
etiquetados con PID = 57 lleva el audio correspondiente en inglés.
Figura 6. 8. Ejemplo de una tabla PMT
Paquete de transporte conteniendo la Program Map Table (MT) del programa nº3
PID= 1127
Program Map Table para el Prog. Nº 3 PID para el Program Clock Referente=726 PID para el Video=726 PID para el Audio (Inglés)=57 PID para el Audio (Francés)=60 PID para el Audio (Alemán)=1022 PID para subtitulos=123
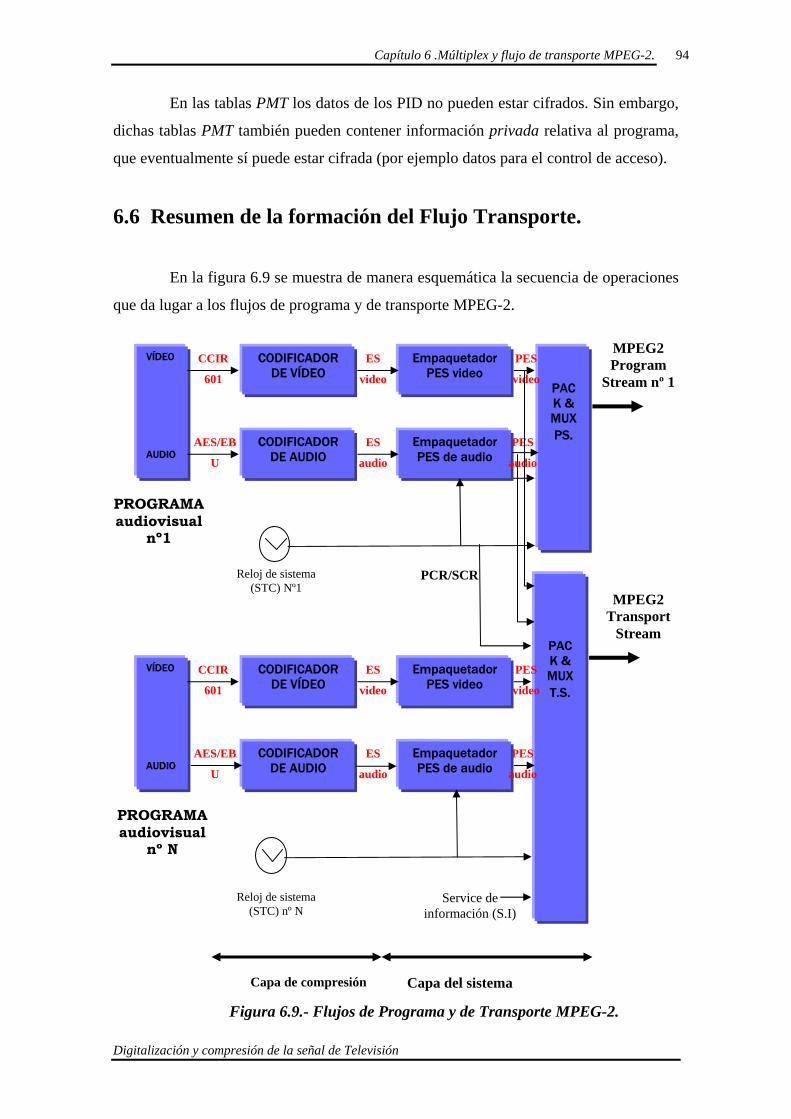
Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
94
En las tablas PMT los datos de los PID no pueden estar cifrados. Sin embargo,
dichas tablas PMT también pueden contener información privada relativa al programa,
que eventualmente sí puede estar cifrada (por ejemplo datos para el control de acceso).
6.6 Resumen de la formación del Flujo Transporte.
En la figura 6.9 se muestra de manera esquemática la secuencia de operaciones
que da lugar a los flujos de programa y de transporte MPEG-2.
Figura 6.9.- Flujos de Programa y de Transporte MPEG-2.
Reloj de sistema (STC) nº N
PACK & MUX PS.
VÍDEO AUDIO
CODIFICADOR DE VÍDEO
CODIFICADOR DE AUDIO
Empaquetador PES video
Empaquetador PES de audio
PACK & MUX T.S.
PROGRAMA audiovisual
nº1
CCIR
601
AES/EB
U
ES
video
ES
audio
PES
video
PES
audio
Reloj de sistema (STC) Nº1
PCR/SCR
VÍDEO AUDIO
CODIFICADOR DE VÍDEO
CODIFICADOR DE AUDIO
Empaquetador PES video
Empaquetador PES de audio
PROGRAMA audiovisual
nº N
CCIR
601
AES/EB
U
ES
video
ES
audio
PES
video
PES
audio
Service de información (S.I)
Capa del sistema Capa de compresión
MPEG2 Program
Stream nº 1
MPEG2 Transport
Stream

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
95
Dicha secuencia de operaciones puede dividirse en dos grandes bloques,
denominados “Capa de Compresión” y “Capa de Sistema”:
En la “Capa de Compresión” se realizan las operaciones propiamente dichas
de codificación MPEG, recurriendo a los procedimientos generales de compresión de
datos, y aprovechando además, para las imágenes, su redundancia espacial (áreas
uniformes) y temporal (imágenes sucesivas), la correlación entre puntos cercanos y la
menor sensibilidad del ojo a los detalles finos de las imágenes fijas.
En cuanto al audio, se utilizan modelos psicoacústicos del oído humano, que
tienen en cuenta la curva de sensibilidad en frecuencia (máxima entre 1 y 5 kHz), los
efectos de enmascaramiento frecuencial (señales simultáneas a diferentes frecuencias) y
enmascaramiento temporal (un sonido de elevada amplitud enmascara sonidos más
débiles anteriores o posteriores), para reducir la cantidad de datos que hay que
transmitir, sin deteriorar de forma perceptible la calidad de la señal de audio.
En la “Capa de Sistema” se realizan las operaciones que conducen a la
obtención de los flujos de señal MPEG-2, consistente en la organización en “paquetes”,
de los datos comprimidos y el posterior multiplexado de todas las señales asociadas al
programa (vídeo, audio, datos, etc).
En el caso de Flujos de Programa MPEG-2, se multiplexan todos los
componentes del programa (vídeo, audio, datos, etc.) y se incorpora el reloj del sistema,
pero solamente se transmite la información correspondiente a un único programa
audiovisual.
En cambio, en el caso de Flujos de Transporte MPEG-2, además de la
posibilidad de multiplexado de varios programas audiovisuales, se añaden en el
múltiplex diversas informaciones relativas al servicio: Tabla de Asociación de
Programas (PAT), Información para Acceso Condicional (CAT), Mapa de cada
Programa (PMT), Tabla de datos de la red (NIT), etc.

Capítulo 6 .Múltiplex y flujo de transporte MPEG-2.
Digitalización y compresión de la señal de Televisión
96
Características básicas de los flujos MPEG-2:
Conviene resaltar dos características notables de los múltiplex MPEG-2:
No existen protecciones contra errores dentro del
múltiplex. Las citadas protecciones y la subsiguiente modulación de los
flujos MPEG son objeto de bloques de procesado posteriores, que son
función del medio de transmisión elegido.
No hay especificación física o eléctrica para los múltiplex
MPEG. El diseñador puede elegir los niveles de señal y tipo de conector
que mejor se adapte a su aplicación.
Terminología empleada:
“Program” o “Programa”
Según la terminología MPEG, “Program” significa: Un servicio o canal
simple de radiodifusión.
“Elementary Stream” (E.S.) o “Flujo Elemental”.
Un “Elementary Stream” es el nombre dado a cada componente simple de un
“Programa”, después de que se ha codificado digitalmente y comprimido según MPEG,
Así, un programa ya comprimido de TV se compone de varios “Elementary Streams”:
Uno para el vídeo, varios para sonido estéreo en diferentes idiomas, otro para el
teletexto, etc.
“Packetised Elementary Stream” (P.E.S.).
Cada “Elementary Stream” se estructura en paquetes, dando lugar a un flujo
que se denomina “Packetised Elementary Stream” (P.E.S.), y que está compuesto por
“PES-packets”.Como cada P.E.S. se obtiene directamente de cada E.S., y éstos son
independientes, existirá por tanto un P.E.S. por cada E.S. original.

Capítulo 7. Bibliografía.
Digitalización y compresión de la señal de Televisión
97
Capítulo VII:

Capítulo 7. Bibliografía.
Digitalización y compresión de la señal de Televisión
98
CAPÍTULO 7. Bibliografía
7.1 Introducción. En este capítulo se van a exponer los títulos de las obras utilizadas en la
documentación sobre el contenido de esta monografía. Así mismo también se indicarán
las direcciones de las páginas web consultadas para la búsqueda de información.
7.2 Bibliografía.
[1] “Televisión Digital”
Autor: Hervé Benoit.
Editorial: Paraninfo.
[2] “Sistemas para la Recepción de TV Analógica y Digital”
Autor: Televés.
Editorial: Televés.

Capítulo 7. Bibliografía.
Digitalización y compresión de la señal de Televisión
99
[3] “Televisión Digital; MPEG-2 y DVB”
Autor: Luis Ortiz Berenguer.
Editorial: E.U.I.T.T. – UPM.
[4] “Televisión por Satélite”
Autor: F.A. Wilson.
Editorial: CEAC.
[5] “Fundamentos de Comunicaciones Analógicas y Digitales”
Autores: José Ramón Velázquez Monzón, Santiago Tomas Pérez
Suárez, Sofía Martín González, Rafael Pérez Jiménez, Juan Ruiz Alzola.
Editorial: Departamento de Señales y Sistemas – ULPGC.
[6] “Principles of Digital Comunications and Coding”
Autores: Andrew J. Viterbi, Jim K. Omura.
Editorial: McGrawHill.
7.3 Direcciones WEB.
www.dvb.org www.dvbgroup.com
www.etsi.org.
www.mpeg.org.
www.monografias.com/trabajos10/vire/vire.shtml.
www.gti.ssr.upm.es/gente/ex/pfcs/pfces/fss/introduccion.html.
www.imagendv.com/mpeg.htm.
http://en.wikipedia.org/wiki/Run_length_encoding.
www.tvdi.net/