Embed Size (px)
Citation preview

1

2
TABLA DE CONTENIDO Tabla de ilustraciones ............................................................................................ 4
1 Resumen ......................................................................................................... 8
2 Introducción .................................................................................................... 9
2.1 El sonido .................................................................................................. 9
2.1.1 Impedancia característica e intensidad acústica ................................11
2.1.2 Frecuencia, periodo, longitud de onda y amplitud ..............................13
2.1.3 Velocidad de propagación ..................................................................17
2.1.4 Espectrogramas .................................................................................18
2.2 Sonidos Pulmonares ...............................................................................27
2.3 Sibilancias ...............................................................................................30
2.3.1 Diferencias existentes entre sibilancias, roncus o ruttles ....................32
3 Objetivos ........................................................................................................35
4 Estado del arte ...............................................................................................36
5 Implementación ..............................................................................................50
5.1 Diagrama de bloques del software propuesto .........................................50
5.2 Implementación de cada bloque ..............................................................52
5.2.1 Etapa 1: adquisición de señal ............................................................52
5.2.2 Etapa 2: transformación tiempo-frecuencia. Cálculo de espectrograma
52
5.2.3 Etapa 3: cálculo de picos más significativos .......................................55
5.2.4 Etapa 4: construcción de trayectorias ................................................60
5.2.5 Etapa 5: clustering de sibilancias .......................................................70
6 Evaluación .....................................................................................................75
6.1 Base de datos. ........................................................................................75
6.1.1 Base de datos de optimización ..........................................................76
6.1.2 Base de datos de testeo I...................................................................76
6.1.3 Base de datos de testeo II..................................................................79
6.2 Métricas ..................................................................................................81
6.3 Fase de optimización ..............................................................................83

3
6.3.1 Optimización a nivel de frame ............................................................84
6.3.2 Optimización a nivel de evento ..........................................................90
6.4 Testeo I ...................................................................................................93
6.5 Testeo II ..................................................................................................97
7 Conclusiones y líneas futuras ....................................................................... 101
8 Bibliografía ................................................................................................... 105
9 Manual de usuario: uso del GUI ................................................................... 108
9.1 Inicio de programa ................................................................................ 109
9.2 Selección de parámetros ....................................................................... 110
9.3 Salida de datos ..................................................................................... 113
9.4 Espectrograma ...................................................................................... 115

4
TABLA DE ILUSTRACIONES
Figura 2.1 – Curvas isofónicas [22] ......................................................................15
Figura 2.2 Ejemplo de enmascaramiento NMT [22] ..............................................17
Figura 2.3 – Espectrograma de una señal con sibilancias usando una ventana de
Hanning de 512 muestras de longitud. .............................................................................23
Figura 2.4 - Espectrograma de una señal con sibilancias usando una ventana de
Hanning de 1024 muestras de longitud. ...........................................................................24
Figura 2.5 - Espectrograma de una señal con sibilancias usando una ventana de
Hanning de 2048 muestras de longitud. ...........................................................................24
Figura 2.6 - Espectrograma de una señal con sibilancias usando una ventana
rectangular de 512 muestras de longitud. ........................................................................25
Figura 2.7 - Espectrograma de una señal con sibilancias usando una ventana
rectangular de 1024 muestras de longitud. ......................................................................25
Figura 2.8 - Espectrograma de una señal con sibilancias usando una ventana
rectangular de 2048 muestras de longitud. ......................................................................26
Figura 2.9 – Ventana rectangular en el dominio de la frecuencia [23] ...................27
Figura 2.10 – Ventana de Hanning en el dominio de la frecuencia. [23] ...............27
Figura 2.11 - Relación entre los términos sonido respiratorio, sonido adventicio y
sonido pulmonar [2]. ........................................................................................................29
Figura 2.12 – Espectrograma de una respiración con estertores o crepitantes
gruesos. ...........................................................................................................................29
Figura 2 13 - Análisis espectral de una respiración normal (arriba) y análisis
espectral de una respiración con sibilancias (abajo) [3]. ..................................................31
Figura 2.14 - Análisis espectral de una grabación normal (A), con sibilancias (B) y
con ruttles (C) [9]. ............................................................................................................33
Figura 4.1 - Diagrama de una respiración humana [8]. .........................................37
Figura 4.2 – Ejemplos de espectrogramas de una respiración sana (a), una con
sibilancias (b) y otra con ruttles (c) [5]. .............................................................................39
Figura 4.3 – Comparación entre respiraciones con distintos sonidos adventicios
[10]. .................................................................................................................................40
Figura 4.4 – Espectrogramas que muestran los picos más significativos obtenidos
en el análisis mediante el sistema WED [11]. ..................................................................41
Figura 4.5 – Resultados del análisis de respiraciones de los 12 sujetos
participantes en la prueba realizada en [13]. ....................................................................43

5
Figura 4.6 – Espectrograma de una respiración sana (a) y de una respiración con
sibilancias (b), mostrando el rango en frecuencia donde suelen aparecer los picos más
significativos [14]. ............................................................................................................44
Figura 4.7 – Diagrama de bloques del algoritmo propuesto en [14]. .....................45
Figura 4.8 – Esquema de la implementación del software propuesto en el artículo
[15]. .................................................................................................................................46
Figura 4.9 – Esquema del sistema propuesto en [24] ...........................................47
Figura 4.10 – a) diagrama de bloques implementado en el módulo de adquisición.
b) hardware que compone el módulo. c) sensor acústico. [24] .........................................48
Figura 4.11 – Diagrama de bloques del software propuesto en [24]. ....................48
Figura 4.12 – Resultados obtenidos en [24] .........................................................49
Figura 5.1 - Esquema de la implementación del software ....................................51
Figura 5.2 - Espectrograma de una señal de audio con sibilancias. .....................54
Figura 5.3 - Espectrograma de una señal de audio con sibilancias, ejemplo 2. ....55
Figura 5.4 – Representación del frame número 115 de la matriz Vabs. ................56
Figura 5.5 - Picos más significativos obtenidos mediante "findpeaks" de la señal
de audio "6025.wav". .......................................................................................................58
Figura 5.6 - Picos más significativos obtenidos mediante "findpeaks" de la señal
de audio "Wheeze-Bronchiolitis2.wav". ............................................................................59
Figura 5.7 - Parte del contenido de la matriz "posicion_picos" extraída del audio
"6025.wav". ......................................................................................................................59
Figura 5.8 – Trayectoria extraída en el proceso de detección de sibilancias para el
audio "143Post7R.wav". ..................................................................................................61
Figura 5.9 - Ejemplo de ventana deslizante ..........................................................63
Figura 5.10 - Ejemplo de una trayectoria contenida en la matriz "trayectorias"
extraída del audio "6025.wav". .........................................................................................65
Figura 5.11 - Ejemplo de interpolación 1 ..............................................................66
Figura 5.12 - Ejemplo de interpolación 2 ..............................................................66
Figura 5.13 - Zoom sobre una trayectoria sin interpolar para "6025.wav" ............67
Figura 5.14 - Zoom sobre una trayectoria interpolada para "6025.wav" ................68
Figura 5.15 - Zoom sobre una trayectoria sin interpolar para "Wheeze-
Bronchiolitis2.wav" ...........................................................................................................69
Figura 5.16 - Zoom sobre una trayectoria interpolada para "Wheeze-
Bronchiolitis2.wav" ...........................................................................................................69
Figura 5.17 - Zoom sobre las trayectorias consideradas sibilancias para
"6025.wav". ......................................................................................................................71

6
Figura 5.18 - Zoom sobre las trayectorias consideradas sibilancias para "Wheeze-
Bronchiolitis2.wav". ..........................................................................................................71
Figura 5.19 – Espectro de una onda cuadrada de amplitud 1 dB y frecuencia 100
Hz con armónicos impares [26]. .......................................................................................72
Figura 5.20 - Armónicos de una sibilancia ............................................................73
Figura 6.1 – Sibilancia número dos (sib2.wav) que se extrae del audio "6025.wav"
........................................................................................................................................78
Figura 6.2 – Espectrograma de la respiración vesicular normal "respiracion.wav".
........................................................................................................................................78
Figura 6.3 – Resultado de la suma de "sib2.wav" sobre la segunda inspiración de
"respiracion.wav" con una diferencia de potencia de 5dB. ...............................................79
Figura 6.4 - Fragmento del vector usado como patrón para una ventana de 512
muestras ..........................................................................................................................85
Figura 6.5 - Fragmento del vector de sibilancias devuelto por el programa principal
para una ventana de 512 muestras ..................................................................................85
Figura 6.6 - Ejemplo de la tabla de datos tras la fase de optimización a nivel de
frame. ..............................................................................................................................86
Figura 6.7 - Ejemplo de la matriz de datos obtenidos tras la fase de optimización a
nivel de eventos ...............................................................................................................91
Figura 6.8 – Esquema de la implementación de la fase de testeo I. .....................94
Figura 6.9 – Esquema de la implementación de la fase de testeo II .....................98
Figura 9.1 - Secciones de la interfaz de usuario ................................................. 108
Figura 9.2 - Apartado 1 de la interfaz ................................................................. 109
Figura 9.3 – Mensaje de aviso en la selección de audio. .................................... 109
Figura 9.4 - Apartado 2 de la interfaz ................................................................. 110
Figura 9.5 – Ejemplo de menú desplegable. ....................................................... 110
Figura 9.6 – Menú desplegable para la selección de paciente. ........................... 111
Figura 9.7 – Menú desplegable para la selección del rango en frecuencia. ........ 111
Figura 9.8 – Menú desplegable para la selección del rango en tiempo. .............. 112
Figura 9.9 – Ejemplo de menú desplegable en el campo "Duración mínima" de la
interfaz. .......................................................................................................................... 112
Figura 9.10 – Mensaje de aviso al no seleccionar correctamente una duración
mínima de trayectoria .................................................................................................... 112
Figura 9.11 - Apartado 2 de la interfaz................................................................ 113

7
Figura 9.12 – Salida de datos en una prueba realizada con el audio "6025.wav"
...................................................................................................................................... 113
Figura 9.13 – Mensaje de aviso en el que se indica que no se han detectado
sibilancias en el audio introducido. ................................................................................. 113
Figura 9.14 – Panel de botones para visualizar cada una de las etapas. ............ 114
Figura 9.15 – Botones para reproducir o grabar las sibilancias especificadas en el
panel mostrado en la figura 9.16. ................................................................................... 114
Figura 9.16 – Panel de selección de sibilancia a reproducir o guardar como
archivo .wav. .................................................................................................................. 114
Figura 9.17 - Ejemplo de espectrograma con bandas limitadoras....................... 115
Figura 9.18 - Localización de la barra de herramientas ...................................... 116
Figura 9.19 - Zoom sobre Etapa 4 ...................................................................... 116

8
1 RESUMEN
Este Trabajo Fin de Grado se centrará en el análisis de señales sonoras
procedentes de la respiración humana con el propósito de poder detectar mediante
software la existencia o no de sibilancias en el audio procesado. En primer lugar,
conoceremos las características que definen la onda mecánica analizada. Mediante una
introducción se mostrará qué es el sonido como concepto de onda, describiremos las
características del sonido generado por una respiración humana y veremos las
principales características que nos permitirán detectar y diferenciar el principal objetivo de
este trabajo: las sibilancias pulmonares. A continuación, presentaremos la problemática
existente a día de hoy en la detección de estos sonidos pulmonares. La no objetividad en
el oído humano a la hora de interpretar los sonidos y detectar ciertos parámetros como
frecuencia, musicalidad, etc. en la respiración humana puede desencadenar en un mal
diagnóstico por parte del médico, pudiendo perjudicar al paciente que padece estas
irregularidades pulmonares.
Tras presentar los principales objetivos que se desean alcanzar con este trabajo,
analizaremos el estado del arte referido a la detección de irregularidades pulmonares
mediante el análisis de señales sonoras.
Una descripción detallada del software implementado en este trabajo será
presentada y se mostrarán las etapas seguidas a la hora de realizar su evaluación y
comparación con otros métodos ya implementados. Seguidamente, se tomarán una serie
de conclusiones al respecto a partir de las cuales se intentará definir el futuro de este
trabajo.
Finalmente, se mostrará la bibliografía utilizada para la recaudación de
información y un manual de usuario para el uso del programa será presentado.

9
2 INTRODUCCIÓN
Hasta hace relativamente pocos años, la detección de multitud de irregularidades
pulmonares ha sido llevada a cabo por un médico capacitado, realizada mediante el uso
del tradicional estetoscopio (también llamado fonendoscopio), mediante técnicas
radiológicas u otros métodos no invasivos. Si nos centramos por completo en las técnicas
basadas en la escucha de sonidos pulmonares, es importante destacar que tanto la
captación de sonidos procedentes del estetoscopio en el oído como su interpretación en
el cerebro humano están sujetos a un conjunto de imperfecciones que imposibilitan el
hecho de obtener una serie de conclusiones y resultados totalmente objetivos por parte
del médico encargado de realizar el diagnóstico. Debemos remarcar la importancia que
tiene el hecho de detectar cuanto antes sonidos como las sibilancias en pacientes de
corta y avanzada edad ya que se trata de grupos de riesgo altamente vulnerables a
enfermedades pulmonares tales como el asma, bronquitis o neumonía. En definitiva, una
rápida y eficaz detección de este tipo de sonidos pulmonares podrá evitar en gran medida
posibles daños mayores e irreversibles causados por las enfermedades ya mencionadas.
Es en este documento donde se presenta un método de detección de sibilancias
no invasivo basado en un software capaz de llevar a cabo un análisis espectral de una
señal sonora pulmonar mediante el cómputo de parámetros objetivos. Para poder
entender el proceso llevado a cabo es importante tener claro ciertos conceptos
relacionados con las señales sonoras, más en concreto con las generadas por la
respiración humana. Para la correcta detección e identificación de sibilancias también es
importante tener claro qué es lo que intentamos detectar, sus características más
importantes y que rasgos diferencian a las sibilancias del resto de irregularidades
pulmonares. Por ello, a continuación se muestra una descripción de los conceptos más
importantes mencionados en el desarrollo de este trabajo.
2.1 El sonido
Según nos refiramos a la palabra "sonido", la Real Academia Española nos
presenta varias definiciones de entre las cuales tendremos en cuenta sobretodo dos. En
la primera entrada esta palabra es definida de la siguiente manera: "Sensación producida
en el órgano del oído por el movimiento vibratorio de los cuerpos, transmitido por un
medio elástico, como el aire". En la cuarta entrada del diccionario se nos presenta una
definición tal que "Vibración mecánica transmitida por un medio elástico". Como vemos,
la primera definición engloba a la segunda, aunque ésta última añade un matiz: "vibración
mecánica". Por lo tanto, el sonido es consecuencia de las ondas acústicas, principal
fenómeno físico estudiado en este TFG. Dichas ondas son mecánicas y surgen por

10
consiguiente de las vibraciones de las partículas que componen el medio elástico. La
dirección de los movimientos vibratorios de las partículas puede ser paralela a la
dirección de propagación de la onda, lo que nos indica que además, las ondas acústicas
son mecánicas y longitudinales (el sonido se propaga de esta forma en gases, líquidos y
en la mayoría de sólidos), por el contrario, si dicho movimiento vibratorio es perpendicular
a la dirección de propagación, las ondas acústicas son mecánicas y transversales. Para
que finalmente esta onda sea descrita como un sonido, debe poder ser percibida por una
persona o instrumento, es decir, debe excitar al oído y ser interpretada por el cerebro,
obviamente en el caso de un ser humano.
Si nos centramos en la propagación del sonido en el aire debemos tener en
cuenta que las vibraciones de las partículas que forman las ondas acústicas
longitudinales generarán zonas de altas y bajas presiones moleculares en el medio, es
decir, la propagación del sonido en el aire implica la existencia de zonas de compresión y
zonas de descompresión. La forma más sencilla de caracterizar una onda acústica que
se propaga por el aire es mediante ondas armónicas ya que se trata de una forma de
excitación periódica simple a partir de la cual pueden expresarse ondas más complejas.
Existe una solución matemática que consiste en expresar varios parámetros que
caracterizan una onda sonora en el aire de tal forma que quede expresada como la
combinación de dos ondas armónicas, a continuación, en las ecuaciones (1), (2) y (3) se
muestran las tres variables acústicas a partir de las cuales podremos definir ciertas
características del sonido
𝜁(𝑥, 𝑡) = �̂�𝑒𝑗(𝜔𝑡−𝑘𝑥) + �̂�𝑒𝑗(𝜔𝑡+𝑘𝑥) (1)
𝑝(𝑥, 𝑡) = 𝑗𝜌0𝑐𝜔( �̂�𝑒𝑗(𝜔𝑡−𝑘𝑥) + �̂�𝑒𝑗(𝜔𝑡+𝑘𝑥)) (2)
𝜇(𝑥, 𝑡) = 𝑗𝜔( �̂�𝑒𝑗(𝜔𝑡−𝑘𝑥) − �̂�𝑒𝑗(𝜔𝑡+𝑘𝑥)) (3)
Donde 𝜁(𝑥, 𝑡) es una función armónica sinusoidal y periódica en 𝑡 (tiempo) que
representa el movimiento o desplazamiento en metros de las partículas del medio debido
a la propagación de una onda acústica, compuesta por �̂� y �̂�, amplitudes complejas de
onda plana longitudinal con frecuencia 𝜔 y número de onda 𝑘 que representan la
propagación de ambas ondas planas en la dirección positiva y negativa del eje x,
respectivamente, con velocidad c. De forma similar, 𝑝(𝑥, 𝑡) y 𝜇(𝑥, 𝑡) son funciones

11
armónicas que representan la presión acústica expresada en Pascales (Pa) y la velocidad
de vibración (m/s) de las partículas, respectivamente. Si nos centramos en la propagación
en dirección positiva con respecto al eje x, 𝑝(𝑥, 𝑡) y 𝜇(𝑥, 𝑡) viajan en fase y están
desplazadas 90º con respecto a 𝜁(𝑥, 𝑡). En cambio, la propagación en el sentido negativo
del eje x, 𝑝(𝑥, 𝑡) y 𝜇(𝑥, 𝑡) están desfasadas 180º entre sí, mientras que 𝜁(𝑥, 𝑡), sigue
mostrando un desfase de 90º con respecto a ambas.
Como podemos apreciar en las expresiones anteriores, en función de las
separaciones entre zonas de alta y baja presión, la variación de presión en éstas y la
velocidad de vibración y propagación de las perturbaciones en el medio, definiremos una
serie de parámetros físicos que caracterizarán al sonido como onda sinusoidal. Además,
se mostrará una herramienta fundamental para el análisis de muestras de audio utilizado
en el software detector de sibilancias.
2.1.1 Impedancia característica e intensidad acústica
De las ecuaciones anteriormente planteadas, debemos tener en cuenta las
referentes a la presión acústica y a la velocidad de vibración de las partículas ya que nos
serán especialmente útiles para definir la impedancia característica del medio de
propagación con la que finalmente podremos mostrar el concepto de intensidad acústica.
Este concepto es clave para determinar si un sonido puede o no llegar a ser percibido por
un oído humano de forma clara.
En primer lugar, expresaremos las ecuaciones (1) y (2) de tal modo que queden
caracterizadas por amplitudes complejas incidentes y reflejadas tal y como se muestra en
las expresiones (4) y (5), según viajen en el sentido positivo o negativo del eje x:
𝑝(𝑥, 𝑡) = 𝑃0+𝑒𝑗(𝜔𝑡−𝑘𝑥) + 𝑃0
−𝑒𝑗(𝜔𝑡+𝑘𝑥) (4)
𝜇(𝑥, 𝑡) = 𝜇0+𝑒𝑗(𝜔𝑡−𝑘𝑥) − 𝜇0
−𝑒𝑗(𝜔𝑡+𝑘𝑥) (5)
Donde 𝑃0+ y 𝜇0
+ son las amplitudes complejas incidentes. 𝑃0− y 𝜇0
− hacen referencia
a las amplitudes complejas reflejadas. Estas vienen expresadas de la siguiente forma, tal
y como se muestra en las ecuaciones (6), (7), (8) y (9):
𝑃0+ = 𝑗�̂�𝜌0𝑐𝜔 (6)

12
𝑃0− = −𝑗�̂�𝜌0𝑐𝜔 (7)
𝜇0+ = 𝑗�̂�𝜔 (8)
𝜇0− = 𝑗�̂�𝜔 (9)
De este modo, podemos definir la impedancia característica de un medio a partir
de las amplitudes complejas definidas, como se muestra en la ecuación (10):
𝑃0+
𝜇0+ =
𝑃0−
𝜇0− = 𝜌0𝑐 = 𝑍0 ∈ ℜ
(10)
Este parámetro nos informa acerca de la resistencia que opone un medio a la
propagación de una onda acústica. En este caso, los subíndices 0 indican que se
caracterizan estos parámetros en un medio como el aire.
Como podemos observar, la impedancia característica depende tanto de la
presión en el ambiente de propagación (densidad estática) 𝜌0 y de la velocidad de
propagación de la onda acústica 𝑐 (será detallado posteriormente). En el aire 𝜌0 ≅
1.21 𝐾𝑔/𝑚3.
De esta manera, somos capaces de expresar 𝜇(𝑥, 𝑡) como muestra la ecuación
(11):
𝜇(𝑥, 𝑡) =𝑃0
+
𝑍0
𝑒𝑗(𝜔𝑡−𝑘𝑥) −𝑃0
−
𝑍0
𝑒𝑗(𝜔𝑡+𝑘𝑥) (11)
Finalmente, podemos describir la intensidad acústica instantánea, en este caso
incidente, tal y como muestra la ecuación (12).
𝐼(𝑥, 𝑡)+ = 𝑃𝑅𝑒+ (𝑥, 𝑡) 𝜇𝑅𝑒
+ (𝑥, 𝑡) =|𝑃0
+|2
2𝑍0
[1 + cos(2𝜔𝑡 − 2𝑘𝑥 + 2𝜙)] (12)

13
𝐼(𝑥, 𝑡)− = 𝑃𝑅𝑒− (𝑥, 𝑡) 𝜇𝑅𝑒
− (𝑥, 𝑡) =|𝑃0
−|2
2𝑍0
[1 + cos(2𝜔𝑡 − 2𝑘𝑥 + 2𝜙)] (13)
Siendo 𝑃𝑅𝑒+ y 𝜇𝑅𝑒
+ las componentes reales de la presión acústica instantánea y de la
velocidad de vibración de las partículas instantánea. 𝜙 indica la fase de 𝑃0+ y 𝑃0
−.
Como podemos apreciar, la intensidad acústica aumenta con el cuadrado del
módulo de la presión acústica y además depende de su fase. También es dependiente de
las características del medio por el cual se propaga la onda acústica Por otro lado,
también depende de forma inversa con el doble de la impedancia característica. De forma
análoga, la intensidad acústica instantánea reflejada se expresa tal y como muestra la
ecuación (13). Dado que la intensidad acústica instantánea representa la cantidad de
energía por unidad de tiempo y área que atraviesa la superficie normal a la dirección de
propagación del sonido, será expresada en 𝑊/𝑚2
2.1.2 Frecuencia, periodo, longitud de onda y amplitud
Llamamos frecuencia de una onda acústica al número de vibraciones completas
producidas en un punto del medio durante un segundo y queda definido mediante la letra
𝑓. Este parámetro está inversamente relacionado con el periodo (𝑇) y la longitud de onda
(𝜆) de la señal. El primero de estos dos parámetros mencionados, periodo de una señal
expresado en segundos (s), es el inverso de la frecuencia medida en hertzios (Hz) y se
define como el tiempo invertido por una onda para realizar una oscilación o vibración
completa. Se expresa mediante la ecuación (14), además de poder ser definida mediante
(15) utilizando la frecuencia angular 𝜔 medida en rad/s.
𝑇(𝑠) = 1
𝑓
(14)
𝑇(𝑠) = 2𝜋
𝜔
(15)
Por otro lado, la longitud de onda es definida como la separación existente entre
dos zonas consecutivas de alta o baja presión (máxima o mínima amplitud de onda).
Viene expresada mediante la igualdad expresada en (16):

14
𝜆(𝑚) =𝑐
𝑓= 𝑐 ∗ 𝑇 (16)
Queda expresada en metros (m). A partir de estos parámetros podemos definir el
llamado periodo fundamental de una señal: valor positivo mínimo de todos los posibles
periodos de una onda, expresado mediante 𝑇0. Su inverso es la frecuencia fundamental
𝑓0 y denominamos armónicos a las frecuencias dominantes múltiplos enteros o casi
enteros de ésta. De este modo, el valor en frecuencia de los armónicos queda reflejado
mediante la ecuación (17):
𝑓𝑛(𝐻𝑧) = 𝑛 ∗ 𝑓0 , 𝑛 > 0 ∈ ℤ (17)
Referido al oído humano, teóricamente somos capaces de percibir sonidos de
entre 20 Hz y 20000 Hz. La propia degradación de los órganos que componen el oído
supondrá una reducción de este rango. Aun así, la detección o no de un sonido por parte
de un ser humano, no solo depende de la frecuencia con la que oscile el sonido, sino que
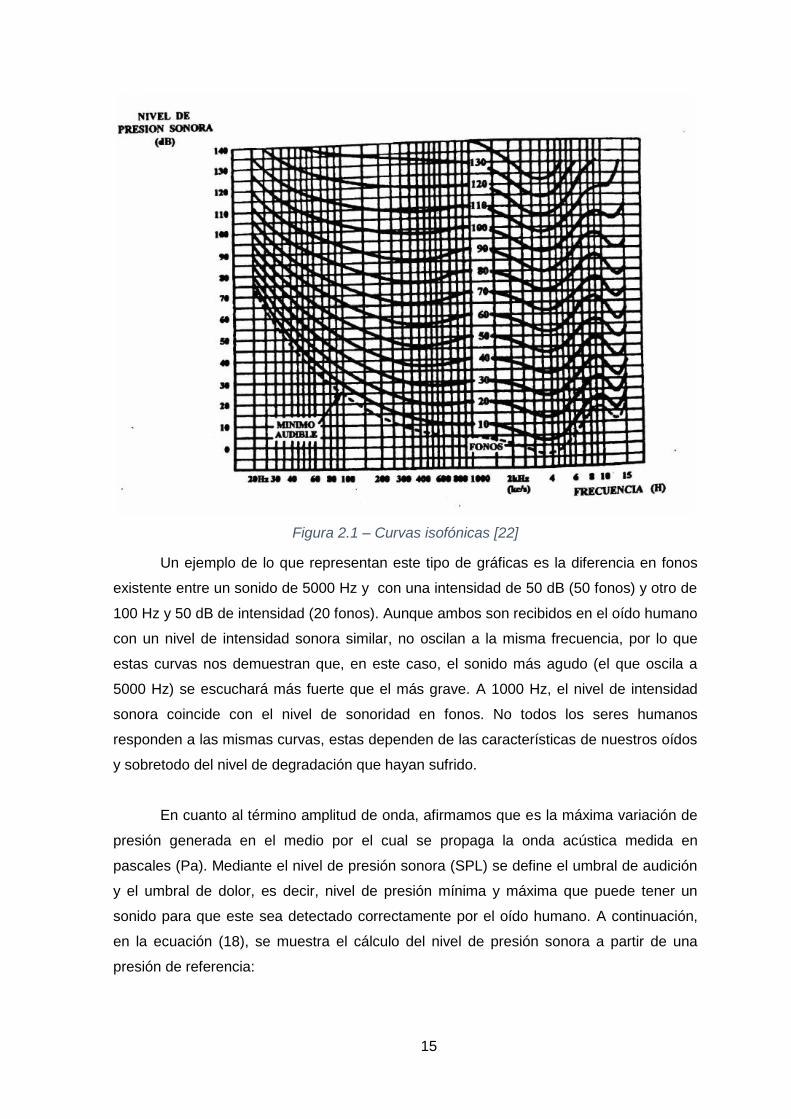
también se ve afectada por su intensidad sonora. A continuación, se muestran las curvas
isofónicas de Fletcher y Munson [22] en la figura 2.1, en las cuales se representa el nivel
de sonoridad de una onda a partir de su intensidad y frecuencia. Estas curvas se miden
en fonos (fon) y fueron obtenidas de forma experimental:
15
Figura 2.1 – Curvas isofónicas [22]
Un ejemplo de lo que representan este tipo de gráficas es la diferencia en fonos
existente entre un sonido de 5000 Hz y con una intensidad de 50 dB (50 fonos) y otro de
100 Hz y 50 dB de intensidad (20 fonos). Aunque ambos son recibidos en el oído humano
con un nivel de intensidad sonora similar, no oscilan a la misma frecuencia, por lo que
estas curvas nos demuestran que, en este caso, el sonido más agudo (el que oscila a
5000 Hz) se escuchará más fuerte que el más grave. A 1000 Hz, el nivel de intensidad
sonora coincide con el nivel de sonoridad en fonos. No todos los seres humanos
responden a las mismas curvas, estas dependen de las características de nuestros oídos
y sobretodo del nivel de degradación que hayan sufrido.
En cuanto al término amplitud de onda, afirmamos que es la máxima variación de
presión generada en el medio por el cual se propaga la onda acústica medida en
pascales (Pa). Mediante el nivel de presión sonora (SPL) se define el umbral de audición
y el umbral de dolor, es decir, nivel de presión mínima y máxima que puede tener un
sonido para que este sea detectado correctamente por el oído humano. A continuación,
en la ecuación (18), se muestra el cálculo del nivel de presión sonora a partir de una
presión de referencia:

16
𝑆𝑃𝐿 (𝑑𝐵) = 20 log𝑝𝑟𝑚𝑠
𝑝𝑟𝑒𝑓 (18)
En este caso, 𝑝𝑟𝑒𝑓 se corresponde con un valor preestablecido equivalente a
20μPa, el cual se corresponde con el umbral de resolución del oído humano a 1kHz en el
aire. Los umbrales de audición y dolor quedan fijados entre 20μPa y 20 Pa
respectivamente, lo cual nos indica que a partir de 0 dB SPL el oído humano será capaz
de percibir un sonido y en el caso de superar los 120 dB SPL resultará dañino para
nuestro sistema auditivo.
Como ya mencionamos anteriormente, el hecho de escuchar más o menos fuerte
un sonido con el mismo nivel de intensidad o presión sonora depende también de la
frecuencia con la que oscile, es por ello que ciertos sonidos con niveles de presión
sonora o amplitudes similares que llegan al oído humano a la vez (como por ejemplo el
sonido de la respiración y el de una sibilancia) suelen enmascarar uno al otro. El
fenómeno de enmascaramiento ocurre cuando a cierta frecuencia y con un nivel
determinado de presión sonora, un sonido se convierte en imperceptible por el oído
humano debido a la presencia de otro que lo enmascara. Por lo general, el ruido presenta
una mayor capacidad de enmascaramiento sobre un tono, es por ello por lo que es muy
común que una sibilancia quede enmascarada por el sonido de la respiración humana o
los latidos del corazón, haciendo casi imperceptible este tipo de sonidos que se asemejan
al de un tono de frecuencia determinada.
En este caso, el fenómeno de enmascaramiento se denomina NMT (noise-
masking-tone) lo que nos indica que el ruido es el que enmascara al tono, dificultando la
percepción de este último. A continuación, en la figura 2.2, se muestra un ejemplo en el
que podemos observar como el umbral de audición de un tono de 1000 Hz queda
modificado por la presencia de un ruido de banda estrecha centrado en 500 Hz con
distintos niveles de presión sonora (𝐿𝑝), presentando el fenómeno de enmascaramiento:

17
Figura 2.2 Ejemplo de enmascaramiento NMT [22]
Podemos apreciar como el umbral de audición para el tono de 1000 Hz queda
modificado en presencia de un ruido, lo cual quiere decir que mientras dicho ruido con un
determinado nivel de presión sonora esté presente, el tono debe tener un nivel de
sonoridad más alto que el indicado en el umbral reflejado en la figura 2.2. Es por ello por
lo que podemos afirmar que el ruido, en este caso, actúa como enmascarador sobre el
tono enmascarado. Como ya se ha mencionado, en el caso que nos ocupa, los sonidos
cardiacos y respiratorios actuarán como ruido enmascarante sobre las sibilancias a
detectar, cuyas características sonoras se asemejan al tono expuesto en el ejemplo
anterior.
2.1.3 Velocidad de propagación
No debemos confundir este parámetro con el de velocidad de vibración de las
partículas. Depende de las características del medio, es decir, de la distancia existente
entre las partículas que lo componen, la temperatura de este y de la masa molecular si
nos referimos a un gas como es el aire. A una temperatura de 20 ºC, el sonido se
propaga en este medio a una velocidad de 340 metros por cada segundo
aproximadamente. Para ondas armónicas, tanto frecuencia como longitud de onda están
relacionadas con la velocidad de propagación mediante la ecuación (19):

18
𝑐 (𝑚/𝑠) = 𝑓 ∙ 𝜆 =𝜆
𝑇
(19)
Donde 𝑐 es la velocidad de propagación (m/s).
2.1.4 Espectrogramas
Se trata de una forma de representación temporal de la variación de energía y
frecuencia de una onda basada en el cálculo de forma progresiva de múltiples
Transformadas de Fourier usando una ventana para la selección de diferentes tramas
consecutivas a lo largo del tiempo (conjunto de muestras de la onda a analizar). En
nuestro software usaremos para la obtención de espectrogramas la Transformada de
Fourier de Tiempo Corto (Short-time Fourier transform, STFT). Esta transformada
consiste en el desplazamiento o deslizamiento de una señal ventana sobre la señal
original con el fin de realizar el cálculo individual de la transformada de Fourier de cada
segmento visto a través de dicha ventana. Todas las secciones o segmentos de corta
duración temporal se obtendrán mediante el enventanado de la señal para así
posteriormente representar las componentes en frecuencia de cada uno de ellos a lo
largo del eje temporal y poder apreciar con claridad la variación espectral durante el
tiempo que dure la señal.
En nuestro caso, nos centraremos en la STFT de tiempo discreto ya que las
señales de audio que trataremos han sido muestreadas y almacenadas en un archivo
.wav, por esta razón, la información perteneciente a la señal con la que realizaremos la
Transformada de Fourier será segmentada o dividida en tramas compuestas por un
conjunto de muestras, las cuales quedarán solapadas en un porcentaje determinado para
evitar saltos bruscos o irregularidades entre tramas transformadas. A continuación, en la
ecuación (20) obtenida en [23], se muestra la expresión matemática con la que se lleva a
cabo la STFT para señales discretas.
𝑆𝑇𝐹𝑇{𝑥[𝑛]} ≡ 𝑋[𝑛, 𝜆) = ∑ 𝑥[𝑚] 𝑤[𝑚 − 𝑛]𝑒−𝑗𝜆𝑚
∞
𝑚=−∞
(20)
Donde 𝑥[𝑛] es la señal discreta y 𝑤[𝑛] la función ventana encargada de
segmentar las muestras de la señal principal:

19
𝑤[𝑛] = {≠ 0 0 ≤ 𝑛 ≤ 𝐿0 𝑟𝑒𝑠𝑡𝑜
(21)
Como vemos en la ecuación (21), la señal 𝑤[𝑛] realiza un truncamiento de L
muestras sobre la señal 𝑥[𝑛] discreta. En este caso, L representa la longitud de la señal
que enventana, 𝑤[𝑛].
En la transformada de Fourier dependiente del tiempo, la señal unidimensional
𝑥[𝑛] (sólo depende de una variable discreta), pasa a ser una variable bidimensional,
dependiente en este caso de una variable discreta temporal como es 𝑛 y de una variable
continua en frecuencia como 𝜆, por lo tanto, es necesario aplicar un método de
transformada capaz de discretizar dicha variable. En el caso de las computadoras y
software capaces de realizar estos cálculos, se utiliza la denominada Transformada de
Fourier Rápida o FFT (Fast Fourier Transform). Consiste en un algoritmo rápido basado
en el cálculo de la DFT (Discrete Fourier Transform) utilizando las técnicas de diezmado
en el tiempo o en frecuencia aplicadas a cada uno de los segmentos truncados por la
señal ventana. Ambos métodos implican la misma complejidad, aunque la salida que
aporta una FFT con diezmado en frecuencia consiste en un conjunto de bits indexados,
es decir, la señal transformada de salida está desordenada y por lo tanto requiere de un
algoritmo adicional capaz de ordenarlo, si la situación lo requiere. Ambos métodos
descomponen la señal 𝑥[𝑛] truncada en subsecuencias con el fin de combinarlas y
obtener la DFT de secuencias mayores, hasta conseguir la transformada de la señal
𝑥[𝑛] (en el caso de ser aplicadas en una STFT, la señal descompuesta será el producto
de la señal original y la ventana seleccionada y no 𝑥[𝑛] al completo).
En el caso de una FFT con diezmado en el tiempo, las secuencias se forman de
forma recursiva, agrupando las muestras pares e impares en diferentes secuencias 𝑔[𝑛] y
ℎ[𝑛], tal y como se muestra en las ecuaciones (22) y (23):
𝑔[𝑛] = 𝑥[2𝑛] , 𝑛 = 0,1 … ,𝑁
2− 1
(22)
ℎ[𝑛] = 𝑥[2𝑛 + 1] , 𝑛 = 0,1 … ,𝑁
2− 1
(23)

20
Siendo 𝑔[𝑛] la secuencia que contiene las muestras pares de la señal discreta a
transformar y ℎ[𝑛] la secuencia que contiene las muestras impares de dicha señal. El
valor de 𝑁 se corresponde con el tamaño en muestras de la señal original (en nuestro
caso, la señal enventanada).
De nuevo, una vez obtenidas estas dos secuencias, se vuelve a realizar el
diezmado en el tiempo sobre 𝑔[𝑛] y ℎ[𝑛] con el fin de obtener otro conjunto de
secuencias más cortas con las que poder realizar la transformada con una carga
computacional menor. Una recombinación de los resultados obtenidos dará lugar a la
transformada del segmento completo. A continuación, se desliza la ventana sobre la
señal original obteniendo otro fragmento truncado sobre el que se realizará de nuevo este
procedimiento recursivo.
Para una FFT con diezmado en frecuencia, las secuencias quedan construidas tal
y como se indica en las expresiones (24) y (25):
𝑔[𝑛] = 𝑥[𝑛] + 𝑥 [𝑛 +𝑁
2]
(24)
ℎ[𝑛] = 𝑥[𝑛] − 𝑥 [𝑛 +𝑁
2]
(25)
El procedimiento llevado a cabo en este caso es muy parecido, basándose en
obtener secuencias cortas con las que poder realizar una transformada de Fourier con
poca carga computacional y en un tiempo mínimo.
Finalmente, el resultado de calcular cada una de las transformadas de Fourier de
tiempo corto y solaparlas de forma correcta acorde a un porcentaje (normalmente del
50%) mediante el uso de las técnicas de FFT, obtenemos un resultado complejo el cual
será almacenado en una matriz y resultará ser la transformada de Fourier de la señal
discreta al completo. Esta matriz contendrá valores en magnitud y fase para cada instante
temporal y cada punto en frecuencia.
En nuestro caso, nos centraremos en el valor absoluto de la señal obtenida, tal y
como se muestra en la ecuación (26):
𝑒𝑠𝑝𝑒𝑐𝑡𝑟𝑜𝑔𝑟𝑎𝑚𝑎{𝑥[𝑛]} ≡ |𝑋(𝑚, 𝜔) | (26)

21
Un aspecto muy importante a tener en cuenta a la hora de representar señales
discretas en un espectrograma es la resolución. Este factor nos muestra la separación
mínima en frecuencia entre dos tonos de igual amplitud para que el resultado final
muestre dos picos bien diferenciados en ambas frecuencias. Una de las características
fundamentales que definen la resolución temporal y en frecuencia de un espectrograma
es la longitud de ventana. Por lo tanto, en función del tamaño y tipo de ventana usada
para la segmentación de la señal, obtendremos diferentes resoluciones. En nuestra
aplicación utilizaremos una ventana de Hanning de 512, 1024 y 2048 muestras de
longitud, por lo que obtendremos unas anchuras de lóbulo principal expresadas en la
tabla 2.1. También compararemos las resoluciones obtenidas con una ventana
rectangular con tamaños similares. El cálculo de la resolución para una ventana de
Hanning se realiza mediante la ecuación (28) mientras que la ecuación (29) muestra la
expresión con la que podemos calcular la resolución ofrecida por una ventana
rectangular. Ambas expresiones incluyen la frecuencia o tasa de muestreo (𝑓𝑠), variable
que se corresponde con el número de muestras tomadas por segundo de una señal
continua para la creación de una señal discreta apta para el tratamiento digital que será
llevado a cabo en el software. Según el teorema de Nyquist-Shannon, para que en el
proceso de muestreo de una señal continua ésta pueda ser recuperada sin pérdida de
información, es decir, poder replicar de nuevo la forma de onda en su totalidad, la
frecuencia de muestreo debe ser como mínimo el doble de la máxima frecuencia de la
señal tal y como se muestra en la ecuación (27).
𝑓𝑠 > 2𝑓𝑚𝑎𝑥 (27)
En la tabla 2.1 se muestran los resultados obtenidos utilizando una frecuencia de
muestreo de 8000 Hz (este valor será utilizado en nuestro software tal y como se
detallará en el apartado 2.2 de esta memoria).

22
Tamaño de ventana en
muestras (L)
Resolución en frecuencia
en Hz (∆𝑓) - Hanning
Resolución en frecuencia
en Hz (∆𝑓) - Rectangular
512 62.5 31.25
1024 31.25 15.625
2048 15.625 7.8125
Tabla 2.1 – Resolución en frecuencia para la obtención de espectrogramas con ventanas
de 512, 1024 y 2048 muestras de longitud.
∆𝑓 (𝐻𝑧) =4
𝐿∗ 𝑓𝑠
(28)
∆𝑓 (𝐻𝑧) =2
𝐿∗ 𝑓𝑠
(29)
Como podemos apreciar en la tabla 2.1, una ventana con menor tamaño en
muestras ofrecerá una menor resolución en frecuencia, siendo ∆𝑓 mayor que el resto, lo
cual nos indica que la separación entre los tonos consecutivos tomados como ejemplo
antes, deben tener una diferencia en frecuencia igual o mayor que dicho valor calculado
para que en el espectrograma podamos apreciarlos claramente. Por otro lado, las
ventanas con un mayor número de muestras ofrecerán una resolución en frecuencia
mayor, obteniendo un ∆𝑓 menor. Aun así, un aumento en la resolución en frecuencia
conlleva una disminución de la resolución temporal, ya que a un mayor tamaño de
ventana, los fragmentos con los que se realizan las transformadas serán mayores y por lo
tanto se abarcará un mayor margen temporal el cual nos permitirá en menor medida
apreciar con claridad variaciones sobre el eje temporal. A continuación, en las figuras 2.3,
2.4, 2.5, 2.6, 2.7 y 2.8 se exponen seis ejemplos de espectrograma extraídos de nuestro
software donde podemos apreciar los resultados obtenidos a la hora de utilizar dos tipos
de ventana diferentes con longitudes distintas para poder observar cómo influyen estos
parámetros sobre la resolución temporal y en frecuencia de los espectrogramas.
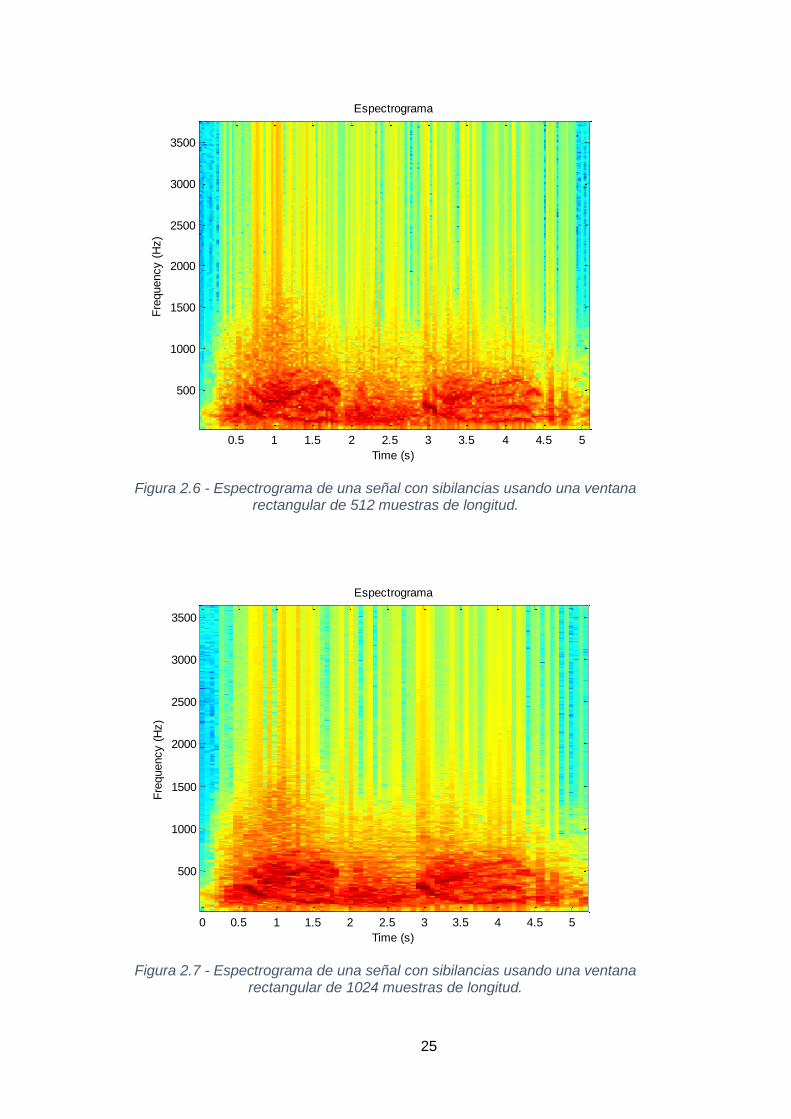
- Ejemplos mostrados en las figuras 2.3, 2.4 y 2.5: se utilizará una ventana de
Hanning de 512, 1024 y 2048 muestras respectivamente.
- Ejemplos mostrados en las figuras 2.6, 2.7 y 2.8: se utilizará una ventana
rectangular con tamaños de ventana similares.

23
Observaremos como para un mismo tipo de ventana, un menor tamaño en
muestras conlleva a una mejor resolución temporal a cambio de perder resolución en
frecuencia.
Debido a que se ha utilizado el audio "sibilancia_polifónica2.wav" (duración 10 s),
en los espectrogramas a continuación expuestos, observaremos las componentes en
frecuencia y tiempo de una señal sonora procedente de una respiración con sibilancias
polifónicas, apreciando componentes más energéticas comprendidas entre los 0 y 1000
Hz con duración no superior a 1.5 s. Se exponen a continuación solo 5 segundos del
audio para poder apreciar estas componentes de forma clara, comprendidas entre los
segundos 0.5 al 2.5 y entre los segundos 3 al 4.5 de la muestra de audio.
Figura 2.3 – Espectrograma de una señal con sibilancias usando una ventana de Hanning de 512 muestras de longitud.
Time (s)
Fre
quency (
Hz)
Espectrograma
0 1 2 3 4 50
500
1000
1500
2000
2500
3000
3500
4000

24
Figura 2.4 - Espectrograma de una señal con sibilancias usando una ventana de Hanning de 1024 muestras de longitud.
Figura 2.5 - Espectrograma de una señal con sibilancias usando una ventana de Hanning de 2048 muestras de longitud.
Time (s)
Fre
quency (
Hz)
Espectrograma
0 1 2 3 4 50
500
1000
1500
2000
2500
3000
3500
4000
Time (s)
Fre
quency (
Hz)
Espectrograma
0 1 2 3 4 50
500
1000
1500
2000
2500
3000
3500
4000
25
Figura 2.6 - Espectrograma de una señal con sibilancias usando una ventana rectangular de 512 muestras de longitud.
Figura 2.7 - Espectrograma de una señal con sibilancias usando una ventana rectangular de 1024 muestras de longitud.
Time (s)
Fre
quency (
Hz)
Espectrograma
0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
500
1000
1500
2000
2500
3000
3500
Time (s)
Fre
quency (
Hz)
Espectrograma
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
500
1000
1500
2000
2500
3000
3500

26
Figura 2.8 - Espectrograma de una señal con sibilancias usando una ventana rectangular de 2048 muestras de longitud.
En estos ejemplos podemos apreciar como la resolución en tiempo es un factor
clave a la hora de elegir el tamaño de ventana que se utilizará para la aplicación, esto es,
a medida que disminuye la longitud de la ventana utilizada, la resolución en tiempo o la
capacidad de apreciar cambios en el tiempo aumenta a costa de perder resolución en
frecuencia. Por esta razón, según el tipo de señal analizada, es necesario obtener una
resolución temporal más o menos alta a costa o a favor de obtener una resolución en
frecuencia menor o mayor respectivamente.
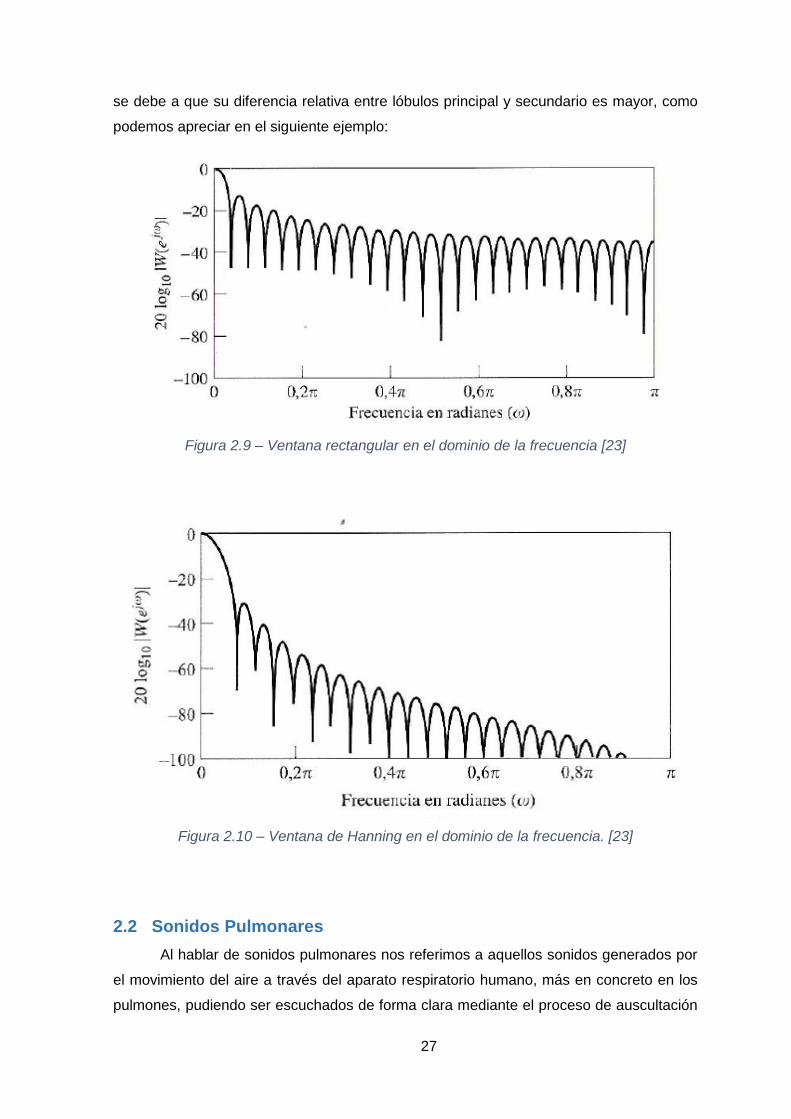
Debemos tener en cuenta también el tipo de ventana a utilizar, como vemos en los
ejemplos expuestos en las figuras 2.9 y 2.10. Cada ventana ofrece una anchura de lóbulo
principal distinta, así como una diferencia relativa entre lóbulo principal y secundario
diferente. Este último factor determinará en gran medida la capacidad de representación
de un espectrograma, como hemos visto en las 6 figuras anteriores, ya que a una menor
diferencia relativa de lóbulos, la dispersión espectral será mayor y la calidad de nuestro
espectrograma disminuirá. Es por ello por lo que nos decantamos por una ventana de
Hanning, aunque ofrece una menor resolución en frecuencia, como apreciamos en la
tabla 2.1 y en las ecuaciones (28) y (29), el grado de dispersión desciende ya que se trata
de una ventana con una pendiente más suave en comparación con una rectangular. Esto
Time (s)
Fre
quency (
Hz)
Espectrograma
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
500
1000
1500
2000
2500
3000
3500
27
se debe a que su diferencia relativa entre lóbulos principal y secundario es mayor, como
podemos apreciar en el siguiente ejemplo:
Figura 2.9 – Ventana rectangular en el dominio de la frecuencia [23]
Figura 2.10 – Ventana de Hanning en el dominio de la frecuencia. [23]
2.2 Sonidos Pulmonares
Al hablar de sonidos pulmonares nos referimos a aquellos sonidos generados por
el movimiento del aire a través del aparato respiratorio humano, más en concreto en los
pulmones, pudiendo ser escuchados de forma clara mediante el proceso de auscultación

28
normalmente realizado con un fonendoscopio situado en determinadas zonas del tórax y
la espalda del paciente. Las alteraciones de los diferentes parámetros anteriormente
definidos en un sonido pulmonar normal pueden permitir a un médico distinguir diferentes
irregularidades pulmonares en el caso de que el paciente las presente. Por lo general, tal
y como se define en el estudio realizado en [1], la frecuencia de los sonidos pulmonares
está comprendida en un rango de entre 50 Hz y 2500Hz pudiendo llegar incluso a los
4000 Hz en sonidos producidos en la tráquea. Existen varios tipos de sonidos pulmonares
normales (procedentes de una respiración sana) en función de la zona auscultada o de la
procedencia del sonido generado durante la respiración, como consecuencia de ello los
parámetros como la frecuencia y la amplitud de la señal acústica variarán en función del
tipo de sonido que analicemos. Entre ellos podemos destacar los sonidos vesiculares
(son los que presentan una frecuencia más baja), bronco-vesiculares (contienen una
frecuencia media dentro del rango establecido) y bronquiales (presenta la frecuencia más
alta y suelen ser más sonoros).
Existe un subgrupo de sonidos pulmonares denominados ruidos adventicios, tal y
como se muestra en el artículo [2] donde se recogen las definiciones de hasta 162
términos relacionados con los sonidos respiratorios y su análisis mediante software.
Estos sonidos quedan superpuestos a los sonidos respiratorios normales mencionados
anteriormente y son un indicio de patología pulmonar. En función de su frecuencia
fundamental, duración, intensidad sonora, continuidad temporal, etc. podemos
clasificarlos en los siguientes grupos [2]: estertores (sonidos continuos parecidos a las
sibilancias, presentan una frecuencia más baja), crepitantes (sonidos discontinuos de
corta duración y frecuencia alta) y estridor (presenta una alta frecuencia y es descrito
como un sonido chillón). Es en este tipo de sonido pulmonar en el que se incluyen las
sibilancias que serán descritas más adelante. En la Figura 2.11 extraída del artículo
anteriormente mencionado se puede apreciar de forma visual la relación existente entre
los términos anteriormente descritos.

29
Figura 2.11 - Relación entre los términos sonido respiratorio, sonido adventicio y sonido pulmonar [2].
Como ya hemos mencionado antes, las muestras de audio que recogen la
respiración humana pueden tener componentes en frecuencia que superen los 2500 Hz o
incluso alcanzan los 4000 Hz, como se muestra en la figura 2.12 extraída de una
respiración con estertores obtenida en [18] ("73Ant2R.wav"). Por esta razón, es
importante tener en cuenta que los audios utilizados en este estudio sean muestreados a
8000 Hz ya que 𝑓𝑚𝑎𝑥 puede tomar valores de hasta 4000 Hz. Esto quiere decir que la
frecuencia de muestreo de los fragmentos de audio debe ser de 8000 Hz. Llegamos a
esta conclusión mediante la ecuación (27) expuesta en el apartado 2.1.4 de esta
memoria, tal y como se define en el teorema de Nyquist-Shannon.
Figura 2.12 – Espectrograma de una respiración con estertores o crepitantes gruesos.

30
2.3 Sibilancias
Se trata de un tipo de sonido adventicio causado por el movimiento del aire entre
las vías respiratorias obstruidas [2]. Los mecanismos fisiopatológicos causantes de estos
tipos de sonidos no están claros a día de hoy, tal y como refleja el artículo [4] y [21], el
cual indica que el exceso de secreción de líquidos en las vías respiratorias puede ser uno
de los principales causantes de estos sonidos debido al estrechamiento que causan en
los conductos respiratorios. En el mismo artículo se muestra como numerosos estudios
teóricos y simulaciones relacionadas con el movimiento del aire a través de diferentes
tipos de conductos similares a los pulmonares, intentan demostrar que la causa por la
que se generan las sibilancias puede radicar en el movimiento vibratorio de las paredes
de las vías respiratorias debido a posibles anomalías en sus formas (estrechamientos)
debido a la obstrucción de éstas.
Como ya hemos mencionado antes, las sibilancias son un indicio de patología
pulmonar causada principalmente por asma u otras enfermedades denominadas EPOC
(Enfermedad Pulmonar Obstructiva Crónica). También pueden ser causadas por
reacciones alérgicas graves e inhalación de sustancias tóxicas [21].
Una de las principales características que podemos observar a simple vista en el
análisis espectral de una muestra de audio que contenga sibilancias es la existencia de
picos bien diferenciados en un rango de frecuencias determinado, es decir, bandas en
frecuencia con una energía significativamente superior al resto. Tal y como se muestra en
la figura 2.13 extraída del análisis realizado en [3], en una respiración normal un alto
porcentaje de la energía se encuentra concentrada en el rango indicado en el apartado
2.2 de esta memoria. Esta energía decae a medida que aumenta la frecuencia, es decir,
las componentes en alta frecuencia son mucho menos energéticas que las de baja
frecuencia. Por otro lado, en el análisis espectral de una respiración con sibilancias
apreciamos la aparición de picos energéticos bien diferenciados en un rango que
definiremos más adelante, lo cual nos indica que dichos sonidos adventicios se
superponen a los sonidos producidos por una respiración normal, modificando el espectro
de una respiración sana:

31
Figura 2 13 - Análisis espectral de una respiración normal (arriba) y análisis espectral de una respiración con sibilancias (abajo) [3].
En cuanto a los rangos en frecuencia en los que suelen aparecer estos picos,
diversos análisis lo definen de forma distinta basados en estudios propios ya que no
existe una estandarización como tal, por lo tanto, en el apartado 4 de esta memoria
quedarán referenciados algunos de estos estudios. En nuestro caso, diferenciaremos dos
rangos según la edad del paciente: como es de esperar, los parámetros que definen las
características de las sibilancias (frecuencia, amplitud, etc.) dependen de la forma y
capacidad de los órganos respiratorios además del tipo de anomalía que exista en el
aparato respiratorio, por esta razón, debido a la edad del paciente las sibilancias podrán
presentar una frecuencia fundamental incluida en un rango espectral o en otro. Según el
estudio realizado en [5] los niños de corta edad (entre 7 y 10 meses) seleccionados a
partir de los cuales se tomaron las muestras de audio, presentan sibilancias cuya
frecuencia fundamental oscila entre los 125 y 375 Hz durante la inspiración. En este
trabajo se ha decidido tomar un rango de frecuencias para sibilancias en pacientes de
corta edad ya que es importante su detección en periodos lactantes y prematuros. La
aparición de otros sonidos como los roncus (ruttles) durante los primeros meses de vida
de algunos niños (fácilmente confundibles con sibilancias por el oído humano) y la
importancia de detectar y diagnosticar asma en estos pacientes hace que pongamos
especial atención a la hora de detectar sibilancias en este grupo.
En cuanto a los adultos, en un intento de estandarización llevado a cabo por un
comité de la ATS (American Thoracic Society) [6] se definió que la frecuencia

32
fundamental de una sibilancia producida por un paciente adulto superará los 400 Hz.
Además define que la duración mínima que la sibilancia debe tener para ser considerada
como tal debe superar los 250 ms. Consideraremos esta misma duración para sibilancias
en niños de corta edad ya que el mismo comité remarca que este dato no se verá
modificado para este tipo de pacientes, por esta razón, la duración temporal no será un
factor a tener en cuenta para la distinción entre grupos para la detección de sibilancias.
Hemos de remarcar el hecho de que muchos de los estudios y artículos
consultados (por ejemplo [8], [10] o [11]) no diferencian entre rangos de frecuencia para
niños de corta edad y adultos, simplemente definen un rango de frecuencias basados en
estudios propios realizados sobre adultos o en el definido en otros artículos.
Otra característica importante que debemos mencionar a la hora de definir una
sibilancia es la aparición o no de armónicos en su espectro. Esto nos permitirá diferenciar
si una sibilancia es polifónica, es decir, contiene una frecuencia fundamental más
energética que el resto y además cuenta con armónicos (picos significativos múltiplos de
la frecuencia fundamental) o es monofónica, en cuyo caso el espectro estará compuesto
por una sola frecuencia fundamental en ausencia de armónicos. Para un médico, definir
si una sibilancia es monofónica o polifónica puede llegar a ser útil en la localización de la
zona respiratoria obstruida o estrechada. Las sibilancias monofónicas son indicadores del
estrechamiento de vías aéreas largas mientras que las polifónicas indican que la
anomalía se encuentra en vías cortas. Este último tipo de sibilancia también está
asociada a enfermedades como el asma y otras EPOC, tal y como se menciona en [14].
2.3.1 Diferencias existentes entre sibilancias, roncus o ruttles
En algunos de los documentos consultados, como por ejemplo [5] y [7], se hace
referencia a las dificultades que presentan algunos padres de niños de corta edad a la
hora de detectar en ellos sibilancias y diferenciarlas de otros sonidos adventicios como
los roncus (también nombrados como ruttles, término que procede de Yorkshire, Reino
Unido [5]). Ambos sonidos aparecen de forma muy frecuente en niños de corta edad y
son indicadores de enfermedades o anomalías respiratorias muy distintas entre sí,
pudiendo ser las que causan las sibilancias mucho más peligrosas y nocivas para el
paciente. Los roncus presentan ciertas características que aunque el oído humano en
ciertos casos es incapaz de detectar, son clave para diferenciarlos de otros ruidos
respiratorios, lo cual nos demuestra como muchos padres se refieren a estos sonidos
adventicios como sibilancias aunque realmente no lo sean. Las características que el
oído humano es incapaz de detectar de forma objetiva procedentes de estos dos tipos de
sonidos pueden ser apreciadas claramente al observar un análisis en frecuencia de cada
uno de los ruidos respiratorios. En la figura 2.14, extraída del artículo [9] se muestran tres

33
análisis en frecuencia de tres sonidos respiratorios distintos: respiración normal, con
sibilancias y con ruttles.
Figura 2.14 - Análisis espectral de una grabación normal (A), con sibilancias (B) y con ruttles (C) [9].
A simple vista podemos apreciar como las sibilancias presentan picos bien
diferenciados en ciertas frecuencias, mientras que los ruttles muestran un análisis
espectral con picos menos significativos y situados de forma más difusa dentro del rango
espectral, es decir, sin picos claramente diferenciados y con una frecuencia fundamental
más baja que la de las sibilancias. Por esta razón, es importante el hecho de distinguir
bien los rangos en frecuencia entre estos dos sonidos. En el artículo [9], tras un estudio
realizado en diferentes niños de corta edad, se llegó a la conclusión de que la frecuencia
fundamental de los ruttles suele aparecer en un rango inferior al definido anteriormente
para las sibilancias en niños de corta edad, esto es, entre los 70 Hz y 190 Hz durante la
inspiración. El hecho de que los ruttles no presenten armonicidad en su forma de onda
nos permitirá distinguirlos claramente con las sibilancias polifónicas, las cuales presentan
armónicos con respecto a su frecuencia fundamental. Por otro lado, aunque las
sibilancias monofónicas también carezcan de armonicidad, su frecuencia fundamental se
encuentra en un rango superior al de los rattles, tal y como se ha mencionado
anteriormente, por lo que esta característica es clave a la hora de diferenciar este tipo de
sonido adventicio y las sibilancias monofónicas.

34
En el software desarrollado se define claramente un umbral en frecuencia
específico para pacientes de corta edad, lo que facilita y agiliza el proceso de selección
de sibilancias, evitando falsos positivos cuando la muestra de audio introducida contiene
ruttles en vez de sibilancias. El proceso de selección de picos significativos dentro del
desarrollo del software también es una herramienta muy útil para descartar estos sonidos
y no ser detectados como sibilancias. En cuanto al análisis en amplitud y tiempo de estos
dos sonidos pulmonares, podemos apreciar como las sibilancias presentan una forma de
onda parecida a la de una señal sinusoidal (en varios documentos referenciados se
denomina este fenómeno como "musicalidad", por ejemplo en [4], [5] o [14]) mientras que
los ruttles presentan una forma de onda irregular (fenómeno denominado como “no
musicalidad”).
De nuevo, hacer hincapié en la importancia que tiene el hecho de descartar ruttles
en la detección de sibilancias ya que aunque estos sonidos son indicadores de exceso de
secreción en las vías respiratorias, no suelen tener consecuencias tan importantes como
las que pueden presentar las sibilancias, sobretodo en niños de corta edad. Un oído
humano inexperto puede llegar a confundir estos sonidos pulmonares pudiendo ser
perjudicial para el paciente que padece la irregularidad pulmonar.

35
3 OBJETIVOS
El principal objetivo de este trabajo fin de grado es la implementación de un
software capaz de detectar sibilancias mediante el tratamiento digital de una señal
acústica a través de la herramienta matemática Matlab. A partir de una serie de
parámetros que obtendremos a lo largo del proceso, el software será capaz de advertir o
no sobre la existencia de sonidos adventicios tales como las sibilancias en la muestras de
audio que serán previamente grabadas.
Para alcanzar este objetivo principal, se han propuesto conseguir los siguientes
objetivos secundarios:
- Conocer los distintos métodos computarizados utilizados para la detección de
sibilancias y otros sonidos pulmonares.
- Estudiar las características de diversos sonidos adventicios para poder
diferenciarlos entre sí.
- Implementar un algoritmo capaz de mejorar ciertos aspectos en cuanto a la
detección de sonidos adventicios.
- Estudiar las distintas posibilidades en cuanto a la aparición de anomalías en el
aparato respiratorio con el fin de cuantificar ciertas características sonoras que
nos permitan distinguir sonidos adventicios.
- Revisión del estado del arte en el ámbito de la auscultación computarizada y la
detección de sibilancias.
- Conocer las técnicas de optimización y testeo para la obtención de resultados
a partir de métricas y otros parámetros.
- Conocer las distintas posibilidades que nos ofrece Matlab a la hora de crear un
GUI (Interfaz Gráfica de Usuario) para que la manipulación de este software
sea intuitiva y cómoda para el usuario final.

36
4 ESTADO DEL ARTE
El primer problema que se nos plantea a la hora de desarrollar este trabajo es la
gran cantidad de artículos de investigación y estudios realizados utilizando parámetros
muy dispares entre sí. Es obvio pensar que las características de una sibilancia
dependen totalmente de la edad del paciente, capacidad de los órganos respiratorios, tipo
de enfermedad que padezca, calidad de la grabación utilizada para el posterior análisis
de la señal de audio, etc. Por estas razones, es casi imposible definir un rango en
frecuencia fijo entre el cual la frecuencia fundamental de una sibilancia oscile. En cuanto
a la duración de una sibilancia ocurre algo similar, esta depende tanto del paciente como
del volumen de los órganos respiratorios en los cuales se genera la señal, además hay
que añadir el hecho de que el tiempo de inspiración y espiración varía en función de
estas características y como es de suponer, la duración de una sibilancia se ve afectada
por ello.
A continuación, se mostrarán algunos rangos en frecuencia y duraciones de
sibilancias extraídas de diversos artículos consultados:
En el estudio [8] donde se propone un método de detección y análisis de
sibilancias, se estudian varios casos de pacientes con asma y se llega a la conclusión de
que la frecuencia fundamental de una sibilancia se encontrará en un rango definido desde
los 100 Hz hasta los 2000Hz, usando muestras de audio grabadas directamente en
pacientes reales. En este caso, no se diferencia entre paciente adulto y de corta edad, ya
que el estudio ha sido realizado mediante la colaboración de dos grupos de personas:
- 16 adultos asmáticos no fumadores.
- 15 adultos sin patologías respiratorias
En dichos pacientes han sido aplicadas sustancias broncodilatadoras con el fin de
aumentar el flujo de aire expirado.
En cuanto a la duración de las sibilancias, los autores indican que su valor debe
estar comprendido entre 80ms y 250 ms.
El estudio ha sido realizado teniendo en cuenta una zona de interés dentro de la
respiración completa, en este caso la exhalación de un paciente, tal y como se muestra
en la figura 4.1, extraída del artículo en cuestión donde se muestra el flujo de aire en
movimiento en litros por segundo frente al tiempo que transcurre durante la respiración:

37
Figura 4.1 - Diagrama de una respiración humana [8].
Las muestras de audio utilizadas en este estudio han sido obtenidas de forma no
invasiva desde la tráquea utilizando un sensor PPG (piezoelectric phonopneumograph).
El proceso de pre-procesado de señal se compone de las siguientes pautas:
- Amplificación de la señal de audio.
- Filtrado mediante un filtro paso-banda analógico Butterworth (70 – 2000 Hz).
- Muestreo de la señal a 5000 Hz.
El proceso de detección de sibilancias se lleva a cabo mediante el análisis
espectral de las muestras de audio una vez procesadas tal y como se ha mencionado.
Para la obtención de los espectrogramas se han utilizado ventanas de Hanning de 256
muestras con solapamientos del 50%. Dicho análisis se realiza mediante la búsqueda de
picos significativos en bandas de 100 Hz, utilizando dos umbrales (a y b) con el fin de
definir posibles muestras pertenecientes a sibilancias. Si estos picos detectados se
encuentran en el umbral establecido entre a y b, dichas muestras pueden pertenecer a
una sibilancia.
Un proceso de agrupación de picos significativos servirá para poder desechar
muestras pertenecientes a otros ruidos adventicios de corta duración o ruido introducido
por los sensores utilizados para la obtención de las muestras de audio. Siguiendo el
siguiente criterio, dos picos significativos pertenecerán a la misma agrupación si su
separación temporal es menor a 25.6 ms y distan en frecuencia 65 Hz o menos.

38
Como ya se mencionó en el apartado 2.3, el estudio [5] ha sido realizado
exclusivamente mediante pacientes de corta edad, por lo tanto, en él se llega a la
conclusión de que la frecuencia fundamental de las sibilancias presentes en la respiración
de niños oscila entre los 125 Hz y 375 Hz. Este estudio, también define que la duración
mínima para que una sibilancia tenga un carácter continuo sea de 250 ms. Según se
indica, este parámetro ha sido obtenido siguiendo las pautas que define el comité de la
ATS [6]. Al tratarse de un estudio realizado fundamentalmente sobre niños de corta edad,
se hace sobretodo hincapié en las diferencias existentes entre ruttles, sibilancias y los
sonidos respiratorios normales, mostrando tres ejemplos mediante el análisis en
frecuencia y tiempo de tres respiraciones. A continuación, se muestra la figura 4.2 la cual
recoge dichos ejemplos donde se aprecia claramente lo mencionado en la sección 2.3.1
de esta memoria, es decir, la diferencia existente entre la frecuencia de oscilación de una
respiración en niños con ruttles y sibilancias. Los picos de una sibilancia se pueden
encontrar en rangos de frecuencia superiores a los picos generados en una respiración
con ruttles.
El estudio se realiza mediante el análisis de la respiración de un total de 15 bebés
de corta edad (entre 7 y 10 meses), 7 de ellos con sibilancias y 8 con ruttles. Las
grabaciones se realizaron utilizando un acelerómetro piezoeléctrico situado en el pecho
de cada uno de los pacientes. La duración de las grabaciones es aproximadamente de un
minuto, llevadas a cabo mientras los bebés respiraban de forma tranquila mientras
dormían.
La fase de pre-procesado consta de las siguientes partes:
- Filtrado paso-banda entre 50 Hz y 2500 Hz usando un filtro Butterworth de
orden 6.
- Amplificación de la señal.
- Muestreo utilizando una frecuencia de 10240 Hz.
- Cálculo de espectrograma usando una FFT de 2048 muestras en intervalos de
100 ms utilizando una ventana de Hanning con un solapamiento de 50 ms.
Mediante el análisis de los espectrogramas de las señales grabadas en los
pacientes se llega a las siguientes conclusiones:
- La frecuencia fundamental de las sibilancias en niños de corta edad está
comprendida entre los 125 Hz y los 375 Hz durante la inspiración y entre los
212 Hz y 303 Hz durante la espiración.
- La frecuencia fundamental de los ruttles se encuentra comprendida entre los
70 Hz y 190 Hz durante la inspiración y entre 87 Hz y 238 Hz durante la
espiración.

39
- La forma de onda de una sibilancia se asemeja en gran medida a una onda
sinusoidal mientras que los ruttles presentan una forma de onda totalmente
irregular.
- El análisis subjetivo de una respiración en un paciente de corta edad puede
llegar a ser erróneo ya que los sonidos adventicios mencionados pueden ser
confundidos por un oído humano inexperto.
Figura 4.2 – Ejemplos de espectrogramas de una respiración sana (a), una con sibilancias (b) y otra con ruttles (c) [5].
En el artículo [10], se hace referencia a los tipos de sonidos adventicios continuos
y discontinuos que pueden ocurrir en la respiración. En este caso se diferencian las
características existentes entre los sonidos continuos como las sibilancias, rhonchis y
estridores, además de mostrar en qué difieren los sonidos discontinuos como son los
crepitantes y squawks (sonidos adventicios de corta duración). En cuanto a sonidos
continuos, la principal diferencia existente entre sibilancias y rhonchis es el rango de

40
frecuencia en el que se encuentra la frecuencia fundamental de ambos sonidos
adventicios. Los rhonchis suelen tener una duración similar a la de las sibilancias, pero su
frecuencia fundamental es inferior (menor de 200 Hz según se menciona en este
artículo). Por otro lado, la principal característica que nos permite distinguir un sonido
sibilante con el producido por un estridor es, además de su frecuencia fundamental, su
tendencia a ser más sonoro en la inspiración del paciente.
Si nos centramos en estos sonidos adventicios continuos, más en concreto en las
sibilancias, de nuevo se define que deben tener una duración superior a los 250 ms pero
esta vez con una frecuencia fundamental situada en 400 Hz. Los sonidos discontinuos
nombrados en este estudio presentan duraciones cortas y por lo tanto no son objeto de
estudio en este trabajo. A continuación, se muestran cuatro diagramas recogidos en la
figura 4.3, obtenidos en el artículo donde se enfrenta amplitud normalizada frente a
tiempo de cuatro sonidos pulmonares entre los que se encuentran los mencionados
anteriormente, con el fin de comparar su estructura frente a la generada por una
respiración normal:
Figura 4.3 – Comparación entre respiraciones con distintos sonidos adventicios [10].
En las pruebas realizadas en este estudio, las muestras de audio utilizadas han
sido obtenidas tanto en el Lemuel Shattuck Hospital como en el Faulkner Hospital. Según
se indica, las características de los pacientes como sexo, edad, peso, etc. no se conocen.
El aspecto clave en este estudio es el hecho de utilizar métodos de fusión a la
hora de crear bases de datos de audio, es decir, conseguir mezclar distintas muestras de
audio obtenidas mediante diferentes sensores situados en múltiples zonas del pecho del
paciente con el fin de poder obtener una mayor cantidad de información acerca del
sonido adventicio que este genera.
El sistema propuesto en este artículo es denominado Automatic Multisensor
Feature-based Recognition System (AMFRS), basado en cuatro bloques, nombrados de
la siguiente manera: DWPD (Discrete Wavelet Packet Decomposition), Feature Selection,
Feature Fusion y Classification.

41
Justificando el método para la detección de sibilancias propuesto en [11]
simplemente se especifica que la frecuencia fundamental de una sibilancia estará situada
por encima de los 100 Hz de forma usual. Además, uno de los criterios aplicados para
determinar la continuidad de una sibilancia es que la duración mínima debe estar entorno
a los 100 ms. En este estudio se usa una frecuencia de muestreo para la grabación de
los sonidos de 5512 Hz. El método implementado en este artículo muestra resultados
parecidos a los obtenidos en nuestro software tal y como se muestra en la figura 4.4:
Figura 4.4 – Espectrogramas que muestran los picos más significativos obtenidos en el análisis mediante el sistema WED [11].
Apreciamos como el sistema obtiene a partir del espectrograma de la señal
original los picos más significativos que tras un una serie de procesos explicados en el
artículo, se mantienen solo aquellos picos pertenecientes a las sibilancias, aunque como
vemos, la existencia de falsos positivos en frecuencias bajas es notable. Esto se debe al
ruido que introducen los métodos de grabación llevados a cabo, incluso ruido de
respiración de baja frecuencia que puede hacer que el sistema obtenga errores. Es
preferible el hecho de que el sistema introduzca falsos positivos a obtener un alto número
de falsos negativos ya que el hecho de no detectar una sibilancia puede incurrir a error en
el diagnóstico. Una falsa alarma puede tener menores consecuencias en el diagnóstico.
El método utilizado y descrito en el artículo [12] utiliza grabaciones de dos sujetos
realizadas durante varios periodos de tiempo con el fin de extraer muestras de audio con
las que trabajar durante su implementación. En este caso, se define que el rango en
frecuencia entre el que se suele encontrar la frecuencia fundamental de una sibilancia se

42
encuentra comprendido entre los 100 Hz y 1300 Hz ya que se realiza un análisis
espectral dividido en 26 sub-bandas a lo largo de dicho rango. Las muestras están
grabadas con una frecuencia de muestreo de 7500 Hz y filtradas con un filtro Butterworth
paso-bajo con frecuencia de corte en 1300 Hz. Por esta razón, aunque no es mencionado
en el artículo, la capacidad de detectar armónicos en este estudio es mermada ya que
gran parte de las componentes en frecuencia de una sibilancia polifónica pueden situarse
en frecuencias superiores a la de corte impuesta por el filtro. Debemos suponer que en
este estudio la búsqueda de armónicos no es de interés.
En este documento no se tiene en cuenta la duración mínima que debe tener una
sibilancia para ser definida como tal. Debemos tener en cuenta que los dos pacientes que
participaron en la grabación de sonidos respiratorios para este estudio (un varón de 18
años asmático y una mujer sana de 19 años) fueron sometidos a la inhalación de
alérgenos con el fin de padecer obstrucciones en las vías respiratorias, reduciendo así un
20 % el volumen de aire inhalado con respecto a una respiración normal. Al final de las
conclusiones, es mencionado el hecho de que los resultados obtenidos por la paciente
femenina no han sido los esperados debido, en parte, a ruidos interferentes en las
grabaciones introducidos por los sistemas de grabación, tos del paciente, posibles
crepitantes en la respiración, etc.
En el estudio realizado en [13] se lleva a cabo la grabación de la respiración de
hasta 12 pacientes con edades comprendidas entre los 22 y los 55 años con el fin de
implementar un sistema capaz de monitorizar las obstrucciones debidas al asma que
aparecen en el aparato respiratorio. Tras la grabación de 30 minutos de respiración de
cada paciente, el sistema elegirá segmentos de duración 250 ms en intervalos de 5
minutos en dicha muestra de audio con el fin de estimar el número de sibilancias
existentes en ese tramo respiratorio de media hora para así poder obtener información
acerca de la gravedad que supone la obstrucción en vías respiratorias del paciente
analizado.
Tras el análisis de los audios, se llega a la conclusión de que las sibilancias están
asociadas a un pico bien diferenciado en frecuencia situado en un rango comprendido
entre los 150 Hz y los 1000 Hz. Teniendo en cuenta que la duración de una sibilancia es
definida con un valor de 250 ms, se utiliza en el algoritmo de análisis de señales sonoras
transformadas rápidas de Fourier en segmentos de la misma duración. La frecuencia de
muestreo usada para la digitalización de las muestras en este estudio es de 2048
muestras por segundo. En este estudio ha sido administrado a cada paciente sustancias
broncodilatadoras con el fin de aumentar el volumen de aire en un espiración forzada
(FEV – Forced expiratory volume). A continuación, se muestra una tabla reflejada en la

43
figura 4.5 con información relativa a la edad de los pacientes y el volumen de aire
espirado antes y después de ser aplicada la sustancia broncodilatadora:
Figura 4.5 – Resultados del análisis de respiraciones de los 12 sujetos participantes en la prueba realizada en [13].
En el estudio se demuestra como la cantidad de aire introducido en las vías
respiratorias está relacionado de forma directa con la aparición de ciertos picos en las
sibilancias producidas por el asma.
Hay que remarcar el hecho de que la mayoría de estudios referenciados no toman
diferentes rangos en frecuencia para diferentes tipos de paciente sino que realizan
estudios orientados exclusivamente a niños de corta edad o adultos, obteniendo rangos
en frecuencia que no son aplicables para otro tipo de paciente que no sea el analizado
como sujeto de prueba. También debemos mencionar que la mayoría de los estudios
llevados a cabo obtienen las muestras de audio de forma autónoma mediante el uso de
diversas técnicas de grabación dirigidas por los autores en cuestión. Como es de esperar,
estas muestras de audio no están disponibles de forma gratuita en la gran mayoría de
casos, llegando a ser escasa la cantidad de audios disponibles sin utilizar métodos de
pago. Otros métodos referenciados toman muestras de audio presentes en bases de
datos alojadas en Internet, siendo necesario realizar una suscripción de pago al servicio
que las gestiona.
En cuanto a software diseñado para la detección de sibilancias cuya
implementación ha sido explicada de forma breve en artículos de investigación, podemos
destacar los siguientes tres a partir de los cuales nuestro software ha sido construido: en
[14], además de tratar la problemática que hemos presentado anteriormente acerca de la

44
gran variedad de rangos en frecuencia propuestos, se presenta la implementación de un
software detector de sibilancias basado en el estudio en frecuencia de la señal de audio.
Aunque referencia el origen de las muestras de audio utilizadas para demostrar la
eficiencia del programa, las páginas webs utilizadas actualmente se encuentran fuera de
servicio y nos ha sido imposible obtener dichas muestras de audio para ser utilizadas en
nuestro software. El análisis espectral ha sido realizado mediante transformadas rápidas
de Fourier con ventanas de 50 ms solapadas al 50% sobre audios muestreados a 5500
Hz. Después de especificar estos parámetros, una breve descripción del proceso de
detección es dada: tras un análisis en frecuencia, se detectan los picos predominantes
que estén localizados dentro del rango en frecuencia usado en este estudio (225-800 Hz)
tal y como se muestra en la figura 4.6, extraída del artículo:
Figura 4.6 – Espectrograma de una respiración sana (a) y de una respiración con sibilancias (b), mostrando el rango en frecuencia donde suelen aparecer los picos más
significativos [14].

45
Dichos picos se deben agrupar y tras ello, se comprobará la continuidad de cada
agrupación, teniendo en cuenta que la duración mínima para una sibilancia se establece
en 250 ms. A continuación, se muestra el esquema del algoritmo propuesto en este
artículo, mostrado en la figura 4.7. Finalmente, son mencionados los resultados obtenidos
por el software para diferentes muestras de audio que contienen distintos tipos de
sibilancias y otros sonidos adventicios. Como podemos observar, en los experimentos
realizados, el software detecta el 100% de las muestras pertenecientes a sibilancias
espiratorias e inspiratorias, detecta el 89% de las sibilancias monofónicas y un 60% del
resto de sonidos sibilantes. De esta manera, podemos observar ante que sonidos
sibilantes es más robusto este software.
Figura 4.7 – Diagrama de bloques del algoritmo propuesto en [14].
Como podremos apreciar en apartados posteriores, el esquema que proponemos
se basa tanto en el expuesto en la figura 4.7 como en el expuesto en la figura 4.8, ya que
ambos basan el proceso de detección de sibilancias en la detección de picos
significativos encontrados en el espectrograma de una señal sonora.
Por otro lado, es en [15] donde se muestra un tipo de software para la detección
de sibilancias parecido al anterior. Este programa también realiza un análisis en
frecuencia de las señales de audio que procese. Las muestras utilizadas han sido
muestreadas con diferentes frecuencias, desde 4000 Hz hasta 8012 Hz. La obtención del

46
espectrograma, de nuevo, se realiza mediante una serie de transformadas de Fourier
rápidas, sin especificar los parámetros usados.
A continuación, se presenta un método de agrupación de picos significativos
basado en el efecto Haas. Según este efecto, si varios sonidos independientes o
procedentes de distintas fuentes sonoras alcanzan nuestro oído en un intervalo inferior a
50 ms de separación entre ellos, el cerebro los interpretará como uno solo. En el método
presentado en nuestro trabajo, se explicará el porqué de basarnos en este efecto para la
agrupación de picos o como denominaremos más adelante, obtención de trayectorias.
Tras la agrupación se realiza un estudio de la continuidad de los grupos obtenidos
y se descartarán los que no superen el tiempo mínimo establecido, en este caso 150 ms.
El método tratado en este artículo añade un último paso en el descarte de posibles falsos
positivos basado en el cálculo de un factor que relaciona la potencia sonora de una
posible sibilancia con la potencia sonora del audio completo. Si dicho factor supera un
umbral, no se descartará la posible sibilancia. Debido a que la duración total del audio
introducido en el programa puede variar según el tipo de grabación y otros factores
ajenos al software, este valor calculado depende totalmente de la longitud de la muestra
introducida, lo cual hace que un umbral determinado solo sirva para descartar posibles
falsos positivos en cierto número de audios utilizados, siendo necesario el hecho de
volver a calcular un nuevo umbral para muestras de audio de mayor o menor duración
total. En nuestro caso, el software implementado en este trabajo no tiene restricciones en
cuanto a duración del audio analizado, por lo tanto, no se considera robusto el cálculo de
un umbral para cada señal introducida, es por ello por lo que se ha decidido no incluir
este último paso en el desarrollo de nuestro detector de sibilancias. En la figura 4.8 se
muestra el esquema de la implementación del software propuesto en el documento
referenciado:
Figura 4.8 – Esquema de la implementación del software propuesto en el artículo [15].
Este método, como vemos, también se basa en la agrupación de picos
significativos, desechando agrupaciones cuya duración mínima no supere los 150 ms de
duración. Tras ello, se realizará el cálculo de la potencia de las supuestas sibilancias para
determinar mediante la comparación con un umbral establecido si realmente lo son o
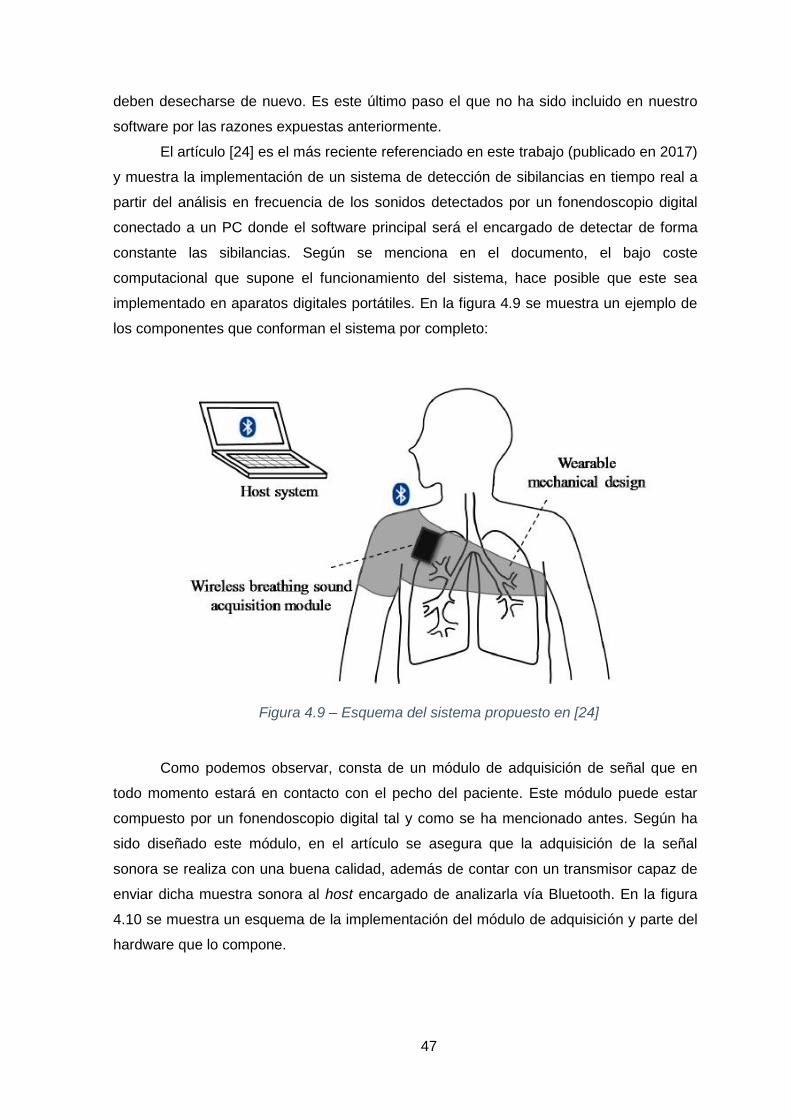
47
deben desecharse de nuevo. Es este último paso el que no ha sido incluido en nuestro
software por las razones expuestas anteriormente.
El artículo [24] es el más reciente referenciado en este trabajo (publicado en 2017)
y muestra la implementación de un sistema de detección de sibilancias en tiempo real a
partir del análisis en frecuencia de los sonidos detectados por un fonendoscopio digital
conectado a un PC donde el software principal será el encargado de detectar de forma
constante las sibilancias. Según se menciona en el documento, el bajo coste
computacional que supone el funcionamiento del sistema, hace posible que este sea
implementado en aparatos digitales portátiles. En la figura 4.9 se muestra un ejemplo de
los componentes que conforman el sistema por completo:
Figura 4.9 – Esquema del sistema propuesto en [24]
Como podemos observar, consta de un módulo de adquisición de señal que en
todo momento estará en contacto con el pecho del paciente. Este módulo puede estar
compuesto por un fonendoscopio digital tal y como se ha mencionado antes. Según ha
sido diseñado este módulo, en el artículo se asegura que la adquisición de la señal
sonora se realiza con una buena calidad, además de contar con un transmisor capaz de
enviar dicha muestra sonora al host encargado de analizarla vía Bluetooth. En la figura
4.10 se muestra un esquema de la implementación del módulo de adquisición y parte del
hardware que lo compone.

48
Figura 4.10 – a) diagrama de bloques implementado en el módulo de adquisición. b) hardware que compone el módulo. c) sensor acústico. [24]
El rango establecido en el cual la frecuencia fundamental de una sibilancia suele
oscilar se encuentra situado entre los 250 Hz y los 800 Hz, con una duración temporal de
más de 250 ms. Mediante estos parámetros, el software propuesto en el artículo será
capaz de extraer información espectral en tiempo real gracias a los módulos que se
implementan y se muestran en la figura 4.11:
Figura 4.11 – Diagrama de bloques del software propuesto en [24].
La fase de pre-procesado consta de un filtro paso banda con frecuencias de corte
situadas en 150 Hz y 1000 Hz con el fin de eliminar ruido introducido por los latidos del
corazón, del movimiento de los músculos y del flujo de sangre. El cálculo espectral será
realizado utilizando una ventana de Hanning de duración 250 ms con solapamiento de

49
200 ms para un posterior cálculo de la FFT de cada segmento del audio una vez pre-
procesado.
En la figura 4.12 se muestra una tabla con los resultados obtenidos, mostrando los
verdaderos positivos (TP), falsos positivos (FP), falsos negativos (FN) y verdaderos
negativos (TN) detectados en el proceso de evaluación llevado a cabo en el estudio.
Figura 4.12 – Resultados obtenidos en [24]
Podemos observar como la ausencia de falsos positivos y la pequeña cantidad de
falsos negativos detectados confirman el hecho de que el software tenga resultados
satisfactorios en un 91.51% de los casos.
Los audios utilizados en este experimento proceden de 40 pacientes adultos con
irregularidades pulmonares y 11 adultos sanos. Estos 40 pacientes fueron sometidos a un
reconocimiento previo en el cual un médico certificó la existencia de sibilancias en sus
respiraciones.
Por último, en [3] se utiliza un software basado en métodos diferentes a los
anteriores, haciendo uso de descriptores para reconocer sibilancias. Estos descriptores
se basan en ratios de energía en bandas de frecuencia (ER, es parecido al método de
obtención de picos significativos en rangos establecidos), cálculos relacionados con los
rangos de frecuencia determinados para la frecuencia fundamental de una sibilancia
(D2M), obtención de correlaciones de la señal original (CF), etc. Mediante la variación de
estos descriptores, se aporta al final del documento una tabla que recoge los diferentes
valores de eficiencia según el parámetro predominante usado. Se obtienen valores desde
un 82.6% de eficiencia hasta un 84.2%.

50
5 IMPLEMENTACIÓN
5.1 Diagrama de bloques del software propuesto
Como el propio título de este trabajo fin de grado indica, el resultado final ha sido
la obtención de un software implementado sobre Matlab capaz de detectar y analizar
sibilancias contenidas en archivos de audio pregrabados. El usuario, ayudándose de una
interfaz gráfica, será capaz de introducir un archivo de audio en formato WAV que
contenga la respiración de un paciente. Como resultado, la interfaz mostrará el número
de sibilancias detectadas (en caso de que las haya), si son polifónicas o monofónicas, el
número de armónicos detectados y una representación gráfica del espectrograma de la
señal. El usuario podrá elegir qué representar en el apartado gráfico. En la sección 9 de
esta memoria se incluye una guía de usuario para ayudar a comprender el
funcionamiento de la interfaz.
En la figura 5.1 se presenta un esquema de los pasos llevados a cabo en la
implementación del software (basado en los esquemas propuestos en [14] y [15]). Cada
bloque muestra un tipo de procesado diferente realizado sobre la muestra de audio y su
espectrograma. A continuación, aunque se muestra una breve descripción de 4 conjuntos
de bloques en la propia figura, se realizará una breve descripción de dichas agrupaciones
para más tarde describir paso a paso de forma específica cada bloque, mostrando una
descripción de su implementación.
Grupo 1: se muestran los preparativos necesarios para el correcto
procesado de la señal de audio que se desea analizar. Dicha muestra de
audio debe ser muestreada a 8000 Hz para poder obtener un
espectrograma adecuado que facilite la detección de sibilancias. Tras esto,
ajustando los parámetros necesarios para realizar el conjunto de
transformadas rápidas de Fourier mediante técnicas de enventanado,
obtendremos el espectrograma de la señal de audio. Dicho espectrograma
servirá para obtener los picos más significativos de la señal original a partir
de los cuales el procesado digital será llevado a cabo.
Grupo 2: aquí se realiza el proceso de agrupación o como ese ha decidido
nombrar en este trabajo, obtención de trayectorias. Mediante un método de
ventana deslizante, analizaremos los picos más significativos obtenidos en
la primera fase para poder agruparlos en función de sus características en
frecuencia y su posición temporal dentro del espectrograma. De forma
sucesiva, se construirán trayectorias o agrupaciones de picos que cumplan
ciertos requisitos mostrados en el siguiente sub-apartado.

51
Figura 5.1 - Esquema de la implementación del software

52
Grupo 3: en él se encuentra el código relacionado con la comprobación de
todos los parámetros obtenidos a lo largo del proceso, mediante los cuales
se tomará la decisión de si las trayectorias obtenidas cumplen las
condiciones necesarias para ser consideradas sibilancias.
Grupo 4: contiene el código necesario para detectar y contar armónicos en
el caso de que los haya. Mediante el análisis de una de las sibilancias, se
buscarán posibles armónicos para poder decidir si esta posible sibilancia
es monofónica (no tiene armónicos) o es polifónica (contiene armónicos).
Como se indica en la figura, este apartado permite descartar ruttles,
anteriormente comentados en el apartado 2.3.
5.2 Implementación de cada bloque
En este apartado se procederá a explicar uno por uno los bloques o etapas
mencionados en el diagrama expuesto anteriormente. Todos ellos están incluidos en el
archivo denominado "principal.m" donde se podrá observar con detalle el código utilizado
para implementar el software detector de sibilancias. Se adjunta con esta memoria.
La versión del programa Matlab utilizada debe ser la R2007b o superior debido a
que es en ella donde se incluye una serie de funciones útiles para el desarrollo de
nuestro software. En nuestro caso, el programa fue desarrollado con la versión R2013a.
5.2.1 Etapa 1: adquisición de señal
En primer lugar, debemos elegir una señal de audio de una respiración humana
que contenga o no sibilancias. No hay ninguna restricción en cuanto a duración de la
muestra introducida, solamente debemos asegurarnos que su formato es del tipo WAV
para que el software pueda extraer correctamente los datos que componen la señal de
entrada. Además, el audio debe haber sido muestreado a 8000 Hz, como se mencionó
anteriormente (las componentes en frecuencia de la respiración pueden llegar a alcanzar
hasta los 4000 Hz). Si el usuario no está seguro de que esto sea así, no debe
preocuparse ya que en la interfaz se han implementado un conjunto de líneas de código
capaces de remuestrear la señal extraída del audio a dicha frecuencia de muestreo. El
archivo de audio original no sufrirá ninguna modificación en este caso. No es relevante el
hecho de que el audio analizado sea o no monocanal.
5.2.2 Etapa 2: transformación tiempo-frecuencia. Cálculo de espectrograma
La obtención del espectrograma a partir del cual se realizará el procesado digital
se efectúa mediante la función denominada "sg", también incluida junto a esta memoria.
Dicha función debe encontrarse en el directorio en el que se sitúe la función principal y el
archivo que contiene el código que implementa la interfaz de usuario "interface.m". Esta
función ejecuta una STFT mediante los siguientes parámetros de entrada:

53
"y": señal que contiene la muestra de audio a analizar.
"nfft": número de transformadas rápidas de Fourier que se efectúan.
Depende del tamaño de la ventana que se elija, lo que a su vez repercutirá
en la resolución del espectrograma. A un mayor tamaño de ventana,
menor resolución temporal y mayor resolución en frecuencia.
"fs": frecuencia de muestreo del audio sobre el que se trabajará.
"window": tipo de ventana que se utilizará para la obtención de
espectrograma, en este caso hemos utilizado una ventana de Hanning con
el número de muestras que introduzca el usuario. En nuestro caso se
recomienda que el tamaño sea de 1024 muestras.
"noverlap": número de muestras que se solaparán en el proceso de
enventanado. En nuestro caso usaremos un solapamiento del 50%, es
decir, la ventana, al desplazarse se solapará con la mitad de las muestras
abarcadas en el instante anterior.
Tras este proceso, obtendremos una matriz cuyo valor absoluto será el que
utilicemos ("Vabs") ya que no nos interesa trabajar con la componente en fase de la
transformada de Fourier. Esto es debido a que en este trabajo solo tendremos en cuenta
el valor de la distribución energética de la señal sonora en el dominio de la frecuencia y
por lo tanto, la componente en fase devuelta por la función anterior no nos aportará
información relevante para la detección de sibilancias.
La representación visual del espectrograma se realizará con la función "imagesc",
especificando en ella los límites de los ejes, siendo el de frecuencia de 0 a 4000 Hz (la
mitad de la frecuencia de muestreo) y el temporal de 0 hasta la duración total del audio.
En cuanto a nomenclatura, llamaremos "frames" a cada una de las columnas que
componen la matriz principal "Vabs" compuesta por los valores que conforman el
espectrograma de la señal sonora y son el resultado del cálculo de cada una de las FFT
de las muestras enventanadas. La duración temporal de cada frame está relacionada
directamente con el número de muestras abarcadas por la ventana, es decir, del tamaño
de esta y del porcentaje de solapamiento utilizado para el cálculo del espectrograma. Es
por esta razón, que a mayor tamaño de ventana utilizado, más muestras abarca la
ventana y por lo tanto la duración temporal de cada frame será mayor. Como
consecuencia, la matriz "Vabs" contendrá menos columnas o frames y la resolución
temporal del espectrograma calculado será menor, tal y como se mostró en el apartado
2.1.4.
Un ejemplo de espectrograma de una respiración con sibilancias polifónicas es el
presentado en la figura 5.2. Podemos ver cómo estas sibilancias se diferencian
claramente en el diagrama ya que son más energéticas que el resto de componentes en

54
frecuencia de la respiración y además, los picos que lo forman son continuos en el tiempo
y cercanos en frecuencia. Este factor será determinante a la hora de realizar
agrupaciones. El audio de duración 10 segundos mediante el cual se ha extraído el
espectrograma reflejado en la figura 5.2 se denomina "6025.wav" (obtenido a partir de
[18]), la ventana usada es de tipo Hanning con una longitud de 1024 muestras. En el
ejemplo podemos apreciar la existencia de 4 sibilancias a partir de los segundos 2, 4, 6.4
y 8.6 respectivamente, todas ellas con aproximadamente 1 segundo de duración.
Figura 5.2 - Espectrograma de una señal de audio con sibilancias.
A continuación, se muestra el espectrograma de otra señal de audio de duración 5
segundos denominada "Wheeze-Bronchiolitis2.wav" (obtenido a partir de [17]), reflejada
en la figura 5.3. Este espectrograma ha sido obtenido mediante una ventana de Hanning
con 512 muestras de longitud. Apreciamos la existencia de 4 sibilancias polifónicas a
partir de los segundos 0.5, 2, 3 y 4.3 respectivamente, cada una con una duración
aproximada de 1 segundo.

55
Figura 5.3 - Espectrograma de una señal de audio con sibilancias, ejemplo 2.
5.2.3 Etapa 3: cálculo de picos más significativos
Es en este bloque donde usaremos la función "findpeaks" para la obtención de los
valores más significativos encontrados en cada frame de la matriz. Se recorrerá mediante
un bucle cada uno de los frames que componen el espectrograma y se aplicará dicha
función de Matlab en cada caso. Los parámetros introducidos en el comando "findpeaks"
son los siguientes:
"SORTSTR": con él se especifica a la función que deseamos obtener los
picos más significativos de forma ordenada. A continuación, debemos
especificar que queremos que los picos se obtengan en orden
descendente (el primer pico que nos devuelva como resultado será el más
energético, mientras que el último será el menos energético en cada
frame).
"NPEAKS": se refiere al número de picos que queremos que la función nos
devuelva en cada frame. Tras varias pruebas, se decidió que devolviese
los 5 más significativos por frame ya que eran suficientes para los
posteriores cálculos.

56
"MINPEAKDISTANCE": hace referencia a la distancia mínima que debe
tener un pico y su consecutivo para que la función lo muestre. En este
caso, de nuevo, tras varias pruebas se ha considerado que la distancia
entre pico y pico consecutivo debe ser como mínimo de 5 muestras. De
este modo evitamos que la función seleccione picos demasiado próximos
que se podrían considerar realmente como uno solo. Esto es debido a que
la anchura espectral de un pico suele ser de 5 muestras aproximadamente,
por lo tanto, cualquier conjunto de picos detectados distanciados por 5 o
menos muestras pueden ser considerados como un único pico.
"THRESHOLD": Sirve para especificar un umbral mínimo a partir del cual
un pico se considera significativo. Este valor muestra cuantas veces debe
ser mayor un pico con respecto a sus valores vecinos para poder ser
seleccionado.
Un ejemplo de frame al que es aplicada esta función puede ser el reflejado en la
figura 5.4, donde se representa mediante la función "plot" de Matlab una de las columnas
que conforman la matriz Vabs, con picos pertenecientes a sibilancias en "6025.wav". En
este caso se muestra el frame número 115 el cual se corresponde con el segundo 7.3 del
audio, aproximádamente:
Figura 5.4 – Representación del frame número 115 de la matriz Vabs.
0 100 200 300 400 500 600-150
-100
-50
0
50
100
X: 40
Y: 44.76
X: 21
Y: 57.61
Frecuencia (filas)
Inte
nsid
ad (
dB
)

57
Podemos observar en la figura anterior la existencia de picos bien diferenciados
dentro de un frame, es decir, un instante corto de tiempo. Sobre el eje "X" se representa
la frecuencia (no expresada en Hz, sino en filas del vector Vabs) de los puntos
pertenecientes al frame en cuestión mientras que sobre el eje "Y" se indica la intensidad
de cada uno de los puntos que conforman el frame número 40, en este caso en concreto.
Los marcadores indican la situación de los picos más enérgicos dentro del frame.
Cada pico detectado con esta función será almacenado en una nueva matriz
denominada "Vabs_pico" cuya estructura es similar a "Vabs", su representación también
se puede efectuar si el usuario lo desea. Además, usando la posición de los picos que
también devuelve el comando anterior, obtendremos una nueva matriz denominada
"posicion_picos" que, como su nombre indica, almacenará la posición en frecuencia y
tiempo de cada uno de los picos obtenidos por frame. Debido a que la respiración
humana y los sistemas de grabación son propensos a introducir ruido de baja frecuencia,
se han implementado un conjunto de líneas de código capaces de eliminar los picos más
significativos detectados debido a la presencia de ruido de baja frecuencia, desechando
dichos picos que se encuentren por debajo de los 70 Hz (basado en el filtrado realizado
en la fase de pre-procesado de [8]). Además, tal y como se ha visto en [5], la frecuencia
fundamental de los ruttles puede oscilar entorno a este valor en niños de corta edad.
A continuación se muestra un ejemplo recogido en la figura 5.5 de los picos más
significativos calculados a partir del espectrograma expuesto en la figura 5.2:

58
Figura 5.5 - Picos más significativos obtenidos mediante "findpeaks" de la señal de audio "6025.wav".
Por otro lado, podemos apreciar esta misma fase de detección de picos aplicada
al espectrograma expuesto en la figura 5.3 perteneciente a la señal de audio contenida
en el archivo "Wheeze-Bronchiolitis2.wav". Como se indicó anteriormente, este ejemplo
se realizó con una ventana de Hanning de 512 muestras (64 ms) con una frecuencia de
muestreo de 8000 Hz y se expone en la figura 5.6:
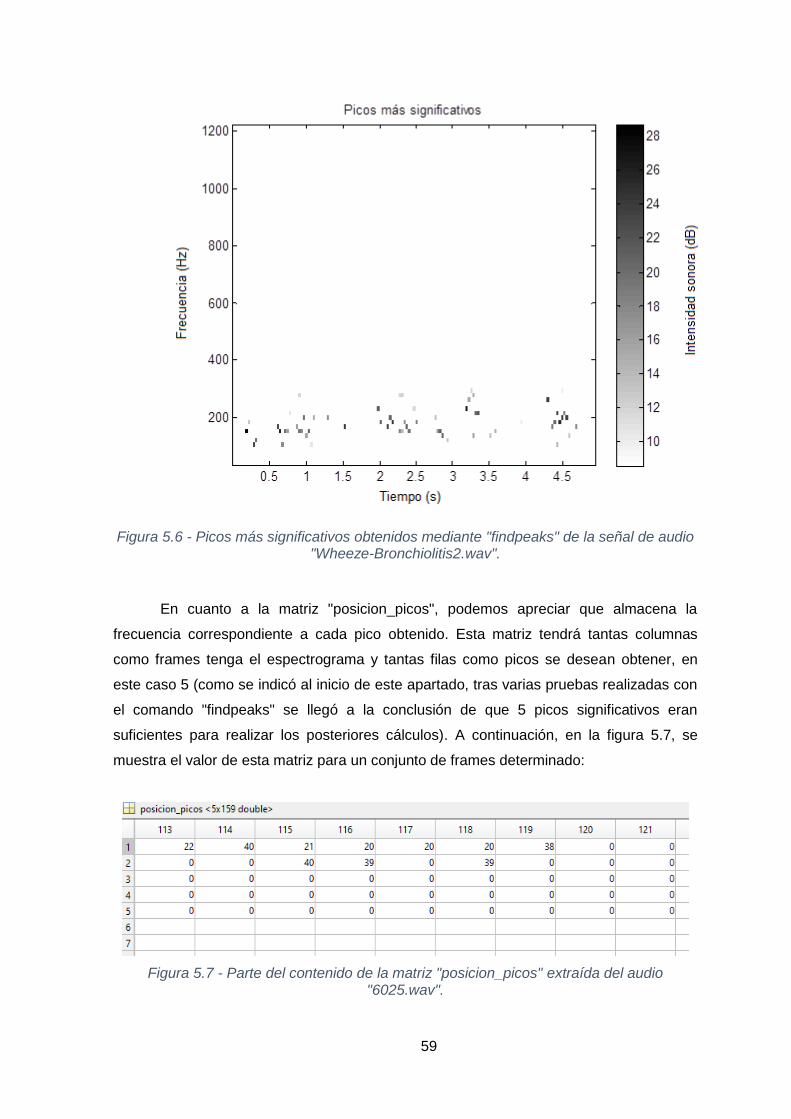
59
Figura 5.6 - Picos más significativos obtenidos mediante "findpeaks" de la señal de audio "Wheeze-Bronchiolitis2.wav".
En cuanto a la matriz "posicion_picos", podemos apreciar que almacena la
frecuencia correspondiente a cada pico obtenido. Esta matriz tendrá tantas columnas
como frames tenga el espectrograma y tantas filas como picos se desean obtener, en
este caso 5 (como se indicó al inicio de este apartado, tras varias pruebas realizadas con
el comando "findpeaks" se llegó a la conclusión de que 5 picos significativos eran
suficientes para realizar los posteriores cálculos). A continuación, en la figura 5.7, se
muestra el valor de esta matriz para un conjunto de frames determinado:
Figura 5.7 - Parte del contenido de la matriz "posicion_picos" extraída del audio "6025.wav".

60
Podemos observar como en cada frame (en este caso se representan los frames
número 113 hasta 121, correspondientes a los segundos 7.2 y 7.7 respectivamente) se
almacenan los valores relativos a la posición en frecuencia de los picos más significativos
ordenados de forma descendente. Por ejemplo, en el frame 115 se han detectado dos
picos significativos (tal y como se indicó en la figura 5.4) que cumplan las condiciones
impuestas con el comando "findpeaks". El valor de la primera fila de este frame se
corresponde con la posición en frecuencia del pico más energético. El valor de la
segunda fila en dicho frame, por lo tanto, se corresponderá con el siguiente pico más
significativo, aunque menos energético que el anterior. Como solo se han detectado 2
picos, el resto de filas se rellenan con 0 hasta completar las 5 filas.
En definitiva, almacenar la posición en frecuencia de cada pico es útil para el
posterior procesado y tener en todo momento la localización en frecuencia y tiempo
dentro del espectrograma principal de dichos valores.
5.2.4 Etapa 4: construcción de trayectorias
Como hemos podido apreciar en los espectrogramas de las sibilancias, estas se
caracterizan por contener componentes de alta energía (picos significativos) en rangos de
frecuencia determinados (definidos en el apartado 2.3). Esto quiere decir que a través del
espectrograma, podemos apreciar zonas de alta energía correspondientes a las
frecuencias excitadas cuando aparecen o se superponen sibilancias sobre la respiración
humana, por el hecho de que estas predominan frente a las componentes en frecuencia
generadas por la respiración humana u otros sonidos, como por ejemplo los producidos
por los latidos del corazón.
También hemos podido observar como la disposición en frecuencia y tiempo de
estos picos significativos es continua, es decir, estas componentes más energéticas son
consecutivas entre sí temporalmente hablando (lo cual nos indica que provienen de la
misma fuente) y su valor en frecuencia se mantiene en un rango establecido (no hay
cambios bruscos de frecuencia), cuando estos picos pertenecen a la misma sibilancia.
Por esta razón, la forma espectral de éstas se asemejará a un conjunto de puntos
temporalmente consecutivos y cercanos en frecuencia. Es por ello por lo que nos interesa
formar agrupaciones de picos significativos que cumplan esa cercanía temporal y en
frecuencia, es decir, queremos encontrar trayectorias para su posterior análisis. Todas las
sibilancias son definidas como trayectorias, pero no todas las trayectorias serán definidas
como sibilancias. Para ser consideradas como tal, estas agrupaciones deben tener una
duración temporal de como mínimo 250ms [6] y su frecuencia fundamental debe oscilar
entre los rangos ya establecidos anteriormente (apartado 2.3). En la figura 5.8 podemos

61
apreciar una trayectoria procedente del audio "143Post7R.wav" [19], perteneciente a la
primera sibilancia que encontramos en él:
Figura 5.8 – Trayectoria extraída en el proceso de detección de sibilancias para el audio "143Post7R.wav".
Podemos apreciar en la figura 5.8 como estos picos significativos se disponen en
el espectrograma tal y como se ha indicado, respetando cierta cercanía en frecuencia y
tiempo.
Por lo tanto, una vez obtenidos todos los picos más significativos, sabiendo que
no todos ellos se corresponden con sibilancias (en el caso de que las haya), debemos
formar agrupaciones que cumplan ciertos requisitos en frecuencia y tiempo, las cuales
serán denominadas trayectorias. Estos grupos estarán formados por picos significativos
continuos en tiempo y frecuencia, es decir, cada uno de los picos que conforme este tipo
de agrupaciones tendrán un valor en frecuencia cercano entre sí y además serán
próximos temporalmente hablando. Por ejemplo, un pico cuya frecuencia tenga un valor
de 100 Hz y esté situado a menos de 50 ms de otro con una frecuencia de 300 Hz no
podrán formar parte de la misma trayectoria ya que no son lo suficientemente cercanos
en freuencia. Los criterios que definen la cercanía o lejanía temporal o en frecuencia
serán explicados más adelante basándonos en diferentes aspectos, por lo tanto, aún no

62
nos centraremos en los rangos en frecuencia definidos para las sibilancias ni la duración
mínima de estas, solamente crearemos grupos de picos significativos cercanos entre sí,
siendo considerados posibles sibilancias para su posterior análisis.
El método para obtener trayectorias se basa en el uso de una ventana temporal
de duración t ± 50ms. Como es propuesto en [15] en cuanto a continuidad temporal, se
realizarán agrupaciones de componentes en frecuencia basadas en el efecto Haas, es
decir, consideraremos grupos de picos significativos cuyo valor en frecuencia sean
cercanos, lo cual implica que la separación temporal entre muestra y muestra no exceda
los 50 ms. Por esta razón, se considerarán muestras de distintas trayectorias aquellas
cuya separación temporal exceda los 50 ms. Por otro lado, aquellas muestras separadas
50 ms o menos, aunque no sean consecutivas, se incluirán en la misma agrupación o
como se ha mencionado antes, se incluirán en la misma trayectoria.
Además, consideraremos que las muestras analizadas para la obtención de
trayectorias pertenecerán a una misma agrupación si presentan cierta continuidad en
frecuencia. En este caso, dos o más picos pertenecerán a la misma trayectoria si,
además de respetar cierta continuidad temporal, sus valores en frecuencia no distan más
de 30 Hz entre sí, tal y como se propone en [14], tras varias pruebas con distintos rangos
propuestos.
La ventana propuesta se deslizará a lo largo de la matriz que está compuesta por
los picos más significativos anteriormente obtenidos, esto es, analizaremos
consecutivamente una muestra cuya posición temporal es "t" (instante actual analizado
en el espectrograma y posición central de la ventana), comparada con picos adyacentes
situados en t ± t_ventana, en este caso, "t_ventana" equivale a 50ms. En función de los
requisitos en tiempo y frecuencia definidos anteriormente, empezaremos a conformar las
agrupaciones, teniendo en cuenta la diferencia de frecuencia y separación temporal entre
picos analizados. El método utilizado está basado en el propuesto en [16], un proyecto fin
de grado donde el principal objetivo es el de confeccionar un sistema para la extracción
de singing voice en señales musicales polifónicas monoaurales. En nuestro caso, hemos
seguido la siguiente metodología:
- En primer lugar, buscaremos el pico con más energía de entre los
comprendidos en la ventana con el fin de tomarlo como umbral, es decir,
supondremos que corresponde a una sibilancia (será el valor de referencia con
el que compararemos el resto de picos comprendidos en el frame
seleccionado en el instante actual t). Este pico será denominado como máximo
absoluto (MA).
- Tomaremos los máximos que se encuentren en el instante actual t
(normalmente estos picos se corresponden con la frecuencia dominante de la

63
sibilancia y con picos en frecuencias armónicas a la anterior). Serán
denominados como máximos relativos (MR).
- Compararemos la frecuencia de cada uno de estos máximos relativos con la
frecuencia de la muestra umbral (máximo absoluto). Si la diferencia de
frecuencias entre ambos picos (absoluto y relativo) es menor a 30Hz y la
separación temporal es menor a 50ms (al encontrarse dentro de los límites de
la ventana cumple este requisito) entonces estos picos pertenecerán a un
mismo grupo o trayectoria.
- La ventana se "deslizará" en el tiempo, es decir, tomaremos un frame central
"t" sucesivo al utilizado anteriormente.
- De nuevo, buscaremos la muestra en frecuencia cuya energía sea máxima en
comparación con el resto de muestras comprendidas en la ventana. Es posible
que este valor sea el mismo que el anterior, por lo que el umbral no varía, en
otros casos este pico absoluto no será el mismo, por ello el umbral de
referencia variará. De nuevo compararemos los máximos relativos contenidos
en el frame con el umbral definido y se decidirá si estos pertenecen o no a las
agrupaciones o trayectorias.
En la figura 5.9 se muestra un ejemplo gráfico de la ventana que se utiliza y los
máximos absolutos o relativos que comparamos en ella. Las curvas de color negro
simbolizan la consecución de picos significativos detectados en una sibilancia y en uno
de sus armónicos. Los puntos de color, tal y como se indican, reflejan la existencia de
máximos relativos y absolutos.
Figura 5.9 - Ejemplo de ventana deslizante

64
Por lo tanto, podemos reflejar este método mediante la expresión (30):
𝑀𝑅(𝑡) ∈ 𝑉𝑡𝑟𝑎𝑦𝑒𝑐𝑡𝑜𝑟𝑖𝑎 → 𝑓max _𝑎𝑏𝑠 − ∆𝑓 ≤ 𝑓(𝑡) ≤ 𝑓max _𝑎𝑏𝑠 + ∆𝑓 (30)
Siendo 𝑀𝑅(𝑡) el máximo relativo analizado en el instante actual 𝑡, 𝑓(𝑡) la
frecuencia de dicho máximo, 𝑉𝑡𝑟𝑎𝑦𝑒𝑐𝑡𝑜𝑟𝑖𝑎 el vector que contiene la trayectoria conformada
en ese instante, 𝑓max _𝑎𝑏𝑠 la frecuencia del máximo absoluto que se encuentre en la
ventana en ese instante, ∆𝑓 el incremento en frecuencia utilizado, siendo en este caso de
30 Hz y finalmente, 𝑡 representa el instante actual en el que se encuentra el centro de la
ventana, es decir, el frame actual analizado donde se encuentra el máximo relativo con el
que se realizará la comparación. Como sabemos, el instante en el que se encuentra el
máximo absoluto que utilizaremos como referencia se encontrará en el siguiente rango
definido por la anchura de la ventana deslizante utilizada en la construcción de
trayectorias, reflejado en la expresión (31):
𝑡 − ∆𝑡 ≤ 𝑡max _𝑎𝑏𝑠 ≤ 𝑡 + ∆𝑡 (31)
Siendo 𝑡max _𝑎𝑏𝑠 la localización temporal dentro del espectrograma de la muestra
considerada como umbral o máximo absoluto (MA) y ∆𝑡 la anchura temporal de la
ventana utilizada para la construcción de las traectorias.
Por lo tanto, confirmamos la igualdad (32):
𝑓max _𝑎𝑏𝑠 = 𝑓(𝑡max _𝑎𝑏𝑠) (32)
Tras este proceso de agrupamiento de picos significativos según los criterios
mencionados, obtendremos dos matrices denominados "trayectorias" y
"trayectorias_frecuencia". Ambas tienen la misma estructura compuesta por tantas
columnas como frames existan en el espectrograma original y tantas filas como
trayectorias se hayan construido. Como es de esperar, cada fila contendrá los valores de
energía de los picos de cada trayectoria de forma independiente. Por otro lado,

65
"trayectorias_frecuencia" contendrá el valor de la frecuencia de cada pico contenido en
las trayectorias para poder tener localizado en todo momento dichos picos. A
continuación, en la figura 5.10, se muestra un ejemplo de estas matrices:
Figura 5.10 - Ejemplo de una trayectoria contenida en la matriz "trayectorias" extraída del audio "6025.wav".
Como vemos, este proceso puede generar trayectorias incompletas, es decir,
pueden incluir ceros entre los picos seleccionados obteniendo trayectorias discontinuas.
Esto es debido a que la separación entre picos relativos analizados (en este caso los
situados en el frame 68 y 71) e incluidos en las trayectorias es menor a 50 ms. Si la
separación entre estos máximos relativos hubiera sido mayor (existieran más ceros entre
ambos picos en la matriz) superando los 50 ms, ambos habrían sido asignados a
trayectorias diferentes.
Para obtener una trayectoria completa debemos interpolar dichos valores nulos
usando las muestras cercanas. Supongamos que el algoritmo ha sido capaz de construir
la trayectoria anteriormente mostrada en la figura 5.10. Tras la ejecución del código
encargado de interpolar las trayectorias, obtenemos de forma consecutiva los siguientes
resultados mostrados en las figuras 5.11 y 5.12. Como vemos, la rutina de interpolación
permite completar las trayectorias construidas, añadiendo valores de amplitud y
frecuencia obtenidos a partir de una media aritmética entre los valores ya conocidos.
Dicho cálculo se realizará con el valor del pico anterior al primer valor nulo encontrado
(en este caso, siguiendo el ejemplo de la figura 5.10, nos referimos al pico situado en la
columna 68) y el siguiente pico (situado en la columna 71). En el caso expuesto, existen
dos valores nulos entre ambos picos, por lo tanto, la media se realizará entre el pico
significativo anterior al primer nulo y el pico posterior más próximo. En el siguiente paso,
existirá solo un valor nulo entre dos picos cuyo valor medio será introducido en el frame
con valor 0. En ambas figuras, 5.11 y 5.12 el valor rodeado es el resultado de la
interpolación y por lo tanto, su valor anterior era 0.

66
Figura 5.11 - Ejemplo de interpolación 1
Figura 5.12 - Ejemplo de interpolación 2
Es el mecanismo de construcción de trayectorias el que se encarga de almacenar
cada trayectoria construida en cada una de las filas de la matriz de trayectorias, por lo
tanto, en cada una de estas fila solo habrá almacenada una trayectoria, incompleta o no,
por lo tanto, el mecanismo de interpolación no necesita diferenciar entre fragmentos de
una misma sibilancia separados por ceros o dos fragmentos de sibilancias distintas
separadas por ceros ya que en una misma fila no habrá partes de trayectorias diferentes.
El proceso de interpolación sigue el siguiente criterio:
Si 𝑓(𝑡) = 0 ,𝑀𝑅(𝑡) ∈ 𝑉𝑡𝑟𝑎𝑦𝑒𝑐𝑡𝑜𝑟𝑖𝑎 , entonces el nuevo valor de 𝑓(𝑡) viene dado por
la expresión (33):
𝑓(𝑡) =𝑓(𝑡 − 1) + 𝑓(𝑡𝑓>0)
2 𝑡𝑓>0 ∈ ℕ
(33)
Donde 𝑡𝑓>0 es un número natural correspondiente al frame posterior a 𝑡 cuyo valor
en frecuencia o en amplitud es mayor que 0. Es considerado el frame que conforma uno
de los extremos del fragmento de trayectoria incompleto consecutivo a 𝑡. El otro extremo
corresponde a 𝑡 − 1 dentro de la matriz de trayectorias. Por lo tanto, la expresión 33
refleja la media aritmética realizada entre los extremos de la discontinuidad en la
trayectoria a interpolar. El resultado obtenido será asignado a 𝑓(𝑡).
Con este método obtenemos finalmente trayectorias completas listas para ser
analizadas en el siguiente bloque de nuestro software. Mediante el cálculo de la duración

67
temporal de las agrupaciones y la frecuencia media de los picos que componen las
trayectorias, se decidirá si éstas son sibilancias o no según los criterios definidos en
apartados anteriores. En las figuras 5.13 y 5.14 podemos observar la diferencia existente
entre las trayectorias sin interpolar y las interpoladas, observando una de ellas antes y
después de ser completada. Ambos ejemplos han sido extraídos de la señal de audio
"6025.wav".
Figura 5.13 - Zoom sobre una trayectoria sin interpolar para "6025.wav"

68
Figura 5.14 - Zoom sobre una trayectoria interpolada para "6025.wav"
En las figuras 5.15 y 5.16 se mostrará el mismo proceso de interpolación pero
esta vez aplicado al segundo audio utilizado para mostrar la implementación de cada una
de los bloques del software, "Wheeze-Bronchiolitis2.wav" con una ventana de 512
muestras.

69
Figura 5.15 - Zoom sobre una trayectoria sin interpolar para "Wheeze-Bronchiolitis2.wav"
Figura 5.16 - Zoom sobre una trayectoria interpolada para "Wheeze-Bronchiolitis2.wav"

70
5.2.5 Etapa 5: clustering de sibilancias
Como ya se definió anteriormente, una sibilancia debe tener una duración mínima
temporal de 250 ms [6] y ha de tener una frecuencia fundamental comprendida entre los
125 Hz y 375 Hz para el caso de un niño [5] o superior a 400 Hz si el paciente es un
adulto [6]. Es en esta parte del algoritmo donde se comprueba que dichos parámetros
correspondientes a las trayectorias verifican estas características. Para ello,
estudiaremos una por una cada agrupación contenida en las matrices ("trayectorias" y
"trayectorias_frecuencia").
En primer lugar, tomaremos cada una de las filas de estas matrices y buscaremos
los valores superiores a 0, los cuales se corresponderán con los picos originales y los
interpolados mediante el método anteriormente descrito. Tras esto, calcularemos el
número de picos que existen por trayectoria, es decir, el número de frames ocupados por
picos para así obtener el valor de la duración temporal de la trayectoria estudiada.
Seguidamente, calcularemos una media ponderada entre los valores en frecuencia de
todos los picos contenidos en esa misma trayectoria, ayudándonos de los valores
almacenados en la matriz "trayectorias_frecuencia". Una vez obtenido el valor medio en
frecuencia de los picos que componen la agrupación, procedemos a comparar tanto la
duración temporal como dicha media con la duración mínima de una trayectoria y los
rangos en frecuencia establecidos. Toda trayectoria que no cumpla los requisitos, será
eliminada. El usuario previamente ha podido seleccionar el tipo de paciente al que
corresponde el audio para poder elegir un rango de frecuencias u otro con el que
comparar estos parámetros. Un ejemplo de las trayectorias que prevalecen tras la
selección es mostrado en la figura 5.17, para el fichero "6025.wav". Por otro lado, en la
figura 5.18, podemos apreciar las trayectorias que no son descartadas, consideradas
sibilancias para el audio "Wheeze-Bronchiolitis2.wav".

71
Figura 5.17 - Zoom sobre las trayectorias consideradas sibilancias para "6025.wav".
Figura 5.18 - Zoom sobre las trayectorias consideradas sibilancias para "Wheeze-Bronchiolitis2.wav".
Podemos apreciar como un conjunto de trayectorias ha sido eliminado mediante el
algoritmo de selección, manteniendo en dos nuevas matrices ("sibilancias" y

72
"sibilancias_frecuencia") los valores de energía y frecuencia de las sibilancias o
trayectorias que han cumplido las características indicadas. Dichas matrices tienen la
misma estructura que la presentada anteriormente en "trayectorias" y
"trayectorias_frecuencia", es decir, están compuestas por tantas columnas como frames
haya y tantas filas como sibilancias se hayan detectado.
Hasta este punto, el algoritmo ha cumplido la función de detectar o no sibilancias
en el audio analizado. En el caso de que existan sibilancias, el algoritmo procederá a
comprobar de que tipo son, monofónicas o polifónicas, mediante el siguiente bloque:
detector de armónicos.
5.2.5.1 Armonicidad
Como ya se ha mencionado, esta sección del código se encarga de obtener el
número de armónicos que existen en las sibilancias detectadas, de nuevo, en el caso de
que existan en el audio. Si el algoritmo no detecta armónicos, entonces se considerará
que las sibilancias son monofónicas, siendo el caso contrario la detección de armónicos y
catalogando las sibilancias como polifónicas.
Consideramos que un sonido es armónico si está formado por la superposición o
suma de ondas sinusoidales con distintas frecuencias, todas ellas múltiplo de la
frecuencia fundamental. Estas ondas son denominadas armónicos. Por esta razón, un
sonido armónico, al ser representado en un espectrograma, mostrará componentes en
frecuencias excitadas múltiplo o casi múltiplo de la frecuencia fundamental (f, 2f, 3f, etc.
siendo f la frecuencia fundamental de la onda sonora) [26]. A continuación, en la figura
5.19 se muestra el análisis espectral de una onda armónica:
Figura 5.19 – Espectro de una onda cuadrada de amplitud 1 dB y frecuencia 100 Hz con armónicos impares [26].
Como podemos observar, la frecuencia más baja de entre las que se compone la
onda es la denominada como fundamental, a partir de la cual surgen otras frecuencias
múltiplos o casi múltiplos enteros. En el caso expuesto, la onda estará compuesta por la
frecuencia fundamental situada en 100 Hz y por componentes en frecuencias múltiplos
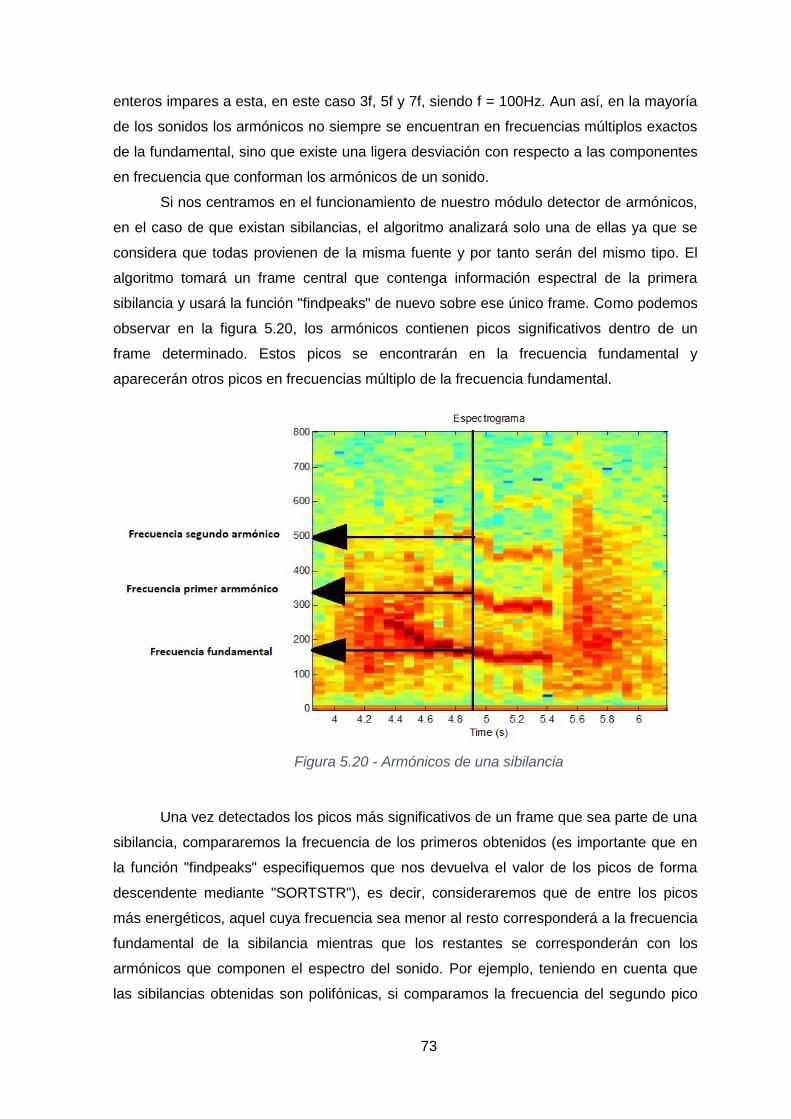
73
enteros impares a esta, en este caso 3f, 5f y 7f, siendo f = 100Hz. Aun así, en la mayoría
de los sonidos los armónicos no siempre se encuentran en frecuencias múltiplos exactos
de la fundamental, sino que existe una ligera desviación con respecto a las componentes
en frecuencia que conforman los armónicos de un sonido.
Si nos centramos en el funcionamiento de nuestro módulo detector de armónicos,
en el caso de que existan sibilancias, el algoritmo analizará solo una de ellas ya que se
considera que todas provienen de la misma fuente y por tanto serán del mismo tipo. El
algoritmo tomará un frame central que contenga información espectral de la primera
sibilancia y usará la función "findpeaks" de nuevo sobre ese único frame. Como podemos
observar en la figura 5.20, los armónicos contienen picos significativos dentro de un
frame determinado. Estos picos se encontrarán en la frecuencia fundamental y
aparecerán otros picos en frecuencias múltiplo de la frecuencia fundamental.
Figura 5.20 - Armónicos de una sibilancia
Una vez detectados los picos más significativos de un frame que sea parte de una
sibilancia, compararemos la frecuencia de los primeros obtenidos (es importante que en
la función "findpeaks" especifiquemos que nos devuelva el valor de los picos de forma
descendente mediante "SORTSTR"), es decir, consideraremos que de entre los picos
más energéticos, aquel cuya frecuencia sea menor al resto corresponderá a la frecuencia
fundamental de la sibilancia mientras que los restantes se corresponderán con los
armónicos que componen el espectro del sonido. Por ejemplo, teniendo en cuenta que
las sibilancias obtenidas son polifónicas, si comparamos la frecuencia del segundo pico

74
obtenido de forma descendente y coincide con el doble de la frecuencia fundamental
(frecuencia del primer pico) con un margen del 20% (como ya se ha mencionado, un
sonido no suele presentar armónicos múltiplos exactos de la frecuencia fundamental, por
lo que se ha decidido aplicar este margen tras realizar varias pruebas), entonces
consideraremos que esta sibilancia al menos tiene un armónico. De forma sucesiva, si
obtenemos la frecuencia del tercer pico obtenido y coincide con el triple de la frecuencia
fundamental más o menos el margen establecido, entonces el número de armónicos
detectado se incrementará en uno. De esta manera, analizaremos la frecuencia de todos
los picos obtenidos hasta encontrar aquellos que coincidan con la frecuencia
correspondiente a los armónicos, si los hay.
Finalmente, tras el conteo de armónicos detectados, el algoritmo decidirá si las
sibilancias detectadas son consideradas polifónicas o monofónicas. El usuario podrá
observar a partir de la interfaz, el número de sibilancias detectadas, el tipo al que
pertenecen y el número de armónicos que contengan las sibilancias, en el caso de que
estas sean polifónicas. Además, el usuario podrá elegir que ver en el apartado de
representación visual, desde el espectrograma original de la señal de audio, hasta una
representación de los picos que forman las sibilancias, pasando por el proceso de
creación de trayectorias y su posterior interpolación.

75
6 EVALUACIÓN
En este apartado, nos dispondremos a comprobar el comportamiento de nuestro
software bajo diferentes circunstancias y muestras de audio recogidas de diferentes
fuentes. Para ello, dividiremos esta sección en dos fases: optimización y testeo. Gracias
al uso de diferentes métricas que serán definidas más adelante, podremos evaluar el
comportamiento frente a diferentes configuraciones de nuestro programa detector de
sibilancias, es decir, en función de los resultados obtenidos, tendremos en cuenta un
conjunto de métricas con las que obtendremos ciertas conclusiones acerca de la
eficiencia del software.
En primer lugar, para llevar a cabo esta fase de pruebas, nuestro software
principal será sometido a una fase de optimización cuya fin es el de realizar múltiples
iteraciones utilizando distintas combinaciones de parámetros de entrada que harán que el
detector de sibilancias desempeñe su función de manera más o menos adecuada. Tras
estas pruebas podremos llegar a la conclusión de cuál es la combinación óptima de
parámetros de entrada para nuestro software, es decir, que instrucciones para su
ejecución sacan el máximo rendimiento para obtener los resultados más precisos.
Una vez realizada la fase de optimización, se llevará a cabo una fase de testeo,
en este caso dividida en dos partes diferentes (testeo I y testeo II). El propósito de esta
sección de la evaluación es el de observar el comportamiento de nuestro software en
situaciones aleatorias o al menos pseudoaleatorias lo más similares posibles a casos de
detección de sibilancias en pacientes reales.
En cada una de las fases de evaluación se utilizará una base de datos de audio
independiente para cada una de las pruebas. Además, utilizaremos métricas adecuadas
para la cuantificación de resultados una vez realizada cada una de las etapas de
evaluación.
6.1 Base de datos.
En primer lugar, insistiremos en la dificultad que ha supuesto el hecho de reunir
una cantidad determinada de muestras de audios con sibilancias para la realización de
este apartado. La gran mayoría de documentos consultados realizan sus pruebas
mediante librerías o bases de datos de audio de pago o privadas, donde se encuentran
muestras grabadas en buenas condiciones e incluso filtradas y tratadas digitalmente para
eliminar ruido de respiración y latidos del corazón, según indican en su desarrollo. Por
otra parte, otras investigaciones han sido llevadas a cabo mediante la grabación de
audios propios, seleccionando un grupo de pacientes de diversas edades y realizando las
grabaciones pertinentes mediante determinados aparatos captadores de sonido. En estos

76
casos, los equipos de investigación no suelen ofrecer sus propias bases de datos de
audio y en el caso de que sea así, se ofrecen a cambio de cierta cantidad de dinero.
Existen sitios webs como [17], [18], [19] y [20] donde se ofrecen una reducida
cantidad de muestras de audio con sibilancias para la demostración de diferentes
anomalías pulmonares que un médico puede encontrarse al auscultar un paciente.
Nosotros hemos tomado dichas muestras de carácter demostrativo para ver el
comportamiento de nuestro software en diferentes situaciones y audios. En otras páginas
webs no es posible realizar la descarga del audio, limitándose a la reproducción de este
desde la propia página. En diferentes sitios webs, las muestras de audio que se ofrecen
contienen gran cantidad de ruido de fondo y de baja frecuencia (debido a que no han sido
filtrados) y por lo tanto, supone la aparición de muchos espurios a la hora de obtener
picos significativos en el proceso de detección de sibilancias.
Todos los audios utilizados en las siguientes bases de datos han sido
muestreadas a 8000 Hz.
6.1.1 Base de datos de optimización
Debido a la problemática expuesta al inicio de esta sección, se ha decidido
realizar la fase de optimización con 4 muestras de audios que en total contienen hasta 15
sibilancias (tres audios contienen 4 sibilancias y un cuarto contiene solo 3). A
continuación, se indica el nombre de cada uno de los audios utilizados, su duración y el
número de sibilancias que contienen:
- "6025.wav" [18]: duración de 10.15 s, contiene 4 sibilancias.
- "Wheeze-Bronchiolitis2.wav" [17]: duración de 5 s, contiene 4 sibilancias.
- "144Post3L.wav" [19]: duración de 10.76 s, contiene 4 sibilancias.
- "143Post7R.wav" [19]: duración de 7.81 s, contiene 3 sibilancias.
Cada una de las sibilancias contenidas en las respiraciones tiene una duración
aproximada de 1 s.
6.1.2 Base de datos de testeo I
Para la primera fase de testeo se ha decidido combinar de forma pseudoaleatoria
cada una de las sibilancias utilizadas en la fase de optimización con un audio que
contiene una respiración vesicular normal. El audio que contiene dicha respiración tiene
las siguientes características.
- "respiracion.wav" [18]: procedente de una respiración vesicular producida por
un paciente sano, sin sonidos adventicios añadidos, con una duración de 8.1 s
aproximadamente. Contiene tres inspiraciones y tres espiraciones.

77
El proceso de creación de la base de datos para la primera fase de testeo es la
siguiente:
- En primer lugar, procedemos a extraer cada una de las sibilancias contenidas
en los audios expuestos en la sección 6.1.1 cuya duración aproximada es de 1
segundo para cada una. En total, obtenemos 15 archivos .wav que contienen
cada una de estas 15 sibilancias por separado. Serán nombradas como
"sib1.wav","sib2.wav", etc. hasta "sib15.wav".
- La mezcla con la respiración normal se realizará de forma pseudoaleatoria, es
decir, mediante un proceso aleatorio llevado a cabo en Matlab (uso del
comando "rand") se elegirá una de las tres inspiraciones dentro del audio
"respiracion.wav" en la que se mezclará una de las sibilancias de tal modo que
quede adherida a la respiración sana. De este modo, conseguiremos crear una
respiración con un sonido adventicio superpuesto a una de las inspiraciones.
- El nivel de señal con el que se realizará la mezcla también es aleatorio,
existiendo tres posibilidades: diferencia de potencia entre sibilancia y señal de
respiración de -5, 0 o +5 dB. De este modo, la sibilancia puede quedar
enmascarada por la respiración vesicular en mayor o menor medida según el
caso que se lleve a cabo de forma aleatoria.
- Este proceso generará 15 archivos de audio de duración 8.1 s
correspondientes a la mezcla pseudoaleatoria llevada a cabo con cada una de
las 15 sibilancias que han sido posible extraer. Cada uno de estos audios,
como se ha indicado, contendrá una sibilancia situada de forma aleatoria en
una de las tres inspiraciones contenidos en el audio de respiración vesicular
con una diferencia de señal aleatoria comprendida entre los valores indicados
en el guion anterior. Cada uno de los audios generados en el proceso se
denominarán "muestra1.wav", "muestra2.wav", etc. hasta "muestra15.wav".
En las siguientes figuras (6.1, 6.2 y 6.3) podemos observar el proceso de mezcla
de sibilancias sobre el audio "respiración.wav", el cual contiene las muestras de audio
que componen la respiración vesicular normal sobre la que se construirán las muestras
pseudoaleatorias.

78
Figura 6.1 – Sibilancia número dos (sib2.wav) que se extrae del audio "6025.wav"
Figura 6.2 – Espectrograma de la respiración vesicular normal "respiracion.wav".
Las inspiraciones y espiraciones del audio "respiración.wav" se encuentran
situadas entre los segundos 0.5 y 2, 3 y 4.5, 6 y 7.5 aproximadamente.
Time (s)
Fre
quency (
Hz)
Espectrograma
0 1 2 3 4 5 6 7 80
500
1000
1500
2000
2500
3000
3500
4000

79
Figura 6.3 – Resultado de la suma de "sib2.wav" sobre la segunda inspiración de "respiracion.wav" con una diferencia de potencia de 5dB.
El resultado obtenido en este ejemplo se ha denominado "muestra2.wav" ya que
contiene la suma sobre la respiración normal de la sibilancia número dos, perteneciente a
"6025.wav".
6.1.3 Base de datos de testeo II
Como hemos podido observar, en la fase anterior solo se generan 15 muestras de
audio pseudoaleatorias con las que poder realizar la primera fase de testeo. El método
utilizado es poco robusto ya que no genera una gran cantidad de casos con los que poder
obtener datos fiables en nuestra fase de pruebas, por lo tanto, se ha decidido proceder a
crear una nueva base de datos de audio que genere hasta 165 muestras de audio con las
que poder llevar a cabo las pruebas pertinentes.
La base de datos consta de los siguientes archivos:
- "sib1.wav","sib2.wav", etc. hasta "sib15.wav" los cuales contienen cada una de
las 15 sibilancias también utilizadas en la fase de testeo I. Proceden de los
audios indicados en el apartado 6.1.1 y de nuevo la duración aproximada de
cada audio es de 1 s.
- "respiracion1.wav", "respiración2.wav", etc. hasta "respiración11.wav": cada
uno de estos audios tiene una duración aproximada de 2 segundos y se

80
corresponde con cada una de las inspiraciones contenidas en los siguientes
audios, obtenidas a partir de [17], [18] y [20]:
o "Coarse crackles.wav": contiene 5 inspiraciones con crepitantes con
una duración de 12.1 s
o "respiracion.wav": audio utilizado en la base de datos de testeo I,
contiene 3 inspiraciones y tiene una duración de 8.1 s.
o "wisppect.wav": contiene 3 inspiraciones y tiene una duración de 6.2 s.
En esta nueva base de datos más robusta se generarán hasta 165 muestras con
las que llevar a cabo la segunda fase de testeo. El proceso de creación de estas
muestras es muy similar al utilizado anteriormente:
- En primer lugar, separaremos cada una de las 11 inspiraciones contenidas en
los audios de respiración mencionados anteriormente, generando los archivos
"respiración1.wav" hasta "respiración5.wav" mediante las 5 inspiraciones de
"Coarse crackles.wav", "respiración6.wav" hasta "respiración8.wav" mediante
las 3 inspiraciones contenidas en "respiracion.wav" y "respiración9.wav" hasta
"respiración11.wav" a partir de las 3 inspiraciones generadas en
"wisppect.wav".
- Cada una de las muestras de respiración obtenidas se mezclará con todas y
cada una de las 15 sibilancias extraídas en la fase de testeo I, utilizando
diferentes niveles de señal entre sibilancia y respiración (proceso
pseudoaleatorio). Lo cual quiere decir que el audio "respiración1.wav"
correspondiente a una inspiración será mezclado en 15 ocasiones distintas.
De forma similar, las 10 inspiraciones restantes serán mezcladas con las 15
sibilancias existentes.
- Finalmente se obtienen 165 (11 x 15) casos de respiración con sibilancias con
el que poder llevar a cabo el proceso de testeo II.
Además de contener 150 casos adicionales con respecto a la de testeo I, esta
base de datos también contempla ciertos casos con sonidos interferentes, como son los
crepitantes contenidos en las inspiraciones de "Coarse crackles.wav". Es por ello que
existirán casos en los que las sibilancias serán mezcladas con otros sonidos adventicios,
haciendo aún más robusta esta base de datos.

81
6.2 Métricas
La evaluación de nuestro software se realizará a dos niveles: a nivel de frame y a
nivel de evento. En primer lugar, el estudio a nivel de frame conlleva una evaluación de
resultados centrada en cada uno de los frames que componen las sibilancias detectadas,
es decir, se estudiará la presencia o ausencia de cada uno de los picos significativos que
componen las sibilancias. En cambio, la evaluación a nivel de evento estudiará la
presencia o no de sibilancias completas, es decir, se evaluarán los frames que contengan
o no sibilancias pero esta vez teniéndolos en cuenta como un conjunto o evento. Mientras
que en la evaluación a nivel de frame nos limitaremos a observar de forma individual
cada uno de los frames que conforman las sibilancias, a nivel de evento nos centraremos
en la sibilancia como conjunto de frames teniendo en cuenta parámetros como el instante
de inicio y final de las sibilancias dentro del espectrograma.
En primer lugar, para el análisis frame a frame, debemos definir tres valores con
los que trabajaremos y obtendremos dichas métricas:
True Positive (TP): se obtendrá cuando nuestro software determine que un
frame contiene un valor perteneciente a una sibilancia y realmente sea así.
False Positive (FP): si el detector de sibilancias determina que cierto frame
es parte de una sibilancia pero realmente no lo es, obtendremos un falso
positivo.
False Negative (FN): cuando nuestro software muestra un frame en el cual
no se ha encontrado valor alguno que pertenezca a una sibilancia pero en
realidad sí existe, se obtiene un falso negativo.
En cada una de las evaluaciones en las que se pondrá a prueba el software, se
recogerá la cantidad de TP, FP y FN en total para cada uno de los resultados. A partir de
estos valores tomados, se calcularán las siguientes métricas extraídas de la tesis doctoral
[25]:
Exhaustividad: viene dado por el cociente entre el número de frames
correctamente detectados (TP) y la suma entre falsos negativos y
verdaderos positivos. Se muestra en la expresión (34).

82
𝐸𝑥ℎ𝑎𝑢𝑠𝑡𝑖𝑣𝑖𝑑𝑎𝑑 =𝑇𝑃
𝑇𝑃 + 𝐹𝑁
(34)
Exactitud: se define como el cociente entre frames correctamente
detectados y la suma entre TP y FP. Queda reflejada en la expresión (35).
𝐸𝑥𝑎𝑐𝑡𝑖𝑡𝑢𝑑 =𝑇𝑃
𝑇𝑃 + 𝐹𝑃
(35)
Precisión: cociente entre el número de frames bien detectados y la suma
de todos los parámetros anteriormente definidos. Se muestra en la
ecuación (36).
𝑃𝑟𝑒𝑐𝑖𝑠𝑖ó𝑛 =𝑇𝑃
𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁
(36)
A nivel de evento o sibilancia, usaremos los siguientes parámetros, también
extraídos de [25]:
Error de substitución: indica el número de sibilancias detectadas
erróneamente. Este error sucede cuando se detecta una sibilancia pero
sus límites de inicio y final no coinciden de forma aproximada con los
reales.
Error de pérdidas: indica el número de sibilancias que no han sido
detectadas.
Error de falsa alarma: indica el número de sibilancias detectadas que
realmente no existen.
Puede existir confusión entre el error de substitución o el de falsa alarma, por lo
que destacaremos la principal característica que los diferencia de forma clara: mientras

83
que un error de substitución refleja la detección de una sibilancia que realmente existe
aunque los límites de inicio y final de esta no coinciden con los de la sibilancia a detectar,
el error de falsa alarma se produce cuando nuestro software detecta un evento o
sibilancia donde realmente no lo hay, por lo tanto, se asemeja a un falso positivo a nivel
de sibilancia. Es por esto por lo que un error de falsa alarma puede ser más grave que
uno de substitución.
6.3 Fase de optimización
Para llevar a cabo esta fase de pruebas, nuestra función principal, la cual contiene
las líneas de código de nuestro software, será ejecutada hasta 81 veces en una serie de
bucles anidados con el fin de variar ciertos parámetros en la configuración de entrada del
software principal. En cada una de las 81 ejecuciones, se recogerán los datos de salida
obtenidos, a partir de los cuales se obtendrán un conjunto de métricas con las que
podremos definir el comportamiento de del programa en cada una de esas 81
situaciones. Los parámetros que varían en cada ejecución son los siguientes:
Tamaño de ventana: las pruebas se realizarán mediante el cálculo de las
STFT con ventanas de 512, 1024 y 2048 muestras [5]. Como sabemos, a
menor tamaño de ventana, más resolución temporal (obtendremos más
frames), pero disminuirá la resolución en frecuencia.
Lejanía en frecuencia: este parámetro está relacionado con la construcción
de trayectorias, por lo que se considerará que dos picos cercanos en
tiempo pertenecerán a la misma trayectoria si su lejanía en frecuencia no
supera los ±30, ±50 o ±100 Hz de margen según el caso que se esté
evaluando. Estos valores han sido extraídos de [14], donde se menciona
que un rango de ±30 Hz confiere mejores resultados que el resto de
márgenes.
Lejanía en tiempo: de nuevo, este parámetro también está directamente
relacionado con la construcción de trayectorias, por lo tanto, dos picos
significativos cercanos en frecuencia pertenecerán a la misma trayectoria
si su lejanía en tiempo no supera los 30, 50 o 100 ms [15].
Duración mínima de una sibilancia: como se ha podido ver en el estado del
arte (apartado 4), muchos estudios definen de forma distinta la duración

84
mínima de una sibilancia, por lo tanto, comprobaremos los resultados en
diferentes muestras de audio con diferentes valores mínimos de duración
temporal de sibilancias. Estos valores se corresponden con 80, 100 y 250
ms [6].
Vemos que existen cuatro parámetros que variarán a lo largo de las pruebas
realizadas. Cada uno de ellos puede tomar 3 valores distintos, por lo tanto, como se ha
mencionado antes, existirán 34 posibles combinaciones de los parámetros de entrada (81
en total) en las cueles se analizará el resultado obtenido y se cuantificará mediante un
conjunto de métricas definidas en el apartado 6.2.
Para llevar a cabo esta fase, usaremos la función "optimización.m" y
"optimización_frame.m" para realizar el estudio tanto a nivel de evento como a nivel de
frame, respectivamente.
Como ya se ha mencionado, nuestro programa "principal.m" será sometido a un
conjunto de bucles anidados donde se introducirán diferentes valores de entrada para un
conjunto de 4 parámetros nombrados al inicio de este apartado. En cada iteración, las
sibilancias detectadas se comprobarán tanto a nivel de frame como a nivel de evento en
busca de parámetros como TP, FP, FN, etc. A partir de estos parámetros obtenidos con
cada una de las combinaciones de datos de entrada posibles, se decidirá cuál es la
configuración que mejores resultados arroja en nuestro programa principal.
6.3.1 Optimización a nivel de frame
Este proceso se lleva a cabo comprobando cada uno de los frames del
espectrograma. En primer lugar, observando la representación en frecuencia y tiempo de
la señal original con sibilancias, indicaremos los frames de inicio y final de cada una de
las sibilancias contenidas con el fin de crear un vector que contenga unos y ceros. Este
vector tendrá una fila y tantas columnas como frames contenga el espectrograma,
indicando con un 1 aquellos frames que contengan un pico de sibilancia, por otro lado,
con un 0 se indicará aquel frame que no contenga un pico significativo perteneciente a
una sibilancia. Como sabemos, el número total de frames contenidos en un
espectrograma depende de forma directa con el número de muestras que abarque la
ventana utilizada, por lo tanto, debemos indicar el inicio y final de cada sibilancia para
cada una de las ventanas utilizadas, en este caso 3. El vector creado se denomina
"patrón" ya que contiene la localización verdadera de cada una de las sibilancias que hay
en el audio y sirve para realizar la comprobación con los resultados obtenidos en cada
iteración sobre el programa principal.

85
A continuación, comienzan a actuar cada uno de los bucles anidados que variarán
los parámetros de entrada del programa principal. En cada iteración, obtendremos un
número de sibilancias y como consecuencia, una matriz que las contiene. Sus
dimensiones dependen del número de sibilancias detectadas, es decir, existirán tantas
filas como sibilancias se detecten y tantas columnas como frames tenga el
espectrograma. Seguidamente, una vez detectadas, se normalizará esta matriz para
obtener unos y ceros (en este caso, en vez de ceros obtendremos NaN o "Not a
Number") en los frames donde supuestamente existan o no picos de sibilancias, esto nos
permitirá pasar a la siguiente fase, donde se comprobará cada uno de los frames de esta
matriz con los del patrón anteriormente mencionado. Si a la hora de comprobar un frame
se observa que realmente existe una sibilancia y el programa devuelve dicho frame
marcado con un uno, entonces obtendremos un TP o verdadero positivo. Si la salida del
programa principal muestra un uno en un frame determinado donde el vector patrón
contiene un 0, se obtendrá un FP o falso positivo. Por último, si en un frame determinado,
el patrón indica que existe un pico de una sibilancia, mediante un uno, pero nuestro
programa devuelve un 0 en dicho frame, diremos que existe un FN o falso negativo. A
continuación se expone un ejemplo sencillo reflejado mediante las figuras 6.4 y 6.5:
Figura 6.4 - Fragmento del vector usado como patrón para una ventana de 512 muestras
Figura 6.5 - Fragmento del vector de sibilancias devuelto por el programa principal para una ventana de 512 muestras
En dicho ejemplo observamos como en los frames 17, 18, 19 y 25 existen picos
de sibilancias según el patrón, pero nuestro programa no ha sido capaz de detectarlos,
por lo tanto, obtendremos 4 falsos negativos.
Tras el conteo del número de TP, FN y FP existentes, se procederá a realizar el
cálculo de las métricas indicadas anteriormente para obtener una descripción en forma de
porcentajes del comportamiento del programa en la iteración actual. De nuevo, se
reiniciarán las variables para continuar con el siguiente paso en los bucles anidados,
sometiendo al programa principal a otra combinación de parámetros de entrada con el

86
que poder realizar de nuevo la comparación con los patrones indicados al inicio. En cada
una de las iteraciones, los datos obtenidos se almacenarán en una matriz que contenga
los siguientes parámetros con el siguiente orden:
Fila 1: muestras que contiene la ventana.
Fila 2: rango en frecuencia para la obtención de trayectorias.
Fila 3: rango en tiempo para la obtención de trayectorias.
Fila 4: duración mínima de una sibilancia.
Fila 5: verdaderos positivos.
Fila 6: falsos positivos.
Fila 7: falsos negativos.
Fila 8: exhaustividad.
Fila 9: exactitud.
Fila 10: precisión.
Fila 11: número de sibilancias detectadas.
Como vemos, las 4 primeras filas indican los parámetros de entrada en cada
iteración, mientras que el resto muestra resultados obtenidos a partir de estos cuatro
parámetros. Hay que remarcar el hecho de que tanto las filas 8, 9 y 10 se expresan con
valores comprendidos entre 0 y 1, al multiplicarlos por 100, obtenemos el tanto por ciento
equivalente. La matriz tendrá tantas columnas como iteraciones se hayan realizado, en
este caso 81. A continuación, en la figura 6.6, se muestra un ejemplo de esta matriz de
datos:
Figura 6.6 - Ejemplo de la tabla de datos tras la fase de optimización a nivel de frame.
Estas tablas son almacenadas en un fichero .mat cuyo nombre se indica de la
siguiente forma: "datos_audio_NombreArchivoAudio_frame.mat", como por ejemplo

87
"datos_audio_6025.mat" para las pruebas realizadas con "6025.wav". Cada uno de los 4
audios estudiados devolverá un archivo con la misma estructura y con un nombre con la
estructura indicada. Si se cargan estos archivos en Matlab, podremos observar cada una
de las tablas obtenidas en la fase de optimización.
Es ahora cuando debemos observar los resultados obtenidos y tomar las
siguientes conclusiones:
Las pruebas realizadas con una ventana de 512 muestras arrojan resultados
significativamente peores con respecto al resto de pruebas realizadas con otras
ventanas. Al existir una amplia resolución temporal, es crucial elegir de forma correcta el
resto de parámetros para que la detección sea lo más exacta posible. Un exceso de
resolución conlleva a una mayor probabilidad de detectar mal las sibilancias, o no hacerlo
de la forma más certera posible. Observamos un porcentaje de precisión bajo con
respecto al resto de ventanas, lo cual nos indica que la cantidad de falsos positivos en
este caso es alta. De nuevo, esto se debe a un exceso de resolución temporal por lo
tanto, un rango en tiempo excesivamente alto, como por ejemplo 100 ms, permite abarcar
más muestras a la hora de construir trayectorias y por lo tanto la tasa de falsos positivos
aumenta. También observamos que si la duración mínima para definir una sibilancia es
pequeño, como por ejemplo 80 ms, existe la posibilidad de que más trayectorias superen
este umbral y sean consideradas sibilancias sin serlo, por ello, de nuevo la tasa de falsos
positivos aumenta. Por otro lado, podemos observar como un exceso en la amplitud del
rango en frecuencia obtenido hace crecer de forma significativa el número de falsos
negativos, esto es debido a que, a la hora de construir las trayectorias, las muestras
incluidas en cada agrupación pueden tener valores en frecuencia muy distantes entre sí,
pudiendo abarcar picos que excedan o no alcancen los niveles mínimos y máximos,
aumentando o disminuyendo la frecuencia media de la trayectoria, obligando a
descartarlas cuando no debería ser así.
Por el contrario, el uso de una ventana de 2048 muestras implica una menor
resolución temporal, lo cual nos presenta un problema totalmente opuesto al anterior,
pero con consecuencias similares. La aparición de un alto número de falsos positivos
debido a que la construcción de trayectorias no es eficiente y se realiza con poca
precisión, abarcando demasiadas muestras que no pertenecen a sibilancias. También
observamos que existen pocas diferencias en los resultados obtenidos al variar los
parámetros de resolución en tiempo y duración mínima. La poca resolución temporal
implica muy poca variación en el comportamiento del programa al modificar estos
parámetros.
Por último, llegamos a la conclusión de que una ventana que abarque 1024
muestras puede ajustarse mejor a este propósito, obteniendo por lo general porcentajes

88
más altos en los cálculos de las métricas. Un exceso o defecto de resolución temporal y
en frecuencia ofrecidos por las ventanas de 512 y 2048 supone, por lo tanto, un bajo
rendimiento en el funcionamiento de nuestro detector de sibilancias aportando un exceso
de falsos negativos y falsos positivos indeseados en la obtención de trayectorias.
Centrándonos en el resto de parámetros:
Rango en frecuencia para la obtención de trayectorias: para una ventana
de 1024 muestras interesa ser introducido en los parámetros de entrada de
nuestro software con un valor bajo debido a que un exceso de amplitud a
la hora de abarcar muestras con valores en frecuencia muy distantes
puede ocasionar un aumento o disminución excesiva de la frecuencia
media de la trayectoria construida, haciendo que esta quede descartada
por no alcanzar o sobrepasar los límites establecidos para ser
consideradas sibilancias.
Rango en tiempo para la obtención de trayectorias: por los resultados
obtenidos, interesa un valor intermedio a los propuestos, un exceso en la
amplitud de este parámetro puede ocasionar la construcción de
trayectorias excesivamente largas temporalmente hablando que abarquen
picos no pertenecientes a sibilancias, obteniendo un exceso de falsos
positivos. Por otro lado, una amplitud pequeña asignada a este valor
puede ocasionar el efecto contrario, la aparición de trayectorias
excesivamente pequeñas que no superen el umbral mínimo de duración
temporal. Puede ocurrir el hecho de que varias trayectorias de corta
duración sean desechadas por no superar el umbral temporal establecido,
aunque realmente, en conjunto, sean componentes de una sibilancia real,
es decir, puede darse el caso de que una sibilancia quede segmentada en
pequeñas trayectorias y no sea detectada. Por lo tanto, un valor pequeño
asignado al rango en tiempo puede ocasionar un aumento en el número de
falsos negativos.
Duración mínima de sibilancia: observamos que para este parámetro,
interesa un valor alto, es decir, debemos definir un umbral temporal alto
con el fin de evitar la aparición de un excesivo número de falsos positivos
ya que si interponemos un pequeño umbral, la probabilidad de que un
excesivo número de trayectorias indeseadas sean consideradas como
sibilancias aumenta.
Por lo tanto, los parámetros a partir de los cuales obtenemos los mejores
resultados en cuanto a las métricas calculadas coinciden con la bibliografía consultada

89
([14] y [15]), verificando con nuestros resultados las conclusiones y decisiones tomadas
en estos documentos. Por lo tanto, en esta fase hemos decidido que la mejor
configuración es la siguiente:
Tamaño de ventana de 1024 muestras.
Resolución en frecuencia de 30 Hz.
Resolución temporal de 50 ms.
Duración mínima de sibilancia de 250 ms.
A continuación, se muestra una tabla con los resultados obtenidos en pruebas
realizadas con uno de los audios que conforman la base de datos de optimización, el cual
contiene hasta 4 sibilancias, utilizando una ventana de 1024 muestras y variando el resto
de parámetros de forma aproximada para observar la mejora de rendimiento en software
con la configuración anterior. La frecuencia de muestreo del audio utilizado es de 8000
Hz:
Muestras
ventana 1024 1024 1024 1024 1024
Rango
frecuencia 30 30 30 30 30
Rango tiempo 30 50 50 50 100
Duración
mínima 250 80 100 250 80
TP 63 63 63 63 63
FP 0 5 5 0 5
FN 14 14 14 14 18
Exhaustividad 0.8182 0.8182 0.8182 0.8182 0.7662
Exactitud 1 0.9565 0.9565 1 0.9219
Precisión 0.8182 0.7683 0.7683 0.8182 0.7195
Número de
sibilancias
detectadas
4 6 6 4 6
Tabla 6.1 - Ejemplo de datos obtenidos en la fase de optimización a nivel de frame

90
La columna marcada en color verde muestra la mejor combinación de parámetros
junto con los resultados obtenidos. El audio analizado a partir del cual se obtuvieron estos
datos es "6025.wav" el cual contiene un total de 4 sibilancias.
6.3.2 Optimización a nivel de evento
Esta segunda fase de optimización consiste en la obtención de resultados a partir
del estudio evento a evento de la respuesta del software principal puesto a prueba en las
mismas 81 situaciones anteriores. Esta vez, compararemos las sibilancias obtenidas en
el análisis realizado con cada una de las posibles combinaciones y se compararán a nivel
de bloque (conjunto de frames que componen las sibilancias) con un conjunto de límites
impuestos previamente. Por lo tanto, a grandes rasgos, el software "optimizacion.m"
contendrá los límites temporales de las sibilancias que se encuentran en el audio
analizado, permitiendo comparar dichos límites de bloques con los que el programa sea
capaz de devolver, es decir, observaremos el inicio y final de cada sibilancia devuelta por
el programa principal y los compararemos con los límites impuestos de forma manual, los
cuales indicarán el inicio y final de las sibilancias reales.
Una vez comenzadas las pruebas, el software principal realizará su función en un
bucle anidado similar al del apartado anterior, obteniendo una matriz que contiene cada
una de las sibilancias detectadas y sus frames de inicio y fin. Se considerarán los
siguientes casos para la obtención de las métricas:
Los límites de la sibilancia analizada coinciden con los límites reales del
espectrograma original, en este caso obtendremos una sibilancia bien
detectada o verdadero positivo. Los límites se han definido en este caso
con un margen de más, menos un número de frames determinado, en
función del tamaño de ventana elegido.
La sibilancia ha sido detectada pero solo uno de los límites (inicio o final)
se encuentran en el rango establecido previamente. Es en este caso
cuando diremos que se ha cometido un error de substitución, es decir, se
ha detectado la sibilancia pero de forma incorrecta.
La sibilancia detectada tiene unos frames de inicio y fin comprendidos
ambos entre los límites impuestos, pero no se ajustan de forma
aproximada a estos. De nuevo, obtendremos un error de substitución.
Los límites de la sibilancia no encajan con ningún límite impuesto y
tampoco se encuentran en dicho rango. En este caso obtendremos un
error de falsa alarma ya que se ha detectado una sibilancia donde no
existe realmente.

91
Si alguna de las sibilancias reales no han sido detectadas por el software,
entonces se habrá cometido un error de pérdidas.
Todos estos posibles casos son analizados mediante el uso de secuencias
condicionales en el software encargado de realizar la fase de optimización. Como
resultado, obtenemos una tabla de datos parecida a la que obtenemos en el apartado
anterior. A continuación, se muestra un ejemplo mediante la figura 6.7:
Figura 6.7 - Ejemplo de la matriz de datos obtenidos tras la fase de optimización a nivel de eventos
La matriz expuesta tiene una estructura muy parecida a la obtenida en la fase de
optimización a nivel de frame:
Fila 1: muestras que contiene la ventana.
Fila 2: rango en frecuencia para la obtención de trayectorias.
Fila 3: rango en tiempo para la obtención de trayectorias.
Fila 4: duración mínima de una sibilancia.
Fila 5: número de sibilancias detectadas.
Fila 6: verdaderos positivos o sibilancias correctamente detectadas.
Fila 7: errores de substitución cometidos.
Fila 8: errores de pérdidas cometidos.
Fila 9: errores de falsa alarma cometidos
De nuevo, estas tablas serán almacenadas en archivos .mat con la nomenclatura
siguiente: "datos_audio_NombreArchivoAudio.mat". Al cargarlos, obtendremos la matriz
de datos del audio seleccionado. En el caso expuesto en la figura 6.7 se examinó el
archivo "datos_audio_6025.mat".
Debido a que este estudio puede ser menos preciso que el anterior, se ha
considerado que las mejores combinaciones de parámetros de entrada serán aquellas
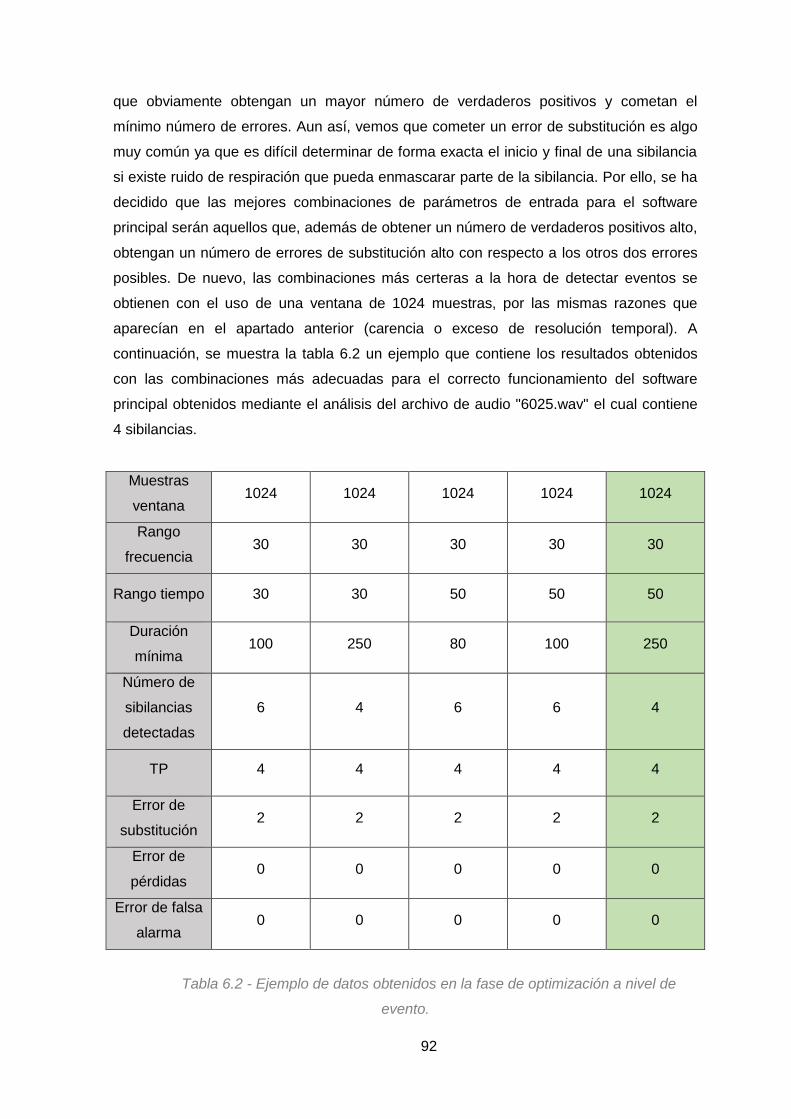
92
que obviamente obtengan un mayor número de verdaderos positivos y cometan el
mínimo número de errores. Aun así, vemos que cometer un error de substitución es algo
muy común ya que es difícil determinar de forma exacta el inicio y final de una sibilancia
si existe ruido de respiración que pueda enmascarar parte de la sibilancia. Por ello, se ha
decidido que las mejores combinaciones de parámetros de entrada para el software
principal serán aquellos que, además de obtener un número de verdaderos positivos alto,
obtengan un número de errores de substitución alto con respecto a los otros dos errores
posibles. De nuevo, las combinaciones más certeras a la hora de detectar eventos se
obtienen con el uso de una ventana de 1024 muestras, por las mismas razones que
aparecían en el apartado anterior (carencia o exceso de resolución temporal). A
continuación, se muestra la tabla 6.2 un ejemplo que contiene los resultados obtenidos
con las combinaciones más adecuadas para el correcto funcionamiento del software
principal obtenidos mediante el análisis del archivo de audio "6025.wav" el cual contiene
4 sibilancias.
Muestras
ventana 1024 1024 1024 1024 1024
Rango
frecuencia 30 30 30 30 30
Rango tiempo 30 30 50 50 50
Duración
mínima 100 250 80 100 250
Número de
sibilancias
detectadas
6 4 6 6 4
TP 4 4 4 4 4
Error de
substitución 2 2 2 2 2
Error de
pérdidas 0 0 0 0 0
Error de falsa
alarma 0 0 0 0 0
Tabla 6.2 - Ejemplo de datos obtenidos en la fase de optimización a nivel de
evento.

93
Es importante remarcar que de nuevo, la duración mínima temporal de una
sibilancia es un parámetro clave para la obtención o no de un gran número de falsos
positivos que en este caso se puede traducir en errores de falsa alarma o errores de
substitución.
Como podemos apreciar claramente, las pruebas realizadas a nivel de evento no
reflejan con gran exactitud la variación de eficiencia al combinar ciertos parámetros de
entrada en el software principal, aun así, los mejores resultados almacenados en los
archivos ".mat" se corresponden con la combinación indicada en la fase de optimización a
nivel de frame, por lo tanto, de nuevo llegamos a la conclusión de que la mejor
combinación de parámetros de entrada para nuestro programa principal es la siguiente:
Tamaño de ventana de 1024 muestras.
Resolución en frecuencia de 30 Hz.
Resolución temporal de 50 ms.
Duración mínima de sibilancia de 250 ms.
Es evidente que la siguiente fase para la obtención de resultados será realizada
con dicha combinación, la cual arroja los resultados más satisfactorios.
6.4 Testeo I
Una vez obtenida la combinación de datos de entrada óptima para un correcto
funcionamiento de nuestro programa principal según la información obtenida en la fase
de optimización, es hora de comprobar el comportamiento del programa ante situaciones
pseudoaleatorias con muestras de audio diferentes a las utilizadas en la fase anterior, es
por ello por lo que utilizaremos la base de datos de audio enfocada a esta fase (base de
datos de testeo I). En la figura 6.8 se presenta un esquema que resume las tareas
llevadas a cabo en la fase de testeo I.

94
Figura 6.8 – Esquema de la implementación de la fase de testeo I.
Los pasos a seguir en la primera fase de testeo son los siguientes:
- En primer lugar, se realizará una ejecución del programa principal con los
parámetros óptimos utilizando la primera de las muestras generadas en la
base de datos de testeo I.
- Almacenamos los resultados obtenidos en esta primera iteración, conservando
las sibilancias detectadas y los frames que las componen.
- Mediante un patrón establecido el cual ha sido creado a partir de las
sibilancias reales que se encuentran en cada una de las 15 muestras
generadas en la base de datos, se comprobarán las sibilancias obtenidas en la
ejecución del programa principal con dichos patrones. Este estudio se realiza a
nivel de frame, tal y como se hizo en la fase de optimización a nivel de frame.
- Tras la comparación, se hará un recuento de los parámetros obtenidos (TP,
FN y FP).
- Finalmente, se llevará a cabo el cálculo de las métricas expuestas en el
apartado 6.2 y se almacenarán todos los datos obtenidos en esta primera
iteración.
Como es lógico, tras la primera iteración el software procede a cambiar de
muestra, en este caso la número 2 con la que se repetirá el proceso descrito. Se
realizarán tantas iteraciones como muestras de audio genera la base de datos de testeo
I, es decir, se realizarán hasta 15 iteraciones utilizando los parámetros de entrada
óptimos en el software principal y se realizará en cada una de estas iteraciones el cálculo
de las métricas pertinentes.

95
Hay que remarcar el hecho de que la generación de la base de datos aleatoria de
audios y el propio análisis de las señales se realizan de forma automática cada vez que
ejecutemos el programa "testeo.m". A continuación, en la tabla 6.3, se muestran los
resultados finales obtenidos (en este caso se genera una matriz de datos similar a la
siguiente, almacenada en el archivo "resultados.mat"):
Muestra
1
Muestra
2
Muestra
3
Muestra
4
Muestra
5
Muestra
6
Muestra
7
Nivel de señal
(dB) 0 5 -5 5 -5 0 0
Zona insertada 1 2 2 3 2 2 2
TP 10 18 15 16 12 7 8
FP 9 5 6 6 5 5 5
FN 2 2 2 2 1 3 0
Exhaustividad 0.8333 0.9 0.8824 0.8889 0.9231 0.7 1
Exactitud 0.5263 0.7826 0.7143 0.7273 0.7059 0.5833 0.6154
Precisión 0.4762 0.72 0.6522 0.6667 0.6667 0.4667 0.6154
Tabla 6.3 - Ejemplo de datos obtenidos en la fase de testeo I. Muestras de audio 1 a 7 de
las 15 analizadas.
La fila 1 muestra el nivel de señal de la sibilancia con respecto al de la respiración
en la mezcla. La segunda fila muestra la zona donde se ha insertado la sibilancia, es
decir, en cuál de las 3 inspiraciones contenidas en el audio "respiración.wav" ha sido
solapada la señal de sibilancia correspondiente, siendo 3 las posibles de entre las que se
elige una de forma aleatoria. El resto de filas pertenece a los parámetros ya explicados
para la obtención de las métricas.
A simple vista se puede observar como el rendimiento del programa desciende
cuando la mezcla de audios se realiza con -5 o 0 dB de diferencia entre la potencia de la
señal de sibilancia y la del audio de respiración vesicular normal. Esto se debe a que la
sibilancia queda parcialmente enmascarada por el audio de respiración y la detección es
más complicada, llevando a obtener más falsos negativos y positivos.

96
Si comparamos los parámetros exactitud y exhaustividad observamos que este
último, por lo general, suele mostrar un porcentaje mayor, por lo tanto podemos llegar a la
conclusión de que la tasa de falsos positivos suele ser mayor que la tasa de falsos
negativos. Por ello, podemos indicar que nuestro software no suele no detectar picos
pertenecientes a sibilancias, es decir, mostrar falsos negativos.
Cuando el nivel de señal de la sibilancia está 5 dB por encima del de la señal de
audio podemos observar como el número de verdaderos positivos aumenta, lo que nos
indica, obviamente, que el rendimiento del programa aumenta en gran medida, aun así, el
número de falsos positivos y negativos no experimenta un descenso acusado, por lo tanto
las métricas no aumentan en exceso cuando esto ocurre.
Tras varias pruebas realizadas obteniendo el valor de las métricas calculadas
sobre varios audios generados de forma aleatoria cuyas mezclas han sido realizadas con
distintos niveles de señal entre respiración y sibilancia, es decir, ejecutando de forma
reiterada la función "testeo.m" y haciendo una media aritmética de todas las métricas
obtenidas, a continuación, en la tabla 6.4, se muestra en porcentaje el valor de cada una
de ellas:
Exhaustividad Exactitud Precisión
91.69 % 71.65 % 67.58 %
Tabla 6.4 – Media aritmética de las métricas obtenidas en la fase de testeo I
Si nos centramos en el parámetro exhaustividad, llegamos a la conclusión de que
la cantidad de verdaderos positivos frente a la cantidad de falsos negativos es muy
superior, lo cual nos da a entender que nuestro sistema introduce una tasa de falsos
negativos reducida, es decir, en pocas ocasiones nuestro detector de sibilancias pasará
por alto ciertas componentes de sibilancias o incluso sibilancias completas.
Por otro lado, el parámetro exactitud nos informa acerca de la proporción de falsos
positivos frente a la de verdaderos positivos. En este caso, la tasa de falsos positivos es
superior en proporción frente a la de falsos negativos, aunque sigue siendo bastante
menor frente a la de falsos positivos. Al comparar estos dos parámetros, exhaustividad y
exactitud, llegamos a la conclusión de que nuestro sistema es más propenso a introducir
falsas alarmas frente a no detectar ciertas sibilancias. Esto puede deberse a la
interferencia que crea el ruido de respiración y latidos del corazón en las señales con
sibilancias. Un alto nivel de señal respiratoria o cardiaca puede hacer que el sistema

97
detecte picos significativos donde realmente no los haya por el simple hecho de que
dichos picos relacionados con la respiración o el corazón posean una frecuencia cercana
a los rangos establecidos para la detección de sibilancias. El ruido introducido por las
grabaciones (micrófonos, ruido de fondo, etc.), también puede contribuir a la aparición de
falsos positivos. Por otro lado, la aparición de falsos negativos se debe al efecto
enmascarador que producen todos estos tipos de ruidos sobre las componentes sonoras
de las sibilancias.
En el ámbito de la detección de sonidos adventicios, consideramos que puede ser
mucho más perjudicial para el paciente el hecho obtener una alta tasa de FN frente a
obtener una alta tasa de FP. Es obvio que ambos errores pueden conducir a un mal
diagnóstico por parte del médico, pero una vez cometidos, observamos que la no
detección de una sibilancia puede llevar a la conclusión de que el paciente está sano
cuando realmente no lo está, pudiendo empeorar su patología si no se toman medidas
sanitarias. Por otro lado, el hecho de generar una falsa alarma (generar FP) puede poner
en alerta al médico encargado de hacer el diagnóstico, obligando al paciente a realizar
otro tipo de pruebas que certifiquen la existencia o no de las sibilancias detectadas por el
software, por lo tanto, esta vez sí se toman ciertas medidas sanitarias. En ambos casos
se cometen errores de diagnósticos aunque podemos observar claramente que las
consecuencias de introducir FN frente a FP pueden ser mucho más perjudiciales para el
paciente. Es por esto por lo que podemos afirmar, tras esta fase de testeo, que nuestro
software es robusto frente a la aparición de FN y por lo tanto, más fiable para la detección
de sibilancias.
Por último, el parámetro precisión nos informa acerca de la cantidad de aciertos
obtenidos (TP) frente a la cantidad de errores cometidos (FN y FP). Como podemos
observar, este porcentaje es superior al 50% por lo que podemos afirmar que la cantidad
de errores en total cometidos por nuestro software es inferior al número de aciertos que
genera.
6.5 Testeo II
El hecho de obtener una base de datos de audio pseudoaleatoria que solo
contemple 15 muestras de respiración con sibilancias nos da a entender que los
resultados obtenidos en la fase de testeo anterior pueden no reflejar con tanta exactitud
el comportamiento de nuestro software frente a situaciones reales. Es por ello por lo que
se decidió crear una nueva base de datos de audio detallada en el apartado 6.1.3 en la
cual se incrementaban hasta 165 los casos a analizar en esta nueva fase de testeo. Con
ello pretendemos obtener un conjunto de resultados más fieles al comportamiento real de

98
nuestro software gracias a la creación de una nueva base de datos más robusto que la
anterior.
El proceso llevado a cabo en esta fase de testeo es muy similar al seguido en la
fase anterior, tal y como podemos observar en el esquema mostrado en la figura 6.9:
Figura 6.9 – Esquema de la implementación de la fase de testeo II
Como podemos observar, los métodos utilizados para la obtención de parámetros
como TP, FN y FP, así como sus métricas correspondientes, son similares a la fase de
testeo anterior. El cambio fundamental se ha producido en el uso de una nueva base de
datos que como ya se ha mencionado, contiene una variedad de casos con sibilancias
superior a la base de datos precedente a la expuesta en el apartado 6.1.3.
De forma similar al apartado anterior (6.4), los pasos seguidos para la obtención
de resultados son los siguientes:
- Ejecución del programa principal utilizando la primera muestra de audio
generada en la base de datos.
- Obtención de sibilancias detectadas.
- Comparación frame a frame da cada sibilancia detectada con el patrón que
representa la sibilancia real en la muestra de audio.
- Obtención de parámetros TP, FN y FP.
- Cálculo de métricas.
- Almacenamiento de datos generados.
- Repetir el proceso cambiando a la muestra de audio siguiente en la base de
datos de testeo II.

99
A continuación, en la tabla 6.5, se muestra un ejemplo de los datos almacenados
en el archivo "resultados.mat":
Muestra
123
Muestra
124
Muestra
125
Muestra
126
Muestra
127
Muestra
128
Muestra
129
Nivel de
señal (dB) -5 0 -5 5 5 0 -5
TP 18 18 17 18 18 18 18
FP 10 12 11 13 4 12 14
FN 1 1 2 1 1 1 1
Exhaustividad 0.9474 0.9474 0.8947 0.9474 0.9474 0.9474 0.9474
Exactitud 0.6429 0.6 0.6071 0.5806 0.8186 0.6 0.5625
Precisión 0.6207 0.5806 0.5667 0.5625 0.7826 0.5806 0.5455
Tabla 6.5 - Ejemplo de datos obtenidos en la fase de testeo II. Muestras de audio 123 a
129 de las 165 analizadas.
Como podemos observar, en la primera fila de la tabla 6.5 se muestra el número
de muestra analizada en la columna correspondiente, en la segunda fila la diferencia de
señal en dB entre las señales de respiración utilizadas y las sibilancias. Las tres filas
consecutivas muestran el número de TP, FP y FN respectivamente. En las tres filas
restantes se muestran los resultados obtenidos en el cálculo de cada una de las metricas
propuestas.
Podemos llegar a unas conclusiones parecidas a las tomadas gracias a la tabla
6.3 correspondiente a los resultados obtenidos en la fase de testeo I, es decir, el
rendimiento del programa se ve perjudicado cuando la mezcla de señal se realiza con
una diferencia de potencia de -5 dB debido al efecto enmascarador que produce la
respiración sobre la sibilancia analizada. La aparición de falsos negativos sigue siendo
inferior a la aparición de falsos positivos y verdaderos positivos, tal y como se reflejará en
la tabla 6.6 a continuación mostrada:

100
Fase Exhaustividad Exactitud Precisión
Testeo I 91.69 % 71.65 % 67.58 %
Testeo II 87.98 % 61.69 % 57.4 %
Tabla 6.6 – Comparación de resultados finales obtenidos en la fase de testeo I y II.
Podemos observar como el porcentaje en las tres métricas analizadas en la fase II
desciende debido al aumento de muestras utilizadas para llevar a cabo esta nueva
evaluación. Además, el descenso de porcentaje también se debe al hecho de que las
señales con respiración utilizadas en la nueva base de datos detallada en la sección 6.1.3
contienen sonidos adventicios, como por ejemplo crepitantes (audio utilizado en la
construcción de la base de datos denominado "Coarse crackles.wav"). Un aumento en el
ruido introducido por la respiración es capaz de enmascarar en mayor medida a las
sibilancias a detectar.
Podemos observar que la métrica cuyo porcentaje desciende en menor medida es
la exhaustividad, lo cual confirma de nuevo el hecho de que nuestro software es robusto
frente a la aparición de falsos negativos. La incorporación de nuevos audios con mayores
interferencias no ha supuesto un gran aumento en la tasa de FN.
Como era de esperar, un aumento en la introducción de ruido ajeno a las
sibilancias ha ocasionado un aumento en la aparición de falsos positivos y por
consiguiente un descenso del 10% aproximadamente en las métricas exactitud y
precisión.
La diferencia entre porcentajes de las tres métricas analizadas nos permite llegar
a conclusiones similares a las obtenidas en el apartado 6.4:
- El número de FN es significativamente menor al número de FP.
- En general, la aparición de FN no se ve excesivamente afectada por la
aparición de ruidos interferentes.
- La aparición de FP si se ha visto afectada en mayor medida por la aparición de
interferencias tales como los crepitantes en las bandas de frecuencia en las
cuales el detector de sibilancias actúa.
- Nuestro sistema sigue siendo robusto frente a la aparición de FN, incluso al
utilizar una base de datos con mayores interferencias y una variedad de
audios mayor.
- El descenso de los porcentajes, en general, no ha sido muy acusado tras
utilizar una base de datos nueva más robusta que la anterior.

101
7 CONCLUSIONES Y LÍNEAS FUTURAS
En primer lugar, la primera conclusión a la que podemos llegar una vez realizadas
todas las tareas descritas en esta memoria es la relativa al cumplimiento de todos los
objetivos propuestos en el apartado número 3:
- Un software capaz de detectar sibilancias ha sido implementado a lo largo de
este trabajo, ofreciendo ciertas funcionalidades que van más allá del simple
hecho de detectarlas. La sencillez y la pequeña cantidad de recursos que
necesita para funcionar son clave frente a otros sistemas mucho más
complejos y sobretodo difíciles de adquirir.
- Tras un estudio del estado del arte en el ámbito de la detección de sonidos
adventicios mediante métodos computarizados, hemos podido estudiar a
fondo ciertas técnicas sobre las cuales nos hemos apoyado para confeccionar
nuestro método de detección de sibilancias.
- Como consiguiente, se han podido observar puntos fuertes y carencias de
estos sistemas con el fin de mejorar en ciertos aspectos nuestro software.
- Se ha realizado un estudio de ciertos sonidos adventicios presentes en la
respiración de pacientes con ciertas patologías, centrándonos en gran medida
en las características propias de las sibilancias y ciertas diferencias que nos
permiten diferenciarlas con respecto a otros sonidos adventicios de
características parcialmente similares.
- Tras este estudio, hemos sido capaces de cuantificar dichas características
con el fin de implementar ciertas etapas del software.
- Hemos conseguido obtener una configuración óptima para nuestro sistema
mediante una serie de fases de evaluación.
- Una fase de testeo dividida en dos secciones ha sido llevada a cabo gracias a
la confección de dos bases de datos de audio distintas, obteniendo resultados
satisfactorios.
- Como se podrá observar en el apartado 9 de esta memoria, un GUI ha sido
creado de forma satisfactoria con el propósito de que el usuario final pueda
aprovechar por completo todas las funcionalidades que aporta el software de
forma fácil e intuitiva.
En lo referente al estudio de los datos obtenidos en las fases de evaluación
podemos destacar los siguientes aspectos:

102
- Los resultados obtenidos en ambas fases de testeo han sido satisfactorios
debido a la obtención de porcentajes relativamente altos en las métricas
propuestas.
- La exhaustividad obtenida en las dos pruebas de testeo realizadas al software
suele ser mayor que la métrica exactitud, por lo tanto, podemos llegar a la
conclusión de que en nuestro software, en la mayoría de las situaciones, la
tasa de falsos negativos es inferior a la de falsos positivos, siendo capaz de
evitar gran cantidad de errores de pérdidas, pudiendo evitar en gran medida la
posibilidad de obviar o pasar por alto componentes espectrales relativos a las
sibilancias en una respiración producida por un paciente. Por esta razón, es
importante remarcar esta ventaja ofrecida por nuestro software.
- El hecho de que nuestro software pueda mostrar una cantidad de falsos
positivos superior a la cantidad de errores cometidos como falsos negativos
puede deberse en gran medida a la calidad de los audios utilizados para llevar
a cabo dichas fases de evaluación. El hecho de no estar filtradas y pre-
procesadas puede ocasionar la aparición de interferencias indeseadas que
dificulten la detección de sibilancias en nuestro software. Por ello, de nuevo
hacer hincapié en la dificultad que hemos encontrado a la hora de obtener
ciertas muestras de audio para completar este trabajo.
- Como es evidente, nuestro software se comportará mejor ante muestras de
audio filtradas y pre-procesadas. El hecho de eliminar componentes en
frecuencia producidas por los ruidos respiratorios y cardiacos aumentará en
gran medida la eficiencia de nuestro sistema a la hora de detectar sibilancias
en la respiración de un paciente.
Una vez tomadas estas conclusiones, nos planteamos la siguiente pregunta: ¿Un
software detector de sibilancias es más fiable para un paciente si genera un exceso de
falsos positivos o un exceso de falsos negativos?
Obviamente, la intención del programador a la hora de diseñar este tipo de
software es la de eliminar todo tipo de espurio que pueda entorpecer el diagnóstico y
evitar perder información a la hora de analizar la señal sonora. Aun así, nos damos
cuenta de que es imposible crear un software perfecto que evite ambos casos, por lo que
es el momento de, una vez asumidos los posibles errores que pueda cometer el software,
determinar cuáles son más o menos graves y determinantes. Desde nuestro punto de
vista, un software detector de sibilancias debería de, ante todo, detectarlas. Aunque
parezca obvio, esto nos da a entender que los posibles falsos positivos no son tan
relevantes a la hora de diagnosticar una enfermedad que los falsos negativos. El no

103
detectar una sibilancia puede hacer que la segunda opinión indique que todo está bien y
no hay anomalías, pudiendo ser el caso contrario y ocasionar un error de diagnóstico
grave. Por otro lado, la aparición de falsas alarmas puede hacer que el médico ponga
especial atención sobre el paciente, llegando a realizar otras pruebas diferentes para
verificar o no la existencia de sibilancias. Puede que con la segunda prueba realmente el
paciente esté sano y con el software se dio una falsa alarma o por el contrario, el
paciente produce sibilancias con su respiración y el hecho de obtener falsos positivos en
la prueba hizo tomar especial atención en el proceso.
Como ya se ha mencionado en ciertas ocasiones, han existido algunas
dificultades que han entorpecido el progreso de este trabajo:
- La escasez de muestras de audio disponibles en la red es la principal. Es un
hecho que ha ralentizado en gran medida la obtención de resultados en la fase
de evaluación de nuestro software.
- La existencia de algunos audios expuestos en ciertas páginas webs no
especializadas en el ámbito de la auscultación no han podido ser utilizadas
debido a un exceso de nivel sonoro en la respiración y ruidos cardiacos,
ocasionando en gran medida un enmascaramiento de las sibilancias que
inducen a error en la detección.
- La creación de una base de datos propia construida a partir de la combinación
pseudoaleatoria de las pocas muestras de audio conseguidas, ha sido una
solución llevada a cabo.
En cuanto al posible futuro de este trabajo, el hecho de seguir mejorando las
características del programa sería una de las prioridades. Para ello, debemos de mejorar
ciertas partes dentro del proceso de detección:
- Construcción de trayectorias. Este es una de las partes clave dentro del
proceso por lo que debemos de hacer especial hincapié en la mejora de esta
técnica. Un aumento en la precisión a la hora de formar trayectorias, evitará en
gran medida posibles errores a la hora de determinar o no el hecho de que
sean sibilancias.
- Pre-procesado para las señales pulmonares que se introduzcan en el
programa. Un nuevo bloque dentro de la estructura del programa como es el
mencionado, puede mejorar mucho la eficiencia del programa. Es un ejemplo
la introducción de ecualizadores y filtros elimina-ruido en el desarrollo del
software.

104
- Obtención de bibliotecas de audios con respiraciones humanas grabadas en
condiciones favorables o incluso planificar una fase de grabación de
respiraciones de pacientes con instrumentos de captación de sonidos
adecuados para esta aplicación.
Tras un proceso de mejora de las prestaciones del programa, una posible
migración a otro lenguaje de programación podría abrir un gran rango de posibilidades a
la hora de implementar esta aplicación en aparatos como fonendoscopios digitales o
incluso en smartphones mediante la confección de una app descargable para los
usuarios. Esto permitiría un rápido y útil uso del software tanto en profesionales como por
usuarios comunes, permitiendo tener una segunda opinión médica al alcance de todos, lo
cual permitiría detectar posibles irregularidades pulmonares a tiempo sin realizar grandes
esfuerzos, un aspecto fundamental a la hora de prevenir y curar multitud de
enfermedades respiratorias.

105
8 BIBLIOGRAFÍA
[1] Sandra Reichert, Raymond Gass, Christian Brandt and Emmanuel Andrès,
Analysis of Respiratory Sounds: State of the Art, Clinical Medicine:
Circulatory, Respiratory and Pulmonary Medicine 2008:2.
[2] A.R.A. Sovijärvi et al. Definition of terms for applications of respiratory
sounds, European Respiratory Review 2000; 10: 77, 597-610.
[3] Marcin Wisniew-ki, Tomasz P. Zielinski, TONALITY DETECTION
METHODS FOR WHEEZES RECOGNITION SYSTEM, AGH University of
Science and Technology, Krakow, Poland. IWSSIP 2012, 11-13 April 2012,
Vienna, Austria.
[4] Hans Pasterkamp, Steve S. Kkraman, and George R. Wodicka, Respiratory
Sounds - Advances Beyond the Stethoscop, Department of Pediatrics and
Child Health, University of Manitoba, Winnipeg, Manitoba; VA Medical
Center, Lexington, Kentucky;School of Electrical and Computer
Engineering, Purdue University, West Lafayette, Indiana.
[5] H.E. Elphick, S. Ritson, H. Rodgers, M.L. Everard, When a "wheeze" is not
a wheeze: acoustic analysis of breath sounds in infants, European
Respiratory Journal 2000; 16: 593-597, UK.
[6] American Thoracic Society Ad Hoc Committee on Pulmonary
Nomenclature. 1977. Updated nomenclature for membership reaction. ATS
News 3:5–6.
[7] R S Cane, S C Ranganathan, S A McKenzie, What do parents of wheezy
children understand by “wheeze”?, Archives of Disease in Childhood 2000;
82:327-332
[8] Antoni Homs-Corbera, José Antonio Fiz, José Morera, and Raimon Jané,
Time-Frequency Detection and Analysis of Wheezes During Forced
Exhalation, IEEE Trasactions on Biomedical Engineering, vol.51, No.1,
January 2004.

106
[9] H E Elphick, G A Lancaster, A Solis, A Majumdar, R Gupta, R L Smyth,
Validity and reliability of acoustic analysis of respiratory sounds in infants.
Archives of Disease in Childhood 2004; 89: 1059-1063. doi:
10.1136/adc.2003.046458
[10] Zbigniew Korona and Mieczyslaw M. Kokar, Lung Sound Recognition Using
Model-Theory Based Feature Selection and Fusion, Department of
Electrical and Computer Engineering, Northeastern University, 360
Huntington Avenue, Boston, MA 02115.
[11] S. A. Taplidou, L. J. Hadjileontiadis, T. Penze, V. Gross and S. M. Panas,
WED: An Efficient Wheezing-Episode Detector Based on Breath Sounds
Spectrogram Analysis, 'Department of Electrical & Computer Engineering,
Aristotle University of Thessaloniki, Thes-saloniki, GREECE Department of
Medicine, Philipps University, Marburg, Germany. 25th Annual Intemational
Conference of the IEEE EMBS. Cancun, Mexico September 17-21,2003.
[12] Mireille Oud, Edo H. Dooijes, AUTOMATED BREATH SOUND ANALYSIS,
University of Amsterdam, Computer Science Dept., Kruislaan 403, The
Netherlands. IEEE EMBS Conf. Proc. 1996, section 4.2.4-3.
[13] Robert P. Baughman, Robert G, Lung Sound Analysis for continuous
Evaluation of Airflow Obstruction in Asthma, Chest 1985;88;364-368.DOI
10.1378/chest.88.3.364.
[14] Abhishek Jain, Jithendra Vepa, Member, IEEE, Lung Sound Analysis for
Wheeze Episode Detection. 30th Annual International IEEE EMBS
Conference, Vancouver, British Columbia, Canada, August 20-24, 2008.
[15] Jiarui Li, Ying Hong, Wheeze detection algorithm based on spectrogram
analysis, Institute of Acoutics, Chinese Academy of Sciences, University of
Chinese Academy of Science. 2015 8th International Symposium on
Computational Intelligence and Design.
[16] J. C. Altozano Racionero, F. J. Cañadas Quesada, Sistema para la
extracción de singing voice en señales musicales polifónicas monoaurales,

107
Proyecto Fin de Carrera, Escuela Politécnica Superior de Linares,
Universidad de Jaén.
[17] Easy Auscultation - https://www.easyauscultation.com
[18] Littmann Stethoscopes - http://www.littmann.com
[19] Thinklabs One - http://www.thinklabs.com
[20] Practical Clinical Skills - https://www.practicalclinicalskills.com/
[21] N. Meslier, G. Charbonneau, J-L. Racineux, Wheezes, European
Respiratory Journal, 1995, 8, 1942–1948, ISSN 0903 - 1936, DOI:
10.1183/09031936.95.08111942, Reino Unido.
[22] Recuero López, Manuel, Ingeniería Acústica, Madrid: Paraninfo, D.L. 1999,
ISBN: 84-283-2639-8.
[23] Alana V. Oppenheim, Ronald W. Schafer, Jhon R. Buck, Tratamiento de
señales en tiempo discreto, 2ª edición, Madrid, 2000, Prentice Hall Iberia,
ISBN: 84-205-2987-7.
[24] Shih-Hong Li, Bor-Shing Lin, Chen-Han Tsai, Cheng-Ta Yang, Bor-Shyh
Lin, Design of Wearable Breathing Sound Monitoring System for Real-Time
Wheeze Detection, Sensors 2017, 17, 171.
[25] F. J. Cañadas Quesada, P. Vera Candeas, N. Ruiz Reyes, Investigación y
desarrollo de técnicas de estimación multi-pitch y su aplicación a la
transcripción automática de señales musicales y polifónicas. Universidad
de Jaén, 2009
[26] Federico Miyara, Acústica y sistemas de sonido, Rosario, República
Argentina, UNR Editora, 2000, ISBN: 950-673-196-9.

108
9 MANUAL DE USUARIO: USO DEL GUI
Se conoce como GUI a la interfaz gráfica de usuario que nos proporciona Matlab a
la hora de desarrollar software. La herramienta que nos brinda para la creación de este
interfaz de usuario es denominada GUIDE o entorno de desarrollo de GUI. Nos permitirá
personalizar por completo la interfaz que se mostrará al usuario, haciendo que este
pueda sacar máximo partido al software de forma rápida e intuitiva. En nuestro caso, el
usuario podrá modificar parámetros de entrada, realizar una selección del audio a
analizar de forma rápida, visualizar todos los parámetros de salida de interés y
seleccionar el tipo de espectrograma que necesite observar. Como se puede intuir, en
este apartado se presentará la interfaz correspondiente a nuestro programa y se mostrará
de forma individual cada uno de los apartados con los que cuenta dicha GUI.
Figura 9.1 - Secciones de la interfaz de usuario
Como apreciamos en la figura 9.1, la interfaz está compuesta por 4 secciones
claramente diferenciadas en la imagen. Es importante remarcar que el usuario tendrá
acceso a este interfaz escribiendo en la línea de comandos de Matlab la palabra
"interface". De esta forma se iniciará la GUI con la que el usuario podrá interactuar e
iniciar el programa principal, denominado como "principal.m". En ningún momento el
usuario se verá obligado a manipular o ejecutar este archivo, simplemente debe
asegurarse de que se encuentre en el mismo directorio que el archivo "interface.m" y
"sg.m". Una vez iniciada la interfaz, el usuario tendrá que interactuar con cada una de las
siguientes secciones que la forman.

109
9.1 Inicio de programa
Es aquí donde el usuario podrá elegir el archivo de audio .wav que deseé analizar
con nuestro programa detector de sibilancias. Para ello, debe pulsar sobre el botón
denominado "Cargar Audio .wav". De esta forma, se abrirá automáticamente una ventana
donde elegir el audio en el directorio donde se ejecuten todas las funciones de Matlab en
ese momento. A continuación, en la figura 9.2, se muestra en detalle esta sección.
Figura 9.2 - Apartado 1 de la interfaz
En la segunda mitad, podemos observar dos indicadores que nos mostrarán la
duración en segundos y la frecuencia de muestreo del audio introducido. Si en algún
momento se cancela la selección de audio o por cualquier otro motivo el archivo no
queda seleccionado, un mensaje de aviso aparecerá en pantalla indicando que no se
realizó correctamente la selección del audio, similar al expuesto en la figura 9.3:
Figura 9.3 – Mensaje de aviso en la selección de audio.

110
9.2 Selección de parámetros
Es en esta sección donde el usuario podrá elegir ciertos parámetros con los que el
programa podrá trabajar y realizar el proceso de detección, además de encontrarse el
botón de inicio del programa principal. En la figura 9.4 se muestra en detalle dicha
sección.
Figura 9.4 - Apartado 2 de la interfaz
En primer lugar, mediante una serie de menús desplegables, el usuario podrá
seleccionar el número de muestras de la ventana con la que se efectuará la STFT al
inicio del programa. Las opciones son 512, 1024 y 2048 muestras (a más muestras por
ventana, menos resolución temporal pero más resolución en frecuencia). En la figura 9.5
podemos observar un ejemplo donde aparecen dichas opciones incluidas en un menú
desplegable.
Figura 9.5 – Ejemplo de menú desplegable.

111
En el siguiente menú, el usuario podrá elegir el tipo de paciente del que se ha
extraído la muestra de audio (niño o adulto), tal y como muestra la figura 9.6.
Figura 9.6 – Menú desplegable para la selección de paciente.
Esto modificará el rango en frecuencia elegido para juzgar las trayectorias. En el
siguiente recuadro que encontramos, observamos tres menús desplegables
correspondientes a la selección de parámetros relativos a la construcción de trayectorias.
En primer lugar, el usuario podrá elegir el rango en frecuencia o cercanía en frecuencia
para la construcción de trayectorias. Podrá elegir entre ±30, ±50 o ±100 Hz tal y como se
muestra en la figura 9.7:
Figura 9.7 – Menú desplegable para la selección del rango en frecuencia.
. En el siguiente menú desplegable, se elegirá la cercanía en tiempo a la hora de
construir las trayectorias. Las opciones son 30, 50 y 100ms, en la figura 9.8 se muestra el
menú desplegable correspondiente.
112
Figura 9.8 – Menú desplegable para la selección del rango en tiempo.
. El tercer menú desplegable que encuentra el usuario está relacionado con la
selección de la duración mínima que debe tener una trayectoria para ser considerada
sibilancia. Las opciones disponibles son las siguientes: 80, 100 y 250 ms. A continuación,
en la figura 9.9, observamos el menú desplegable que nos da a elegir entre las
duraciones mínimas disponibles.
Figura 9.9 – Ejemplo de menú desplegable en el campo "Duración mínima" de la interfaz.
Si alguno de estos parámetros no es seleccionado correctamente, aparecerá un
mensaje de aviso como el que podemos apreciar en la figura 9.10.
Figura 9.10 – Mensaje de aviso al no seleccionar correctamente una duración mínima de trayectoria

113
Por último, encontramos el botón de inicio de programa, el usuario deberá
pulsarlo cuando todos los parámetros hayan sido seleccionados correctamente. Es en
este momento cuando se ejecutará el programa principal y aparecerán los resultados en
la sección 3 de la interfaz.
9.3 Salida de datos
Una vez iniciada la ejecución del programa principal, los datos de salida se
mostrarán en esta sección. Seguidamente se muestra en detalle en la figura 9.11.
Figura 9.11 - Apartado 2 de la interfaz
Como vemos en el ejemplo, se mostrarán los siguientes datos y opciones, en la
figura 9.12 se pueden observar los siguientes elementos:
- Número de sibilancias detectadas.
- Tipo de sibilancia (polifónica o monofónica)
- Número de armónicos que contienen las sibilancias. En el caso de que estas
sean monofónicas, este indicador será rellenado con un 0.
Figura 9.12 – Salida de datos en una prueba realizada con el audio "6025.wav"
Si no se han detectado sibilancias, aparecerá un mensaje de aviso tras pulsar el
botón de inicio de la sección anterior. En ese caso, no se modificarán estos indicadores.
En la figura 9.13 se muestra este mensaje:
Figura 9.13 – Mensaje de aviso en el que se indica que no se han detectado sibilancias en el audio introducido.

114
A continuación, nos encontramos una serie de botones cuya selección permitirá
visualizar cada una de las etapas en el proceso de detección de sibilancias. En la figura
9.14 se observan dichos botones con los que visualizar cada una de las siguientes
etapas:
- Etapa 1: corresponde al espectrograma de la señal de audio.
- Etapa 2: muestra los picos más significativos detectados.
- Etapa 3: permitirá observar las trayectorias interpoladas.
- Etapa 4: mostrará las sibilancias detectadas, en el caso de que existan.
Figura 9.14 – Panel de botones para visualizar cada una de las etapas.
Por último, nos encontramos dos botones y un cuadro de texto editable con los
cuales el usuario podrá especificar qué sibilancia desea reproducir o grabar (mostrado en
la figura 9.16), de forma individual y separada del resto del audio. Como se puede
apreciar en las imágenes asignadas a cada botón, el de la parte superior permite
reproducir la sibilancia indicada y el restante abrirá una ventana con la que podremos
guardar dicho fragmento de audio en un fichero .wav con el nombre que indique el
usuario. En la figura 9.15 podemos visualizar con más detalle estos botones:
Figura 9.15 – Botones para reproducir o grabar las sibilancias especificadas en el panel mostrado en la figura 9.16.
Figura 9.16 – Panel de selección de sibilancia a reproducir o guardar como archivo .wav.
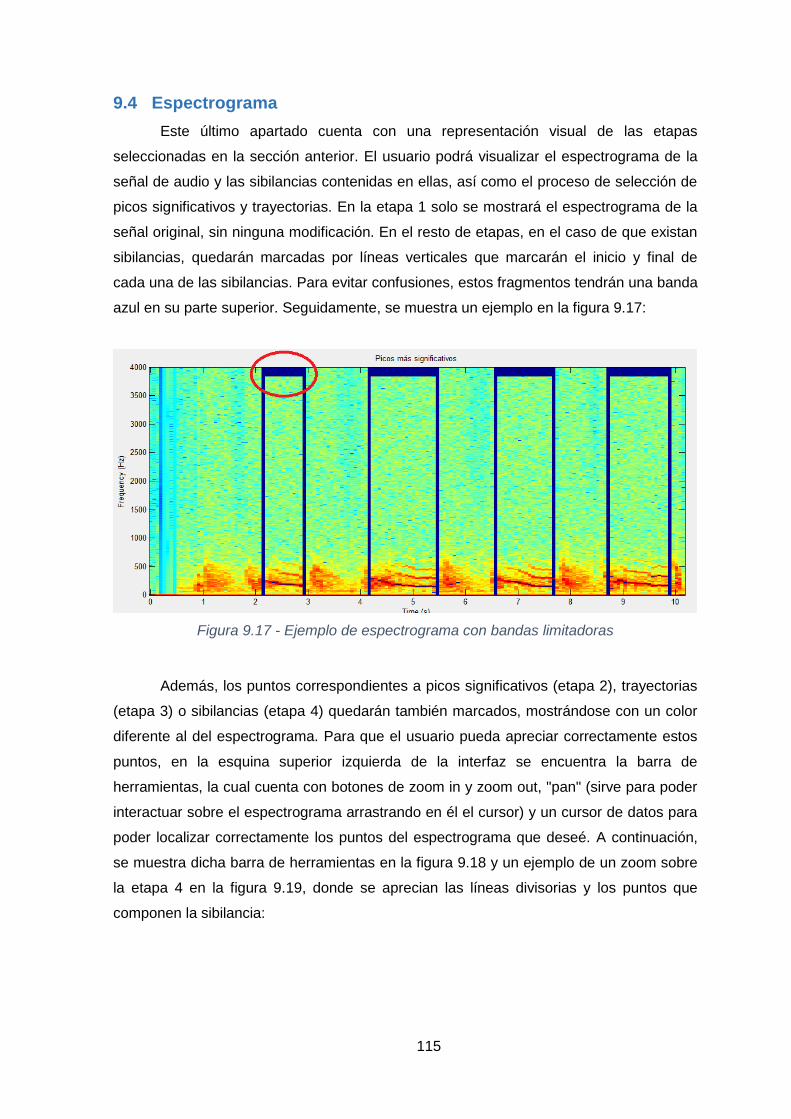
115
9.4 Espectrograma
Este último apartado cuenta con una representación visual de las etapas
seleccionadas en la sección anterior. El usuario podrá visualizar el espectrograma de la
señal de audio y las sibilancias contenidas en ellas, así como el proceso de selección de
picos significativos y trayectorias. En la etapa 1 solo se mostrará el espectrograma de la
señal original, sin ninguna modificación. En el resto de etapas, en el caso de que existan
sibilancias, quedarán marcadas por líneas verticales que marcarán el inicio y final de
cada una de las sibilancias. Para evitar confusiones, estos fragmentos tendrán una banda
azul en su parte superior. Seguidamente, se muestra un ejemplo en la figura 9.17:
Figura 9.17 - Ejemplo de espectrograma con bandas limitadoras
Además, los puntos correspondientes a picos significativos (etapa 2), trayectorias
(etapa 3) o sibilancias (etapa 4) quedarán también marcados, mostrándose con un color
diferente al del espectrograma. Para que el usuario pueda apreciar correctamente estos
puntos, en la esquina superior izquierda de la interfaz se encuentra la barra de
herramientas, la cual cuenta con botones de zoom in y zoom out, "pan" (sirve para poder
interactuar sobre el espectrograma arrastrando en él el cursor) y un cursor de datos para
poder localizar correctamente los puntos del espectrograma que deseé. A continuación,
se muestra dicha barra de herramientas en la figura 9.18 y un ejemplo de un zoom sobre
la etapa 4 en la figura 9.19, donde se aprecian las líneas divisorias y los puntos que
componen la sibilancia:

116
Figura 9.18 - Localización de la barra de herramientas
Figura 9.19 - Zoom sobre Etapa 4
Con las 4 secciones mostradas, el usuario podrá manipular el programa de forma
correcta e intuitiva, pudiendo elegir con total libertad un conjunto de parámetros con los
que el programa realizará las funciones pertinentes. Además, en su mano queda qué
representar en cada caso, adaptando la salida de datos visuales y auditivos según la
situación y el interés del usuario.





























