Embed Size (px)
Citation preview

Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros Informáticos
Grado en Ingeniería Informática
Trabajo Fin de Grado
Despliegue, Monitorización y Recuperación de Clústeres Kubernetes
Autor: Juan Ramírez Arana Tutora: Marta Patiño Martínez
Madrid, mayo 2021

Este Trabajo Fin de Grado se ha depositado en la ETSI Informáticos de la Universidad Politécnica de Madrid para su defensa.
Trabajo Fin de Grado Grado en Ingeniería Informática Título: Despliegue, Monitorización y Recuperación de Clústeres Kubernetes Mayo 2021
Autor: Juan Ramírez Arana Tutora:
Marta Patiño Martínez Lenguajes y Sistemas Informáticos e Ingeniería de Software ETSI Informáticos Universidad Politécnica de Madrid

i
Resumen Este Trabajo de Fin de Grado tiene como misión aprender sobre los servicios que ofrecen las nubes públicas, la arquitectura de los clústeres de Kubernetes y el uso de Ansible como herramienta de automatización.
El proyecto trata la creación de la infraestructura necesaria para el posterior despliegue de un clúster de Kubernetes en Google Cloud Platform, una nube pública. También se muestra cómo monitorizar dicho clúster mediante la instalación de aplicaciones dirigidas a ese propósito (en concreto Prometheus y Grafana), así como una posible configuración de esas herramientas. Por otro lado, se indica cómo desplegar una base de datos PostgreSQL y una aplicación sobre el clúster para comprobar que el funcionamiento de este sea el adecuado.
El despliegue del clúster está enfocado a la automatización utilizando la herramienta Ansible. Dicho despliegue es una tarea repetitiva que puede ser automatizada para hacerla más cómoda y sencilla. La solución que se plantea es compatible con cualquier entorno (público o privado) cuyas máquinas virtuales se encuentren ya desplegadas.
Por último, se presenta una idea para el diseño de un sistema de auto-reparación. No se ha llegado a implementar de manera práctica en este proyecto, dando lugar a futuras líneas de desarrollo de este.
Palabras clave: despliegue de clústers, Kubernetes, nubes públicas, monitorización, automatización.

ii
Abstract The main aim of this end-of-degree dissertation is to learn about the services offered by public clouds, Kubernetes cluster architecture, and how Ansible can be used as an automation tool.
The project consists of the deployment of a Kubernetes cluster by means of a public cloud provider (particularly, Google Cloud Platform). It also shows how to monitor this cluster by installing applications such as Prometheus and Grafana, as well as how to configure said applications. A deployment of a PostgreSQL database and the installation of an application that supervises the appropriate performance of the cluster are also included.
The deployment of the cluster is focused on automation, using Ansible as the tool of choice for that purpose. Since the deployment is a repetitive task, the process can be automatized in order to save time in the future. The proposed solution would be compatible with any environment (both public and private) that already has the required virtual machines ready.
Last, although the practical implementation of a self-repair system has not yet been included in this dissertation, the idea of designing one has been introduced at least at the theoretical level, thus leading to a possible further extension of the project in the future.
Keywords: cluster deployment, Kubernetes, public clouds, monitorization, automation.

iii
Tabla de contenidos 1 Introducción .........................................................................................1
1.1 Objetivos del trabajo ........................................................................... 2 2 Conceptos previos .............................................................................3
2.1.1 Nubes públicas ............................................................................ 3 2.1.1.1 Google Cloud Platform .............................................................. 3
2.1.2 Kubernetes .................................................................................. 4 2.1.2.1 Arquitectura ............................................................................. 4 2.1.2.2 Objetos de Kubernetes .............................................................. 4 2.1.2.3 Componentes del plano de control ............................................ 5 2.1.2.4 Componentes de nodo ............................................................... 5 2.1.2.5 Resumen................................................................................... 6
2.1.3 Prometheus .................................................................................. 6 2.1.4 Grafana ........................................................................................ 7 2.1.5 Ansible ......................................................................................... 7
3 Desarrollo ..........................................................................................8 3.1 Preparación del entorno en GCP ......................................................... 8
3.1.1 Configuración de red .................................................................... 8 3.1.2 Creación máquinas virtuales ...................................................... 11 3.1.3 Clave SSH .................................................................................. 13 3.1.4 Balanceador de carga ................................................................. 13
3.2 Configuración del bastión ................................................................. 14 3.3 Despliegue del clúster con kubeadm ................................................ 15
3.3.1 Inventario de Ansible ................................................................. 15 3.3.2 Creación del rol para el despliegue del clúster ............................ 15 3.3.3 Cuenta de servicio ...................................................................... 22
3.4 Despliegue aplicaciones monitorización: Prometheus y Grafana ....... 23 3.4.1 Persistencia de los datos ............................................................ 23
3.4.1.1 Servidor NFS ........................................................................... 25 3.4.1.2 Cliente NFS ............................................................................. 26 3.4.1.3 NFS en el clúster..................................................................... 27
3.4.2 Instalación Prometheus .............................................................. 29 3.4.3 Instalación Grafana.................................................................... 30
3.5 Prometheus: configuración de alertas ............................................... 31 3.5.1 Configuración Alertmanager ....................................................... 31 3.5.2 Instalación conector ................................................................... 32 3.5.3 Configuración alertas ................................................................. 33
3.6 Grafana: creación de dashboards ..................................................... 40 3.6.1 Configuración de Grafana .......................................................... 40

iv
3.6.2 Dashboard información general clúster ...................................... 42 3.7 Despliegue de la base de datos: PostgreSQL ..................................... 48
3.7.1 Instalador Operador PostgreSQL ................................................ 48 3.7.2 Creación clúster PostgreSQL ...................................................... 49
3.8 Instalación herramientas de desarrollo ............................................. 50 3.8.1 Jira ............................................................................................ 50
3.9 Automatización de la reparación ...................................................... 51 4 Conclusiones y líneas futuras .......................................................... 53
4.1 Conclusiones .................................................................................... 53 4.2 Líneas futuras .................................................................................. 53
5 Análisis de Impacto ......................................................................... 54 6 Bibliografía ...................................................................................... 55 7 Anexo .............................................................................................. 58
7.1 ConfigMap Prometheus .................................................................... 58 7.2 Dashboard Grafana .......................................................................... 59

v
Índice de figuras Figura 1 - Evolución de los diferentes entornos ............................................... 1
Figura 2 - Distintos modelos de servicios en la nube ....................................... 3
Figura 3 - Elementos de un clúster de Kubernetes .......................................... 6
Figura 4 – Arquitectura de Prometheus ........................................................... 6
Figura 5 - Creación de una subred en GCP ..................................................... 8
Figura 6 - Creación de una regla de firewall en GCP ....................................... 9
Figura 7 - Creación de una regla de firewall en GCP ..................................... 10
Figura 8 – Reglas firewall .............................................................................. 11
Figura 9 - Creación de una VM en GCP ......................................................... 11
Figura 10 - Creación de una VM en GCP ....................................................... 12
Figura 11 - Creación de una VM en GCP (interfaz de red) .............................. 12
Figura 12 - Clave SSH en GCP ...................................................................... 13
Figura 13 – Frontend del balanceador de carga ............................................. 13
Figura 14- Backend del balanceador de carga ............................................... 14
Figura 15 – Nodos del clúster ........................................................................ 22
Figura 16 – Creación de un disco en GCP ..................................................... 23
Figura 17– Programación de la snapshot ....................................................... 24
Figura 18 – Añadir disco en la máquina bastión ........................................... 24
Figura 19 – Regla de firewall para el servidor NFS......................................... 26
Figura 20 – Página web de Prometheus ......................................................... 30
Figura 21 – Página web de Grafana ............................................................... 31
Figura 22 – Alerta Nodo caído configurada en Prometheus ............................ 34
Figura 23– Valores devueltos de la métrica up .............................................. 34
Figura 24– Alerta nodo worker2 caído ........................................................... 35
Figura 25 – Alerta solucionada nodo worker2 caído ...................................... 35
Figura 26– Alerta espacio ocupado en disco en Prometheus .......................... 36
Figura 27– Alerta disparada Espacio ocupado en disco ................................. 36
Figura 28 – Alerta uso de CPU en los nodos en Prometheus .......................... 36
Figura 29 – Alerta disparada Uso de CPU en los nodos ................................. 37
Figura 30 – Alerta uso de memoria en Prometheus ....................................... 37
Figura 31 – Alerta Número de réplicas bajo ................................................... 38
Figura 32 – Alerta disparada Número de réplicas bajo .................................. 38
Figura 33 – Bucle de reinicios en un pod en Prometheus .............................. 38
Figura 34 – Alerta disparada Bucle de reinicios ............................................. 39

vi
Figura 35 – etcd funcionando correctamente en Prometheus......................... 39
Figura 36 – Número de pods etcd corriendo .................................................. 39
Figura 37 – Estado API Server en Prometheus ............................................... 40
Figura 38 – Estado del pod para el servidor API ............................................ 40
Figura 39 – Configuración de la fuente de datos de Prometheus en Grafana . 41
Figura 40 – Panel de Grafana: estado de los nodos ........................................ 41
Figura 41– Panel estado servidor API ............................................................ 42
Figura 42 – Panel uso de CPU ....................................................................... 42
Figura 43 – Panel uso de memoria ................................................................ 43
Figura 44– Panel uso de disco ....................................................................... 43
Figura 45 – Panel uso de CPU en el tiempo ................................................... 44
Figura 46 - Panel estado de los nodos ........................................................... 44
Figura 47 – Dashboard estado del clúster ..................................................... 45
Figura 48 – Variable nodo del dashboard ...................................................... 45
Figura 49– Panel de presión de memoria, disco y PID.................................... 46
Figura 50 – Panel carga CPU ......................................................................... 46
Figura 51 – Panel espacio libre en disco ........................................................ 47
Figura 52 - Panel estado pods ....................................................................... 47
Figura 53 - Dashboard estado del nodo ......................................................... 48
Figura 54 – Página web de Jira ..................................................................... 51
Figura 55 – Sistema para la auto-reparación ................................................. 51

1
1 Introducción La manera en la que creamos aplicaciones ha cambiado drásticamente a lo largo de los años. Al principio, las aplicaciones eran ejecutadas en servidores físicos, y por lo tanto no había manera de definir límites para los recursos que podían utilizar las aplicaciones y si una aplicación utilizaba demasiados recursos, podía interferir en las otras aplicaciones.
Debido al mal uso de recursos y a los altos costes de mantenimiento, apareció una alternativa. La virtualización permite ejecutar varias máquinas virtuales (VMs) en un mismo procesador. Gracias a ella, las aplicaciones podían ser ejecutadas estableciendo límites y escaladas fácilmente, por lo que el uso de recursos mejoró considerablemente.
Cada VM incluye su propio sistema operativo encima del hardware virtualizado. Esto permite a las aplicaciones mantenerse aisladas ofreciendo así seguridad, ya que una aplicación no puede acceder los datos de otra.
Aunque la virtualización era una buena alternativa, apareció otra forma de desarrollar aplicaciones: los contenedores. Los contenedores son parecidos a las VMs pero más ligeros que la virtualización. Están desacoplados de la infraestructura que haya por debajo, lo que hace que funcionen sin problemas en distintos entornos.
Los contenedores trabajan de una forma similar a las máquinas virtuales. Por ejemplo, cuentan con su propio sistema de ficheros, parte de CPU y memoria entre otras cosas.
En la figura 1 presentada a continuación se puede observar la evolución de los entornos actuales tal y como se ha explicado anteriormente.
Figura 1 - Evolución de los diferentes entornos[1]
Para facilitar el despliegue de aplicaciones contenerizadas apareció un nuevo concepto: los orquestadores de contenedores. Un orquestador de contenedores es una herramienta que automatiza el despliegue, gestión, escalado, interconexión y disponibilidad de estas aplicaciones.[1]
Kubernetes es un orquestador de contenedores que ha ido ganando popularidad desde que se lanzó en 2014. Desde entonces, las empresas han ido cambiando el desarrollo tradicional de aplicaciones por las aplicaciones contenerizadas.
1 The Kubernetes Authors (2021), What is Kubernetes? Available: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/

2
La monitorización del clúster de Kubernetes es esencial para comprobar que el sistema y sus aplicaciones funcionan correctamente. Para ello existen diferentes herramientas que podemos utilizar como Prometheus (para definir alertas) y Grafana (para visualizar los datos).
El despliegue de un clúster de Kubernetes y las herramientas de monitorización son una tarea repetitiva por lo que es una buena idea pensar en la automatización. Ansible permite automatizar estas tareas, haciendo que cada vez que queramos desplegar un clúster el proceso sea rápido y esté exento de errores.
Por otro lado, con la virtualización se hizo famosa la computación en la nube. Este concepto se refiere a la prestación de servicios alojados a través de Internet.
Las nubes públicas son el tipo más común de informática en la nube. Tienen muchas ventajas; entre ellas, permiten que no se tenga que adquirir hardware ni software, pagar solo por el servicio que usa o que el proveedor de servicios se ocupe del mantenimiento, escalabilidad y disponibilidad.[2]
1.1 Objetivos del trabajo El objetivo principal del proyecto es familiarizarse con los conceptos de Kubernetes, nubes públicas y distintas herramientas muy utilizadas en estos entornos. Se aplicarán los conocimientos que he ido adquiriendo desde septiembre de 2020 en la empresa INETUM donde estoy realizando unas prácticas actualmente.
En este proyecto se desplegará un clúster de Kubernetes con su respectiva monitorización. El trabajo estará enfocado a la automatización, y más en concreto, al despliegue de las herramientas y herramientas de monitorización.
En la parte final del trabajo se plantea el diseño de un sistema de auto-reparación. Con las herramientas de monitorización que se van a utilizar, se presentará un sistema que permita automatizar la solución de algunos de los errores más comunes que puedan ocurrir.
La lista de tareas que van a llevarse a cabo en este proyecto es: Preparación del entorno en GCP Despliegue del clúster con kubeadm Despliegue de aplicaciones de monitorización: Prometheus y Grafana Prometheus: configuración de alertas Grafana: creación de dashboards (paneles de información) Despliegue de la base de datos: PostgreSQL Despliegue de aplicaciones de desarrollo Automatización de la reparación
2 Microsoft (2021), ¿Qué es la nube pública, privada e híbrida? Available: https://azure.microsoft.com/es-es/overview/what-are-private-public-hybrid-clouds/#public-cloud

3
2 Conceptos previos En este capítulo se explicarán las distintas herramientas que se van a utilizar a lo largo de este trabajo.
2.1.1 Nubes públicas Antes se han mencionado las nubes públicas. Dependiendo de las necesidades, hay distintas soluciones disponibles:
IaaS (Infraestructura como servicio): es una infraestructura informática inmediata que se aprovisiona y administra a través de Internet. Se puede escalar en función de la demanda permitiendo pagar solo por lo que se utiliza. Al no tener servidores propios físicos, evita el gasto y la complejidad que suponen la compra y administración de estos. El proveedor se encarga de la administración del sistema.[3]
PaaS (Plataforma como servicio): incluye IaaS y más servicios como, por ejemplo, bases de datos, middleware o herramientas de desarrollo. Es ideal para los desarrolladores que solo quieren centrarse en la implementación y desarrollo de sus aplicaciones, puesto que el desarrollador no tiene que preocuparse por los recursos y software.[4]
SaaS (Software como servicio): permite a los usuarios conectarse a aplicaciones basadas en la nube a través de Internet y usarlas. Ofrece una solución de software integral que se compra a un proveedor de servicios en la nube mediante un modelo de pago por uso.[5]
La figura 2 muestra las diferencias entre estos tres servicios:
Figura 2 - Distintos modelos de servicios en la nube
2.1.1.1 Google Cloud Platform Google Cloud Platform es la nube pública de Google. Es un conjunto de recursos físicos que se encuentran en los centros de datos de Google en todo el mundo.
Este proyecto se centrará en el modelo IaaS que ofrece Google. Se necesitará una infraestructura donde desplegar las VMs, discos y demás servicios que ofrece la plataforma. Para este trabajo se va a utilizar la prueba gratuita del servicio, que ofrece 300$ para examinar y evaluar todo el entorno. [5]
3 Microsoft (2021), ¿Qué es IaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-iaas/ 4 Microsoft (2021), ¿Qué es PaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-paas/ 5 Microsoft (2021), ¿Qué es SaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-saas/

4
2.1.2 Kubernetes Como ya se ha indicado anteriormente, este trabajo se basa en el uso de contenedores. Los contenedores son una buena forma de ejecutar aplicaciones y asegurarse de que hay una alta disponibilidad.
Kubernetes soluciona el problema de tener que estar pendiente del estado del contenedor. Es un orquestador de contenedores que ofrece un framework, permitiendo ejecutar servidores de una forma elástica. Se ocupa del escalado, deployment, balanceo de carga, registros y monitoreo.[1]
2.1.2.1 Arquitectura Un clúster de Kubernetes es un conjunto de máquinas de nodos que ejecutan aplicaciones en contenedores. Las máquinas de un clúster se pueden dividir en dos: el plano de control (masters) y los nodos worker. Todo clúster tiene al menos un nodo worker.
2.1.2.2 Objetos de Kubernetes Los objetos básicos de Kubernetes incluyen:
Pod: es un conjunto de uno o más contenedores implementados en un solo nodo. Son los objetos más pequeños y básicos, poseen recursos compartidos para la red y almacenamiento, y su objetivo es ejecutar una única instancia de la aplicación en el clúster.[6]
Servicio: es una forma de exponer una aplicación que se ejecuta en un conjunto de pods como servicio de una red.[7]
Volumen: los archivos en un contenedor son efímeros. Si un Pod crashea, los datos que no estén en un volumen persistente se perderán.[8]
Namespace: es un clúster virtual respaldado por el mismo clúster físico. Se denominan “espacios de nombres” (namespaces).[9]
Kubernetes también cuenta con abstracciones de nivel superior llamadas Controladores. Los controladores son bucles de control que observan el estado del clúster y ejecutan o solicitan los cambios que sean necesarios para alcanzar el estado deseado. Incluyen:
ReplicaSet: su propósito es mantener un conjunto estable de réplicas de Pods ejecutándose en todo momento, asegurando de esta forma la disponibilidad de un número específico de Pods idénticos.[10]
Deployment: proporciona actualizaciones declarativas para Pods y ReplicaSets.[11]
StatefulSet: gestiona el despliegue y escalado de un conjunto de Pods. Además, garantiza el orden y unicidad de dichos Pods.[12]
6 Google (2021), Pod. Available: https://cloud.google.com/kubernetes-engine/docs/concepts/pod 7 Red Hat, Inc. (2021), Learning Kubernetes basics. Available: https://www.redhat.com/en/topics/containers/learning-kubernetes-tutorial 8 The Kubernetes Authors (2021), Volumes. Available: https://kubernetes.io/docs/concepts/storage/volumes/ 9 The Kubernetes Authors (2021), Namespaces. Available: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/ 10 The Kubernetes Authors (2021), ReplicaSet. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/replicaset/ 11 The Kubernetes Authors (2021), Deployment. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/deployment/ 12 The Kubernetes Authors (2021), StatefulSets. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/statefulset/

5
DaemonSet: garantiza que todos (o algunos de) los nodos ejecuten una copia de un Pod.[13]
Job: crea uno o más Pods y se cerciora de que un número específico de ellos termine de forma satisfactoria.[14]
2.1.2.3 Componentes del plano de control Los componentes del plano de control toman decisiones sobre el clúster (por ejemplo, la planificación) y responden ante eventos que ocurran en el clúster (por ejemplo, iniciar un nuevo pod si el campo de las réplicas no se cumple).
Estos componentes se pueden ejecutar en cualquier nodo, pero por simplicidad estos nodos no ejecutan contenedores del usuario. [15]
La lista de componentes es la siguiente: kube-apiserver: el servidor de la API expone la API de Kubernetes. Es el
frontend de Kubernetes que recibe las peticiones y actualiza correctamente el estado en etcd. [15]
etcd: allí se almacenan los datos de configuración e información sobre el estado del clúster. Es una base de datos de almacenamiento de valor clave, distribuida y con tolerancia a los fallos, así como la principal fuente de información del clúster.[16]
kube-scheduler: monitoriza los Pods que no tienen ningún nodo asignado y selecciona uno donde ejecutar dicho(s) Pod(s). La decisión de en qué nodo se ejecutará depende de factores como los requisitos de recursos o las restricciones de hardware/software/políticas.[15]
kube-controller-manager: ejecuta los controladores de Kubernetes. [15] cloud-controller-manager: ejecuta controladores que interactúan con
proveedores de la nube. [15]
2.1.2.4 Componentes de nodo kubelet: es una aplicación muy pequeña que se comunica con el plano
de control y garantiza que sus contenedores se ejecuten en un pod. Cuando el plano de control necesita que algo suceda en un nodo, kubelet se encarga de ejecutarlo. [16]
kube-proxy: es un proxy de red que facilita los servicios de red. Administra las comunicaciones de red dentro y fuera del clúster. [16]
Runtime de contenedores: es el software responsable de ejecutar los contenedores. Soporta varios de ellos, incluyendo Docker y containerd. [15]
13 The Kubernetes Authors (2021), DaemonSet. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/daemonset/ 14 The Kubernetes Authors (2021), Jobs - Ejecución hasta el final. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/jobs-run-to-completion/ 15 The Kubernetes Authors (2021), Componentes de Kubernetes. Available: https://kubernetes.io/es/docs/concepts/overview/components/ 16 Red Hat, Inc. (2021), Introducción a la arquitectura de Kubernetes. Available: https://www.redhat.com/es/topics/containers/kubernetes-architecture

6
2.1.2.5 Resumen La figura 3[16] ofrece una imagen de los distintos elementos de un clúster:
Figura 3 - Elementos de un clúster de Kubernetes
2.1.3 Prometheus Prometheus es un conjunto de herramientas de monitoreo y alerta de sistemas de código abierto. Desde su inicio en 2012 ha sido adoptado por muchas empresas y organizaciones, contando con una comunidad de usuarios y desarrolladores muy activa.
Permite recolectar métricas usando un modelo de datos multidimensional e incluye un lenguaje de consulta flexible propio (PromQL).
La arquitectura de Prometheus con algunos de sus componentes se puede ver en la figura 4[17]:
Figura 4 – Arquitectura de Prometheus
17 Prometheus Authors (2021), What is Prometheus? Available: https://prometheus.io/docs/introduction/overview/

7
2.1.4 Grafana Grafana es un software de análisis y visualización de código abierto. Permite consultar, visualizar, alertar y explorar las métricas sin importar dónde estén almacenadas, además de convertir los datos de una base de datos (Prometheus en este caso) en paneles gráficos para poder visualizarlos.[18]
2.1.5 Ansible Ansible es un motor de automatización de código abierto que automatiza el aprovisionamiento en la nube, la gestión de la configuración, la implementación de las aplicaciones, entre otras cosas.
Está diseñado para describir cómo se interrelacionan todos sus sistemas en lugar de solo administrar un sistema a la vez.
Utiliza un lenguaje muy simple (YAML, en forma de Ansible-Playbooks) que permite realizar los trabajos de automatización de una forma sencilla.
Ansible funciona conectándose a sus nodos y distribuyendo pequeños programas llamados módulos, que están escritos para ser modelos de recursos del estado deseado de la máquina. Ansible ejecuta estos módulos y los elimina cuando termina.[19]
18 Grafana Labs (2021), What is Grafana? Available: https://grafana.com/docs/grafana/latest/getting-started/ 19 Red Hat, Inc. (2020), How Ansible Works. Available: https://www.ansible.com/overview/how-ansible-works

8
3 Desarrollo En este capítulo se desarrollarán los objetivos del proyecto. El punto de partida será crear la infraestructura en GCP, continuando después con la infraestructura de Kubernetes y el despliegue de una base de datos y aplicaciones para probar que el entorno funciona correctamente. Por último, se presentará el diseño de un sistema de auto-reparación del clúster.
3.1 Preparación del entorno en GCP Para instalar un clúster de Kubernetes primero se ha de preparar el entorno. Los requisitos a cumplir son:[20]
Una máquina Linux basada en Debian o Red Hat. 2 o más GB de RAM por máquina. 2 CPUs o más. Conectividad total entre todas las máquinas del clúster. Ciertos puertos abiertos en las máquinas. Swap desactivada
Para empezar, primero se configura la red en GCP.
3.1.1 Configuración de red Se debe tener conectividad total entre todas las máquinas del clúster, por lo que primero se procede a crear una subred para que todas las máquinas estén en la misma red.
Figura 5 - Creación de una subred en GCP
20 The Kubernetes Authors (2021), Installing kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
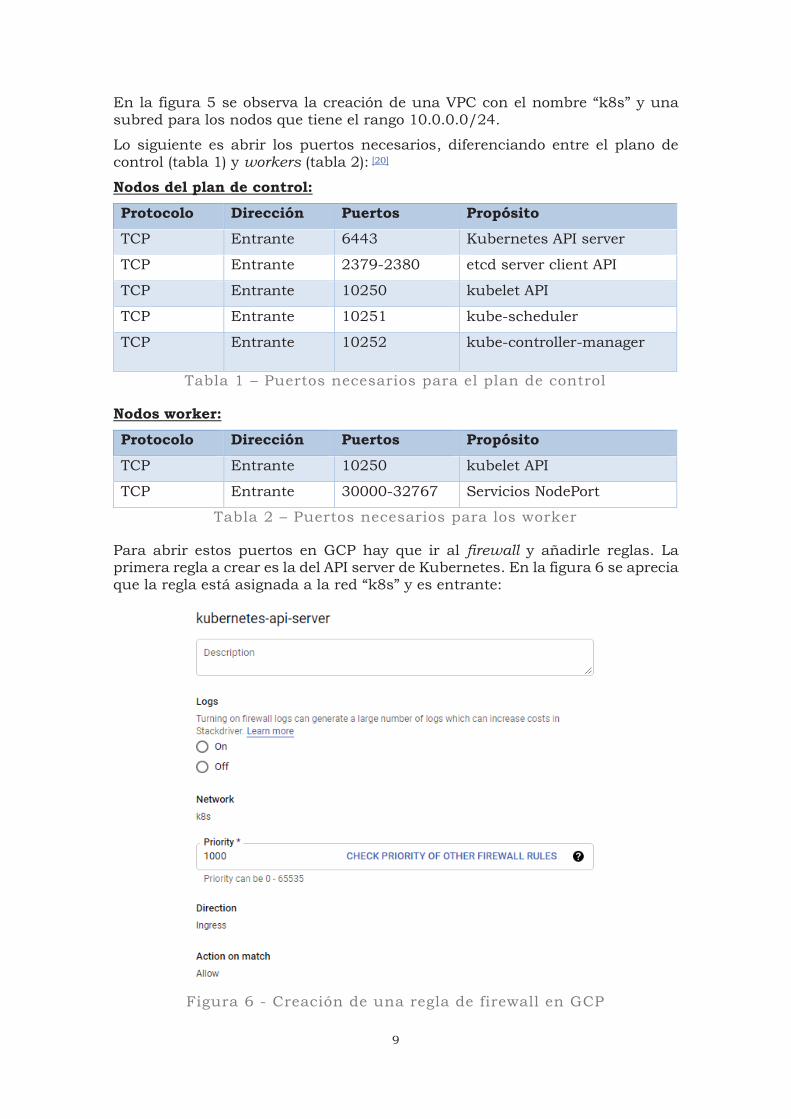
9
En la figura 5 se observa la creación de una VPC con el nombre “k8s” y una subred para los nodos que tiene el rango 10.0.0.0/24.
Lo siguiente es abrir los puertos necesarios, diferenciando entre el plano de control (tabla 1) y workers (tabla 2): [20]
Nodos del plan de control: Protocolo Dirección Puertos Propósito TCP Entrante 6443 Kubernetes API server
TCP Entrante 2379-2380 etcd server client API
TCP Entrante 10250 kubelet API
TCP Entrante 10251 kube-scheduler
TCP Entrante 10252 kube-controller-manager
Tabla 1 – Puertos necesarios para el plan de control
Nodos worker: Protocolo Dirección Puertos Propósito TCP Entrante 10250 kubelet API
TCP Entrante 30000-32767 Servicios NodePort
Tabla 2 – Puertos necesarios para los worker
Para abrir estos puertos en GCP hay que ir al firewall y añadirle reglas. La primera regla a crear es la del API server de Kubernetes. En la figura 6 se aprecia que la regla está asignada a la red “k8s” y es entrante:
Figura 6 - Creación de una regla de firewall en GCP
10
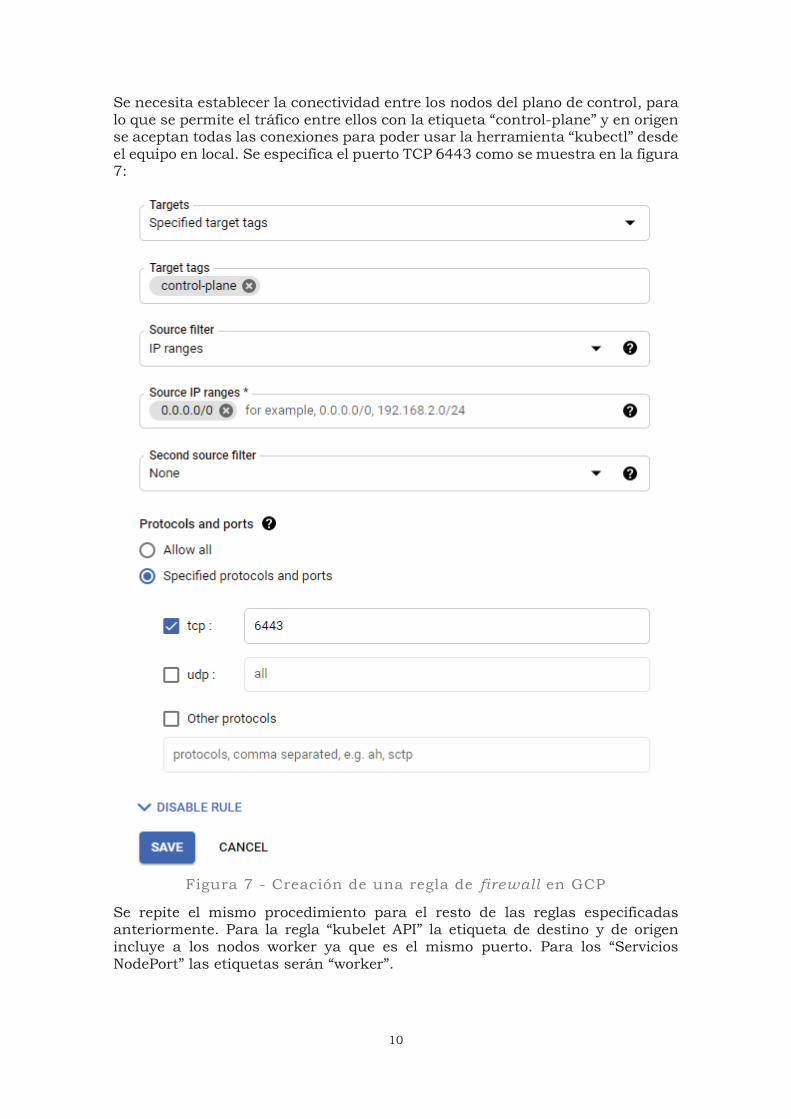
Se necesita establecer la conectividad entre los nodos del plano de control, para lo que se permite el tráfico entre ellos con la etiqueta “control-plane” y en origen se aceptan todas las conexiones para poder usar la herramienta “kubectl” desde el equipo en local. Se especifica el puerto TCP 6443 como se muestra en la figura 7:
Figura 7 - Creación de una regla de firewall en GCP
Se repite el mismo procedimiento para el resto de las reglas especificadas anteriormente. Para la regla “kubelet API” la etiqueta de destino y de origen incluye a los nodos worker ya que es el mismo puerto. Para los “Servicios NodePort” las etiquetas serán “worker”.

11
Las reglas finalmente quedarían configuradas como en la figura 8. Se ha añadido una regla que permite el acceso SSH (puerto 22) a todas las máquinas.
Figura 8 – Reglas firewall
3.1.2 Creación máquinas virtuales El objetivo es crear un clúster de alta disponibilidad de Kubernetes, por lo que se necesitarán tres nodos master. En caso de que se caiga un master, los otros dos nodos podrán seguir operando el clúster.[21]
Las máquinas a utilizar tendrán 2GB de RAM, 2 vCPUs, CentOs 7 de sistema operativo y 100GB de disco SSD. Al usar GCP, podrán incrementarse los recursos a medida se vaya necesitando más potencia.
En la figura 9 se ha configurado el primer nodo master del plan de control. La región utilizada ha sido Bélgica (europe-west1).
Figura 9 - Creación de una VM en GCP
21 The Kubernetes Authors (2021), Creating a cluster with kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
12
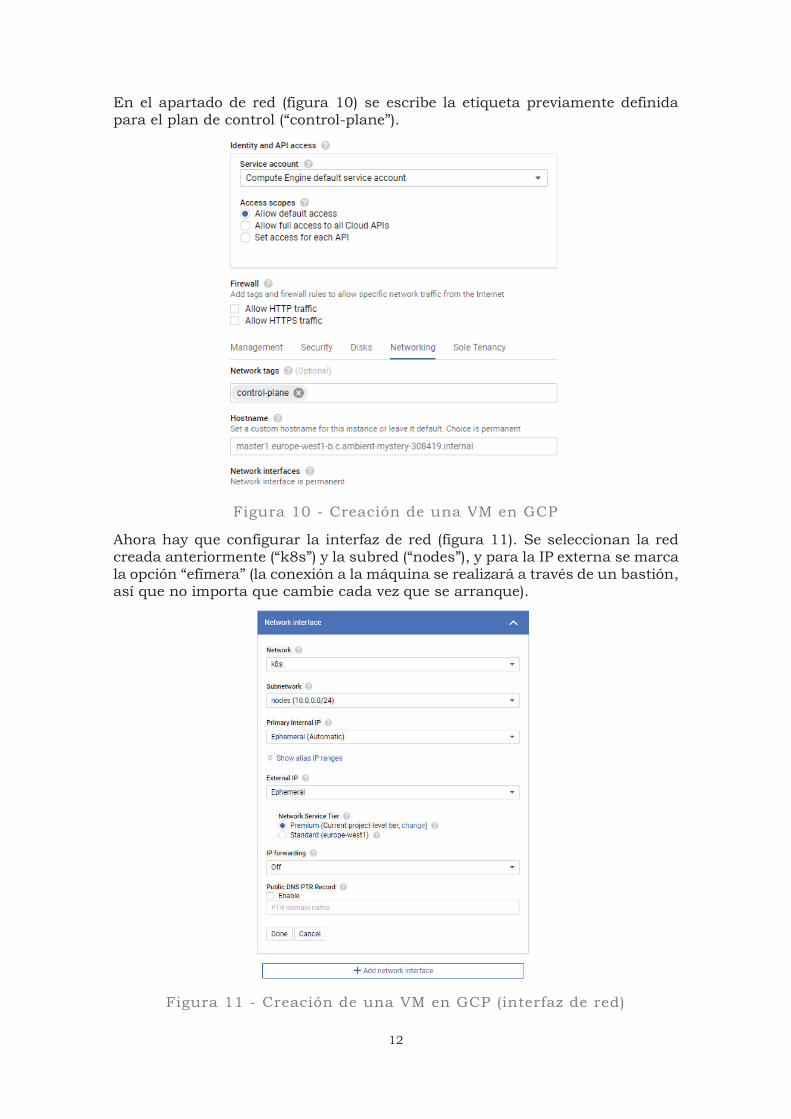
En el apartado de red (figura 10) se escribe la etiqueta previamente definida para el plan de control (“control-plane”).
Figura 10 - Creación de una VM en GCP
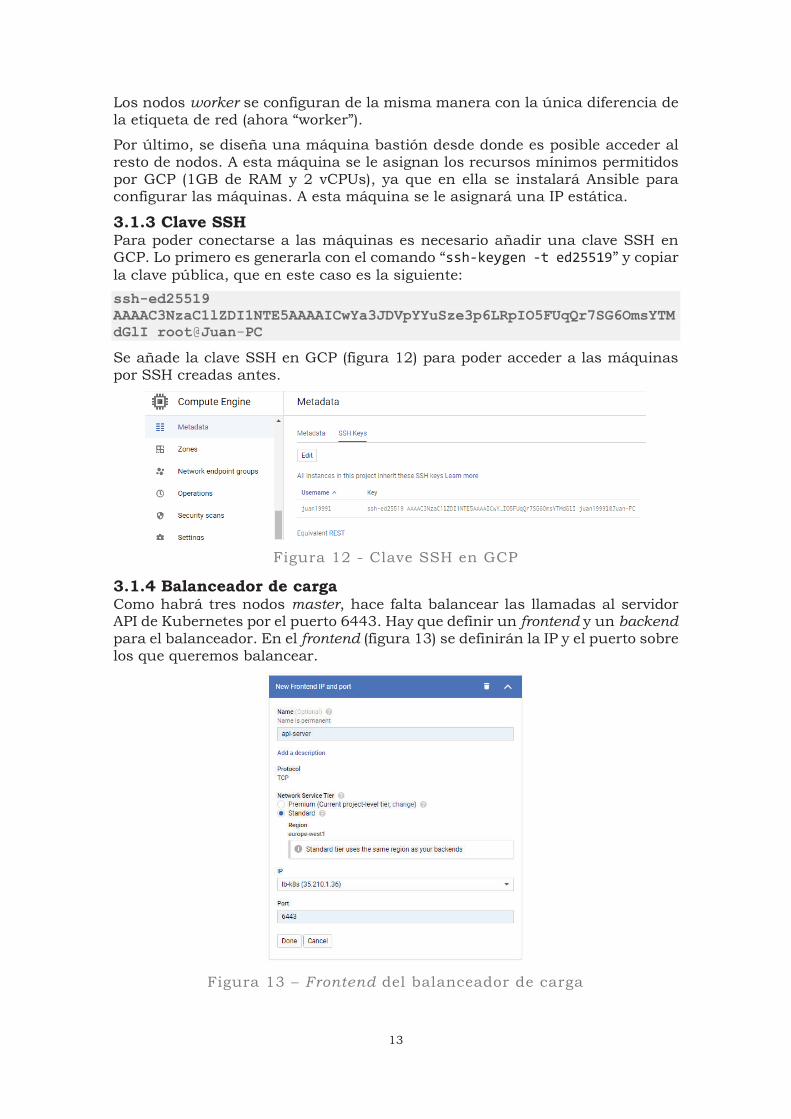
Ahora hay que configurar la interfaz de red (figura 11). Se seleccionan la red creada anteriormente (“k8s”) y la subred (“nodes”), y para la IP externa se marca la opción “efímera” (la conexión a la máquina se realizará a través de un bastión, así que no importa que cambie cada vez que se arranque).
Figura 11 - Creación de una VM en GCP (interfaz de red)
13
Los nodos worker se configuran de la misma manera con la única diferencia de la etiqueta de red (ahora “worker”).
Por último, se diseña una máquina bastión desde donde es posible acceder al resto de nodos. A esta máquina se le asignan los recursos mínimos permitidos por GCP (1GB de RAM y 2 vCPUs), ya que en ella se instalará Ansible para configurar las máquinas. A esta máquina se le asignará una IP estática.
3.1.3 Clave SSH Para poder conectarse a las máquinas es necesario añadir una clave SSH en GCP. Lo primero es generarla con el comando “ssh-keygen -t ed25519” y copiar la clave pública, que en este caso es la siguiente: ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAICwYa3JDVpYYuSze3p6LRpIO5FUqQr7SG6OmsYTMdGlI root@Juan-PC
Se añade la clave SSH en GCP (figura 12) para poder acceder a las máquinas por SSH creadas antes.
Figura 12 - Clave SSH en GCP
3.1.4 Balanceador de carga Como habrá tres nodos master, hace falta balancear las llamadas al servidor API de Kubernetes por el puerto 6443. Hay que definir un frontend y un backend para el balanceador. En el frontend (figura 13) se definirán la IP y el puerto sobre los que queremos balancear.
Figura 13 – Frontend del balanceador de carga
14
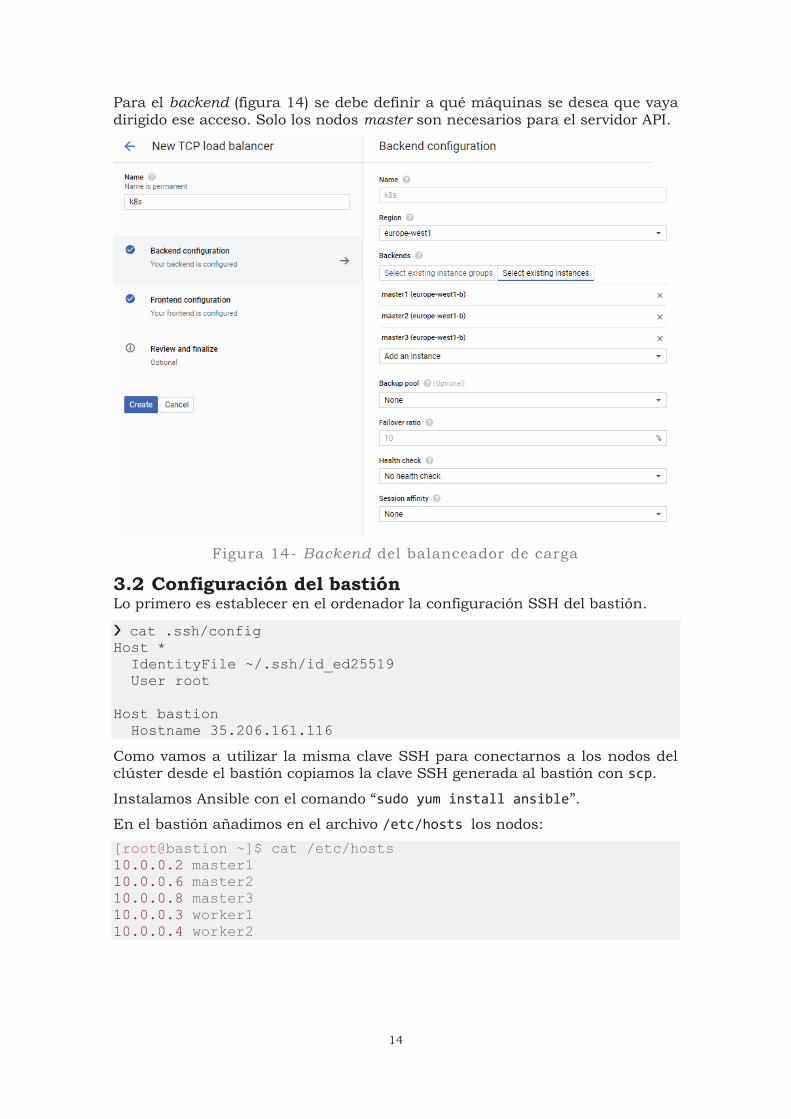
Para el backend (figura 14) se debe definir a qué máquinas se desea que vaya dirigido ese acceso. Solo los nodos master son necesarios para el servidor API.
Figura 14- Backend del balanceador de carga
3.2 Configuración del bastión Lo primero es establecer en el ordenador la configuración SSH del bastión.
cat .ssh/config Host * IdentityFile ~/.ssh/id_ed25519 User root Host bastion Hostname 35.206.161.116
Como vamos a utilizar la misma clave SSH para conectarnos a los nodos del clúster desde el bastión copiamos la clave SSH generada al bastión con scp.
Instalamos Ansible con el comando “sudo yum install ansible”.
En el bastión añadimos en el archivo /etc/hosts los nodos: [root@bastion ~]$ cat /etc/hosts 10.0.0.2 master1 10.0.0.6 master2 10.0.0.8 master3 10.0.0.3 worker1 10.0.0.4 worker2

15
3.3 Despliegue del clúster con kubeadm Ya está todo preparado para empezar con el despliegue del clúster. Para esta parte se va a desarrollar un rol de Ansible que permita configurar todos los nodos a la vez y automatizar la instalación para futuros despliegues.
Se va a seguir la guía de la documentación oficial de Kubernetes “Installing kubeadm”[20] y “Creating a cluster with kubeadm”.[21]
3.3.1 Inventario de Ansible El inventario de Ansible permite trabajar contra múltiples hosts al mismo tiempo. Se definirá todo el clúster en conjunto en [kube_cluster], los nodos master en [master], los nodos worker en [worker] y para el plano de control se separarán en master 1 ([control_plane_1]) y en los otros dos master ([control_plane_2_and_3]).
[kube_cluster] master1 ansible_host=10.0.0.2 ansible_user=root master2 ansible_host=10.0.0.6 ansible_user=root master3 ansible_host=10.0.0.8 ansible_user=root worker1 ansible_host=10.0.0.3 ansible_user=root worker2 ansible_host=10.0.0.4 ansible_user=root [master] master1 master2 master3 [worker] worker1 worker2 [control_plane_1] master1 [control_plane_2_and_3] master2 master3
3.3.2 Creación del rol para el despliegue del clúster Se dividirá el rol en diferentes playbooks de Ansible. Lo primero es cambiar el hostname a los nodos.
customize_hostname.yaml:
- name: Change master names hostname: name: "{{ item }}" with_items: - "{{ groups['master'] }}" - name: Change worker names hostname: name: "{{ item }}" with_items: - "{{ groups['worker'] }}"
16
La siguiente tarea es preparar el Sistema Operativo (CentOS 7). Se precisa desactivar el servicio del firewall, deshabilitar SELinux en todos los nodos, desactivar la memoria swap, instalar Docker, actualizar todos los paquetes de las máquinas y, por último, reiniciarlas.
customize_os.yaml: # Stop and Disable Firewall service in all K8S cluster nodes - name: Stop service firewalld, if started service: name: firewalld state: stopped enabled: no when: inventory_hostname in groups['kube_cluster'] # Stop and Disable SELinux on all K8S cluster nodes - name: disable SELinux command: setenforce 0 ignore_errors: yes when: inventory_hostname in groups['kube_cluster'] - name: disable SELinux on reboot selinux: state: disabled when: inventory_hostname in groups['kube_cluster'] # Disable swap on all K8S cluster nodes - name: disable swap command: swapoff -a when: inventory_hostname in groups['kube_cluster'] # Remove swap entry from /etc/fstab from all K8S cluster nodes - name: Remove swapfile from /etc/fstab mount: name: swap fstype: swap state: absent when: inventory_hostname in groups['kube_cluster'] # Enable EPEL Repo on all K8S cluster nodes - name: install EPEL Repo yum: name: epel-release state: present update_cache: true when: inventory_hostname in groups['kube_cluster'] # Install Docker on all K8S cluster nodes using remote repo link (this is to make sure we install recommended Docker version) - name: install Docker from a remote repo yum: name: docker state: present when: inventory_hostname in groups['kube_cluster']

17
# Start Docker service on all K8S cluster nodes - name: start Docker service: name: docker enabled: yes state: started when: inventory_hostname in groups['kube_cluster'] # Update all packages - name: upgrade all packages yum: name: '*' state: latest when: inventory_hostname in groups['kube_cluster'] # Restart all VMs - name: Rebooting VMs reboot: when: inventory_hostname in groups['kube_cluster']
El siguiente paso es instalar kubelet (aplicación que se comunica con el plano de control) y kubeadm (para realizar el despliegue del clúster).
install-kube-tools.yaml:
# Add Kubernetes YUM Repo on all K8S cluster nodes - name: add Kubernetes YUM repository yum_repository: name: Kubernetes description: Kubernetes YUM repository baseurl: https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 gpgkey: https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg gpgcheck: yes when: inventory_hostname in groups['kube_cluster'] # Install kubelet on all K8S cluster nodes - name: install kubelet yum: name: - kubelet state: present when: inventory_hostname in groups['kube_cluster'] # Install kubeadm on all K8S cluster nodes - name: install kubadm yum: name: - kubeadm state: present when: inventory_hostname in groups['kube_cluster']

18
# Start kubelet service on all K8S cluster nodes - name: start kubelet service: name: kubelet enabled: yes state: started when: inventory_hostname in groups['kube_cluster']
Los paquetes tienen que ser procesados por las iptables de los nodos para el filtro de paquetes, reenviado de puertos y que los pods puedan comunicarse entre ellos.
copy_k8s-conf.yaml:
- name: copy k8s config file template: src: k8s.conf dest: '/usr/lib/sysctl.d/90-override.conf' mode: 0644 when: inventory_hostname in groups['kube_cluster'] - name: charge sysctl vars shell: sysctl -p /usr/lib/sysctl.d/90-override.conf register: sysctlvars when: inventory_hostname in groups['kube_cluster'] - name: viewing sysctl vars stdout debug: msg: "{{sysctlvars.stdout}}" when: inventory_hostname in groups['kube_cluster']
k8s.conf:
net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1
Ahora los nodos ya se encuentran preparados y listos para hacer el despliegue con kubeadm. Hay que inicializar el primer nodo del plano de control, que es la máquina donde sus componentes se ejecutan (incluyendo etcd y API server).
Debido a que el objetivo es diseñar un clúster con alta disponibilidad es necesario pasarle al comando “kubeadm init” el parámetro “--control-plane-endpoint 35.206.161.116:6443” con la dirección del balanceador de carga que ha sido creado antes y el puerto del servidor de la API.
kubeadm_init_master.yaml:[22]
- name: kubeadm init control-plane-1 shell: kubeadm init --pod-network-cidr 192.168.0.0/16 --control-plane-endpoint "{{ lb.lb_dns }}":"{{ lb.lb_port }}" --upload-certs > $HOME/kubeadm_init.log when: inventory_hostname in groups['control_plane_1']
22 The Kubernetes Authors (2021), Creating Highly Available clusters with kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/

19
- name: get create cluster stdout shell: tail -26 $HOME/kubeadm_init.log register: kubeadminit when: inventory_hostname in groups['control_plane_1'] - name: show kubeadm init stdout debug: msg: "{{kubeadminit.stdout_lines}}" when: inventory_hostname in groups['control_plane_1'] - pause: seconds=20 - name: create kube dir shell: mkdir -p $HOME/.kube when: inventory_hostname in groups['control_plane_1'] - name: copy admin conf shell: cp -i /etc/kubernetes/admin.conf $HOME/.kube/config when: inventory_hostname in groups['control_plane_1'] - name: change permissions shell: chown $(id -u):$(id -g) $HOME/.kube/config when: inventory_hostname in groups['control_plane_1'] - name: export KUBECONFIG var shell: export KUBECONFIG=$HOME/.kube/config when: inventory_hostname in groups['control_plane_1'] - name: deploy networkd pods shell: kubectl apply -f "https://cloud.weave.works/k8s/net" when: inventory_hostname in groups['control_plane_1'] - debug: msg: - "Waiting to all pods running." - pause: seconds=60 - name: check control-plane-1 node status shell: kubectl get nodes register: getnodes when: inventory_hostname in groups['control_plane_1'] - name: show check status debug: msg: "{{getnodes.stdout_lines}}" when: inventory_hostname in groups['control_plane_1']

20
El siguiente paso es incluir el resto de nodos master al plano de control. Cuando “kubeadm init” termina, genera un comando para unir el resto de nodos al plano de control. Para ello se captura el output de “kubeadm init” del primer nodo para usarlo en los demás nodos.
kubeadm_join_masters.yaml:
- name: get create cluster stdout shell: grep -B2 "control-plane --certificate-key" $HOME/kubeadm_init.log | sed 's/\\//g' | sed ':a;N;$!ba;s/\n/ /g' | sed -e 's/ \+/ /g' | sed 's/^ //' register: kubeadmjoin delegate_to: master1 - name: kubeadm join control-plane-2-3 shell: "{{kubeadmjoin.stdout_lines[0]}} > $HOME/kubeadm_init.log" when: inventory_hostname in groups['control_plane_2_and_3'] - name: get create cluster stdout shell: tail -26 $HOME/kubeadm_init.log when: inventory_hostname in groups['control_plane_2_and_3'] - debug: msg: - "Waiting to all pods running." - pause: seconds=60 - name: create kube dir shell: mkdir -p $HOME/.kube when: inventory_hostname in groups['control_plane_2_and_3'] - name: copy admin conf shell: cp -i /etc/kubernetes/admin.conf $HOME/.kube/config when: inventory_hostname in groups['control_plane_2_and_3'] - name: change permissions shell: chown $(id -u):$(id -g) $HOME/.kube/config when: inventory_hostname in groups['control_plane_2_and_3'] - name: export KUBECONFIG var shell: export KUBECONFIG=$HOME/.kube/config when: inventory_hostname in groups['control_plane_2_and_3'] - name: check control-plane-2 node status shell: kubectl get nodes register: getnodes when: inventory_hostname in groups['control_plane_2_and_3'] - name: show check status debug: msg: "{{getnodes.stdout_lines}}" when: inventory_hostname in groups['control_plane_2_and_3']

21
Una vez finalizados los nodos master, es el turno de incluir en el clúster los nodos worker. En el output del comando “kubeadm init” también queda indicado cómo añadir los nodos worker al clúster así que, de una forma similar, se capturará el output del comando y se ejecutará en los nodos worker.
kubeadm_join_computes.yaml:
- name: get create cluster stdout shell: grep -B1 "discovery-token-ca-cert-hash" $HOME/kubeadm_init.log | head -2 | sed 's/\\//g' | sed ':a;N;$!ba;s/\n/ /g' | sed -e 's/ \+/ /g' | sed 's/^ //' register: kubeadmjoin delegate_to: master1 - name: kubeadm join workers shell: "{{ kubeadmjoin.stdout_lines[0]}} > $HOME/kubeadm_join.log" when: inventory_hostname in groups['worker'] - name: get create cluster stdout shell: tail -6 $HOME/kubeadm_join.log register: kubeadmjoin when: inventory_hostname in groups['worker'] - name: show kubeadm join stdout debug: msg: "{{kubeadmjoin.stdout_lines}}" when: inventory_hostname in groups['worker'] - debug: msg: - "Waiting to all pods running." - pause: seconds=60
Se comprueba que los nodos se han añadido correctamente al clúster.
check_workers.yaml:
- name: check cluster nodes status shell: kubectl get nodes register: getnodes when: inventory_hostname in groups['control_plane_1'] - name: show check nodes status debug: msg: "{{getnodes.stdout_lines}}" when: inventory_hostname in groups['control_plane_1']

22
Para terminar, es preciso instalar un plugin que nos maneje el CNI (Container Network Interface). Se trata de una interfaz entre un runtime de contenedores y un plugin de red (configura el runtime de contenedores con la red).[23]
deploy-calico.yaml: - name: deploy calico shell: kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml when: inventory_hostname in groups['control_plane_1']
En la figura 15 se muestra el clúster ya inicializado con todos los nodos funcionando y en la última versión de Kubernetes (v1.21 a la hora de escribir este documento).
Figura 15 – Nodos del clúster
Ahora que el clúster ya está preparado se procede a crear una cuenta de servicio para poder operar el clúster con la herramienta “kubectl” desde el ordenador local.
3.3.3 Cuenta de servicio Se implementará el control de acceso basado en roles, que permite regular el acceso a los recursos en función del rol de los usuarios.[24]
Una cuenta de servicio de Kubernetes es un recurso de Kubernetes que se crea y administra con la API de Kubernetes. Está destinada a ser utilizada por entidades creadas por Kubernetes en el clúster para realizar la autenticación al servidor de la API de Kubernetes o a servicios externos.[25]
Se creará una cuenta con permisos de administrador para administrar el clúster sin necesidad de un servidor intermedio (el bastión) con los siguientes comandos:
1. kubectl create serviceaccount clusteradmin 2. kubectl create clusterrolebinding clusteradmin --
serviceaccount=default:clusteradmin --clusterrole=cluster-admin
23 vikram fugro (26 de septiembre de 2018), Container Networking Interface aka CNI. Available: https://cotigao.medium.com/container-networking-interface-aka-cni-bdfe23f865cf 24 The Kubernetes Authors (2021), Using RBAC Authorization. Available: https://kubernetes.io/docs/reference/access-authn-authz/rbac/ 25 Google (2021), Usa cuentas de servicio de Kubernetes. Available: https://cloud.google.com/kubernetes-engine/docs/how-to/kubernetes-service-accounts?hl=es-419

23
Se obtiene el token desde un nodo master que se acaba de crear para usarlo en el ordenador:
1. TOKEN=$(kubectl describe secrets "$(kubectl describe serviceaccount clusteradmin | grep -i Tokens | awk '{print $2}')" | grep token: | awk '{print $2}')
Por último, se selecciona como servidor por defecto el que ha sido creado en la máquina:
1. kubectl config set-credentials clusteradmin --token=$TOKEN 2. kubectl config set-cluster gcp-cluster --
server=https://35.210.1.36:6443 --insecure-skip-tls-verify=true 3. kubectl config set-context clusteradmin-gcp-cluster --cluster=gcp-
cluster --user=clusteradmin 4. kubectl config use-context clusteradmin-gcp-cluster
3.4 Despliegue aplicaciones monitorización: Prometheus y Grafana
Las aplicaciones de Prometheus y Grafana tienen que guardar datos por lo que necesitan un volumen persistente. Se generará un servidor NFS en el bastión para que las aplicaciones puedan compartir datos entre todos los nodos.
3.4.1 Persistencia de los datos Se podría utilizar un volumen NFS en GCP, pero en este proyecto se ha optado por desplegar uno propio en la máquina bastión para no gastar todo el crédito de la prueba gratuita.
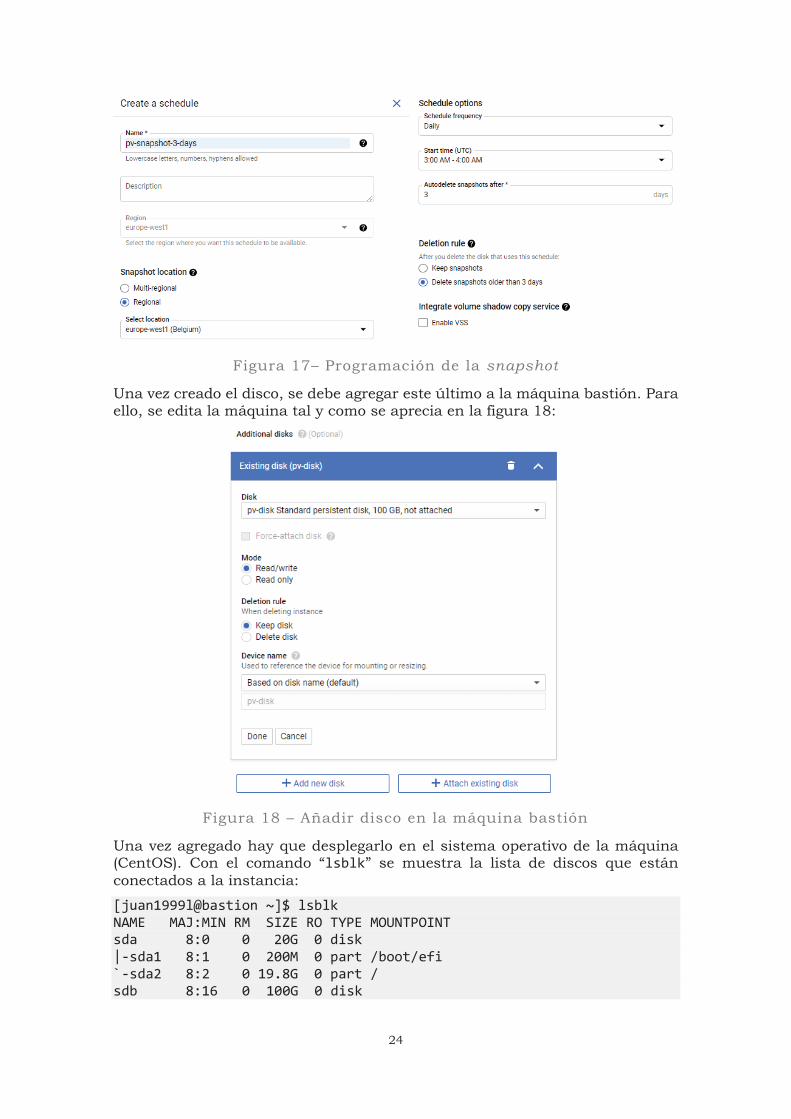
Se crea un disco en GCP donde se guardarán los datos persistentes que puedan requerir las aplicaciones. Se utilizará un disco HDD de 100 GB (figura 16) del que se hará una snapshot todos los días y guardarán los últimos 3 (figura 17).
Figura 16 – Creación de un disco en GCP
24
Figura 17– Programación de la snapshot
Una vez creado el disco, se debe agregar este último a la máquina bastión. Para ello, se edita la máquina tal y como se aprecia en la figura 18:
Figura 18 – Añadir disco en la máquina bastión
Una vez agregado hay que desplegarlo en el sistema operativo de la máquina (CentOS). Con el comando “lsblk” se muestra la lista de discos que están conectados a la instancia:
[juan1999l@bastion ~]$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk |-sda1 8:1 0 200M 0 part /boot/efi `-sda2 8:2 0 19.8G 0 part / sdb 8:16 0 100G 0 disk

25
Se observa ver que el disco “sdb” es el que se acaba de acoplar a la instancia. Se procede a formatear el disco con la herramienta “mkfs”:
sudo mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb
Por último, se monta el disco cuando la máquina se inicie. Mediante el comando “sudo blkid /dev/sdb” se obtiene el UUID del disco. Es necesario editar el archivo “/etc/fstab” para montar el disco al inicio de la máquina. Se añade la siguiente información al archivo:
UUID=eece0c63-bf71-41a9-8669-b8f3221275f6 /mnt/disks/pv-disk ext4 discard,defaults,nofail 0 2
Se introducen el UUID obtenido anteriormente, el directorio donde queremos montar el disco (/mnt/disks/pv-disk), el sistema de archivos (ext4) y las diferentes opciones a la hora de montarlo.
Se reinicia la instancia y se comprueba con el comando “lsblk” que el disco ha sido montado correctamente: “sdb 8:16 0 100G 0 disk /mnt/disks/pv-disk”. [26]
3.4.1.1 Servidor NFS Con el disco ya montado es hora de configurar el servidor NFS. En el bastión se debe instalar el servidor (yum install nfs-utils) y otorgarle permisos a la carpeta donde se ha montado el disco (chmod -R 755 /mnt/disks/pv-disk y chown nfsnobody:nfsnobody /mnt/disks/pv-disk). Lo siguiente es iniciar y habilitar el servicio al inicio de la instancia: [27] [28]
1. systemctl enable rpcbind 2. systemctl enable nfs-server 3. systemctl enable nfs-lock 4. systemctl enable nfs-idmap 5. systemctl start rpcbind 6. systemctl start nfs-server systemctl 7. start nfs-lock 8. systemctl start nfs-idmap
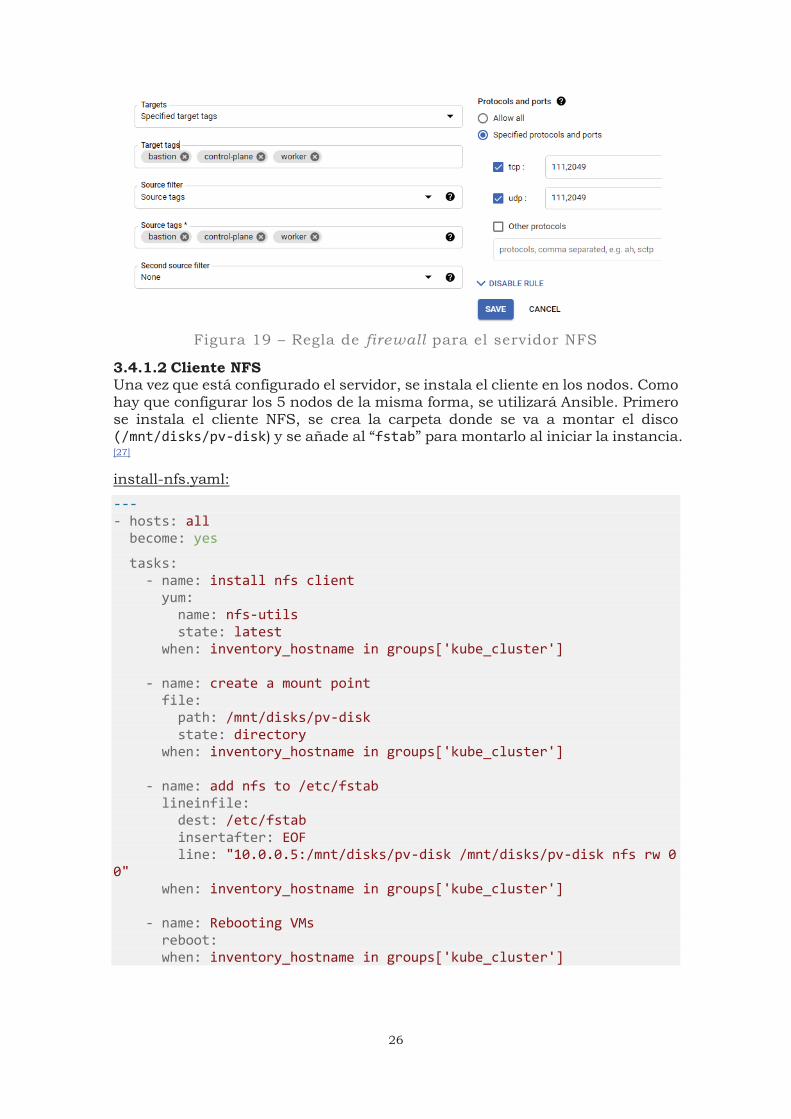
Se añade la carpeta a compartir en el archivo “/etc/exports”. Se otorgan también permisos de lectura y escritura (rw), de manera que todas las instancias puedan acceder (se podría restringir a las IPs de los nodos, *): /mnt/disks/pv-disk/ *(rw,sync,no_subtree_check,no_root_squash) Es necesario configurar algunos puertos para permitir el tráfico entre los nodos por los puertos que usa el servidor NFS (figura 19). Por defecto los puertos que usa el servidor NFS son 111 y 2049 (TCP y UDP).
26 Google (2021), Crea y conecta un disco. Available: https://cloud.google.com/compute/docs/disks/add-persistent-disk?hl=es-419 27 Srijan Kishore, NFS Server and Client Installation on CentOS 7. Available: https://www.howtoforge.com/nfs-server-and-client-on-centos-7 28 Nikolaj Goodger (27 de abril de 2018), NFS Filestore on GCP for free. Available: https://medium.com/@ngoodger_7766/nfs-filestore-on-gcp-for-free-859593e18bdf
26
Figura 19 – Regla de firewall para el servidor NFS
3.4.1.2 Cliente NFS Una vez que está configurado el servidor, se instala el cliente en los nodos. Como hay que configurar los 5 nodos de la misma forma, se utilizará Ansible. Primero se instala el cliente NFS, se crea la carpeta donde se va a montar el disco (/mnt/disks/pv-disk) y se añade al “fstab” para montarlo al iniciar la instancia.
[27]
install-nfs.yaml:
--- - hosts: all become: yes
tasks: - name: install nfs client yum: name: nfs-utils state: latest when: inventory_hostname in groups['kube_cluster'] - name: create a mount point file: path: /mnt/disks/pv-disk state: directory when: inventory_hostname in groups['kube_cluster'] - name: add nfs to /etc/fstab lineinfile: dest: /etc/fstab insertafter: EOF line: "10.0.0.5:/mnt/disks/pv-disk /mnt/disks/pv-disk nfs rw 0 0" when: inventory_hostname in groups['kube_cluster'] - name: Rebooting VMs reboot: when: inventory_hostname in groups['kube_cluster']

27
Se comprueba con la herramienta “df -h” que se ha montado correctamente en las máquinas: [juan1999l@worker1 ~]$ df -h 10.0.0.5:/mnt/disks/pv-disk 99G 60M 99G 1% /mnt/disks/pv-disk [juan1999l@master1 ~]$ df -h 10.0.0.5:/mnt/disks/pv-disk 99G 60M 99G 1% /mnt/disks/pv-disk
Además, para verificar que funciona, se procede a crear un archivo desde el nodo master1 y a analizarlo en el nodo worker1: [juan1999l@master1 ~]$ nano /mnt/disks/pv-disk/prueba.txt Esto es una prueba [juan1999l@worker1 ~]$ cat /mnt/disks/pv-disk/prueba.txt Esto es una prueba
Como se puede comprobar, los archivos se comparten sin problemas. El siguiente paso es configurar el servidor NFS en el clúster de Kubernetes.
3.4.1.3 NFS en el clúster El objetivo es poder provisionar de forma dinámica volúmenes persistentes para las aplicaciones. Se despliega la aplicación “Kubernetes NFS Subdir External Provisioner”[29] en el clúster que nos facilita la integración de un servidor NFS con el clúster.
Para desplegar la aplicación utilizaremos Helm. Helm es un administrador de paquetes para Kubernetes que permite gestionar recursos empaquetados y preconfigurados, además de unas plantillas que facilitan la instalación de cualquier objeto de Kubernetes.[30]
Para instalar la aplicación que queremos se designará un namespace para una mejor organización. Se creará mediante el comando “kubectl create namespace nfs-provisioner” y se establecerá como el namespace que será utilizado por defecto con “kubectl config set-context --current --namespace=nfs-provisioner”.
Con los siguientes comandos se despliega la aplicación. El primer comando añade el repositorio donde está la aplicación y el segundo la instala. De acuerdo con los parámetros del segundo comando, se le asigna a la aplicación la dirección IP del bastión donde se encuentra el servidor NFS (35.206.161.116) y la ruta donde se desea montar el disco (/mnt/disks/pv-disk).
1. helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
2. helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set nfs.server=35.206.161.116 --set nfs.path=/mnt/disks/pv-disk
29 Kubernetes SIGs (2021), Kubernetes NFS Subdir External Provisioner [Source code]. https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner 30 Helm Authors (2021), What is Helm? Available: https://helm.sh/

28
Para comprobar que se ha instalado correctamente, se observarán los objetos que ha creado y se desplegará un volumen persistente de prueba. Se aprecia que se ha desplegado un Pod en el namespace que hemos generado, y también un StorageClass (esto es, un recurso utilizado para diferenciar y delimitar los niveles de almacenamiento y usos):
kubectl get pods NAME READY nfs-subdir-external-provisioner-bffd78b8c-zgszn 1/1
STATUS RESTARTS AGE
Running 2 41h
kubectl get sc NAME PROVISIONER nfs-client cluster.local/nfs-subdir-external-provisioner
RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
Delete Immediate true 41h
Se creará un volumen persistente por medio del recién creado StorageClass:
create-pvc.yaml:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: claim1 spec: accessModes: - ReadWriteOnce storageClassName: nfs-client resources: requests: storage: 5Gi
kubectl apply -f create-pvc.yaml persistentvolumeclaim/claim1 created
kubectl get pvc NAME STATUS VOLUME CAPACITY claim1 Bound pvc-cc043889-82bf-4fe2-ab2b-1d0694a61f0a 5Gi
ACCESS MODES STORAGECLASS AGE
RWO nfs-client 5s
kubectl get pv NAME CAPACITY ACCESS MODES pvc-cc043889-82bf-4fe2-ab2b-1d0694a61f0a 5Gi RWO
RECLAIM POLICY STATUS CLAIM STORAGECLASS
Delete Bound nfs-provisioner/claim1 nfs-client
REASON AGE
6s

29
Como se observa, el volumen se crea correctamente. Se procede a establecer el StorageClass que se ha creado como el que se usará por defecto mediante el siguiente comando:
kubectl patch storageclass nfs-client -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
Ahora que ya se ha preparado la persistencia de los datos de las aplicaciones en Kubernetes, es posible instalar las aplicaciones de monitorización.
3.4.2 Instalación Prometheus Para la instalación de Prometheus también se utilizará Helm. Se instalarán Prometheus y Grafana en el mismo namespace para una mejor organización. Para ello, se usan los siguientes comandos; el primero crea el namespace y el segundo lo configura como el namespace por defecto:
kubectl create namespace monitoring namespace/monitoring created kubectl config set-context --current --namespace=monitoring Context "clusteradmin-gcp-cluster" modified.
Lo primero que hay que hacer con Helm es añadir el repositorio de Prometheus y actualizar todos los repositorios:[31]
1. helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
2. helm repo add stable https://charts.helm.sh/stable 3. helm repo update
Se definen unos parámetros para la instalación. El primero indica que se requiere un volumen persistente de 25Gb para el servidor de Prometheus y el segundo indica un volumen persistente de 10Gb para el Alertmanager (controla las alertas que manda el servidor de Prometheus). Los otros dos parámetros sirven para señalar que los servicios sean del tipo NodePort:
helm install prometheus prometheus-community/prometheus \ --set server.persistentVolume.size=25Gi \ --set alertmanager.persistentVolume.size=10Gi \ --set server.service.type=NodePort \ --set alertmanager.service.type=NodePort
Para probar que la aplicación está funcionando se abre en local, redireccionando por SSH un puerto desde el ordenador en cuestión hacia el que está expuesto en el nodo.[32]
kubectl get svc NAME TYPE CLUSTER-IP PORT(S) AGE prometheus-server NodePort 10.104.62.244 80:31462 /TCP 3m6s
31 Prometheus Monitoring Community (2021), Helm Charts [Source code]. https://github.com/prometheus-community/helm-charts 32 Vladimir Kaplarevic (18 de mayo de 2020), How to Use SSH Port Forwarding. Available: https://phoenixnap.com/kb/ssh-port-forwarding
30
Como se aprecia, la aplicación está funcionando en el puerto 32453, así que se redirige con el siguiente comando:
ssh -L 30080:35.210.116.69:31462 35.210.116.69
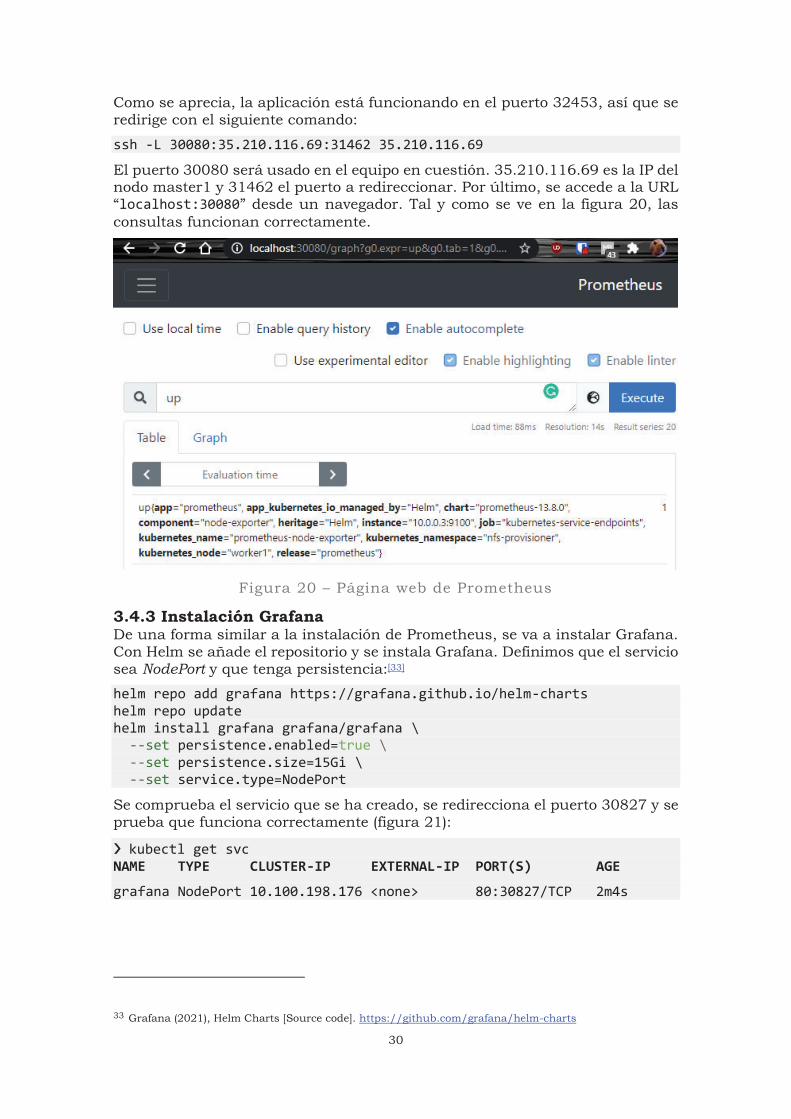
El puerto 30080 será usado en el equipo en cuestión. 35.210.116.69 es la IP del nodo master1 y 31462 el puerto a redireccionar. Por último, se accede a la URL “localhost:30080” desde un navegador. Tal y como se ve en la figura 20, las consultas funcionan correctamente.
Figura 20 – Página web de Prometheus
3.4.3 Instalación Grafana De una forma similar a la instalación de Prometheus, se va a instalar Grafana. Con Helm se añade el repositorio y se instala Grafana. Definimos que el servicio sea NodePort y que tenga persistencia:[33]
helm repo add grafana https://grafana.github.io/helm-charts helm repo update helm install grafana grafana/grafana \ --set persistence.enabled=true \ --set persistence.size=15Gi \ --set service.type=NodePort
Se comprueba el servicio que se ha creado, se redirecciona el puerto 30827 y se prueba que funciona correctamente (figura 21):
kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.100.198.176 <none> 80:30827/TCP 2m4s
33 Grafana (2021), Helm Charts [Source code]. https://github.com/grafana/helm-charts
31
Figura 21 – Página web de Grafana
Lo último que queda por hacer es conseguir la contraseña de la cuenta “admin” de Grafana:
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
3.5 Prometheus: configuración de alertas Lo siguiente es definir unas alertas que den un aviso si el clúster no está funcionando de forma normal.
3.5.1 Configuración Alertmanager Antes de empezar a definir las alertas, se debe configurar un conector del Alertmanager con Microsoft Teams. Se edita el ConfigMap (que guarda datos no confidenciales del tipo clave-valor[34]) del Alertmanager con el comando “kubectl edit cm prometheus-alertmanager”, cambiando las siguientes líneas:[35]
data: alertmanager.yml: | global: {} receivers: - name: prometheus-msteams webhook_configs: - send_resolved: true http_config: {} url: http://prometheus-msteams.monitoring.svc.cluster.local:2000/alertmanager max_alerts: 0 templates: [] route: receiver: prometheus-msteams group_by:
34 The Kubernetes Authors (2021), ConfigMaps. Available: https://kubernetes.io/docs/concepts/configuration/configmap/ 35 lapee79's Tech Blog (2 de Agosto de 2019), Alerts of the Prometheus Alertmanager with MS Teams. Available: https://lapee79.github.io/en/article/prometheus-alertmanager-with-msteams/

32
- job routes: - receiver: prometheus-msteams match: alertname: Watchdog group_interval: 5m group_wait: 30s repeat_interval: 12h
Con esto queda configurado Alertmanager para que envíe alertas usando un servicio que se va a desplegar a continuación. El siguiente paso es instalar el conector de Prometheus con Microsoft Teams.
3.5.2 Instalación conector Se necesita un archivo de configuración que se le pasará a la instalación de Helm. Para la configuración se precisará un webhook que se obtendrá de un conector en un equipo de Teams.[36]
config.yaml:
--- replicaCount: 1 image: repository: quay.io/prometheusmsteams/prometheus-msteams tag: v1.4.1 connectors: - alertmanager: https://upm365.webhook.office.com/webhookb2/22da7552-1194-44fe-9c01-a1ccc0cc5f31@6afea85d-c323-4270-b69d-a4fb3927c254/IncomingWebhook/5689a654eac34ece8e3e0db4f90eccda/c73fe70b-1004-49ae-bd14-36d21f9ece9e
container: additionalArgs: - -debug
Se instalará el conector con Helm:[36] 1. helm repo add prometheus-msteams https://prometheus-
msteams.github.io/helm-chart 2. helm repo update 3. helm install prometheus-msteams prometheus-msteams/prometheus-
msteams -f config.yaml
Ya se encuentra todo configurado. Ahora hay que establecer las alertas en Prometheus.
36 prometheus-msteams (2021), prometheus-msteams [Source code]. https://github.com/prometheus-msteams/prometheus-msteams/blob/master/chart/prometheus-msteams/README.md

33
3.5.3 Configuración alertas En esta sección se definirán algunas métricas para monitorizar el clúster. Para ello se ha de modificar el ConfigMap “prometheus-server” con “kubectl edit cm prometheus-server”. Hay que añadir en el apartado “rules” lo siguiente para agrupar las alertas en un grupo:
rules: | groups: - name: k8s alerts rules:
Los valores y métricas que se van a monitorizar son los mostrados en la tabla 3:
Alerta Umbral Nodo caído Más de 3 mediciones consecutivas
Espacio ocupado en disco (nodos y servidor NFS)
Superior a 85%
Volumen persistente tiene poco espacio
Superior a 85%
Uso de CPU en los nodos Superior a 85%
Uso de CPU en los pods Superior a 85%
Uso de memoria en los nodos Superior a 85%
Número de réplicas bajo en un pod Más de 3 mediciones consecutivas
Bucle de reinicios en un pod Más de 3 mediciones consecutivas
Estado etcd Más de 3 mediciones consecutivas
Estado API Server Más de 3 mediciones consecutivas
Tabla 3 – Alertas definidas para Prometheus
Con las alertas ya definidas se puede comenzar su implementación. Se debe editar el ConfigMap mencionado anteriormente y luego añadir las consultas debajo de la sección “rules”.
A continuación se explica cómo se han configurado las alertas (para ver el código completo del ConfigMap, dirigirse al anexo).
Nodo caído:
Como se aprecia en la figura 22, se ha definido una alerta con el nombre “Kubernetes node down”. La consulta que se realiza es “up{component="node-exporter"} == 0”. Gracias a ella se muestra la métrica “up” filtrando por el componente “node-exporter” que devuelve un 1 o un 0 en función de si el nodo está activo o no, respectivamente. Se le añade una etiqueta para indicar que se trata de algo crítico, además de definir un título y escribir una descripción para la alerta. La alerta es analizada durante 3 mediciones consecutivas de 1 minuto entre mediciones.
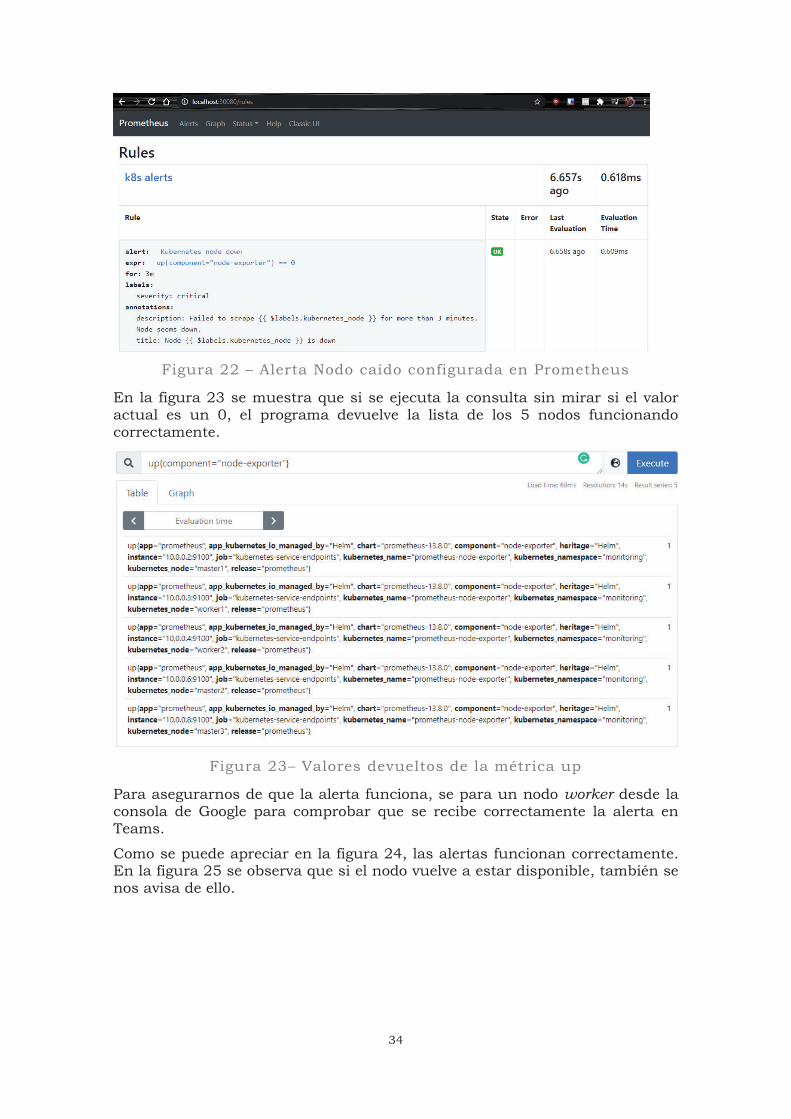
34
Figura 22 – Alerta Nodo caído configurada en Prometheus
En la figura 23 se muestra que si se ejecuta la consulta sin mirar si el valor actual es un 0, el programa devuelve la lista de los 5 nodos funcionando correctamente.
Figura 23– Valores devueltos de la métrica up
Para asegurarnos de que la alerta funciona, se para un nodo worker desde la consola de Google para comprobar que se recibe correctamente la alerta en Teams.
Como se puede apreciar en la figura 24, las alertas funcionan correctamente. En la figura 25 se observa que si el nodo vuelve a estar disponible, también se nos avisa de ello.

35
Figura 24– Alerta nodo worker2 caído
Figura 25 – Alerta solucionada nodo worker2 caído
36
Espacio ocupado en disco:
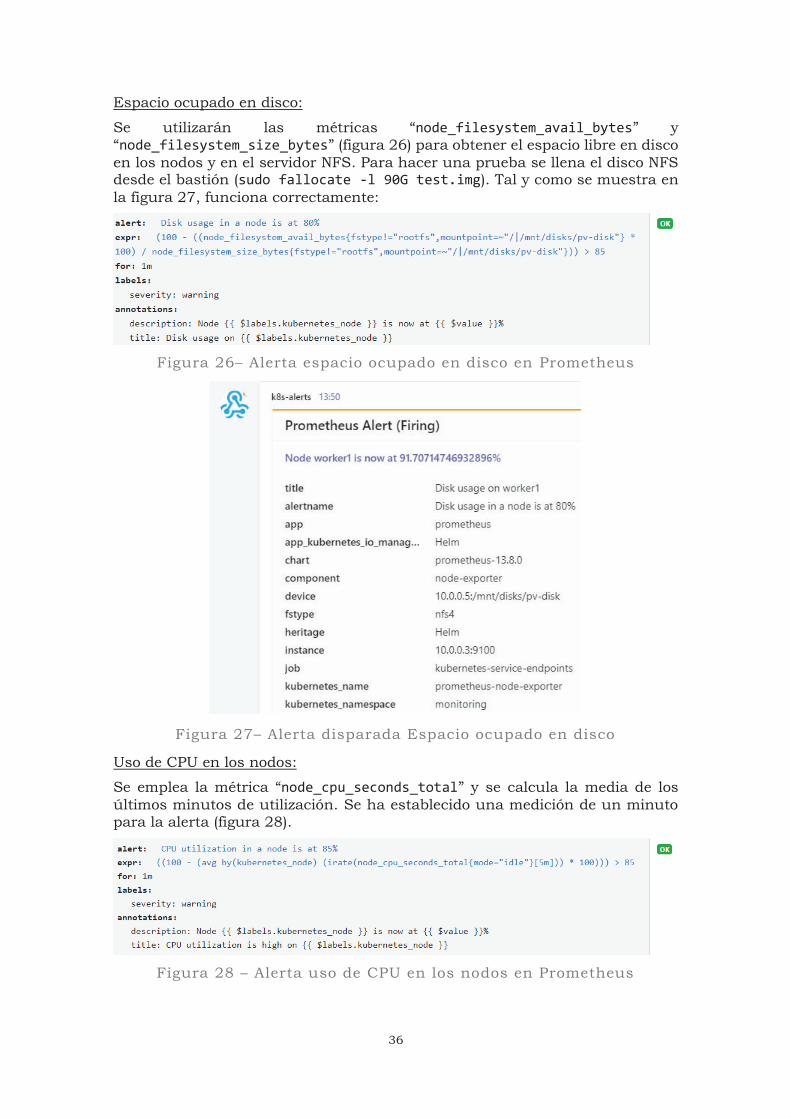
Se utilizarán las métricas “node_filesystem_avail_bytes” y “node_filesystem_size_bytes” (figura 26) para obtener el espacio libre en disco en los nodos y en el servidor NFS. Para hacer una prueba se llena el disco NFS desde el bastión (sudo fallocate -l 90G test.img). Tal y como se muestra en la figura 27, funciona correctamente:
Figura 26– Alerta espacio ocupado en disco en Prometheus
Figura 27– Alerta disparada Espacio ocupado en disco
Uso de CPU en los nodos:
Se emplea la métrica “node_cpu_seconds_total” y se calcula la media de los últimos minutos de utilización. Se ha establecido una medición de un minuto para la alerta (figura 28).
Figura 28 – Alerta uso de CPU en los nodos en Prometheus
37
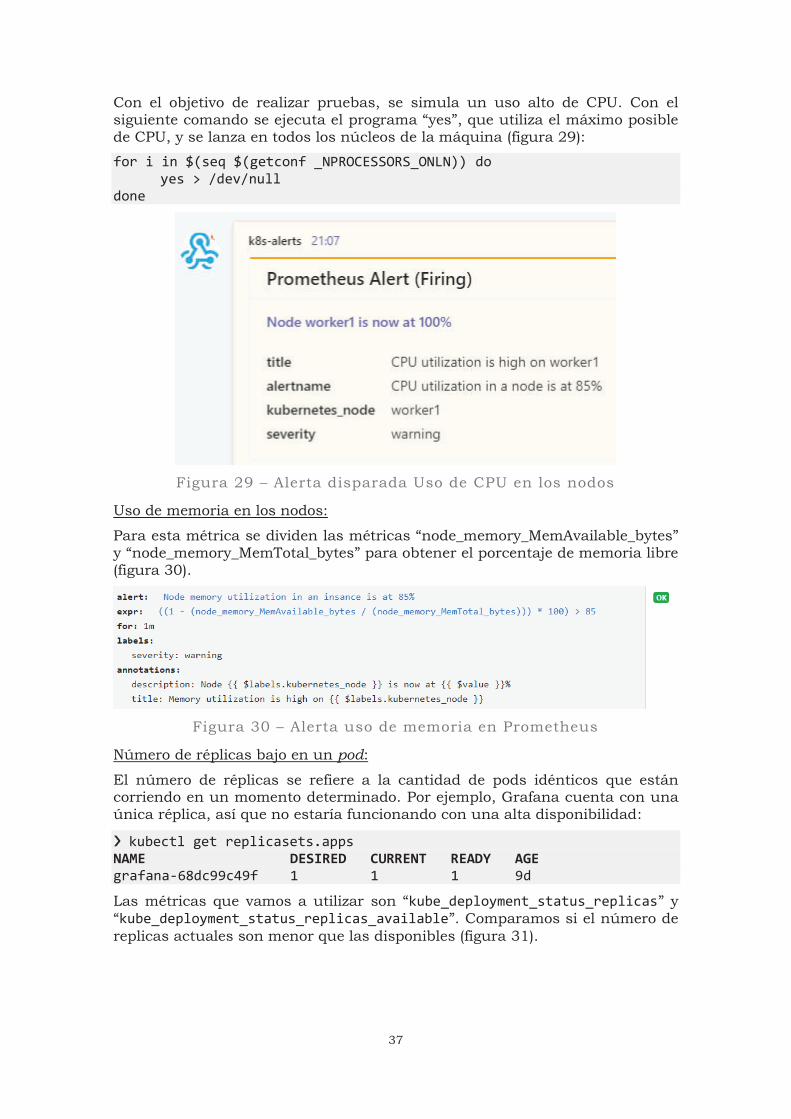
Con el objetivo de realizar pruebas, se simula un uso alto de CPU. Con el siguiente comando se ejecuta el programa “yes”, que utiliza el máximo posible de CPU, y se lanza en todos los núcleos de la máquina (figura 29):
for i in $(seq $(getconf _NPROCESSORS_ONLN)) do yes > /dev/null
done
Figura 29 – Alerta disparada Uso de CPU en los nodos
Uso de memoria en los nodos:
Para esta métrica se dividen las métricas “node_memory_MemAvailable_bytes” y “node_memory_MemTotal_bytes” para obtener el porcentaje de memoria libre (figura 30).
Figura 30 – Alerta uso de memoria en Prometheus
Número de réplicas bajo en un pod:
El número de réplicas se refiere a la cantidad de pods idénticos que están corriendo en un momento determinado. Por ejemplo, Grafana cuenta con una única réplica, así que no estaría funcionando con una alta disponibilidad:
kubectl get replicasets.apps NAME DESIRED CURRENT READY AGE grafana-68dc99c49f 1 1 1 9d
Las métricas que vamos a utilizar son “kube_deployment_status_replicas” y “kube_deployment_status_replicas_available”. Comparamos si el número de replicas actuales son menor que las disponibles (figura 31).
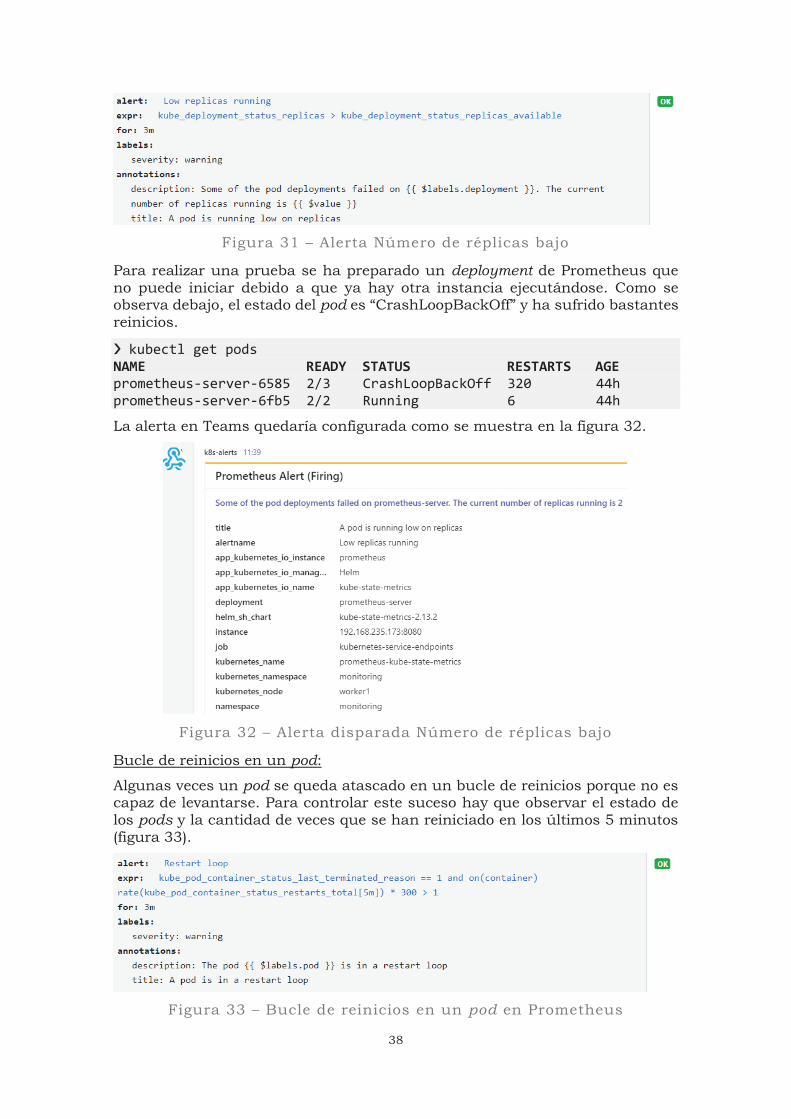
38
Figura 31 – Alerta Número de réplicas bajo
Para realizar una prueba se ha preparado un deployment de Prometheus que no puede iniciar debido a que ya hay otra instancia ejecutándose. Como se observa debajo, el estado del pod es “CrashLoopBackOff” y ha sufrido bastantes reinicios.
kubectl get pods NAME READY STATUS RESTARTS AGE prometheus-server-6585 2/3 CrashLoopBackOff 320 44h prometheus-server-6fb5 2/2 Running 6 44h
La alerta en Teams quedaría configurada como se muestra en la figura 32.
Figura 32 – Alerta disparada Número de réplicas bajo
Bucle de reinicios en un pod: Algunas veces un pod se queda atascado en un bucle de reinicios porque no es capaz de levantarse. Para controlar este suceso hay que observar el estado de los pods y la cantidad de veces que se han reiniciado en los últimos 5 minutos (figura 33).
Figura 33 – Bucle de reinicios en un pod en Prometheus
39
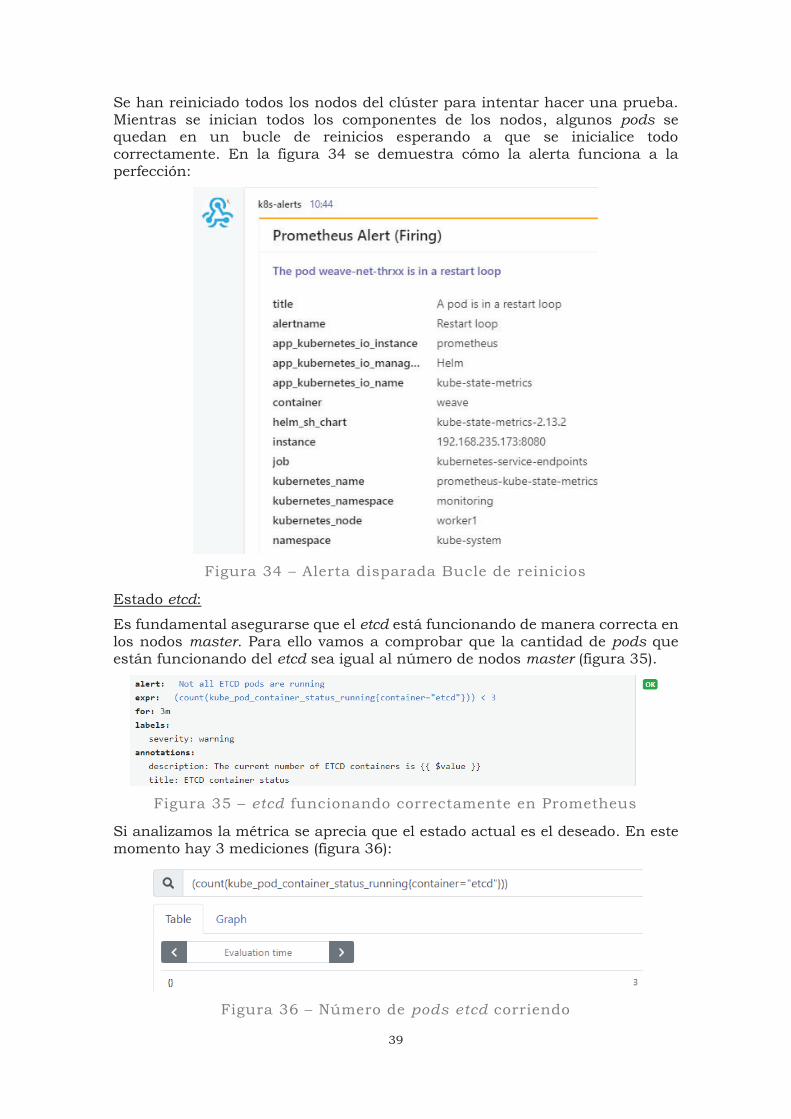
Se han reiniciado todos los nodos del clúster para intentar hacer una prueba. Mientras se inician todos los componentes de los nodos, algunos pods se quedan en un bucle de reinicios esperando a que se inicialice todo correctamente. En la figura 34 se demuestra cómo la alerta funciona a la perfección:
Figura 34 – Alerta disparada Bucle de reinicios
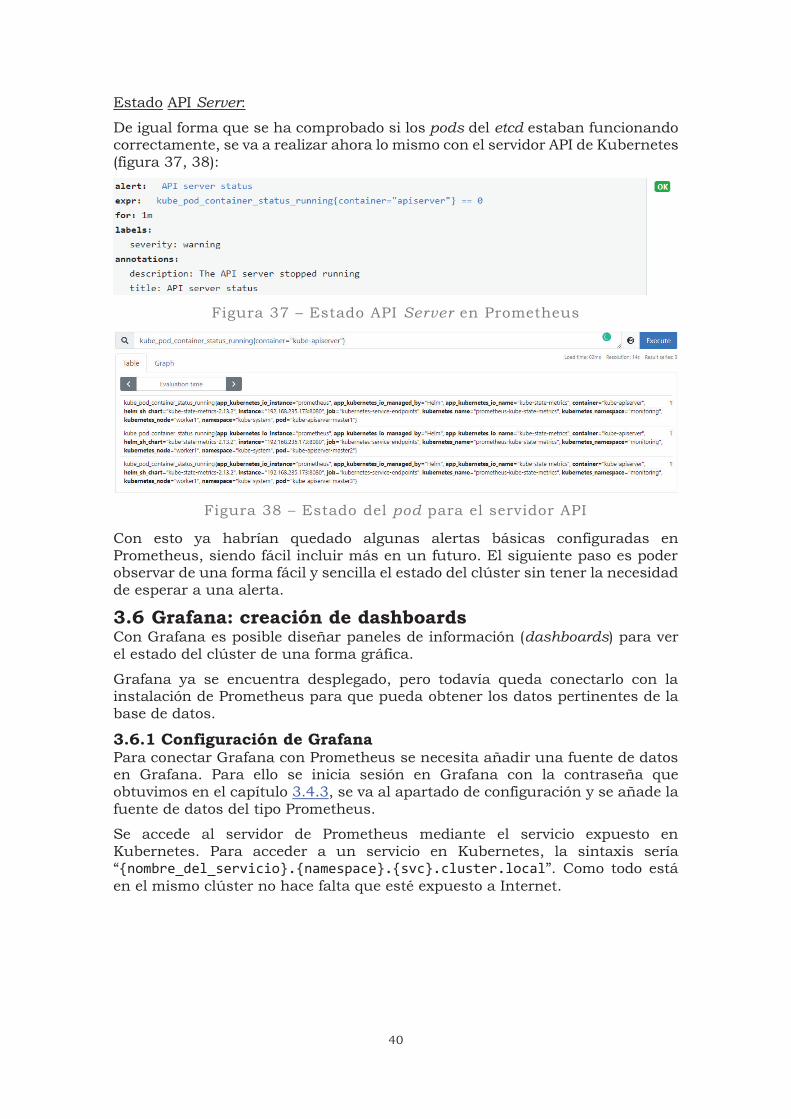
Estado etcd:
Es fundamental asegurarse que el etcd está funcionando de manera correcta en los nodos master. Para ello vamos a comprobar que la cantidad de pods que están funcionando del etcd sea igual al número de nodos master (figura 35).
Figura 35 – etcd funcionando correctamente en Prometheus
Si analizamos la métrica se aprecia que el estado actual es el deseado. En este momento hay 3 mediciones (figura 36):
Figura 36 – Número de pods etcd corriendo
40
Estado API Server:
De igual forma que se ha comprobado si los pods del etcd estaban funcionando correctamente, se va a realizar ahora lo mismo con el servidor API de Kubernetes (figura 37, 38):
Figura 37 – Estado API Server en Prometheus
Figura 38 – Estado del pod para el servidor API
Con esto ya habrían quedado algunas alertas básicas configuradas en Prometheus, siendo fácil incluir más en un futuro. El siguiente paso es poder observar de una forma fácil y sencilla el estado del clúster sin tener la necesidad de esperar a una alerta.
3.6 Grafana: creación de dashboards Con Grafana es posible diseñar paneles de información (dashboards) para ver el estado del clúster de una forma gráfica.
Grafana ya se encuentra desplegado, pero todavía queda conectarlo con la instalación de Prometheus para que pueda obtener los datos pertinentes de la base de datos.
3.6.1 Configuración de Grafana Para conectar Grafana con Prometheus se necesita añadir una fuente de datos en Grafana. Para ello se inicia sesión en Grafana con la contraseña que obtuvimos en el capítulo 3.4.3, se va al apartado de configuración y se añade la fuente de datos del tipo Prometheus.
Se accede al servidor de Prometheus mediante el servicio expuesto en Kubernetes. Para acceder a un servicio en Kubernetes, la sintaxis sería “{nombre_del_servicio}.{namespace}.{svc}.cluster.local”. Como todo está en el mismo clúster no hace falta que esté expuesto a Internet.
41
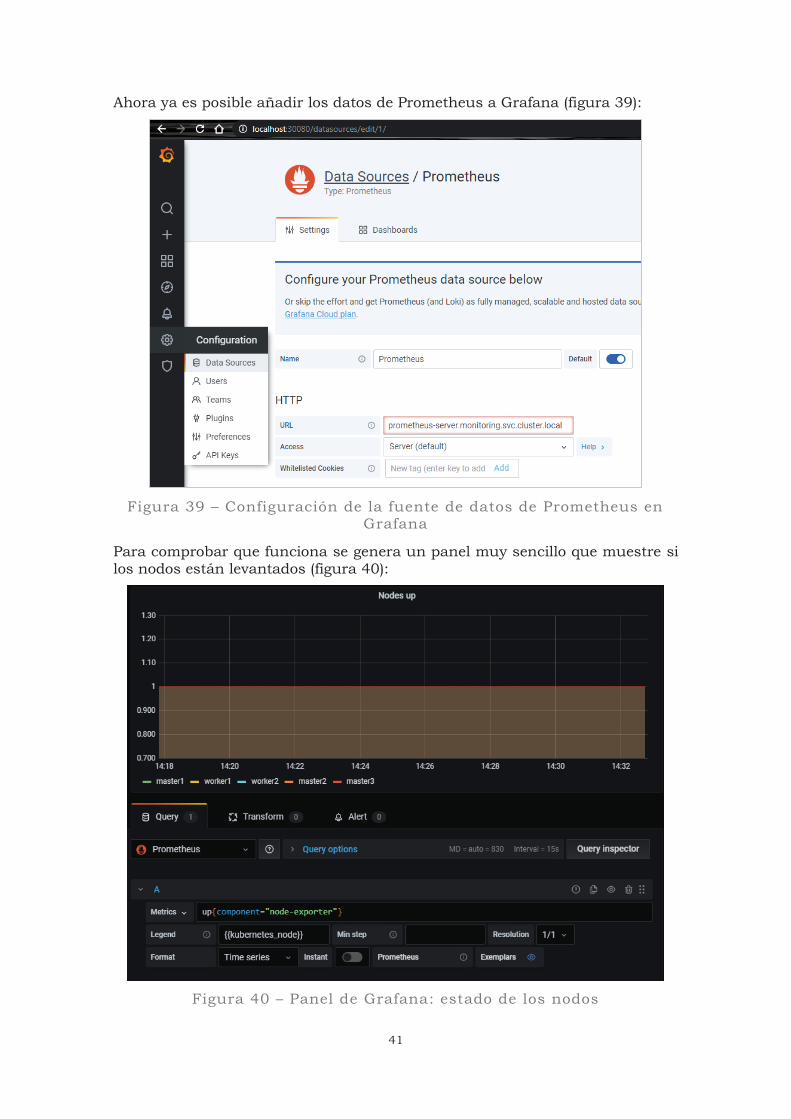
Ahora ya es posible añadir los datos de Prometheus a Grafana (figura 39):
Figura 39 – Configuración de la fuente de datos de Prometheus en
Grafana
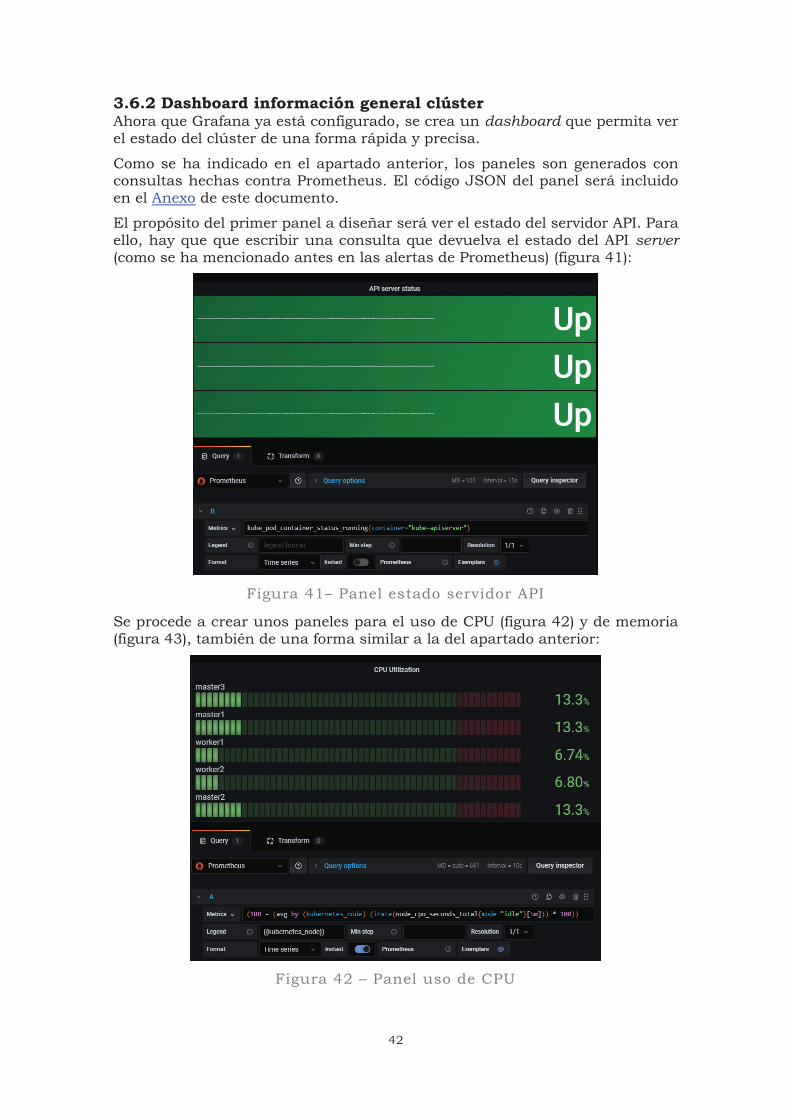
Para comprobar que funciona se genera un panel muy sencillo que muestre si los nodos están levantados (figura 40):
Figura 40 – Panel de Grafana: estado de los nodos
42
3.6.2 Dashboard información general clúster Ahora que Grafana ya está configurado, se crea un dashboard que permita ver el estado del clúster de una forma rápida y precisa.
Como se ha indicado en el apartado anterior, los paneles son generados con consultas hechas contra Prometheus. El código JSON del panel será incluido en el Anexo de este documento.
El propósito del primer panel a diseñar será ver el estado del servidor API. Para ello, hay que que escribir una consulta que devuelva el estado del API server (como se ha mencionado antes en las alertas de Prometheus) (figura 41):
Figura 41– Panel estado servidor API
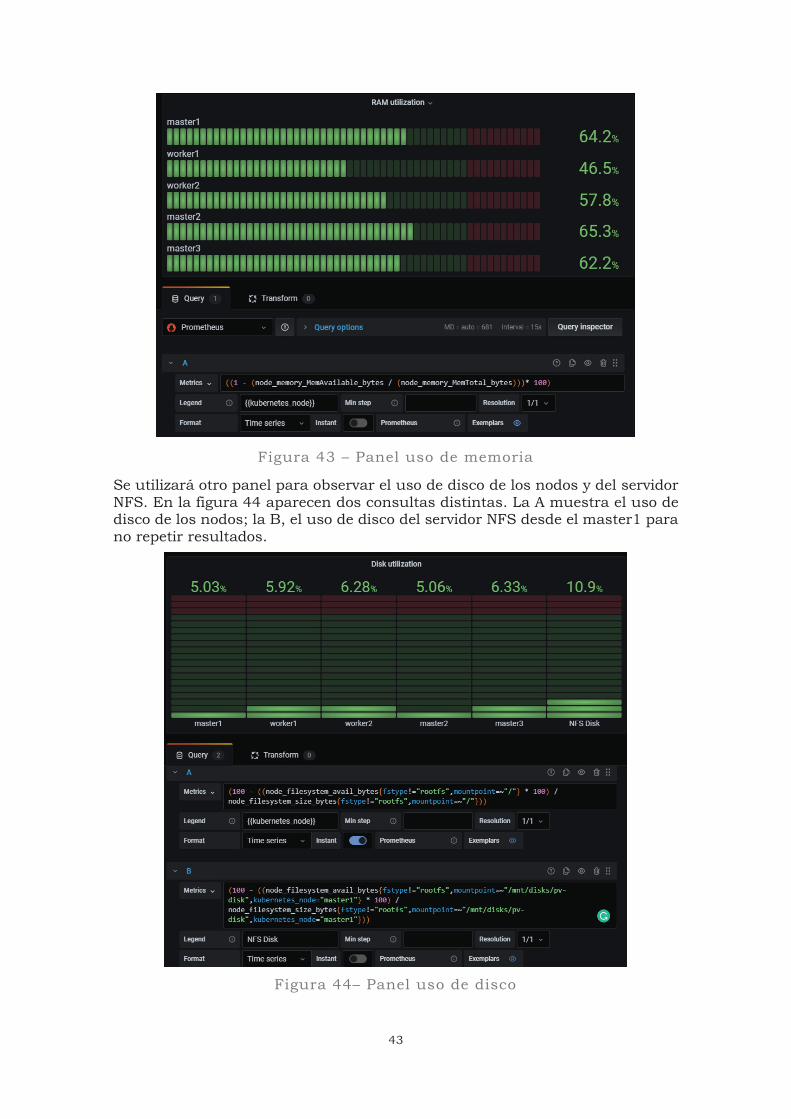
Se procede a crear unos paneles para el uso de CPU (figura 42) y de memoria (figura 43), también de una forma similar a la del apartado anterior:
Figura 42 – Panel uso de CPU
43
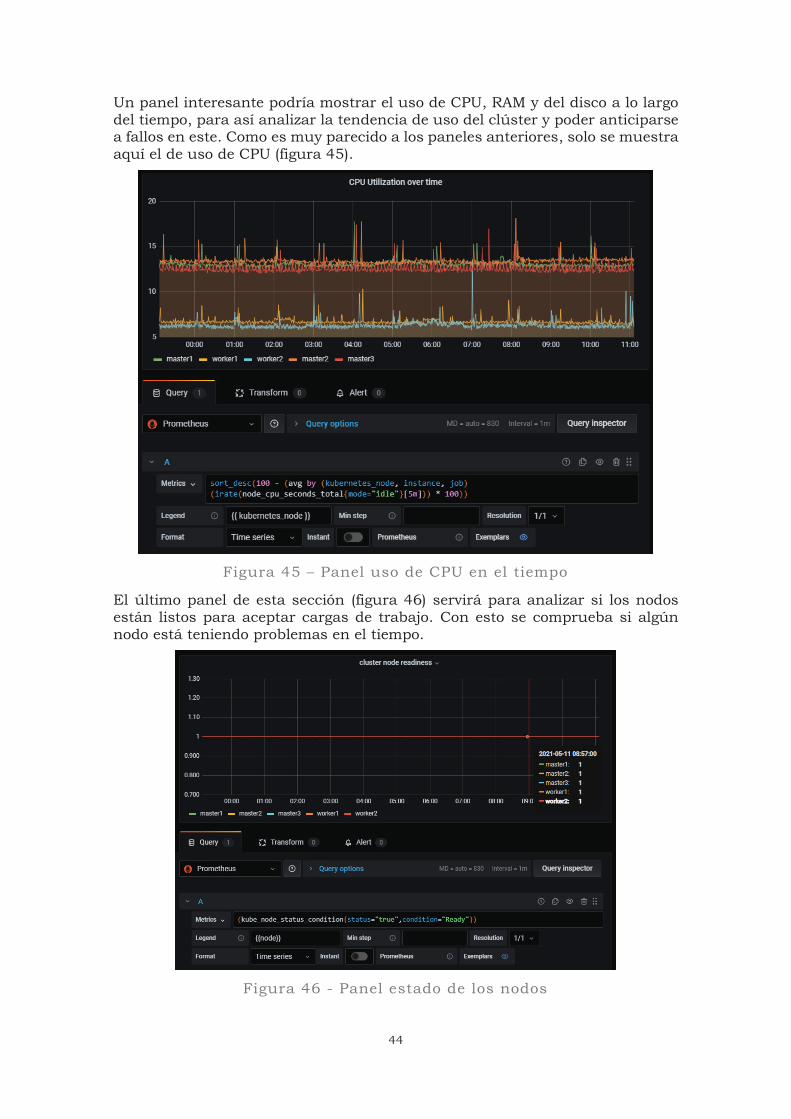
Figura 43 – Panel uso de memoria
Se utilizará otro panel para observar el uso de disco de los nodos y del servidor NFS. En la figura 44 aparecen dos consultas distintas. La A muestra el uso de disco de los nodos; la B, el uso de disco del servidor NFS desde el master1 para no repetir resultados.
Figura 44– Panel uso de disco
44
Un panel interesante podría mostrar el uso de CPU, RAM y del disco a lo largo del tiempo, para así analizar la tendencia de uso del clúster y poder anticiparse a fallos en este. Como es muy parecido a los paneles anteriores, solo se muestra aquí el de uso de CPU (figura 45).
Figura 45 – Panel uso de CPU en el tiempo
El último panel de esta sección (figura 46) servirá para analizar si los nodos están listos para aceptar cargas de trabajo. Con esto se comprueba si algún nodo está teniendo problemas en el tiempo.
Figura 46 - Panel estado de los nodos
45
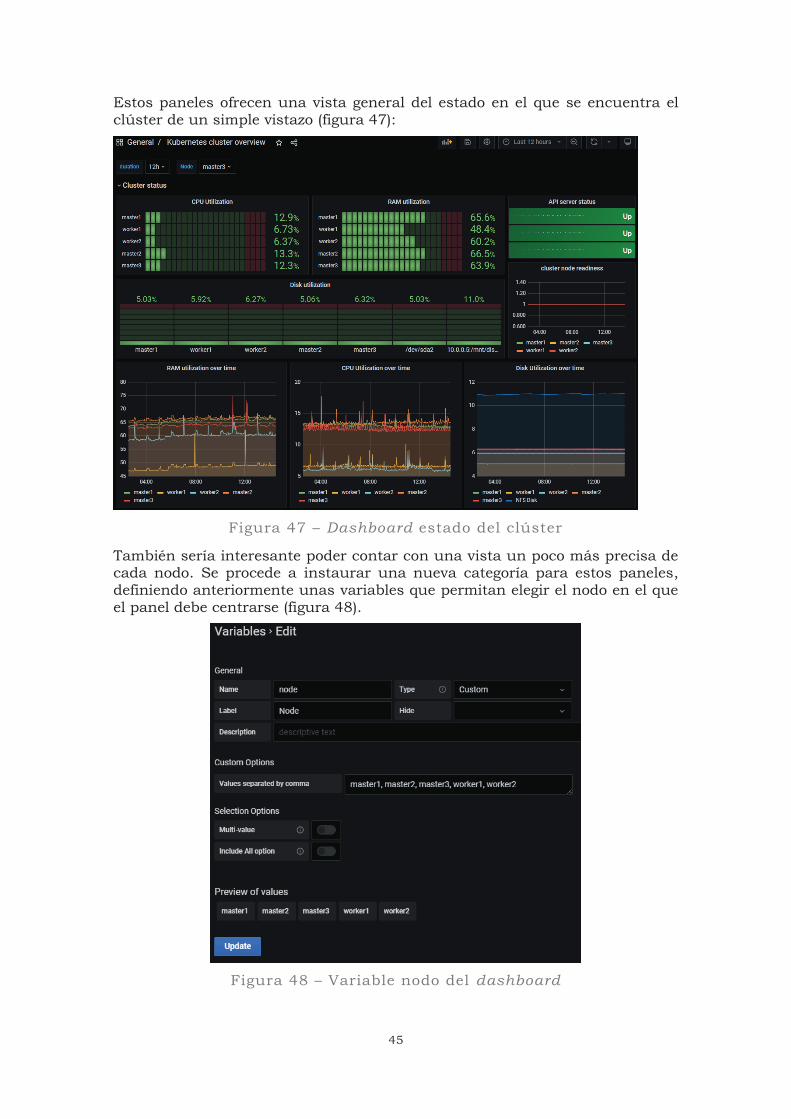
Estos paneles ofrecen una vista general del estado en el que se encuentra el clúster de un simple vistazo (figura 47):
Figura 47 – Dashboard estado del clúster
También sería interesante poder contar con una vista un poco más precisa de cada nodo. Se procede a instaurar una nueva categoría para estos paneles, definiendo anteriormente unas variables que permitan elegir el nodo en el que el panel debe centrarse (figura 48).
Figura 48 – Variable nodo del dashboard
46
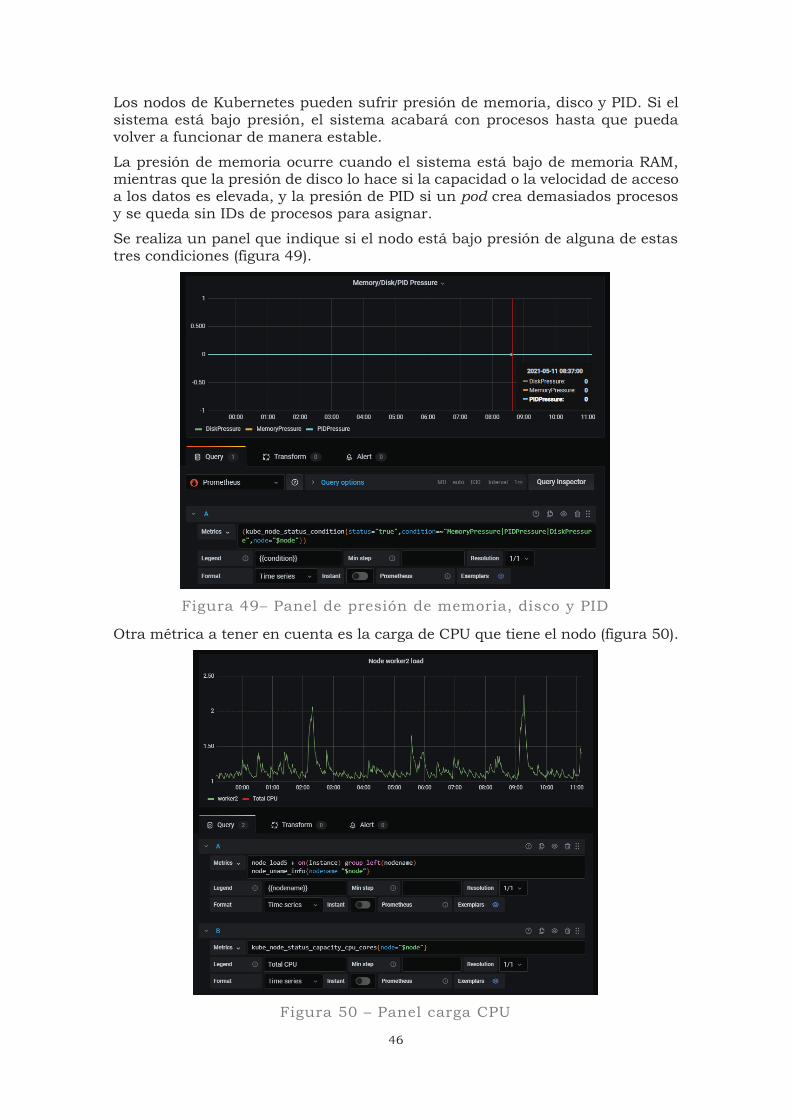
Los nodos de Kubernetes pueden sufrir presión de memoria, disco y PID. Si el sistema está bajo presión, el sistema acabará con procesos hasta que pueda volver a funcionar de manera estable.
La presión de memoria ocurre cuando el sistema está bajo de memoria RAM, mientras que la presión de disco lo hace si la capacidad o la velocidad de acceso a los datos es elevada, y la presión de PID si un pod crea demasiados procesos y se queda sin IDs de procesos para asignar.
Se realiza un panel que indique si el nodo está bajo presión de alguna de estas tres condiciones (figura 49).
Figura 49– Panel de presión de memoria, disco y PID
Otra métrica a tener en cuenta es la carga de CPU que tiene el nodo (figura 50).
Figura 50 – Panel carga CPU
47
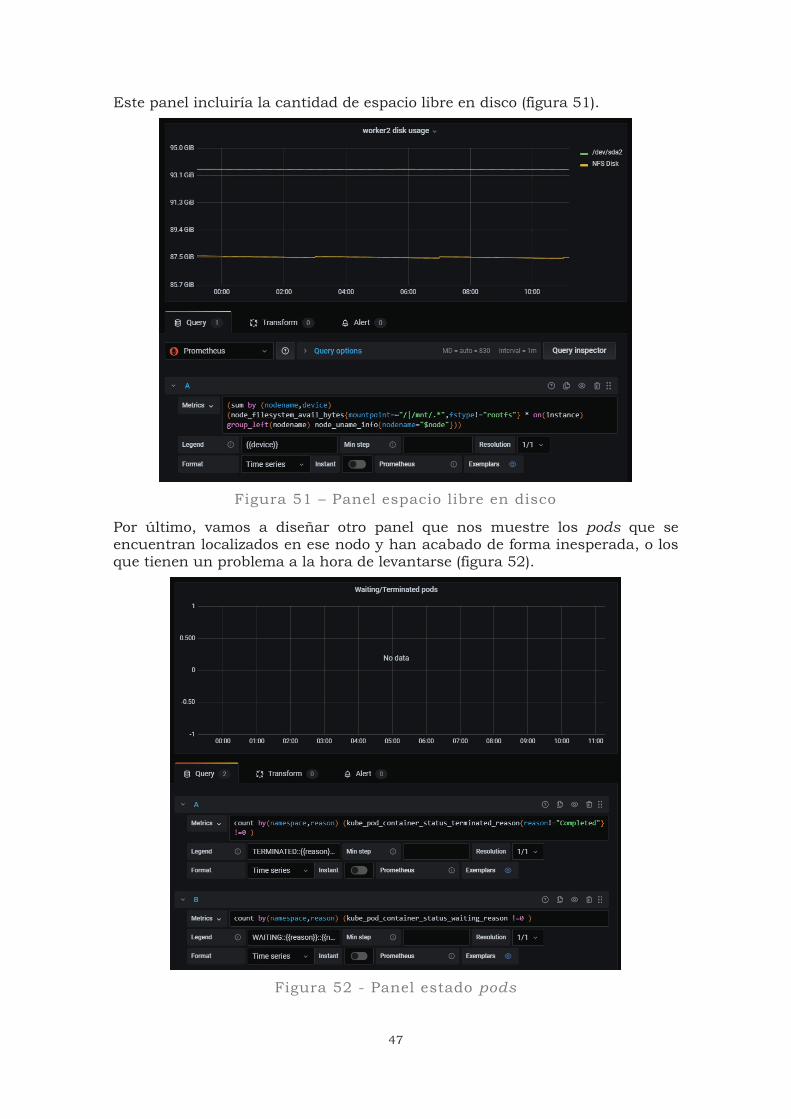
Este panel incluiría la cantidad de espacio libre en disco (figura 51).
Figura 51 – Panel espacio libre en disco
Por último, vamos a diseñar otro panel que nos muestre los pods que se encuentran localizados en ese nodo y han acabado de forma inesperada, o los que tienen un problema a la hora de levantarse (figura 52).
Figura 52 - Panel estado pods

48
Con estos 4 últimos paneles el dashboard quedaría dispuesto como se indica en la figura 53:
Figura 53 - Dashboard estado del nodo
3.7 Despliegue de la base de datos: PostgreSQL En esta sección se desplegará dentro del clúster una base de datos para las aplicaciones que lo necesiten.
3.7.1 Instalador Operador PostgreSQL La opción elegida ha sido PostgreSQL, una base de datos relacional que extiende el lenguaje SQL y permite almacenar datos de una forma segura, además de trabajar con grandes cantidades de datos.[37]
Para facilitar la instalación sobre el clúster se ha elegido “Crunchy PostgreSQL Operator”. Esta herramienta es útil porque permite desplegar de manera sencilla la base de datos sobre el clúster.[38]
Debido a que en la sección 3.4.1.3 ya fue configurado el StorageClass como predeterminado, la instalación se realizará en este paso usando directamente estos comandos:
kubectl create namespace pgo kubectl apply -f https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.6.2/installers/kubectl/postgres-operator.yml
37 The PostgreSQL Global Development Group (2021), What is PostgreSQL? Available: https://www.postgresql.org/about/ 38 Crunchy Data Solutions (2021), PostgreSQL Operator Quickstart. Available: https://access.crunchydata.com/documentation/postgres-operator/4.6.2/quickstart/

49
El archivo de instalación lanza un contenedor que prepara el entorno. Ahora hay que esperar hasta que termine el despliegue:
kubectl get pods NAME READY STATUS RESTARTS AGE pgo-deploy-rjzfv 0/1 Completed 0 7m29s postgres-operator-6b6679cd7b 4/4 Running 1 6m27s
Lo siguiente es instalar el cliente pgo en el ordenador en cuestión para poder administrar la base de datos.
curl https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.6.2/installers/kubectl/client-setup.sh > client-setup.sh chmod +x client-setup.sh
./client-setup.sh
Una vez instalado, se añaden al .bashrc las siguientes líneas:
export PGOUSER="${HOME?}/.pgo/pgo/pgouser" export PGO_CA_CERT="${HOME?}/.pgo/pgo/client.crt" export PGO_CLIENT_CERT="${HOME?}/.pgo/pgo/client.crt" export PGO_CLIENT_KEY="${HOME?}/.pgo/pgo/client.key" export PGO_APISERVER_URL='https://127.0.0.1:8443' export PGO_NAMESPACE=pgo
Se comprueba ahora que el cliente tiene conectividad con el clúster. Para ello se precisa redirigir el puerto 8443 para posibilitar la conexión:
kubectl -n pgo port-forward svc/postgres-operator 8443:8443 pgo version pgo client version 4.6.2 pgo-apiserver version 4.6.2
3.7.2 Creación clúster PostgreSQL Para poder crear bases de datos es necesario un clúster donde almacenar dichos datos. Para ello se utilizará el cliente pgo con el comando “create cluster”, así como unos parámetros que especifiquen la base de datos necesaria (para Jira, que se desplegará más adelante) y el tamaño deseado para el clúster y para la copia de seguridad:
pgo create cluster apps \ --pvc-size=10Gi \ --pgbackrest-pvc-size=15Gi \ --password-superuser= XXXXXXXX \ --database=jiradb \ --username=jirauser \ --password=XXXXXXXX
created cluster: apps workflow id: 9cd69a81-89c4-464a-8a8d-1d09b16abdc1 database name: jiradb users: username: jirauser password: XXXXXXXX

50
Para comprobar que se ha creado sin problemas, se observan los pods y PVs que se han creado:
kubectl get pods NAME READY STATUS RESTARTS AGE apps-7d4c98f759-jdh8r 1/1 Running 0 2m8s apps-backrest-shared-repo 1/1 Running 0 2m10s backrest-backup-apps-dn65b 0/1 Completed 0 93s kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS pvc-3b43e899-a8d7 10Gi RWO Delete Bound
pvc-5a596a66-59d6 15Gi RWO Delete Bound
CLAIM STORAGECLASS REASON AGE
pgo/apps nfs-client 2m11s pgo/apps-pgbr-repo nfs-client 2m11s
3.8 Instalación herramientas de desarrollo En esta sección se instalará una aplicación que requiere una base de datos para funcionar.
3.8.1 Jira Para la instalación de Jira se usará de nuevo Helm. Lo primero es crear un nuevo namespace para Jira, después se añade el repositorio y se procede a instalar:
kubectl create ns jira kubectl config set-context --current --namespace=jira helm repo add mox https://helm.mox.sh helm repo update helm install jirasoftware mox/jira-software \ --set postgresql.enabled=false \ --set persistence.size=10Gi \ --set databaseConnection.host=apps.pgo.svc.cluster.local \ --set databaseConnection.user=jirauser \ --set databaseConnection.password=Temporal123. \ --set databaseConnection.database=jiradb \ --set service.type=NodePort
Los parámetros utilizados para la instalación de Helm indican la persistencia deseada en un volumen de 10Gi y el host necesario para la conexión a la base de datos (similar a lo explicado en la sección 3.6.1).
Como ya se hizo con Prometheus y Grafana, para acceder a la aplicación se redirige el puerto por el que esta ha sido expuesta (32538).
kubectl get svc NAME TYPE CLUSTER-IP EXT-IP PORT(S) AGE jirasoftware NodePort 10.100.40.251 <none> 80:32538/TCP 15h kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS pvc-1c121313-dddf 25Gi RWO Delete Bound
CLAIM STORAGECLASS REASON AGE
jira/jirasoftware-jira-software-home nfs-client 15h

51
Una vez instalado, se configura la aplicación. Como muestra la figura 54, Jira está funcionando correctamente con la base de datos y el volumen persistente.
Figura 54 – Página web de Jira
3.9 Automatización de la reparación En esta sección se plantea un sistema de auto-reparación. Se diseñará un sistema que permita automatizar la solución de algunos de los errores más comunes que puedan ocurrir. La idea de esta implementación sería crear un conector para el Alertmanager que mandaría las alertas a una aplicación encargada de remediar los problemas.
Para el conector una posible implementación sería desarrollar un servidor web en Go que reciba las alertas del Alertmanager y las mande a la aplicación. Sería como llevar un paso más allá la idea del conector de Alertmanager con Microsoft Teams que ya hemos utilizado previamente.[36]
Por otro lado, para la aplicación sería imprescindible crear un pequeño programa que interprete las alertas que reciba del conector. Por ejemplo, se podría implementar un servidor REST que reciba las alertas que envíe el conector.
La aplicación podría hacer uso de playbooks de Ansible para solucionar los posibles problemas que puedan surgir.
En la figura 55 se muestra un esquema de cómo funcionaría este sistema:
Figura 55 – Sistema para la auto-reparación
Un ejemplo de cómo funcionaría todo este sistema sería que Prometheus enviase una alerta al Alertmanager de que se ha utilizado el 85% del espacio disponible en el disco. Ante esta situación, se podrían tomar diferentes decisiones sobre cómo solucionarlo en función del espacio que pueda liberarse con cada solución. La primera consistiría en borrar archivos temporales o copias de seguridad antiguas que ya no se necesiten. Si no fuera suficiente con esto, se podría

52
redimensionar automáticamente el sistema de archivos (si el disco lo permitiera) para obtener más espacio.
Otro ejemplo sería detectar cuándo el espacio en un volumen persistente se está llenando y de este modo lanzar un playbook para aumentar el espacio en un 20% del que ya tenga actualmente reservado.
Una última idea involucraría el auto-escalado de recursos en la máquina. Para esta tarea se podría usar Terraform, una herramienta diseñada para construir, cambiar y versionar infraestructura desde el código.[39] Si se detectara que los recursos de CPU o memoria tienen una tendencia a dejar pocos recursos libres, podríamos utilizar Terraform para aumentar los recursos de nuestras máquinas y así migrar el entorno a una infraestructura más potente.
39 HashiCorp (2021), Introduction to Terraform. Available: https://www.terraform.io/intro/index.html

53
4 Conclusiones y líneas futuras En este capítulo se presentan los resultados y conclusiones junto con algunas líneas futuras de desarrollo para poder mejorar el proyecto.
4.1 Conclusiones Con este proyecto nos hemos familiarizado con los conceptos de nubes públicas, Kubernetes y Ansible, combinando los tres para crear una estructura escalable y fiable.
En el documento hemos presenciado el despliegue de un clúster de Kubernetes sobre Google Cloud Platform, intentando aprovechar al máximo las facilidades que nos ofrecen las nubes públicas.
El resultado ha sido un clúster plenamente funcional de alta disponibilidad que permitirá ofrecer un servicio PaaS (Plataforma como servicio) para la infraestructura y mantenimiento de esta misma.
Gran parte del proceso ha sido automatizado con Ansible, especialmente lo relativo al despliegue del clúster y todo lo necesario para que este funcione correctamente. Gracias a ello, podremos ofrecer el clúster como servicio sin tener que preocuparnos por cometer pequeños fallos a la hora del despliegue.
Se han cumplido todos los objetivos del proyecto, aunque la parte de automatización de la reparación se ha dejado simplemente esbozada a nivel teórico debido a la gran cantidad de trabajo que supondría.
El proyecto aún tiene mucho margen de mejora. A continuación, se expondrán algunas ideas en la siguiente sección.
4.2 Líneas futuras En esta sección se incluyen algunas ideas acerca de cómo mejorar el proyecto mediante el despliegue de las máquinas necesarias para el clúster y en lo referente a la infraestructura de Kubernetes y al sistema de auto-reparación.
Para empezar, la infraestructura creada a mano en GCP se podría desplegar directamente desde el código utilizando Terraform. Esto permitiría acelerar aún más el proceso de despliegue del clúster y evitaría posibles preocupaciones por cometer algún pequeño error.
Otro aspecto que se podría mejorar en la infraestructura de Kubernetes sería exponer los servicios a Internet (Jira, por ejemplo) utilizando NGINX Ingress Controller.
También se podría instalar un sistema de creación de copias de seguridad de los volúmenes persistentes, para lo que se podría emplear Velero, una herramienta que permite hacer copias de seguridad y restaurarlas ante cualquier desastre.
Por último, quedaría pendiente implementar el sistema de auto-reparación. Debido a la extensión del proyecto solo ha sido posible presentarlo como idea, dejando para un futuro trabajo su implementación práctica.

54
5 Análisis de Impacto En este capítulo se realizará un análisis del impacto potencial de los resultados obtenidos con este proyecto.
A nivel personal este proyecto me ha servido para desarrollar mi conocimiento con Kubernetes y las nubes públicas. Además, gracias a los conocimientos que he ido adquiriendo durante la realización del proyecto, he sido capaz de diseñar un sistema de auto-reparación.
Por otra parte, sería conveniente analizar el potencial impacto del proyecto haciendo referencia a los Objetivos de Desarrollo Sostenible (ODS) de la Agenda 2030.[40]
El primer objetivo a tener en cuenta es el objetivo 12: Producción y Consumo Responsables. Gracias al uso de las nubes públicas, las empresas no tienen que estar comprando hardware nuevo cada vez que quieren aumentar sus servicios. Por otro lado, si una empresa ya no necesita más esos recursos, pueden ser liberados para que otras empresas o individuos los utilicen. Así, la contaminación por desechos informáticos es reducida ya que se reutilizarán los componentes mucho más. El objetivo 12 busca que el consumo y la producción mundial que dependen del uso del medioambiente natural y de los recursos no tengan un efecto tan destructivo sobre el planeta, por lo que esta solución ayuda a lograr este objetivo.
El segundo objetivo sería el 13: Acción por el clima. Como se ha explicado en el párrafo anterior, la informática produce bastantes desechos perjudiciales para el medioambiente. El objetivo 13 busca adoptar medidas para reducir el impacto del cambio climático y las nubes públicas permiten compartir recursos entre empresas y elimina la necesidad de disponer de un centro de procesamiento de datos, ahorrando recursos que son perjudiciales para el medioambiente.
Por último, hay que mencionar también el objetivo 9: Industria, Innovación e Infraestructuras. Este proyecto presenta la idea de un sistema de auto-reparación. Si finalmente se llevase, a cabo podría dar lugar a la creación de un software que podrá crear puestos de trabajo e innovar en el campo de la automatización de solución de errores en Kubernetes.
40 Naciones Unidas (2021), Objetivos de desarrollo sostenible. Available: https://www.un.org/sustainabledevelopment/es/objetivos-de-desarrollo-sostenible/
55
6 Bibliografía [1] The Kubernetes Authors (2021), What is Kubernetes? Available: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
[2] Microsoft (2021), ¿Qué es la nube pública, privada e híbrida? Available: https://azure.microsoft.com/es-es/overview/what-are-private-public-hybrid-clouds/#public-cloud
[3] Microsoft (2021), ¿Qué es IaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-iaas/
[4] Microsoft (2021), ¿Qué es PaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-paas/
[5] Microsoft (2021), ¿Qué es SaaS? Available: https://azure.microsoft.com/es-es/overview/what-is-saas/
[6] Google (2021), Pod. Available: https://cloud.google.com/kubernetes-engine/docs/concepts/pod
[7] Red Hat, Inc. (2021), Learning Kubernetes basics. Available: https://www.redhat.com/en/topics/containers/learning-kubernetes-tutorial
[8] The Kubernetes Authors (2021), Volumes. Available: https://kubernetes.io/docs/concepts/storage/volumes/
[9] The Kubernetes Authors (2021), Namespaces. Available: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
[10] The Kubernetes Authors (2021), ReplicaSet. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/replicaset/
[11] The Kubernetes Authors (2021), Deployment. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/deployment/
[12] The Kubernetes Authors (2021), StatefulSets. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/statefulset/
[13] The Kubernetes Authors (2021), DaemonSet. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/daemonset/
[14] The Kubernetes Authors (2021), Jobs - Ejecución hasta el final. Available: https://kubernetes.io/es/docs/concepts/workloads/controllers/jobs-run-to-completion/
[15] The Kubernetes Authors (2021), Componentes de Kubernetes. Available: https://kubernetes.io/es/docs/concepts/overview/components/
[16] Red Hat, Inc. (2021), Introducción a la arquitectura de Kubernetes. Available: https://www.redhat.com/es/topics/containers/kubernetes-architecture
[17] Prometheus Authors (2021), What is Prometheus? Available: https://prometheus.io/docs/introduction/overview/
[18] Grafana Labs (2021), What is Grafana? Available: https://grafana.com/docs/grafana/latest/getting-started/
[19] Red Hat, Inc. (2020), How Ansible Works. Available: https://www.ansible.com/overview/how-ansible-works

56
[20] The Kubernetes Authors (2021), Installing kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
[21] The Kubernetes Authors (2021), Creating a cluster with kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
[22] The Kubernetes Authors (2021), Creating Highly Available clusters with kubeadm. Available: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
[23] vikram fugro (26 de septiembre de 2018), Container Networking Interface aka CNI. Available: https://cotigao.medium.com/container-networking-interface-aka-cni-bdfe23f865cf
[24] The Kubernetes Authors (2021), Using RBAC Authorization. Available: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
[25] Google (2021), Usa cuentas de servicio de Kubernetes. Available: https://cloud.google.com/kubernetes-engine/docs/how-to/kubernetes-service-accounts?hl=es-419
[26] Google (2021), Crea y conecta un disco. Available: https://cloud.google.com/compute/docs/disks/add-persistent-disk?hl=es-419
[27] Srijan Kishore, NFS Server and Client Installation on CentOS 7. Available: https://www.howtoforge.com/nfs-server-and-client-on-centos-7
[28] Nikolaj Goodger (27 de abril de 2018), NFS Filestore on GCP for free. Available: https://medium.com/@ngoodger_7766/nfs-filestore-on-gcp-for-free-859593e18bdf
[29] Kubernetes SIGs (2021), Kubernetes NFS Subdir External Provisioner [Source code]. https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
[30] Helm Authors (2021), What is Helm? Available: https://helm.sh/
[31] Prometheus Monitoring Community (2021), Helm Charts [Source code]. https://github.com/prometheus-community/helm-charts
[32] Vladimir Kaplarevic (18 de mayo de 2020), How to Use SSH Port Forwarding. Available: https://phoenixnap.com/kb/ssh-port-forwarding
[33] Grafana (2021), Helm Charts [Source code]. https://github.com/grafana/helm-charts
[34] The Kubernetes Authors (2021), ConfigMaps. Available: https://kubernetes.io/docs/concepts/configuration/configmap/
[35] lapee79's Tech Blog (2 de Agosto de 2019), Alerts of the Prometheus Alertmanager with MS Teams. Available: https://lapee79.github.io/en/article/prometheus-alertmanager-with-msteams/
[36] prometheus-msteams (2021), prometheus-msteams [Source code]. https://github.com/prometheus-msteams/prometheus-msteams/blob/master/chart/prometheus-msteams/README.md
[37] The PostgreSQL Global Development Group (2021), What is PostgreSQL? Available: https://www.postgresql.org/about/

57
[38] Crunchy Data Solutions (2021), PostgreSQL Operator Quickstart. Available: https://access.crunchydata.com/documentation/postgres-operator/4.6.2/quickstart/
[39] HashiCorp (2021), Introduction to Terraform. Available: https://www.terraform.io/intro/index.html
[40] Naciones Unidas (2021), Objetivos de desarrollo sostenible. Available: https://www.un.org/sustainabledevelopment/es/objetivos-de-desarrollo-sostenible/

58
7 Anexo En este capítulo se incluye el código utilizada para algunas partes del trabajo.
7.1 ConfigMap Prometheus El código para definir las alertas en el ConfigMap de Prometheus es el siguiente:
rules: | groups: - name: k8s alerts rules: - alert: Kubernetes node down expr: up{component="node-exporter"} == 0 for: 3m labels: severity: critical annotations: title: Node {{ $labels.kubernetes_node }} is down description: Failed to scrape {{ $labels.kubernetes_node }} for more than 3 minutes. Node seems down. - alert: Disk usage in a node is at 85% expr: (100 - ((node_filesystem_avail_bytes{mountpoint=~"/|/mnt/disks/pv-disk",fstype!="rootfs"} * 100) / node_filesystem_size_bytes{mountpoint=~"/|/mnt/disks/pv-disk",fstype!="rootfs"})) > 85 for: 1m labels: severity: warning annotations: title: Disk usage on {{ $labels.kubernetes_node }} description: Node {{ $labels.kubernetes_node }} is now at {{ $value }}% - alert: CPU utilization in a node is at 85% expr: ((100 - (avg by (kubernetes_node) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100))) > 85 for: 1m labels: severity: warning annotations: title: CPU utilization is high on {{ $labels.kubernetes_node }} description: Node {{ $labels.kubernetes_node }} is now at {{ $value }}% - alert: Node memory utilization in an insance is at 85% expr: ((1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))*100) > 85 for: 1m labels: severity: warning annotations: title: Memory utilization is high on {{ $labels.kubernetes_node }} description: Node {{ $labels.kubernetes_node }} is now at {{ $value }}%

59
- alert: Low replicas running expr: kube_deployment_status_replicas > kube_deployment_status_replicas_available for: 3m labels: severity: warning annotations: title: A pod is running low on replicas description: Some of the pod deployments failed on {{ $labels.deployment }}. The current number of replicas running is {{ $value }} - alert: Restart loop expr: kube_pod_container_status_last_terminated_reason == 1 and on(container) rate(kube_pod_container_status_restarts_total[5m]) * 300 > 1 for: 3m labels: severity: warning annotations: title: A pod is in a restart loop description: The pod {{ $labels.pod }} is in a restart loop - alert: Not all ETCD pods are running expr: (count(kube_pod_container_status_running{container="etcd"})) < 3 for: 3m labels: severity: warning annotations: title: ETCD container status description: The current number of ETCD containers is {{ $value }} - alert: API server status expr: kube_pod_container_status_running{container="kube-apiserver"} == 0 for: 1m labels: severity: warning annotations: title: API server status description: The API server stopped running
7.2 Dashboard Grafana A continuación, se incluye el código JSON del panel creado en la sección 3.6.
{ "annotations": { "list": [ { "builtIn": 1, "datasource": "-- Grafana --", "enable": true, "hide": true, "iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts", "type": "dashboard" } ] }, "editable": true, "gnetId": null, "graphTooltip": 0, "id": 1, "iteration": 1621496838105,

60
"links": [], "panels": [ { "collapsed": false, "datasource": null, "gridPos": { "h": 1, "w": 24, "x": 0, "y": 0 }, "id": 10, "panels": [], "title": "Cluster status", "type": "row" }, { "datasource": null, "fieldConfig": { "defaults": { "mappings": [], "thresholds": { "mode": "percentage", "steps": [ { "color": "green", "value": null }, { "color": "red", "value": 80 } ] }, "unit": "percent" }, "overrides": [] }, "gridPos": { "h": 5, "w": 9, "x": 0, "y": 1 }, "id": 8, "options": { "displayMode": "lcd", "orientation": "horizontal", "reduceOptions": { "calcs": [ "mean"
], "fields": "", "values": false }, "showUnfilled": true, "text": {} }, "pluginVersion": "7.5.3", "targets": [ { "expr": "(100 - (avg by (kubernetes_node) (irate(node_cpu_seconds_total{mode=\"idle\"}[5m])) * 100))", "format": "time_series", "instant": true, "interval": "", "legendFormat": "{{kubernetes_node}}", "refId": "A" } ], "timeFrom": null, "timeShift": null, "title": "CPU Utilization", "transformations": [], "type": "bargauge" }, { "datasource": null, "fieldConfig": { "defaults": { "decimals": 1, "mappings": [], "thresholds": { "mode": "absolute", "steps": [ { "color": "green", "value": null }, { "color": "red", "value": 80 } ] }, "unit": "percent" }, "overrides": [] },

61
"gridPos": { "h": 5, "w": 9, "x": 9, "y": 1 }, "id": 14, "options": { "displayMode": "lcd", "orientation": "horizontal", "reduceOptions": { "calcs": [ "mean" ], "fields": "", "values": false }, "showUnfilled": true, "text": {} }, "pluginVersion": "7.5.3", "targets": [ { "expr": "((1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100)", "interval": "", "legendFormat": "{{kubernetes_node}}", "refId": "A" } ], "timeFrom": null, "timeShift": null, "title": "RAM utilization", "type": "bargauge" }, { "cacheTimeout": null, "datasource": "Prometheus", "fieldConfig": { "defaults": { "mappings": [ { "id": 0, "op": "=", "text": "Down", "type": 1, "value": "0"
}, { "from": "", "id": 1, "operator": "", "text": "Up", "to": "", "type": 1, "value": "1" } ], "thresholds": { "mode": "absolute", "steps": [ { "color": "#d44a3a", "value": null }, { "color": "#299c46", "value": 1 } ] }, "unit": "none" }, "overrides": [] }, "gridPos": { "h": 4, "w": 6, "x": 18, "y": 1 }, "id": 35, "interval": null, "links": [], "maxDataPoints": 100, "options": { "colorMode": "background", "fieldOptions": { "calcs": [ "mean" ] }, "graphMode": "none", "justifyMode": "auto", "orientation": "horizontal", "reduceOptions": { "calcs": [

62
"mean" ], "fields": "", "values": false }, "text": {}, "textMode": "auto" }, "pluginVersion": "7.5.3", "targets": [ { "exemplar": true,
"expr": "kube_pod_container_status_running{container=\"kube-apiserver\"}", "interval": "", "legendFormat": "", "refId": "B" } ], "timeFrom": null, "timeShift": null, "title": "API server status", "type": "stat" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "Prometheus", "fieldConfig": { "defaults": { "links": [] }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 6, "w": 6, "x": 18, "y": 5 }, "hiddenSeries": false, "id": 21, "legend": { "alignAsTable": false,
"avg": false, "current": false, "hideZero": false, "max": false, "min": false, "rightSide": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "exemplar": true, "expr": "(kube_node_status_condition{status=\"true\",condition=\"Ready\"}) ", "interval": "", "legendFormat": "{{node}}", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [ { "colorMode": "background6", "fill": true, "fillColor": "rgba(234, 112, 112, 0.12)", "line": false, "lineColor": "rgba(237, 46, 24, 0.60)", "op": "time" } ], "timeShift": null,

63
"title": "cluster node readiness", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "datasource": null, "fieldConfig": { "defaults": { "mappings": [], "thresholds": { "mode": "absolute", "steps": [ { "color": "green", "value": null }, { "color": "red",
"value": 80 } ] }, "unit": "percent" }, "overrides": [] }, "gridPos": { "h": 5, "w": 18, "x": 0, "y": 6 }, "id": 16, "options": { "displayMode": "lcd", "orientation": "auto", "reduceOptions": { "calcs": [ "mean" ], "fields": "", "values": false }, "showUnfilled": true, "text": {} }, "pluginVersion": "7.5.3", "targets": [ { "exemplar": true, "expr": "(100 - ((node_filesystem_avail_bytes{fstype!=\"rootfs\",mountpoint=~\"/\"} * 100) / node_filesystem_size_bytes{fstype!=\"rootfs\",mountpoint=~\"/\"}))", "instant": true, "interval": "", "legendFormat": "{{kubernetes_node}}", "refId": "A" }, { "exemplar": true, "expr": "(100 - ((node_filesystem_avail_bytes{fstype!=\"rootfs\",mountpoint=~\"/|/mnt/disks/pv-disk\",kubernetes_node=\"master1\"} * 100) / node_filesystem_size_bytes{fstyp

64
e!=\"rootfs\",mountpoint=~\"/|/mnt/disks/pv-disk\",kubernetes_node=\"master1\"}))", "hide": false, "interval": "", "legendFormat": "{{device}}", "refId": "B" } ], "timeFrom": null, "timeShift": null, "title": "Disk utilization", "type": "bargauge" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": null, "fieldConfig": { "defaults": {}, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 9, "w": 8, "x": 0, "y": 11 }, "hiddenSeries": false, "id": 37, "legend": { "avg": false, "current": false, "max": false, "min": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3",
"pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "sort_desc((1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100)", "interval": "", "legendFormat": "{{ kubernetes_node }}", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "RAM utilization over time", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1,

65
"max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": null, "fieldConfig": { "defaults": {}, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 9, "w": 8, "x": 8, "y": 11 }, "hiddenSeries": false, "id": 41, "legend": { "avg": false, "current": false, "max": false, "min": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false,
"targets": [ { "expr": "sort_desc(100 - (avg by (kubernetes_node, instance, job) (irate(node_cpu_seconds_total{mode=\"idle\"}[5m])) * 100))", "interval": "", "legendFormat": "{{ kubernetes_node }}", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "CPU Utilization over time", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true } ],
"yaxis": {

66
"align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": null, "fieldConfig": { "defaults": {}, "overrides": [ { "matcher": { "id": "byName", "options": "{app=\"prometheus\", app_kubernetes_io_managed_by=\"Helm\", chart=\"prometheus-13.8.0\", component=\"node-exporter\", device=\"10.0.0.5:/mnt/disks/pv-disk\", fstype=\"nfs4\", heritage=\"Helm\", instance=\"10.0.0.2:9100\", job=\"kubernetes-service-endpoints\", kubernetes_name=\"prometheus-node-exporter\", kubernetes_namespace=\"monitoring\", kubernetes_node=\"master1\", mountpoint=\"/mnt/disks/pv-disk\", release=\"prometheus\"}" }, "properties": [ { "id": "displayName", "value": "NFS Disk" } ] } ] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 9, "w": 8, "x": 16, "y": 11
}, "hiddenSeries": false, "id": 42, "legend": { "avg": false, "current": false, "max": false, "min": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "exemplar": true, "expr": "(100 - ((node_filesystem_avail_bytes{fstype!=\"rootfs\",mountpoint=~\"/\"} * 100) / node_filesystem_size_bytes{fstype!=\"rootfs\",mountpoint=~\"/\"}))", "interval": "", "legendFormat": "{{ kubernetes_node }}", "refId": "A" }, { "exemplar": true, "expr": "(100 - ((node_filesystem_avail_bytes{fstype!=\"rootfs\",mountpoint=~\"/mnt/disks/pv-disk\",kubernetes_node=\"master1\"} * 100) / node_filesystem_size_bytes{fstype!=\"rootfs\",mountpoint=~\"/mnt/disks/pv-disk\",kubernetes_node=\"master1

67
\"}))", "hide": false, "interval": "", "legendFormat": "", "refId": "B" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Disk Utilization over time", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "collapsed": false, "datasource": null, "gridPos": {
"h": 1, "w": 24, "x": 0, "y": 20 }, "id": 25, "panels": [], "title": "Node status", "type": "row" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "Prometheus", "fieldConfig": { "defaults": { "links": [] }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 6, "w": 7, "x": 0, "y": 21 }, "hiddenSeries": false, "id": 23, "legend": { "avg": false, "current": false, "max": false, "min": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [],

68
"spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "exemplar": true, "expr": "(kube_node_status_condition{status=\"true\",condition=~\"MemoryPressure|PIDPressure|DiskPressure\",node=\"$node\"})", "interval": "", "legendFormat": "{{condition}}", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Memory/Disk/PID Pressure", "tooltip": { "shared": true, "sort": 1, "value_type": "individual" }, "transformations": [], "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false
} ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "Total CPU": "dark-red" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "Prometheus", "fieldConfig": { "defaults": { "links": [] }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 6, "w": 7, "x": 7, "y": 21 }, "hiddenSeries": false, "id": 31, "legend": { "avg": false, "current": false, "max": false, "min": false, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1, "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10,

69
"stack": false, "steppedLine": false, "targets": [ { "expr": "node_load5 + on(instance) group_left(nodename) \nnode_uname_info{nodename=\"$node\"}", "hide": false, "interval": "", "legendFormat": "{{nodename}}", "refId": "A" }, { "expr": "kube_node_status_capacity_cpu_cores{node=\"$node\"}", "interval": "", "legendFormat": "Total CPU", "refId": "B" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Node $node load", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true },
{ "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": {
"align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "Prometheus", "fieldConfig": { "defaults": { "links": [] }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 6, "w": 10, "x": 14, "y": 21 }, "hiddenSeries": false, "id": 33, "legend": { "alignAsTable": false, "avg": false, "current": false, "hideEmpty": true, "hideZero": true, "max": false, "min": false, "rightSide": true, "show": true, "total": false, "values": false }, "lines": true, "linewidth": 1,

70
"nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "exemplar": true, "expr": "(sum by (nodename,device) (node_filesystem_avail_bytes{mountpoint=~\"/|/mnt/.*\",fstype!=\"rootfs\"} * on(instance) group_left(nodename) node_uname_info{nodename=\"$node\"}))", "interval": "", "legendFormat": "{{device}}", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "$node disk usage", "tooltip": { "shared": true, "sort": 0, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "bytes", "label": null,
"logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "cacheTimeout": null, "dashLength": 10, "dashes": false, "datasource": "Prometheus", "fieldConfig": { "defaults": { "links": [] }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 6, "w": 18, "x": 0, "y": 27 }, "hiddenSeries": false, "id": 29, "legend": { "avg": false, "current": false, "hideEmpty": true, "hideZero": true, "max": false, "min": false, "show": true, "total": false, "values": false },

71
"lines": false, "linewidth": 1, "links": [], "nullPointMode": "null", "options": { "alertThreshold": true }, "percentage": false, "pluginVersion": "7.5.3", "pointradius": 1, "points": true, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "count by(namespace,reason) (kube_pod_container_status_terminated_reason{reason!=\"Completed\"} !=0 )", "hide": false, "instant": false, "legendFormat": "TERMINATED::{{reason}}::{{namespace}}", "refId": "A" }, { "expr": "count by(namespace,reason) (kube_pod_container_status_waiting_reason !=0 )", "hide": false, "legendFormat": "WAITING::{{reason}}::{{namespace}}", "refId": "B" }, { "refId": "C" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Waiting/Terminated pods", "tooltip": { "shared": true, "sort": 0,
"value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } } ], "refresh": false, "schemaVersion": 27, "style": "dark", "tags": [], "templating": { "list": [ { "allValue": null, "current": { "selected": true, "text": "12h", "value": "12h" }, "description": null, "error": null, "hide": 0, "includeAll": false, "label": null, "multi": false,

72
"name": "duration", "options": [ { "selected": false, "text": "10m", "value": "10m" }, { "selected": false, "text": "30m", "value": "30m" }, { "selected": false, "text": "1h", "value": "1h" }, { "selected": false, "text": "2h", "value": "2h" }, { "selected": false, "text": "6h", "value": "6h" }, { "selected": true, "text": "12h", "value": "12h" }, { "selected": false, "text": "1d", "value": "1d" }, { "selected": false, "text": "2d", "value": "2d" }, { "selected": false, "text": "5d", "value": "5d" }, { "selected": false, "text": "14d", "value": "14d" }, { "selected": false,
"text": "30d", "value": "30d" } ], "query": "10m,30m,1h,2h,6h,12h,1d,2d,5d,14d,30d", "queryValue": "", "skipUrlSync": false, "type": "custom" }, { "allValue": null, "current": { "selected": false, "text": "master3", "value": "master3" }, "description": null, "error": null, "hide": 0, "includeAll": false, "label": "Node", "multi": false, "name": "node", "options": [ { "selected": false, "text": "master1", "value": "master1" }, { "selected": false, "text": "master2", "value": "master2" }, { "selected": false, "text": "master3", "value": "master3" }, { "selected": false, "text": "worker1", "value": "worker1" }, { "selected": true, "text": "worker2", "value": "worker2" } ], "query": "master1, master2, master3, worker1,

73
worker2", "queryValue": "", "skipUrlSync": false, "type": "custom" } ] }, "time": { "from": "now-12h",
"to": "now" }, "timepicker": {}, "timezone": "", "title": "Kubernetes cluster overview", "uid": "mmu5Go0Gk", "version": 8 }

Este documento esta firmado porFirmante CN=tfgm.fi.upm.es, OU=CCFI, O=Facultad de Informatica - UPM,
C=ES
Fecha/Hora Thu Jun 03 18:39:09 CEST 2021
Emisor delCertificado
[email protected], CN=CA Facultad deInformatica, O=Facultad de Informatica - UPM, C=ES
Numero de Serie 630
Metodo urn:adobe.com:Adobe.PPKLite:adbe.pkcs7.sha1 (AdobeSignature)





























