
CONSTRUCCIÓN DE ALGORITMO PARA ANÁLISIS DE CAUSA RAÍZ DE
ACCIDENTES DE TRANSITO UTILIZANDO REDES NEURONALES Y MINERÍA DE
DATOS.
HERNANDO VELEZ SANCHEZ
Trabajo de grado para optar al título de Especialista en Higiene, Seguridad y Salud en el trabajo
Docente Director
Heberto Saavedra M, II, Msc
UNIVERSIDAD DISTRITAL FRANCISCO JOSE DE CALDAS.
FACULTAD DE INGENIERIA
BOGOTA D.C
2018

1
AGRADECIMIENTOS
A DIOS QUE ME GUIA Y ACOMPAÑA SIEMPRE, A MIS PADRES POR QUIENES
SIENTO UN AMOR INFINITO, AL INGENIERO MSC HEBERTO SAAVEDRA M POR SU
VALIOSA ORIENTACION.
“Nadie puede pasar por este mundo e irse dejándolo igual que lo encontró, uno debe de hacer
algo para que los demás sepan que uno estuvo aquí”
Arthur Miller (William Loman).

2

3
Contenido
1. INTRODUCCION. ............................................................................................................................ 8
2. PLANTEAMIENTO DEL PROBLEMA. ........................................................................................ 9
3. JUSTIFICACION. ........................................................................................................................... 11
4. OBJETIVOS.................................................................................................................................... 13
4.1. OBJETIVO GENERAL. ............................................................................................................. 13
4.2. OBJETIVOS ESPECIFICOS. .................................................................................................... 13
5. ESTADO DEL ARTE. .................................................................................................................... 14
6. MARCO TEORICO ........................................................................................................................ 16
6.1. CARACTERISTICAS DE UN ACCIDENTE DE TRANSITO. ............................................... 16
6.1.1. ACTORES EN LA ACCIDENTALIDAD DE TRANSITO. PELIGROS Y
FACTORES DE RIESGO. 16
6.1.2. COMPLEJIDAD DEL SISTEMA E INTERRELACON ENTRE LOS
FACTORES DE RIESGO. 24
6.2. MODELOS CAUSALES DE ACCIDENTES. ........................................................................... 27
6.2.1. Modelos secuenciales. 1931. Heinrich. 27
6.2.2. Modelos epidemiológicos 1997 (Reason). 28
6.2.3. Modelos sistémicos avanzados Docker, 2006. 29
6.2.4. Relaciones de causalidad. 29
6.3. METODOS DE INVESTIGACION DE ACCIDENTES. ......................................................... 30
6.3.1. Técnicas basadas en modelos secuenciales. 31
6.3.2. TECNICAS BASADAS EN MODELOS EPIDEMIOLOGICOS. 33
6.3.3. Análisis de causa raíz. (RCA). 34
6.3.4. Método de tablas de Forrester. 36
6.3.5. COMPARACION DE LAS TECNICAS. 37
6.4. MODELO DE ANALISIS DE CAUSA RAIZ DE ACCIDENTES. .......................................... 40

4
6.4.1. Modelo de accidentes de transito.. 40
6.4.2. Identificación de factores, representación y relaciones. 42
6.4.3. Metodologìa de análisis de causa raíz. 42
6.5. PROCESO DE INVESTIGACION DE ACCIDENTES. ........................................................... 48
6.6. MINERIA DE DATOS. .............................................................................................................. 50
6.6.1. TECNICAS DE MINERIA DE DATOS. 51
6.6.2. Análisis de la red neuronal. Métricas. 58
6.6.3. Algoritmos bayesianos. 64
6.6.4. SOFTWARE PARA MINERIA DE DATOS. 65
7. METODOLOGIA Y DESARROLLO DEL PROYECTO. ........................................................... 66
7.1. CASO BASE DE DATOS 1. ...................................................................................................... 66
7.1.1. ANALISIS DEL DOMINIO. 66
7.1.2. FIJAR NETAS. 71
7.1.3. SELECCIÓN, EXPLORACION, LIMPIEZA Y TRANSFORMACION DE
DATOS 72
7.1.4. PREPARACION DEL DATASET O VISTA MINABLE. 76
7.1.5. MODELADO Y DESARROLLO DEL DATA MINING, CAUSA PROXIMA.
84
Preprocesamiento. 94
7.2. CASO BASE DE DATOS 2. .................................................................................................... 123
7.2.1. Análisis estadístico base de datos 2. 124
7.2.2. ETAPA DE CLASIFICACION BASE DE DATOS EMPRESAS DE
TRANSPORTE ALLIANZ. 129
7.3. MODELO DE CAUSA RAIZ. .................................................................................................. 143
7.3.1. Construcción de la base de datos para causa basica o raiz. 143
7.3.2. Aplicación de la tecnica PART para determinar la causa raíz de a ccidentes de
tránsito en empresas de transporte. 146
7.3.3. Modelo PART. 147
7.3.4. EJEMPLO DE APLICACIÓN DEL MODELO. 157
Sistema de frenos. 160
Compresor. 160
Análisis sicosensométrico del conductor. ............................................................................................................ 170

5
8. CONCLUSIONES. ........................................................................................................................ 174
9. BIBLIOGRAFÍA. ......................................................................................................................... 176

6
RESUMEN
La determinación de la causa de los accidentes de tránsito tiene una gran utilidad para comprender
la dinámica de estos eventos.
Existe una gran cantidad de técnicas aplicables que requieren la participación de personas
involucradas de alguna manera con el análisis de accidentalidad vial y aprovechan su experiencia
en este campo.
La minería de datos es una tecnología emergente que se adapta a fenómenos de distinta complejidad
como son los accidentes de tránsito y permiten utilizar la información contenida en los datos
acumulados de accidentalidad y que por lo general administran las agencias del estado encargadas
de formular políticas para disminuirla.
En este trabajo se han utilizado dos base de datos de accidentalidad. La primera con 38 campos y
34628 registros o instancias disponible en el portal de datos abiertos.
(https://www.datos.gov.co/widgets/79fi-zm8c)
La segunda base de datos tiene información solamente de accidentes de tránsito en empresas de
transporte. Para ello se ha utilizado información de empresas aseguradas con Allianz, como Coca
Cola, transportes Iceberg, Transportes La Carolina, Pronavicola, Servientrega, Transmeta, Femsa
logística, transportadora nacional de Coca Cola, Harinera del Valle, Sistema de transporte masivo
de Cali (MIO), Conalvías.
El modelo para causa raíz se ha dividido en dos partes: Esta base de datos tiene información de 880
siniestros en diferentes ciudades y carretas nacionales.
El modelo de causa raíz se ha dividido en dos partes, uno para encontrar la causa próxima y el otro
para la causa raíz de los accidentes.
Para ello Se han propuesto dos algoritmos para analizar los datos de estas bases; redes neuronales
artificiales (perceptrón multicapas) y Naive Bayes, que sirven para clasificar los datos
corresp0ndientes a casos nuevos baja la etiqueta de causa de accidente. Se ha utilizado el software
libre Weka.
Se encuentra que el algoritmo Naive Bayes tiene un mejor desempeño que la red neuronal, la cual
requiere una gran capacidad de procesamiento.
La segunda parte para encontrar la posible causa raíz de los accidentes. Para ello se ha utilizado la
base de datos 2 y el algoritmo PART.

7
La validación de los modelos se ha realizado aplicando las métricas normalmente disponibles.
Adicionalmente se ha analizado y aplicado el algoritmo al caso de siniestro de un vehículo de
transportes Iceberg.
Palabras claves:
Accidentalidad vial, minería de datos, redes neuronales, algoritmo de Naive Bayes, causa raíz ,
causa inmediata, Weka.

8
1. INTRODUCCION.
La accidentalidad vial en las carretas colombianas ha sido claramente identificada como un
problema de salud pública por parte de las entidades del estado relacionadas con los sectores de
salud y transporte. Dadas las cifras documentadas de accidentalidad vial, se observa que las
medidas tomadas por los diferentes implicados en el problema no han dado los resultados
esperados. Se han logrado disminuciones no muy significativas en el número de accidentes en las
vías.
Para tratar este problema el estado ha ampliado la legislación la cual ha evolucionado hacia la
organización de las empresas encargadas de prestar el servicio y de sus procesos asociados.
También ha intentado establecer políticas de promoción de prácticas de comportamiento
saludables. Estas disposiciones van dirigidas principalmente a mejorar el nivel de gestión de las
empresas.
Las investigaciones relacionadas con accidentalidad muestran que existe una relación muy estrecha
entre la gestión de los factores de riesgo principalmente los relacionados con el comportamiento
humano y los indicadores de accidentalidad. Aquí participan también factores asociados con el
vehículo y las condiciones de la vía.
Para la formulación de las políticas públicas tendientes a disminuir la accidentalidad y su impacto
en la sociedad y la economía de la nación, es importante conocer las causas más frecuentes de los
mismos.
Este trabajo pretende formular un modelo computacional basado en técnicas de gestión de
información, para realizar una aproximación a la determinación de las causas mencionadas.

9
2. PLANTEAMIENTO DEL PROBLEMA.
Una de las actividades más importantes dentro del proceso de gestión del riesgo es la investigación
de los accidentes y la determinación de sus causas para formular los controles y soluciones
adecuadas al mismo.
Dentro de las metodologías utilizadas para realizar el análisis del accidente se encuentran las de
cinco porque, espina de pescado o Ishikawa, árbol de decisión, análisis de causa efecto y otras.
Estas metodologías recurren a la experiencia y análisis lógico por parte de los integrantes del
equipo que realiza la actividad.
La mayoría de ellas utilizan la experiencia de las personas familiarizadas con esta clase de trabajo,
sin embargo no tienen en cuenta de una manera sistemática la información existente sobre casos
de accidentalidad vial para extraer relaciones y patrones de accidentalidad que pueden servir para
determinar de una manera más precisa las causas de los accidentes.
Poder realizar una identificación de las causas próximas y básicas que permita una confiabilidad
adecuada en la estimación es una tarea difícil, debido a la cantidad de variables que intervienen en
el accidente y a la complejidad de sus relaciones. Esto es más cierto cuando no existe mucha
información de las condiciones prevalecientes en el momento y lugar del accidente.
Lo anterior constituye el problema objeto de este trabajo, que busca aplicar técnicas de análisis de
datos referentes a los accidentes de tránsito para determinar con buena confiabilidad las causas
próxima y básica de los accidentes de tránsito.
Las modernas técnicas de minería de datos e inteligencia artificial proveen herramientas que
permiten identificar patrones de comportamiento de los datos y llevar a la identificación de las
causas raíz de los accidentes dentro de un proceso probabilístico que permita obtener respuestas
con una exactitud razonable a la pregunta : “qué ocasionó el accidente"?. En esta propuesta se
plantea el uso de las técnicas de inteligencia artificial particularmente el uso de redes neuronales
entrenadas con las estadísticas de accidentes disponibles para construir un algoritmo que permita
una rápida y precisa identificación de la causa raíz de los accidentes.
Se ha enfatizado en la aplicación a empresas de transporte porque en los accidentes de particulares
se evalúan las causas a nivel individual y las medidas correctivas y los controles que se puedan
sugerir deben hacerse mediante el convencimiento individual de los conductores. En una empresa,
esta puede incluir en sus políticas y procedimientos de conducción los controles de una manera
más efectiva y supervisada. Sin embargo esto no quiere decir que no se pueda aplicar al análisis de
cualquier tipo de accidente.

10
Se puede extender el análisis de la causa próxima o inmediata a cualquier tipo de vehículo empresa
o particular, teniendo en cuenta que el modelo es dinámico y se actualiza al actualizar la base de
datos con nuevos casos de accidentes de tránsito.
En la mayoría de los casos la vía es compartida por vehículos de diferente tipo, y cuando ocurre un
accidente, las causas próximas no dependen del tipo de vehículo, en la forma en que se están
formulando.
En la bibliografía consultada los modelos que se aplican tienen en cuenta el tipo de vehículo pero
no la actividad que estos realizan.
Siendo el evento de accidentalidad un suceso aleatorio de complejidad variable, el algoritmo
desarrollado no suministra la causa raíz de los accidentes, sino que ayuda en la determinación de
esta, suministrando un procedimiento estructurado y sistemático para hacerlo.

11
3. JUSTIFICACION.
La actividad del transporte de personas, bienes y mercancías implica la existencia de riesgos
tangibles cuya materialización puede tener consecuencias sobre la integridad de las personas,
activos y el medio ambiente.
Esta actividad; por realizarse principalmente en la vía, está en alguna forma fuera del control y
supervisión permanente por parte de las personas encargadas de su administración.
La accidentalidad vial como consecuencia de factores de riesgo asociados tanto con el
comportamiento de las personas como con el estado de la vía y de los vehículos, presenta cifras
que tienen una incidencia en la economía y el bienestar social.
La importancia de intervenir en la organización y operación del sistema de transporte ha llevado
al estado colombiano a expedir normas que propenden por la disminución de las cifras relacionadas
con este tipo de eventos indeseables. Recientemente se ha creado mediante Decreto 000787 de
2015, la Agencia nacional de seguridad Vial, encargada de coordinar las políticas y esfuerzos del
estado y el sector privado, para mejorar los indicadores actuales, que no solo en Colombia sino
también en el mundo ha sido considerado como evidencia de un problema de salud pública.
Entre las cifras relevantes que evidencian la existencia del problema y la necesidad de acciones
contundentes para su intervención están las siguientes:
Las estadísticas y análisis de causa raíz indican que el 90% de accidentes en la vía se relacionan
con factores de riesgo humanos como principal determinante.
En el periodo entre 2005 y 2014 se han documentado 1.800.000 incidentes viales que han tenido
una consecuencia de 58000 personas fallecidas y 411000 lesionadas. Esto conlleva consecuencias
sobre el bienestar de la población y la productividad del país.
Según fuentes del Banco Interamericano de Desarrollo (BID) el costo de estos accidentes para
el país llega a 13500 millones de dólares al año, cerca de 3 puntos del PIB. Las edades de las
personas involucradas están entre 5 y 14 años y 15 y 44 años en promedio.
Según la CEPAL; La tasa de accidentes con víctimas fatales en Colombia en el año 2013 fue
de 13.18 por cada 100000 habitantes, mayor que a principios de 2010 donde se registraron 12.2.
En el continente es superada solamente por Canadá, Estados Unidos, México, Guatemala y Chile.
El estado a través de sus instituciones pertinentes busca enfrentar el problema mediante el
cambio de actitud de los protagonistas, o sea cultura y pedagogía.
Si bien este intento tiene un fuerte componente de apelar a la condición individual para afrontar un
problema social, cuyo diagnóstico como se menciono tiene causas de factores de riesgo asociados

12
con el comportamiento humano, se debe tener en cuenta el papel de las organizaciones que operan
el sistema de transporte en el país.
Es innegable la importancia de disminuir la accidentalidad vial y el beneficio para las empresas
involucradas y la sociedad en general.
Es aquí en donde interviene la gestión que cada empresa realiza de su flota y sistema en
particular. Aun teniendo en cuenta que una gran cantidad de accidentes involucran a particulares e
individuos, como es el caso de los motociclistas y a los vehículos particulares, que no pertenecen
a empresas, e incluso a peatones que tampoco sufren accidentes en cumplimiento de sus actividades
laborales, por lo general los accidentes relacionados con flotas empresariales aportan cifras
importantes al analizar el problema.
El objetivo principal al desarrollar el algoritmo es poder identificar causas básicas de
accidentes de tránsito y aplicarlo en empresas de transporte en proyectos posteriores, para
establecer los controles que permitan por un lado disminuir los riesgos inherentes a la actividad de
transporte automotor y consecuentemente la disminución de la accidentalidad vial. Por lo tanto el
alcance del proyecto llega hasta proporcionar la herramienta que ayude en la identificación de las
causas raíz mencionadas, así como encontrar relaciones no evidentes entre los diferentes factores
de riesgo. Esta es su principal utilidad.
Desde el punto de vista del especialista en Seguridad y Salud en el trabajo, su intervención en el
diseño de controles que permitan abordar los temas de accidentalidad es una de sus posibles
actividades misionales. A su vez, la identificación de las causas de los accidentes es un paso
fundamental en el diseño de los controles mencionados. Es decir su actividad es preventiva y
correctiva.
Se propone la aplicación del modelo principalmente a las empresas de transporte ya que en los
accidentes de particulares se evalúan las causas a nivel individual y las medidas correctivas y los
controles que se puedan sugerir deben hacerse mediante el convencimiento individual de los
conductores. En una empresa, esta puede incluir en sus políticas y procedimientos de conducción
los controles de una manera más efectiva y supervisada. Sin embargo esto no quiere decir que no
se pueda aplicar al análisis de cualquier tipo de accidente.
De otro lado el número de kilómetros recorridos tanto en las carreteras como en la ciudad es alto
en el caso de empresas de transporte y por lo tanto su tiempo de exposición es mayor que en el caso
de los particulares.

13
4. OBJETIVOS.
4.1. OBJETIVO GENERAL.
Elaborar un algoritmo para análisis de causa raíz de accidentes en empresas de transporte utilizando
redes neuronales y minería de datos.
4.2. OBJETIVOS ESPECIFICOS.
• Identificar los factores de riesgo y las variables asociados con los mismos en la
accidentalidad en transporte.
• Construir un modelo para representar el evento de accidentalidad.
• Configurar una red neuronal asociado con el modelo de accidentalidad propuesto.
• Entrenar la red neuronal asignando los pesos asociados a las interacciones de las neuronas
• Calibrar y validar el modelo utilizando datos con estadísticas de accidentalidad vial en
Colombia.

14
5. ESTADO DEL ARTE.
La mayoría de literatura encontrada se centra en la aplicación de sistemas inteligentes y minería de
datos para la detección de accidentes de tránsito. A continuación se mencionan los trabajos más
relacionados con la identificación de causa raíz y otros que aplican algoritmos inteligentes para la
detección de accidentes.
Olutayo et al presentan un estudio donde comparan el desempeño de un algoritmo de res neuronales
y otro de árboles de decisión para el análisis de accidentalidad en carreteras de Nigeria. Utilizan
una base de datos de los años 2002 y 2003. La red neuronal escogida fue un perceptrón multicapas
con una tasa de entrenamiento de 0,01 tratando de minimizar el error medio absoluto y el error
cuadrático medio, obteniendo valores de 52.70% de aciertos y errores de 0.3479 y 0.5004
respectivamente. Con el algoritmo de árboles de decisión obtuvieron un mejor desempeño con
77.7% de aciertos y 0.1835% Y 0.5029% en los errores medio absoluto y medio cuadrático
respectivamente.
Weerasuriya realizó una tesis de doctorado aplicando redes neuronales a detección de accidentes
de tránsito en autopistas. Desarrolló 16 modelos de redes neuronales con diferentes arquitecturas
(feed forward y recurrent), y comparó sus resultados encontrando que los modelos con doble
número de capas ocultas presentaron un desempeño con menor error.
Jiangfeng Xi et al aplicaron un algoritmo hibrido para el análisis de causa de accidentes utilizando
minería de datos. Utilizaron reglas de asociación basado en optimización de enjambre de partículas,
para analizar la correlación entre atributos y cusas de accidentes. Para evaluar el rendimiento del
algoritmo mejorado utilizo el modelo de prueba T y el método Delphi. Obtuvo velocidades de
procesamiento diez veces superior a las de los algoritmos convencionales. El algoritmo se probó
en unas bases de datos de más de 20000 registros con 56 atributos cada una.
Elfadil Abdalla realizo un estudio para la identificación de causas de accidentes de tránsito
utilizando algoritmo de máquinas de soporte vectorial multi clase. Utilizo una base de datos de la
policía de Dubai en Emiratos Árabes Unidos. Obtuvo una precisión mayor a 75% en la predicción
de causas de accidentes de tránsito.
Srinivasan et al utilizaron una red neuronal adaptativa para la detección de accidentes de tránsito
en autopistas en Singapur. Utilizó un perceptrón multicapas, una red probabilística básica (BPN)
y una red probabilística constructiva CPNN. El perceptrón multicapas presentó el mejor desempeño
desde el punto de vista de detección de accidentes. Variando el límite entre casos positivos
verdaderos y falsos negativos, encontró tasas de detección del orden de 90%. Vario la tasa de
entrenamiento y el momentum para mejorar el rendimiento de la red neuronal.
Molinero Francisco realizó una aplicación de redes bayesianas para diagnosticar la causa raíz de
fallas en un sistema de red de comunicaciones.

15
En [4] se aplica un algoritmo hibrido de reglas de asociación y peso en las capas de atributo y valor
fe atributo para calcular la influencia de los factores desencadenantes del accidente en la severidad
de este.
Martin Luis señala que tradicionalmente se han utilizado métodos estadísticos y de análisis de
regresión para determinar la relación entre los accidentes y las causas de estos. Estos modelos
requieren la formulación de hipótesis, así como el conocimiento de las relaciones entre las
variables dependientes e independientes. Si las hipótesis no se cumplen, se pueden obtener
conclusiones erróneas.
Para resolver estos inconvenientes, se ha utilizado una técnica denominada minería de datos, para
formular los modelos del sistema bajo estudio.
S.L González Ruiz, presenta el uso de minería de datos para identificar las localizaciones de los
accidentes que tiene mayor probabilidad de ocurrir, y después se analizan para identificar los
factores que afectan los accidentes de tránsito en esas locaciones utilizando clusstering, después se
utiliza el algoritmo de reglas de asociación para revelar la correlación entre diferentes atributos en
los datos del accidente y comprender las características de estas localizaciones.
Luego se utiliza un algoritmo de asociación para clasificar la severidad del accidente. Se utiliza
después un algoritmo de15asociación para para predecir la probabilidad de accidente en la ciudad
del estudio.
Bahram Sadeghi Bigham presenta un análisis de accidentes de carretera utilizando minería de datos
y reglas de asociación. La muestra que obteniendo las reglas de asociación se puede identificar los
factores involucrados en el accidente que ocurre junto de manera fácil.
Si ocurre un evento x entonces ocurre un evento Y en M% de las veces y este patrón ocurre en N%
de todos los eventos en el dataset.
M: confianza probabilidad de que el evento Y ocurra, cuando ha ocurrido el evento X.
N Apoyo: probabilidad de que ambos eventos Y,Y ocurran simultáneamente en la base de datos.
Lift: relación de probabilidad de que ocurra Y, y la probabilidad de que ocurra X.
Avellan Joaquin, presenta un estudio sobre el uso de árboles de decisión para obtener reglas de
decisión aplicables a determinar la severidad de los accidentes de tránsito en Granda, España.
Arzlan y Kecesi desarrollan un método denominado SHARE para el análisis de causa raíz en
accidentes marítimos. Incluyen un resumen interesante de la taxonomía de causa raíz de los
accidentes, de la cual se puede tomar una parte relativa al comportamiento humano principalmente
de los operarios frente al accidente.

16
MARCO TEORICO
Se realiza a continuación una breve descripción de los principales conceptos característicos de la
accidentalidad de tránsito en carretera
5.1. CARACTERISTICAS DE UN ACCIDENTE DE TRANSITO.
De acuerdo con el artículo 2° del código Nacional de Tránsito Ley 769 del 2002, se define
Accidente de tránsito como: evento generalmente involuntario, generado al menos por un vehículo
en movimiento, que causa daños a personas y bienes involucrados en este e igualmente afecta la
normal circulación de los vehículos que se movilizan por la vía o las vías comprendidas en el lugar
o dentro de la zona de influencia del hecho.
Según Hassinger Rodriguez Mark Mirko “es un evento raro, aleatorio y de múltiples factores
siempre precedido por una situación en la que uno o más conductores no pueden hacer frente al
entorno de la carretera . Cada accidente es el resultado de una cadena de eventos que es en su
totalidad único pero algunos factores son comunes a varias circunstancias del accidente y la
identificación de estos y sus interdependencias puede llevarse a cabo mediante la técnica de
minería de datos”.
Un solo hecho o evento básico puede aparecer en muchos accidentes. Existen varios factores que
intervienen en la ocurrencia de un accidente de tránsito.
Se puede distinguir entre características antes y después del accidente, así como en características
o datos del accidente, Por ejemplo, la fecha, hora y genero de los participantes en el mismo.
El objetivo aquí es identificar las variables y las categorías a las que pertenecen, así como los
valores que pueden tener y la relación entre las mismas, para seleccionar las variables que sean
independientes. Vale decir que unas variables pueden depender de otras y en este caso se prefiere
utilizar solamente las que sean independientes.
En primer lugar, se identifican los actores presentes en la accidentalidad de tránsito así como sus
características y papel que desempeñan en el accidente, tanto antes como durante el mismo.
5.1.1. ACTORES EN LA ACCIDENTALIDAD DE TRANSITO. PELIGROS Y
FACTORES DE RIESGO.
El desempeño exitoso de la operación una vez el vehículo se encuentra en ruta, está ligado
íntimamente al desempeño y condiciones reales de los siguientes componentes:
• Equipo.
• Operario.

17
• Vía.
• Condiciones ambientales.
La combinación del estado de estos cuatro elementos determina el rendimiento del proceso de
transporte en su parte de operación.
Teniendo en cuenta lo expuesto anteriormente, los factores de riesgo se identifican considerando
las condiciones peligrosas que pueden presentar los elementos componentes mencionados.
En el caso del vehículo, se estima principalmente la influencia y los temas relacionados con la
integridad de este en todos sus sistemas y componentes, en particular los que pueden ocasionar una
pérdida en la función de control del mismo, como los sistemas de frenos, dirección, suspensión,
acople king pin, ejes, estabilidad del remolque y la carga, llantas, partes expuestas a explosión o
incendio como lo relativo al sistema eléctrico y de combustible y escape, así como los factores
ergonómicos que afectan la condición del confort del operador del equipo.
En los factores relacionados con el operador, se tiene en cuenta no solamente su condición física,
sino también sicológica, ya que por las características de su labor, se requiere una concentración
100% durante todo el tiempo que esté al frente del equipo así como un funcionamiento óptimo de
su sistema sensorial y los reflejos para tomar y ejecutar decisiones en forma rápida y correcta ,
frente a las condiciones irregulares que pueden generar el funcionamiento del equipo y la vía
propiamente dicha, incluyendo los eventos en la misma como la conducción de otros vehículos que
pueda encontrar en la carretera, la ocurrencia de condiciones climáticas y ambientales diversas
(lluvia, granizo, derrumbes, vientos fuertes, terremotos, etc.) y las amenazas a las condiciones de
seguridad física producidas por situaciones de orden público.
El panorama visto de esta forma resulta de una complejidad grande, y la presión sobre el operador
del equipo puede llegar a afectar su capacidad para un desempeño exitoso.
Factores de riesgo psico laborales: se refiere a aquellos aspectos intrínsecos y organizativos del
trabajo y a las interrelaciones humanas que al interactuar con factores humanos endógenos (edad,
patrimonio genético, antecedentes sicológicos) y exógenos (vida familiar, cultural...etc.), tienen la
capacidad potencial de producir cambios sociológicos del comportamiento (agresividad, ansiedad,
satisfacción) o trastornos físicos o psicosomáticos (fatiga, dolor de cabeza, hombros, cuello,
espalda, propensión a la úlcera gástrica, la hipertensión, la cardiopatía, envejecimiento acelerado).
Los factores de riesgos locativos: condiciones de las instalaciones o áreas de trabajo que bajo
circunstancias no adecuadas pueden ocasionar accidentes de trabajo o pérdidas para la empresa.
Como los factores de riesgo sociolaboral tienen una influencia muy grande en el desempeño del
operador del equipo, las políticas y directivas de la organización (cuando se trata de empleados

18
conductores), deben proveer sistemas de seguimiento y control para mitigar los efectos y eliminar
en lo posible las causas de estas situaciones.
En muchos procesos de análisis de causa raíz, se llega a la conclusión de que esta se relaciona con
el factor humano, ya sea a través de errores en la conducción del vehículo, ò en las medidas que
deben servir como barreras para evitar el accidente o minimizar su consecuencia. Las causas
relacionadas con el componente equipo propiamente dicha, no son las más frecuentes, y los
incidentes/accidentes en los cuales se refieren causas como sueño y cansancio del conductor, falla
en la forma de asegurar y manejar la carga (cuando aplica), no cumplimiento de las
reglamentaciones viales, maniobras riesgosas sin evaluar la oportunidad de estas, es muy claro que
son circunstancias atribuibles a decisiones que toman las personas.
En el anexo 4 se presentan la matriz de peligros y la matriz de riesgo para la empresa
TRANSPORTES ICEBERG.
Es de señalar que teniendo en cuenta el objetivo final del trabajo, no se requiere la valoración de
los riesgos, ya que para la construcción del algoritmo de búsqueda de causa próxima y causa raíz
solamente exige la identificación de los riesgos y su representación mediante los atributos de la
base de datos que se utilizará para la construcción.
Además, la valoración de los riesgos depende de características particulares de la empresa y aquí
se plantea la construcción de un algoritmo aplicable a empresas de transporte en general.
Para la construcción de la matriz de riesgo se ha utilizado la estructura de la norma NTC 45 y la
valoración de los riesgos se ha hecho empleando el método William Fine. Se han dejado sin llenar
las columnas correspondientes al factor de costo (FC) y factor de corrección (FCR, )así como la
justificación económica (JI).
A continuación se presentan en la tabla 1 una clasificación de las causas próximas o inmediatas,
las cuales, al ser analizadas en forma apropiada, permiten realizar una aproximación a la causa raíz
del accidente. Aquí se han resumido causas identificadas a partir de los trabajos realizados por
Hinfeng Xi y colaboradores, V.A Olutayo, Griselda López y colaboradores.
POSIBLES CAUSAS INMEDIATAS DE ACCIDENTES DE TRANSITO
Causas Descripción
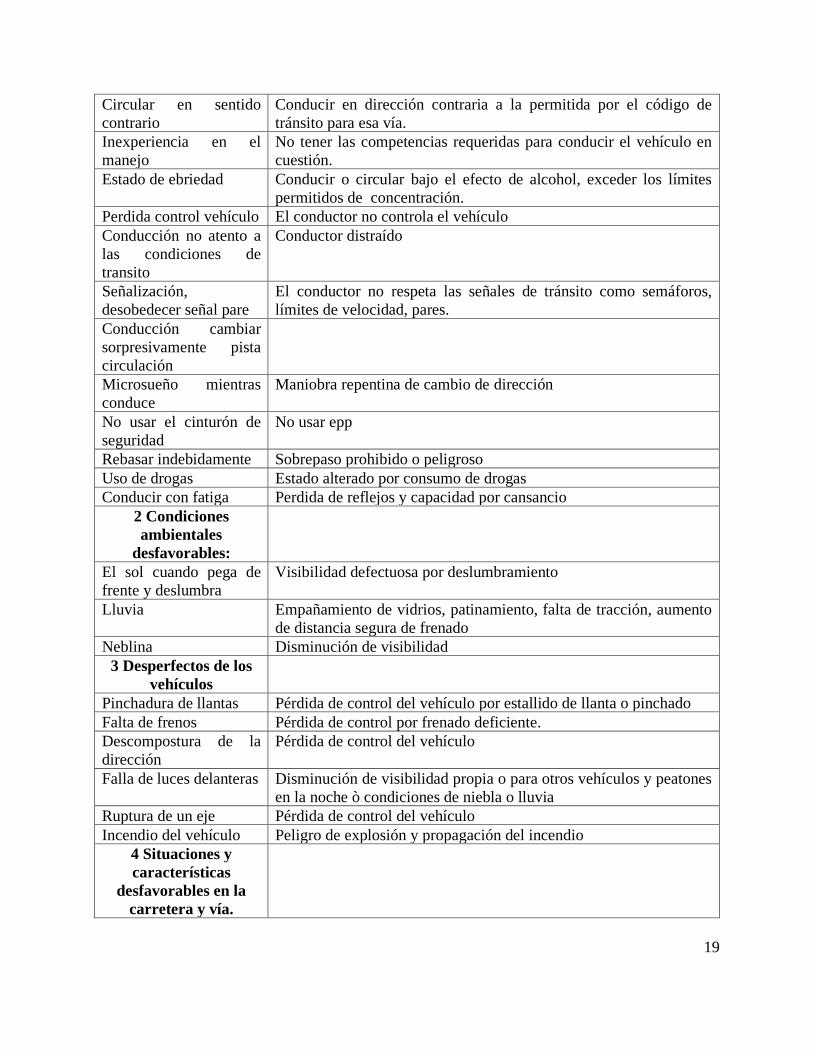
1 Conductor
Exceso de velocidad Exceder el límite de velocidad permitido para la vía.
Conducción si mantener
distancia razonable ni
prudente
Acercarse demasiado al vehículo que está por delante. En Colombia
esta distancia es de aproximadamente 10 metros en ciudad.
19
Circular en sentido
contrario
Conducir en dirección contraria a la permitida por el código de
tránsito para esa vía.
Inexperiencia en el
manejo
No tener las competencias requeridas para conducir el vehículo en
cuestión.
Estado de ebriedad Conducir o circular bajo el efecto de alcohol, exceder los límites
permitidos de concentración.
Perdida control vehículo El conductor no controla el vehículo
Conducción no atento a
las condiciones de
transito
Conductor distraído
Señalización,
desobedecer señal pare
El conductor no respeta las señales de tránsito como semáforos,
límites de velocidad, pares.
Conducción cambiar
sorpresivamente pista
circulación
Microsueño mientras
conduce
Maniobra repentina de cambio de dirección
No usar el cinturón de
seguridad
No usar epp
Rebasar indebidamente Sobrepaso prohibido o peligroso
Uso de drogas Estado alterado por consumo de drogas
Conducir con fatiga Perdida de reflejos y capacidad por cansancio
2 Condiciones
ambientales
desfavorables:
El sol cuando pega de
frente y deslumbra
Visibilidad defectuosa por deslumbramiento
Lluvia Empañamiento de vidrios, patinamiento, falta de tracción, aumento
de distancia segura de frenado
Neblina Disminución de visibilidad
3 Desperfectos de los
vehículos
Pinchadura de llantas Pérdida de control del vehículo por estallido de llanta o pinchado
Falta de frenos Pérdida de control por frenado deficiente.
Descompostura de la
dirección
Pérdida de control del vehículo
Falla de luces delanteras Disminución de visibilidad propia o para otros vehículos y peatones
en la noche ò condiciones de niebla o lluvia
Ruptura de un eje Pérdida de control del vehículo
Incendio del vehículo Peligro de explosión y propagación del incendio
4 Situaciones y
características
desfavorables en la
carretera y vía.
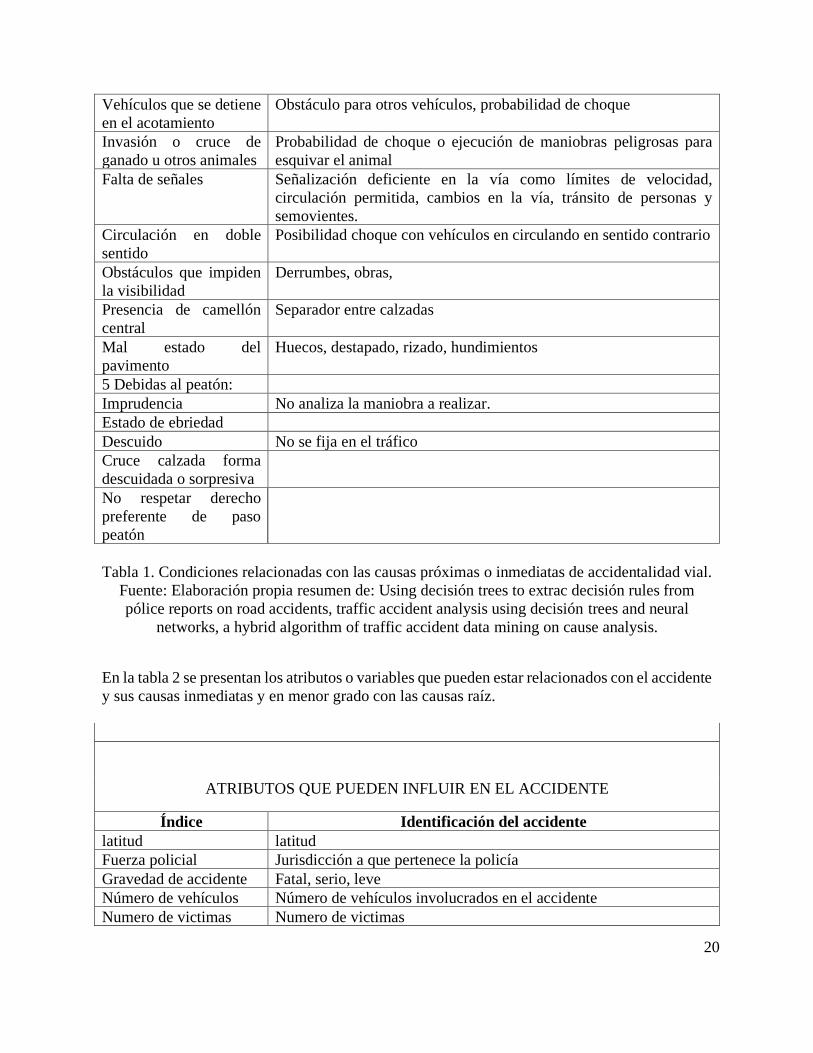
20
Vehículos que se detiene
en el acotamiento
Obstáculo para otros vehículos, probabilidad de choque
Invasión o cruce de
ganado u otros animales
Probabilidad de choque o ejecución de maniobras peligrosas para
esquivar el animal
Falta de señales Señalización deficiente en la vía como límites de velocidad,
circulación permitida, cambios en la vía, tránsito de personas y
semovientes.
Circulación en doble
sentido
Posibilidad choque con vehículos en circulando en sentido contrario
Obstáculos que impiden
la visibilidad
Derrumbes, obras,
Presencia de camellón
central
Separador entre calzadas
Mal estado del
pavimento
Huecos, destapado, rizado, hundimientos
5 Debidas al peatón:
Imprudencia No analiza la maniobra a realizar.
Estado de ebriedad
Descuido No se fija en el tráfico
Cruce calzada forma
descuidada o sorpresiva
No respetar derecho
preferente de paso
peatón
Tabla 1. Condiciones relacionadas con las causas próximas o inmediatas de accidentalidad vial.
Fuente: Elaboración propia resumen de: Using decisión trees to extrac decisión rules from
pólice reports on road accidents, traffic accident analysis using decisión trees and neural
networks, a hybrid algorithm of traffic accident data mining on cause analysis.
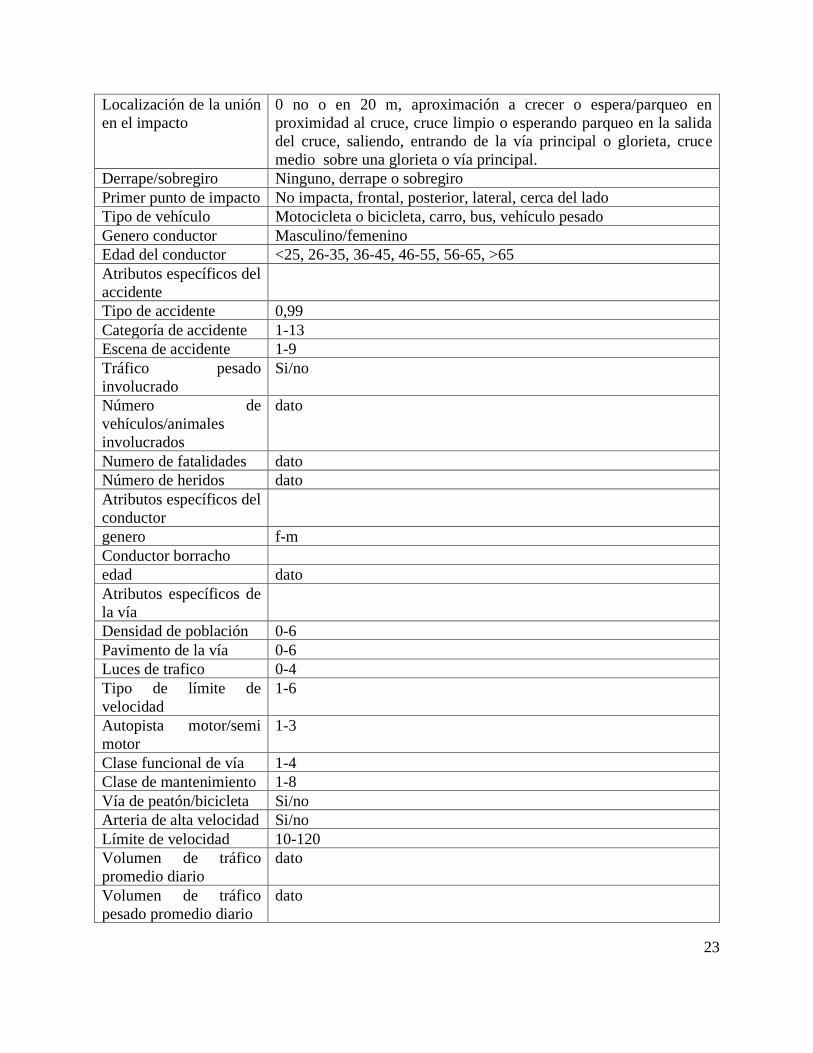
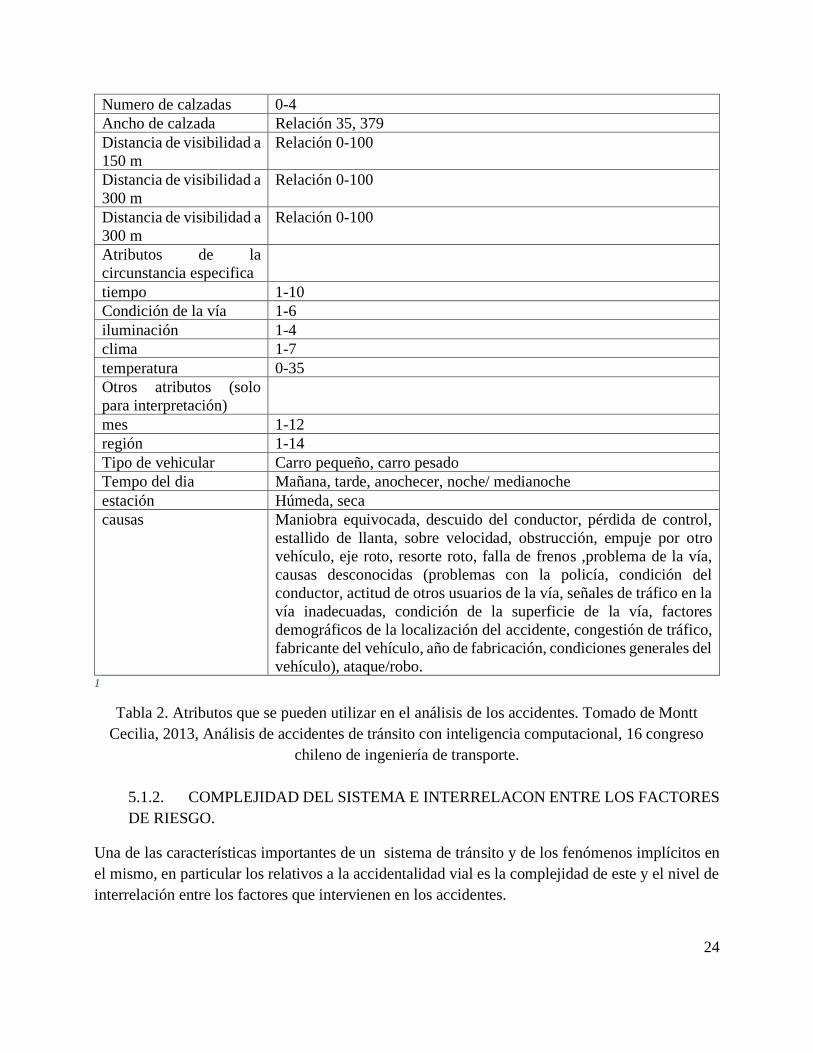
En la tabla 2 se presentan los atributos o variables que pueden estar relacionados con el accidente
y sus causas inmediatas y en menor grado con las causas raíz.
ATRIBUTOS QUE PUEDEN INFLUIR EN EL ACCIDENTE
Índice Identificación del accidente
latitud latitud
Fuerza policial Jurisdicción a que pertenece la policía
Gravedad de accidente Fatal, serio, leve
Número de vehículos Número de vehículos involucrados en el accidente
Numero de victimas Numero de victimas
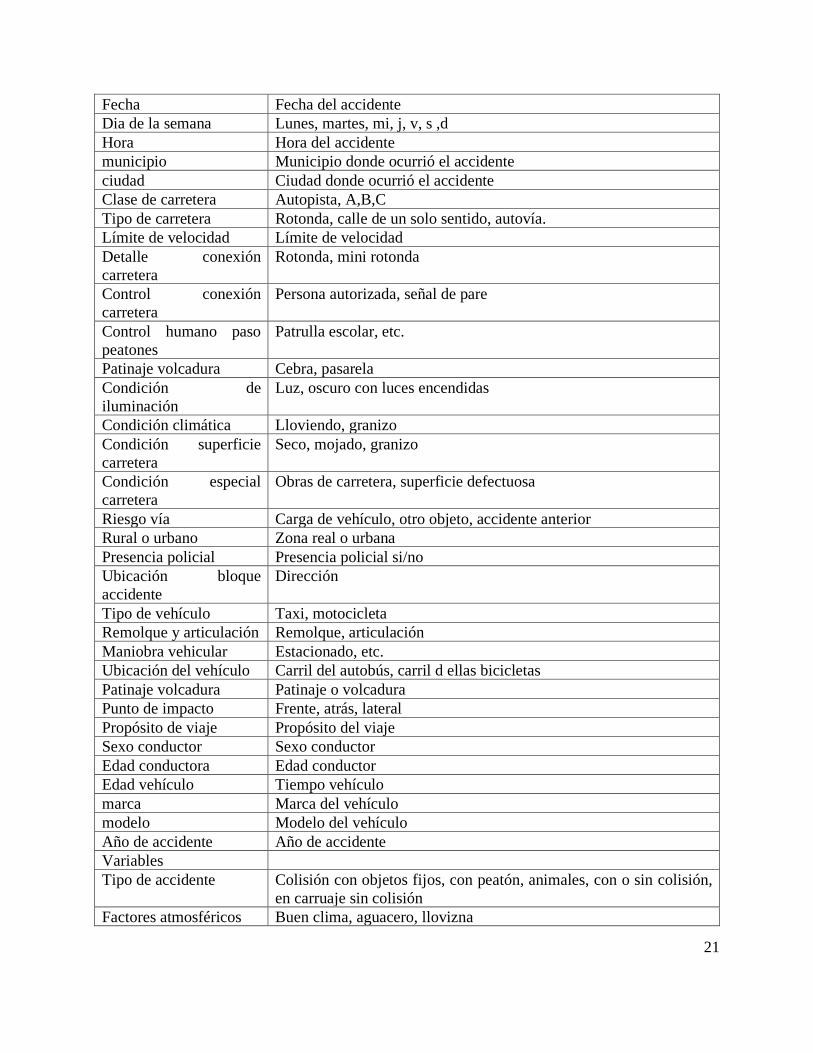
21
Fecha Fecha del accidente
Dia de la semana Lunes, martes, mi, j, v, s ,d
Hora Hora del accidente
municipio Municipio donde ocurrió el accidente
ciudad Ciudad donde ocurrió el accidente
Clase de carretera Autopista, A,B,C
Tipo de carretera Rotonda, calle de un solo sentido, autovía.
Límite de velocidad Límite de velocidad
Detalle conexión
carretera
Rotonda, mini rotonda
Control conexión
carretera
Persona autorizada, señal de pare
Control humano paso
peatones
Patrulla escolar, etc.
Patinaje volcadura Cebra, pasarela
Condición de
iluminación
Luz, oscuro con luces encendidas
Condición climática Lloviendo, granizo
Condición superficie
carretera
Seco, mojado, granizo
Condición especial
carretera
Obras de carretera, superficie defectuosa
Riesgo vía Carga de vehículo, otro objeto, accidente anterior
Rural o urbano Zona real o urbana
Presencia policial Presencia policial si/no
Ubicación bloque
accidente
Dirección
Tipo de vehículo Taxi, motocicleta
Remolque y articulación Remolque, articulación
Maniobra vehicular Estacionado, etc.
Ubicación del vehículo Carril del autobús, carril d ellas bicicletas
Patinaje volcadura Patinaje o volcadura
Punto de impacto Frente, atrás, lateral
Propósito de viaje Propósito del viaje
Sexo conductor Sexo conductor
Edad conductora Edad conductor
Edad vehículo Tiempo vehículo
marca Marca del vehículo
modelo Modelo del vehículo
Año de accidente Año de accidente
Variables
Tipo de accidente Colisión con objetos fijos, con peatón, animales, con o sin colisión,
en carruaje sin colisión
Factores atmosféricos Buen clima, aguacero, llovizna
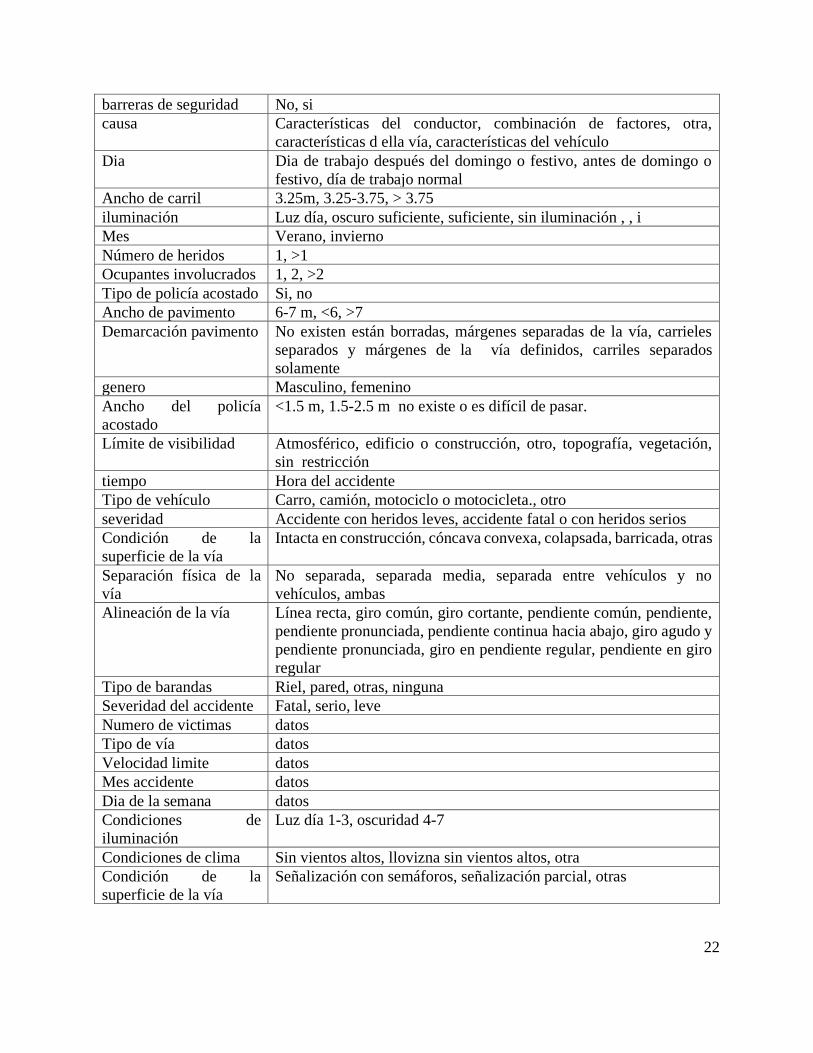
22
barreras de seguridad No, si
causa Características del conductor, combinación de factores, otra,
características d ella vía, características del vehículo
Dia Dia de trabajo después del domingo o festivo, antes de domingo o
festivo, día de trabajo normal
Ancho de carril 3.25m, 3.25-3.75, > 3.75
iluminación Luz día, oscuro suficiente, suficiente, sin iluminación , , i
Mes Verano, invierno
Número de heridos 1, >1
Ocupantes involucrados 1, 2, >2
Tipo de policía acostado Si, no
Ancho de pavimento 6-7 m, <6, >7
Demarcación pavimento No existen están borradas, márgenes separadas de la vía, carrieles
separados y márgenes de la vía definidos, carriles separados
solamente
genero Masculino, femenino
Ancho del policía
acostado
<1.5 m, 1.5-2.5 m no existe o es difícil de pasar.
Límite de visibilidad Atmosférico, edificio o construcción, otro, topografía, vegetación,
sin restricción
tiempo Hora del accidente
Tipo de vehículo Carro, camión, motociclo o motocicleta., otro
severidad Accidente con heridos leves, accidente fatal o con heridos serios
Condición de la
superficie de la vía
Intacta en construcción, cóncava convexa, colapsada, barricada, otras
Separación física de la
vía
No separada, separada media, separada entre vehículos y no
vehículos, ambas
Alineación de la vía Línea recta, giro común, giro cortante, pendiente común, pendiente,
pendiente pronunciada, pendiente continua hacia abajo, giro agudo y
pendiente pronunciada, giro en pendiente regular, pendiente en giro
regular
Tipo de barandas Riel, pared, otras, ninguna
Severidad del accidente Fatal, serio, leve
Numero de victimas datos
Tipo de vía datos
Velocidad limite datos
Mes accidente datos
Dia de la semana datos
Condiciones de
iluminación
Luz día 1-3, oscuridad 4-7
Condiciones de clima Sin vientos altos, llovizna sin vientos altos, otra
Condición de la
superficie de la vía
Señalización con semáforos, señalización parcial, otras
23
Localización de la unión
en el impacto
0 no o en 20 m, aproximación a crecer o espera/parqueo en
proximidad al cruce, cruce limpio o esperando parqueo en la salida
del cruce, saliendo, entrando de la vía principal o glorieta, cruce
medio sobre una glorieta o vía principal.
Derrape/sobregiro Ninguno, derrape o sobregiro
Primer punto de impacto No impacta, frontal, posterior, lateral, cerca del lado
Tipo de vehículo Motocicleta o bicicleta, carro, bus, vehículo pesado
Genero conductor Masculino/femenino
Edad del conductor <25, 26-35, 36-45, 46-55, 56-65, >65
Atributos específicos del
accidente
Tipo de accidente 0,99
Categoría de accidente 1-13
Escena de accidente 1-9
Tráfico pesado
involucrado
Si/no
Número de
vehículos/animales
involucrados
dato
Numero de fatalidades dato
Número de heridos dato
Atributos específicos del
conductor
genero f-m
Conductor borracho
edad dato
Atributos específicos de
la vía
Densidad de población 0-6
Pavimento de la vía 0-6
Luces de trafico 0-4
Tipo de límite de
velocidad
1-6
Autopista motor/semi
motor
1-3
Clase funcional de vía 1-4
Clase de mantenimiento 1-8
Vía de peatón/bicicleta Si/no
Arteria de alta velocidad Si/no
Límite de velocidad 10-120
Volumen de tráfico
promedio diario
dato
Volumen de tráfico
pesado promedio diario
dato
24
Numero de calzadas 0-4
Ancho de calzada Relación 35, 379
Distancia de visibilidad a
150 m
Relación 0-100
Distancia de visibilidad a
300 m
Relación 0-100
Distancia de visibilidad a
300 m
Relación 0-100
Atributos de la
circunstancia especifica
tiempo 1-10
Condición de la vía 1-6
iluminación 1-4
clima 1-7
temperatura 0-35
Otros atributos (solo
para interpretación)
mes 1-12
región 1-14
Tipo de vehicular Carro pequeño, carro pesado
Tempo del dia Mañana, tarde, anochecer, noche/ medianoche
estación Húmeda, seca
causas Maniobra equivocada, descuido del conductor, pérdida de control,
estallido de llanta, sobre velocidad, obstrucción, empuje por otro
vehículo, eje roto, resorte roto, falla de frenos ,problema de la vía,
causas desconocidas (problemas con la policía, condición del
conductor, actitud de otros usuarios de la vía, señales de tráfico en la
vía inadecuadas, condición de la superficie de la vía, factores
demográficos de la localización del accidente, congestión de tráfico,
fabricante del vehículo, año de fabricación, condiciones generales del
vehículo), ataque/robo. 1
Tabla 2. Atributos que se pueden utilizar en el análisis de los accidentes. Tomado de Montt
Cecilia, 2013, Análisis de accidentes de tránsito con inteligencia computacional, 16 congreso
chileno de ingeniería de transporte.
5.1.2. COMPLEJIDAD DEL SISTEMA E INTERRELACON ENTRE LOS FACTORES
DE RIESGO.
Una de las características importantes de un sistema de tránsito y de los fenómenos implícitos en
el mismo, en particular los relativos a la accidentalidad vial es la complejidad de este y el nivel de
interrelación entre los factores que intervienen en los accidentes.

25
Según el accidente se puede describir mediante un sistema espacio tiempo en el cual se distinguen
tres fases; percepción, decisión y conflicto.
La percepción se refiere al acto mediante el cual el conductor o persona involucrada en él, se da
cuenta de que existe una situación anómala que puede desencadenar un accidente. Esta condición
puede ocurrir de un momento para otro, o en un lapso. Por ejemplo, cuando el conductor está
conduciendo dentro de las condiciones normales respetando su carril en la vía ,así como la
velocidad adecuada, con el vehículo en condiciones normales y de un momento a otro parece un
vehículo, peatón, semoviente invadiendo su carril en una curva, esto constituye una condición
inesperada para el conductor y el tiempo para elaborar, tomar y ejecutar una decisión puede ser
muy corto.
De otro lado, si la visibilidad es buena, la carretera recta y se presenta la misma situación, quizás
el conductor puede advertir la misma con una anticipación suficiente para tomar la decisión
adecuada y ejecutar la maniobra tendiente a evitar la colisión, o al menos disminuir sus
consecuencias.
Al colocar como actores principales a las personas; conductor y peatones, este análisis se centra en
las decisiones tomadas por estos actores, cuando se percibe el peligro inminente de accidente.
Debido a que los factores y las correspondientes variables que pueden incidir en el accidente son
muchas y en algunos casos no todas están presentes, la complejidad del proceso de accidente de
tránsito puede ser variable. Además de esto, las decisiones tomadas por las personas incluyen un
proceso de razonamiento que como todo acto humano puede tener motivaciones muy particulares,
el análisis de estas puede ser bastante simple o por otro lado muy complejo. También participan
aquí los actos reflejos o decisiones que no son completamente conscientes sino el producto de las
vivencias del individuo que las toma.
La determinación de las causas de los accidentes requiere la existencia de registros que permitan
al investigador hacer una reconstrucción lo más fiel posible de los hechos que antecedieron al
accidente.
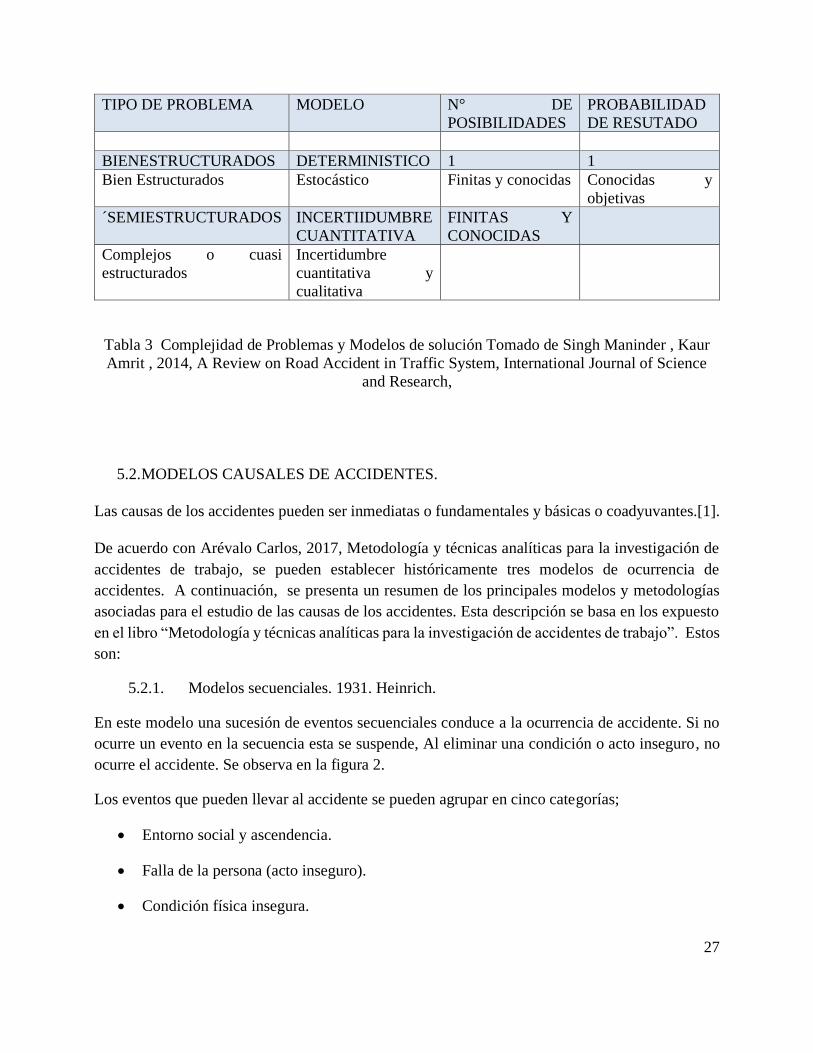
Según Vásquez en ¨ Causas de los accidentes de tránsito desde una visión de la medicina social”,
las relaciones entre la causa raíz de los accidentes, la causa inmediata y los factores de riesgo
asociados, se puede resumir en la figura 1. Se reconoce la multicausalidad de los accidentes de
tránsito, tratando de no asociarlos a numerosas causas sin que se puedan identificar las más
probables, ni a tan pocas como para perder la verdadera relación entre el accidente y las posibles
causas.

26
Figura 1 Esquema jerárquico multicausal aplicado a los accidentes de tránsito. Tomado de causa
de los accidentes de tránsito desde una visión de la medicina epidemiológica.
Según Fernández, el problema de la accidentalidad vial se puede catalogar como complejo, de
acuerdo con la tabla 3.
TIPO DE
PROBLEMA
MODELO NUMERO DE
POSIBILIDADES
PROBABILIDAD
DE RESULTADO
Bien Estructurados Determinístico 1 1
Bien Estructurados Estocástico Finitas y conocidas Conocidas y
objetivas
Semiestructurados Incertidumbre
cuantitativa
Finitas y conocidas
Complejos o cuasi
estructurados
Incertidumbre
cuantitativa y
cualitativa
DETERMINAN
TES BASICOS
POBLACION AMBIENTE
ORGANIZACIÓN SOCIAL GENOMA
DETERMINANTES
RSTRUCTURALES
INDICE DE MOTORIZACION DEL PAIS NIVEL DE
URBANIZACION SEÑALIZACION VIAL
LEGISLACION SEGURIDAD VIAL EDUCACION
VIAL TOLERAN CIA SOCIAL CONSUMO DE
ALCOHOL Y DROGAS %CONDCUTORES MENORES
DE 25 ALOS MAYORES DE 65
DETERMINANTES
PROXIMOS
CONGESTIO VEHICUAR EN VIA PUBLICA
MAL ESTADO DE LA VIA SEDÑALIZACION
MALAS CONDICIONES CLIMATICAS ESCESO
DE VELOCIDAD IMPERICIA EN EL MANEJO
INTOXICACION ETILICA DEL CONDUCTOR
27
TIPO DE PROBLEMA MODELO N° DE
POSIBILIDADES
PROBABILIDAD
DE RESUTADO
BIENESTRUCTURADOS DETERMINISTICO 1 1
Bien Estructurados Estocástico Finitas y conocidas Conocidas y
objetivas
´SEMIESTRUCTURADOS INCERTIIDUMBRE
CUANTITATIVA
FINITAS Y
CONOCIDAS
Complejos o cuasi
estructurados
Incertidumbre
cuantitativa y
cualitativa
Tabla 3 Complejidad de Problemas y Modelos de solución Tomado de Singh Maninder , Kaur
Amrit , 2014, A Review on Road Accident in Traffic System, International Journal of Science
and Research,
5.2. MODELOS CAUSALES DE ACCIDENTES.
Las causas de los accidentes pueden ser inmediatas o fundamentales y básicas o coadyuvantes.[1].
De acuerdo con Arévalo Carlos, 2017, Metodología y técnicas analíticas para la investigación de
accidentes de trabajo, se pueden establecer históricamente tres modelos de ocurrencia de
accidentes. A continuación, se presenta un resumen de los principales modelos y metodologías
asociadas para el estudio de las causas de los accidentes. Esta descripción se basa en los expuesto
en el libro “Metodología y técnicas analíticas para la investigación de accidentes de trabajo”. Estos
son:
5.2.1. Modelos secuenciales. 1931. Heinrich.
En este modelo una sucesión de eventos secuenciales conduce a la ocurrencia de accidente. Si no
ocurre un evento en la secuencia esta se suspende, Al eliminar una condición o acto inseguro, no
ocurre el accidente. Se observa en la figura 2.
Los eventos que pueden llevar al accidente se pueden agrupar en cinco categorías;
• Entorno social y ascendencia.
• Falla de la persona (acto inseguro).
• Condición física insegura.

28
• Accidentes y lesiones.
Figura 2. Teoría causal o de fichas de dominó. Tomado de Arévalo Carlos, 2017, Metodología y
técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.
5.2.2. Modelos epidemiológicos 1997 (Reason).
Son modelos lineales que consideran los accidentes como el resultado de una combinación de
condiciones inseguras latentes, condiciones activas o actos inseguros. En este caso las causas
básicas son las condiciones inseguras, que se activan mediante la ejecución de un acto inseguro.
Los accidentes se previenen fortaleciendo las barreras o defensas. Los actos inseguros se pueden
observar directamente mientras las condiciones inseguras son latentes, diseño, organización,
formación, desequilibrio entre niveles de competencia y responsabilidades. Según esta teoría el
hecho de que no todos los actos inseguros se conviertan en accidentes es debido a la existencia de
las barreras creadas por la organización. Las deficiencias en las defensas pueden cambiar con el
tiempo.
Debido a la incidencia de los factores organizativos, el error humano no se considera una causa
sino un efecto. Permite detectar interacciones complejas y se centra en la organización y gestión.
Las condiciones latentes a nivel de organización y gestión y los factores de organización del lugar
de trabajo facilitan la ocurrencia de actos inseguros y estos ante la deficiencia en las barreras, los
accidentes. Si las barreras se ubican en niveles más bajos del modelo, se requieren más errores o
actos inseguros para romperlas.
Se incluyen las condiciones latentes presentes en el sistema para la ocurrencia de cualquier
accidente, figura 3.
Las deficiencias de la organización y gestión se consideraban normales antes del accidente.

29
Figura 3. Modelo epidemiológico, tomado de Arévalo Carlos, 2017, Metodología y técnicas
analíticas para la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.
5.2.3. Modelos sistémicos avanzados Docker, 2006.
Los accidentes se producen por combinaciones inesperadas de condiciones normales, en lugar de
fallas humanas. La naturaleza del fenómeno es compleja. Aunque el trabajador tome una
decisión acertada, al combinarse con otra variable se produce la falla del sistema. De acuerdo con
esto, si no existen las otras condiciones, la acción del trabajador no hubiera producido la falla o
accidente. Existen factores causales que con base en la correlación propia de la obra o el proyecto
pueden aumentar sus efectos.
5.2.4. Relaciones de causalidad.
Tradicionalmente las técnicas para el análisis de accidentes se basan en establecer una relación
jerárquica entre la causa y el efecto como en el árbol de causa efecto. A partir del accidente se trata
de ir estableciendo la ocurrencia de causas y actos inseguros, figura 4.
En este modelo se suponen:
• La causa precede al efecto en el tiempo.
• La misma causa genera siempre el mismo efecto.
La causa se refiere en términos modernos a factores mecánicos o físicos, mientras que en los demás
casos se refiere a factores causales.
Factor causal: acto o condición necesaria para llegar a la secuencia del accidente.

30
Causas directas o primarias: factores, condiciones o acciones que desencadenaron de manera
inmediata el accidente. Son las condiciones presentes en el lugar del accidente.
Causas, factor causal: son factores que en combinación con otros aumentan la probabilidad de
ocurrencia del accidente, pero que aisladamente no lo producen.
Factores coadyuvantes: son aquellos de condición más general y permanente que afectan las
condiciones de trabajo relacionado y que por sí mismos no producen el accidente, incrementan la
probabilidad de ocurrencia de este.
Causa raíz o básica: causa primordial del accidente, relacionada con los aspectos más generales y
sistémicos de la organización y gestión del trabajo. Una causa básica genera varios factores
coadyuvantes.
El análisis de causa raíz debe incluir el análisis de las barreras existentes.
Las causas básicas pueden ser:
• Barreras insuficientes o inadecuadas.
• Fallos activos.
• Precursores de fallos humanos.
• Condiciones inseguras. (gestión, organización o lugar del trabajo).
Figura 4 Modelo de investigación de accidentes. Tomado de Arévalo Carlos, 2017, Metodología y
técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.
5.3. METODOS DE INVESTIGACION DE ACCIDENTES.

31
Existen numerosas técnicas y metodologías que se han utilizado para el análisis de accidentes. De
cualquier manera, el análisis termina siendo realizado por un equipo de expertos, que finalmente
llega a una conclusión utilizando una de las metodologías existentes. Según Arévalo Carlos, una
clasificación de estas técnicas, teniendo como base los modelos de causas de accidentes
presentados anteriormente, es la siguiente;
• Técnicas basadas en Métodos secuenciales.
• Técnicas basadas Métodos epidemiológicos.
• Técnicas basadas en Métodos sistémicos.
En la tabla 4 se muestran diferentes técnicas clasificadas como se dijo anteriormente.
En la figura 10 se presenta un diagrama de procesos para la investigación de accidentes según
Niven Karen.
A continuación, se describe brevemente de acuerdo con Arévalo Carlos, las técnicas más utilizadas.
5.3.1. Técnicas basadas en modelos secuenciales.
Se presentan las principales técnicas pertenecientes a los modelos definidos anteriormente.
Árbol de causas.
Se busca evidenciar las relaciones entre los hechos que han producido el accidente. La pregunta
que se hace es qué tuvo que ocurrir para que se produjera el hecho. Para hallar la respuesta se busca
reconstruir las circunstancias en el momento anterior al accidente. Esto permite identificar las
causas coadyuvantes y raíz.
Se cumplen los principios de encadenamiento, conjunción, disyunción.
Se identifican las causas que, propiciando el origen del accidente, no necesitan una situación
anterior para ser explicadas. Cuando falta información, se desconocen los antecedentes que
propiciaron una situación. Se puede utilizar para obtener una primera aproximación cuando las
interacciones en el entorno no son muchas.
Permite una mejor aproximación y organización de las causas identificadas mediante el árbol de
causa efecto.
Se pueden manejar niveles de relevancia de las causas principales para tratar primero las más
relevantes. Se recomienda analizar globalmente el proceso de accidente e identificar las causas
primarias.

32
Se forma a partir de los modelos secuenciales e introduce modificaciones que tienen en cuenta el
proceso de gestión introduciendo causas inmediatas y básicas.
Las causas básicas se deben a fallas en los procesos de control y gestión de la empresa, siendo los
actos subestándares y las condiciones subestándar que no son controladas,(ausencias de medidas
de seguridad, mantenimiento inadecuado) , los detonantes del accidente. Las causas básicas se
agrupan en factores personales Comportamiento humano (falta de conocimiento, competencias, no
seguir procedimientos) y factores del trabajo (condiciones en el lugar de trabajo, procesos,
elementos de seguridad, equipos, normas). Los detonantes son procedimientos inadecuados o no
aplicación, figura 5.
Figura 5 Modelo de control de perdidas. Bird. Tomado de Arévalo Carlos, 2017, Metodología y
técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.
La técnica SCAT incluye las barreras dentro del desarrollo secuencial del accidente. Esta técnica
identifica tres motivos de falta de control:
• Falta o insuficiencia de programación.
• Falta de procedimientos y estándares.
• Incumplimiento de estos.

33
La información recolectada y su análisis se resumen en una gráfica que contiene cinco bloques;
descripción del incidente, contactos que pudieron llevar al accidente, causas inmediatas, causas
básicas comunes, acciones utilizadas para el control de los factores identificados.
5.3.2. TECNICAS BASADAS EN MODELOS EPIDEMIOLOGICOS.
Es una representación gráfica de la cronología del accidente en base a los sucesos, factores causales
que han contribuido al mismo. Permiten incluir sucesos que no se han probado dentro del proceso
de investigación, aunque tengan soporte probatorio. Esto se observa en la figura 6.
El método consta de sucesos (acciones y hechos a que incluyen fecha, cuantificación, (son activos),
condiciones (situaciones y circunstancias,( pasivos) está asociada al hecho e incluyen fechas y
tiempo en que concurrieron), sucesos y condiciones supuestas.
Sus etapas son:
• Cadena de sucesos acaecida.
• Identificación de factores causales.
• Análisis de condiciones de los sucesos. Relacionan los sucesos con las condiciones en que
acaecieron.
Figura 6 Análisis gráfico de factores causales. Tomado de Arévalo Carlos, 2017, Metodología y
técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.
Esta técnica es complementaria a la anterior y adiciona el análisis de barreras que podrían haber
evitado el accidente. La barrera es cualquier medio utilizado para controlar, prevenir o impedir la
ocurrencia del accidente.

34
En la figura 7 se presenta varias clases de barreras que se pueden incluir en el análisis. Estas se
pueden analizar en los niveles de la actividad que se desarrolla, la instalación y corporativo.
Figura 7 Barreras que se pueden incluir en el análisis. Tomado de Arévalo Carlos, 2017,
Metodología y técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín
de Betancourt.
Se fundamente en la presunción de que los cambios en los sistemas generan desviaciones de estos.
Los cambios pueden ser programados o imprevistos.
La técnica compara un escenario de ocurrencia del accidente, y otro en el que este no ocurre. Se
evalúan las diferencias que llevaron al accidente y el efecto que los cambios (procedimientos,
acciones, condiciones) tuvieron.
Esta técnica se puede incorporar a la anterior. Para establecer las diferencias entre los dos
escenarios, se pueden incluir las preguntas que, como, donde, cuando, quien.
5.3.3. Análisis de causa raíz. (RCA).
Es el método más utilizado y permite identificar los factores que al ser corregidos evitan la
ocurrencia del accidente.
Se centra en el sistema de gestión de la empresa y permite responder por qué ocurrió el accidente.
Puede incluir aspectos como:
Deficiencias en la organización de funciones técnicas y preventivas.
• Deficiencia en los procedimientos de gestión.

35
• Deficiencia en la programación y supervisión de trabajos.
• Pueden existir más de una causa raíz del accidente, pero no deben sobrepasar de cuatro.
El procedimiento es:
• Conocimiento previo de los hechos y sucesos alrededor del accidente.
Se puede realizar una aproximación mediante otras técnicas, y disponer de un listado inicial de
factores causales.
• Se valida la significancia y normalidad. Para ello se pregunta:
¿Si el factor se hubiera evitado, se hubiera roto la cadena del accidente?
¿El factor es habitual y ha generado el resultado esperado?
Si la primera respuesta es afirmativa y la segunda negativa, se considera un factor relevante.
El análisis debe realizarse en los diferentes niveles jerárquicos.
• Se agrupan los factores causales que dependen de una sola causa raíz.
No todas las cadenas de sucesos generan factores causales o causa raíz.
Figura 8 Agrupación de factores causales. Tomado de Arévalo Carlos, 2017, Metodología y
técnicas analíticas para la investigación de accidentes de trabajo, Fundación Agustín de
Betancourt.
Además de las metodologías convencionalmente conocidas, se proponen las siguientes
metodologías:

36
Sequential timing events plotting. STEP.
Functional resonance analysis method. FRAM.
5.3.4. Método de tablas de Forrester.
Este método se basa en la aplicación del diagrama causal a la dinámica de sistemas. Permite la
validación del modelo que representa el sistema, cómo es la evolución de las variables asociadas
al mismo y realizar un análisis de sensibilidad para observar las variaciones en las entradas y
salidas del modelo.
Mediante su aplicación se obtiene una transformación del diagrama de causas en un sistema de
ecuaciones que relacionan las variables.
Se pueden aplicar los siguientes pasos en el desarrollo del modelo por este método:
• Representación mental del sistema, incluyendo los actores que intervienen en el
mismo; en el caso de los accidentes de tránsito pueden ser el conductor, los
peatones, la vía, el vehículo, el ambiente. Esto constituye los niveles.
• Se representan los flujos que constituyen las variaciones de los niveles en el
tiempo.
• Los demás elementos se consideran variables auxiliares y los valores que
permanezcan constantes se consideran variables auxiliares constantes.
• En la figura se muestra una representación de un accidente de tránsito
utilizando los diagramas de Forrester.
Figura 9. Representación de un accidente de tránsito utilizando diagramas de Forrester. Tomado
de Modelo Dinámico-sistémico de accidentes de tránsito.
El diagrama contiene 56 variables que describen el funcionamiento del sistema.
Esta técnica permite realizar el análisis de sistemas estructurados, no estructurados, modelos
conceptuales, problemas relacionados con el sistema, soluciones y compararlas entre ellas.

37
Es aplicable al análisis de causas en accidentes de tránsito, de acuerdo con el documento
presentado por Loyola John y colaboradores en Modelo Dinámico-sistémico de accidentes de
tránsito. Realizaron un estudio aplicando la técnica de diagramas de Forrester en el estudio de
accidentalidad en la población de Trujillo en el Perú. Determinaron que las principales causas de
accidentalidad están relacionadas con el factor humano principalmente el conductor y el peatón,
por no respetar la reglamentación existente y de incurrir en actos inseguros.
Utilizaron una técnica denominada Sistemas suaves y dinámica de sistemas para determinar las
causas de los accidentes. El modelo dinámico que construyeron permite identificar las relaciones
entre los diferentes actores del sistema.
5.3.5. COMPARACION DE LAS TECNICAS.
La selección de la técnica de investigación de accidentes depende de varios elementos; el principal
de ellos incluye las características de interrelación y complejidad de los factores de riesgo del
sistema analizado. Sin embargo, existen otros factores como la disponibilidad de recursos,
incluyendo el tiempo, metodología de investigación y programación, sector en el que ocurre el
suceso investigado, calificación de los investigadores.
De acuerdo con la interrelación de los factores y la complejidad del sistema analizado, se muestran
las técnicas sugeridas de acuerdo con en la figura 10.
Figura 10 Selección de modelos de análisis de accidentes en función de la complejidad e
interacción de factores. Tomado de Arévalo Carlos, 2017, Metodología y técnicas analíticas para
la investigación de accidentes de trabajo, Fundación Agustín de Betancourt.

38
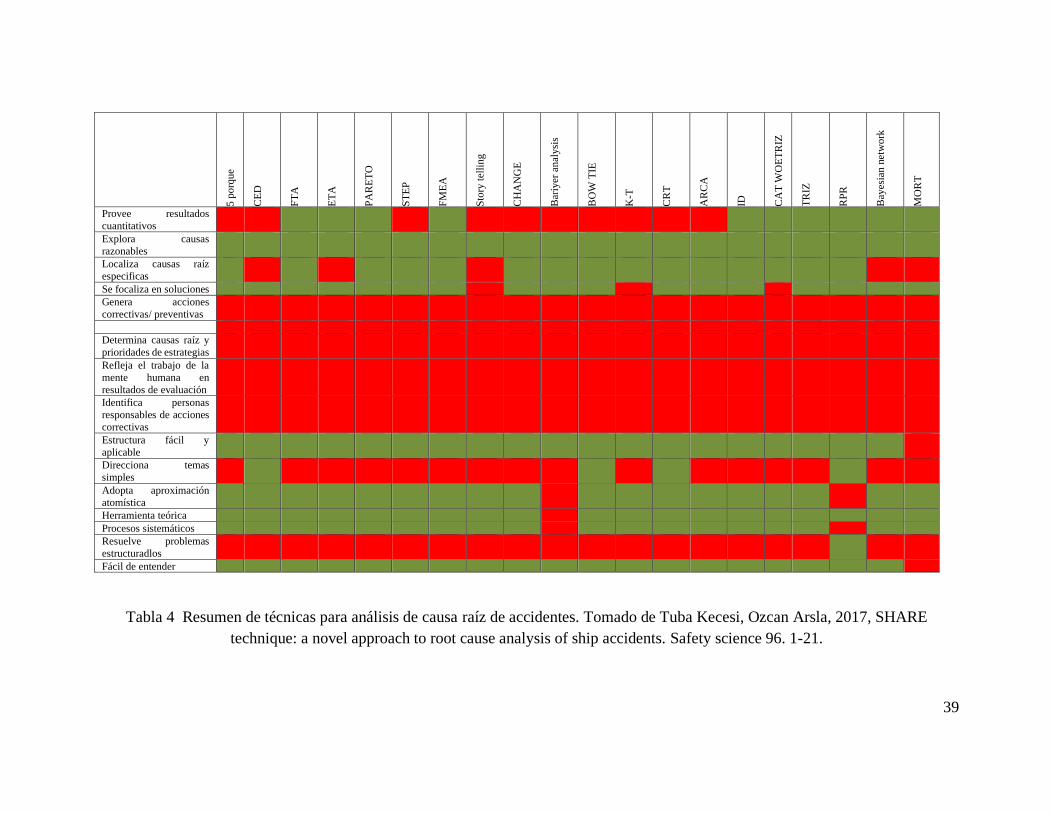
La tabla 4 presenta un resumen de técnicas utilizadas para el análisis de causas de accidentes, así
como su aplicación . Para el caso particular de análisis de causa raíz se observa que existen varias
técnicas recomendadas entre ellas cinco porque, Pareto, FMEA, Change, Baryver análisis. La
técnica de redes bayesianas encuentra causas razonables.
Los cuadros rojos indican deficiencia en la aplicación de la técnica para conseguir los objetivos de
la columna izquierda, mientras los verdes representan resultados cualitativos.
39
5 p
orq
ue
CE
D
FT
A
ET
A
PA
RE
TO
ST
EP
FM
EA
Sto
ry t
elli
ng
CH
AN
GE
Bar
iyer
anal
ysi
s
BO
W T
IE
K-T
CR
T
AR
CA
ID
CA
T W
OE
TR
IZ
TR
IZ
RP
R
Bay
esia
n n
etw
ork
MO
RT
Provee resultados
cuantitativos
Explora causas
razonables
Localiza causas raíz
especificas
Se focaliza en soluciones
Genera acciones
correctivas/ preventivas
Determina causas raíz y
prioridades de estrategias
Refleja el trabajo de la
mente humana en
resultados de evaluación
Identifica personas
responsables de acciones
correctivas
Estructura fácil y
aplicable
Direcciona temas
simples
Adopta aproximación
atomística
Herramienta teórica
Procesos sistemáticos
Resuelve problemas
estructuradlos
Fácil de entender
Tabla 4 Resumen de técnicas para análisis de causa raíz de accidentes. Tomado de Tuba Kecesi, Ozcan Arsla, 2017, SHARE
technique: a novel approach to root cause analysis of ship accidents. Safety science 96. 1-21.

40
5.4. MODELO DE ANALISIS DE CAUSA RAIZ DE ACCIDENTES.
Para realizar el análisis de causa raíz de accidentes se debe plantear en primer lugar un
modelo conceptual del accidente, después identificar los factores que inciden y coadyuvan
a la materialización del mismo así como sus relaciones y finalmente establecer un método
para realizar el análisis.
5.4.1. Modelo de accidentes de tránsito.
De acuerdo con los modelos presentados anteriormente, y el documento Dream 3.0, se
plantea un modelo de accidente para describir la dinámica del mismo, basándose en los
eventos que determinan y concurren con la ocurrencia de los accidentes.
Según Girard, todos los accidentes pueden describirse a partir de cuatro etapas;
• Fase de conducción: no hay demandas especiales sobre el conductor. La conducción
es normal. Hay un balance entre las demandas sobre el sistema uy su capacidad de
respuesta.
• Fase de discontinuidad: la continuidad se interrumpe por un evento inesperado y la
demanda sobre el sistema excede su capacidad de respuesta.
• Fase de emergencia: el tiempo y la distancia entre la discontinuidad y el impacto , el
tiempo disponible para que los componentes del sistema respondan al incremento
súbito en la demanda.
• Fase de choque o colisión.
El proceso de respuesta del conductor involucra características cognitivas, de observación,
interpretación y planeación. Existen otros factores como la desatención.
Según DREAM 3.0 existen los fenómenos o eventos observables en el momento del
accidente, denominados fenotipos,(acciones humanas y eventos del sistema) y que tienen
que ver con tiempo, velocidad, distancia, objeto, dirección, fuerza, y otros denominados
genotipos o factores coadyuvantes (humanos como fallas en interpretación, observación y
planeamiento y otros factores más generales temporales o permanentes como desatención,
así como factores del vehículo y la vía y organizacionales como mantenimiento, diseño,
logística), que incluyen factores o eventos en un blunt end (los frenos del vehículo fallan)
que están relacionados con hombre vehículo, organización, vía, y en el Sharp en (el conductor
no ve la luz roja del semáforo), con los mismos factores y que están en la proximidad del
accidente. Entre ellos existen las condiciones de falla latentes, que contribuyen al accidente.
Los eventos de blunt end y Sharp end están espaciados en el tiempo y espacio. Este modelo
no es secuencial ni jerárquico sino en forma de red. Esto se observa en la figura 11.

41
Figura 11 Representación gráfica del modelo de accidente, basado en Dream 3.0 versión
2008.
Desde el punto de vista teórico se refleja en cómo se definen los factores
contribuyentes en el esquema de clasificación, y como se relacionan entre ellos.
El esquema de clasificación incluye factores observables en el momento del accidente
(fenotipos) y factores contribuyentes al mismo (genotipos).
Los fenotipos pueden ser vistos como la causa inmediata o próxima.
Los enlaces entre fenotipos y genotipos indican la forma en que interactúan entre ellos.
Los fenotipos son los puntos finales en la cadena de causalidad. Cuando los genotipos actúan
como enlaces, se pueden deducir cadenas enteras de causas consecuencias. Al comenzar con
un fenotipo al final de la cadena de causas, se puede hacer el análisis hacia atrás hasta que no
existan más genotipos o factores significativos. El uso de enlaces debe estar soportado por la
información.
Un genotipo general puede llevar a otro genotipo general. Los genotipos contribuyen no
determinan los fenotipos.
Los diferentes vehículo comparten la misma vía con las mismas reglas. Las causas inmediatas
son coadyuvadas por las causas raíz a diferentes niveles.
Factores particulares de una empresa de transporte que influyen en las causas próximas.
Para cada vehículo participante en el accidente se selecciona un solo fenotipo.

42
En el modelo propuesto, los fenotipos corresponden a la causa próxima del accidente,
mientras los genotipos son una aproximación a la causa raíz de este. El fenotipo se debe
buscar en la fase de discontinuidad.
Fenotipos Fenotipos específicos
Tiempo Acción prematura, acción tardía, inacción
Velocidad Velocidad muy alta, velocidad muy baja
Distancia Distancia muy próxima
Dirección Dirección equivocada
Fuerza Demasiada fuerza, fuerza insuficiente
Objeto Objeto adyacente
Tabla 5 Fenotipos y fenotipos específicos de DREAM 3.0-
Los genotipos relacionados en proximidad al fenotipo se acercan a la causa próxima, mientras
que a medida que se avanza en la cadena de genotipos, el análisis se dirige hacia la causa
raíz.
5.4.2. Identificación de factores, representación y relaciones.
Partiendo de los conceptos presentados en el modelo DREAM 3.0, una vez identificados los
factores que pueden incidir en los accidentes de tránsito, se debe establecer una relación entre
ellos (genotipos) y la causa próxima (fenotipos), así como entre los mismos genotipos.(causa
raíz).
Las relaciones entre las causas próximas y los factores coadyuvantes a las mismas se
presentan en la tabla del apéndice 3. Las relaciones entre las causas coadyuvantes se
muestran en la tabla del mismo apéndice.
Estas tablas se han utilizado para construir la base de datos número 3 para la identificación
de la causa raíz del accidente de tránsito mediante las reglas de decisión suministradas por la
aplicación de la técnica PART en WEKA 3.8.
5.4.3. Metodología de análisis de causa raíz.
Una vez realizada una aproximación a la causa inmediata ò próxima del accidente, se realiza
un análisis de los resultados obtenidos mediante un panel de expertos, y se propone una
segunda aproximación esta vez a la probable causa raíz de este.

43
Siguiendo el trabajo desarrollado por Mesec y Arlan, donde realizan una clasificación
detallada de las diferentes causas atribuibles a los accidentes de barcos, se elabora una tabla
en la que se han seleccionado las causas que pueden ser aplicables a los accidentes de tránsito
por carretera. Esta información se ha complementado con la clasificación de genotipos
(antecedentes o causas) y fenotipos (consecuentes o causa próxima) proporcionada por
DREAM 3.0 y se presentan en la tabla 5.
Estas causas básicas o raíz incluyen dos categorías; las relacionadas con las personas y las
relacionadas con el factor trabajo. Muchas están orientadas a la organización o empresa y
otras a personas particulares. Como en los accidentes pueden intervenir personas naturales o
personas que conducen vehículos de empresas, se tiene en cuenta las características de ambos
tipos. En la tabla 7 se presentan los diferentes factores relacionados con los accidentes de
tránsito.

44
1 FACTORES RELACIONADOS CON LAS PERSONAS.
Características humanas
Reacción lenta
Baja aptitud de aprendizaje
Competencia
Bajas competencias de comunicación.
Complacencia
Habilidad de percepción
Percepción del riesgo
Relaciones de trabajo por debajo del óptimo
Vigilancia
Inatención
Inadecuada situacional
Distracción por temas diferentes al trabajo
Comportamiento humano
Cultura
Caracter
Falta de autodisciplina
Capacidad estrés física y fisiológica
sensibilidad
Sensibilidad o alergia a sustancias
Sensibilidad a temperatura, sonido, etc.
Deficiencias sensoriales
Deficiencia en la visión y escucha
Otras deficiencias sensoriales (gusto, tacto, equilibrio)
Discapacidades temporales/permanentes
Uso de alcohol/droga
Enfermedad
Peso, tamaño, altura, alcance inadecuados
Capacidad-estrés sicológico
Enfermedad mental, emocional
Pánico
Frustración
Miedos y fobias
Agresión inapropiada
Preocupación con problemas
Carga emocional
Presión de tiempo
Fatiga
Fatiga debida a carga o duración del trabajo
Fatiga debida a falta de descanso
Fatiga debida a sobrecarga sensorial
Fatiga debida a demandas extremas de percepción y concentración

45
Rutina, monotonía, demanda por vigilancia continua
Demandas extremas de juicio y decisión
Conocimiento, habilidades y entrenamiento deficientes
Práctica inadecuada
Conocimiento insuficiente de los equipos y sistemas
Conocimiento técnico inadecuado
Entrenamiento actualizado inadecuado
Entrenamiento inicial inadecuado
Orientación del ambiente de trabajo inadecuado
Falta de entrenamiento en equipo
Inadecuado conocimiento de las operaciones del vehículo
Falta de experiencia
Inadecuado conocimiento de las reglamentaciones y estándares
Pobre uso de la información para la toma de decisiones
Problemas de comunicación
Comunicación deficiente entre los miembros de la tripulación del vehículo
Mal entendimiento
No uso de smcp
Problema con equipo de comunicaciones
Cultura de equipo inadecuada
Ausencia de modelo mental compartido
Brm inefectivo
Falta de pertenencia
Overreliance en el equipo, las personas o el sistema
Sobre confianza en el supervisor
Liderazgo inadecuado
Relaciones conflictivas
Instrucciones iniciales inadecuadas
Falta de coaching
revisión de instrucción inadecuada
Falta de supervisión/conocimiento de gestión del trabajo
Falta de disciplina de la tripulación/pasajeros
Delegación impropia o insuficiente
Asignación de responsabilidades no clara o conflictiva
Ejemplo de supervisión inadecuada
Mano de obra insuficiente para la tarea
Temas relacionados con seguridad
Falta de cultura de seguridad
Actos inseguros
Acciones involuntarias
confusión
Desorden
Fallas de memoria
Pasar por alto

46
Intento impropio de ahorro de tiempo o esfuerzo
Intento impropio de evitar incomodidad
Sabotaje
Tomar precauciones inadecuadas
Factores de falta de motivación
Falta de incentivos
Castigo por rendimiento apropiado
El rendimiento inadecuado es premiado
Presión entre los miembros de la tripulación
Intento impropio por ganar atención
Medida inadecuada de desempeño
Retroalimentación inadecuada del desempeño
Medida y evaluación inadecuada del desempeño
Presión jerárquica
Inadecuada tripulación
Inadecuado nivel de la tripulación
Inadecuada disponibilidad de fuerza de trabajo
2 FACTORES RELACIONADOS CON EL TRABAJO
Diseño, construcción inadecuados del vehículo
Ergonomía deficiente del vehículo
Monitoreo y evaluación inadecuada de cambios
Inadecuada evaluación de preparación operacional
Ensamble defectuoso en la construcción
Defecto de construcción
Diseño inadecuado
Material de construcción inadecuado
Falla mecánica del material
Fatiga de material
Defectos de sellamiento
Soldadura defectuosa
Deterioro químico/UV
Equipo/material inadecuado
Equipo no operacional
Uso inadecuado el equipo
Herramientas/equipo inadecuado
Inadecuada disponibilidad de herramientas/equipo
Estándares y especificaciones inadecuadas de herramienta/equipo
Equipo operado por persona no autorizada
Mantenimiento inadecuado
Evaluación inadecuada de requerimientos preventivos de mantenimiento
Inadecuada reparación
Equipos/herramientas para reparación/ajuste/mantenimiento
Reparaciones provisionales inadecuadas
Inspección/monitoreo inadecuados del equipo

47
Inadecuada recuperación de salvamento del equipo
Problema con características de manejo del vehículo
Inadecuada selección del vendedor
Inadecuadas especificaciones o requisiciones
Inadecuada investigación del equipo
Inadecuada comunicación de datos de salud y seguridad
Manejo inadecuado de materiales
Almacenamiento inadecuado de materiales
Temas relacionados con la carga
Deterioro de la carga
Autoignición de la carga
Radiación
Temas relacionados con el sistema
Procedimiento, reglas y estándares
Ausencia de procedimientos en la compañía
Los procedimientos de la compañía no reúnen los requerimientos legales
Discrepancias entre procedimientos
Mala aplicación de procedimientos
Ausencia de registro y análisis de accidentes
Ausencia de sistema de lecciones aprendidas de accidentes/incidentes
Inadecuada actualización de procedimientos
Reglas, estándares y políticas
Ausencia de regulaciones, políticas y estándares
Mala aplicación de regulaciones, políticas y estándares
Regulaciones/políticas pobres, ambiguas
Estándares del trabajo
Inadecuado desarrollo de estándares de trabajo
Inadecuada comunicación de estándares de trabajo
Inadecuado monitoreo de cumplimiento de estándares de trabajo
Gestión
Gerencia de la empresa
No tomar acciones correctivas
Desorden en documentación de procesos
Fraude en certificación
Inspección inadecuada
Sistema de alerta inadecuado
Inadecuada referenciación de documentos, directrices y lineamientos
Evaluación del riesgo
Inadecuada evaluación del riesgo
Proceso de evaluación del riesgo inadecuado
Proceso de evaluación del riesgo no implementado
Toma inadecuada de precauciones relacionadas con el riesgo
Factores ambientales
Ambiente natural

48
Normal
Clima pesado
Desastres naturales
Ambiente natural peligroso
Granizo
Temperatura
humedad
Ambiente visual/iluminación
Ambiente de trabajo
Ruido
Vibración
Gestión interna deficiente
Lugar de trabajo sucio
Iluminación deficiente
Inadecuada ventilación
Factores debidos a terceros
Tabla 7 Posibles causa básica de accidentes de tránsito. Tomado de Tuba Kecesi, Ozcan
Arsla, 2017, SHARE technique: a novel approach to root cause analysis of ship accidents.
Safety science 96. 1-21.
5.5. PROCESO DE INVESTIGACION DE ACCIDENTES.
Es un proceso en el cual se pueden distinguir cuatro fases que se desarrollan secuencialmente.
La primera de ellas es la recolección de la información en el lugar del accidente. Esta etapa
es clave como entrada de las etapas posteriores y la calidad de las conclusiones o salidas de
cada una de ellas y del proceso en general. Desde el punto de vista legal esta fase es realizada
por la autoridad competente que por lo general es la policía de tránsito y en casos de
accidentes fatales la fiscalía. El documento oficial es el informe del accidente que se
documenta en el formato mostrado en el apéndice . este es diligenciado por la persona
autorizada y lleva las firmas de las personas protagonistas del accidente. Estos documentos
son almacenados y custodiados por la policía. En Colombia son un documento reservado y
para tener acceso al mismo se requiere la autorización de la ley o de las personas que
intervinieron en el accidente. Por tratarse de la primera información sobre el accidente
tomada en el sitio de ocurrencia y sobre las condiciones objetivas y reales del mismo, son la
fuente fundamental para cualquier análisis posterior a que trate de determinar
responsabilidades y las probables causas del accidente. Actualmente con los recursos
tecnológicos existen otras fuentes de información como los registros realizados por cámaras
ubicadas en proximidad del sitio del accidente. Además, se puede obtener información de
testigos presentes en el lugar.

49
Respecto del vehículo, siempre y cuando exista la posibilidad de hacerlo, en los equipos que
poseen la tecnología para ello se puede tratar de recuperar información acerca de las
condiciones de velocidad y algunos parámetros mecánicos sobre el funcionamiento de los
sistemas de este en el momento del accidente, como por ejemplo condición del sistema de
frenos o de la presión de aire en el mismo, en caso de que sea pertinente.
La segunda es la identificación y análisis de las variables contenidas en la información
recaudada.
En tercer lugar está la búsqueda de las posibles causas del accidente, aquí se utiliza alguna
de las técnicas descritas en la sección 6.2.
En la cuarta etapa se diseñan políticas y procedimientos tendientes a evitar la ocurrencia de
los accidentes o disminuir su impacto.
En general el proceso de investigación de accidentes se puede resumir en la figura 11.
ACCIDENTE DE TRABAJO
INVESTIGACION DEL ACCIDENTE
CAUSAS DEL ACCIDENTE
MEDIDAS CORRECTIVAS
DESCRIPCION DE HECHOS.HORA, LUGAR, FECHA, TURNO, TIPO DE
TRABAJO, TIPO DE VEHICULO, DIRECCION, CONDICIONES CLIMATICAS
ANALISIS DE VARIABLES CONTENIODAS EN LA DESCRIPCION DETALLADA DE LOS HECHOS. ESCOGER METODOLOGIA .
CONCLUSIONES: FALTA DE PROCEDIMIENTOS, FALLAS EN EQUIPOS Y
MAQUINAS, ACTOS INSEGUROS DEL PERSONAL, ETC.
DISEÑO DE POLITICAS YPROCEDIMIENTOS
BASE DE DATOS
PROCESO DE INVESTIGACION DE
A CCIDENTES
Figura 11 Proceso de investigación de accidentes. Tomado de Niven Karen, 2004, Real
time evaluation of health and safety management in the national health service. Recuperado
de http://www.hse.gov.uk/research/rrpdf/rr280.pdf

50
5.6. MINERIA DE DATOS.
Según Hanget al en mining road traffic accidents] se puede definir la minería de datos como
“el análisis de conjuntos de datos observacionales, generalmente de gran tamaño, con el
objetivo de encontrar relaciones no previstas y resumir los datos en formas nuevas que son
entendibles y útiles para el usuario de estos”.
De otro lado el descubrimiento de conocimiento en bases de datos (Knowledge Discovery
data)de acuerdo con Margaret Dunham [12 en mining road traffic Accidents] es “el procedo
de encontrar información y patrones útiles en los datos”.
En la figura 12, se muestra un diagrama del proceso completo de descubrimiento de
conocimiento, y de la minería de datos como una parte dentro del mismo.
Figura 12 Proceso de adquisición de conocimiento a través de minería de datos. Tomado de
Hassinger Rodriguez Mark Mirko, 2015, Aplicación técnica de minería de datos en
accidentes de tráfico, Tesis de Maestría, Universidad Politécnica de Valencia.
Según Olutayo V.A, Eleudire A.A el proceso de descubrimiento de conocimiento se puede
dividir en las siguientes etapas;

51
Selección.
• Recopilar e integrar las diferentes fuentes de datos existente.
• Identificar y seleccionar las variables relevantes en los datos.
• Aplicar las técnicas de muestreo adecuadas.
Exploración.
• Utilizar las técnicas de análisis exploratorio de datos.
• Deducir la distribución de los datos, simetría y normalidad.
• Analizar las correlaciones existentes en la información.
Limpieza.
• Detectar y tratar la presencia de valores atípicos
• Imputar la información faltante o valores perdidos.
• Eliminar datos erróneos e irrelevantes.
Transformación.
• Utilizar técnicas de reducción y aumento de la dimensión.
• Aplicar técnicas de discretización y numeración.
• Realizar escalado simple y multidimensional.
Minería de datos..
• Utilizar técnicas predictivas.
• Utilizar técnicas descriptivas.
En la minería de datos se construye un modelo basado en los datos recopilados para ello, es
una descripción de los patrones y relaciones entre los datos, que pueden usarse para hacer
predicciones, entender mejor los datos o explicar situaciones pasadas.
5.6.1. TECNICAS DE MINERIA DE DATOS.
Existen varias técnicas que permiten realizar el proceso de minería de datos, es decir construir
el modelo de datos requerido para extraer la información. Asociadas con estas técnicas se
encuentran los algoritmos o herramientas utilizadas para desarrollar las técnicas.
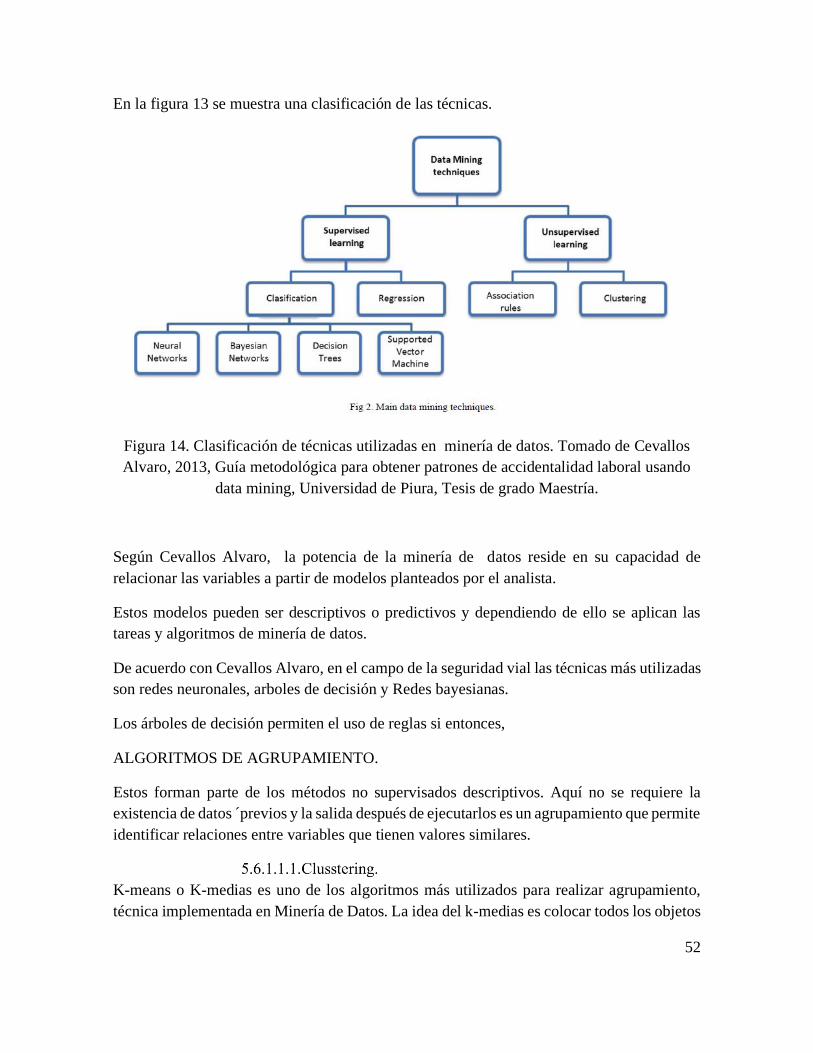
52
En la figura 13 se muestra una clasificación de las técnicas.
Figura 14. Clasificación de técnicas utilizadas en minería de datos. Tomado de Cevallos
Alvaro, 2013, Guía metodológica para obtener patrones de accidentalidad laboral usando
data mining, Universidad de Piura, Tesis de grado Maestría.
Según Cevallos Alvaro, la potencia de la minería de datos reside en su capacidad de
relacionar las variables a partir de modelos planteados por el analista.
Estos modelos pueden ser descriptivos o predictivos y dependiendo de ello se aplican las
tareas y algoritmos de minería de datos.
De acuerdo con Cevallos Alvaro, en el campo de la seguridad vial las técnicas más utilizadas
son redes neuronales, arboles de decisión y Redes bayesianas.
Los árboles de decisión permiten el uso de reglas si entonces,
ALGORITMOS DE AGRUPAMIENTO.
Estos forman parte de los métodos no supervisados descriptivos. Aquí no se requiere la
existencia de datos ́ previos y la salida después de ejecutarlos es un agrupamiento que permite
identificar relaciones entre variables que tienen valores similares.
K-means o K-medias es uno de los algoritmos más utilizados para realizar agrupamiento,
técnica implementada en Minería de Datos. La idea del k-medias es colocar todos los objetos

53
en un espacio determinado y dadas sus características formar grupos de objetos con rasgos
similares pero diferentes a los demás que integran otros grupos.
El criterio básico es el de distancia o similitud entre las observaciones.
Sin embargo, el algoritmo presenta algunos inconvenientes:
• El agrupamiento final depende de los centroides iniciales.
• La convergencia en el óptimo global no está garantizada, y para problemas con muchos
ejemplares, requiere de un gran número de iteraciones para converger [3].
Descripción del algoritmo k-means
Paso 1. Inicialización: Se definen un conjunto de objetos a los cuales se les aplica el proceso
de clustering que consiste en la división de los datos en grupos y un centroide (centro
geométrico del clústeres) para cada uno. Los centroides iniciales se pueden determinar
aleatoriamente, mientras que en otros casos procesan los datos y se determinan los centroides
mediante cálculos.
Paso 2. Clasificación: Para cada dato se calcula la distancia (euclidiana cuadrada) con
respecto a los centroides, se determina el centroide más cercano a cada uno de los datos, y el
objeto se anexa al clúster del centroide que fue seleccionado.
Paso 3. Cálculo de centroides: Para cada uno de los clústeres se vuelve a recalcular los
centroides.
Paso 4. Verificación de convergencia: En este paso se comprueba si una de las condiciones
del algoritmo se ha cumplido y que este debe parar, a esto se le llama condición de
convergencia o paro. A continuación, se mencionan algunas de las condiciones de
convergencia:
• El número de iteraciones.
• Cuando los centroides obtenidos en dos iteraciones sucesivas no cambian su valor.
• Cuando la diferencia entre los centroides de dos iteraciones sucesivas no supera cierto
umbral.
• Cuando no hay transferencia de objetos entre grupos en dos iteraciones sucesivas.
Si algunas de las condiciones de convergencia no cumplen se repiten los pasos dos, tres y
cuatro del algoritmo.
ALGORITMOS DE CLASIFICACION.

54
Los algoritmos de clasificación son técnicas supervisadas, en las cuales se realiza un
aprendizaje a partir de unos datos disponibles, y una vez ajustado el modelo de clasificación
o predicción, se realiza una prueba para ajustar el modelo de predicción.
La escogencia del algoritmo adecuado para realizar la actividad de clasificación depende
entre otras cosas de la naturaleza de los datos. Cuando estos son nominales, se utilizan
técnicas como las redes neuronales artificiales, mientras que para datos numéricos se utilizan
técnicas como la regresión.
A continuación, se describen las redes neuronales artificiales y el algoritmo Naive Bayes.
Las redes neuronales artificiales son algoritmos de procesamiento de datos basados en el
funcionamiento de las neuronas biológicas. Para ello tratan de imitar las conexiones
existentes entre las diferentes neuronas para transmitir señales que contienen datos.
El objetivo de una red neuronal es poder realizar predicciones sobre datos de un fenómeno
en el cual ha sido entrenada con un conjunto de datos que incluye las entradas y las salidas
correspondientes. Durante esta etapa la red neuronal construye un modelo en donde asigna
unos pesos a las diferentes variables de entrada que permiten obtener una salida lo más
cercana posible a la que se conoce para ese conjunto de entradas. Aquí se trata de minimizar
el error de la salida de la predicción con respecto a la que se conoce de los datos.
La unidad autónoma de la red neuronal es la neurona, figura 15 que es un procesador local
con conexiones que transportan la información a las otras neuronas.
Figura 15 Neurona artificial. Tomado de Velazco Avendaño Juana Yenny, 2017, redes
neuronales aplicadas al análisis de datos,
La arquitectura de una red neuronal posee una capa de entrada, una o más capas ocultas y
una capa de salida.
La red neuronal funciona en la modalidad feed forward procesando los flujos de las señales
desde la capa de entrada hacia adelante.

55
Capa de entrada.
Contiene las neuronas que se conectan con la información de entrada al algoritmo. En el caso
de la base de datos de accidentes de tránsito, aquí se colocan los atributos que pueden explicar
la causa del accidente. Cuando los datos salen de la capa de entrada son transformados en la
siguiente capa según se ve en la Figura 16.
Figura 16 Arquitectura de una red neuronal. Tomado de Velazco Avendaño Juana Yenny,
2017, redes neuronales aplicadas al análisis de datos,
Capas ocultas.
Contienen los pesos para transformar los datos de entrada y las neuronas ocultas que se
activan para permitir las conexiones entre los datos de entrada y la capa de salida.
Funcionamiento de la red neuronal.
Cuando un patrón de señales o datos ingresa a la capa de entrada, primero se transforma por
los pesos de la capa oculta y se utiliza para activar las neuronas ocultas. Las salidas de estas
sirven como entradas para la siguiente capa, y se repite el mismo proceso de transformación
y activación hasta la capa de salida.
Una neurona biológica puede estar activa (excitada estado 1) o inactiva (no excitada estado
0 o -1), Las neuronas artificiales también tienen un estado de activación como las biológicas.
La función de activación es una entrada global. La neurona recoge las señales por su sinapsis
sumando todas las influencias excitadoras e inhibidoras.
El entrenamiento del modelo de perceptrón se realiza presentando un conjunto de datos o
señales de entrada y salida a la red y ajustando los pesos en las capas de salida y oculta para
tratar de minimizar el error o diferencia entre las salidas producidas y las esperadas. La idea
es obtener una combinación adecuada de los pesos en las conexiones para disminuir el error
en la capa de salida, o sea ajustar los parámetros de la red en la dirección del gradiente

56
descendiente de la superficie de error de la salida . Para ajustar los pesos se calcula el error a
la salida y se propaga hacia atrás a las capas ocultas. La magnitud del ajuste del peso y la
rapidez de convergencia se ajustan mediante la tasa de aprendizaje y momento.
Cada neurona en una capa funciona a partir del conjunto de pesos asignados aleatoriamente
multiplicado por la entrada respectiva.
𝐼 = ∑𝑊𝑖Xi + ɵi (ec 1).
I: vector de entrada de la neurona
ɵ: peso adicional que influencia el resultado.
Wi: peso asignado a la conexión i.
Los datos de entrada se procesan mediante una función de activación. Hay varios tipos de
función de activación que producen estados de la neurona normalizados en valores entre 0 y
1, o entre -1 y 1. Algunas de las funciones de activación más utilizadas son la sigmoide,
logística, tangente hiperbólica. La mayoría de las funciones no son lineales.
Los valores de los pesos se ajustan iterativamente. El criterio de minimización de error que
puede ser el error cuadrático medio:
𝑆𝑆𝐸(𝑤) =1
2∑(𝑌𝑖 − 𝑌𝑖2) (ec 2)
Diseño de la red neuronal para Entrenamiento.
En el desarrollo de la red neuronal se sigue varios pasos secuenciales. En la figura 16 se
muestra un diagrama con el proceso de diseño de la red neuronal hasta su uso.
La magnitud del ajuste de los pesos y la velocidad de convergencia se obtienen mediante la
tasa de entrenamiento y el momentun.
La figura 17 muestra el proceso de desarrollo de la red neuronal.

57
RED NEURONAL ARTIFICIAL
(ANN)
TRATAMIENTO DE LOS DATOS
ELECCION DE LA ANN
ALGORITMO DE
ENTRENAMIENTO
TOPOLOGIA DE LA ANN
ENTRENAMIENTO DE LA
RED
PRUEBA DE LA RED
PREDICCION DE CAUSA DE
NUEVOS ACCIDENTES
.
Figura. 17. Proceso de desarrollo e implementación de una red neuronal. Elaboración
propia.
Prueba.
En la prueba del ajuste del modelo de red neuronal a los datos, se utilizan cuatro opciones:
Utilizar el conjunto de datos de entrenamiento para probar el modelo. Este método no se
sugiere ya que los resultados son muy próximos al óptimo porque el modelo ya conoce el
comportamiento de los datos con que se va a probar y por esta razón los resultados obtenidos
son muy altos en cuanto al desempeño de este. Cuando los datos de entrenamiento se utilizan
para la prueba, la precisión es cercana a 100%.
Utilizar un conjunto independiente para realizar la prueba.
Utilizar el método de validación cruzada, que divide el conjunto de datos. al azar en un
número de folds y toma un subconjunto para el entrenamiento y otro para la prueba. La

58
validación cruzada consiste en la construcción de un modelo de N + 1 veces, donde N es el
numero elegido de los folds. Los primeros N veces, una fracción (N + 1)=N (90% de diez
veces la validación cruzada) de los datos se utiliza para el entrenamiento y el tiempo _final
del conjunto de datos completo se utiliza.
Utilizar un porcentaje del conjunto de datos (entre 66-6% y 80%) y el restante subconjunto
para la prueba, implica la construcción del modelo en dos ocasiones, una vez en el conjunto
de datos reducidos y de nuevo en el conjunto de datos completo.
Los dos primeros métodos de prueba, la evaluación en el conjunto de entrenamiento y el uso
de una unidad de prueba suministrada, implican la construcción de un modelo de una sola
vez.
5.6.2. Análisis de la red neuronal. Métricas.
Para analizar el rendimiento del algoritmo de clasificación, se utilizan métricas que están
definidas previamente. Dependiendo del tipo de clasificador se utilizan las técnicas más
apropiadas. Algunas se adaptan mejor a variables numéricas, otros a categóricas o a ambas.
Criterios básicos para evaluar.
En problemas de clasificación, si tenemos una clase con muchos más datos que otra, el
porcentaje de aciertos a superar es el porcentaje de datos de la clase mayoritaria. En este caso
los porcentajes de la clase mayoritaria para los cinco atributos escogidos para clasificación
son los siguientes;
— Ej.: Sean dos clases (+ y -). Hay 90 datos + y 10 -. Un clasificador que prediga siempre +
(independientemente de los atributos), ya acertara en un 90%. Hay que hacerlo mejor que
eso.
La correlación dice que tan relacionados están los valores verdadero y estimado.
Los estadísticos que se describen a continuación comparan los valores estimados con los
verdaderos. Dan una idea de cuan alejados están los valores estimados de los verdaderos. A
veces se usan las raíces cuadradas y otras los errores absolutos porque cuando hay valores
extremos tienen mayor incidencia en el resultado. El error medio absoluto y la raíz del error
cuadrático medio simplemente miran la diferencia promedio entre dos valores, y se pueden
interpretar comparando con la escala de la variable,
En RAE y RRSE se dividen las diferencias por la variación de la variable de manera que
tienen una escala entre 0 y 1 y si se multiplica por 100 se cambia la escala de 1 a 100. Los
valores ∑(𝜃 − 𝜃𝑖)2 y ∑(𝜃 − 𝜃𝑖) muestran como varia ϴ de su valor medio o sea cuanto varia
respecto de si misma comparar con la varianza, como se denominan relativas, se compararán
respecto de la escala de ϴ.

59
Para interpretar correctamente los resultados de la clasificación, las clases deben de estar
balanceadas.
De acuerdo con [12] la bondad de los modelos de predicción, contrario a lo que se esperaría,
no depende del número de instancias o registros de la base de datos utilizada para construir
el modelo cuando este se basa en reglas.
• Estadístico Kappa.
Mide la concordancia entre las categorías clasificadas por el modelo y las observadas. Se
tienen en cuenta los aciertos que pueden verse a causas aleatorias. La interpretación de este
indicador se puede apreciar en la tabla 8.
kappa grado de acuerdo
< 0,00 sin acuerdo
>0,00 - 0,20 insignificante
0,21 - 0,40 discreto
>0,41 - 0,60 moderado
0,61 - 0,80 sustancial
0,81 - 1,00 casi perfecto
Tabla 8. Interpretación de los valores del índice Kappa.
Si el valor es 1 concuerda perfectamente. Si es 0 la concordancia se debe al azar y si es
negativo se tiene una concordancia menor de la que podría obtenerse por azar.
A continuación, se muestran las medidas que se relacionan con el error de clasificación.
• Error absoluto medio.
Es una medida de la diferencia entre dos variables continuas. En este caso se trata de la
diferencia entre los valores obtenidos mediante la predicción y los observados. Se determina
mediante la expresión;
𝑀𝐴𝐸 =1
𝑁∑𝑑𝑖
𝑁
𝑖=1

60
di: son valores correspondientes a un vector que se calcula en la siguiente forma:
• Se construye un vector binario que tiene un uno en la posición de la clase a
• la que pertenece la instancia y ceros en las demás.
• Se determina el vector de probabilidades de asignación a las distintas clases
• que proporciona el clasificador.
• Se realiza la diferencia entre el par de vectores asociados.
• Las componentes de los vectores diferencia proporcionan los valores di.
• Raíz del error cuadrático medio.
Es la raíz cuadrada del promedio de los cuadrados de las diferencias entre los valores de la
predicción y los observados
𝑅𝑀𝑆𝐸 = √1
𝑁∑𝑑𝑖
2
𝑁
𝑖=1
• Error absoluto relativo.
Es la relación entre el error absoluto medio y la media del error medio absoluto para el
algoritmo utilizado.
𝑅𝐴𝐸 =Error absoluto medio
Promedio de las diferencias de la media𝑥100
• Raíz del error cuadrático relativo.
Es la relación entre la raíz del error cuadrático medio y la raíz del error medio del algoritmo
utilizado.
RRSE =Raiz cuadrada del error cuadratico medio
Raíz cuadrada del promedio de las diferencias de la media𝑥100
• Número total de instancias.
Es el número de registros en la base de datos.
Indicadores relativos a la precisión de la predicción.

61
• Matriz de confusión.
Una forma de hacer la validación es la matriz de confusión, que permite visualizar en una
tabla los errores cometidos por el clasificador. Los valores ubicados sobre la diagonal de la
matriz son los correctamente clasificados para cada valor de la clase o etiqueta, asumiendo
que los valores en la matriz pueden ser verdaderos positivos, falsos negativos, verdaderos
negativos o falsos positivos.
Con base en los valores anteriores, se pueden definir las tasas de error y acierto.
• Exactitud por clase.
A continuación, se presenta el análisis de los resultados obtenidos para cada uno de los cinco
modelos construidos para las respectivas causas probables de accidente
• Análisis de costo beneficio.
Otra forma de determinar la bondad del modelo es a través de la relación costo beneficio.
Cuando el valor asignado a los errores, en este caso a un falso negativo no es igual al de un
falso positivo, se utiliza para determinar la bondad del modelo el concepto de costo beneficio,
que se puede representar mediante una matriz o una gráfica. Se incluyen en la matriz o gráfica
los costos por cada tipo de error. Se establecen las siguientes relaciones:
Beneficio= VPxBVP+VNxBVN ( ec -3)
Costo= FNxCFN+ FPxCFP (ec-4)
• Curva de margen de predicción (Margin curve).
Genera puntos que ilustran el margen de predicción. El margen se define como la diferencia
entre la probabilidad predicha para la clase verdadera y la probabilidad de la más alta
predicha para las otras clases. Para un buen desempeño del modelo es que incrementan el
margen en los datos de entrenamiento lo cual produce un mejor desempeño en los datos de
prueba.
• Curva ROC.
La curva ROC es una curva paramétrica del límite de manera que un punto (pareja de
verdadero positivo-falso positivo) pertenece a la curva si existe un valor límite para el cual
el experimento resulta en tasa de verdadero positivo igual a tpr y tasa de falso positivo igual
a fpr.

62
En un buen modelo la curva esta hacia la parte superior derecha del plano. Se trata de
optimizar el área bajo la curva. Cuando las clases están separadas, la curva se dibuja hacia la
parte superior izquierda. El área bajo la curva para un buen modelo debe estar entre 0.75 y 1.
Esto quiere decir que puede clasificar correctamente los verdaderos positivos y los
verdaderos negativos como tales.
El valor de treshold (limite) se define para separar la probabilidad de verdadero positivo y
falso positivo. Cuando se tiene dos clases, la probabilidad es 0,5 es decir que para calificar
como verdadero positivo, la probabilidad debe ser mayor de 0.5. cuando hay más de dos
clases, este valor limite puede cambiar. Sin embargo, existe una condición en la cual no se
pude distinguir el valor limite, para identificarlo se colorea la curva.
En la figura 18 se observan diferentes formas de curvas ROC, indicando la aplicabilidad de
estas.
Figura 18. Formas de curvas ROC. Tomado de Beltrán Pascual tesis.
• Verdaderos positivos. (TP)
Instancias correctamente reconocidas por el sistema. Corresponden a los valores de la
diagonal;
• Verdaderos negativos. (TN)
Instancias que son negativas y correctamente reconocidas como tales. Si consideramos
únicamente el estudio para una clase, por ejemplo, para la clase I, entonces los verdaderos
negativos serían
• Falsos positivos (FP)
Instancias que son negativas pero el sistema dice que no lo son.

63
• Falsos negativos (FN)
Instancias que son positivas y que el sistema dice que no lo son.
El cálculo de los indicadores de precisión se realiza en la siguiente forma;
𝑇𝑃𝑅𝑎𝑡𝑒 =𝑇𝑃
𝑇𝑃+𝐹𝑁 (ec-5)
• Tasa de falsos positivos.
𝐹 𝑃𝑟 𝑎 𝑡𝑒 =𝐹𝑃
𝐹𝑃+𝑇𝑁 (ec-6)
∑(𝜃 − 𝜃𝑖)2
• Medida de precisión.
Pr𝑒𝑠𝑖𝑐𝑖𝑜𝑛 =𝑇𝑃
𝑇𝑃+𝐹𝑃 (ec-7)
• Valor límite (treshold)
Es el valor que separa los verdaderos positivos de los falsos positivos. Solamente se utiliza
para variables continuas.
• Recall. (sensitividad)
Mide la proporción de términos correctamente reconocidos respecto del total de términos
reales. En qué grado están todos los términos que son. Cómo puede clasificar los casos
positivos dentro de todos los casos positivos presentes en la prueba.
Re𝑐𝑎𝑙𝑙(𝑥) =Numero de instancias de la clase X clasificadas correctamente
número total de instancias de la clase X (ec-8)
Recall = TP rate.
Las curvas precisión recall son más útiles para estimar la precisión del modelo que las ROC,
ya que estas solamente dan una idea aproximada de cómo está desempeñándose en general
el clasificador. Sin importar como son las probabilidades de las diferentes clases, dan valores
parecidos. Por ejemplo, consideran iguales las clases positiva y negativa. Por el contrario,
los valores PRC son más útiles si el interés es cómo se comporta el clasificador en cada clase.
Un valor ROC AUC d e0.5 indica que el clasificador es aleatorio

64
• Precisión.
Mide la proporción de términos correctamente reconocidos respecto de los términos
predichos.
Una medida de desempeño muy utilizada consiste en representar la gráfica Recall-vs
precisión.
En el eje horizontal se representa el recall y en el vertical la precisión. Entre más hacia la
parte superior derecha se encuentre la curva, el modelo es más adecuado, o sea los valores
de mayor recall y mayor precisión. La precisión no es sensible a la distribución de clases
• Medida F.
Combina la precisión con el recall.
𝐹 −𝑚𝑒𝑎𝑠𝑢𝑟𝑒 =2𝑇𝑃
2𝑇𝑃+𝐹𝑃+𝐹𝑁=
2𝑥𝑃𝑟𝑒𝑠𝑖𝑐𝑖𝑜𝑛𝑥𝐶𝑜𝑏𝑒𝑟𝑡𝑢𝑟𝑎
𝑃𝑟𝑒𝑠𝑖𝑐𝑖𝑜𝑛+𝑐𝑜𝑏𝑒𝑟𝑡𝑢𝑟𝑎 (ec-9)
• Curva ROC (Receiver operating characteristics) Roc area
El threshold o límite separa los verdaderos positivos de los verdaderos negativos y se puede
desplazar. Los ejes están numerados en una escala de 0 a 1.
El área bajo la curva AUC mide la probabilidad de que el clasificador puntuara una instancia
positiva elegida aleatoriamente más alta que una negativa.
Prc area
Es el área debajo de la curva Presicion-Recall. Esta se determina para cada clase por la
prevalencia de la clase en los datos de prueba. Si una clase ocurre 30% de las instancias de
prueba, su peso es 0.3.
5.6.3. Algoritmos bayesianos.
De acuerdo con García González, presenta una medida probabilística cuantitativa acerca de
que tan importantes son los valores de la variable clase dentro del problema. Entre los
atributos del conjunto de entrenamiento no pueden existir correlaciones. Este algoritmo se
basa en el teorema de Bayes y supone funciona bien con datos reales y con mecanismos de
selección de atributos para eliminar la redundancia.
Entre los algoritmos bayesianos se distinguen dos: Naive Bayes y Bayes Net.

65
En el primero se supone que al conocer el valor de la variable clase, todos los atributos son
independientes entre sí. Esta hipó tesis de independencia da lugar a un modelo de un único
nodo raíz, correspondiente a la clase, y en el que todos los atributos son nodos hoja que tienen
como único origen a la variable clase.
5.6.4. SOFTWARE PARA MINERIA DE DATOS.
Entre los programas disponibles para las tareas de minería de datos algunos son libres y otros
no. Entre los programas más utilizados se tienen;
• XLMiner.
• Matlab.
• IBM SPSS
• SAS
• Salford System Data Mining.
• Oracle Data Mining.
• Rapid Miner
• Knime
• R
• Orange
• Weka.

66
6. METODOLOGIA Y DESARROLLO DEL PROYECTO.
La metodología utilizada se presenta a continuación, teniendo en cuenta que se han usado
dos bases de datos diferentes para la construcción del modelo. Estas son:
• Base de datos 1: Base de datos accidentes de tránsito Bogotá 2016.
• Base de datos 2: Base de datos de accidentes de tránsito en empresas de transporte
suministrada por la compañía aseguradora Allianz.
En consecuencia con lo anterior, se han desarrollado dos modelos diferentes. Cuando se
utiliza la base de datos 1 se incluyen 34931 registros de accidentes de tránsito sin discriminar
el uso de los vehículos, es decir figuran accidentes de vehículos particulares y de empresas
de transporte. De otro lado, al utilizar la base de datos 2 se han considerado únicamente
accidentes de tránsito de empresas de transporte con un total de 894 registros como se
describirà màs adelante.
Siguiendo la metodología propuesta en S.L González Ruiz se presenta el desarrollo del
trabajo. En este paso se asume que se ha elaborado el modelo de accidente, lo cual se ha
presentado en el apartado
En general, se puede resumir el proceso de adquisición de conocimiento a partir de los datos,
en las siguientes etapas:
6.1. CASO BASE DE DATOS 1.
A continuación se presenta la metodología aplicada utilizando la base de datos 1.
6.1.1. ANALISIS DEL DOMINIO.
En el análisis del dominio se hace una selección inicial de los datos y la forma en que se
desean organizar, con base en las características de estos y del sistema o fenómeno que se
va a estudiar.
Como resultado del análisis del dominio, se miden y almacenan las variables de interés en
las bases de datos para el análisis posterior.
En este caso, no se realizaron mediciones, sino que se buscaron bases de datos de
accidentalidad en tránsito en las diferentes entidades que se relacionan con este tema. En
Colombia, las principales instituciones que manejan la información de accidentalidad son:
• Ministerio de transporte base de datos rnat.
• Fasecolda.

67
• Policía nacional (informes de accidentes de tránsito).
• Instituto de medicina legal.
• Agencia de seguridad vial (antes fondo de seguridad vial).
La principal fuente de datos del estado corresponde al RNAT, Registro Nacional de
accidentes de tránsito, el cual fue establecido en el año 2014 mediante resolución número y
que fue administrado inicialmente por el Ministerio de transporte, y en el año 2015 trasladado
al RUNT (Registro único nacional de transporte).
Debido al carácter de la información contenida en estas bases de datos, no ha sido posible
hasta el momento, tener acceso a la misma.
En el portal Datos Abiertos, administrado por el Ministerio de Comunicaciones e
información, se han encontrado varias bases de datos, entre las cuales son de interés las
siguientes;
• Base de datos de accidentes de tránsito a nivel nacional año 2010.
• Base de datos de accidentes de tránsito Cali año.
• Base de datos accidentes de tránsito Bogotá 2016.
Se ha seleccionado la base de datos de accidentes de la ciudad de Bogotá durante el año 2016,
debido a que es la que más información relevante tiene para el desarrollo del proyecto.
• Base de datos de accidentalidad vial en empresas aseguradas con Allianz.
De acuerdo con la experiencia del autor en el tema de accidentalidad vial, se recurre a bases
de datos suministradas por la aseguradora Allianz dentro de su programa de disminución del
riesgo en los asegurados con pólizas de accidentalidad vehicular.
Esta base de datos consta de 894 registros de accidentes en diferentes empresas de transporte
y ciudades y vías del territorio nacional. Sin embargo, al realizar el preprocesamiento de ,los
datos la base se ha reducido a 325 registros, que contienen información detallada de los
accidentes y siniestros ocurridos entre los años 2009 y 2011.
Aunque todas las empresas realizan actividades de transporte, en algunos casos se tiene el
transporte de pasajeros como en Transportes La Carolina, ubicada en Soledad Atlántico y
EM (empresa de transporte metropolitano de Cali) que equivale al sistema Transmilenio de
Bogotá, mientras que en otras se realiza un servicio de transporte a terceros como
Servientrega y en las demás El transporte es de materia prima o producto terminado hacia
sus diferentes plantas o bodegas de distribución como Femsa Logística transportadora de

68
Coca Cola entre ciudades, o la división de transporte de Coca Cola en los centros urbanos,
Harinera del Valle, Transportes Iceberg, Pronavicola, que operan a nivel del país y en algunos
casos del exterior.
Selección y exploración de la base de datos.
En la selección de la base de datos a utilizar se tuvieron en cuenta los datos de accidentalidad
de tránsito disponibles en el país. Para ello se recurrió a las entidades relacionadas con el
transporte y la accidentalidad de tránsito.
Se visitaron entidades como Fasecolda, la Agencia Nacional de Seguridad vial, El ministerio
de Transporte, la Secretaría Distrital de Tránsito, la policía Nacional, El Instituto de Medicina
Legal, así como los portales del estado que manejan la información de diferente índole,
conocida como datos abiertos.
De todas las anteriores solamente fue posible conseguir información útil en el portal de datos
abiertos. Allí se encontró información de accidentalidad de tránsito en el país y en diferentes
municipios. Al analizar la información encontrada, se desechó en algunos casos debido a que
la información era insuficiente respecto de los datos del accidente en particular, y no
consideraba algunos factores o atributos que son valiosos para el análisis del accidente como
por ejemplo estado de la vía, clima, señalización, conductores, peatones, pasajeros, probables
causas determinadas en el momento del accidente por las autoridades competentes. En otros
casos los registros o instancias no tenían el volumen suficiente para construir modelos
descriptivos y de predicción robustos.
Sin embargo, en la Agencia Nacional de seguridad Vial, entidad que tiene acceso a esta
información, solamente se suministra información sobre estadística de los datos y no de los
datos brutos. Por esta razón no fue posible acceder a la base de datos como tal.
Arquitectura Nacional ITS de Colombia
Este subsistema recoge, archiva, maneja, y distribuye los datos generados por los ITS para el
uso en la administración del transporte, la evaluación de la política, la seguridad, la
planeación, la supervisión de funcionamiento, el gravamen de programa, operaciones, y usos
para la investigación. Los datos recibidos se dan formato, marcado con etiqueta con las
cualidades que definen la fuente de datos, las condiciones bajo las cuales fueron recogidos,
las transformaciones de los datos, y la otra información (es decir metadatos) necesaria
interpretar los datos. El subsistema puede fundir datos generados por los ITS con datos de
fuentes no-ITS y de otros archivos para generar los productos de la información que utilizan
datos de áreas funcionales, de modos, y de jurisdicciones múltiples. Este subsistema se puede
ejecutar en muchas maneras diferentes. Puede residir dentro de un centro operacional y
proporcionar el acceso enfocado a un agencia particular o archivos de los datos ITS

69
operacionales. Alternativamente, puede funcionar como centro distinto que recoja datos de
las agencias y de las fuentes múltiples y proporcione un servicio del almacén de datos
generales para una región.
El RNAT es la sigla del Registro Nacional de Accidentes de Tránsito.
Es el sistema que centraliza la información de todos los informes policiales de accidentes de
tránsito (IPAT), realizados en todo el país, con el fin de contar con un sistema que cuente con
la actualización de los registros de información inherente a heridos, fallecidos y prueba de
alcoholemia.
Los actores que deben inscribirse y proveen información al Registro Nacional de accidentes
de Tránsito son:
• Autoridad de control (Dirección de Tránsito y Transporte de la Policía Nacional o
Agente de Tránsito)
• Autoridad Administrativa (Organismos de Tránsito, Alcaldías, Seccional de la
Policía de Carreteras, DITTRA)
• Ministerio de Protección Social
• Ministerio de Transporte
La información registrada en el Rnat es la siguiente;
• Autoridad de tránsito
• Número IPAT
• Organismo de tránsito radicación
• Gravedad
• Clase de accidente
• Objeto fijo
• Otro (Objeto fijo)
• Otro (Clase de accidente)
• Fecha de accidente
• Hora de accidente
• Fecha levantamiento

70
• Hora levantamiento
• Información del lugar del accidente
• Señales de las vías que intervinieron en el accidente
• Vías que intervinieron en el accidente
• Testigos involucrados con el accidente
• Vehículos que intervinieron en el accidente
• Víctimas que intervinieron en el accidente
• Información de quien conoce el accidente
En el caso de la base de datos suministrada por Allianz, se tienen los siguientes datos
suministrados en la misma.
• Autoridad de tránsito
• Organismo de tránsito radicación
• Gravedad
• Clase de accidente
• Objeto fijo
• Otro (Objeto fijo)
• Otro (Clase de accidente)
• Fecha de accidente
• Hora de accidente
• Estado del Tiempo
• Condiciones de la vía.
• Tipo de tránsito.
• Genero de los conductores.
• Tipo de vía.

71
• Información del lugar del accidente
• Vías que intervinieron en el accidente
• Vehículos que intervinieron en el accidente
• Tipo de vehículo.
• Víctimas que intervinieron en el accidente
• Información de quien conoce el accidente.
De acuerdo con las características del estudio a realizar, la metodología de minería de datos
y los datos en particular, se sugiere utilizar una estructura de datos en donde estos se
organizan en tres niveles, que son; factores, atributos o variables y valores de estos. Además,
cada atributo o variable tiene su correspondiente categoría nominal o numérica. Esta
organización de los datos representa el modelo de datos correspondiente al modelo de
accidente definido anteriormente en la sección .
En la figura19 se presenta el modelo utilizado para la estructura de los datos a manejar.
BASE DE DATOS DE ACCIDENTES DE
TRANSITO
FACTORES DE RIESGO
NIVEL DE ATRIBUTOS/VARIABLES
NIVEL DE VALOR DE ATRIBUTO/VARIABLE
CLASE DE ATRIBUTO
HUMANOS VIACLIMA/TIEMPO
VEHICULO PEATONES PASAJERO
GENERO/EDAD/
ANTIGÜEDAD LICENCIA
CONDUCTOR
PAVIMENTADA/SEÑALES/GEOMETRIA
NUBLADO/LLUVIOSO/
VIENTO
ESTADO INTEGRIDAD MECANICO/ELECTRICO/SEGURIDAD
RESPETAR SEÑALES
SEGURIDAD
NOMINAL/NUMERICO/
STRING
NOMINAL/NUMERICO/
STRING
NOMINAL/NUMERICO/
STRING
NOMINAL/NUMERICO/
STRING
NOMINAL/NUMERICO/
STRING
NOMINAL/NUMERICO/
STRING
M-F/20-30,30-40,40-50
SI-NO/CURVA-GLORIETA-
TUNEL-PUENTE
SI-NO
ESTADOFRENOS-DIRECCION-
LUCES-LLANTAS
PASAR EN ROJO/
CAMINAR POR LA CALZADA
DESCENDER VEHICULO EN MOVIMIENTO
Figura 19. Modelo de Estructura de datos con los diferentes niveles. Fuente: elaboración
propia.
6.1.2. FIJAR NETAS.
La meta del proceso de minería de datos está relacionada con la disponibilidad de datos. En
este caso, no se ha encontrado una base de datos con la información suficientemente completa

72
que contenga todos los datos deseados. Sin embargo, la meta de la investigación se adapta a
la misma, y es el descubrimiento de patrones de accidentalidad que contienen las variables
que pueden asociarse a las causas de los accidentes.
6.1.3. SELECCIÓN, EXPLORACION, LIMPIEZA Y TRANSFORMACION DE
DATOS
Como se mencionó anteriormente, en los datos abiertos suministrados por las agencias del
estado, se ha seleccionado la base de datos accidentes de tránsito en la ciudad de Bogotá,
correspondientes al año 2016.
La base de datos en mención contiene 34931 registros de accidentes ocurridos en el perímetro
urbano de la ciudad de Bogotá durante el año 2016, con diferentes clases de consecuencias.
Los datos seleccionados se encuentran en una tabla de Excel, por lo cual no requieren
integración, ya que estos datos fueron ingresados al sistema bajo un mismo formato, por las
autoridades que participaron en el conocimiento inicial del accidente.
El documento base para capturar la información es el formato de reporte policial de
accidentes de tránsito de acuerdo con la resolución 004040 de 2004 modificado por
resolución 1814 de 2005. (anexo 1).
La técnica utilizada depende del objetivo o meta planteado y de la base de datos seleccionada,
además de la relación entre los atributos y el atributo clase seleccionado para la clasificación.
Métodos de selección de atributos.
El conjunto de datos del accidente contiene información relacionada con:
Las variables de interés que sería adecuado estuvieran incluidas en la base de datos son, por
ejemplo:
• Atributos relacionados con el accidente
Severidad (fatal o no fatal).
Sitio del accidente (región, distrito, carretera o vía, tramo de la vía, distancia desde el
comienzo de la vía, dirección).
Tiempo (año. Mes, día, hora, fecha)
Ambiente: clima, temperatura, iluminación.
Condiciones de la vía (superficie, ancho de la vía, aceras, cruces, iluminación de tráfico,
semáforos, límites de velocidad, trabajos en la vía, volumen máximo y mínimo de tráfico)

73
Tipo de accidente (giro y golpe, golpe a animal, número de heridos, causas)
Una vez ingresada la base de datos al programa Weka, se realiza una primera fase que es la
de preproceso, la cual consiste en realizar la estadística descriptica de los datos. Aquí se
pueden observar los atributos y sus medidas de tendencia central y dispersión. El programa
permite identificar los atributos que tienen poca relación con el atributo escogido como clase
y no son los más adecuados para describir el comportamiento de la accidentalidad, ni aportan
información relevante acerca de la causa probable de los accidentes. Desde este punto de
vista pueden ser eliminados de la base de datos, o filtrados para que no aparezcan en los
cálculos posteriores en las etapas de agrupamiento y predicción.
Inicialmente, y con el objetivo de encontrar particularidades en el comportamiento de los
datos, se realiza un análisis estadístico con el módulo de preprocesamiento del programa
Weka. Aquí se realiza una primera limpieza de los datos, que busca eliminar valores atípicos,
repetidos, con datos nulos, etc.
Como resultado de esta primera exploración y limpieza de los datos, se han identificado los
valores de las variables que presentan un menor número de conteos o frecuencia. Inicialmente
se podría esperar que estos valores debido a su poca aparición podrían eliminarse en la base
de datos minable.
Se realizó un análisis estadístico descriptivo, utilizando el programa WEKA. Este permite
encontrar medidas estadísticas de las variables o atributos que figuran en la base de datos
seleccionada, así como eliminar los atributos que muestran poca importancia desde el punto
de vista de la influencia en los objetivos del estudio, en este caso, en la causa de los
accidentes.
A continuación, se presenta algunos de los resultados obtenidos en este análisis.
El valor solo daños tiene unas frecuencias de 23818 conteos, que corresponde al 68.19%,
heridos 10555 con 30.21% y muertos 555 con 1.5%.
Para el atributo clase nombre, las frecuencias son choque 29947, atropello 3668, otro 92,
caída acompañante 869 , volcamiento 347.
El atributo choque nombre, las frecuencias son vehículo 28857, objeto fijo 1043, otro 41,
semoviente 6.
Para el atributo objeto fijo nombre, las frecuencias son inmueble 123, vehículo estacionado
266, muro 229, árbol 40, poste 261, semáforo 31, barandas 37, tarima caseta 8, valla señal
19, defensa metálica 1, hidrante 3, separador de calzada 18, roca 5, panel luminoso 2.

74
El atributo nombre otra clase, las frecuencias son aprisionamiento 78, caída dentro del
vehículo 8.
El atributo tipo vía, las frecuencias son KR 11596, CL 11610, AV 6300, AK 2546, DG 623,
TR 745,
El atributo localidad, las frecuencias son Kennedy 4009, Engativa 3487, Usaquén 3538,
Barrios Unidos 1884, Fontibón 2793, Suba 3334, Chapinero 2418, Puente Aranda 2409, Bosa
1524, Santafé 967, Usme 654, Teusaquillo 1778,Los Mártires 1389.
El atributo tipo diseño, figura, las frecuencias son vehículo 28857, objeto fijo 1043, otro 41,
semoviente 6.
El atributo tipo tiempo, figura, las frecuencias son normal 33604, lluvia 1214, viento 43,
niebla 35.
El atributo causa peatón, las frecuencias son otras1087, cruzar sin observar 948, pararse sobre
la calzada 92, salir por delante de vehículo 92, cruzar en estado de ebriedad 257, pasar
semáforo en rojo 87, cruzar en diagonal 30, transitar POR la calzada 162,
El atributo causa vehículo, las frecuencias son fallas en los frenos 108, fallas en las llantas
25, otro 24, fallas en la dirección 17,fallas en las puertas 10.
Después de analizar la estadística descriptiva, se abordan las siguientes tareas:
• Eliminación de valores atípicos (outlets)
• Llenado de valores perdidos, que corresponden a las casillas vacías de la tabla. Aquí
se debe observar que como las causas figuran en diez columnas, solamente se
coloca una causa o máximo dos por cada registro o instancia, haciendo que las
casillas correspondientes a las demás causas queden vacías.
• Definición del atributo clase, que va a servir como índice en la fase de clasificación,
o sea la salida del clasificador. En este caso el atributo clase es el que corresponde
con la causa del accidente. Se fusionan en la base de datos original los diez atributos
correspondientes a las causas de accidentes, en uno solo denominado causa.
• Selección de atributos más relacionados con el atributo clase. Existen atributos que
a primera vista no deben tener relación con la causa del accidente. Estos se pueden
eliminar de la base de datos minable.
• Para poder realizar las fases de selección de atributos de acuerdo con su importancia
respecto del atributo clase, se debe tener atributos de tipo nominal únicamente. Por
esta razón se eliminan los atributos de tipo numérico y Sting.

75
• Debido a la importancia del atributo clase en este caso causa, se debe depurar en la
base de datos de Excel los valores de la variable causa. Inicialmente en la base de
datos convertida a formato csv, se obtienen 1082 valores distintos. Esto a pesar de
que los valores relevantes son 72. Esto ocurre debido a que La sintaxis del registro
se ha escrito de manera diferente. Una depuración lleva a obtener 72 valores del
atributo causa. Posteriormente se identifican los valores que presentan una menor
frecuencia, y se eliminan de la base de datos en Excel.
• Como resultado de los anteriores procesos se obtiene una base de datos con 22
atributos y 30465 registros que son la base para el dataset minable.
El programa contiene varias funciones que permiten realizar las anteriores tareas.
Para adecuar el diseño de la red neuronal a la arquitectura de los datos y a la salida deseada,
se tienen en cuenta varios factores de estos.
Otra situación importante de análisis consiste en el hecho de que la base de datos disponible
contiene la información sobre las causas de los accidentes distribuida en 10 columnas, que
corresponden a los atributos; causa vía 1 descripción, causa vía 2 descripción, causa vehículo
1 descripción, causa vehículo 2 descripción, causa conductor 1 descripción, causa conductor
2 descripción, causa peatónldescripciòn, causa peatón2descripciòn, causa conductor1
descripción, causa conductor2descripciòn.
Como el objetivo principal de la salida es obtener una aproximación a las posibles causas que
produjeron el accidente, se pueden tener dos opciones desde el punto de vista de la
organización de los datos.
La primera consiste en tener un solo atributo que se denomine causa, y en el cual figuren
todos los posibles valores de este atributo. Por ejemplo, en esta columna estarían las causas
atribuibles al vehículo, conductor, vía, peatones, pasajeros. Esta organización presenta la
ventaja de que se tendría un solo modelo de red neuronal para realizar la predicción sobre
una sola clase que correspondería al valor del atributo o variable dependiente causa. Para la
elaboración de la vista minable, estas columnas se reducen a una sola bajo el nombre causa.
En segundo lugar, se pueden tener diferentes atributos para las causas relacionadas con los
diferentes factores de riesgo. Por ejemplo, para las causas relacionadas con los factores
asociados al conductor se define un atributo, para las causas relacionadas con los factores
asociados a la vía, otro atributo y así sucesivamente. En este caso se tendrían cinco atributos
para agrupar las diferentes causas, eliminando los atributos que se repiten, como
causavialdecripciòn y causavialldescripciòn, solamente se deja uno. Es en esta forma como
está organizada la base de datos. Este modelo presenta la dificultad de que se deben construir
cinco modelos de red neuronal, cada uno teniendo como clase de salida uno de los atributos

76
mencionados. Por ejemplo, un modelo de red neuronal para predecir la causa asociada a los
factores de riesgo relacionados con el conductor, otro para la vía, otro para el vehículo, para
el peatón y finalmente para el pasajero. Presenta la ventaja de que se puede tener por aparte
las causas relacionadas a cada posible actor del accidente. Además, desde el punto de vista
computacional, la causa que más valores posibles tiene es conductor, con valores, lo cual
disminuye la capacidad de procesamiento requerida porque en la fase de clasificación, se
procesa un atributo causa a la vez, y el algoritmo de clasificación trabaja solamente con los
valores correspondientes a ese atributo, mientras que en la opción de unir todos los atributos
causa en uno solo que se denomine causa, resultan cerca de 72 valores diferentes que puede
tomar el atributo clase, lo cual hace mucho más exigente el requerimiento de memoria y
procesamiento en el computador, haciendo que el proceso sea más lento, y en algunos casos
no se pueda realizar.
6.1.4. PREPARACION DEL DATASET O VISTA MINABLE.
El data set minable se obtiene después de realizar la limpieza y transformación de los datos,
como eliminación de atributos que no son relevantes para las tareas de agrupamiento y
clasificación.
Para definir el data set minable se tienen en cuenta entre varios factores los siguientes;
Importancia del atributo en la explicación del fenómeno que se quiere describir o predecir.
Independencia de otros atributos similares. Algunos atributos pueden ser incluidos dentro de
otros o fusionados para formar un solo atributo.
Como resultado de la fase de exploración y limpieza de la base de datos se obtuvo una base
de datos modificada con 11 atributos y 24285 instancias.
Sobre esta nueva base de datos modificada se realiza nuevamente la etapa de
preprocesamiento con el programa Weka y las etapas de agrupamiento y clasificación.
En la figura 20 se muestra la estadística descriptiva resultante de este preprocesamiento.
Se puede observar en el histograma del atributo causa, que existen cuatro valores de esta
variable que contienen el mayor número de conteos. Son los que están en colores azul, rojo,
verde y lavanda que corresponden a los valores: no mantener la distancia de seguridad (8474
observaciones), adelantar cerrando (5019 observaciones), otras (4509 observaciones) y
desobedecer señales (4187 observaciones), siguen después no respetar prelación con 1056 y
reverso imprudente con 1040 observaciones, sobre 24285.
De lo anterior se puede hacer una aproximación en el momento de realizar la fase de
clasificación, que consiste en seleccionar con el programa los valores que presenten las

77
mayores frecuencias, y asignando cero observaciones a los demás valores de la variable
causa. Esto es conveniente para que el procesamiento computacional sea más rápido y aunque
se incurre en un error, dado que las frecuencias de los valores de la variable causan que no
se tienen en cuenta son bajos, el error también lo será.
Una vez realizado el análisis estadístico de los datos, se procede a transformarlos para obtener
el data set minable. Esta tarea se realiza principalmente mediante las opciones de filtros
disponibles en el programa. Las tareas están orientadas a identificar cuáles son los atributos
que tienen mayor relación con los atributos de clasificación tomar una decisión sobre los
registros nulos o datos perdidos, los valores extremos o outliers, los registros o instancias
repetidas. Después de realizadas estas tareas, se debe tener la base de datos con los atributos
más pertinentes para el objetivo de clasificación, así como el número de registros más
adecuado para fines computacionales.
El número de registros considerados es ahora de 30637 y se aprecian cambias en los conteos
para los atributos seleccionados. En la figura 19 se presentan las gráficas con los histogramas
para los diferentes atributos.
Cada diagrama presenta información gráfica sobre los atributos, en forma de histogramas; en
el eje horizontal se representan los valores de los atributos y en el vertical las frecuencias o
conteos de cada valor que puede tomar el atributo,
En la figura 20 a, se observa que el valor solo daños en color rojo tiene unas frecuencias de
31474 conteos, heridos 8738 y muertos 474.
Para el atributo clase nombre, figura 20 b, las frecuencias y porcentajes son choque 26438,
atropello 3190, otro 92, caída acompañante 706 , volcamiento 210.
El atributo choque nombre, figura 20 c, las frecuencias y porcentajes son vehículo 25782,
objeto fijo 625, otro 28, semoviente 3.
Para el atributo objeto fijo nombre, figura 20 d, las frecuencias y porcentajes son inmueble
123, vehículo estacionado 186, muro 138, árbol 29, poste 158, semáforo 18, barandas 15,
tarima caseta 8, valla señal 19, defensa metálica 1, hidrante 3, separador de calzada 12, roca
3, panel luminoso 2, inmueble 62.
78
Figura 20 a Gravedad accidente
Figura 20 b clase nombre.
Figura 20 c choque nombre.
79
Figura 20 d Objeto fijo nombre.
Figura 20 e Nombre otra clase

80
Figura 20 f Tipo vía.
Figura 20 g localidad
Figura Diagramas de barras obtenidos del preprocesamiento del data set minable. En el
eje horizontal están los valores de las variables o atributos y en el vertical el número de
conteos o frecuencia para cada una.
Fuente: elaboración propia programa Weka 3.8.
El atributo nombre otra clase, figura 20 e, las frecuencias y porcentajes son aprisionamiento
75, caída dentro del vehículo 8.
El atributo tipo vía, figura 20 f, las frecuencias y porcentajes son KR 10123, CL 10143, AV
5589, AK 2277, DG 527, TR 636,
El atributo localidad, figura 20 g, las frecuencias y porcentajes son Kennedy 4009, Engativa
3042, Usaquén 3538, Barrios Unidos 1884, Fontibón 2449, Suba 2887, Chapinero 2418,
Puente Aranda 2132, Bosa 1524, Santafé 967, Usme 556, Teusaquillo 1601, Los Mártires
1044, Rafael Uribe Uribe 809.

81
El software especializado posee ayudas y técnicas para la selección de atributos.
• Atributos relacionados con las personas.
El conjunto de datos de personas contiene atributos como:
Información de las personas involucradas.
Conductor culpable, conductor no acusado, prueba de alcohol.
• Atributos de los participantes.
Otros participantes como vehículos, animales, etc.
• Atributos de Densidad de población.
La densidad de población es un riesgo potencial para el accidente de tránsito. La densidad de
población de las áreas cercanas al sitio del accidente se registra vs el numero d ella vía, los
tramos inicial y final, la distancia desde el tramo inicial, la distancia desde el tramo final,
Estos datos por lo general se encuentran en bases de datos diferentes y deben ser integradas
a la base de datos principal. La densidad de población puede ser la misma en todos los tramos
de la vía o variar dentro de un tramo en una distancia corta.
Después de la selección de datos, se obtiene el número de variables del estudio.
En la tabla 9 se presenta el resumen con los atributos existentes en la base de datos de
accidentes en 2016 Bogotá, seleccionados, el tipo y los valores permitidos para los mismos.
De acuerdo con el análisis del sistema y el fenómeno de accidentalidad bajo estudio, además
de la bibliografía al respecto, sería deseable tener una información más detallada referente
principalmente a genero ò sexo de los conductores, peatones, pasajeros ò personas
involucradas en el accidente, edad de estos, tiempo de expedición de la licencia de
conducción y antecedentes del conductor. características del vehículo como clase de
vehículo, tiempo de fabricación, información sobre el estado mecánico del mismo como
certificados de revisión mecánica y gases,
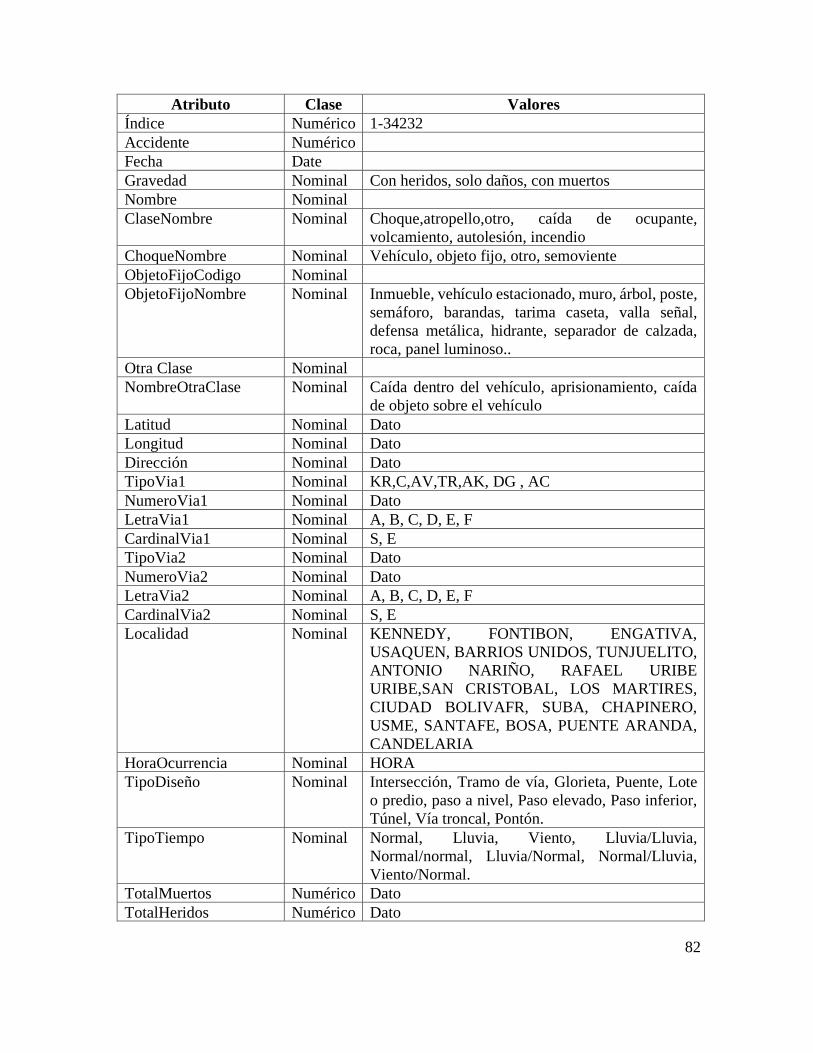
82
Atributo Clase Valores
Índice Numérico 1-34232
Accidente Numérico
Fecha Date
Gravedad Nominal Con heridos, solo daños, con muertos
Nombre Nominal
ClaseNombre Nominal Choque,atropello,otro, caída de ocupante,
volcamiento, autolesión, incendio
ChoqueNombre Nominal Vehículo, objeto fijo, otro, semoviente
ObjetoFijoCodigo Nominal
ObjetoFijoNombre Nominal Inmueble, vehículo estacionado, muro, árbol, poste,
semáforo, barandas, tarima caseta, valla señal,
defensa metálica, hidrante, separador de calzada,
roca, panel luminoso..
Otra Clase Nominal
NombreOtraClase Nominal Caída dentro del vehículo, aprisionamiento, caída
de objeto sobre el vehículo
Latitud Nominal Dato
Longitud Nominal Dato
Dirección Nominal Dato
TipoVia1 Nominal KR,C,AV,TR,AK, DG , AC
NumeroVia1 Nominal Dato
LetraVia1 Nominal A, B, C, D, E, F
CardinalVia1 Nominal S, E
TipoVia2 Nominal Dato
NumeroVia2 Nominal Dato
LetraVia2 Nominal A, B, C, D, E, F
CardinalVia2 Nominal S, E
Localidad Nominal KENNEDY, FONTIBON, ENGATIVA,
USAQUEN, BARRIOS UNIDOS, TUNJUELITO,
ANTONIO NARIÑO, RAFAEL URIBE
URIBE,SAN CRISTOBAL, LOS MARTIRES,
CIUDAD BOLIVAFR, SUBA, CHAPINERO,
USME, SANTAFE, BOSA, PUENTE ARANDA,
CANDELARIA
HoraOcurrencia Nominal HORA
TipoDiseño Nominal Intersección, Tramo de vía, Glorieta, Puente, Lote
o predio, paso a nivel, Paso elevado, Paso inferior,
Túnel, Vía troncal, Pontón.
TipoTiempo Nominal Normal, Lluvia, Viento, Lluvia/Lluvia,
Normal/normal, Lluvia/Normal, Normal/Lluvia,
Viento/Normal.
TotalMuertos Numérico Dato
TotalHeridos Numérico Dato
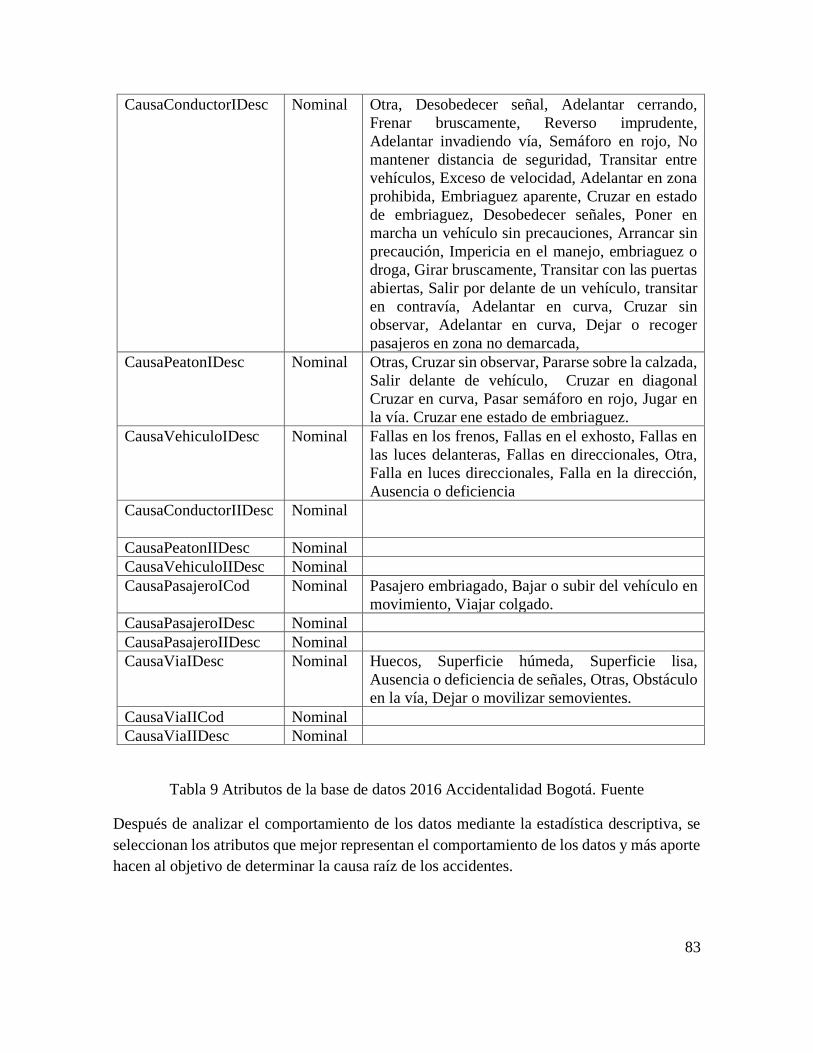
83
CausaConductorIDesc Nominal Otra, Desobedecer señal, Adelantar cerrando,
Frenar bruscamente, Reverso imprudente,
Adelantar invadiendo vía, Semáforo en rojo, No
mantener distancia de seguridad, Transitar entre
vehículos, Exceso de velocidad, Adelantar en zona
prohibida, Embriaguez aparente, Cruzar en estado
de embriaguez, Desobedecer señales, Poner en
marcha un vehículo sin precauciones, Arrancar sin
precaución, Impericia en el manejo, embriaguez o
droga, Girar bruscamente, Transitar con las puertas
abiertas, Salir por delante de un vehículo, transitar
en contravía, Adelantar en curva, Cruzar sin
observar, Adelantar en curva, Dejar o recoger
pasajeros en zona no demarcada,
CausaPeatonIDesc Nominal Otras, Cruzar sin observar, Pararse sobre la calzada,
Salir delante de vehículo, Cruzar en diagonal
Cruzar en curva, Pasar semáforo en rojo, Jugar en
la vía. Cruzar ene estado de embriaguez.
CausaVehiculoIDesc Nominal Fallas en los frenos, Fallas en el exhosto, Fallas en
las luces delanteras, Fallas en direccionales, Otra,
Falla en luces direccionales, Falla en la dirección,
Ausencia o deficiencia
CausaConductorIIDesc
Nominal
CausaPeatonIIDesc Nominal
CausaVehiculoIIDesc Nominal
CausaPasajeroICod Nominal Pasajero embriagado, Bajar o subir del vehículo en
movimiento, Viajar colgado.
CausaPasajeroIDesc Nominal
CausaPasajeroIIDesc Nominal
CausaViaIDesc Nominal Huecos, Superficie húmeda, Superficie lisa,
Ausencia o deficiencia de señales, Otras, Obstáculo
en la vía, Dejar o movilizar semovientes.
CausaViaIICod Nominal
CausaViaIIDesc Nominal
Tabla 9 Atributos de la base de datos 2016 Accidentalidad Bogotá. Fuente
Después de analizar el comportamiento de los datos mediante la estadística descriptiva, se
seleccionan los atributos que mejor representan el comportamiento de los datos y más aporte
hacen al objetivo de determinar la causa raíz de los accidentes.

84
En la tabla 9 se presentan los atributos que forman parte de data set minable. Se han eliminado
los atributos tipo numérico y string, ya que como se mencionó anteriormente, estos no pueden
incluirse en los algoritmos de clasificación disponibles en el programa.
Numero Atributo Clase
3 Gravedad Nominal
5 ClaseNombre Nominal
6 ChoqueNombre Nominal
7 ObjetoFijoNombre Nominal
9 NombreOtraClase Nominal
10 TipoVia1 Nominal
12 Localidad Nominal
13 HoraOcurrencia Nominal
14 TipoDiseño Nominal
15 TipoTiempo Nominal
Tabla 10 Atributos seleccionados para el data set minable. Fuente: elaboración propia.
6.1.5. MODELADO Y DESARROLLO DEL DATA MINING, CAUSA PROXIMA.
En esta etapa se selecciona una o varias de las técnicas mencionadas anteriormente. Para el
presente trabajo se escoge las redes neuronales contenido en la opción funciones de
clasificación y en particular el perceptrón multicapas.
Alternativamente se van a evaluar el desempeño de los algoritmos bayesianos NaivesBayes
y BayesNet, descritos en la sección
Esta tarea se empieza a diseñar desde que se comienzan a gestionar los datos. Los
componentes principales son:
Entrada es el bloque de entrada, conformado por la vista minable, los datos están
seleccionados, muestreados, transformados..
Dadas las características de los objetivos y metas planteados, a saber, la asociación o a
identificar la causa de accidentes de tránsito, se desearía tener un algoritmo de predicción, el
cual, dadas unas condiciones particulares del accidente a analizar, y con una herramienta
entrenada para realizar predicción, se puede identificar la probable causa o causas de un
accidente. Sin embargo, al tener en cuenta que las características de un accidente son muy
particulares, se puede ver también como una guía para realizar un análisis por parte de
expertos y ahí si determinar las causas más probables. En este caso, la herramienta serviría
como guía para que los expertos partan de sus resultados y el trabajo resulte menos extenso.
Una limitación para que esto ocurra es el hecho de que las bases de datos existentes no

85
contienen toda la cantidad de variables que pueden intervenir en un accidente. Es decir,
después de la extracción visual de patrones, se realiza el análisis para la extracción de
conocimiento y su posterior uso que sería identificar la causa raíz del accidente.
Además, el llegar a tener una aproximación respecto de las causas próximas es un buen
comienzo para comenzar la búsqueda de las causas básicas, y que esta es una labor mucho
más técnica y en donde se debe escudriñar bastante para llegar a la causa básica más probable,
analizando los detalles mínimos del accidente y aplicando conceptos físicos particulares.
En la literatura se ha encontrado en [1] dentro de las recomendaciones de aplicación de
minería de datos en análisis de riesgos, “así mismo y a nivel predictivo un objetivo
supremo seria obtener probabilidades más confiables de ocurrencia de accidentes dadas
ciertas condiciones iniciales, esto a través de un modelo clasificador por ejemplo”.
Algunos autores proponen realizar primero una tarea descriptiva para identificar los
patrones de accidentalidad, seguida por una tarea predictiva para identificar las variables
que se relacionan con las causas básicas del accidente.
En algunos casos se utiliza la técnica de agrupamiento y en otros la de reglas de asociación.
El primer caso se utiliza en las referencias [1], [6] y la segunda en la referencia [4].
Para la extracción de las variables relacionadas con la causa próxima o inmediata se utilizan
las técnicas de redes neuronales y algoritmos bayesianos.
En [1] se plantea el uso en primer lugar de un algoritmo de agrupamiento, el cual permite la
identificación de patrones de accidentalidad, es decir para un mismo grupo se incluyen los
atributos que se repiten en esa clase de accidente.
Una vez seleccionados los atributos más influyentes se procede a correr el algoritmo de
clasificación o predicción que consiste en que dados los grupos, se obtiene la serie de
atributos cuyas instancias relacionadas permiten obtener cada uno de ellos, para lo cual se
pueden combinar distintos grupos de atributos según su mayor a menor influencia al
modelo descriptivo.
En el algoritmo predictivo se requiere seleccionar un atributo clasificador.
En [3] se recomienda deducir las causas del accidente a partir del análisis de patrones de
variables independientes. Por esta razón al aplica la asociación de árboles de decisión se
obtienen las reglas a partir de las cuales se pueden determinar las causas de los accidentes.
Aquí los accidentes se encuentran agrupados en la fase de agrupación.
En resumen, no se obtiene directamente las causas del accidente.

86
Se puede trabajar un modelo descriptivo, el principal es el de reglas de asociación, para
estudiar la relación entre las diferentes variables que pueden causar el accidente, y otras
características de este. De aquí se pueden utilizar esta información para agilizar un método
con la participación de expertos permita obtener diferentes hipó tesis de causa del accidente.
De otro lado esto puede ser acompañado con técnicas de agrupamiento. En que paso se
describen los patrones de accidentalidad. Puede ser en el paso de reglas de asociación o
clusstering.
Interpretación de resultados y conclusiones.
En este paso se obtienen los patrones que definen el comportamiento de la accidentalidad [1].
Se pueden confirmar o rechazar hipótesis a priori.
El estudio de patrones de accidentalidad describe los patrones detectados sin explicar porque
ocurren o se asocian a tal o cual forma. Esta es tarea del analista y los expertos.
En la figura se presenta el proceso de modelamiento de los datos de minería de datos a partir
del data set minable.
A continuación, se desarrolla cada una de las etapas o tareas mencionadas.
Para el análisis de los clústeres se pueden presentar dos tipos de gráficas.
En primer lugar, se presenta en el eje x los valores de un atributo y en el otro eje los de otro
atributo. Aquí se puede visualizar como se agrupan los datos con respecto a los valores de
los dos atributos, mientras que el color de cada dato representa el clúster al cual pertenece.
En segundo lugar, se pueden tener las gráficas en las que en un eje se presenta un atributo y
en el otro los diferentes clústeres. Aquí se visualiza para cada clúster los valores que
corresponden en una determinada variable o atributo.
Se utiliza para el agrupamiento el algoritmo K-means. Esto se hace por medio del programa
Weka, y se eliminan los atributos que no aportan información relevante, quedando veintidós
atributos para esta actividad.
Se presentan los resultados de este agrupamiento, identificando como clases, los atributos
que sirven para definir cada grupo de atributos con características comunes. Los valores
perdidos se reemplazaron con la media.

87
FASE DE ENTRADA
RECOLECCION DE DATOS
FASE DE MINADO
CLUSTERING DE ACCIDENTES K
MEANS
EXTRACCION DE REGLAS
CLASIFICACION DE CAUSA DE
ACCIDENTE
MODELO DE PREDICCION
ANN
PREPROCESAMIENTO DE LOS DATOS
FASE DE SALIDA
SALIDA DE PREDICCION
POSIBLES CAUSAS DE ACCIDENTE
Figura 21 Proceso de modelamiento de minería de datos. Fuente: elaboración propia.
Debido a que los atributos presentes en la mayoría de los cinco clústeres tienen valores muy
similares, se reduce el número de clústeres y se analiza el agrupamiento solamente con dos
clústeres.
Los resultados se muestran en la tabla 10.
A continuación, se presenta el análisis de cada uno de los cluesteres obtenidos, y las
conclusiones respectivas. El programa entrega una serie de gráficos que permiten realizar los
siguientes análisis;
• En el eje horizontal presenta el clúster identificado por colores y en el eje vertical
uno de los atributos del data set. Aquí se observa de manera diferenciada cada
clúster en una sola zona de la figura.

88
• En el eje horizontal y vertical se presentan dos atributos mientras que en el color
asignado a cada clúster se observan los datos agrupados. En esta gráfica los
clústeres no se encuentran en una sola forma, sino que pueden estar distribuidos en
distintos puntos de la figura, pero son identificados mediante su color respectivo.
Inicialmente se configuró el programa con dos clústeres. En la tabla se presenta el resumen
de los valores de los atributos que caracterizan cada uno de ellos. Se observa que los valores
son iguales, por lo tanto, al considerar este caso no aporta más información. En la figura se
observa que los clústeres 0 y 2 están prácticamente sobrepuestos, lo cual indica que no existe
un atributo al menos que permita diferenciarlos.
Figura 22 Gráfica agrupamiento con dos clústeres. Eje x clúster, eje y gravedad accidente.
Clúster 0 color azul, clúster 1 color rojo. Fuente: elaboración propia programa Weka 3.8.

89
En la figura 22 se aprecia que no existe prácticamente ninguna diferencia entre los dos
clústeres, ya que los puntos en azul que corresponden al clúster 0 prácticamente coinciden en
su posición con los rojos, del clúster 1.
Desde este punto de vista y mirando la tabla,
Tabla 11 Resultados agrupamiento con dos clústeres, Fuente: elaboración propia programa
Weka 3.8.
En la figura 22 se presenta la configuración del algoritmo de agrupamiento Simple K means
en Weka. La tabla presenta el porcentaje de instancias perteneciente a cada clúster, y se
realiza el análisis de las características de cada grupo.

90
Figura 23 Configuración del algoritmo K -means en Weka. Fuente: elaboración propia
programa Weka 3.8.
Se han obtenido cinco clústeres, con la siguiente distribución de datos:
Clúster n° Instancias/registros %
0 11173 32
1 12773 37
2 5723 16
3 524 2
4 4735 14
Tabla 12 Porcentaje de instancias incluidas en cada clúster. Fuente: elaboración propia
programa Weka 3.8.

91
En la siguiente tabla se muestra el resumen en donde se incluyen los atributos y sus
respectivos valores característicos de los diferentes clústeres.
Como se aprecia en la figura 23 se pueden observar los cinco clústeres bien diferenciados
con algunas observaciones por fuera de ellos.
Clúster 0 azul
El clúster cero se caracteriza principalmente por accidentes que involucran choque con otro
vehículo, con consecuencia de solo daños, en glorietas, condición climática normal, en
algunos casos presencia de huecos en la vía. Como los accidentes analizados son dentro de
la ciudad con una velocidad límite de60 kph, no se espera que esté presente la condición de
velocidad alta, aunque esto podría ocurrir. Sin embargo, las condiciones de maniobra en las
glorietas, con acceso de varios vehículos simultáneamente, hace que estos tramos de vía sean
más propensos a la ocurrencia de conflictos viales. Probablemente la condición de baja
velocidad se relacione con la consecuencia de solo daños.
Clúster 1 rojo
En este caso predominan los accidentes con choque y atropello, muertos y en menor
proporción heridos, con vehículo, en glorieta, condición ambiental normal, peatón transitar
en menor proporción y en mayor otra, en algunos casos vías con huecos.
Clúster 2 verde
Accidentes con choques, en menor cantidad volcamiento, heridos, en glorieta y en menor
cantidad paso y puente, condición atmosférica normal, y en menor cantidad con viento,
atribuibles al peatón otra, pasar, transitar, atribuibles al pasajero otra, colgados, vía con
huecos en algunos casos.
Clúster 3 aguamarina
Accidentes con choques y heridos y otro vehículo, objeto fijo en menor cantidad, transitando
por glorieta y en menor cantidad paso, puente, condición atmosférica normal y en menor
cantidad con viento, como causa de pasajero otra y colgados, huecos en la vía.
Clúster 4 lila
Accidentes con choque, solo daños, transitando por glorieta, en paso o puente en menor
cantidad, condición atmosférica normal, con viento en menor cantidad, con peatón parado o
transitando, vehículo con fallas, pasajero otra o colgado huecos en la vía, superficie húmeda
y poste en menor cantidad.
92
T
Tabla 13 Resumen clusters. Fuente: elaboración propia programa Weka 3.8.
.
93
Figura 24 Gráfica agrupamiento algoritmo K-Means con cinco clústeres. Fuente:
elaboración propia programa Weka 3.8.

94
En esta etapa se trata de asignar etiquetas a la variable o variables de predicción, relacionadas
con el conjunto de variables definidas como independientes o predictoras.
El algoritmo seleccionado en primer lugar es el de redes neuronales artificiales descrito
anteriormente. Se considera también la aplicación de un algoritmo bayesiano, en este caso
Naive Bayes por tratarse de una técnica con menores requerimientos computacionales que la
red neuronal y buen desempeño.
Una vez obtenido el data set minable de acuerdo con los objetivos del estudio, se procede a
procesar los datos contenidos en el mismo con el algoritmo de perceptrón multicapas.
Se realizaron varias corridas utilizando los algoritmos Perceptrón multicapas y Naive
Bayes. Se seleccionaron las configuraciones de los clasificadores que presentaron un mejor
desempeño de acuerdo con las métricas estudiadas anteriormente.
En la tabla 14 se resumen las diferentes corridas realizadas. Las corridas en color rojo son
las que presentaron mejor desempeño.
En la figura 15 se presentó un diagrama de proceso de la configuración y aplicación de la red
neuronal artificial. Como se mencionó anteriormente como en cualquier algoritmo para
minería de datos el primer paso es el preprocesamiento de los datos para obtener la vista
minable. En segundo lugar, se selecciona la clase de red neuronal a utilizar. En este estudio
se trata del perceptrón multicapas que por su estructura y funcionamiento se asimila a la
estructura de datos disponible.
A continuación, se muestra la configuración del clasificador.
El número de capas ocultas es a, que es igual a:
Número de atributos + número de clases /2 = 11+2/2 = 6.5 aproximadamente 7 capas
ocultas.
La tasa de aprendizaje es de 0.3, teniendo en cuenta que el valor no debe de ser muy
pequeño porque el algoritmo se demora más ni muy grande porque puede saltar el valor
óptimo que busca.
El momentum es de 0,2.
Preprocesamiento.
Entre los métodos utilizados por el programa para aumentar la precisión del clasificador
están:

95
Selección de atributos.
Ranker.
Aplicación de filtros-
Aplicación de envoltorios (wrapper).
Selección con principal componente análisis.
Entrenamiento.
El entrenamiento de la red se realizó utilizando el data set minable y el procedimiento
descrito en la sección 5.4.3.1.1.
Durante esta fase, y dependiendo de las características del dataset como ruido, pequeño
número de datos y del clasificador como su complejidad, se pueden presentar algunas
situaciones que disminuyen el rendimiento de la red. cuando las clases están desbalanceadas,
es decir según Singh Maninder existen diferencias apreciables entre el número de instancias
negativas y positivas, especialmente cuando las negativas sobrepasan a las positivas. Estas
pueden ser;
Sobre aprendizaje y sub-aprendizaje.
La sobre adaptación o sobre aprendizaje puede ocurrir cuando el clasificador obtiene un alto
porcentaje de aciertos en entrenamiento, pero pequeño en test, aprende los datos de memoria
y no generaliza. Den la validación cruzada se obtienen porcentajes cercanos al azar, es decir
la índice kappa es cercano a cero. De otro lado si la complejidad del clasificador no es
suficiente de acuerdo con el problema, se produce su adaptación.
Validación del modelo.
Para determinar la bondad del proceso de clasificación se utiliza la validación del modelo,
el cual trata de determinar la capacidad de predicción del clasificador. Para ello se utilizan
las métricas y criterios presentados en la sección 5.4.3.1.2. esta actividad es realizada por el
programa Weka, se acuerdo con las opciones presentadas, y los resultados presentados en la
hoja para el efecto.
Análisis de las métricas seleccionadas.
Después de correr el programa con la configuración seleccionada del clasificador, en este
caso el perceptrón multicapas, se obtienen los resultados en forma de tablas y gráficas que
resumen las características de desempeño del modelo de acuerdo con las métricas
seleccionadas.
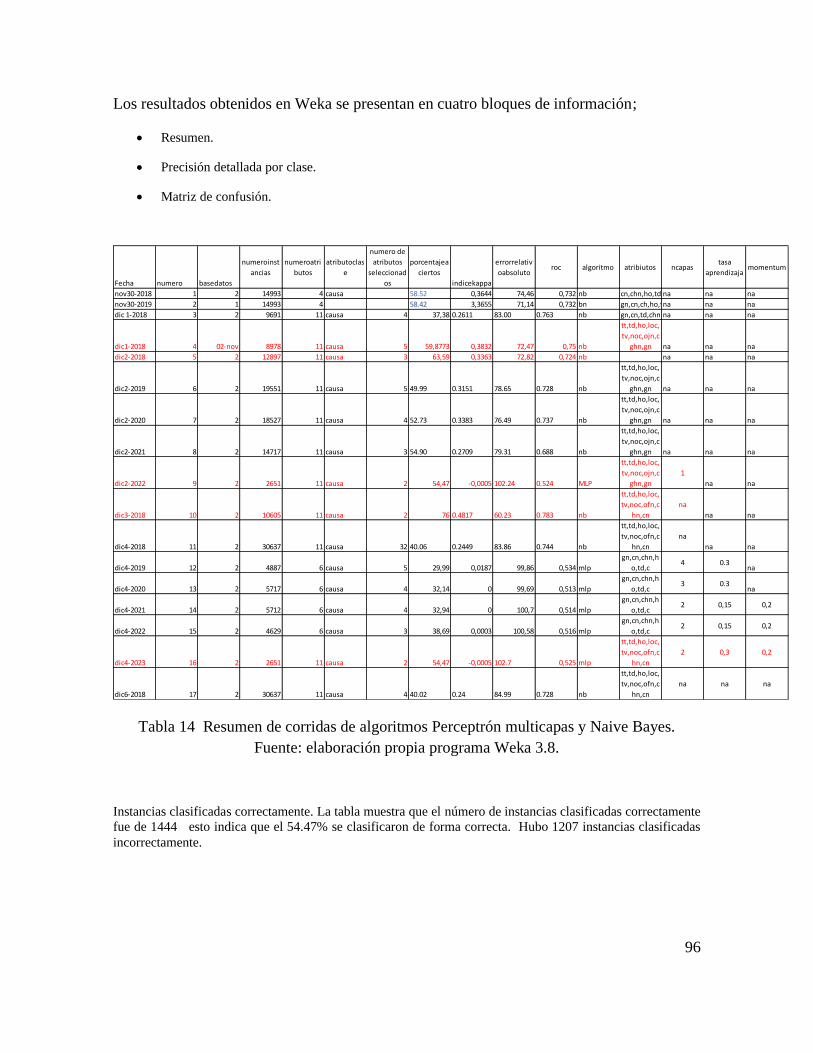
96
Los resultados obtenidos en Weka se presentan en cuatro bloques de información;
• Resumen.
• Precisión detallada por clase.
• Matriz de confusión.
Tabla 14 Resumen de corridas de algoritmos Perceptrón multicapas y Naive Bayes.
Fuente: elaboración propia programa Weka 3.8.
Instancias clasificadas correctamente. La tabla muestra que el número de instancias clasificadas correctamente
fue de 1444 esto indica que el 54.47% se clasificaron de forma correcta. Hubo 1207 instancias clasificadas
incorrectamente.
Fecha numero basedatos
numeroinst
ancias
numeroatri
butos
atributoclas
e
numero de
atributos
seleccionad
os
porcentajea
ciertos
indicekappa
errorrelativ
oabsolutoroc algoritmo atribiutos ncapas
tasa
aprendizajamomentum
nov30-2018 1 2 14993 4 causa 58.52 0,3644 74,46 0,732 nb cn,chn,ho,td na na na
nov30-2019 2 1 14993 4 58.42 3,3655 71,14 0,732 bn gn,cn,ch,ho,tdna na na
dic 1-2018 3 2 9691 11 causa 4 37,38 0.2611 83.00 0.763 nb gn,cn,td,chn na na na
dic1-2018 4 02-nov 8978 11 causa 5 59,8773 0,3832 72,47 0,75 nb
tt,td,ho,loc,
tv,noc,ojn,c
ghn,gn na na na
dic2-2018 5 2 12897 11 causa 3 63,59 0,3363 72,82 0,724 nb na na na
dic2-2019 6 2 19551 11 causa 5 49.99 0.3151 78.65 0.728 nb
tt,td,ho,loc,
tv,noc,ojn,c
ghn,gn na na na
dic2-2020 7 2 18527 11 causa 4 52.73 0.3383 76.49 0.737 nb
tt,td,ho,loc,
tv,noc,ojn,c
ghn,gn na na na
dic2-2021 8 2 14717 11 causa 3 54.90 0.2709 79.31 0.688 nb
tt,td,ho,loc,
tv,noc,ojn,c
ghn,gn na na na
dic2-2022 9 2 2651 11 causa 2 54,47 -0,0005 102.24 0.524 MLP
tt,td,ho,loc,
tv,noc,ojn,c
ghn,gn
1
na na
dic3-2018 10 2 10605 11 causa 2 76 0.4817 60.23 0.783 nb
tt,td,ho,loc,
tv,noc,ofn,c
hn,cn
na
na na
dic4-2018 11 2 30637 11 causa 32 40.06 0.2449 83.86 0.744 nb
tt,td,ho,loc,
tv,noc,ofn,c
hn,cn
na
na na
dic4-2019 12 2 4887 6 causa 5 29,99 0,0187 99,86 0,534 mlp
gn,cn,chn,h
o,td,c4 0.3
na
dic4-2020 13 2 5717 6 causa 4 32,14 0 99,69 0,513 mlp
gn,cn,chn,h
o,td,c3 0.3
na
dic4-2021 14 2 5712 6 causa 4 32,94 0 100,7 0,514 mlp
gn,cn,chn,h
o,td,c2 0,15 0,2
dic4-2022 15 2 4629 6 causa 3 38,69 0,0003 100,58 0,516 mlp
gn,cn,chn,h
o,td,c2 0,15 0,2
dic4-2023 16 2 2651 11 causa 2 54,47 -0,0005 102.7 0,525 mlp
tt,td,ho,loc,
tv,noc,ofn,c
hn,cn
2 0,3 0,2
dic6-2018 17 2 30637 11 causa 4 40.02 0.24 84.99 0.728 nb
tt,td,ho,loc,
tv,noc,ofn,c
hn,cn
na na na
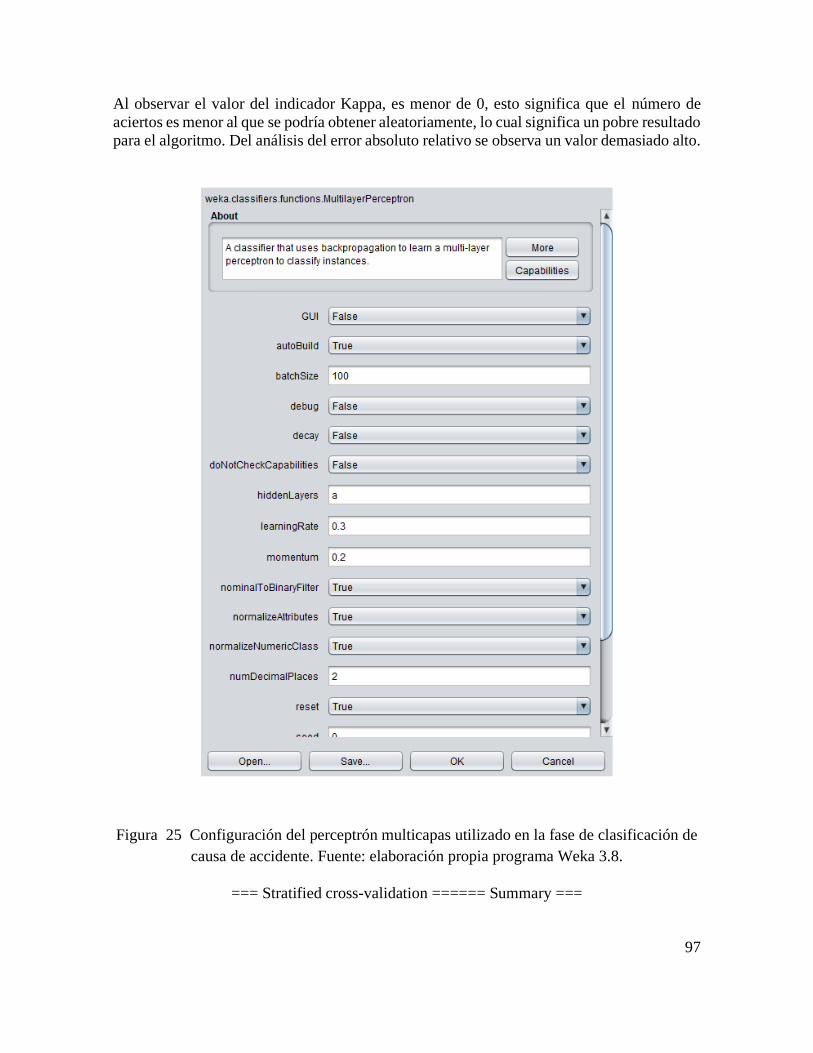
97
Al observar el valor del indicador Kappa, es menor de 0, esto significa que el número de
aciertos es menor al que se podría obtener aleatoriamente, lo cual significa un pobre resultado
para el algoritmo. Del análisis del error absoluto relativo se observa un valor demasiado alto.
Figura 25 Configuración del perceptrón multicapas utilizado en la fase de clasificación de
causa de accidente. Fuente: elaboración propia programa Weka 3.8.
=== Stratified cross-validation ====== Summary ===

98
Correctly Classified Instances 1444 54.47 %
Incorrectly Classified Instances 1207 45.53 %
Kappa statistic -0.0005
Mean absolute error 0.0316
Root mean squared error 0.1253
Relative absolute error 102.1792 %
Root relative squared error 101.3349 %
Total number o Instances 2651
En la tabla análisis detallado por clase, se muestran los valores de los indicadores Tasa de
verdaderos positivos 0.401, tasa de falsos positivos 0.16, recall 0.545, precisión 0.511, F
mesure, área bajo la curva ROC 0.744 en promedio, área PRC 0.311. En esta tabla se
incluyen todos los valores de la variable causa, aunque se mantuvieron solamente los dos con
frecuencias más altas. Por esa razón en la tabla los indicadores figuran con un signo de
interrogación.
El valor de recall o cobertura indica que el 54.55 de las instancias han sido clasificadas
correctamente.
La precisión indica que el 51.1% de las instancias clasificadas como verdaderos lo son
realmente.
Para el indicador F su valor promedio no figura el promedio, sin embargo, para la clase
mayoritaria no mantener distancia de seguridad, su valor es de 0.564 los cual significa que
este valor es la media armónica de la precisión y la cobertura.
En la tabla se presenta la matriz de confusión, que muestra 1219 aciertos para la clase no
mantener distancia de seguridad, y 225 aciertos para la segunda clase que es otras causas de
accidente. Las demás clases presentan valores de cero debido a que solamente se tuvieron en
cuenta las dos clases con mayor frecuencia.
Análisis de las gráficas.
En las figuras 24 a 28 se presenta en forma gráfica la información más representativa
para evaluar el modelo clasificador.
Análisis de curva margen de predicción (margin curve).

99
Esta curva representa el margen de predicción, es decir la diferencia entre el valor de
probabilidad para la clase predicha y el valor de la probabilidad más alta para las clases
diferentes a la predicha. Entre más alto sea este valor hay mayor certeza de que la predicción
sea correcta, ya que hay un mayor margen para equivocarse.
Un margen de 1 significa que la confiabilidad de la predicción es del 100% mientras un
margen de -1 significa lo contrario, es decir que la confiabilidad es de predicción de una clase
incorrecta es del 100%. Como el valor mínimo en la gráfica es de -0.33 para la instancia 1, y
comienza a aumentar para las otras instancias, quiere decir que el margen va aumentando a
medida que se aumenta el número de instancias y para 2651 instancias, que son las que se
analizaron es de 0.33 que representa una confiabilidad de 33%, que, aunque no es el valor
óptimo (100%) tampoco es un valor tan bajo. Esto significa que entre mayor sea el número
de instancias analizadas, mayor el valor del margen de predicción y por lo tanto la
confiabilidad de la predicción.
Análisis de curva de error.
Se muestran las instancias bien clasificadas con una cruz y las mal clasificadas con un
cuadrado, para cada valor del atributo causa. Se observa una mayor cantidad de instancias
bien clasificadas (cruces) para la clase adelantar cerrando en color azul y para la clase no
mantener distancia de seguridad en color rojo.
Análisis de curva PRC (Recall-Precisión).
El área bajo la curva RP (recall-precisión) es de 0.314 que es un valor bajo. Para el sistema
bajo estudio resulta más útil considerar el valor ROC, ya que el RPC se utiliza más cuando
es más importante acertar en una clase que en otras, por ejemplo “buscar una aguja en un
pajar”. En el caso bajo estudio, si la clase “no respetar distancia de seguridad” fuera más
importante que la clase otras, o la clase adelantar cerrando, ò huecos, sería mejor aplicar la
curva PRC ya que no debería dejarse por fuera del clasificador ningún caso, es decir el
algoritmo clasificador no debería dejar de clasificar correctamente ningún caso de no respetar
distancia de seguridad, pero esta no es la situación bajo estudio.
Análisis de la curva ROC.
El área bajo la curva ROC es de 0.744. el rango de valores recomendado para un buen
modelo según y está entre 0.75 y 1. En este caso el valor está ligeramente por debajo de 0.75.
Esto significa que puede clasificar correctamente los verdaderos positivos y los verdaderos
negativos.
Análisis de la curva Beneficio Costo.
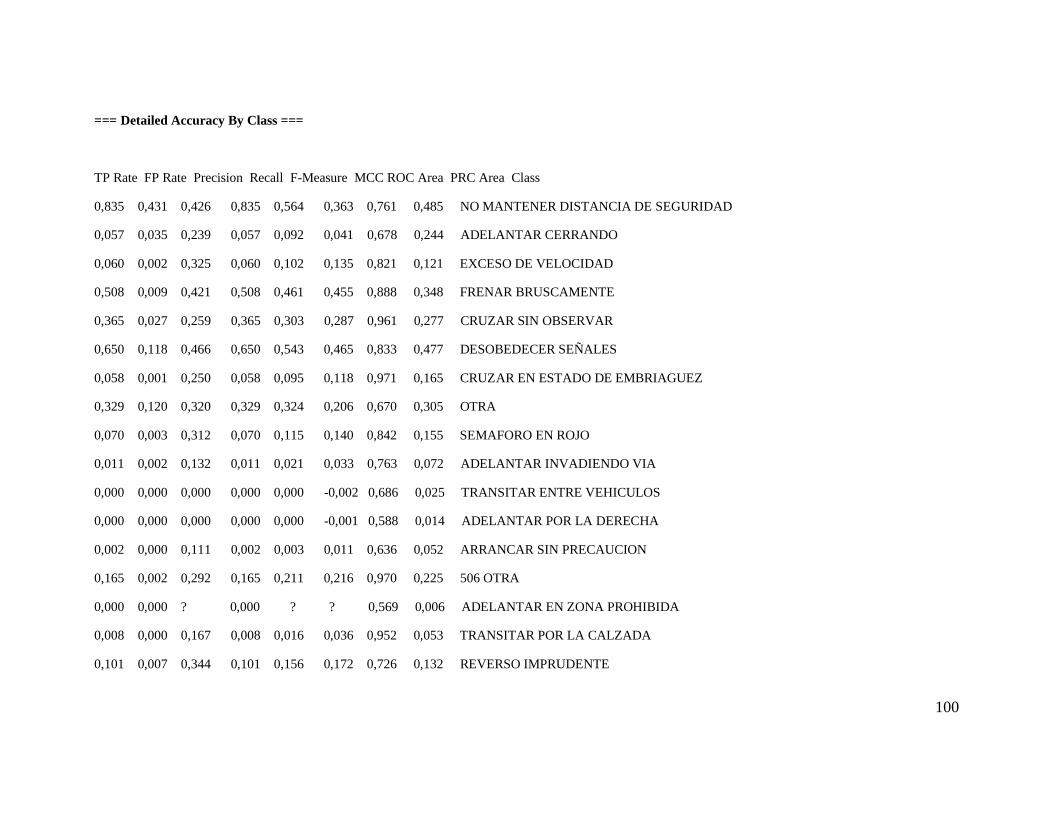
100
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0,835 0,431 0,426 0,835 0,564 0,363 0,761 0,485 NO MANTENER DISTANCIA DE SEGURIDAD
0,057 0,035 0,239 0,057 0,092 0,041 0,678 0,244 ADELANTAR CERRANDO
0,060 0,002 0,325 0,060 0,102 0,135 0,821 0,121 EXCESO DE VELOCIDAD
0,508 0,009 0,421 0,508 0,461 0,455 0,888 0,348 FRENAR BRUSCAMENTE
0,365 0,027 0,259 0,365 0,303 0,287 0,961 0,277 CRUZAR SIN OBSERVAR
0,650 0,118 0,466 0,650 0,543 0,465 0,833 0,477 DESOBEDECER SEÑALES
0,058 0,001 0,250 0,058 0,095 0,118 0,971 0,165 CRUZAR EN ESTADO DE EMBRIAGUEZ
0,329 0,120 0,320 0,329 0,324 0,206 0,670 0,305 OTRA
0,070 0,003 0,312 0,070 0,115 0,140 0,842 0,155 SEMAFORO EN ROJO
0,011 0,002 0,132 0,011 0,021 0,033 0,763 0,072 ADELANTAR INVADIENDO VIA
0,000 0,000 0,000 0,000 0,000 -0,002 0,686 0,025 TRANSITAR ENTRE VEHICULOS
0,000 0,000 0,000 0,000 0,000 -0,001 0,588 0,014 ADELANTAR POR LA DERECHA
0,002 0,000 0,111 0,002 0,003 0,011 0,636 0,052 ARRANCAR SIN PRECAUCION
0,165 0,002 0,292 0,165 0,211 0,216 0,970 0,225 506 OTRA
0,000 0,000 ? 0,000 ? ? 0,569 0,006 ADELANTAR EN ZONA PROHIBIDA
0,008 0,000 0,167 0,008 0,016 0,036 0,952 0,053 TRANSITAR POR LA CALZADA
0,101 0,007 0,344 0,101 0,156 0,172 0,726 0,132 REVERSO IMPRUDENTE
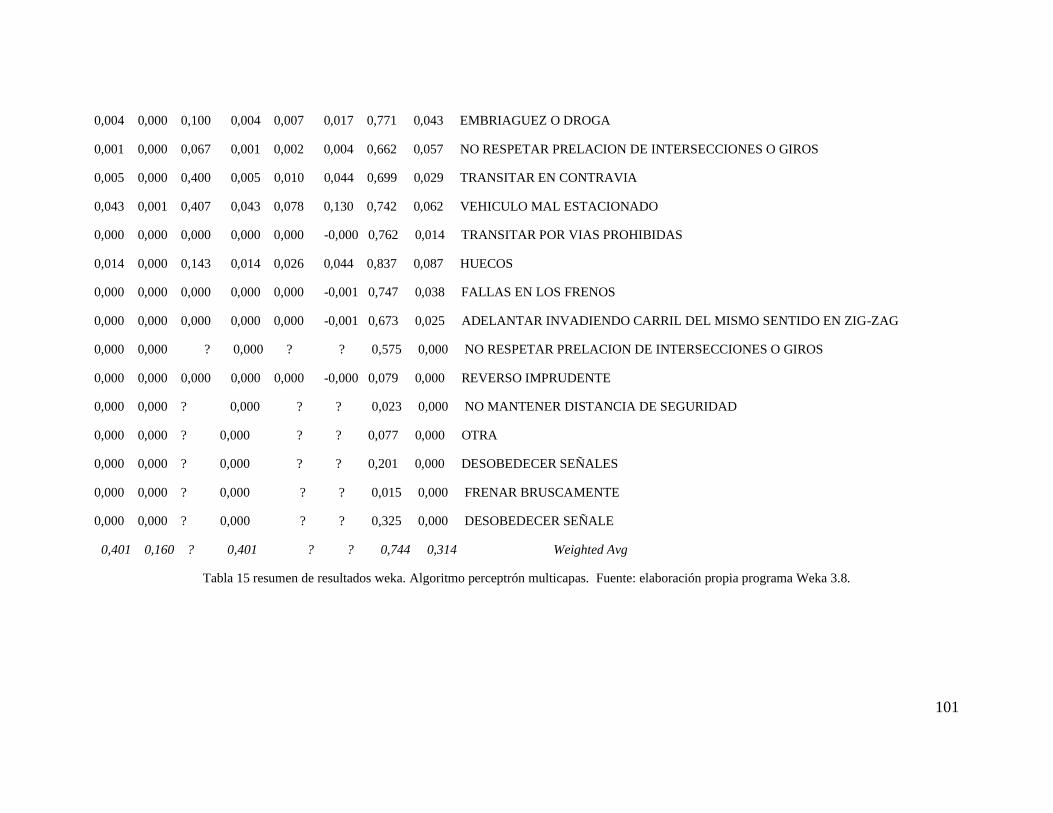
101
0,004 0,000 0,100 0,004 0,007 0,017 0,771 0,043 EMBRIAGUEZ O DROGA
0,001 0,000 0,067 0,001 0,002 0,004 0,662 0,057 NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0,005 0,000 0,400 0,005 0,010 0,044 0,699 0,029 TRANSITAR EN CONTRAVIA
0,043 0,001 0,407 0,043 0,078 0,130 0,742 0,062 VEHICULO MAL ESTACIONADO
0,000 0,000 0,000 0,000 0,000 -0,000 0,762 0,014 TRANSITAR POR VIAS PROHIBIDAS
0,014 0,000 0,143 0,014 0,026 0,044 0,837 0,087 HUECOS
0,000 0,000 0,000 0,000 0,000 -0,001 0,747 0,038 FALLAS EN LOS FRENOS
0,000 0,000 0,000 0,000 0,000 -0,001 0,673 0,025 ADELANTAR INVADIENDO CARRIL DEL MISMO SENTIDO EN ZIG-ZAG
0,000 0,000 ? 0,000 ? ? 0,575 0,000 NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0,000 0,000 0,000 0,000 0,000 -0,000 0,079 0,000 REVERSO IMPRUDENTE
0,000 0,000 ? 0,000 ? ? 0,023 0,000 NO MANTENER DISTANCIA DE SEGURIDAD
0,000 0,000 ? 0,000 ? ? 0,077 0,000 OTRA
0,000 0,000 ? 0,000 ? ? 0,201 0,000 DESOBEDECER SEÑALES
0,000 0,000 ? 0,000 ? ? 0,015 0,000 FRENAR BRUSCAMENTE
0,000 0,000 ? 0,000 ? ? 0,325 0,000 DESOBEDECER SEÑALE
0,401 0,160 ? 0,401 ? ? 0,744 0,314 Weighted Avg
Tabla 15 resumen de resultados weka. Algoritmo perceptrón multicapas. Fuente: elaboración propia programa Weka 3.8.

102
Análisis de la curva de costo.
Cuando se incluye el concepto de costo en el análisis, se considera el costo de clasificar un
negativo como positivo o un positivo como negativo. Las curvas de costo son según
Drummond Holte más adecuadas para estimar la bondad de un modelo que las curvas ROC.
Permiten visualizar el desempeño a través de la tasa de error o costo de mala clasificación.
Muestra los intervalos de confianza en el desempeño del clasificador y la significancia
estadística en el rendimiento de dos clasificadores.
La gráfica presenta en el eje x la función de probabilidad de costo y en el eje Y el costo
esperado. Cada línea en la figura es una curva de costo que corresponde a una condición en
la curva ROC, o sea a una pareja de valores tasa de falso positivo-tasa de verdadero positivo,
o sea que representa el costo esperado del clasificador en el rango completo de posibles
distribuciones de clase y costos de mala clasificación. Para el caso bajo estudio no es tan
importante tener en cuenta los costos, sin embargo, se han incluido las gráficas. Los valores
extremos de las líneas representan en el eje y los costos de falso positivo cuando x igual cero
y costo de falso negativo cuando x igual a 1. El costo de clasificar bien una instancia es
siempre menor que el de clasificarla mal. El mejor clasificador, que clasifica siempre de
modo correcto, tiene un costo igual a cero.
El costo máximo de clasificación o sea 1 ocurre cuando todas las instancias son clasificadas
incorrectamente. El valor en y es una extensión de la tasa de error a los costos normalizados.
Fracción de la diferencia entre los costos máximo y mínimo en que se incurre al utilizar el
clasificador. El mayor valor de costo esperado está un poco por debajo de 0.5, que
corresponde al valor de la envolvente inferior de todas las curvas de costo. Esto sirve para
comparare el rendimiento de varios clasificadores. El que tenga un menor costo esperado
tiene un mejor desempeño cuando los costos son importantes.

103
=== Confusion Matrix ===
a b c d e f g h i j k l m n o p q r s t u v w x y z aa ab ac ad ae af <-- classified as
1219 0 0 0 0 0 0 305 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | a = NO MANTENER DISTANCIA DE SEGURIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | b = ADELANTAR CERRANDO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | c = EXCESO DE VELOCIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | d = FRENAR BRUSCAMENTE 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | e = CRUZAR SIN OBSERVAR
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | f = DESOBEDECER SE ム ALES
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | g = CRUZAR EN ESTADO DE EMBRIAGUEZ
902 0 0 0 0 0 0 225 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | h = OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | i = SEMAFORO EN ROJO 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | j = ADELANTAR INVADIENDO VIA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | k = TRANSITAR ENTRE VEHICULOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | l = ADELANTAR POR LA DERECHA 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | m = ARRANCAR SIN PRECAUCION
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | n = 506 OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | o = ADELANTAR EN ZONA PROHIBIDA 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | p = TRANSITAR POR LA CALZADA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | q = REVERSO IMPRUDENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | r = EMBRIAGUEZ O DROGA 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | s = NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | t = TRANSITAR EN CONTRAVIA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | u = VEHICULO MAL ESTACIONADO 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | v = TRANSITAR POR VIAS PROHIBIDAS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | w = HUECOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | x = FALLAS EN LOS FRENOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | y = ADELANTAR INVADIENDO CARRIL DEL MISMO SENTIDO EN ZIG-ZAG
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | z = NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | aa = REVERSO IMPRUDENTE 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ab = NO MANTENER DISTANCIA DE SEGURIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ac = OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ad = DESOBEDECER SE ム ALES
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ae = FRENAR BRUSCAMENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | af = DESOBEDECER SE ム ALES
104
Gráficas.
Figura 26 Curva de margen de predicción (Margin curve) Fuente: elaboración propia
programa Weka 3.8.
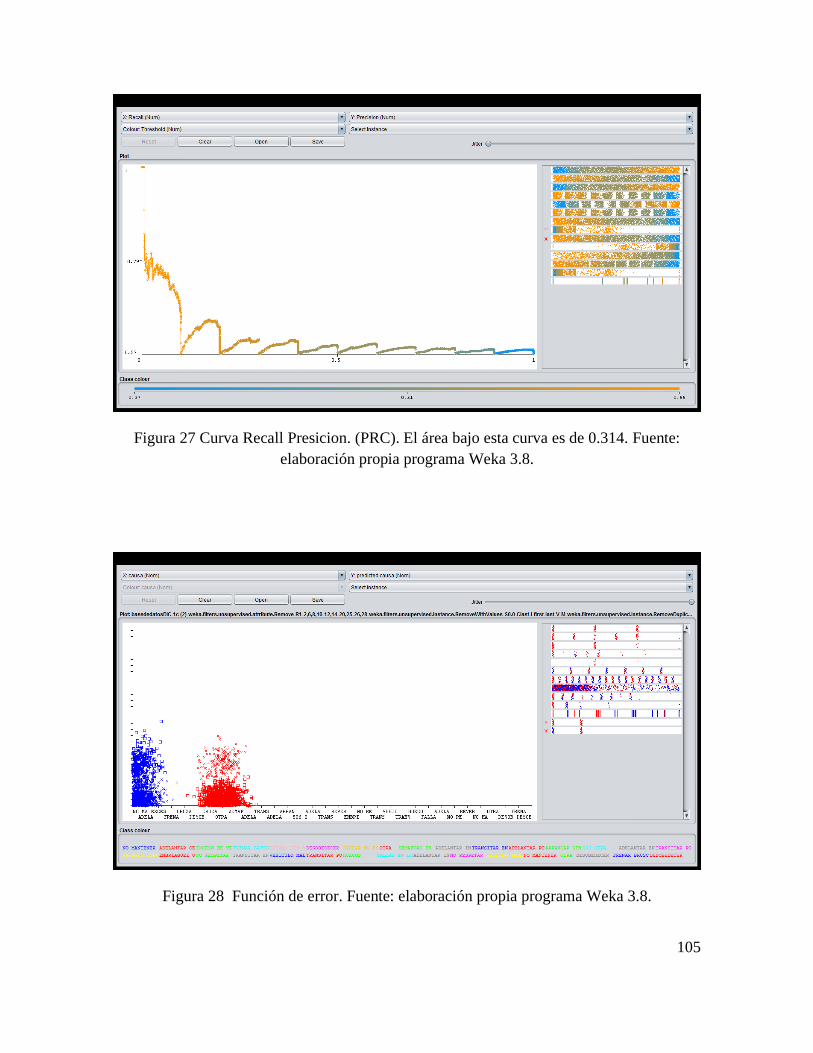
105
Figura 27 Curva Recall Presicion. (PRC). El área bajo esta curva es de 0.314. Fuente:
elaboración propia programa Weka 3.8.
Figura 28 Función de error. Fuente: elaboración propia programa Weka 3.8.
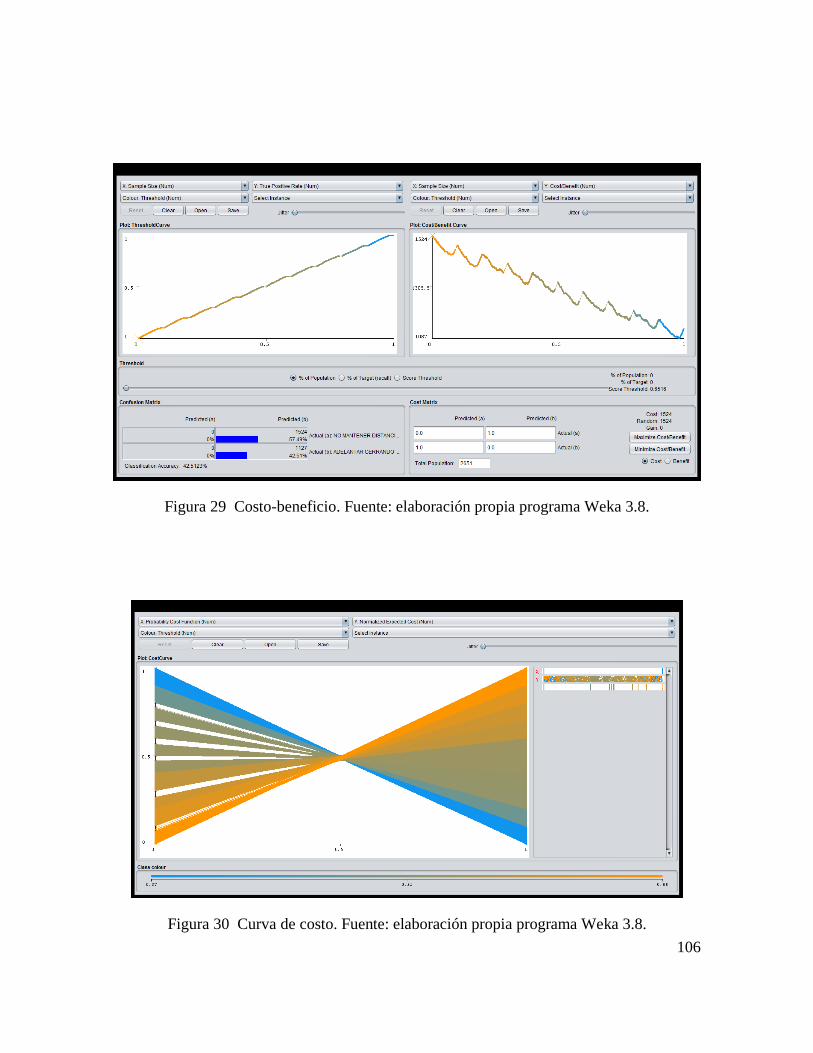
106
Figura 29 Costo-beneficio. Fuente: elaboración propia programa Weka 3.8.
Figura 30 Curva de costo. Fuente: elaboración propia programa Weka 3.8.

107
Como alternativa al modelo de perceptrón multicapas se aplica el modelo de Naive Bayes.
Inicialmente se configura el modelo utilizando el data set minable sin aplicar filtros para
eliminar los valores menos frecuentes. El algoritmo utiliza los 30637 registros de este.
Los resultados de este modelo se presentan en las tablas .
Configuración de algoritmo Naive Bayes.
Figura 30 Parámetros configuración algoritmo Naive Bayes. Fuente: elaboración propia
programa Weka 3.8.
Instancias clasificadas correctamente. La tabla muestra que el número de instancias
clasificadas correctamente fue de 8107 esto indica que el 76.44% se clasificaron de forma
correcta. Hubo 2498 instancias clasificadas incorrectamente.
Al observar el valor del indicador Kappa, es de 0.4817, esto significa que el número de
aciertos es mayor al que se podría obtener aleatoriamente, y aunque está alejado de 1, es un
valor satisfactorio para el algoritmo. Del análisis del error absoluto relativo se observa un
valor de 60.23% que, aunque es alto se puede tomar como aceptable.

108
=== Stratified cross-validation ====== Summary ===
Correctly Classified Instances 8107 76.4451 %
Incorrectly Classified Instances 2498 23.5549 %
Kappa statistic 0.4817
Mean absolute error 0.0181
Root mean squared error 0.1023
Relative absolute error 60.2305 %
Root relative squared error 83.5118 %
Total Number of Instances 10605
En la tabla análisis detallado por clase, se muestran los valores de los indicadores Tasa de
verdaderos positivos, tasa de falsos positivos, recall, precisión, F mesure, área bajo la curva
a R, área PRC. El valor ROC (área bajo la curva R) es de 0,525 en promedio. En esta tabla
se incluyen todos los valores de la variable causa, aunque se mantuvieron solamente los dos
con frecuencias más altas. Por esa razón en la tabla los indicadores figuran con un signo de
interrogación.
El Treshold es el valor a partir del cual se decide que un valor es positivo.
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0,911 0,455 0,750 0,911 0,823 0,502 0,783 0,798 NO MANTENER DISTANCIA DE SEGURIDAD
? 0,000 ? ? ? ? ? ? ADELANTAR CERRANDO
? 0,000 ? ? ? ? ? ? EXCESO DE VELOCIDAD
? 0,000 ? ? ? ? ? ? FRENAR BRUSCAMENTE
? 0,000 ? ? ? ? ? ? CRUZAR SIN OBSERVAR
? 0,000 ? ? ? ? ? ? DESOBEDECER SEムALE
? 0,000 ? ? ? ? ? ? CRUZAR EN ESTADO DE EMBRIAGUEZ
0,545 0,089 0,803 0,545 0,649 0,502 0,783 0,789 OTRA
? 0,000 ? ? ? ? ? ? SEMAFORO EN ROJO

109
? 0,000 ? ? ? ? ? ? ADELANTAR INVADIENDO VIA
? 0,000 ? ? ? ? ? ? TRANSITAR ENTRE VEHICULOS
? 0,000 ? ? ? ? ? ? ADELANTAR POR LA DERECHA
? 0,000 ? ? ? ? ? ? ARRANCAR SIN PRECAUCION
? 0,000 ? ? ? ? ? ? 506 OTRA
? 0,000 ? ? ? ? ? ? ADELANTAR EN ZONA PROHIBIDA
? 0,000 ? ? ? ? ? ? TRANSITAR POR LA CALZADA
? 0,000 ? ? ? ? ? ? REVERSO IMPRUDENTE
? 0,000 ? ? ? ? ? ? EMBRIAGUEZ O DROGA
? 0,000 ? ? ? ? ? ? NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
? 0,000 ? ? ? ? ? ? TRANSITAR EN CONTRAVIA
? 0,000 ? ? ? ? ? ? VEHICULO MAL ESTACIONADO
? 0,000 ? ? ? ? ? ? T RANSITAR POR VIAS PROHIBIDAS
? 0,000 ? ? ? ? ? ? HUECOS
? 0,000 ? ? ? ? ? ? FALLAS EN LOS FRENOS
? 0,000 ? ? ? ? ? ? ADELANTAR INVADIENDO CARRIL DEL MISMO SENTIDO EN ZIG-ZAG
? 0,000 ? ? ? ? ? ? NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
? 0,000 ? ? ? ? ? ? REVERSO IMPRUDENTE
? 0,000 ? ? ? ? ? ? NO MANTENER DISTANCIA DE SEGURIDAD
? 0,000 ? ? ? ? ? ? OTRA
? 0,000 ? ? ? ? ? ? DESOBEDECER SEムALES
? 0,000 ? ? ? ? ? ? FRENAR BRUSCAMENTE
? 0,000 ? ? ? ? ? ? DESOBEDECER SEムALES
Weighted Avg. 0,764 0,308 0,771 0,764 0,753 0,502 0,783 0,794
La tasa de verdaderos positivos que es el mismo recall es en promedio 0,764 que es un valor
adecuado a lo esperado, la tasa de falsos positivos es 0.308, bastante baja, la precisión es
0.771 lo cual indica que del total de términos clasificados, este porcentaje se hizo
correctamente, el treshold es 0.5 , el accuracy es la suma de predicciones verdaderas sobre la
suma de todas las clasificaciones no figura en la tabla , la medida F es 0.753 en promedio,
lo cual significa que la relación entre la tasa de verdaderos positivos y la suma de las
predicciones sin tener en cuenta los verdaderos negativos, es relativamente alta , el área bajo
la curva ROC es 0.783, que es bastante aceptable cercano a 1, el área PRC es 0.794 en
promedio.

110
Análisis de las gráficas.
En las figuras 30 a 34 se presenta en forma gráfica la información más representativa para
evaluar el modelo clasificador.
Análisis de curva margen de predicción (margin curve).
Esta curva representa el margen de predicción, es decir la diferencia entre el valor de
probabilidad para la clase predicha y el valor de la probabilidad más alta para las clases
diferentes a la predicha. Entre más alto sea este valor hay mayor certeza de que la predicción
sea correcta, ya que hay un mayor margen para equivocarse.
Un margen de 1 significa que la confiabilidad de la predicción es del 100% mientras un
margen de -1 significa lo contrario, es decir que la confiabilidad es de predicción de una clase
incorrecta es del 100%. Como el valor mínimo en la gráfica es de -0.33 para la instancia 1, y
comienza a aumentar para las otras instancias, quiere decir que el margen va aumentando a
medida que se aumenta el número de instancias y para 2651 instancias, que son las que se
analizaron es de 0.33 que representa una confiabilidad de 33%, que, aunque no es el valor
óptimo (100%) tampoco es un valor tan bajo. Esto significa que entre mayor sea el número
de instancias analizadas, mayor el valor del margen de predicción y por lo tanto la
confiabilidad de la predicción.
Análisis de curva PRC (Recall-Precisión).
El área bajo la curva RP (recall-precision) es de 0.794 que es un valor alto. Para el sistema
bajo estudio resulta más útil considerar el valor ROC, ya que el RPC se utiliza más cuando
es más importante acertar en una clase que en otras, por ejemplo “buscar una aguja en un
pajar”. En e l caso bajo estudio, si la clase “no respetar distancia de seguridad” fuera más
importante que la clase otras, o la clase adelantar cerrando, ò huecos, sería mejor aplicar la
curva PRC ya que no debería dejarse por fuera del clasificador ningún caso, es decir el
algoritmo clasificador no debería dejar de clasificar correctamente ningún caso de no respetar
distancia de seguridad, pero esta no es la situación bajo estudio.
Análisis de curva de error.
Se muestran las instancias bien clasificadas con una cruz y las mal clasificadas con un
cuadrado, para cada valor del atributo causa. Se observa una mayor cantidad de instancias
bien clasificadas (cruces) para la clase no mantener distancia de seguridad en color azul y
para la clase otra en color rojo.
Análisis de la curva ROC.

111
El área bajo la curva ROC es de 0.783. el rango de valores recomendado para un buen
modelo según y está entre 0.75 y 1. En este caso el valor está por encima de 0.75. Esto
significa que puede clasificar correctamente los verdaderos positivos y los verdaderos
negativos. La forma de la curva ROC está dentro de las que son aceptables. Este valor es
mayor al encontrado en el perceptrón multicapas.
Análisis de la curva costo.
Se puede observar que la envolvente inferior tiene el punto más bajo en aproximadamente
0.3 que corresponde al máximo costo esperado y es sensiblemente menor que el encontrado
para el perceptrón multicapas. Des de este punto de vista este algoritmo es más adecuado
para la clasificación de las causas de accidentes.

112
=== Confusion Matrix ===
a b c d e f g h i j k l m n o p q r s t u v w x y z aa ab ac ad ae af <-- classified as
5793 0 0 0 0 0 0 566 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | a = NO MANTENER DISTANCIA DE SEGURIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | b = ADELANTAR CERRANDO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | c = EXCESO DE VELOCIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | d = FRENAR BRUSCAMENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | e = CRUZAR SIN OBSERVAR
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | f = DESOBEDECER SEÑALES
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | g = CRUZAR EN ESTADO DE EMBRIAGUEZ
1932 0 0 0 0 0 0 2314 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | h = OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | i = SEMAFORO EN ROJO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | j = ADELANTAR INVADIENDO VIA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | k = TRANSITAR ENTRE VEHICULOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | l = ADELANTAR POR LA DERECHA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | m = ARRANCAR SIN PRECAUCION
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | n = 506 OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | o = ADELANTAR EN ZONA PROHIBIDA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | p = TRANSITAR POR LA CALZADA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | q = REVERSO IMPRUDENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | r = EMBRIAGUEZ O DROGA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | s = NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | t = TRANSITAR EN CONTRAVIA

113
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | u = VEHICULO MAL ESTACIONADO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | v = TRANSITAR POR VIAS PROHIBIDAS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | w = HUECOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | x = FALLAS EN LOS FRENOS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | y = ADELANTAR INVADIENDO CARRIL DEL MISMO SENTIDO EN
ZIG-ZAG
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | z = NO RESPETAR PRELACION DE INTERSECCIONES O GIROS
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | aa = REVERSO IMPRUDENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ab = NO MANTENER DISTANCIA DE SEGURIDAD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ac = OTRA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ad = DESOBEDECER SEÑALES
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ae = FRENAR BRUSCAMENTE
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | af = DESOBEDECER SEÑALES
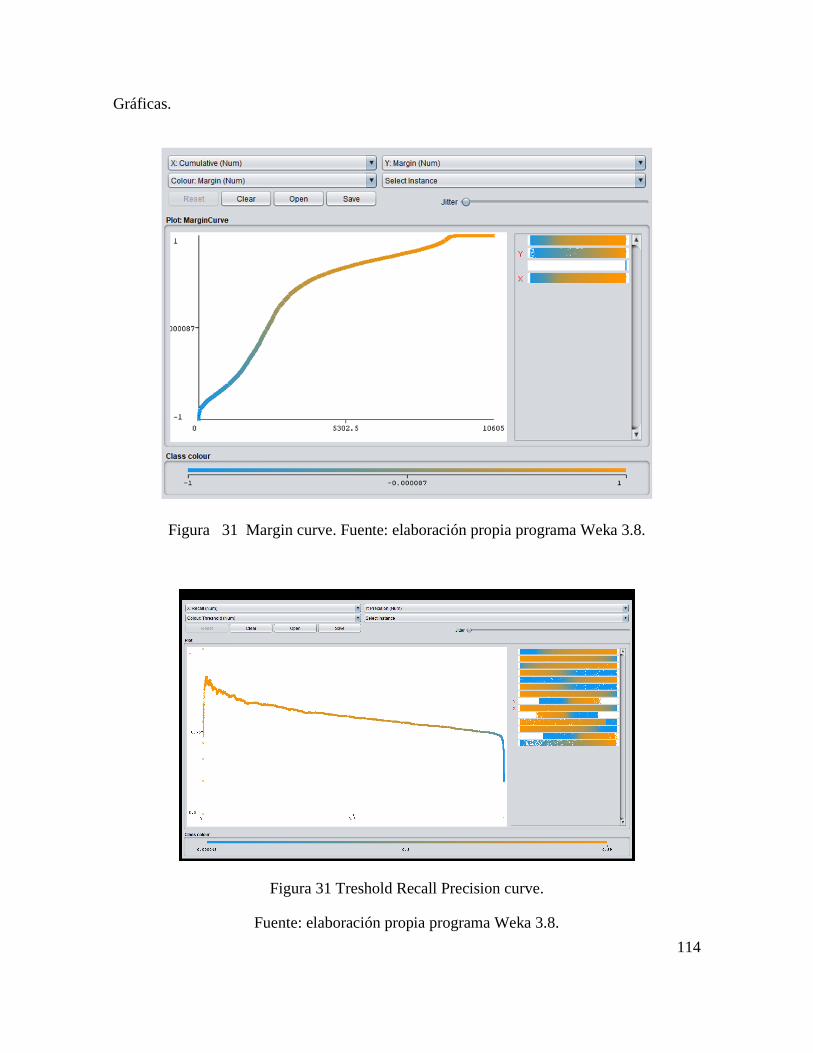
114
Gráficas.
Figura 31 Margin curve. Fuente: elaboración propia programa Weka 3.8.
Figura 31 Treshold Recall Precision curve.
Fuente: elaboración propia programa Weka 3.8.
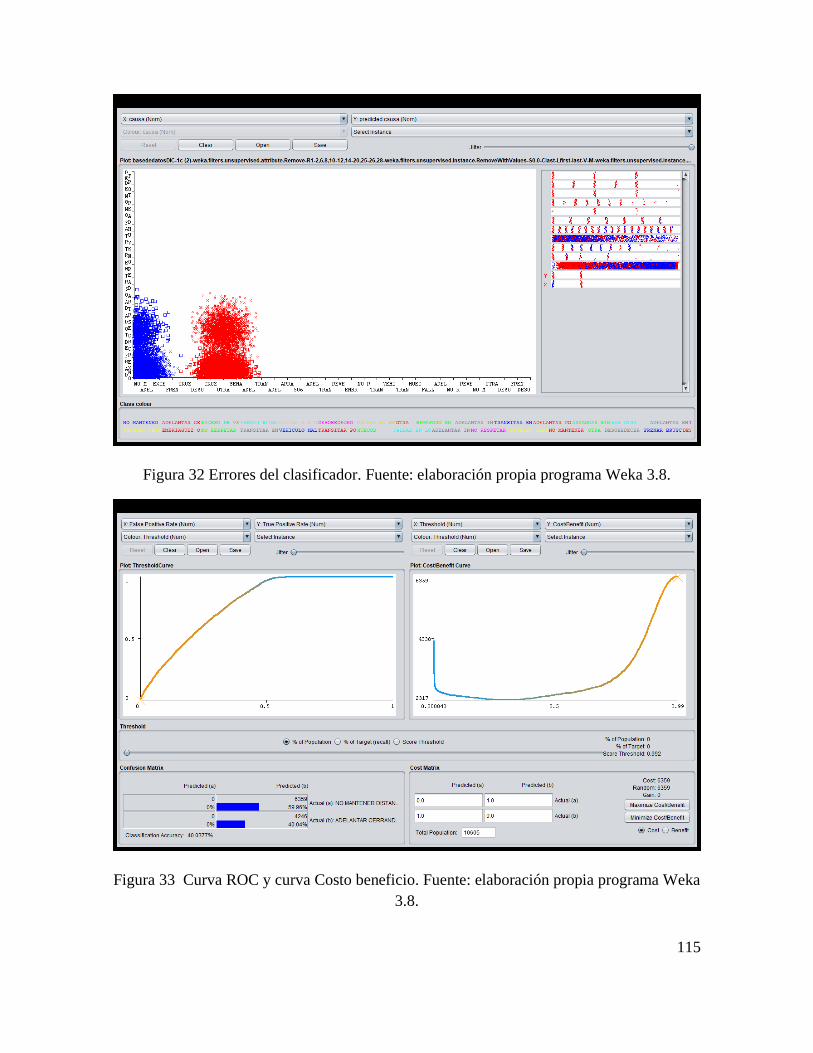
115
Figura 32 Errores del clasificador. Fuente: elaboración propia programa Weka 3.8.
Figura 33 Curva ROC y curva Costo beneficio. Fuente: elaboración propia programa Weka
3.8.
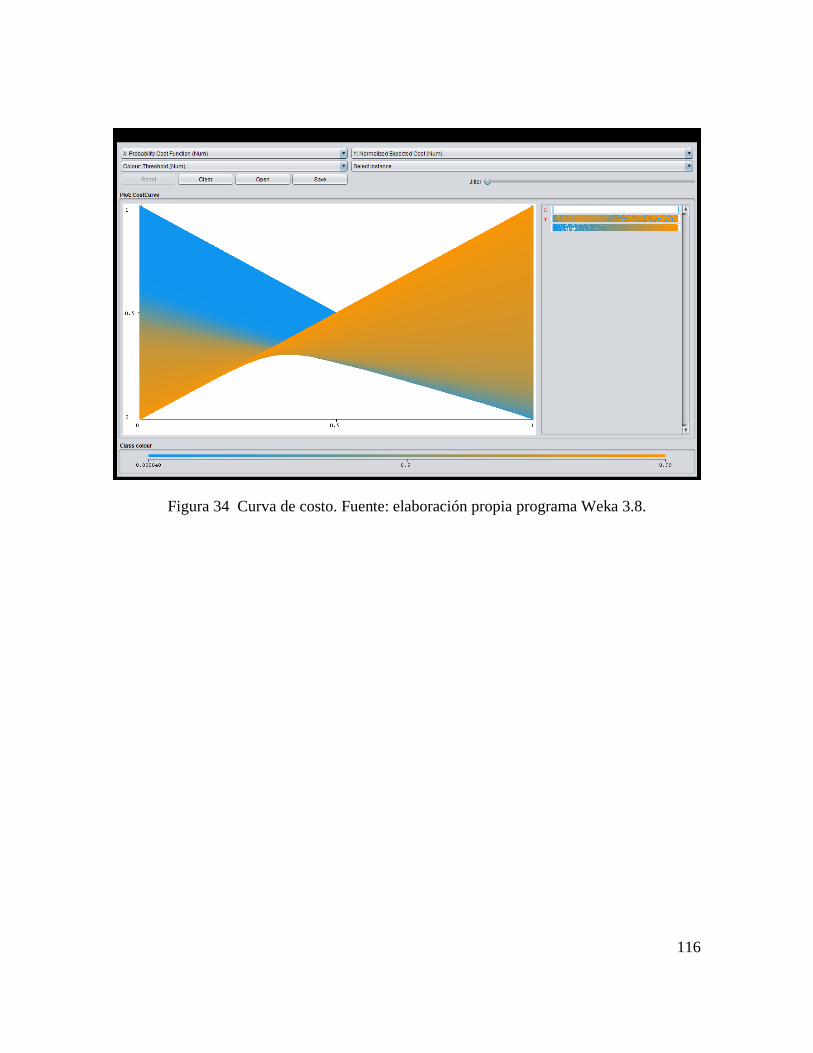
116
Figura 34 Curva de costo. Fuente: elaboración propia programa Weka 3.8.

117

118
Para aproximar la causa de un accidente con datos nuevos, o sea que no están en la base de
datos minable, se construye una plantilla para ingresar los datos, se carga el modelo ajustado
y se aplica a los nuevos datos.
En la tabla se muestran los nuevos datos para realizar la predicción. Se trata de cinco casos a
los cuales se les han asignado valores arbitrariamente.
Accidente,Fecha,GravedadNombre,ClaseNombre,ChoqueNombre,ObjetoFijoCodigo,ObjetoFijoNombre,OtraClase,NombreOtraClase,Latitud,Longitud,Direccion,TipoVia1,NumeroVia1,LetraVia1,CardinalVia1,TipoVia2,NumeroVia2,LetraVia2,CardinalVia2,Localidad,HoraOcurrencia,TipoDiseño,TipoTiempo,TotalMuertos,TotalHeridos,causa,NO
5.433.429,10/08/2018 0:00,Solo Daños,Choque,Objeto Fijo, , , , ,0,0,CL 32-KR 19 28,KR,13, , ,KR,19, , ,KENNEDY,10/20/22016 01:10:00 AM,Tramo Via,Normal,0,0,? ,
5.433.430,11/09/2018 0:00,Con Heridos,Atropello,Vehiculo, , , , ,0,0,CL 23-KR 67 28,CL,13, , ,KR,67, , ,FONTIBON,10/20/22016 01:10:00 AM,Interseccion,Lluvia,0,0,? ,
5.433.431,14/10/2018 0:00,Solo Daños,Choque,Vehiculo, , , , ,0,0,AV 72-KR 19 14,AV,13, , ,KR,72, , ,SUBA,10/20/22016 01:10:00 AM,Glorieta,Viento,0,0,? ,
5.433.432,17/10/2018 0:00,Con Heridos,Choque,Semoviente, , , , ,0,0,CL 68-KR 67 12,CL,13, , ,KR,72, , ,USME,10/20/22016 01:10:00 AM,Puente,Niebla,0,0,? ,
5.433.433,11/11/2018 0:00,Solo Daños,Atropello,Vehiculo, , , , ,0,0,CL 23-KR 67 28,CL,13, , ,KR,72, , ,RAFEL URIBE URIBE,10/20/22016 01:10:00 AM,Tramo Via,Normal,0,0,? ,
A continuación, se presentan los resultados de la clasificación para los dos algoritmos
considerados; en primer lugar, el perceptrón multicapas y en segundo lugar Naive Bayes.
Clasificación utilizando el algoritmo Perceptrón multicapas.
Se puede apreciar que para todos los cinco casos nuevos la clase asignada como causa de
falla es NO MANTENER DISTANCIA DE SEGURIDAD. El menor error se presenta para
el caso número 2 con 0.585.
=== Model information ===
Filename: mlpdic2.model
Scheme: weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S
0 -E 20 -H 1
Relation: basededatosDIC-1c (2)-weka.filters.unsupervised.attribute.Remove-R1-
2,6,8,10-12,14-20,25-26,28-weka.filters.unsupervised.instance.RemoveWithValues-S0.0-
Clast-Lfirst-last-V-M-weka.filters.unsupervised.instance.RemoveDuplicates-
weka.filters.unsupervised.instance.RemoveDuplicates-

119
weka.filters.unsupervised.instance.RemoveFrequentValues-Clast-N2-
weka.filters.unsupervised.instance.RemovePercentage-P50.0-
weka.filters.unsupervised.instance.RemovePercentage-P50.0
Attributes: 11
GravedadNombre
ClaseNombre
ChoqueNombre
ObjetoFijoNombre
NombreOtraClase
TipoVia1
Localidad
HoraOcurrencia
TipoDiseño
TipoTiempo
causa
=== Re-evaluation on test set ===
User supplied test set
Relation: plantillaDIC-5
Instances: unknown (yet). Reading incrementally
Attributes: 28
=== Predictions on user test set ===
inst# actual predicted error prediction

120
1 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.827
2 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.585
3 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.844
4 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.594
5 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.841
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 5
Clasificación utilizando el algoritmo Naive Bayes.
Se muestra la salida del programa con las clases asignadas a cada caso. Para el primero se
asigna la clase OTRA con un error de 0.028, la clase asignada al caso 4 es ADELANTAR
CERRANDO y tiene el menor error de predicción con0.033.
=== Model information ===
Filename: nbdic3-31.model
Scheme: weka.classifiers.bayes.NaiveBayes
Relation: basededatosDIC-1c (2)-weka.filters.unsupervised.attribute.Remove-R1-
2,6,8,10-12,14-20,25-26,28-weka.filters.unsupervised.instance.RemoveWithValues-S0.0-
Clast-Lfirst-last-V-M-weka.filters.unsupervised.instance.RemoveDuplicates-
weka.filters.unsupervised.instance.RemoveFrequentValues-Clast-N3-
weka.filters.unsupervised.instance.RemoveDuplicates-
weka.filters.unsupervised.instance.RemoveFrequentValues-Clast-N2
Attributes: 11
GravedadNombre
ClaseNombre

121
ChoqueNombre
ObjetoFijoNombre
NombreOtraClase
TipoVia1
Localidad
HoraOcurrencia
TipoDiseño
TipoTiempo
causa
=== Classifier model ===
Naive Bayes Classifier
=== Re-evaluation on test set ===
User supplied test set
Relation: plantillaDIC-5
Instances: unknown (yet). Reading incrementally
Attributes: 28
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 8:OTRA 0.928
2 1:? 8:OTRA 0.997
3 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.949
4 1:? 2:ADELANTAR CERRANDO 0.033
5 1:? 8:OTRA 0.99
=== Summary ===

122
Total Number of Instances 0
Ignored Class Unknown Instances 5
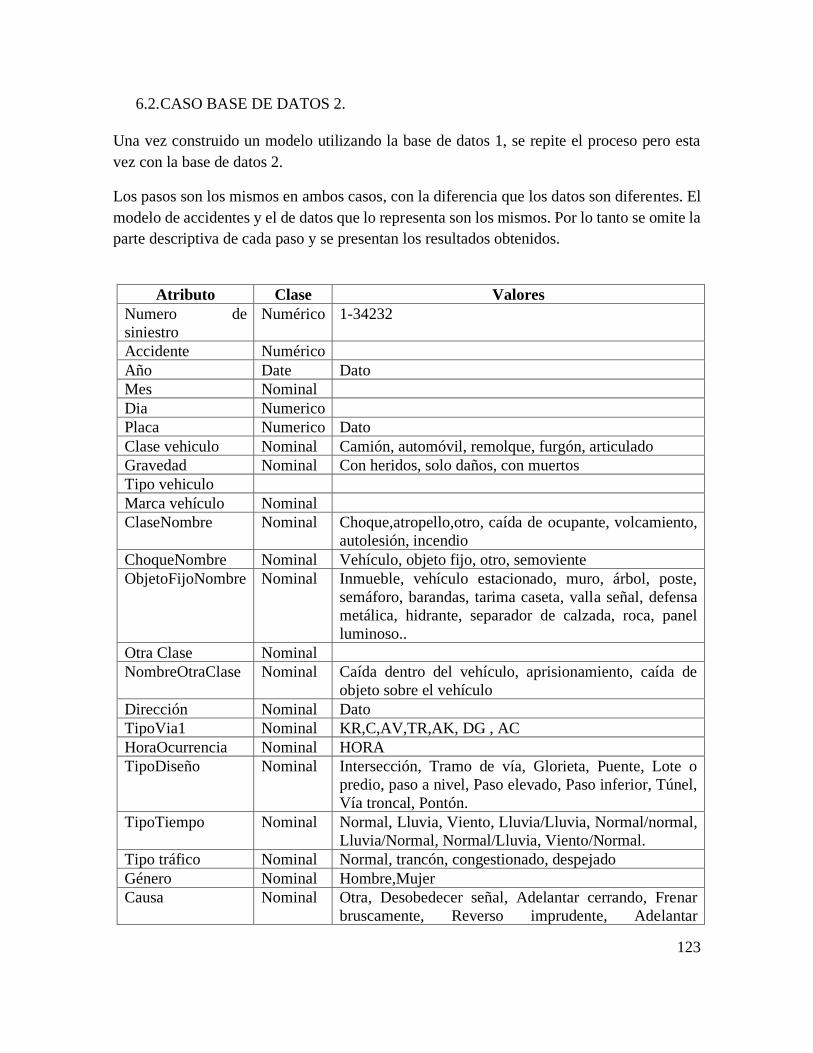
123
6.2. CASO BASE DE DATOS 2.
Una vez construido un modelo utilizando la base de datos 1, se repite el proceso pero esta
vez con la base de datos 2.
Los pasos son los mismos en ambos casos, con la diferencia que los datos son diferentes. El
modelo de accidentes y el de datos que lo representa son los mismos. Por lo tanto se omite la
parte descriptiva de cada paso y se presentan los resultados obtenidos.
Atributo Clase Valores
Numero de
siniestro
Numérico 1-34232
Accidente Numérico
Año Date Dato
Mes Nominal
Dia Numerico
Placa Numerico Dato
Clase vehiculo Nominal Camión, automóvil, remolque, furgón, articulado
Gravedad Nominal Con heridos, solo daños, con muertos
Tipo vehiculo
Marca vehículo Nominal
ClaseNombre Nominal Choque,atropello,otro, caída de ocupante, volcamiento,
autolesión, incendio
ChoqueNombre Nominal Vehículo, objeto fijo, otro, semoviente
ObjetoFijoNombre Nominal Inmueble, vehículo estacionado, muro, árbol, poste,
semáforo, barandas, tarima caseta, valla señal, defensa
metálica, hidrante, separador de calzada, roca, panel
luminoso..
Otra Clase Nominal
NombreOtraClase Nominal Caída dentro del vehículo, aprisionamiento, caída de
objeto sobre el vehículo
Dirección Nominal Dato
TipoVia1 Nominal KR,C,AV,TR,AK, DG , AC
HoraOcurrencia Nominal HORA
TipoDiseño Nominal Intersección, Tramo de vía, Glorieta, Puente, Lote o
predio, paso a nivel, Paso elevado, Paso inferior, Túnel,
Vía troncal, Pontón.
TipoTiempo Nominal Normal, Lluvia, Viento, Lluvia/Lluvia, Normal/normal,
Lluvia/Normal, Normal/Lluvia, Viento/Normal.
Tipo tráfico Nominal Normal, trancón, congestionado, despejado
Género Nominal Hombre,Mujer
Causa Nominal Otra, Desobedecer señal, Adelantar cerrando, Frenar
bruscamente, Reverso imprudente, Adelantar
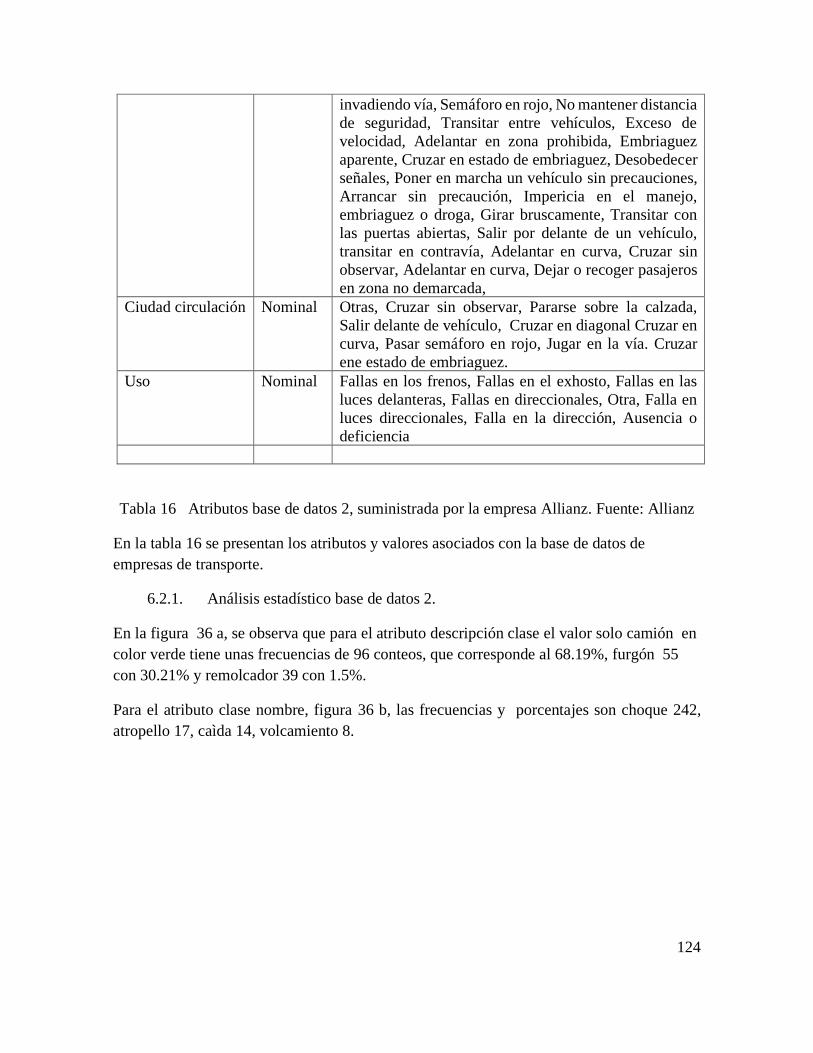
124
invadiendo vía, Semáforo en rojo, No mantener distancia
de seguridad, Transitar entre vehículos, Exceso de
velocidad, Adelantar en zona prohibida, Embriaguez
aparente, Cruzar en estado de embriaguez, Desobedecer
señales, Poner en marcha un vehículo sin precauciones,
Arrancar sin precaución, Impericia en el manejo,
embriaguez o droga, Girar bruscamente, Transitar con
las puertas abiertas, Salir por delante de un vehículo,
transitar en contravía, Adelantar en curva, Cruzar sin
observar, Adelantar en curva, Dejar o recoger pasajeros
en zona no demarcada,
Ciudad circulación Nominal Otras, Cruzar sin observar, Pararse sobre la calzada,
Salir delante de vehículo, Cruzar en diagonal Cruzar en
curva, Pasar semáforo en rojo, Jugar en la vía. Cruzar
ene estado de embriaguez.
Uso Nominal Fallas en los frenos, Fallas en el exhosto, Fallas en las
luces delanteras, Fallas en direccionales, Otra, Falla en
luces direccionales, Falla en la dirección, Ausencia o
deficiencia
Tabla 16 Atributos base de datos 2, suministrada por la empresa Allianz. Fuente: Allianz
En la tabla 16 se presentan los atributos y valores asociados con la base de datos de
empresas de transporte.
6.2.1. Análisis estadístico base de datos 2.
En la figura 36 a, se observa que para el atributo descripción clase el valor solo camión en
color verde tiene unas frecuencias de 96 conteos, que corresponde al 68.19%, furgón 55
con 30.21% y remolcador 39 con 1.5%.
Para el atributo clase nombre, figura 36 b, las frecuencias y porcentajes son choque 242,
atropello 17, caìda 14, volcamiento 8.
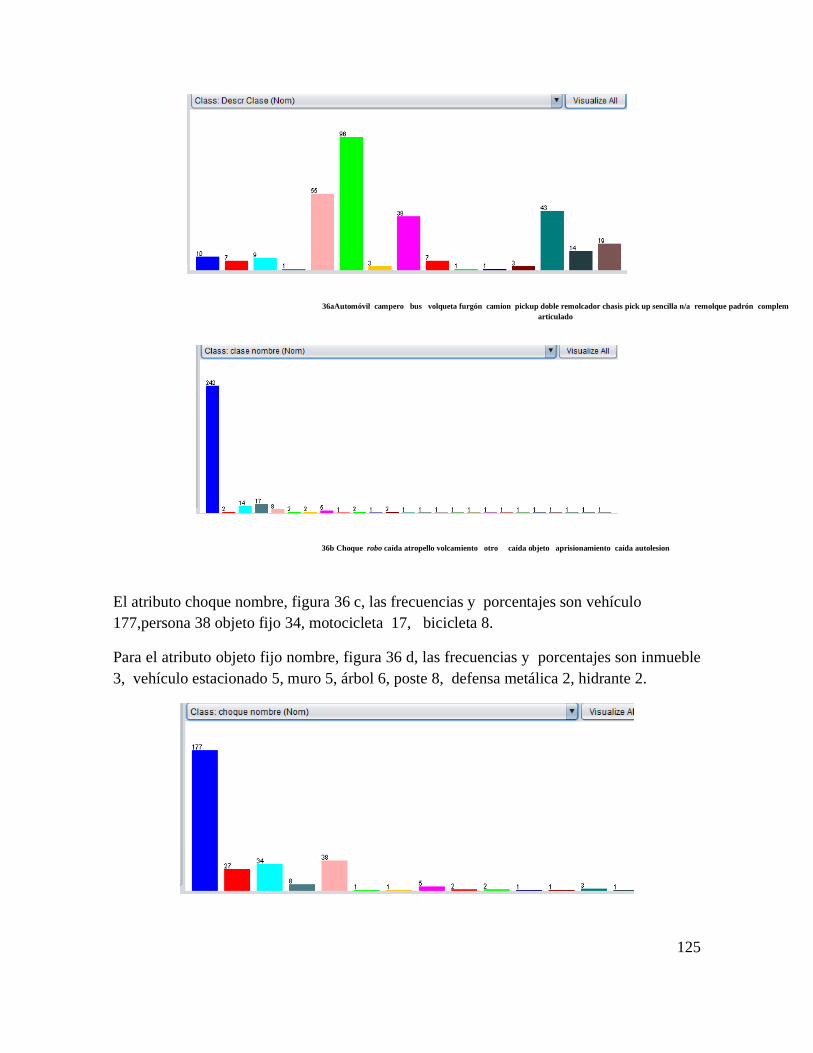
125
El atributo choque nombre, figura 36 c, las frecuencias y porcentajes son vehículo
177,persona 38 objeto fijo 34, motocicleta 17, bicicleta 8.
Para el atributo objeto fijo nombre, figura 36 d, las frecuencias y porcentajes son inmueble
3, vehículo estacionado 5, muro 5, árbol 6, poste 8, defensa metálica 2, hidrante 2.
36aAutomóvil campero bus volqueta furgón camion pickup doble remolcador chasis pick up sencilla n/a remolque padrón complem
articulado
36b Choque robo caída atropello volcamiento otro caída objeto aprisionamiento caída autolesion
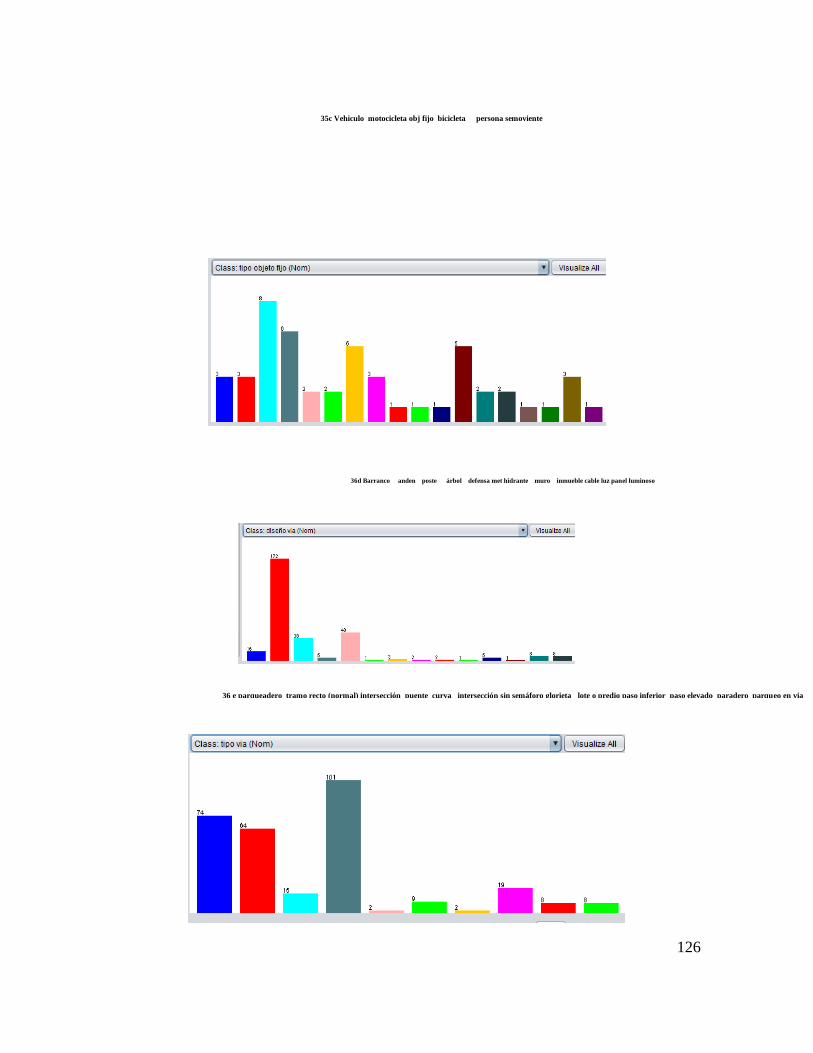
126
35c Vehiculo motocicleta obj fijo bicicleta persona semoviente
36 e parqueadero tramo recto (normal) intersección puente curva intersección sin semáforo glorieta lote o predio paso inferior paso elevado paradero parqueo en via
36d Barranco anden poste árbol defensa met hidrante muro inmueble cable luz panel luminoso
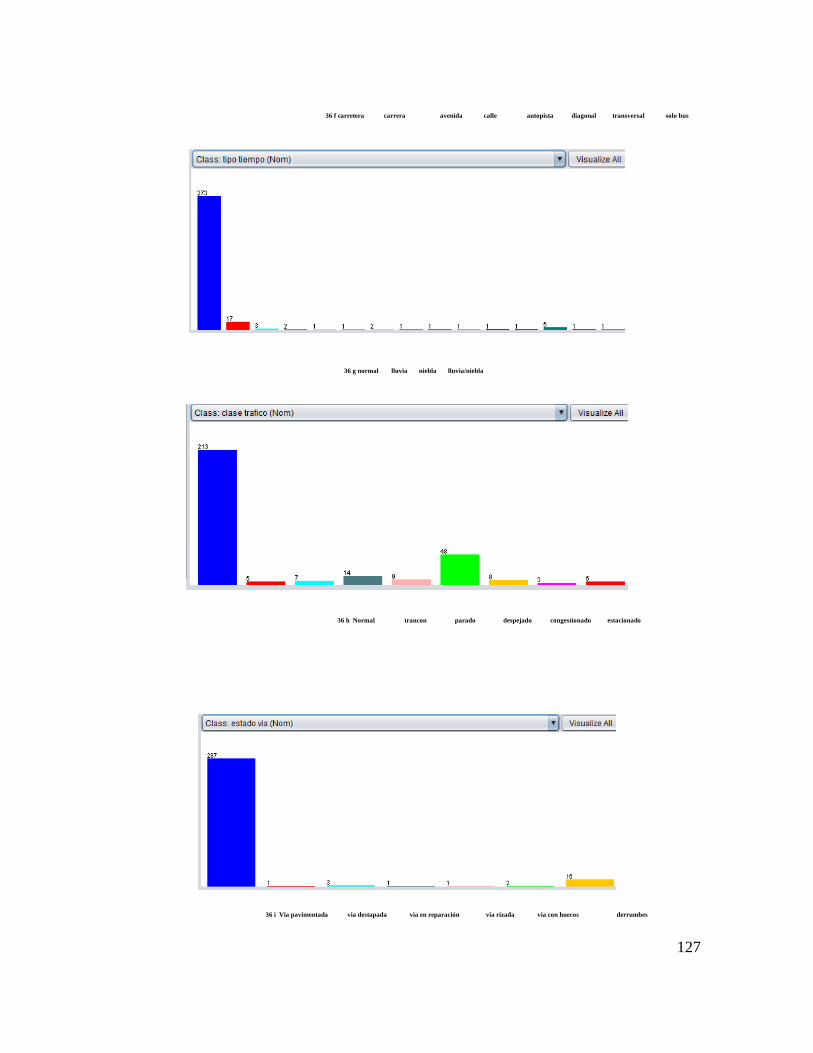
127
36 f carretera carrera avenida calle autopista diagonal transversal solo bus
36 g normal lluvia niebla lluvia/niebla
36 h Normal trancon parado despejado congestionado estacionado
36 i Via pavimentada via destapada via en reparación via rizada via con huecos derrumbes
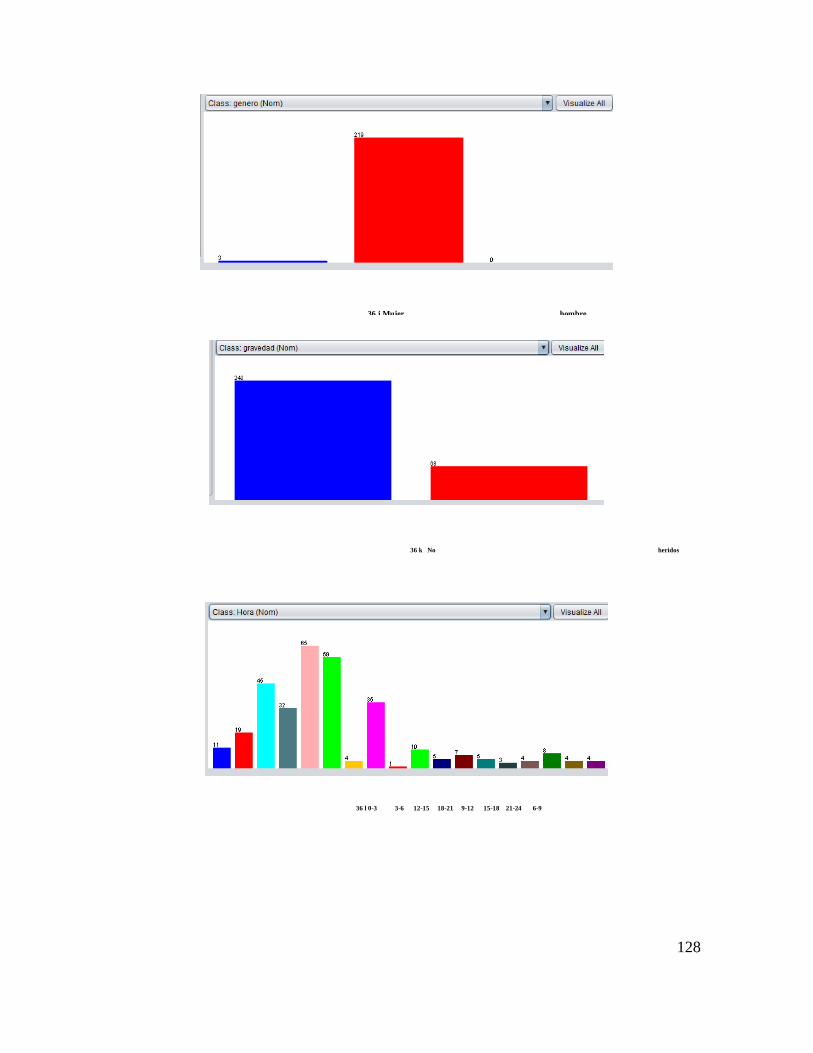
128
36 j Mujer hombre
36 k No heridos
36 l 0-3 3-6 12-15 18-21 9-12 15-18 21-24 6-9
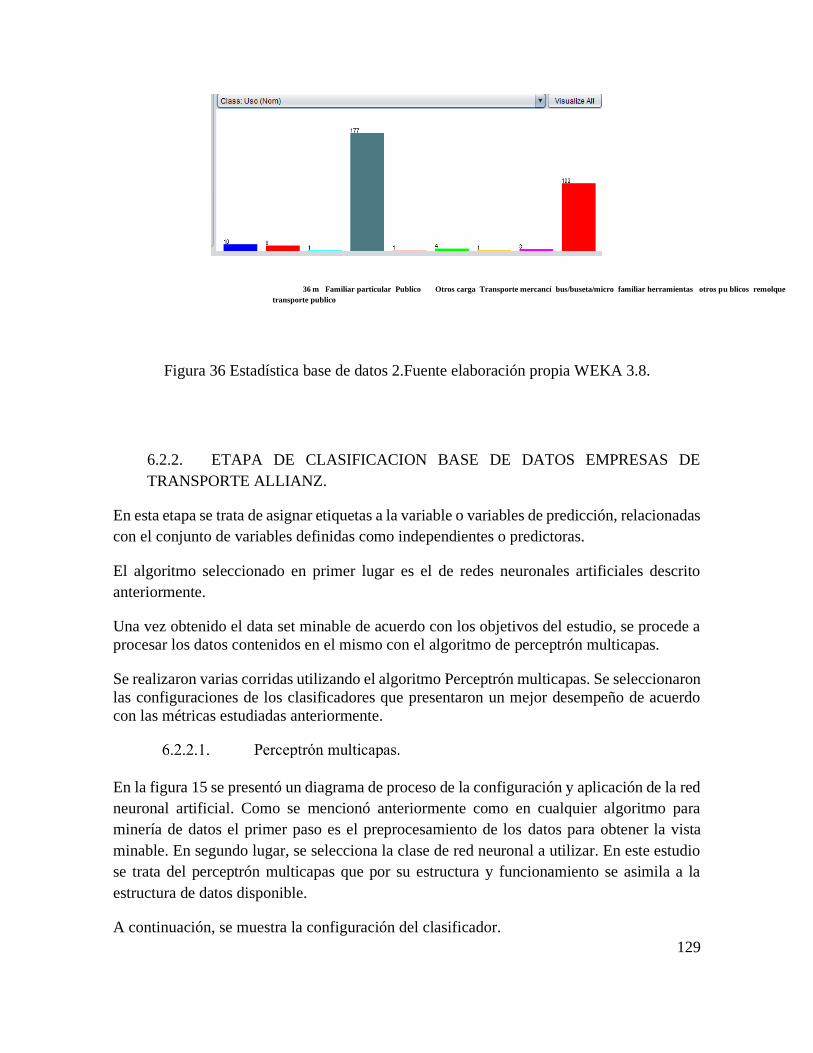
129
Figura 36 Estadística base de datos 2.Fuente elaboración propia WEKA 3.8.
6.2.2. ETAPA DE CLASIFICACION BASE DE DATOS EMPRESAS DE
TRANSPORTE ALLIANZ.
En esta etapa se trata de asignar etiquetas a la variable o variables de predicción, relacionadas
con el conjunto de variables definidas como independientes o predictoras.
El algoritmo seleccionado en primer lugar es el de redes neuronales artificiales descrito
anteriormente.
Una vez obtenido el data set minable de acuerdo con los objetivos del estudio, se procede a
procesar los datos contenidos en el mismo con el algoritmo de perceptrón multicapas.
Se realizaron varias corridas utilizando el algoritmo Perceptrón multicapas. Se seleccionaron
las configuraciones de los clasificadores que presentaron un mejor desempeño de acuerdo
con las métricas estudiadas anteriormente.
En la figura 15 se presentó un diagrama de proceso de la configuración y aplicación de la red
neuronal artificial. Como se mencionó anteriormente como en cualquier algoritmo para
minería de datos el primer paso es el preprocesamiento de los datos para obtener la vista
minable. En segundo lugar, se selecciona la clase de red neuronal a utilizar. En este estudio
se trata del perceptrón multicapas que por su estructura y funcionamiento se asimila a la
estructura de datos disponible.
A continuación, se muestra la configuración del clasificador.
36 m Familiar particular Publico Otros carga Transporte mercancí bus/buseta/micro familiar herramientas otros pu blicos remolque
transporte publico

130
El número de capas ocultas es a, que es igual a:
Número de atributos + número de clases /2 = 11+2/2 = 6.5 aproximadamente 7 capas ocultas.
La tasa de aprendizaje es de 0.3, teniendo en cuenta que el valor no debe de ser muy pequeño
porque el algoritmo se demora más ni muy grande porque puede saltar el valor óptimo que
busca.
El momentum es de 0,2.
Entre los métodos utilizados por el programa para aumentar la precisión del clasificador
están:
Selección de atributos.
Ranker.
Aplicación de filtros-
Aplicación de envoltorios (wrapper).
Selección con principal componente análisis.
El entrenamiento de la red se realizó utilizando el data set minable y el procedimiento
descrito en la sección 5.4.3.1.1.
Durante esta fase, y dependiendo de las características del dataset como ruido, pequeño
número de datos y del clasificador como su complejidad, se pueden presentar algunas
situaciones que disminuyen el rendimiento de la red. cuando las clases están desbalanceadas,
es decir según Singh Maninder existen diferencias apreciables entre el número de instancias
negativas y positivas, especialmente cuando las negativas sobrepasan a las positivas. Estas
pueden ser;
Sobre aprendizaje y sub-aprendizaje.
La sobre adaptación o sobre aprendizaje puede ocurrir cuando el clasificador obtiene un alto
porcentaje de aciertos en entrenamiento, pero pequeño en test, aprende los datos de memoria
y no generaliza. Den la validación cruzada se obtienen porcentajes cercanos al azar, es decir
la índice kappa es cercano a cero. De otro lado si la complejidad del clasificador no es
suficiente de acuerdo con el problema, se produce su adaptación.

131
Para determinar la bondad del proceso de clasificación se utiliza la validación del modelo,
el cual trata de determinar la capacidad de predicción del clasificador. Para ello se utilizan
las métricas y criterios presentados en la sección 5.4.3.1.2. esta actividad es realizada por el
programa Weka, se acuerdo con las opciones y los resultados presentados en la hoja para el
efecto.
Después de correr el programa con la configuración seleccionada del clasificador, en este
caso el perceptrón multicapas, se obtienen los resultados en forma de tablas y gráficas que
resumen las características de desempeño del modelo de acuerdo con las métricas
seleccionadas.
Los resultados obtenidos en Weka se presentan en cuatro bloques de información;
• Resumen.
• Precisión detallada por clase.
• Matriz de confusión.
Gráficas.
Instancias clasificadas correctamente.
La tabla muestra que el número de instancias clasificadas correctamente fue de 129 esto indica que
el 68.2% se clasificaron de forma correcta. Hubo 48 instancias clasificadas incorrectamente.
Al observar el valor del indicador Kappa, es mayor de 0 ( 0,543), esto significa que el número de
aciertos es mayor al que se podría obtener aleatoriamente, lo cual significa un buen resultado para el
algoritmo. Del análisis del error absoluto relativo se observa un valor de 45,66% que no es muy alto.

132
Figura 37 Configuración del perceptrón multicapas utilizado en la fase de clasificación de
causa de accidente. Fuente: elaboración propia programa Weka 3.8.
=== Stratified cross-validation ====== Summary ===
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 129 72.8814 %
Incorrectly Classified Instances 48 27.1186 %
Kappa statistic 0.5437
Mean absolute error 0.0118
Root mean squared error 0.0952
Relative absolute error 39.2143 %
Root relative squared error 81.4138 %
Total Number of Instances 177
Tabla Resumen métricas Perceptron multicapas. Fuente; elaboración propia WEKA 3.8.

133
En la tabla análisis detallado por clase, se muestran los valores de los indicadores Tasa de
verdaderos positivos 0.0 que es un valor adecuado a lo esperado,729 , tasa de falsos positivos
0.093 bastante baja, recall 0.729, F mesure 0,925, área bajo la curva ROC 0.918 en promedio
cercano a 1, área PRC 0.739. En esta tabla se incluyen todos los valores de la variable causa,
aunque se mantuvieron solamente los dos con frecuencias más altas. Por esa razón en la tabla
los indicadores figuran con un signo de interrogación. El treshold es 0.5 , el accuracy es la
suma de predicciones verdaderas sobre la suma de todas las clasificaciones no figura en la
tabla , la medida F es 0.753 en promedio,
El valor de recall o cobertura indica que el 72.9% de las instancias han sido clasificadas
correctamente.
La precisión indica que del total de términos clasificados, este porcentaje se hizo
correctamente no está definida.
Para el indicador F no figura el promedio, sin embargo, para la clase mayoritaria reversa imprudente,
su valor es de 0.943 los cual significa que este valor es 0,925 lo cual significa que la relación entre
la tasa de verdaderos positivos y la suma de las predicciones sin tener en cuenta los verdaderos
negativos, es relativamente alta, es decir la media armónica de la precisión y la cobertura.
En la tabla 18 se presenta la matriz de confusión, que muestra 99 aciertos para la clase
reversa sin precaución, y 44 aciertos para la segunda clase que es no mantener distancia de
seguridad. .
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
? 0,000 ? ? ? ? ? ? conducir sin precaución
? 0,000 ? ? ? ? ? ? Invasión de carril
? 0,000 ? ? ? ? ? ? Hurto en parquedero
? 0,000 ? ? ? ? ? ? impericia
? 0,000 ? ? ? ? ? ? no mantener distancia de
seguridad
? 0,000 ? ? ? ? ? ? adelantamiento
? 0,000 ? ? ? ? ? ? Descuido conductores
0,000 0,006 0,000 0,000 0,000 -0,006 0,523 0,012 Falla Mécanica
0,000 0,000 ? 0,000 ? ? 0,906 0,243 Distancia Incadecuada
0,000 0,000 ? 0,000 ? ? 0,040 0,006 Exceso de Velocidad
? 0,000 ? ? ? ? ? ? Cruce imprudente
? 0,000 ? ? ? ? ? ? Imprudencia
134
0,000 0,000 ? 0,000 ? ? 0,769 0,212 impericia
0,609 0,104 0,467 0,609 0,528 0,452 0,893 0,496 conducir sin precaucion
0,000 0,006 0,000 0,000 0,000 -0,014 0,888 0,226 invadir carril
0,625 0,144 0,405 0,625 0,492 0,405 0,885 0,436 no mantener distancia de
seguridad
0,000 0,000 ? 0,000 ? ? 0,534 0,012 semoviente en la via
0,971 0,108 0,926 0,971 0,948 0,873 0,978 0,987 reversa sin precaucion
0,000 0,000 ? 0,000 ? ? 0,880 0,079 desacato normas
0,000 0,000 ? 0,000 ? ? 0,589 0,020 ASEGURADO
0,000 0,000 ? 0,000 ? ? 0,714 0,029 Sin determinar
? 0,000 ? ? ? ? ? ? adelantar en curva
? 0,000 ? ? ? ? ? ? microsueño
? 0,000 ? ? ? ? ? ? DAÑO CONTRA ARBOL
? 0,000 ? ? ? ? ? ? llanta pinchada
? 0,000 ? ? ? ? ? ? sobrepaso sin precaucion
? 0,000 ? ? ? ? ? ? cruzar semaforo en rojo
0,000 0,000 ? 0,000 ? ? 0,525 0,031 girar sin precaucion
? 0,000 ? ? ? ? ? ? NO SE ASEGURA BIEN LA CARGA
-REVISAR AMARRES
? 0,000 ? ? ? ? ? ? CONFIRMACION PTD
? 0,000 ? ? ? ? ? ? CODIFICACION 103 SEGÚN
CROQUIS Y PARA EL TERCERO 102
? 0,000 ? ? ? ? ? ? giro prohibido
? 0,000 ? ? ? ? ? ? adelantar cerrando
? 0,000 ? ? ? ? ? ? frenar bruscamente
? 0,000 ? ? ? ? ? ? desobedecer señales
? 0,000 ? ? ? ? ? ? cierre de puertas
? 0,000 ? ? ? ? ? ? DAÑOS DE LA NATURALEZA
? 0,000 ? ? ? ? ? ? adelantar invadiendo carril
? 0,000 ? ? ? ? ? ? cruzar sin observar
? 0,000 ? ? ? ? ? ? PADRON
? 0,000 ? ? ? ? ? ? embriaguez evidente
? 0,000 ? ? ? ? ? ? ARTICULADO
? 0,000 ? ? ? ? ? ? COMPLEMENTARIO
? 0,000 ? ? ? ? ? ? MPRUDENCIA DEL ASEGURADO
? 0,000 ? ? ? ? ? ? DESCUIDO CONTRARIO

135
? 0,000 ? ? ? ? ? ? HURTO PARQUEADERO
? 0,000 ? ? ? ? ? ? HURTO EN LA VIA
Weighted Avg. 0,729 0,096 ? 0,729 ? ? 0,915 0,718
Tabla 18 resumen de resultados weka. Algoritmo perceptrón multicapas. Fuente: elaboración propia programa Weka 3.8.
=== Confusion Matrix ===
a b c d e f g h i j k l m n o p q r s t u v w x y z aa ab ac ad ae af ag ah ai aj ak al am an ao ap aq ar as at au <-- classified as
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | a = conducir sin
precaución
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | b = Invasión de carril
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | c = Hurto en parquedero
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | d = impericia
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | e = no mantener
distancia de seguridad
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | f = adelantamiento
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | g = Descuido
conductores
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | h = Falla Mécanica
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | i = Distancia
Incadecuada
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | j = Exceso de Velocidad
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | k = Cruce imprudente
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | l = Imprudencia
0 0 0 0 0 0 0 0 1 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | m = impericia
0 0 0 0 0 0 0 0 1 0 0 0 0 12 0 6 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | n = conducir sin
precaucion
0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | o = invadir carril

136
0 0 0 0 0 0 0 0 0 1 0 0 0 6 2 14 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | p = no mantener
distancia de seguridad
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | q = semoviente en la
via
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 100 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | r = reversa sin
precaucion
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | s = desacato normas
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | t = ASEGURADO
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | u = Sin determinar
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | v = adelantar en curva
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | w = microsueño
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | x = DAÑO CONTRA ARBOL
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | y = llanta pinchada
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | z = sobrepaso sin
precaucion
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | aa = cruzar semaforo en
rojo
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ab = girar sin
precaucion
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ac = NO SE ASEGURA BIEN
LA CARGA -REVISAR AMARRES
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ad = CONFIRMACION PTD
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ae = CODIFICACION 103
SEGÚN CROQUIS Y PARA EL TERCERO 102
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | af = giro prohibido
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ag = adelantar cerrando
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ah = frenar bruscamente
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ai = desobedecer señales
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | aj = cierre de puertas
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ak = DAÑOS DE LA
NATURALEZA
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | al = adelantar
invadiendo carril
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | am = cruzar sin observar
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | an = PADRON

137
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ao = embriaguez evidente
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ap = ARTICULADO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | aq = COMPLEMENTARIO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | ar = MPRUDENCIA DEL
ASEGURADO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | as = DESCUIDO CONTRARIO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | at = HURTO PARQUEADERO
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | au = HURTO EN LA VIA
Tabla 19 Matriz de confusión modelo perceptrón multicapa

138
Análisis de las gráficas.
En las figuras 30 a 34 se presenta en forma gráfica la información más representativa para
evaluar el modelo clasificador.
Análisis de curva margen de predicción (margin curve).
Esta curva representa el margen de predicción, es decir la diferencia entre el valor de
probabilidad para la clase predicha y el valor de la probabilidad más alta para las clases
diferentes a la predicha. Entre más alto sea este valor hay mayor certeza de que la predicción
sea correcta, ya que hay un mayor margen para equivocarse.
Un margen de 1 significa que la confiabilidad de la predicción es del 100% mientras un
margen de -1 significa lo contrario, es decir que la confiabilidad es de predicción de una clase
incorrecta es del 100%. Como el valor mínimo en la gráfica es de -0.33 para la instancia 1, y
comienza a aumentar para las otras instancias, quiere decir que el margen va aumentando a
medida que se aumenta el número de instancias y para 2651 instancias, que son las que se
analizaron es de 0.33 que representa una confiabilidad de 33%, que, aunque no es el valor
óptimo (100%) tampoco es un valor tan bajo. Esto significa que entre mayor sea el número
de instancias analizadas, mayor el valor del margen de predicción y por lo tanto la
confiabilidad de la predicción.
Análisis de curva PRC (Recall-Precisión).
El área bajo la curva RP (recall-precision) es de 0.794 que es un valor alto. Para el sistema
bajo estudio resulta más útil considerar el valor ROC, ya que el RPC se utiliza más cuando
es más importante acertar en una clase que en otras, por ejemplo “buscar una aguja en un
pajar”. En e l caso bajo estudio, si la clase “no respetar distancia de seguridad” fuera más
importante que la clase otras, o la clase adelantar cerrando, ò huecos, sería mejor aplicar la
curva PRC ya que no debería dejarse por fuera del clasificador ningún caso, es decir el
algoritmo clasificador no debería dejar de clasificar correctamente ningún caso de no respetar
distancia de seguridad, pero esta no es la situación bajo estudio.
Análisis de curva de error.
Se muestran las instancias bien clasificadas con una cruz y las mal clasificadas con un
cuadrado, para cada valor del atributo causa. Se observa una mayor cantidad de instancias
bien clasificadas (cruces) para la clase no mantener distancia de seguridad en color azul y
para la clase otra en color rojo.
Análisis de la curva ROC.
El área bajo la curva ROC es de 0.783. el rango de valores recomendado para un buen
modelo según y está entre 0.75 y 1. En este caso el valor está por encima de 0.75. Esto

139
significa que puede clasificar correctamente los verdaderos positivos y los verdaderos
negativos. La forma de la curva ROC está dentro de las que son aceptables. Este valor es
mayor al encontrado en el perceptrón multicapas.
Análisis de la curva costo.
Se puede observar que la envolvente inferior tiene el punto más bajo en aproximadamente
0.3 que corresponde al máximo costo esperado y es sensiblemente menor que el encontrado
para el perceptrón multicapas. Des de este punto de vista este algoritmo es más adecuado
para la clasificación de las causas de accidentes.
140
Gráficas.
Figura 38 Margin curve. Fuente: elaboración propia programa Weka 3.8.
Figura 39 Treshold Recall Precision curve.
Fuente: elaboración propia programa Weka 3.8.
141
Figura 40 Errores del clasificador. Fuente: elaboración propia programa Weka 3.8.
Figura 41 Curva ROC y curva Costo beneficio. Fuente: elaboración propia programa Weka
3.8.
142
Figura 42 Curva de costo. Fuente: elaboración propia programa Weka 3.8

143
6.3. MODELO DE CAUSA RAIZ.
La segunda parte del modelo consiste en construir un algoritmo para realizar una
aproximación al análisis y determinación de la causa o causas básicas de los accidentes de
tránsito. Siguiendo la metodología explicada, esta aproximación se realiza a partir de la causa
básica o próxima.
En este caso, se dificulta utilizar técnicas de minería de datos por no disponer de los mismos
y por constituir una característica de cada accidente en particular. Debido a que las categorías
de causa raíz; factores humanos y factores del trabajo están relacionados estrechamente con
las características particulares de las personas que participan en el accidente, ya sea
conductor, peatón, pasajero, mecánicos de mantenimiento, supervisores de la flota de
transporte, etc., y de la organización, es difícil obtener información con algún nivel de detalle
para realizar este análisis.
Por estas razones construir un algoritmo que realice la predicción ò clasificación basándose
en la causa básica no es lo más apropiado al problema bajo estudio. Esta fase se debe realizar
utilizando la participación de expertos los cuales a partir de una información clasificada
sistemáticamente pueda llegar a determinar la causa o causas más probables de los
accidentes.
Se propone entonces con base en los conceptos presentados en el apartado y el método
DREAM 3.0, la construcción de un algoritmo que proporcione reglas de decisión que sirvan
como punto de partida para que los expertos puedan llegar a conclusiones acordes con las
particularidades del caso, siguiendo el procedimiento de investigación de accidentes.
Este modelo no busca realizar una provisión de explicaciones de la causa del accidente, sino
ser un organizador de las mismas, por lo tanto para que los factores contribuyentes a un
accidente puedan ser aplicables al mismo, deben ser soportados por información empírica
relevante obtenida a partir del accidente. Se trata de clasificar y organizar la información
obtenida de los accidentes con el objetivo de identificar de forma estructurada las causas
detrás del accidente expresadas en un conjunto de categorías formalmente definidas de los
factores contribuyentes. Si no existe esta información, no es posible realizar la clasificación.
Por esta razón se ha decidido utilizar un algoritmo cuya salida sean reglas de decisión con
información que debe ser validada en el proceso de investigación de accidentes con la
obtenida por el análisis particular del accidente.
El modelo proporciona pues un punto de partida, no de llegada para la determinación de la
causa raíz del accidente.
6.3.1. Construcción de la base de datos para causa básica o raíz.

144
Se ha diseñado entonces una base de datos con 20 campos, que corresponden a la causa
próxima probable del accidente encontrada en la primera parte del modelo mediante la
técnica de perceptrón multicapas, y a los factores coadyuvantes en la ocurrencia del mismo,
clasificados en 19 categorías, que a su vez dentro del modelo de datos mostrado en la figura
17 corresponden a los niveles de atributos / variables con los respectivos valores que puede
tomar cada atributo.
Para la elaboración de la base de datos se toma cada uno de los valores del atributo causa
próxima y se establece una relación con los valores de la posible causa raíz expresados en
los valores de los 19 atributos mencionados.
Al comparar el modelo de datos propuesto con el presentado en DREAM 3.0, se observan
unas coincidencias y diferencias en la forma de clasificar los factores de riesgo expresados
como atributos o como fenotipos y genotipos.
Mientras en el modelo propuesto en este trabajo se utilizan las 19 categorías o atributos para
agrupar las posibles causa raíz, en el DREAM 3.0 se utilizan 23 categorías para agrupar
genotipos generales.
Retomando los factores y variables asociadas a los mismos definidos en la tabla 5 y los
criterios de clasificación de genotipos y su relación entre ellos y con los fenotipos definidos
en el método DREAM 3.0, se ha realizado un arreglo para establecer las relaciones entre los
mismos y la causa próxima identificada por el algoritmo obtenido en la primera parte del
modelo.
Para que la base de datos sea representativa se deben establecer de forma clara los posibles
valores de las categorías o atributos de causa raíz y de otro lado establecer las relaciones
mencionadas.
Se debe mencionar que las combinaciones de valores pueden ser numerosas, sin embargo la
clasificación realizada en DREAM 3.0 ayuda a definir las más probables.
La base de datos se elaboró con base a la experiencia, se tomó una causa inmediata como por
ejemplo no mantener distancia de seguridad, y de las diferentes causas asociadas con factores
humanos, se asignaron los más probables, por ejemplo esto puede ocurrir debido a temas
relacionados con la seguridad como los mencionados anteriormente, o características
humanas como reacción demorada o lentitud, percepción equivocada del riesgo, desatención
como hablar por teléfono, actitud relajada, entre otras razones o debidas a comportamiento
humano como carácter, cultura, faltas de disciplina, o en temas relacionados con la seguridad
como actos inseguros o pasar por alto situaciones riesgosas, o con el vehículo como falla
mecánica,

145
En DREAM 3.0 los genotipos relacionados pueden ser miedo, fatiga, conducir bajo la
influencia de sustancias, discapacidad funcional súbita, limitación temporal de acceso, falla
de equipo, mal juzgamiento de tiempo o distancia, viento lateral fuerte.
Para seleccionar las relaciones, se ha realizado primero una homologación de los genotipo
con los atributos de la base de datos 3, y después se ha utilizado la tabla de relaciones entre
fenotipos y genotipos de la tabla del anexo y la relación entre genotipos de la tabla . el
resultado es la base de datos 3 utilizada para el algoritmo de clasificación PART.
Es de anotar que esta base de datos puede ser mejorada en la medida en que se tenga acceso
a datos relacionados con el tema, y la participación de los expertos sea mayor.
Los factores de riesgo asociados a las causas básicas de accidentes de tránsito en empresas
de transporte, se han clasificado en las siguientes categorías definidas en la tabla ,
• Características humanas.
• Comportamiento humano.
• Fatiga.
• Capacidad de estrés físico/fisiológico.
• Capacidad de estrés sicológico.
• Conocimiento/competencia/entrenamiento inadecuado.
• Problemas de comunicación.
• Cultura de equipo inadecuada.
• Temas relacionados con seguridad.
• Factores de falta de comunicación.
• Tripulación inadecuada.
• Falla mecánica.
• Mantenimiento inadecuado.
• Inadecuada selección del proveedor.
• Factores ambientales.
• Ambiente de trabajo.

146
• Reglas estándares procedimientos.
• Gestión.
• Evaluación del riesgo.
• Causa próxima.
Los valores que pueden tomar estos atributos figuran en el anexo de la base de datos 3 y en
la tabla 5.
6.3.2. Aplicación de la técnica PART para determinar la causa raíz de a accidentes
de tránsito en empresas de transporte.
Partiendo de la causa próxima se utiliza la plantilla con las principales causas asociadas con
ella, que figuran en la tabla 5.
La base de datos que se ha construido consta de 550 instancias. Para la construcción de esta
base de datos se ha utilizado la experiencia de personas que han laborado en el sector
transporte así como los documentos elaborados por Aslan y DREAM 3.0, así como
Se parte del principio de que los factores que participan en la materialización de un accidente
no están necesariamente relacionados entre ellos ni jerarquizados. Esto significa que la red
que incluye los factores que son coadyuvantes en la ocurrencia del accidente y no
necesariamente determinantes del mismo.
Estos factores de acuerdo con numerosos estudios están relacionados con condiciones de las
personas y en mucho menor cantidad con los vehículos o las vías. Por esta razón los factores
relacionados con las personas son mucho más numerosos que los de los vehículos y vía.
Aunque pueden existir diferentes factores contribuyentes a un mismo accidente, en la
construcción de la base de datos se ha tratado de colocar simultáneamente un número máximo
para disminuir la complejidad del modelo de datos y porque además no es muy común que
al mismo tiempo se presenten varios factores similares como por ejemplo los relacionados
con fatiga, estrés físico, estrés sicológico, características humanas, comportamiento humano
y por otro lado de gerencia y organización.
En la tabla se presentan los factores generales y específicos contribuyentes utilizados en la
base de datos.
En la figura 35 parte izquierda se presenta el histograma para la clase causa raíz
características humanas. En el eje horizontal se representan las 8 clase o valores de la variable
(atributo) causa raíz características humanas. En el eje vertical, los conteos o frecuencias.

147
En la parte derecha se presenta la causa próxima o inmediata con sus 20 valores posibles,
tomados de la tabla 8, con los histogramas estratificados para la causa raíz, representados en
diferentes colores.
Por ejemplo, la primera columna corresponde al valor de causa próxima desobedecer señales
con 12 conteos, y de los doce hay cuatro colores sobrepuestos; azul oscuro, rojo, aguamarina
y amarillo, los cuales corresponden a cuatro valores diferentes de la variable causa raíz
características humanas, y así para las demás barras del histograma.
La mayor frecuencia para la causa raíz, en el diagrama de la izquierda, corresponde a la clase
o valor temas relacionados con seguridad, que incluyen factores como: actos inseguros,
acciones imprevistas como acciones inoportunas, falta de memoria, pasar por alto
situaciones, acciones inapropiadas tendientes a ahorrar tiempo, esfuerzo, o evitar
incomodidad, sabotaje.
En segundo lugar está el comportamiento humano con 101 conteos en color azul. Este valor
de la variable incluye, de acuerdo con la tabla 5, circunstancias como: cultura, carácter y falta
de disciplina de las personas.
6.3.3. Modelo PART.
A partir de la base de datos causa raíz se construyó un modelo de clasificación utilizando la
técnica PART incluida en el programa WEKA 3.8. Este clasificador se configuró con los
parámetros mostrados en la figura con la configuración mostradas en la figura 36. El
número mínimo de atributos incluidos en las reglas de decisión se ha fijado en 3.
Se obtuvieron los resultados mostrados a continuación:
Reglas de decisión obtenidas a partir del modelo PART.

148
Figura 43 Configuración de la técnica PART en Weka.
A continuación se presentan los resultados obtenidos a partir de la aplicación de la técnica
PART utilizando la base de datos número 3 para causa raíz, partiendo de la causa próxima
identificada en la primera parte del modelo.
=== Classifier model (full training set) ===
PART decision list
------------------
fatiga = Fatiga debida a falta de descanso: microsueño (27.82/2.82)
caracteristicas humanas = desatencion AND
temas relacionados con seguridad = precausiones inadecuadas: frenar
bruscamente (24.76/1.76)
fatiga = Fatiga debida a sobrecarga sensorial: microsueño (26.68/2.84)
caracteristicas humanas = competencia AND
capacidad estrés fisico/fisiologico = deficiencias sensoriales: no
mantener distancia de seguridad (23.61/2.61)

149
caracteristicas humanas = competencia: estacioanar sin seguridad
(17.45/3.45)
capacidad estrés sicologico = carga emocional AND
fatiga = por falta de descanso: reverso imprudente (21.0/3.0)
capacidad estrés sicologico = carga emocional AND
fatiga = demanda percepcion/concentracion extrema: en contravia (21.0)
caracteristicas humanas = complacencia: semaforo en rojo (13.38/0.38)
caracteristicas humanas = incomunicacion AND
temas relacionados con seguridad = actos inseguros: semaforo en rojo
(9.26/1.26)
caracteristicas humanas = percepcion de riesgo AND
fatiga = demanda percepcion/concentracion extrema AND
comportamiento humano = carácter: no mantener distancia de seguridad
(58.0/1.0)
capacidad estrés sicologico = carga emocional AND
caracteristicas humanas = habilidad de percepcion AND
fatiga = por sobrecarga sensorial: en contravia (16.0/4.0)
capacidad estrés sicologico = carga emocional AND
caracteristicas humanas = habilidad de percepcion: no respetar
prelacion de intersecciones o giros (16.59/7.59)
caracteristicas humanas = percepcion de riesgo AND
fatiga = demanda percepcion/concentracion extrema AND
temas relacionados con seguridad = precausiones inadecuadas: exceso de
velocidad (18.0)
caracteristicas humanas = percepcion de riesgo AND
capacidad estrés fisico/fisiologico = sensibilidad: no mantener
distancia de seguridad (23.9/0.9)
capacidad estrés sicologico = uso de alcohol/droga: no respetar
prelacion de intersecciones o giros (14.55/2.55)
caracteristicas humanas = habilidad de percepcion AND
temas relacionados con seguridad = precausiones inadecuadas: no mantener
distancia de seguridad (47.15/3.44)
caracteristicas humanas = habilidad de percepcion AND

150
temas relacionados con seguridad = actos inseguros AND
fatiga = demanda percepcion/concentracion extrema: exceso de velocidad
(20.0)
caracteristicas humanas = habilidad de percepcion AND
temas relacionados con seguridad = falta de cultura de seguridad: invadir
carril (59.86/21.13)
capacidad estrés fisico/fisiologico = deficiencias sensoriales AND
fatiga = por falta de descanso: desobedecer señales (15.38/0.38)
capacidad estrés fisico/fisiologico = deficiencias sensoriales: semaforo
en rojo (15.0/2.0)
fatiga = por falta de descanso: adelantar invadiendo via (17.0/6.0)
fatiga = rutina/monotonia vigilancia AND
factores de falta de motivacion = presion jerarquica AND
temas relacionados con seguridad = precausiones inadecuadas: exceso de
velocidad (15.0)
fatiga = demanda por decisión/juicio extremo: no mantener distancia de
seguridad (9.0)
fatiga = rutina/monotonia vigilancia AND
temas relacionados con seguridad = precausiones inadecuadas: no mantener
distancia de seguridad (7.0)
fatiga = por sobrecarga sensorial: frenar bruscamente (9.0/4.0)
fatiga = por carga o duracion del trabajo: embriaguez o droga (6.0/1.0)
: en contravia (9.61/4.61)
Number of Rules : 27
Time taken to build model: 0.09 seconds
=== Predictions on test data ===
inst#,actual,predicted,error,prediction
=== Classifier model for fold 1 ===
PART decision list
------------------
fatiga = Fatiga debida a falta de descanso: microsueño (25.58/2.58)
caracteristicas humanas = desatencion AND

151
temas relacionados con seguridad = precausiones inadecuadas: frenar
bruscamente (22.6/1.6)
fatiga = Fatiga debida a sobrecarga sensorial: microsueño (24.51/2.6)
caracteristicas humanas = competencia AND
capacidad estrés fisico/fisiologico = deficiencias sensoriales: no
mantener distancia de seguridad (22.55/2.55)
caracteristicas humanas = competencia: estacioanar sin seguridad
(15.37/3.37)
capacidad estrés sicologico = carga emocional AND
fatiga = por falta de descanso: reverso imprudente (18.0/2.0)
capacidad estrés sicologico = carga emocional AND
caracteristicas humanas = percepcion de riesgo AND
factores de falta de motivacion = presion jerarquica: en contravia
(16.42/0.42)
caracteristicas humanas = complacencia: semaforo en rojo (13.34/0.34)
caracteristicas humanas = lentitud de reaccion: desobedecer señales
(8.21/0.21)
capacidad estrés sicologico = uso de alcohol/droga: no respetar
prelacion de intersecciones o giros (14.36/2.36)
caracteristicas humanas = incomunicacion AND
capacidad estrés fisico/fisiologico = uso de alcohol/droga: frenar
bruscamente (7.18/2.18)
capacidad estrés sicologico = carga emocional AND
caracteristicas humanas = habilidad de percepcion: en contravia
(31.81/11.81)
caracteristicas humanas = percepcion de riesgo AND
fatiga = demanda percepcion/concentracion extrema AND
comportamiento humano = carácter: no mantener distancia de seguridad
(55.0/1.0)
temas relacionados con seguridad = precausiones inadecuadas AND
fatiga = demanda percepcion/concentracion extrema: exceso de velocidad
(19.99/1.99)
temas relacionados con seguridad = precausiones inadecuadas AND
fatiga = por sobrecarga sensorial: no mantener distancia de seguridad
(17.87/2.05)

152
temas relacionados con seguridad = precausiones inadecuadas AND
fatiga = rutina/monotonia vigilancia AND
factores de falta de motivacion = falta de incentivos: no mantener
distancia de seguridad (16.68)
caracteristicas humanas = habilidad de percepcion AND
temas relacionados con seguridad = precausiones inadecuadas: no mantener
distancia de seguridad (20.85/1.56)
caracteristicas humanas = habilidad de percepcion AND
temas relacionados con seguridad = actos inseguros AND
fatiga = demanda percepcion/concentracion extrema: exceso de velocidad
(19.0)
caracteristicas humanas = habilidad de percepcion AND
temas relacionados con seguridad = falta de cultura de seguridad: invadir
carril (53.93/19.79)
capacidad estrés fisico/fisiologico = deficiencias sensoriales AND
temas relacionados con seguridad = actos inseguros: semaforo en rojo
(17.19/1.19)
fatiga = rutina/monotonia vigilancia AND
temas relacionados con seguridad = precausiones inadecuadas: exceso de
velocidad (10.0)
fatiga = por falta de descanso AND
caracteristicas humanas = percepcion de riesgo: adelantar invadiendo
via (16.0/5.0)
fatiga = demanda por decisión/juicio extremo: no mantener distancia de
seguridad (9.0)
fatiga = demanda percepcion/concentracion extrema: no mantener
distancia de seguridad (7.0)
fatiga = rutina/monotonia vigilancia : en contravia (6.0/2.0)
fatiga = por carga o duracion del trabajo: embriaguez o droga (6.0/1.0)
: desobedecer señales (10.54/5.54)
Number of Rules : 27
Tabla 20 Reglas de decisión obtenidas a partir de la técnica PART. Fuente: elaboración
propia WEKA 3.8.

153
=== Classifier model (full training set) ===
=== Run information ===
Scheme: weka.classifiers.rules.PART -M 3 -C 0.25 -Q 1
Relation: crjunio23-2019-
weka.filters.unsupervised.attribute.StringToNominal-Rfirst-last-
weka.filters.unsupervised.attribute.Remove-R11-14
Instances: 549
Attributes: 18
caracteristicas humanas
comportamiento humano
capacidad estrés fisico/fisiologico
capacidad estrés sicologico
fatiga
conocimiento/competencias/entrenamiento inadecuado
problemas de comunicación
cultura equipo inadecuada
temas relacionados con seguridad
factores de falta de motivacion
Factores ambientales
Ambiente de trabajo
Procedimiento
reglas y estándares
Reglas estándares y políticas
Gestión
Evaluación del riesgo
causa proxima
Test mode: 10-fold cross-validation
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 524 95.4463 %

154
Incorrectly Classified Instances 25 4.5537 %
Kappa statistic 0.9463
Mean absolute error 0.0091
Root mean squared error 0.0754
Relative absolute error 7.4655 %
Root relative squared error 30.6183 %
Total Number of Instances 549
Se obtuvo un porcentaje de 53% de instancias correctamente clasificadas, un indicador
kappa de 0.3588, error relativo absoluto de 78.352, error medio absoluto de 0.1531, área
bajo la curva ROC 0.757 que es un valor entre 0.75 y 1 para un buen desempeño.
A continuación se presentan la precisión detallada por clase y la matriz de confusión.
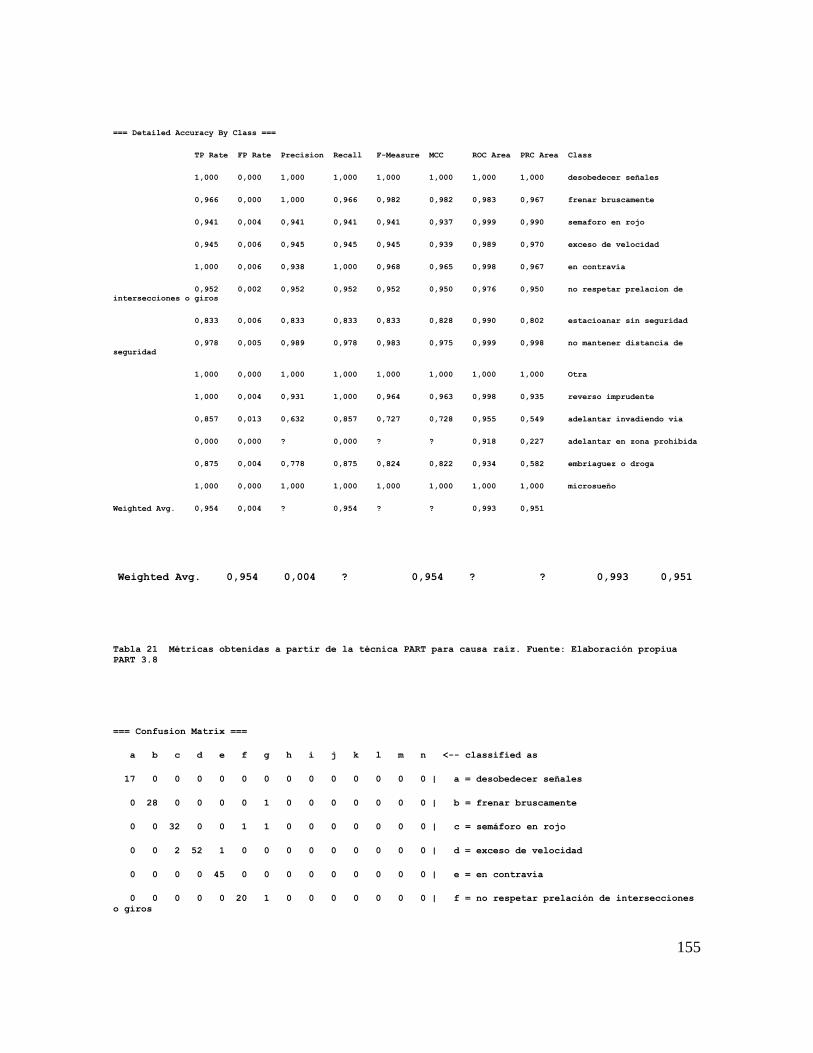
155
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1,000 0,000 1,000 1,000 1,000 1,000 1,000 1,000 desobedecer señales
0,966 0,000 1,000 0,966 0,982 0,982 0,983 0,967 frenar bruscamente
0,941 0,004 0,941 0,941 0,941 0,937 0,999 0,990 semaforo en rojo
0,945 0,006 0,945 0,945 0,945 0,939 0,989 0,970 exceso de velocidad
1,000 0,006 0,938 1,000 0,968 0,965 0,998 0,967 en contravia
0,952 0,002 0,952 0,952 0,952 0,950 0,976 0,950 no respetar prelacion de
intersecciones o giros
0,833 0,006 0,833 0,833 0,833 0,828 0,990 0,802 estacioanar sin seguridad
0,978 0,005 0,989 0,978 0,983 0,975 0,999 0,998 no mantener distancia de
seguridad
1,000 0,000 1,000 1,000 1,000 1,000 1,000 1,000 Otra
1,000 0,004 0,931 1,000 0,964 0,963 0,998 0,935 reverso imprudente
0,857 0,013 0,632 0,857 0,727 0,728 0,955 0,549 adelantar invadiendo via
0,000 0,000 ? 0,000 ? ? 0,918 0,227 adelantar en zona prohibida
0,875 0,004 0,778 0,875 0,824 0,822 0,934 0,582 embriaguez o droga
1,000 0,000 1,000 1,000 1,000 1,000 1,000 1,000 microsueño
Weighted Avg. 0,954 0,004 ? 0,954 ? ? 0,993 0,951
Weighted Avg. 0,954 0,004 ? 0,954 ? ? 0,993 0,951
Tabla 21 Métricas obtenidas a partir de la técnica PART para causa raíz. Fuente: Elaboración propiua
PART 3.8
=== Confusion Matrix ===
a b c d e f g h i j k l m n <-- classified as
17 0 0 0 0 0 0 0 0 0 0 0 0 0 | a = desobedecer señales
0 28 0 0 0 0 1 0 0 0 0 0 0 0 | b = frenar bruscamente
0 0 32 0 0 1 1 0 0 0 0 0 0 0 | c = semáforo en rojo
0 0 2 52 1 0 0 0 0 0 0 0 0 0 | d = exceso de velocidad
0 0 0 0 45 0 0 0 0 0 0 0 0 0 | e = en contravía
0 0 0 0 0 20 1 0 0 0 0 0 0 0 | f = no respetar prelación de intersecciones
o giros

156
0 0 0 0 1 0 15 2 0 0 0 0 0 0 | g = estacionar sin seguridad
0 0 0 3 1 0 0 176 0 0 0 0 0 0 | h = no mantener distancia de seguridad
0 0 0 0 0 0 0 0 43 0 0 0 0 0 | i = Otra
0 0 0 0 0 0 0 0 0 27 0 0 0 0 | j = reverso imprudente
0 0 0 0 0 0 0 0 0 2 12 0 0 0 | k = adelantar invadiendo vía
0 0 0 0 0 0 0 0 0 0 6 0 2 0 | l = adelantar en zona prohibida
0 0 0 0 0 0 0 0 0 0 1 0 7 0 | m = embriaguez o droga
0 0 0 0 0 0 0 0 0 0 0 0 0 50 | n = micro sueño
Tabla 22 Matriz de confusión obtenido por la técnica PART para causa raíz. Fuente:
Elaboración propia WEKA 3.8

157
6.3.4. EJEMPLO DE APLICACIÓN DEL MODELO.
A continuación se presenta la aplicación del modelo a un caso real tomado de la base de
datos suministrada por la empresa Allianz.
Algunos detalles se excluyen por constituir información reservada.
RECOLECCION DE INFORMACION DEL ACCIDENTE.
De acuerdo con la información suministrada por las personas responsables de la operación
en la empresa Iceberg, el vehículo de placas SKL458 entró a revisión al taller el día 4 de
abril de 2011 y salió el día 5 de abril. Se realizaron entre otras actividades el cambio de
mangueras de conducción de aire desde la unidad tractora hasta el remolque, y ajuste de
los frenos. Según el conductor, solicito expresamente la revisión de este sistema.
El vehículo salió con carga con destino hacia Venezuela el día 5 de abril a las 4pm., a
cargo del conductor Faiver Iván Paloma. Esa noche, el conductor guardó el vehículo con
la carga y se alojó en un hospedaje en la vía.
El día 6 de abril el conductor continuó su viaje y hacia las 8:30 a.m. cuando iba en terreno
de descenso al intentar frenar según su versión; el sistema no respondió, produciéndose
un volcamiento de este. De acuerdo con el croquis suministrado por la empresa, el
accidente ocurrió en una curva pronunciada. El documento elaborado por la autoridad de
tránsito, no señala presencia de huellas en la vía debido a frenado, derrape, o
deslizamiento del vehículo sobre la misma.
Se realizó una inspección del vehículo en el patio de Iceberg el día 11 de abril. Debido al
estado de este, no fue posible revisar en detalle componentes de interés, particularmente
del sistema de frenos. Se presenta el resultado de la revisión de los sistemas, la cual como
se anota fue realizada visualmente. Se revisó con especial atención el sistema de frenos,
dada la declaración de conductor.
Sin embargo, se hace énfasis más adelante en la conveniencia de realizar una revisión
detallada del sistema mencionado, con el objeto de determinar la integridad en cuanto a
su funcionamiento, teniendo en cuenta que según la versión del conductor el accidente se
debió a una falla en el mismo. También es de interés poder obtener la información sobre
los datos de operación del vehículo, almacenada en el computador de este. Por tratarse de
un motor Cummins, se requeriría el uso del sistema Insite.
Condición tecno mecánica.
Durante la revisión del vehículo, se pudo determinar un gran daño en la parte estructural,
perdida de integridad estructural del chasis de la unidad tractora, pérdida en la integridad
estructural de la carrocería del remolque así como en su cerramiento, perdida en la
integridad de la unidad de enfriamiento.

158

159
Figura 44. Documento de levantamiento del accidente. Suministrado por transportes
Iceberg a Allianz.

160
Dado el estado de este, no es posible realizar una puesta en marcha de la unidad motriz,
sin antes realizar un acondicionamiento detallado de la misma.
Sistema de frenos.
Al revisar los componentes del sistema de frenos, se hace notar que el sistema de frenado
de emergencia probablemente fue activado, pero no se ha determinado si esto ocurrió por
falla en el suministro de aire antes del volcamiento, o fue producto de un daño después
del mismo.
En la inspección visual se observa lo siguiente:
Compresor.
No se observa deterioro exteriormente, la correa se encuentra en su lugar. Las conexiones
de aire tubería y mangueras están en su sitio y no se observa deterioro en los mismos.
Regulador de presión.
Se observa en buenas condiciones exteriormente, así como sus conexiones.
Depósitos de aire.
Se observa en buena condición exteriormente. Las conexiones están en su sitio en buena
condición.
Secador de aire.
Está ubicado al interior del tanque secador y no se observa su estado desde afuera.
Conducciones.
Se observan exteriormente en buenas condiciones.
Válvula de pedal.
A pesar de que el impacto desplazo parte del torpedo en el lado d la válvula, se observa
en buena condición, aunque el acceso es un poco difícil.
Válvula repartidora.
Se observa exteriormente en buen estado.
Válvula de descarga rápida.
Se observa exteriormente en buen estado.
Válvula check simple.
Se observa exteriormente en buen estado.
Válvula check doble.
Se observa externamente en buen estado.
Válvula de seguridad del tanque.
Se observa exteriormente en buen estado.

161
Válvula relay.
En buen estado exterior.
Cámaras de frenos de emergencia.
No se determinó si estaban activadas. De acuerdo con la información recogida, se
activaron probablemente en el momento del accidente y fueron recogidas para poder
trasladar el vehículo en la grúa.
Cámaras de frenos.
Delantera derecha.
En buen estado exterior.
Delantera izquierda.
En buen estado exterior.
Posterior derecha troque delantero.
En buen estado exterior.
Posterior izquierdo troque delantero.
En buen estado exterior.
Posterior derecha troque posterior.
En buen estado exterior.
Posterior izquierda troque posterior.
En buen estado exterior.
Mangueras y acoples del tráiler.
En buen estado, así como sus conexiones. No se encontraron las manos en el tráiler. Las
mangueras se cambiaron antes del viaje.
Conjuntos de frenos. (Porta zapatas, bandas, leva, resortes)
Conjunto freno delantero derecho. En buen estado exterior.

162
Figura 45 Diagrama sistema de frenos.

163
Válvula relay Figura Deposito de aire..
Figura 46 a. Válvula relay, diafragmas, depósito, llantas.
Cámara y llanta delantera izquierda se observan exteriormente en buen estado. El labrado no
presenta evidencia de desgaste por frenado abrupto o bloqueo de las llantas debido a
accionamiento del freno de seguridad. Igual sucede con las llantas y cámaras de la unidad
tractora y del remolque. Bombona de suspensión lado posterior izquierdo dañada.

164
Figura 46 b. Mangueras de conexión, Tanque y válvulas del tráiler en buen estado exterior.
Conjunto freno eje delantero
En buen estado exterior.
Conjunto eje posterior.
En buen estado exterior.
Conjuntos frenos tráiler.
En buen estado exterior.
Figura 46 c. Control manual de frenos del tráiler.
Instrumentos.
Indicador caída de presión.
No se tuvo acceso por la condición de la cabina.
Sistema antibloqueo (ABS).

165
El vehículo tiene incorporado este sistema que evita el bloqueo de las llantas y por lo tanto el
derrape del vehículo en la vía. No se revisó el sistema de control de ABS para verificar su
integridad.
Sugerencia.
Realizar una inspección detallada de los componentes del sistema, incluyendo el desmontaje de
las llantas, el desmontaje de la válvula de pedal y de la válvula relay tanto de la unidad motriz
como del remolque.
llantas.
Como se mencionó anteriormente, el estado general es normal. Algunas presentan cortes en el
flanco y en la unión entre la carcasa y la banda de rodamiento reencauchada, pero
probablemente sea debido al accidente. No hay llantas estalladas.
Figura 46 d. Llantas posteriores de la unidad tractora Deterioro en la Cabina
en buen estado.
Carrocería.
La parte de la cabina es la que presenta el mayor deterioro. En particular el espacio ocupado por
el conductor, ya que la parte frontal y el techo de la cabina se desplazaron hacia atrás y abajo
respectivamente. Esto indica que el volcamiento se produjo hacia el lado que el vehículo salido
de la vía y se recostó hacia el lado del conductor girando la cabina con el techo hacia abajo. En
estas condiciones el impacto hacia el lado del conductor fue de una gran magnitud.

166
Figura 46 e. Posición de la columna de dirección y el asiento del conductor.
ANALISIS DINAMICO DEL VEHICULO.
La carga estimada del vehículo, peso neto vehicular es de 48 toneladas, repartidas en la siguiente
forma:
Peso bruto vehicular: 18 toneladas.
Carga: 30 toneladas.
En el lugar del accidente, se observa una pendiente cuyo valor se desconoce.
El accidente ocurrió en una curva en descenso, y el vehículo se desplazó cerca de cincuenta
metros con respecto a la curva hasta el sitio en donde rompió la barrera de protección y se
precipitó fuera de la vía.
No se tienen detalles en el croquis acerca de la velocidad del vehículo, ni de la existencia de
huellas de frenado o deslizamiento del vehículo sobre la vía que se encontraba seca y en buenas
condiciones.
De otro lado, las llantas no presentan evidencia de fricción con la vía en las bandas de rodadura
reencauchadas en las llantas posteriores y originales en las llantas delanteras.
Asumiendo un peralte estándar en la vía, (5%) con una pendiente normal, el peso del vehículo
con la carga genera un incremento en la velocidad, que puede exceder el valor seguro en bajada.
Las fuerzas inerciales resultantes constituyen una condición peligrosa que pueden ocasionar un
aumento de la fuerza centrífuga que exceda la acción estabilizadora del peralte en la parte más
pronunciada de la curva. ,

167
Obviamente la influencia de la dirección de las llantas delanteras y del conjunto del vehículo en
sí mismas puede producir también la salida de la vía, con la trayectoria que indica el croquis. Es
decir que no necesariamente la fuerza centrífuga producto de la combinación masa del vehículo
y su velocidad son necesarias para hacer que este se salga de la vía.
Sin conocer los detalles de la velocidad, y teniendo en cuenta la versión del conductor en el
sentido de que se desplazó cerca de dos Km. sin frenos, en bajada, la cantidad de movimiento
adquirida por el vehículo puede ser lo suficientemente alta para producir que este rodara una
distancia mayor a los 17 metros reportados en el croquis. En este caso, el efecto de la barda
como elemento absorbedor de energía, es bajo por las características livianas de la misma.
Esto lleva a entrever una probable inconsistencia en la versión del conductor respecto de las
condiciones en que ocurrió el evento.
Este pudo ser ocasionado también por una acción intencional.
La empresa Iceberg ha suministrado los datos obtenidos del GPS acerca de la velocidad del
vehículo. Sin embargo, como el reporte no es continuo, se desconoce la velocidad en el instante
exacto de la salida de la vía y el volcamiento. Este dato es importante para establecer con certeza
las condiciones de este.
El último reporte del GPS es a las 7:50 mientras el accidente según versión del conductor es a
las 8:30 am. Los reportes del GPS son aproximadamente cada 15 minutos. Por esta razón, la
información obtenida no es lo suficientemente consistente para estimar la velocidad en el
momento en que se presentó el evento.
Figura 46 f Medidor de velocidad

168
Se aplica el primer modelo de perceptrón multicapas para realizar una aproximación hacia la
causa próxima del accidente. Para comparar los modelos obtenidos utilizando las bases de datos
1 y 2 se aplican al mismo accidente y se obtiene los resultados mostrados a continuación.
Los datos de entrada para el modelo fueron los siguientes;
Base de datos 2:
empresa numpoliza numcis modelo placa Descr Marca Descr Clase Tipo1 año
transportes iceberg 2010 skl458 KENWORTH REMOLCADOR 2011
Aunque aquí figuran los 22 atributos de la base de datos Accidentes de empresas de transporte
de Allianz, solamente se consideran 17 ya que son los que contiene el modelo de perceptrón
multicapas definido en la sección ..
Del análisis de salida del modelo se observa que la causa determinada es la de invadir carril.
=== Re-evaluation on test set ===
User supplied test set
Relation: PLANTILLA JUNIO25-2019
Instances: unknown (yet). Reading incrementally
Attributes: 17
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 15:invadir carril 0.671
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 1
Es de observar que la causa próxima FALLA MECANICA, que corresponde a la declaración
del conductor, no figura en la salida del modelo, lo que es consecuente con el resultado obtenido

169
de su aplicación y con el análisis realizado a partir de la documentación existente y del estado
en que quedó el vehículo.
El modelo proporciona solamente un valor de causa próxima bajo las condiciones de entrada
definidas a partir del análisis de la información disponible del accidente.
Se comparó el resultado anterior con el obtenido al utilizar el modelo resultante de la aplicación
de la base de datos 1 o sea de accidentalidad en general para Bogotá en 2016.
Los resultados obtenidos para el caso bajo análisis fueron;
=== Re-evaluation on test set ===
User supplied test set
Relation: plantilladjulio2-2019ok
Instances: unknown (yet). Reading incrementally
Attributes: 28
=== Predictions on user test set ===
inst# actual predicted error prediction
1 1:? 1:NO MANTENER DISTANCIA DE SEGURIDAD 0.605
=== Summary ===
Total Number of Instances 0
Ignored Class Unknown Instances 1
Partiendo del modelo de causa raíz obtenido a partir de la técnica PART, utilizando la tabla con
las reglas de decisión presentadas en la tabla se pueden inferir algunas probables causas
básicas que están relacionadas con la causa próxima invadir carril.
De la tabla de reglas de decisión obtenida del modelo que utiliza la técnica PART, se extraen
las causas asociadas con la causa próxima INVADIR CARRIL.
características humanas = habilidad de percepción AND
temas relacionados con seguridad = falta de cultura de seguridad: invadir
carril (59.86/21.13)

170
Estas reglas sugieren centrarse en las características humanas y de comportamiento del
conductor, y llevan a revisar las pruebas sicosensométricas realizadas según se muestra en el
anexo .
Análisis sicosensométrico del conductor.
Teniendo en cuenta la información obtenida a partir próxima y causa raíz, y teniendo en cuenta
que no se presentan evidencias que soporten la declaración del conductor en el sentido de que
el accidente se debió a una falla mecánica, en este caso falla en el sistema de frenos, se toma la
hipótesis 1 que indica que la causa se pudo deber a una operación o maniobra de conducción
indebida.
Para reforzar esta hipótesis, se recurre a la revisión de las pruebas sicosensométricas al
conductor involucrado en el accidente. Este estudio no está disponible para presentar en el
trabajo.
En el anexo 5 se presenta un modelo utilizado por la empresa Allianz para la realización de estas
pruebas.
RESULTADOS DE LAS PRUEBAS PSICOSENSOMÉTRICAS
Las pruebas psicosensométricas son evaluaciones que buscan identificar de manera precoz las
posibles alteraciones que pueda presentar una persona en su visión, audición y motricidad.
Constituyen el primer acercamiento para que la empresa conozca los resultados consolidados de
las condiciones de salud de sus trabajadores y proceda a tomar las medidas preventivas
correspondientes, tales como la remisión oportuna a controles médicos y la intervención sobre
los factores de riesgo presentes en el ambiente laboral de sus conductores.
Los exámenes miden la aptitud física y mental de los trabajadores.
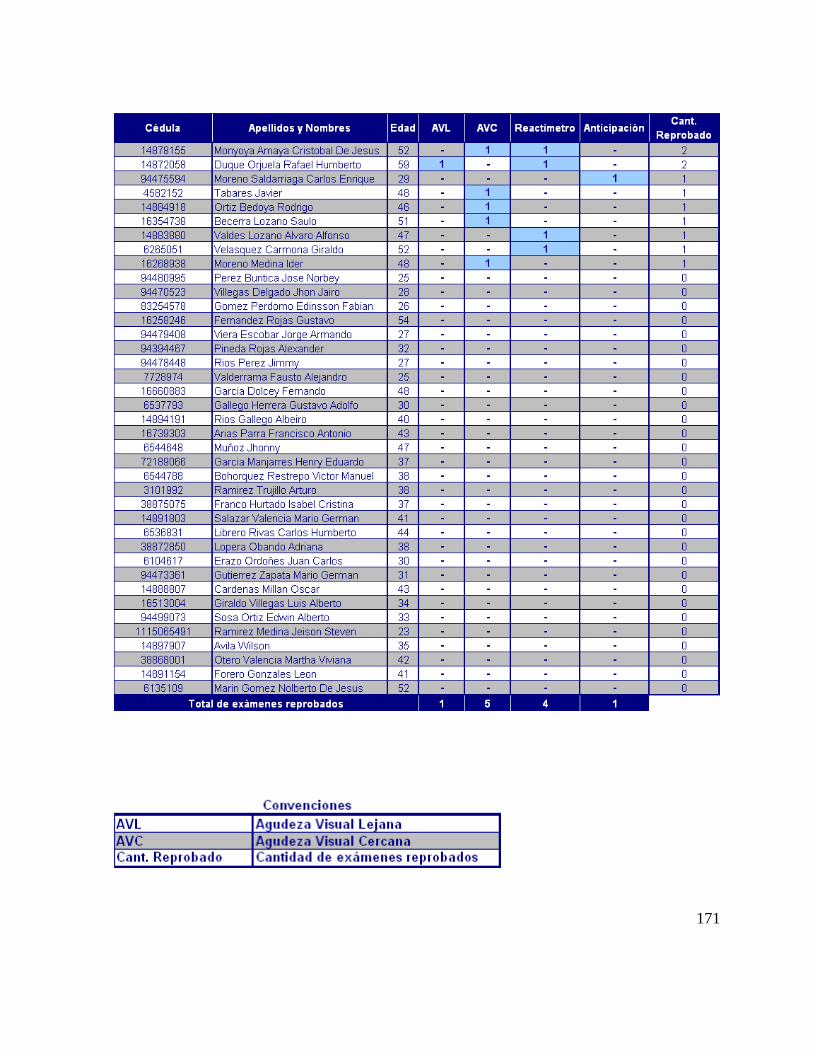
171

172
RESUMEN.
Respecto de las posibles causas del accidente, después de realizar el análisis del vehículo y
del croquis elaborado por la autoridad de carreteras entregado por Iceberg, se plantean dos
hipó tesis.
Hipó tesis 1. Pérdida de control del vehículo por parte del conductor debido a maniobra
incorrecta, operación deficiente, falta de reacción ante las condiciones de la vía, descenso y
curva pronunciada, negligencia o dolo por parte del conductor.
Como se mencionó, no es muy claro que el vehículo haya alcanzado una velocidad que
produjera la pérdida de control del mismo por parte del conductor, esto se contrasta con la
distancia de caída (17.90 metros), y la distancia que el conductor afirma haber recorrido sin
frenos.
De otro lado no se evidencia la presencia de testigos que validen la información suministrada
por el conductor.
Hipó tesis 2. Pérdida de control del vehículo debido a probable falla en el sistema de frenos.
Esta hipó tesis parece no tener asidero de acuerdo con los resultados obtenidos.
Para verificar la posible ocurrencia del evento debido a esta causa, se ha realizado una
inspección que ha tratado de ser exhaustiva, teniendo en cuenta el estado del vehículo y las
limitaciones de información sobre la operación de este en el instante del accidente.
Es importante realizar dos actividades complementarias.
Se sugiere recuperar la información del computador del vehículo, utilizando el sistema insite
de Cummins, y del GPS para determinar las condiciones de operación antes del accidente, en
particular la velocidad del motor, marcha en la que estaba funcionando, presión en el sistema
de aire, accionamiento del freno de motor, y otros parámetros de interés.
Revisión detallada de los componentes del sistema de frenos en particular válvula de pedal y
válvulas relay.
Además sería importante obtener información acerca de la geometría de la vía hasta 500
metros antes de la curva en la cual se produjo el accidente, con el fin de estimar los escenarios
posibles, en particular el de la velocidad desarrollada por el peso del vehículo más la carga.
Sin tener conocimiento detallado de la misma, de acuerdo con información recogida, se
establece que la vía tiene una característica conocida como de repechos y que en realidad la
pendiente pronunciada comienza al pasar la curva.

173
El operador del vehículo argumenta que iba a pasar de quinto a cuarto cambio y no fue
posible hacerlo, porque el vehículo ya había adquirido una velocidad que no lo permitió.
Además tenía aplicado el freno de motor.
La validación de esta hipó tesis seria corroborada en consecuencia con los resultados de la
inspección al sistema de frenos.
PLAN DE ACCION.
En consecuencia con las hipó tesis planteadas y con el objeto de utilizar el accidente como
una lección aprendida, además de profundizar más en la determinación d la causa raíz de
este, se propone realizar las siguientes actividades;
• Revisión de componentes del sistema de frenos válvula de pedal, válvula relay.
• Descargar y analizar información del computador del vehículo. (Insite).
• Analizar con más elementos de juicio la información sobre la integridad de cada uno
de los componentes del sistema de frenos.
• Conseguir la información sobre la topografía y características geométricas de la vía.
• Investigar posible negligencia del conductor.
• Revisar el programa de mantenimiento en cuanto a la periodicidad de las rutinas a los
diferentes sistemas relacionados, en particular el de frenos, axial como los
procedimientos de prueba de estos.

174
8. CONCLUSIONES.
Una vez desarrollado el estudio se obtienen las siguientes conclusiones.
Se desarrolló e implementó un algoritmo para la predicción de causa inmediata de accidentes
de tránsito utilizando dos bases de datos; una compuesta por 34000 registros y que contiene
bases de datos de diferentes tipos de accidentes en la ciudad de Bogotá en el año 2016, y la
otra con 880 registros tomada de la base de datos de la empresa Allianz entre los años 2009
y 2011 en diferentes empresas y zonas del país.
El modelo de propuesto consta de dos partes; la primera determina la causa próxima y la
segunda la causa raíz de los accidentes de tránsito.
Se aplicaron los algoritmos de clasificación redes neuronales artificiales y el algoritmo Naive
Bayes, para determinar la causa próxima de los accidentes en la base de datos 1, y algoritmos
de agrupamiento como clusstering, C-K means para identificar relaciones de agrupamiento
entre los atributos o variables de la base de datos de accidentalidad en Bogotá en el año 2016.
Para la base de datos de empresas de transporte se utilizó la técnica perceptròn multicapas..
Se realizó un análisis de las posibles causas básicas partiendo de la identificación de la causa
próxima y empleando el algoritmo de clasificación PART que suministra reglas de decisión
para determinar las causas básicas asociadas con la causa próxima determinada en la primera
parte.
La construcción de los modelos se realizó en el caso de la base de datos 1con menos datos
de los que contenía la base de datos inicial (34323) ya que el tamaño inicial saturaba la
capacidad de procesamiento del computador. En el caso de la base 2 , después de depurar los
880 registros disponibles, se obtuvo una base de datos reducida de 327 registros.
Para evaluar el desempeño de los dos modelos construidos, se utilizaron las métricas de uso
común en minería de datos.
Se aplicaron los modelos obtenidos con las dos bases de datos para aplicar el modelo de
predicción. Los resultados obtenidos fueron diferentes. Para el modelo basado en la base de
datos 1 se obtuvo como causa próxima “no respetar distancia de seguridad” y para el modelo
correspondiente a la base de datos 2: “invadír carril”.
Se compararon diferentes algoritmos de clasificación, encontrando que, para el caso bajo
estudio, las técnicas bayesianas producen resultados superiores a los de la red neuronal.
Para el modelo de causa próxima el perceptrón multicapas utilizando la base de datos de
accidentalidad en empresas de transporte produjo un porcentaje de 72% de aciertos.

175
Se recomienda utilizar bases de datos con información sobre características del conductor
como edad, genero, tiempo y clase de emisión de la licencia de conducción, antecedentes de
accidentalidad, del vehículo como tipo, año de fabricación.
De acuerdo con los modelos analizados, las causas de accidentalidad en Bogotá y en las
carreteras están relacionadas principalmente con el comportamiento de los conductores
frente a las reglas de tránsito.

176
9. BIBLIOGRAFÍA.
Allireza Pakgohar, Reza Sigari Tabrisi, Mohadeseh Khalili, Alliresa Esmaleili, 2011,The role
of human factor in incidence and severity of road crashes based on CART an LR regression
an data mining approach, Procedar Computer Science, 3, , 764-769.
Arévalo Carlos, 2017, Metodología y técnicas analíticas para la investigación de accidentes
de trabajo, Fundación Agustín de Betancourt.
Avellan Joaquin, Griselda Lopez , De Oya Juan, 2013, Analysis of traffic accidents severity
using decision rules via decision trees,, Expert systems and application, 40,.
Bahram Sadeghi Bigham, 2014, Road accident data analysis: a data mining approach, , indian
journal of scientific research, mayo.
Beltrán Pascual, 2015, Diseño e implementación de un nuevo clasificador de préstamos
bancarios a través de la minería de datos Tesis maestría.
Cevallos Alvaro, 2013, Guía metodológica para obtener patrones de accidentalidad laboral
usando data mining, Universidad de Piura, Tesis de grado Maestría.
Corso Cynthia Lorena, 2013, Aplicación de algoritmos de clasificación supervisada usando
weka.. Universidad Tecnologica Nacional Facultad regional Cordoba.
Día Hussein, 1997,Development and evaluation of neural network freeway incident detection
models using field data, Recuperado de
https://www.sciencedirect.com/science/article/pii/S0968090X97000168
Drummond Cris, Holter Robert C, 2006, Cost curves: an improved method for visualizing
classifier performance, Mach learn, , 95-130.
G Janani, N Ramya Devi, 2017, Road traffic accident analysis using data mining techniques.
Recuperado de
https://www.tandfonline.com/doi/full/10.1080/13588265.2015.1122278?src=recsys
García González Fernando, 2013, Aplicación de técnicas de minería de datos a datos
obtenidos por el Centro Andaluz de Medio Ambiente, Universidad de ranada,
Gutiérrez Cruz Doricela, 2017, Manual para practicas del departamento de computo, Taller
con Weka, , Universidad Autónoma del estado de México,
Halk Mark, Frank Eibe, , 2011, Practical data mining, , University of Waikato.

177
Harasri Rungratanaubul, 2011, An exploratory neural network model for predicting disability
severity from road traffic accidents in Thailand, , Third international conference on
knowledge and smart technologies.
Hassinger Rodríguez Mark Mirko, 2015, Aplicación técnica de minería de datos en
accidentes de tráfico, Tesis de Maestría, Universidad Politécnica de Valencia.
Introducción al aprendizaje automático y a la minería de datos con Weka.
JiangFeng Xi, Zhenhai Gao,1 Shifeng Niu,3 Tongqiang Ding,2 and Guobao Ning4,,2012, A
hybrid algorithm of traffic accident data mining on cause analysis, Mathematical problems
in engineering, Procedia Social and Behavioral Sciences, 160, 607-614.
Kirkbi Richard, Frank Eiber, 2004, Weka explorer user guide, University of Waikato,.
Liu Xiao,1995, Artificial neural networks for freeway incident detection, Transportation
research Journal,
Martin Luis, Baena Leticia, Barach Laura, Lopez Griselda, 2014, Using data mining
techniques to road safety improvement in spanish roads.
Montt Cecilia, 2013, Análisis de accidentes de tránsito con inteligencia computacional, 16
congreso chileno de ingeniería de transporte.
Niven Karen, 2004, Real time evaluation of health and safety management in the national
health service. Recuperado de http://www.hse.gov.uk/research/rrpdf/rr280.pdf
Olutayo V.A, Eleudire A.A ,2014, Traffic accident analysis using decision trees and neural
networks. Information Technology and Computer Science, 02, 22-28
Poojitha Shetty1, Sachin P C2, Supreeth V Kashyap3, Venkatesh Madi4, 2017, Analysis of road
accidents using data mining techniques, vol 4, tema 4.
Rojas Mauricio, 2015,Predicción de accidentes de tránsito utilizando redes neuronales
artificiales, Pontificia Universidad Católica de Valparaíso, Tesis de grado,
S.L González Ruiz. I Gómez Gallego, 2014, Algoritmos de clasificación y redes neuronales
en la observación automatizada de registros. Cuadernos de sicología del deporte, Vol 15, 1-
31-40.
Sami Ayramo, Pasi Pirtala, Janne Kauttonen, Kashif Naveed, Tomi Karkainnen, 2009,
Mining road traffic accidents, Tesis de maestria, University of Jyvaskyla, Finlandia..
Singh Maninder , Kaur Amrit , 2014, A Review on Road Accident in Traffic System,
International Journal of Science and Research,

178
Taamneh Madahr M, 2026,Data mining techniques for traffic accident modeling and
prediction in the united arab emirates, Journal of Transportation Safety and Security,
Takaya Saito, Marc Reinsbeier, 2015, The precision recall curve is more informative than
the ROC plot when evaluating binary classifiers on imbalanced datasets, , Plos One,
Tuba Kecesi, Ozcan Arsla, 2017, SHARE technique: a novel approach to root cause analysis
of ship accidents. Safety science 96. 1-21.
Vásquez Rodolfo, Causas de los accidentes de tránsito desde una visión de la medicina social,
el binomio alcohol-tránsito, Red Mes Uruguay, 2004, 20, 178-186.
Velazco Avendaño Juana Yenny, 2017, redes neuronales aplicadas al análisis de datos,
H Wallen Waner ,Dream 3.0 (Driving reliability and error analysis method), 2008.
Shirley A Cotreras Ulloa, John A Loyola Díaz, Modelo dinámico sistémico; caso análisis de
accidentes de tránsito en Trujillo Peru,
179
ANEXOS
ANEXO 1. FORMULARIO REGISTRO POLICIAL ACCIDENTE DE TRANSITO.

180
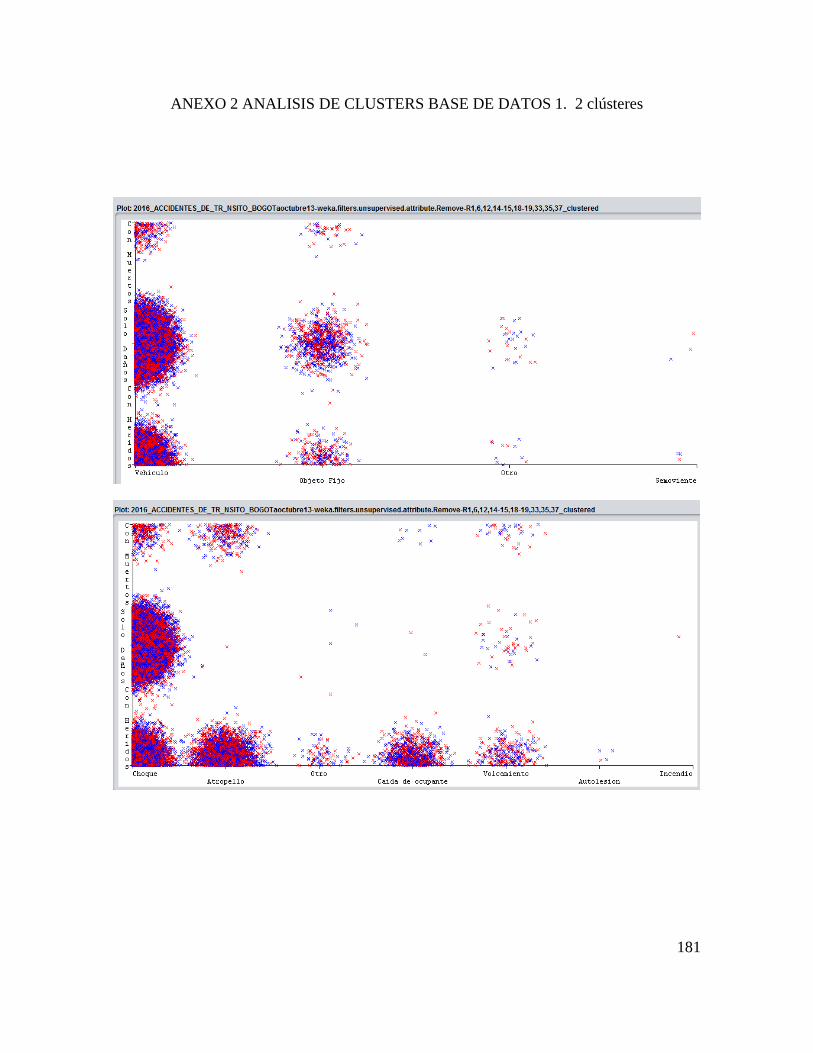
181
ANEXO 2 ANALISIS DE CLUSTERS BASE DE DATOS 1. 2 clústeres
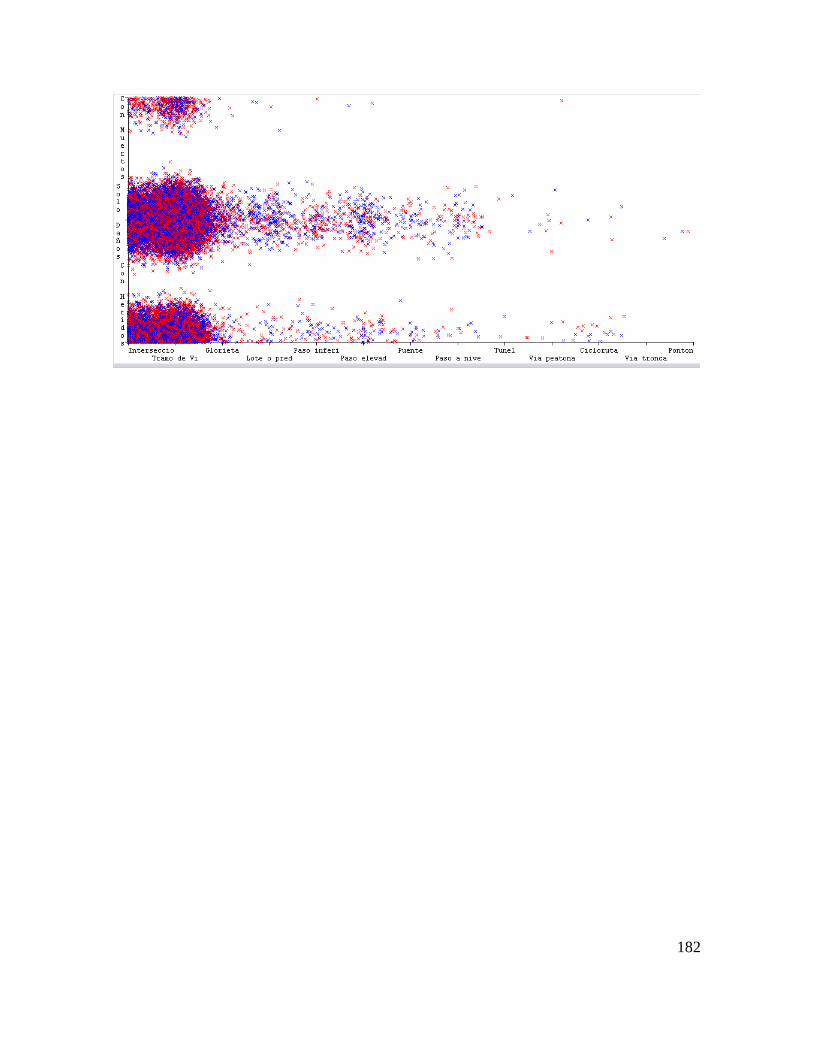
182
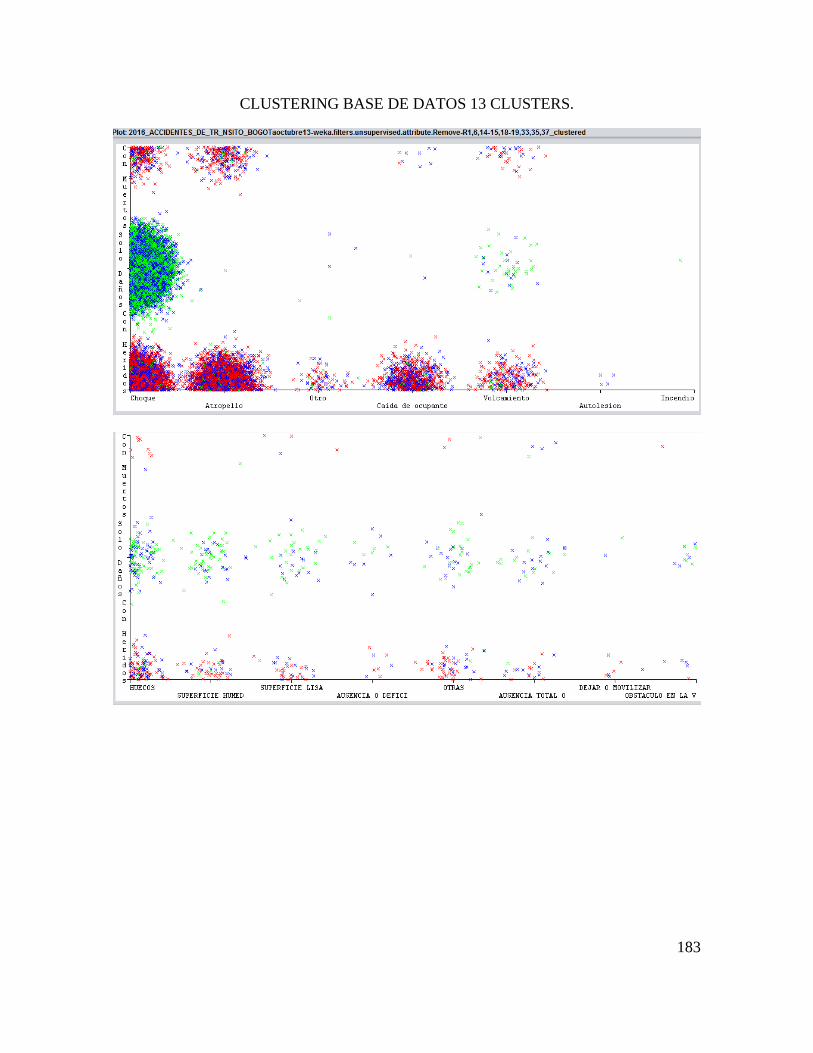
183
CLUSTERING BASE DE DATOS 13 CLUSTERS.
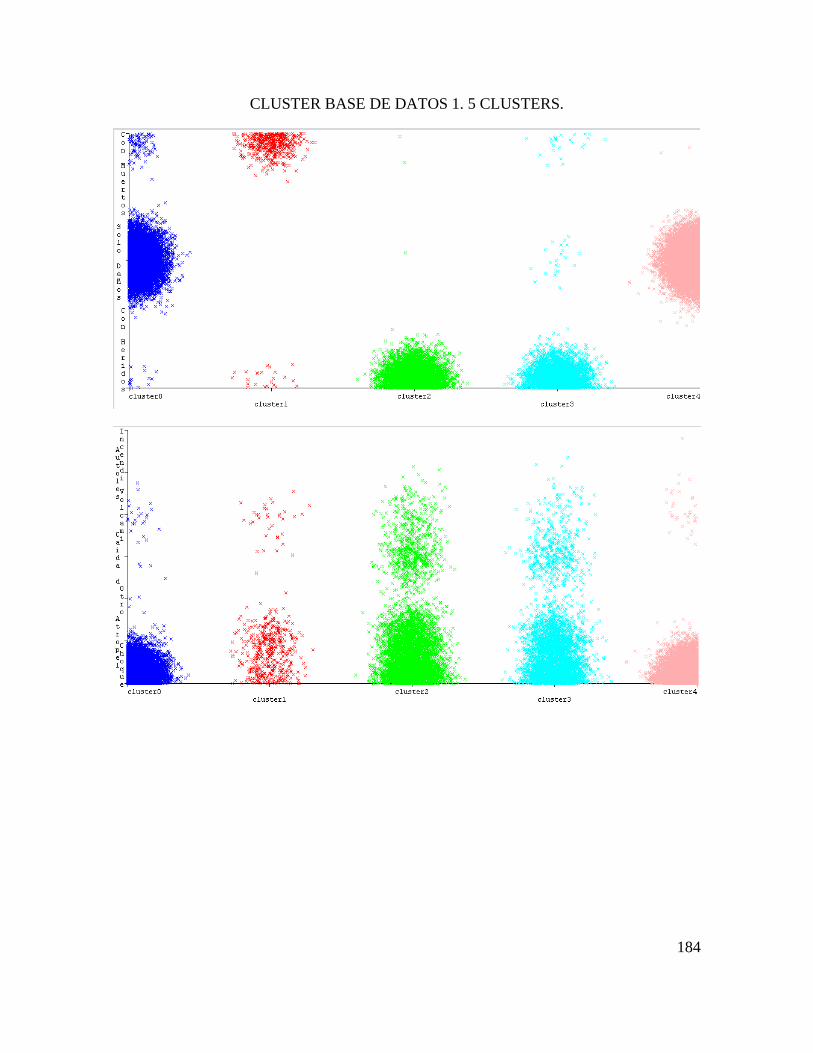
184
CLUSTER BASE DE DATOS 1. 5 CLUSTERS.
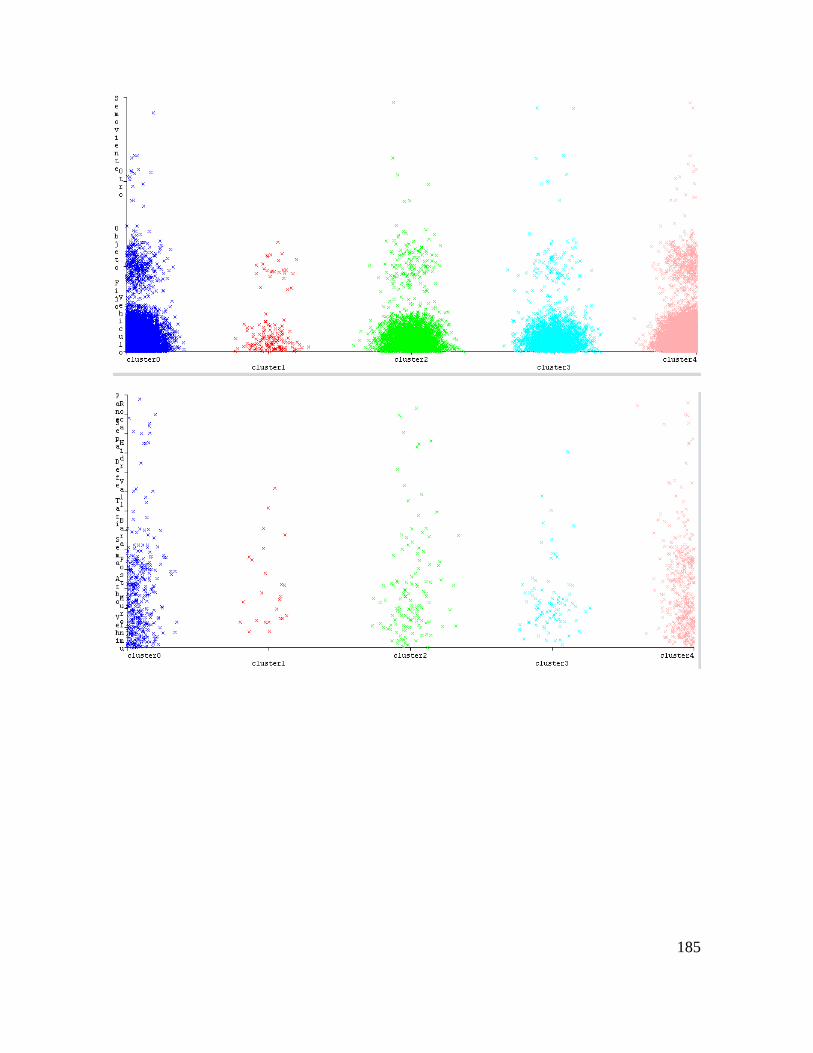
185
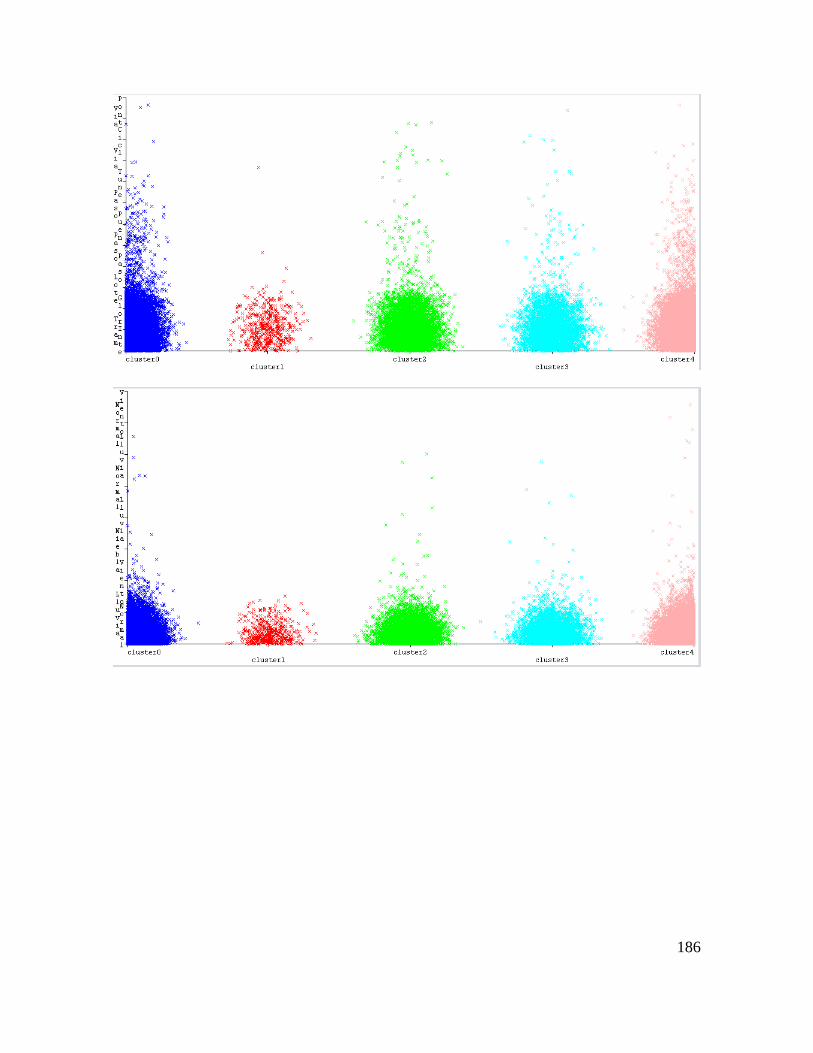
186
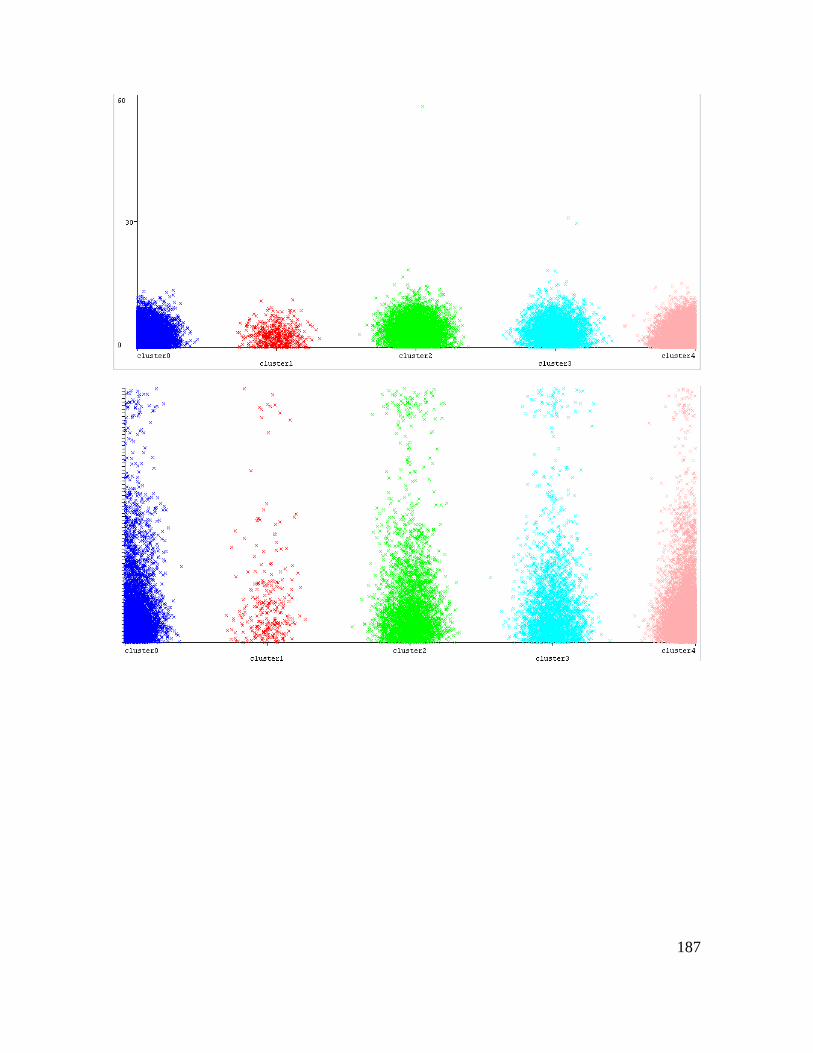
187
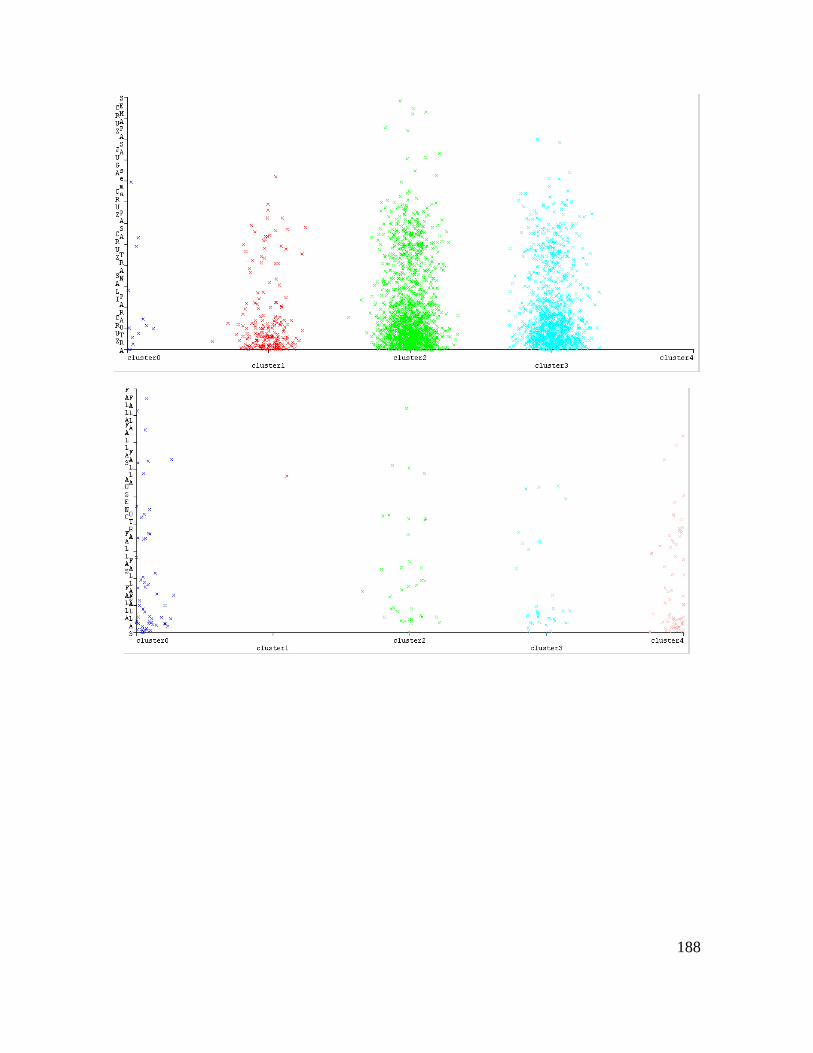
188
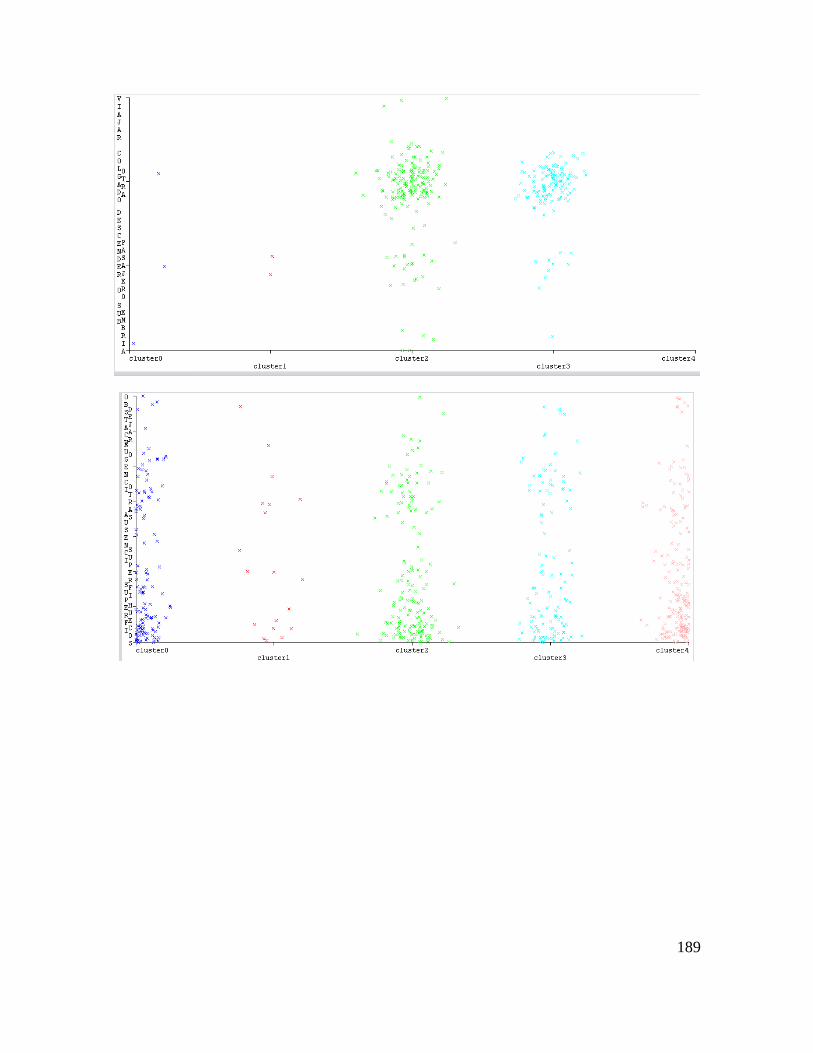
189

190
ANEXO 3 RELACION ENTRE Y GENOTIPOS Y ENTRE GENOTIPOS SEGÚN
DREAM 3.0.
CONSECUENCIAS
ANTECEDENTES Acción
temprana
Acción tardía inacción Exceso de
velocidad
Velocidad
baja
No
mantener
distancia de
seguridad
Dirección
equivocada
Exceso de
fuerza
Fuerza
insuficiente
Objeto
adyacente
MIEDO
Accidentes en intersecciones.
Sobrepasos
invasión de
carril.
Cambio de
carril
Accidentes en intersecciones.
Sobrepasos
invasión de
carril.
Cambio de
carril
Freno o
maniobra tardía
para evitar
colisión con vehículo por
delante
Accidentes en
intersecciones
pasar semáforo
en rojo, no respetar
señales de
pare.
Sobrepasos
invasión de
carril. No hace nada para
evitar
accidente con
vehículo en dirección
contraria.
Cambio de carril. No ve
otro vehículo
al hacer la
maniobra El conductor
no toma acción
para evitar
colisión con carro delante
de él (frenar o
maniobrar).
Accidentes en
intersecciones:
el conductor
llega a la intersección
con mayor
velocidad de lo esperado.
Tomar una
curva
demasiado rápido.
Sobrepaso
demasiado rápido.
Colisionar con
un vehículo delante debido
a exceso de
velocidad.
Colisión por conducir más
despacio de
lo esperado
por otros conductores.
El
conductor mantiene
una
distancia
muy pequeña
con el
vehículo
delante de él.
Accidentes en
intersecciones.
Realizar cruces
prohibidos. Cambio de
carril en vía
recta o curva.
Conducir en
contravía.
Accidentes
de salir de
carril por
sobre giro en la dirección.
El conductor
gira más bruscamente
de lo
esperado por
otros conductores.
Accidentes
por frenado
insuficiente.
El conductor
frena con
poca fuerza o los frenos
no
responden.
El
conductor
pisa el
acelerador en lugar
del freno
FATIGA
Bajo la influencia
de sustancias
Discapacidad
funcional súbita
Limitación temporal de acceso
Falla de equipo
Viento lateral
fuerte
Mal juzgamiento
de tiempo
Mal juzgamiento
de distancia

191
ANEXO 3 CONTINUACION RELACION ENTRE GENOTIPOS.
ANTECEDENTES B1 B2 B3 C1 C2 D1 E1 E2 E3 E4 E5 E6 E7 F1 F2 F3 F4 F5 F6 G1 G1 G2 G3 G4 G5 H1 H2 H3 I1 J1 J2 K1 K2 L1 L2 L3 L4
Pérdida de
observación (B1)
X
Observación
tardía (B2)
X X
Observación falsa
(B3)
X X
Apreciación
errónea de
intervalo de
tiempo (C1)
X
Apreciación
errónea d e la
situación (C2)
X
Miedo (E1) X X X x
Desatención (E2) X X X X X
Fatiga (E3) X X X X X
Bajo la influencia
de sustancias (E4)
X X X X X X X X
Búsqueda de
éxitos(E5)
x
Perdida funcional
instantánea (E6)
X X X X x
Estrés sicológico
(E7)
X X X X X x
Perdida funcional
permanente (F1)
X X X X X

192
Expectativa de
ambiente vía
estable (F3)
X X X X
Bajo la influencia
de sustancias (F4)
x x
Sobreestimación
de capacidad (F5)
x
Falta de conocim X X X X X X
iento competencia
(F6)
Problema
temporal de
iluminación (G1)
X X X X
Problema
temporal de sonido
(G2)
X X X X
Problema
permanente de
iluminación(H1)
X X X X
Obstrucción
temporal de la
visión G3)
X X X X
Información
incorrecta (G5)
X
Problema
permanente de
sonido (H2)
X X X X
Obstrucción
permanente de la
visión (H3)
X X X X
Falla de equipo
(I1)
X X X X X X X X X X X
Visibilidad
reducida (J1)
X X X X X X

193
Obstrucción
temporal para ver
(k1)
X X X
Obstrucción
permanente de la
visión (K2)
X X X
Señalización
insuficiente (L1)
X
Fricción reducida
(L2)
X
Degradación de la
superficie d e la
vía (L3)
X
Objeto en la vía
(L4)
X
Geometría
inadecuada de la
vía (L5)
X X X
Transmisión
inadecuado desde
usuarios de otra
vía (M1)
X X X
Transmisión
inadecuada desde
otro ambiente de
vía. (M2)
X X X X
Presión del tiempo
(N1)
X X
Horas de trabajo
excesivas (N2)
X X
Actividad física
pesada antes de
conducir(N3)
X X

194
Características
impredecibles del
sistema (P4)
X X X
NO DEFINIDO X X X X X X X X X X X
Diseño inadecuado
de la vía (Q1)
X
Inadecuado
mantenimiento m
de la vía (O2)
X X X
Inadecuado diseño
de la vía (Q2)
X X X X
Entrenamiento
inadecuado (N4)
Falla de equipo
(I1)
Diseño inadecuado
de la cabina (P1)
X X X
Inadecuado
mantenimiento del
vehículo (O1)
X
Diseño inadecuado
de dispositivos de
comunicación (P1)
X
Diseño inadecuado
de estructuras del
vehículo (P3)
X
Sin definir

195

196
ANEXO 4 MATRIZ DE PELIGROS Y RIESGOS. VER ANEXO DIGITAL EN EXCEL

197
ANEXO 5 PRUEBAS SICOSENSOMETRICAS.
Capacidad visual en:
Visión perimétrica
Agudeza visual, visión cercana, visión lejana y visión en profundidad
Visión nocturna, visión en encandilamiento y recuperación al encandilamiento
Discriminación de colores
Capacidad auditiva:
Se evalúa cada oído y la capacidad de orientación auditiva en cinco frecuencias entre los
500 a 8.000 Hz y desde 10 hasta los 70 decibeles.
Coordinación motriz:
Coordinación bimanual, coordinación manual (ojo-mano) y capacidad de reacción a un
estímulo (coordinación ojo-pie).
Estas evaluaciones se realizan bajo parámetros internacionales y estándares
preestablecidos y tienen sólo el carácter de tamizaje, que indica si el evaluado se
encuentra o no dentro de los rangos correspondientes. No se consideran como examen
de diagnóstico médico como tal y se recomienda a cada persona realizar control médico
en el área de salud que corresponda (optómetra, oftalmólogo, fonoaudiólogo, Audiólogo,
Terapeuta, etc.,) si el resultado está fuera de los rangos.
Estas pruebas tampoco determinan si el trabajador es “apto” o “no” para desempeñar un
oficio o labor determinada.
INFORME DE RESULTADOS
Resultados obtenidos en las Evaluaciones Psicosensométricas realizadas a 39 personas
en la ciudad de Buga
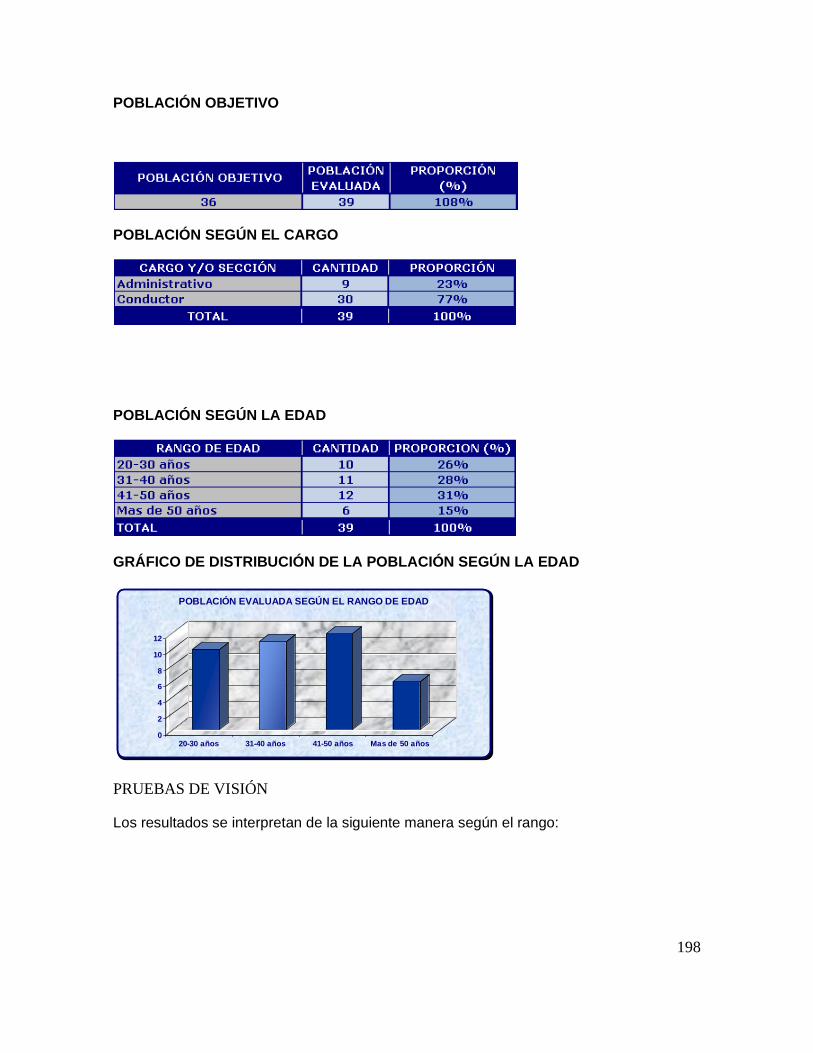
198
POBLACIÓN OBJETIVO
POBLACIÓN SEGÚN EL CARGO
POBLACIÓN SEGÚN LA EDAD
GRÁFICO DE DISTRIBUCIÓN DE LA POBLACIÓN SEGÚN LA EDAD
PRUEBAS DE VISIÓN
Los resultados se interpretan de la siguiente manera según el rango:
0
2
4
6
8
10
12
20-30 años 31-40 años 41-50 años Mas de 50 años
POBLACIÓN EVALUADA SEGÚN EL RANGO DE EDAD

199
Algunos exámenes de visión nos determinan únicamente si el evaluado VE o NO VE.
El Gabinete Psicotécnico evalúa la visión de las personas mediante los siguientes
exámenes:
: Evalúa el Campo Visual, es decir, la visión periférica. Determina la capacidad de una
persona de percatarse de móviles u objetos ubicados a sus costados.
Parámetros mundiales sugieren que las personas tengan como mínimo 70 grados de
campo visual. Nuestro Sistema de Evaluación permite descubrir a conductores cuyo
campo visual sea de solo 40 grados.
Una persona que no tiene el campo visual mínimo establecido de 70º, no tienen la
capacidad de percatarse de móviles ubicados inmediatamente a sus costados, por lo que
al cambiar de vía solo ven lo que ocurre hacia atrás y no hacia los lados.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
Ningún evaluado amerita remisión para examen confirmatorio.
APROBARON
Son los evaluados cuyos resultados obtenidos en la evaluación de los DOS OJOS, están por encima del parámetro de aprobación establecido (mayor o igual al 70%, es decir, visión 30/20.)
NO APROBARON
Son los evaluados cuyos resultados obtenidos en la evaluación de los DOS OJOS, están por debajo del parámetro de aprobación establecido (menor que 70%, es decir, visión 30/20.)
EN OBSERVACIÓN
Son los evaluados cuyos resultados obtenidos en la evaluación de los DOS OJOS, están por debajo del parámetro de aprobación establecido (menor que 70%, es decir, visión 30/20.) Un ojo aprueba y el otro no.
200
AGUDEZA VISUAL, VISIÓN CERCANA, VISIÓN LEJANA: Evalúan la calidad de Visión que
se tiene con respecto a lo que está mirando. Define la capacidad de discernir las cosas y
los detalles de estas.
Los Parámetros Internacionales Estándar para evaluar la Agudeza Visual son:
Tabla Snellen
Eficiencia
Visual
(Dist. En
pies).
Eficiencia
Visual (%)
20/200 10%
20/100 20%
20/70 25%
20/60 30%
20/50 40%
20/40 50%
20/30 70%
20/25 80%
20/20 100%
20/15 130%
20/10 200%
El Resultado mínimo de Eficiencia Visual que se considera debe tener una persona al
momento de conducir es del 20/30 que corresponde al 70% de la Agudeza Visual.
Una persona pasa el examen si obtiene este resultado; sin embargo presenta una ligera
deficiencia en la visión, por lo cual se recomienda ir al especialista para que efectúe el
tratamiento correspondiente.
Del total de la muestra evaluada, se estiman los siguientes resultados:

201
Agudeza Visual Lejana
Un evaluado amerita remisión para examen confirmatorio y ocho deben permanecer en
observación en Agudeza Visual Lejana.
Agudeza Visual Cercana
AGUDEZA VISUAL LEJANA
Aprobaron
76%
No Aprobaron
3%
En Observación
21%

202
Cinco evaluados no aprobaron y ameritan remisión para examen confirmatorio y siete
están en observación en Agudeza Visual Cercana.
VISIÓN EN PROFUNDIDAD: Mide la capacidad de determinar las distancias de ubicación
de los objetos en el espacio.
Cada año se presentan alrededor de 1200 accidentes por “mal rebasamiento”.
El mal rebasamiento puede generar un choque frontal o un volcamiento, accidentes que
más engrosan el número de muertos en las estadísticas. El mal rebasamiento en la
mayoría de los casos, más que una imprudencia del conductor, obedece al mal cálculo
que se hace con respecto al espacio que se tiene para rebasar un vehículo, producto de
fallas en la visión en profundidad. Se ubica un vehículo a 300 metros cuando en realidad
se encuentra a 200 metros. En otros casos, se estima que se trata de un gran camión
ubicado a una distancia amplia cuando en realidad es un pequeño furgón a muy corta
distancia.
Estas diferencias en las apreciaciones de las distancias no le conceden el tiempo
suficiente para rebasar en el espacio que se estimó amplio, generando así un choque
frontal o un volcamiento al esquivar.
La prueba evalúa la Capacidad de Visión en Profundidad en 3 niveles diferentes. El
evaluado debe identificar al menos 2 de los 3 niveles para pasar el examen con el 70%.
AGUDEZA VISUAL CERCANA
Aprobaron
69%
No Aprobaron
13%
En Observación
18%

203
Si el evaluado identifica 3
niveles
Aprueba el Test con el 100%
Si el evaluado identifica 2
niveles
Aprueba el Test con el 70%
Si el evaluado identifica 1
nivel
No Aprueba el Test
Si el evaluado identifica
ningún nivel
No Aprueba el Test
Tomando en cuenta el cuadro anterior, tenemos que, del total de la muestra evaluada, se
determinaron los siguientes resultados:
Ningún evaluado amerita remisión para examen confirmatorio.
Discriminación de Colores: Evalúa la visión cromática.
Este examen permite identificar a conductores que confunden los colores de los
elementos que se encuentran en las vías o en sus inmediaciones. Pueden ver como tierra
o arena lo que es agua. Hay quienes ven café lo que es azul o ven verde lo rojo. En otros
casos no pueden distinguir las ramas de las hojas en los árboles.

204
Estas personas tienen grandes dificultades para distinguir con antelación el tipo de señal
dispuesta en la vía, y sólo la agudeza visual les permite reconocer la señal, sin contar con
la opción del color, que es lo primero que se advierte normalmente
Del total de la muestra evaluada, se determinaron los siguientes resultados:
Según los resultados obtenidos, ningún evaluado amerita examen confirmatorio en el Test
Discriminación de Colores.
VISIÓN NOCTURNA: Evalúa la capacidad visual en condiciones de poca luminosidad.
Así como encontramos conductores que no ven en condiciones de encandilamiento o
mucha luminosidad, hay otros que no ven con poca luminosidad. Esto quiere decir que no
es seguro para estas personas manejar durante la noche.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
De acuerdo con los resultados obtenidos, ningún evaluado amerita remisión para examen
confirmatorio.
VISIÓN EN ENCANDILAMIENTO: Mide la capacidad de visión de una persona, al
enfrentarse a un fuerte estímulo lumínico.

205
Este examen permite identificar a personas que pierden su capacidad de visión en un
grado importante, al enfrentarse en la noche a vehículos con luces altas.
Todas las personas nos encandilamos en estas condiciones, pero la mayoría podemos
distinguir aún el camino y las condiciones de éste.
Hay personas que no distinguen nada a su alrededor cuando se le enfrenta a una alta
intensidad lumínica. Estos son conductores de alto riesgo, pues en esa circunstancia no
se percatarán de vehículos que les preceden a velocidades menores o de obstáculos en
la vía.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
Ningún evaluado amerita remisión para examen c
RECUPERACIÓN AL ENCANDILAMIENTO (tiempo en segundos): Mide la capacidad de la
recuperación visual luego de enfrentarse a un fuerte estímulo lumínico.
La capacidad de recuperación al encandilamiento se transforma en un examen
importantísimo, toda vez que los conductores no deben tener problemas para recuperarse
antes de 3 segundos después de haber enfrentado luces enceguecedoras.
Según el Parámetro Estándar, una persona en condiciones normales, debe recuperar su
visión después del encandilamiento en un tiempo no mayor a 5 segundos. (Menor o Igual
a 5 seg.)
Las personas que no se recuperan en menos de 5 seg. al encandilamiento y se
encuentran conduciendo a 80 Km./hr, alcanzan a recorrer cerca de 111 metros en esta
condición sin percatarse de cambios en la vía.
Del total de la muestra evaluada, se determinaron los siguientes resultados:

206
Según los resultados obtenidos, ningún evaluado amerita examen confirmatorio en el Test
de Recuperación al Encandilamiento.
PRUEBAS DE AUDICIÓN
Aspecto importante en la evaluación sensométrica es la audición, sentido por el cual
percibimos sonidos que llegan a nosotros a distintas frecuencias y en diferentes
intensidades y emitidos desde lugares que debemos estar en capacidad de ubicar.
¿Percibe el conductor tal o cual tipo de sonido? ¿Ubica el conductor dónde está la fuente
de ese sonido?
En las pruebas de audición se tomaron en cuenta dos aspectos importantes:
CAPACIDAD AUDITIVA DE CADA OÍDO: Mide la capacidad auditiva de cada oído en
diferentes frecuencias y decibeles.
CAPACIDAD DE ORIENTACIÓN AUDITIVA: Mide la capacidad que tiene una persona de
determinar de donde proviene un sonido.
El parámetro que se tuvo en cuenta para establecer los resultados de los evaluados en la
empresa es de máximo 40 dB (decibeles) en todas las frecuencias, ya que se tuvo en
cuenta la intensidad de ruido que había en el entorno. Esto significa que el evaluado
debía escuchar el estímulo en 40 dB o por debajo de este.
Del total de la muestra evaluada, se determinaron los siguientes resultados:

207
En los resultados, algunos evaluados escucharon con los dos oídos los estímulos
auditivos dentro de los parámetros establecidos “Aprobaron”, otros escucharon con los
dos oídos los estímulos auditivos pero fuera de los parámetros establecidos, “No
aprobaron” y los evaluados que se encuentran “en observación” son el resultado de
alguna deficiencia en alguno de los dos oídos. (Un oído está bien y otro no).
Los Evaluados que están en observación o no aprobaron el Test, se recomienda que
vayan al especialista indicado (Fonoaudiólogo – Otorrinolaringólogo).
Los conductores manejan vehículos que pesan toneladas, las cuales generan distintos
tipos de ruidos en su funcionamiento normal. También en muchos casos acusan sus
desperfectos a través de diferentes ruidos anormales como por ejemplo un reventón de
ruedas, una pieza metálica que arrastra, roces anormales en el sistema de frenos,
rodamientos fundidos o neumáticos sin aire (desinflados).
Estos diferentes ruidos están relacionados con la seguridad en la conducción y, a su vez,
con las toneladas que se desplazan a distintas velocidades. Por otra parte, ésta el medio
ambiente y las condiciones generales de tránsito en las vías, donde una vez más seremos
advertidos de situaciones especiales a través de los ruidos:
el camión que nos rebasa, los neumáticos de otro vehículo que chillan en una frenada, las
bocinas, las diferentes sirenas de los vehículos de emergencia, pasos ferroviarios y otros.
Para esto es indispensable que el conductor aspirante a la licencia de conducir tenga una
audición normal en términos de intensidades e identificación de diferentes frecuencias, al
menos las más comunes como, neumáticos desinflados, etc.

208
PRUEBAS DE COORDINACIÓN MOTRIZ
Las Pruebas de Coordinación Motriz permiten identificar personas que no presentan la
habilidad de coordinar movimientos simultáneos. En la conducción esta habilidad nos
permite, por ejemplo, accionar la palanca de cambios con una mano mientras con la otra
cambiamos de dirección con el timón.
El Test de Reactímetro mide la capacidad de reaccionar rápidamente ante un estímulo o
suceso repentino, y esta habilidad no se adquiere con el tiempo ni la experiencia.
Capacidad de Coordinación Manual - Coordinación Motriz ojo-mano (Test de Punteo): El
Test de punteo es un medidor de coordinación de vista y mano, identifica a conductores que
tienden a perder la concentración en una actividad determinada.

209
Este examen es realizado por el TEST DE PUNTEO, el cual es un medidor de reflejos y
de coordinación motriz. Establece capacidad de concentración y permanencia, número de
aciertos y número de errores, ante estímulos visuales.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
Ningún evaluado amerita remisión para examen confirmatorio
Capacidad de Coordinación Bimanual – Coordinación Viso-motriz (Test de palanca):
Factores que se tuvieron en cuenta para el resultado:
Es un examen que identifica a conductores que pueden llegar a presentar dificultad en
coordinar los movimientos manos-vista en la conducción (volante, palanca de cambios,
etc.).
Ejemplo: La mano izquierda gira el volante mientras la mano derecha pasa el cambio de
3° a 2°, y al tiempo debe mirar para todos los lados para efectuar el giro de una manera
segura.
Este examen se realiza con el TEST DE PALANCA el cual tiene por finalidad evaluar
objetivamente la capacidad de percepción y coordinación visomotor del examinado. El
examinado realiza una tarea diferente con cada mano.
Este examen determina:
Aciertos
Debería presentar más de 24
aciertos
Errores
Debería presentar menos de 23
aciertos
Permanencia en el Acierto
Debería ser mayor o igual a 4 seg.

210
Tiempo de recorrido de un trazado.
Número de errores o veces que abandona el trazado.
Tiempo de reacción para salir del error.
Identifica la coordinación bimanual.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
Ningún evaluado amerita remisión para examen confirmatorio.
Capacidad de Reacción a un Estímulo – Coordinación Motriz ojo-pie (Test de
Reactímetro):
La reacción al freno, permite determinar cuántos metros recorre un conductor antes de
aplicar los frenos frente a una emergencia.
El tiempo de reacción de frenado es lo que demora el conductor desde que se decide a
aplicar los frenos del vehículo hasta el instante en que realmente comienza a aplicarlos.
Esta prueba está hecha para que el evaluado responda ó reaccione ante el estímulo
visual inesperado, con el pie al frenado en máximo 43 centésimas de segundo (0.43 seg.)
en promedio.
Este examen se realiza con el REACTÍMETRO, el cual permite medir automáticamente el
tiempo promedio transcurrido entre un estímulo visual y la reacción con el pie al frenar,
medido en centésimas de segundo. Indica además la aceleración y frenadas anticipadas.
Del total de la muestra evaluada, se determinaron los siguientes resultados:

211
Según los resultados obtenidos, cuatro evaluados ameritan examen confirmatorio en el
Test de Reactímetro.
TEST DE ANTICIPACIÓN
Mediante el test de anticipación podemos evaluar posibles desviaciones de percepción de
la velocidad que tenga un operador. En esta prueba el evaluado debe realizar un ejercicio
de auto- control para no precipitar ni anticipar una respuesta.
El test cuenta con una fase de ensayo la cual permite al evaluado adaptarse al manejo de
los mandos y al examinador poder dar las explicaciones.
La prueba se presenta al evaluado a través de un móvil el que avanza a una velocidad
constante y de forma rectilínea ocultándose al sujeto, éste debe apreciar, usando su
habilidad perceptiva, el momento que estima pasará el móvil frente a una señal que se
encuentra en la parte superior de la zona oculta. En este test se presenta al examinado
diferentes recorridos, tres en dirección de derecha a izquierda y tres en dirección de
izquierda a derecha, evitando así efectos como lateralidad y direccionalidad. Los
parámetros establecidos están hechos según estudios realizados en Chile para selección
de conductores de vehículos motorizados.
Del total de la muestra evaluada, se determinaron los siguientes resultados:
0
5
10
15
20
25
Crítico Regular Medio Bueno Excelente
TEST DE ANTICIPACIÓN
Recommended

















