
FACULTAD DE INFORMÁTICA UNIVERSIDAD POLITÉCNICA DE MADRID
UNIVERSIDAD POLITÉCNICA DE MADRID
FACULTAD DE INFORMÁTICA
TRABAJO FIN DE CARRERA
HERRAMIENTA DE SOPORTE DE PATRONES DE DISEÑO AUTORES: José María Pérez Vence & Alejandro García García TUTOR: Ana María Moreno Sanchez-Capuchino

1
Resumen
En nuestros tiempos, el desarrollo del software es un negocio que mueve grandes cantidades
de recursos, tanto económicos como de personas. Es necesario desarrollar aplicaciones en
tiempos y esfuerzos cada vez más pequeños para mejorar la productividad del ejercicio. En
esta tesis se desarrolla un proceso para aplicar patrones de diseño software a diseños
específicos, mediante la creación de un sistema experto y una librería para generar
documentos de intercambio de metamodelos.
Abstract
Nowadays, development of software is a business that moves a large amount of resources,
both financial and people. It is necessary to develop applications in time and effort getting
smaller to improve the productivity of the exercise. In this thesis is developed a process to
apply software design patterns to specific designs by means of an expert system and a library
for generating metamodels exchange documents.

2
Índice
Resumen ........................................................................................................................................ 1
Abstract ......................................................................................................................................... 1
Índice ............................................................................................................................................. 2
1 Introducción .......................................................................................................................... 4
1.1 Presentación del problema ........................................................................................... 4
1.2 Descripción de la estructura del documento ................................................................ 7
2 Material base – Directrices de usabilidad ............................................................................. 8
3 Objetivos ............................................................................................................................. 14
3.1 Roles y responsabilidades ........................................................................................... 14
3.1.1 Usuario/Desarrollador ......................................................................................... 14
3.1.2 Administrador y/o Experto .................................................................................. 14
3.2 Descripción de objetivos ............................................................................................. 15
3.2.1 Administración .................................................................................................... 15
3.2.2 Usuario/Desarrollador ......................................................................................... 16
3.3 Satisfacer objetivos ..................................................................................................... 17
3.3.1 Administración .................................................................................................... 17
3.3.2 Usuario/Desarrollador ......................................................................................... 18
4 Conocimientos ..................................................................................................................... 20
4.1 Sistema Experto ........................................................................................................... 20
4.2 UML ............................................................................................................................. 21
4.2.1 MOF ..................................................................................................................... 22
4.3 XML .............................................................................................................................. 23
4.4 XSD .............................................................................................................................. 24
4.5 Lógica funcional (Acciones, flujos y estados) .............................................................. 25
4.6 XMI .............................................................................................................................. 26
5 Investigación ....................................................................................................................... 27
5.1 Guía de diseño ............................................................................................................. 28
5.1.1.1 Generar xsd (XML SchemaDocument) ............................................................ 29
5.2 Guía de elicitación ....................................................................................................... 38
5.2.1 Bases de Datos .................................................................................................... 39
5.2.2 Generar XSD (XML SchemaDocument) ............................................................... 40
5.2.2.1 Automatizar la definición de responsabilidades. ............................................ 42
5.2.2.2 Manejo de modelos en el sistema. ................................................................. 43

3
5.3 Ofrecer modelos reusables ......................................................................................... 54
5.3.1 Primera aproximación ......................................................................................... 55
5.3.1.1 XML Data Binding ............................................................................................ 56
5.3.1.2 De XML a UML ................................................................................................. 61
5.3.1.3 Reflexiones de la primera aproximación ......................................................... 62
5.3.2 Segunda aproximación ........................................................................................ 63
5.3.2.1 XMI .................................................................................................................. 63
5.3.2.2 Aplicación de XMI en el proyecto .................................................................... 64
5.3.2.3 UMLGraph ....................................................................................................... 65
5.3.2.4 Otras librerías parecidas.................................................................................. 66
5.3.2.5 Construcción de una librería ........................................................................... 67
5.3.2.6 XMI & StarUML ................................................................................................ 67
5.3.2.7 Representación XMI ........................................................................................ 68
5.3.2.8 Representación en objetos ............................................................................. 99
5.3.3 Reflexiones de la segunda aproximación .......................................................... 100
6 Desarrollo .......................................................................................................................... 101
6.1 Especificación de Requisitos Software ...................................................................... 101
6.2 Diseño ........................................................................................................................ 104
6.2.1 Casos de uso ...................................................................................................... 104
6.2.2 Clases ................................................................................................................. 107
6.3 Implementación ........................................................................................................ 113
6.4 Instalación ................................................................................................................. 118
7 Resultados ......................................................................................................................... 119
8 Conclusiones y trabajos futuros ........................................................................................ 120
9 Bibliografía ........................................................................................................................ 121
Anexo 1. Patrones de usabilidad-Undo ..................................................................................... 123

4
1 Introducción
Este trabajo forma parte de una investigación que ha sido reflejada en dos proyectos final de
carrera. El otro proyecto final de carrera lleva por título “Herramienta de soporte de patrones
de diseño. Parte I. Administrador” y cuyo autor ha sido José María Pérez Vence. La estructura
común a ambos proyectos comprenderá la introducción, el material base, los objetivos y la
investigación A partir de este último capítulo mencionado, cada tomo particularizará su
proyecto en base al ámbito que desarrolla, Administrador o Usuario/Desarrollador.
Con este documento se pretende presentar una herramienta para ayudar a desarrolladores
software a la hora de incluir patrones de diseño a sus proyectos. Concretamente, el estudio de
aplicación se centra en patrones de usabilidad generados por investigadores del área de
Ingeniería del Software de la Facultad de Informática de la UPM. Sin embargo, posteriormente
veremos que el marco de uso del proceso/herramienta se extiende a cualquier patrón
software definido sobre un estándar descrito en la sección 2. Material Base.
1.1 Presentación del problema
El problema raíz al cual se plantea dar solución se podría resumir en la necesidad de
automatizar y simplificar el proceso mediante el cual un desarrollador software puede aplicar
un patrón de diseño a su proyecto, en tiempo y coste efectivos. Para ello se plantea la
construcción de una herramienta que dé soporte a dicho proceso.
El caso de uso base, es decir, el proceso manual que realiza un desarrollador para aplicar los
patrones, parte de la siguiente situación:
1. Un desarrollador quiere introducir en sus modelos un determinado patrón de
usabilidad (por ejemplo, “deshacer”).
2. Existen una serie de patrones de usabilidad ya creados por investigadores del área de
Ingeniería del Software de la UPM, cuyo formato es en papel y en el que se incluyen,
entre otros, una guía de responsabilidades a satisfacer por el sistema software que los
incluya y unos modelos de diseño genéricos que se particularizarán en función de las
responsabilidades elegidas.
3. El desarrollador define aquellas responsabilidades que necesita incluir.
4. El patrón indica qué componentes del modelo genérico son aplicables según las
responsabilidades elegidas.
5. El desarrollador construye sus modelos específicos teniendo en cuenta los
componentes de los modelos genéricos recomendados en los patrones.

5
A medida que profundizamos en ello, determinamos varios problemas inherentes al
mencionado y con tal peso que formaría el groso de una fase de investigación previa a la
resolución del presente trabajo.
Como hemos indicado, partimos de unos patrones en formato papel que contienen modelos
de diseño y un conjunto de responsabilidades, más adelante en la sección 2. Material base –
Directrices de usabilidad, se explicara cómo están definidos los patrones de diseño, pero a este
nivel podemos definir los modelos de diseño como diagramas de diseño y las
responsabilidades como flujos y estados, ¿cómo los introducimos en nuestro sistema? ¿Cómo
podemos modificarlos en función de las necesidades del usuario? ¿Cómo manejar los flujos de
todos los patrones otorgando una cierta ambigüedad para que la solución esté abierta para la
inclusión de patrones sin tener que modificar el sistema? Y, finalmente, ¿cómo ofreceremos el
resultado una vez terminado el proceso, para que los modelos puedan ser utilizados por el
desarrollador?
Todas estas cuestiones son, a alto nivel, con las que nos hemos encontrado y a las que da
solución el proceso que hemos definido.
Con el fin de tener una visión más clara del mismo, a continuación se muestra en la figura 1
como se representa el proceso a modo de caja negra:
Figura 1: proceso genérico de uso de los patrones

6
La explicación de la figura 1 es muy simple. A través de una guía de elicitación y de las
respuestas proporcionadas por el usuario se construye documentos específicos. La guía de
elicitación expresa el procedimiento para la construcción de un sistema software. Se pretende
conseguir un sistema que a partir de la documentación en papel y de las respuestas que indica
un usuario, genere documentación y modelos de diseño personalizados.
Este es el primer ejemplo donde podemos diferenciar claramente la separación del trabajo en
dos. Una parte estará encargada de la administración interna del proyecto, más
concretamente en cómo introducir los documentos proporcionados en el sistema. La otra
parte se encarga de transformar la información que conforma el sistema en documentos
personalizados gracias a la aportación de un usuario, es decir, estará dirigida a un
usuario/desarrollador.

7
1.2 Descripción de la estructura del documento
En esta sección describiremos la estructura de la que está compuesta esta tesis.
Primeramente, explicaremos de manera detallada en qué consiste el material proporcionado
por el departamento de Ingeniería del Software de la UPM, es decir, analizaremos en
profundidad los patrones de usabilidad proporcionados y qué podemos extraer de esta
información.
A continuación describiremos los objetivos. Puesto que la investigación ha sido divida en dos
trabajos, los objetivos están divididos separando el trabajo general a realizar por roles. De esta
forma, se irá componiendo el documento en base a estos roles.
Una vez descritos los objetivos, debemos realizar una explicación sobre los conceptos que
vamos a manejar a lo largo del trabajo.
Más adelante entraremos en la investigación. En la investigación se ha seguido dividiendo el
trabajo en partes más pequeñas siguiendo los objetivos sobre los que se ha investigado y por
tanto, que se han abordado en la etapa de investigación.
Después, explicaremos el desarrollo de la aplicación realizada para solventar el problema
adherido al rol que documenta esta tesis.
De manera resumida, la estructura del documento consta de:
Material Base – Directrices de usabilidad
Objetivos
o Usuario/Desarrollador
o Administrador
Conocimientos (Antecedentes)
Investigación
o Introducir modelos en el sistema
o Automatizar la definición de responsabilidades
o Manejo de modelos en el sistema
o Ofrecer modelos reusables
Desarrollo
Resultados
Conclusiones y trabajos futuros
Bibliografía

8
2 Material base – Directrices de usabilidad
Como hemos indicado, inicialmente partimos de la necesidad de automatizar el proceso
mediante el que se aplican los patrones de usabilidad facilitados por el departamento de
Ingeniería del Software. Estos patrones consisten en unas directrices de usabilidad que
redactan de forma completa la descripción y el uso de cada uno de los patrones. El documento
original relativo al patrón de usabilidad “Undo”, se proporciona en el Anexo1.
Cada patrón facilitado se compone de una serie de pautas y recomendaciones a seguir para
llevar a cabo su implementación. Cada guía consta de:
- Resumen: primer acercamiento al patrón donde se explica de manera muy resumida
en qué consiste, que problemas resuelve, en qué tipo de contexto podemos
encontrarnos ese problema, mecanismos que incluye, familia a la que pertenece, etc.
Figura 2: Resumen

9
- Tabla Guía de Elicitación de Usabilidad: esta tabla agrupa los diferentes aspectos que
iremos desglosando más profundamente en los siguientes módulos. Es decir, por cada
recomendación que da el HCI, se relaciona por un lado con métodos de elaboración
del patrón, por otro las preguntas que deben realizarse a los usuarios y por último,
muestra unos ejemplos.
Figura 3: guía de elicitación
- Modelo de Casos de Uso: diagrama general y completo de los casos de uso del patrón.
Figura 4: modelo de casos de uso

10
- Agrupación de las responsabilidades del sistema: diagrama de estado del sistema
donde se muestra de forma gráfica las responsabilidades del sistema. A través de esta
guía elaboraremos el flujo y los estados que contendrá el formulario final.
Figura 5: responsabilidades del sistema
Abreviaturas y significado:
[Id]_Q[n]
[Id]_L[n]
U_Q1: Pregunta 1 del patrón Undo.
U_L3: Lista 3 del patrón Undo.
[Id] Identificador de patrón
[n] Número de orden Q Pregunta L Lista

11
- Tabla Guía de Diseño Genéricas: relaciona las responsabilidades del sistema con sus
componentes de forma genérica.
Figura 6: guía de diseño general
- Tabla Guía de Diseño Concreta: relaciona las responsabilidades del sistema con sus
componentes a nivel de objeto.
Figura 7: guía de diseño específica

12
- Diagrama de clases: Diagrama de clases completo del patrón.
Figura 8: modelo de clases

13
- Diagramas de secuencia: un diagrama de secuencia por cada interacción.
Figura 9: modelo de interacción
Todas estas directrices muestran cada patrón de forma completa, es decir, de algún modo
debemos mapear esta información genérica a elementos software para que en fases
posteriores dichos elementos software puedan ser particularizados según las decisiones del
usuario.
Como podemos apreciar, existe una clara clasificación de los elementos facilitados en las
directrices:
Documentación en formato gráfico UML: disponemos de los tres tipos de modelos
más útiles y comunes: modelo de casos de uso, modelo de secuencia y modelo de
clases.
Documentación en formato flujo de estados: corresponde a la Agrupación de las
responsabilidades del sistema. El flujo muestra las responsabilidades que debe
tener el diseño que estamos creando en función de ciertas condiciones.
Documentación en formato de texto o tabla: el formato del resto de la
documentación facilitada corresponde con algún tipo de formato office.

14
3 Objetivos
Una vez planteado el problema del cual partimos, automatizar el proceso mediante el cual un
usuario/desarrollador puede aplicar patrones a sus diseños, podemos pasar a la siguiente fase.
Ésta se centra en determinar los objetivos del proyecto, describirlos y definir cómo van a ser
satisfechos. Así mismo, se especificarán los roles y responsabilidades de los participantes del
sistema.
3.1 Roles y responsabilidades
Antes de explicar en qué consisten los objetivos, explicaremos los roles y responsabilidades de
los actores involucrados en el sistema. Posteriormente, una vez conocidos los roles, podremos
comprender la separación lógica establecida a lo largo de toda la tesis.
3.1.1 Usuario/Desarrollador
El usuario/desarrollador será nuestra base de respuesta y tendrá la responsabilidad de la
solución obtenida por el sistema. Deberá ir respondiendo a las preguntas que el sistema le irá
proponiendo y de forma totalmente transparente se irá conformando el resultado que se
entregará como fin. No es necesario que tenga claro que patrones usará y de qué manera,
puesto que es lo que va a obtener del sistema, pero si deberá tener un conocimiento previo
sobre qué y en qué formato va a obtener la respuesta. Por lo tanto estamos hablando de que
el usuario deberá ser un actor especializado, que tenga conocimientos de diseño software.
3.1.2 Administrador y/o Experto
El administrador será el encargado de introducir la base de conocimientos, es decir, de que el
sistema experto contenga toda su inteligencia/lógica para desarrollar las preguntas y que a
partir de las respuestas pueda también construir el resultado personalizado. En ciertas
ocasiones, el administrador también podrá actuar como usuario/desarrollador en caso de que
éste sea el que introduzca los datos (respuestas) en el sistema. El administrador incorporará
todo el conocimiento necesario al sistema a través de una importación de datos externos.

15
3.2 Descripción de objetivos
A continuación se listan los objetivos que se han fijado. Se engloban en dos grupos definidos
en base al destino: Administración y Usuario/Desarrollador.
3.2.1 Administración
Introducir modelos a nuestro sistema.
Los modelos de diseño asociados a cada patrón son diagramas de casos de uso, clases y
colaboración en formato UML. Es necesario definir un procedimiento a través del cual
mapear dichos diagramas a elementos que una aplicación informática pueda tratar.
Ambigüedad para el intercambio de conocimiento.
El sistema no debe ser estático, sino que debe ser capaz de procesar y asimilar nuevo
conocimiento, en forma de nuevos patrones o modificaciones en los mismos. De este
modo, es necesario que el conocimiento no esté embebido en el sistema.
Ofrecer modelos reusables.
Puesto que el fin más primitivo del proyecto es ofrecer la posibilidad de obtener modelos
basados en unos patrones genéricos, es de vital importancia que los modelos que
ofrezcamos tengan un formato que pueda ser utilizado en cuantos más ámbitos mejor. Por
tanto es necesario estudiar los estándares y tendencias sobre el modelado de diseño para
que el producto final posea el valor de seguir un estándar extendido y que las aplicaciones
actuales (y futuras) puedan utilizarlo.

16
3.2.2 Usuario/Desarrollador
Automatizar la definición de responsabilidades.
Puesto que cada patrón contiene un conjunto de responsabilidades que pueden incluirse o
no al resultado final, es necesario crear un flujo mediante el que el sistema sea capaz de
conducir y asimilar las particularizaciones sobre los patrones existentes en el sistema.
Manejo de modelos en el sistema.
Al mismo tiempo que el sistema transcurre por el flujo de elicitación, pasa por diferentes
estados, en los cuales para pasar al siguiente han de realizarse acciones sobre los
elementos de los modelos. Finalmente se entregarán diagramas como elemento más
representativo. De este modo, es necesario establecer cómo van a traducirse estas
acciones.
Así mismo es importante abstraer al usuario de toda la lógica, relativamente compleja, que
el sistema maneja para determinar y procesar las acciones que alteran los modelos.
Entorno de la aplicación
Para que el proceso pueda ser utilizado es preciso crear una aplicación a la que los
usuarios puedan acceder y utilizar. Puesto que existen múltiples formas de presentarlo es
necesario definir un entorno de aplicación.

17
3.3 Satisfacer objetivos
En este apartado, plantearemos cómo dar solución a los objetivos marcados. Es importante
puntualizar que el fin de la sección no es entrar en detalle en la solución implementada, ni
describir todas las posibilidades que hemos manejado, sino destacar qué conceptos hay que
tener en cuenta para satisfacer los objetivos. La sección en la que se detallan las soluciones y
decisiones es la sección 5. Investigación.
A continuación se describen dichos conceptos por objetivo y que a su vez se han agrupado en
objetivos de Administración y objetivos de Usuario/Desarrollador.
3.3.1 Administración
Introducir modelos a nuestro sistema
Como hemos indicado, los modelos de diseño software que contienen los patrones siguen
el lenguaje de modelado de sistemas de software más conocido y utilizado en la
actualidad, UML (Unified Modeling Language), referirse al apartado 4.2. UML.
Introducir los modelos al sistema pasa por construir entidades que pueda manejar, y por
tanto de algún modo, mapear diagramas UML a elementos software. Para ello, es
necesario encontrar o construir una librería que maneje esta información.
Por otro lado, también es importante recordar que el proceso que definimos se encargará
de particularizar los diseños de patrones a los requerimientos del usuario, y por tanto que
los modelos a personalizar deberán precargarse en el sistema previamente a su utilización.
Ambigüedad para el intercambio de conocimiento.
El propósito de este objetivo se centra en definir el mecanismo con el que se introducirá
conocimiento al sistema. De este modo, es necesario crear un lenguaje que el sistema
entienda y sepa procesar.
Para ello podemos pensar en un lenguaje de etiquetas, mediante el cual, el sistema una
vez leída una etiqueta sabe qué tiene que hacer con su contenido.
En este punto introduciremos el concepto de XML (Extensible Markup Language),
explicado en el apartado 4.3 XML. Gracias a él podemos satisfacer todas nuestras
necesidades en este ámbito, el sistema podrá leer y procesar el contenido de ficheros XML
y a su vez podremos introducir nuevos ficheros XML que correspondan a cuantos patrones
queramos introducir.
Ofrecer modelos reusables
En una primera instancia para satisfacer este objetivo, tenemos que conocer en qué
ámbitos pueden ser reusables los modelos que entreguemos. Comprobamos que son dos:
por un lado herramientas CASE para crear código a partir de modelos de diseño y por otro
herramientas de diseño para poder editar modelos.
Partimos con una gran ventaja y es que existe un estándar enormemente extendido para
el intercambio de meta-modelos, XMI (XML Metadata Interchange) desarrollado en el
apartado 4.6 XMI.

18
3.3.2 Usuario/Desarrollador
Automatizar la definición de responsabilidades
Como se ha indicado, este objetivo pasa por construir un flujo que abstraiga al usuario de
la lógica que el sistema sigue para concretar las responsabilidades del sistema por cada
patrón.
Para satisfacer dicho objetivo, el sistema debe definir y ofrecer al usuario unas preguntas a
modo de cuestionario, y a través de ellas pasar por diferentes estados.
Así mismo el comportamiento del sistema debe ser siempre el mismo para unas
condiciones determinadas.
Una vez explicado esto, debemos analizar en primera instancia que tipo de sistema vamos
a crear. Debido al carácter tan especifico del dominio, determinamos construir un sistema
experto. En la sección 4.1 Sistema Experto se define este concepto.
A continuación, debemos establecer qué conocimiento requerimos y definirlo:
Necesitaremos conocimiento de flujo, a qué estado pasará el sistema con cada condición,
y conocimiento de acciones, qué deberá hacer el sistema en cada estado en el que se
encuentre.
Manejo de modelos en el sistema
En este punto debemos presentar cómo satisfacer la necesidad de tratar los elementos
software que representan los modelos de diseño.
Como se ha indicado, a medida que el usuario pasa a través de la guía de elicitación se irán
definiendo las responsabilidades y por tanto es en este punto dónde debemos introducir
un mecanismo para personalizar los diagramas precargados (ver Introducir modelos a
nuestro sistema).
Cuando pensamos en estos mecanismos introducimos el concepto de acción, el cual está
desarrollado en el apartado 4.5 lógica funcional (Acciones, flujos y estados).
Entorno de la aplicación
Necesitamos crear una aplicación que parte de dos necesidades: poseer la lógica de un
sistema experto, y ser portable.
Estas premisas nos han llevado a pensar en centralizar el proceso y el conocimiento en un
sistema remoto, ofreciendo acceso a través de la red.
Lo ideal sería la construcción de una única aplicación que si introdujéramos algún cambio,
pudiera estar reflejado en todas las distribuciones del proyecto. Es por esto por lo que se
ha escogido un entorno web que permita mantener la consistencia de los cambios,
permita usar la herramienta sin necesidad de instalación y realice la labor de distribución.

19
Una vez realizado el análisis inicial, deberemos realizar el trabajo de especialización en el
campo que estamos trabajando y es por eso que la etapa más importante del proyecto sea la
investigación de lo que se puede llegar a crear a partir de conocimientos expertos.
Más adelante, considerando una especialización profunda en este ámbito, deberemos llegar a
la toma de decisiones, punto decisivo a la hora de tomar referencias de esfuerzo, puesto que
aprobar una decisión errónea nos llevará a un punto donde deberemos probablemente
retornar.
Puesto que nos veremos implicados dentro de un proceso iterativo, realizaremos cada una de
las fases que consta el proceso unificado tantas veces como nos sea necesario para alcanzar
nuestra meta.

20
4 Conocimientos
Una vez explicada la información facilitada, debemos analizar los conceptos en los que
debemos especializarnos y tecnologías que se adaptan a la construcción de la solución.
En los siguientes apartados veremos las definiciones y características de cada uno de ellos,
haciendo constancia de lo que aporta al sistema.
Puesto que no es el fin del proyecto el estudio de estas tecnologías, sino que han sido vitales
sus aplicaciones, en las siguientes secciones se presentan las descripciones de los mismos.
4.1 Sistema Experto
Los sistemas expertos son llamados así porque emulan el comportamiento de un experto en
un dominio concreto y en ocasiones son usados por éstos. Con los sistemas expertos se busca
una mejor calidad y rapidez en las respuestas dando así lugar a una mejora de la productividad
del experto.
Un sistema experto es un conjunto de programas que, sobre una base de conocimientos,
posee información de uno o más expertos en un área específica. Se puede entender como una
rama de la inteligencia artificial, donde el poder de resolución de un problema en una
aplicación, viene del conocimiento de un dominio específico. Estos sistemas imitan las
actividades de un humano para resolver problemas de distinta índole (no necesariamente
tiene que ser de inteligencia artificial). También se dice que un Sistema Experto se basa en el
conocimiento declarativo (hechos sobre objetos, situaciones) y el conocimiento de control
(información sobre el seguimiento de una acción).
Para que un sistema experto sea una herramienta efectiva, los usuarios deben interactuar de
una forma fácil, reuniendo dos capacidades para poder cumplirlo:
1. Explicar sus razonamientos o base del conocimiento: los sistemas expertos se deben
realizar siguiendo ciertas reglas o pasos comprensibles de manera que se pueda
generar la explicación para cada una de estas reglas, que a la vez se basan en hechos.
2. Adquisición de nuevos conocimientos o integrador del sistema: son mecanismos de
razonamiento que sirven para modificar los conocimientos anteriores. Sobre la base de
lo anterior se puede decir que los sistemas expertos son el producto de investigaciones
en el campo de la inteligencia artificial ya que ésta no intenta sustituir a los expertos
humanos, sino que se desea ayudarlos a realizar con más rapidez y eficacia todas las
tareas que realiza.
Normalmente se están mezclando diferentes técnicas o aplicaciones aprovechando las
ventajas que cada una de estas ofrece para poder objetivos de forma más segura. Un ejemplo
de estas técnicas sería nuestro sistema a desarrollar.

21
4.2 UML
Lenguaje Unificado de Modelado (LUM o UML, por sus siglas en inglés, Unified Modeling
Language) es el lenguaje de modelado de sistemas de software más conocido y utilizado en la
actualidad; está respaldado por el OMG (Object Management Group). Es un lenguaje gráfico
para visualizar, especificar, construir y documentar un sistema. UML ofrece un estándar para
describir un "plano" del sistema (modelo), incluyendo aspectos conceptuales tales como
procesos de negocio y funciones del sistema, y aspectos concretos como expresiones de
lenguajes de programación, esquemas de bases de datos y componentes reutilizables.
Es importante resaltar que UML es un "lenguaje de modelado" para especificar o para describir
métodos o procesos. Se utiliza para definir un sistema, para detallar los artefactos en el
sistema y para documentar y construir. En otras palabras, es el lenguaje en el que está descrito
el modelo.
Se puede aplicar en el desarrollo de software entregando gran variedad de formas para dar
soporte a una metodología de desarrollo de software (tal como el Proceso Unificado Racional o
RUP), pero no especifica en sí mismo qué metodología o proceso usar.
UML no puede compararse con la programación estructurada, pues UML significa Lenguaje
Unificado de Modelado, no es programación, solo se diagrama la realidad de una utilización en
un requerimiento. Mientras que, programación estructurada, es una forma de programar
como lo es la orientación a objetos, sin embargo, la programación orientada a objetos viene
siendo un complemento perfecto de UML, pero no por eso se toma UML sólo para lenguajes
orientados a objetos.
UML cuenta con varios tipos de diagramas, los cuales muestran diferentes aspectos de las
entidades representadas.
En UML 2.0 hay 13 tipos diferentes de diagramas. Para comprenderlos de manera concreta, a
veces es útil categorizarlos jerárquicamente.
Los Diagramas de Estructura enfatizan en los elementos que deben existir en el sistema
modelado:
Diagrama de clases
Diagrama de componentes
Diagrama de objetos
Diagrama de estructura compuesta (UML 2.0)
Diagrama de despliegue
Diagrama de paquetes
Los Diagramas de Comportamiento enfatizan en lo que debe suceder en el sistema modelado:
Diagrama de actividades
Diagrama de casos de uso
Diagrama de estados

22
Los Diagramas de Interacción son un subtipo de diagramas de comportamiento, que enfatiza
sobre el flujo de control y de datos entre los elementos del sistema modelado:
Diagrama de secuencia
Diagrama de comunicación, que es una versión simplificada del Diagrama de
colaboración (UML 1.x)
Diagrama de tiempos (UML 2.0)
Diagrama global de interacciones o Diagrama de vista de interacción (UML 2.0)
4.2.1 MOF
El Meta-Object Facility (MOF) también fue creado por el OMG (Object Management Group)
para la ingeniería basada en el modelo . La página oficial de referencia se puede encontrar en
el sitio web de OMG (http://www.omg.org/).
MOF parte del Lenguaje de Modelado Unificado (UML), el OMG tenía la necesidad de
una arquitectura de modelado para definir el estándar UML. MOF se ha diseñado como una
arquitectura de cuatro capas. Proporciona un modelo de meta-meta en la capa superior,
llamada la capa “M3”. Este modelo M3 es el lenguaje utilizado para la construcción de
metamodelos MOF, llamada “M2-modelos”. El ejemplo más prominente de un nivel 2 del
modelo MOF es el metamodelo UML, el modelo que describe el propio UML. Estos M2-
modelos describen los elementos de la M1-capa, y por lo tanto M1-modelos. Estos serían, por
ejemplo, modelos de escritos en UML. La última capa es la “M0” o “capa de datos”. Se utiliza
para describir los objetos del mundo real.
Más allá del modelo M3, MOF describe los medios para crear y manipular modelos y
metamodelos mediante la definición de interfaces CORBA que describen las
operaciones. Debido a las similitudes entre el M3-modelo y la estructura de los modelos UML,
los metamodelos MOF son usualmente modelados como diagramas de clases UML. Un nivel de
soporte de MOF es XMI , que define un formato de intercambio basado en XML para los
modelos en el M3, M2 o M1-capa.

23
4.3 XML
XML, siglas en inglés de eXtensible Markup Language (lenguaje de marcas extensible), es un
metalenguaje extensible de etiquetas desarrollado por el World Wide Web Consortium (W3C).
Es una simplificación y adaptación del SGML y permite definir la gramática de lenguajes
específicos (de la misma manera que HTML es a su vez un lenguaje definido por SGML). Por lo
tanto XML no es realmente un lenguaje en particular, sino una manera de definir lenguajes
para diferentes necesidades. Algunos de estos lenguajes que usan XML para su definición son
XHTML, SVG, MathML.
XML no ha nacido sólo para su aplicación en Internet, sino que se propone como un estándar
para el intercambio de información estructurada entre diferentes plataformas. Se puede usar
en bases de datos, editores de texto, hojas de cálculo y casi cualquier cosa imaginable.
XML es una tecnología sencilla que tiene a su alrededor otras que la complementan y la hacen
mucho más grande y con unas posibilidades mucho mayores. Tiene un papel muy importante
en la actualidad ya que permite la compatibilidad entre sistemas para compartir la información
de una manera segura, fiable y fácil.
XML, con todas las tecnologías relacionadas, representa una manera distinta de hacer las
cosas, más avanzada, cuya principal novedad consiste en permitir compartir los datos con los
que se trabaja a todos los niveles, por todas las aplicaciones y soportes. Así pues, el XML juega
un papel importantísimo en este mundo actual, que tiende a la globalización y la
compatibilidad entre los sistemas, ya que es la tecnología que permitirá compartir la
información de una manera segura, fiable, fácil. Además, XML permite al programador y los
soportes dedicar sus esfuerzos a las tareas importantes cuando trabaja con los datos, ya que
algunas tareas tediosas como la validación de estos o el recorrido de las estructuras corre a
cargo del lenguaje y está especificado por el estándar, de modo que el programador no tiene
que preocuparse por ello.
Vemos que XML no está sólo, sino que hay un mundo de tecnologías alrededor de él, de
posibilidades, maneras más fáciles e interesantes de trabajar con los datos y, en definitiva, un
avance a la hora de tratar la información, que es en realidad el objetivo de la informática en
general. XML, o mejor dicho, el mundo XML no es un lenguaje, sino varios lenguajes, no es una
sintaxis, sino varias y no es una manera totalmente nueva de trabajar, sino una manera más
refinada que permitirá que todas las anteriores se puedan comunicar entre sí sin problemas,
ya que los datos cobran sentido.

24
4.4 XSD
XSD (XML Schema) es un lenguaje de esquema utilizado para describir la estructura y las
restricciones de los contenidos de los documentos XML de una forma muy precisa, más allá de
las normas sintácticas impuestas por el propio lenguaje XML. Se consigue así una percepción
del tipo de documento con un alto nivel de abstracción. Fue desarrollado por el World Wide
Web Consortium (W3C) y alcanzó el nivel de recomendación en mayo de 2001.
El término "XML Schema" es utilizado con varios significados dentro del mismo contexto de
descripción de documentos, y es importante tener en cuenta las siguientes consideraciones:
1. "XML Schema" es el nombre oficial otorgado a la recomendación del W3C, que elaboró
el primer lenguaje de esquema separado de XML (la definición de tipo de documentos
(DTD) forma parte de XML).
2. Es habitual referirse a los esquemas como "XML schema" de forma genérica, pero se
recomienda utilizar el término “documento esquema” (schema document) o
"definición de esquema"(schema definition), y reservar “XML Schema” para la
denominación de este lenguaje específico.
3. Aunque genéricamente se utilice "XML schemas", XSDL (XSD Language) es el nombre
técnico de los lenguajes de esquema de XML como:
Definición de Tipo de Documento (DTD)
Namespace Routing Language (NRL)
Document Schema Definition Languages (DSDL)
Document Definition Markup Language (DDML)
Document Structure Description (DSD)
Schema for Object-Oriented XML (SOX)
XML Schema es un lenguaje de esquema escrito en XML, basado en la gramática y pensado
para proporcionar una mayor potencia expresiva que las DTD, menos capaces al describir los
documentos a nivel formal.
Los documentos esquema (XSD) se concibieron como una alternativa a las DTD, más
complejas, intentando superar sus puntos débiles y buscar nuevas capacidades a la hora de
definir estructuras para documentos XML. El principal aporte de XML Schema es el gran
número de tipos de datos que incorpora. De esta manera, XML Schema aumenta las
posibilidades y funcionalidades de aplicaciones de procesado de datos, incluyendo tipos de
datos complejos como fechas, números y strings.
La programación en Schema XML se basa en Namespaces. Cada Namespace contiene
elementos y atributos que están estrechamente relacionados con el Namespace para que a la
hora de definir un elemento o un atributo, siempre se creará una conexión entre los diferentes
campos de éste. Además, esta forma de trabajar nos permite relacionar elementos que no
están en el mismo Namespace.
Después de escribir un Schema XML se puede confirmar la correcta realización mediante la
validación de esquemas XML.

25
4.5 Lógica funcional (Acciones, flujos y estados)
Como se muestra en la figura 5 del apartado 2 Material base, la guía de elicitación se presenta
como un tipo de diagrama de flujo.
Un diagrama de flujo es una representación gráfica de un algoritmo o proceso. Se utiliza en
disciplinas como la programación, la economía, los procesos industriales y la psicología
cognitiva. Estos diagramas utilizan símbolos con significados bien definidos que representan
los pasos del algoritmo, y representan el flujo de ejecución mediante flechas que conectan los
puntos de inicio y de término.
Un diagrama de flujo siempre tiene un único punto de inicio y un único punto de término.
Además, todo camino de ejecución debe permitir llegar desde el inicio hasta el término.
Simbología y significado:
Rectángulo: Actividad (Representa la ejecución de una o más actividades o
procedimientos).
Rombo: Decisión (Formula una pregunta o cuestión).
Paralelogramo: Producto (Representa un resultado).
Rectángulo redondeado: Agrupación (Representa responsabilidades)
Figura 10: diagrama de flujo del sistema

26
4.6 XMI
XMI o XML Metadata Interchange (XML de Intercambio de Metadatos) es el nombre que
recibe el estándar para el intercambio de metamodelos usando XML. Su principal objetivo es
permitir un intercambio de metainformación entre herramientas de modelado basadas en
UML y repositorios de metainformación basados en MOF en entornos distribuidos
heterogéneos. Incluye tres estándares: XML, UML y MOF.
Al utilizar XML permite una gran flexibilidad en la estructura de la información, ya que esta no
se especifica como sucede en HTML, lo que permite tener más de una vista de un documento
al estar separado el contenido de la estructura.
XMI es el único estándar para el intercambio de información en entornos de trabajo
distribuido donde se colabora para conseguir un objetivo común.
La especificación para el intercambio de diagramas fue escrita para proveer una manera de
compartir modelos UML entre diferentes herramientas de modelado. En versiones anteriores
de UML se utilizaba un esquema XML para capturar los elementos utilizados en el diagrama;
pero este esquema no decía nada acerca de cómo el modelo debía graficarse.
Para solucionar este problema la nueva Especificación para el Intercambio de Diagramas fue
desarrollada mediante un nuevo esquema XML que permite construir una representación SVG
(Scalable Vector Graphics). Típicamente esta especificación es solamente utilizada por quienes
desarrollan herramientas de modelado UML.
UML es un estándar que define un lenguaje de modelado orientado a objetos que es
soportado por una gama de herramientas de diseño gráfico y MOF es un estándar que define
un marco de trabajo para definir modelos de metainformación y proporciona herramientas
con interfaces programadas para almacenar y acceder a metainformación en un repositorio. Es
por esto, que el hecho de incluir tres estándares como XML, UML y MOF, permite a los
desarrolladores de sistemas distribuidos compartir modelos de objetos y otra información
sobre Internet. De esta forma se consigue un modelado, una gestión y una publicación de
metainformación estándar a través de la web, utilizando UML y MOF para el diseño de
metamodelos y XML para transferir la información.
27
5 Investigación
En este apartado se desarrollará el cuerpo de la investigación que se ha realizado para
construir la solución.
Se ha separado en tres grandes grupos, según los tres procesos el que el sistema manejará,
guía de diseño, guía de elicitación y ofrecer modelos reusables.
Cada proceso está descrito en dos apartados diferentes en los que encontraremos una
descripción del proceso, las investigaciones de tecnologías estudiadas en relación a las
necesidades, y el resultado que se obtuvo, manteniendo en su presentación un orden
cronológico.
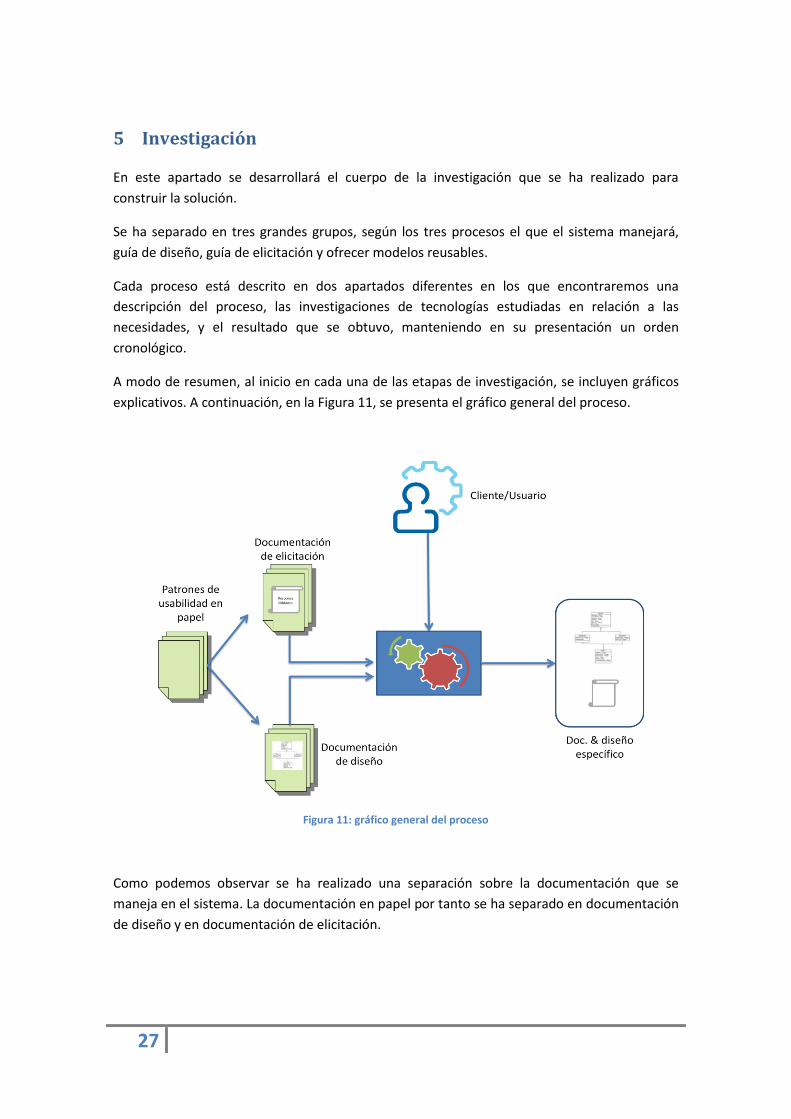
A modo de resumen, al inicio en cada una de las etapas de investigación, se incluyen gráficos
explicativos. A continuación, en la Figura 11, se presenta el gráfico general del proceso.
Figura 11: gráfico general del proceso
Como podemos observar se ha realizado una separación sobre la documentación que se
maneja en el sistema. La documentación en papel por tanto se ha separado en documentación
de diseño y en documentación de elicitación.

28
5.1 Guía de diseño
Haciendo referencia a los objetivos, la guía de diseño satisface el objetivo de Introducir
modelos a nuestro sistema, y por tanto, hacemos referencia a la parte de administración. La
guía de diseño es el proceso que define todos los elementos que inicialmente deben estar
cargados de forma invariable en el sistema. Estos elementos a los que se hacen mención son
todos aquellos elementos relacionados con el diseño software. La figura 12 explica de forma
gráfica de qué se trata:
Figura 12: guía de diseño
Para la creación de un modelo, independientemente de la manera que queramos
estructurarlo, debemos tener en cuenta las características del mismo, es decir, no podemos
considerar que la estructura prevista de inserción de datos para el modelo de clases, vaya a
funcionar de forma parecida para el modelo de casos de uso, ya que los elementos internos de
cada modelo son totalmente diferentes.
Otra duda que se plantea frente a una personalización, es si una creación de cero de un
modelo sería correcta. Una construcción progresiva a través de inclusiones simples de
elementos parece lo más lógico, pero quizá no sea lo más óptimo para algunos casos, puesto
que las personalizaciones de algunos modelos comprenden pocas variaciones frente al modelo
completo. Partiendo de esta duda, cabe la posibilidad de contemplar una precarga que facilite
de alguna manera la inclusión de ciertos elementos e incluso que pueda existir la posibilidad
de partir de un modelo completo para después ir particularizando con acciones simples el
mismo.
De estas dos tendencias, surge una necesidad de realizar y mantener una precarga, que para
cualquier caso inicial, siempre sea la misma a modo de simplificación del formulario y de sus
acciones.

29
A partir de ahora nos encontramos con una situación de toma de decisiones de un gran
impacto:
Cómo construir la estructura interna de los modelos de diseño.
Realizar una estandarización de un método de precarga en base a acciones.
5.1.1.1 Generar xsd (XML SchemaDocument)
Para construir la guía de diseño de cada uno de los patrones, se utilizará un esquema XSD que
permita generar y validar documentos XML. Cada documento XML corresponderá a la guía de
diseño de un patrón, es decir, haciendo un símil con la programación orientada a objetos, el
esquema XSD representa una clase en la que se define la estructura y los documentos XML
representan las instancias de la clase con contenido propio (objetos).
A continuación se presenta la definición del esquema en función del objetivo que satisface, en
él destacaremos los elementos relevantes y se describirá el significado de las etiquetas
utilizadas. La figura 13 representa más en profundidad el proceso concreto de la guía de
diseño.
Figura 13: proceso de introducción de la guía de diseño
Como podemos observar, primero se ha realizado una traducción de la documentación de
diseño en formato UML (imágenes) a una documentación de diseño en un formato que puede
ser interpretado por una aplicación (XSD). Más adelante, deberemos introducir esa
información en el sistema (objetos).

30
Antes de comenzar a definir la estructura del documento XSD, se muestra brevemente el
formato que debe seguir el documento. Deberá tener dos partes diferenciadas:
Cabecera: irá siempre al principio del documento y deberá contener las propiedades
del documento:
o XML parser (con el que se validará este documento)
o targetNameSpace: Establece el Identificador uniforme de recursos
(Identificador URI) del espacio de nombres de destino del esquema.
o Xmlns:tns: Establece el identificador único “tns” como como espacio de
nombres de destino del esquema.
o elementFormDefault=”qualified”: Indica que todos los elemento, incluso
locales, deben ser cualificados en los documentos de instancia.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://xml.netbeans.org/schema/ DesignPreload "
xmlns:tns="http://xml.netbeans.org/schema/DesignPreload "
elementFormDefault="qualified">
Cuerpo: contendrá el resto de la información del esquema XSD asociada al patrón que
queramos representar.
A continuación describiremos todo el posible contenido del cuerpo del documento XSD.

31
5.1.1.1.1 Introducir modelos en el sistema
Como se indica en la descripción de objetivos, es necesario definir un procedimiento a través
del cual se puedan mapear diagramas UML a elementos del sistema. El procedimiento se
encargará de precargar elementos de los diagramas UML de cada patrón.
De este modo se ha definido un esquema de precarga de diseño que contenga los campos
precisos para construir la guía de diseño:
<xs:element name="DesignPreload">
<xs:annotation>
<xs:documentation>Design preload xml schema</xs:documentation>
</xs:annotation>
Existe un elemento complejo llamado Precarga que englobará a todos los diagramas:
<xs:complexType>
<xs:sequence>
<xs:element name="Precarga">
<xs:complexType>
<xs:sequence>
Los diagramas UML estarán representados en XSD de la siguiente manera:
Diagrama de clases: tendremos un diagrama de clases por cada patrón:
<xs:element name="DiagramaClases" type="tns:dclase" minOccurs="0"
maxOccurs="1"/>
Diagrama de casos de uso: también deberemos incorporar un diagrama de casos de
uso:
<xs:element name="DiagramaCasosDeUso"type="tns:duso"minOccurs="0"maxOccurs="1"/>
Diagramas de interacción: puesto que el número de diagramas de interacción
dependerá de cada patrón, en este punto podremos añadir los diagramas de
interacción necesarios:
<xs:element name="DiagramasInteraccion" type="tns:dinteraccion" minOccurs="0"
maxOccurs="unbounded"/>

32
5.1.1.1.1.1 Modelo de clases
El modelo de clases se representa a través de un tipo complejo llamado “dclase”. Este tipo
incorpora una serie indeterminada de clases, es decir, una lista de clases conforman el
diagrama completo. Esto es posible gracias a que cada clase incorpora a su vez todos los
atributos, método y relaciones posibles.
<xs:complexType name="dclase">
<xs:sequence>
<xs:element name="Clase" type="tns:clase" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
Como se ha indicado, a la hora de añadir una clase al diagrama de clases, necesitaremos los
valores típicos de una clase. Pasamos directamente a describirlos:
Nombre de la clase:
<xs:complexType name="anadirClase">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
Atributos de la clase, es importante mencionar que podrá aparecer un número
indeterminado de atributos:
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="atributo" type="xs:string"/>
</xs:sequence>
Métodos de la clase, a su vez, podremos encontrar un número indeterminado de
métodos:
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="metodo" type="xs:string"/>
</xs:sequence>
Relaciones de la clase con otras clases. Puesto que existen diferentes tipos de
relaciones y cada una de ellas contiene diferentes tipos de datos se ha creado una
etiqueta para cada una de ellas.
o Dependencias: Representa un tipo de relación muy particular, en la que una
clase es instanciada (su instanciación es dependiente de otro objeto/clase). El
uso más particular de este tipo de relación es para denotar la dependencia que
tiene una clase de otra.
<xs:element name="dependency" type="tns: associationType " minOccurs="0" maxOccurs="unbounded"/>
o Asociaciones: Indica relaciones de mandato bidireccionales. Conlleva
dependencia semántica y no establece una dirección de dependencia. Tienen
cardinalidad.
<xs:element name="association" type="tns: associationType " minOccurs="0" maxOccurs="unbounded"/>

33
o Composiciones: Es un tipo de relación estática, en donde el tiempo de vida del
objeto incluido está condicionado por el tiempo de vida del que lo incluye.
<xs:element name="composition" type="tns:comp_aggr" minOccurs="0" maxOccurs="unbounded"/>
o Agregaciones: Es un tipo de relación dinámica, en donde el tiempo de vida del
objeto incluido es independiente del que lo incluye.
<xs:element name="aggregation" type="tns:comp_aggr" minOccurs="0" maxOccurs="unbounded"/>
o Generalizaciones: Indica que una subclase hereda los métodos y atributos
especificados por una Super Clase, por ende la Subclase además de poseer sus
propios métodos y atributos, poseerá las características y atributos visibles de
la Super Clase
<xs:element name="generalization" type="tns:generalization" minOccurs="0" maxOccurs="unbounded"/>
Los tipos de datos que se manejarán se han agrupado en tres grupos en base al contenido que
manejarán:
Tipo asociación(associationType): Este tipo se utilizará tanto para relaciones de
dependencia como para relaciones de asociación.
<xs:complexType name="associationType">
<xs:sequence>
Se caracteriza por tres elementos:
o association-class: indicará el nombre de la clase con la que se relaciona
<xs:element name="association-class" type="xs:string"/>
o association-multiplicity: de forma opcional se podrá indicar la multiplicidad de
la relación. Los valores que podrá tener son: “optional”, “one” o “many”.
<xs:element name="association-multiplicity" type="tns:multiplicityVal" minOccurs="0"
maxOccurs="1"/>
o role-name: de forma opcional se podrá indicar la etiqueta que llevará la
relación.
<xs:element name="role-name" type="xs:string" minOccurs="0" maxOccurs="1"/>
Tipo composición/agregación(comp_aggr): Este tipo se utilizará tanto para relaciones
de composición como para relaciones de agregación.
<xs:complexType name="comp_aggr">
<xs:sequence>
En este caso, este tipo complejo de datos contiene dos etiquetas:
o association-class: indicará el nombre de la clase con la que se relaciona
<xs:element name="association-class" type="xs:string"/>
o role-name: de forma opcional se podrá indicar la etiqueta que llevará la
relación.
<xs:element name="role-name" type="xs:string" minOccurs="0" maxOccurs="1"/>

34
Tipo generalización (generalization): Este tipo se utilizará únicamente para el tipo de
relaciones de generalización.
<xs:complexType name="generalization">
<xs:sequence>
En este caso, este tipo complejo de datos contiene una etiqueta:
o Class-name: indicará el nombre de la clase con la que se relaciona.
<xs:element name="class-name" type="xs:string"/>

35
5.1.1.1.1.2 Modelo de casos de uso
Los diagramas de casos de uso se representan a través del tipo complejo “duso”. Este tipo
complejo contendrá un número indeterminado de actores y de casos de uso.
<xs:complexType name="duso">
<xs:sequence>
<xs:element name="Actor" type="xs:string" minOccurs="0" maxOccurs="unbounded" />
<xs:element name="CasoDeUso" type="tns:casoUso" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
Tal y como pasaba en el modelo de clases, necesitaremos la información típica de un casos de
uso; nombre del mismo y las relaciones que posee con otros casos de uso. Se han definido 3
tipos de relaciones posibles: asociación, inclusión y extensión.
<xs:complexType name="anadirCasoUso">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
<xs:element name="associationUC" type="tns:relationUC" minOccurs="0"
maxOccurs="unbounded"/>
<xs:element name="include" type="tns:relationUC" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="extend" type="tns:relationUC" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
La etiqueta relationUC engloba todas las relaciones. La relación está compuesta por el origen
de la relación (source), y el destino (target). Por lo general el campo source estará vacío,
indicando así que el origen de la relación es el propio caso de uso que la contiene. En algunos
casos, siempre que el origen sea un actor, el elemento “source” expresará un origen.
<xs:complexType name="relationUC">
<xs:sequence>
<xs:element name="target" type="xs:string"/>
<xs:element name="source" type="xs:string" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
</xs:complexType>

36
5.1.1.1.1.3 Modelo de interacción
Por último hablaremos del modelo de interacción. Los diagramas de interacción son
completos, por tanto se ha definido incluir todos los diagramas durante la precarga con una
variable que indicará si están activos, es decir si en base a las responsabilidades definidas se
aplican a la particularización del usuario, o si por el contrario no estarán habilitados.
La representación de los diagramas de interacción se realiza a través del tipo complejo
“dinteraccion”. Cada diagrama de interacción individual estará representado por la etiqueta
“DiagramaInteraccion”.
<xs:complexType name="dinteraccion">
<xs:sequence>
<xs:element name="DiagramaInteraccion"minOccurs="0"maxOccurs="unbounded">
Las etiquetas que se manejan en este tipo de datos serán las siguientes:
Asignación, este tipo nos permitirá indicar si un diagrama está activo desde la precarga
o si por el contrario se tendrá que activar durante la fase de elicitación. Los valores que
podrá tomar son Active” (visible) o “Inactive” (no visible).
<xs:sequence>
<xs:element name="asignacion">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="Active"/>
<xs:enumeration value="Inactive"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
Nombre del diagrama, puesto que podrán existir varios diagramas para un mismo
documento, éstos deberán tener un nombre para referenciarlos.
<xs:element name="nombre" type="xs:string"/>
Objeto, existirán un número indeterminado de elementos “objeto”, que representarán
todos los objetos que existen en un diagrama de interacción concreto.
<xs:element name="objeto" type="tns:objeto" minOccurs="0" maxOccurs="unbounded" />
Interacción, también existirán tantas interacciones como sean necesarias. Éstas
representas las peticiones entre objetos que existen en el diagrama. Hemos de tener
en cuenta que el orden con el que se suceden establece el orden de las peticiones.
<xs:element name="interaccion" type="tns:interaccion" minOccurs="0" maxOccurs="unbounded"/>

37
Analizando el elemento objeto, observamos que contiene un elemento nombre y un elemento
clase, que será el nombre de la clase a la que pertenece este objeto.
<xs:complexType name="objeto">
<xs:sequence>
<xs:element name="nombre" type="xs:string" minOccurs="0" maxOccurs="1"/>
<xs:element name="clase" type="xs:string"/>
</xs:sequence>
</xs:complexType>
En el tipo complejo llamado “interaccion” se representan todos los elementos simples
necesarios para definir una interacción. Por un lado tendremos los objetos emisor,
“objetoEmisor”, y receptor “objetoReceptor”, por otro el nombre del método a ejecutar,
“methodName”, y por último tendremos que definir el tipo del estímulo, “type” y los
parámetros del mensaje, “param”.
<xs:complexType name="interaccion">
<xs:sequence>
<xs:element name="objetoEmisor" type="xs:string"/>
<xs:element name="objetoReceptor" type="xs:string"/>
<xs:element name="methodName" type="xs:string"/>
<xs:element name="param" type="xs:string" minOccurs="0"/>
<xs:element name="tipo" type="tns:tipoMensaje"/>
</xs:sequence>
</xs:complexType>
El tipo del mensaje está representado por los cuatro tipos de estímulos existentes: llamada
“call”, envío “send”, retorno “return”, creación “create” y destrucción “destroy”
<xs:simpleType name="tipoMensaje">
<xs:restriction base="xs:string">
<xs:enumeration value="call"/>
<xs:enumeration value="send"/>
<xs:enumeration value="return"/>
<xs:enumeration value="create"/>
<xs:enumeration value="destroy"/>
</xs:restriction>
</xs:simpleType>
</xs:schema>

38
5.2 Guía de elicitación
La guía de elicitación describe el proceso lógico mediante el que se definirán las
responsabilidades. Como se ha explicado en el apartado 2.2.5 Lógica funcional, está
representado por un diagrama de flujo que incorpora el proceso o algoritmo.
Figura 14: gráfico del proceso de elicitación
Nuestro cometido en este punto es tratar de encontrar una solución para mapear los
elementos de un diagrama a elementos software del sistema.
El contenido a mapear para desarrollar el flujo consta de los siguientes elementos:
1. Identificador de la pregunta: Corresponde a un identificador único por diagrama, de
esta forma será posible referirnos a una pregunta de forma inequívoca.
2. Contenido de la pregunta: Corresponde al texto que se mostrará cuando el sistema
presente un elemento pregunta.
3. Flujo: Corresponde al identificador de la siguiente pregunta a la se pasará en función
de la respuesta del usuario.
4. Acciones: Contiene la información asociada a las operaciones que se realizarán para
particularizar los modelos genéricos de los patrones.
Independientemente del lenguaje de programación utilizados, debemos crear una estructura
de tipos de datos en la que incluir la información. Sin embargo, en este punto tenemos que
tomar una decisión en cuanto a la forma de introducir el contenido correspondiente los
patrones de diseño.

39
Por un lado, introducir en el propio código del sistema el contenido de los patrones hace que
nuestro sistema fuera muy sensible a cambios. Es decir, tanto si alguno de los patrones se
modificara o se deseara incluir alguno nuevo, sería necesario modificar el código del sistema.
Por tanto, en este punto fue necesario tomar una decisión en cuanto al método con el que se
introduciría, de forma externa al sistema, los datos referentes a la guía de elicitación.
5.2.1 Bases de Datos
Analizando la posibilidad de incluir una base de datos para representar la elicitación en el
sistema, observamos la correcta aproximación a los elementos anteriormente citados, como
son los patrones y los formularios.
Por un lado tenemos que la representación de un patrón consta simplemente de un nombre y
éste debe llevar asociado un único formulario, por lo que determinamos que no supondría
ningún problema en el modelado.
Por otro lado tenemos el formulario, donde necesitaremos incluir información sobre la
identificación de la pregunta, que será el identificador de cada pregunta, la descripción de la
pregunta, las posibles bifurcaciones y por último las acciones a realizar dependiendo de las
respuestas. Estas acciones a priori complican notablemente el modelo entidad-relación puesto
que la diversidad de éstas hace complejo el diseño de dicho modelo. Además, teniendo en
cuenta el grado de ambigüedad que se le quiere aportar al sistema, realizar un cambio en
algún tipo de acción podría tener un elevado impacto sobre el comportamiento funcional del
sistema.
Si tenemos en cuenta otros factores como son la sostenibilidad y el uso de una base de datos
para el sistema propuesto, parece que la propuesta pierde peso. Puesto que lo que se intenta
generar es un sistema experto, los cambios producidos en él representan en el futuro un
porcentaje excesivamente bajo, por lo que no tiene mucho sentido mantener levantada una
base de datos para realizar únicamente tareas de consulta. Además la centralización de datos
que requiere el sistema, se realiza a través de la distribución web, y dicha distribución al
necesitar únicamente labores de consulta no requerirá concurrencia a la hora de realizar una
escritura, puesto que las salidas producidas por el sistema serán únicas para cada caso.
Por estas razones, es más lógico pensar en una solución que implemente una base de
conocimientos estática, es decir, que se pueda extraer de un soporte de datos estático, como
por ejemplo un fichero.
Para la creación de un metamodelo en un fichero, la forma de representarlo de forma más
cercana a un lenguaje natural es a través de un fichero XML. Este fichero debe seguir un
esquema fijado a modo de acotación de dominio del sistema, es decir, que tengamos una
verificación de que todo elemento introducido en el fichero está correctamente formateado y
validado como se comenta a continuación.

40
5.2.2 Generar XSD (XML SchemaDocument)
Después de descartar el uso de una base de datos como base de conocimiento del sistema,
centraremos la construcción de ésta en la creación de un esquema XML (XSD).
De este modo, para construir la guía de elicitación de cada uno de los patrones, se utilizará un
esquema XSD que permitiera generar y validar documentos XML. Cada documento XML
corresponderá a la guía de elicitación de un patrón.
Figura 15: proceso de introducción de documentación de elicitación
En la figura 15, se explica de forma gráfica el proceso que debemos seguir para introducir la
guía de elicitación en el sistema, es decir, traducir la información de la que disponemos
inicialmente en un tipo de documentación que pueda ser interpretada por el sistema. Como
podemos observar, se ha dividido en dos pasos, primero se realiza una traducción y después se
introduce esa traducción en el sistema (objetos).

41
A continuación se presenta la definición del esquema en función del objetivo que satisface, en
él destacaremos los elementos relevantes y se describirá el significado de las etiquetas
utilizadas.
Antes de comenzar a definir la estructura del documento XSD, se muestra brevemente el
formato que debe seguir el documento. Deberá tener dos partes diferenciadas:
Cabecera: irá siempre al principio del documento y deberá contener las propiedades
del documento:
o XML parser (con el que se validará este documento)
o targetNameSpace: Establece el Identificador uniforme de recursos
(Identificador URI) del espacio de nombres de destino del esquema.
o Xmlns:tns: Establece el identificador único “tns” como como espacio de
nombres de destino del esquema.
o elementFormDefault=”qualified”: Indica que todos los elemento, incluso
locales, deben ser cualificados en los documentos de instancia.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://xml.netbeans.org/schema/Formulario"
xmlns:tns="http://xml.netbeans.org/schema/Formulario"
elementFormDefault="qualified">
Cuerpo: contendrá el resto de la información del esquema XSD asociada al patrón que
queramos representar.
Los apartados posteriores se centrarán en el desarrollo del cuerpo del documento xsd.

42
5.2.2.1 Automatizar la definición de responsabilidades.
Como se indica en la descripción de objetivos, este espacio hace referencia a la necesidad de
crear un flujo mediante el que el sistema sea capaz de conducir y asimilar las
particularizaciones sobre los patrones existentes en el sistema.
De este modo, se ha definido un formulario que contenga los campos precisos para construir
el flujo:
<xs:element name="Formulario">
<xs:annotation>
<xs:documentation>Formulario xml schema</xs:documentation>
</xs:annotation>
<xs:complexType>
Cada formulario, por tanto, contiene un número indeterminado de Preguntas:
<xs:sequence>
<xs:element name="Pregunta" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
A su vez, cada pregunta engloba el contenido a mapear para desarrollar el flujo. Consta de los
elementos descritos previamente:
5. Identificador de la pregunta: Corresponde a un identificador único por diagrama, de
esta forma será posible referirnos a una pregunta de forma inequívoca.
<xs:element name="id" type="xs:integer"/>
6. Contenido de la pregunta: Corresponde al texto que se mostrará cuando el sistema
presente un elemento pregunta.
<xs:element name="valor" type="xs:string"/>
7. Flujo: Corresponde al identificador de la siguiente pregunta a la se pasará en función
de la respuesta del usuario.
Si el usuario respondiera Si:
<xs:element name="nodoSI" type="xs:integer"/>
Si el usuario respondiera No:
<xs:element name="nodoNO" type="xs:integer"/>
8. Acciones: Contiene la información asociada a las operaciones que se realizarán para
particularizar los modelos genéricos de los patrones.
El sistema realizará indeterminadas acciones en función de la respuesta del usuario,
por tanto:
Si el usuario respondiera Sí, se listaría las acciones tras la etiqueta:
<xs:element name="accionesSI" type="tns:acciones" minOccurs="0"/>
Si por el contrario contestara No, se listaría tras la etiqueta:
<xs:element name="accionesNO" type="tns:acciones" minOccurs="0"/>
En este punto es necesario hacer una explicación mucho más extensa del contenido,
por lo que en el siguiente sub-apartado se desarrollaran todas las posibles acciones.

43
5.2.2.2 Manejo de modelos en el sistema.
Como se ha indicado, al mismo tiempo que el sistema transcurre por el flujo de elicitación,
pasa por diferentes estados, en los cuales para pasar al siguiente han de realizarse
acciones sobre los elementos de los modelos.
Este apartado se ocupa de describir cómo se han definido estas acciones. Aunque hasta
ahora únicamente hemos hablado de las acciones que particularizarán los modelos de
diseño genéricos, existen más tipos de acciones que personalizarán diferentes aspectos
genéricos de los patrones.
El esquema nos permitirá elegir por cada acción un tipo de los listados a continuación:
<xs:complexType name="acciones">
<xs:sequence>
<xs:element name="accion" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:choice>
<xs:element name="fichero" type="tns:fichero"/>
<xs:element name="table" type="tns:table"/>
<xs:element name="system" type="tns:system"/>
<xs:element name="diseno" type="tns:diseno"/>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
A continuación, en los siguientes apartados se presentarán y definirán las acciones del
sistema en función de su tipología.

44
5.2.2.2.1 Acciones de tipo Fichero
Este tipo de acciones se harán cargo de crear los ficheros que describirán los requisitos de
diseño.
La mejor forma de entender este concepto es con un ejemplo:
En el patrón Undo, encontramos la siguiente pregunta.
¿Qué acciones del usuario están consideradas como peligrosas?
De este modo, la respuesta a la misma corresponderá a la lista de acciones
potencialmente peligrosas.
Para representar esta información en el esquema se han utilizado dos etiquetas, nombre
de la lista, en este caso “Lista de acciones potencialmente peligrosas”, y ruta que indicará
dónde se creará el fichero que contendrá dicha lista.
<xs:complexType name="fichero">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
<xs:element name="ruta" type="xs:string"/>
</xs:sequence>
</xs:complexType>
No es necesario incluir una etiqueta para hacer referencia al contenido que el usuario
responderá porque no forma parte del patrón, sino del material personalizado y por tanto
su sitio es en una primera instancia un objeto software del sistema y finalmente un
documento pdf que se entregará al usuario.

45
5.2.2.2.2 Acciones de tipo Tabla
Este tipo de acciones se encargan de personalizar el contenido de las tablas de los patrones,
estas son: Tabla 1. Guía de elicitación de usabilidad, Tabla 2. Guía de diseño genérico y Tabla 3.
Guía de diseño concreto, descritas en el apartado x.
En este caso y puesto que las tablas que se incluyen en los patrones son completas, las
personalizaciones sobre las mismas se basarán en eliminar responsabilidades, y en definitiva
eliminar filas de las tablas. De este modo las etiquetas que se han definido para este fin son el
nombre de la tabla que se desea personalizar y eliminarFila, que indica el número de la fila
que tiene que desaparecer para eliminar una responsabilidad concreta de la tabla genérica:
<xs:complexType name="table">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
<xs:element name="eliminarFila" type="xs:integer"/>
</xs:sequence>
</xs:complexType>
46
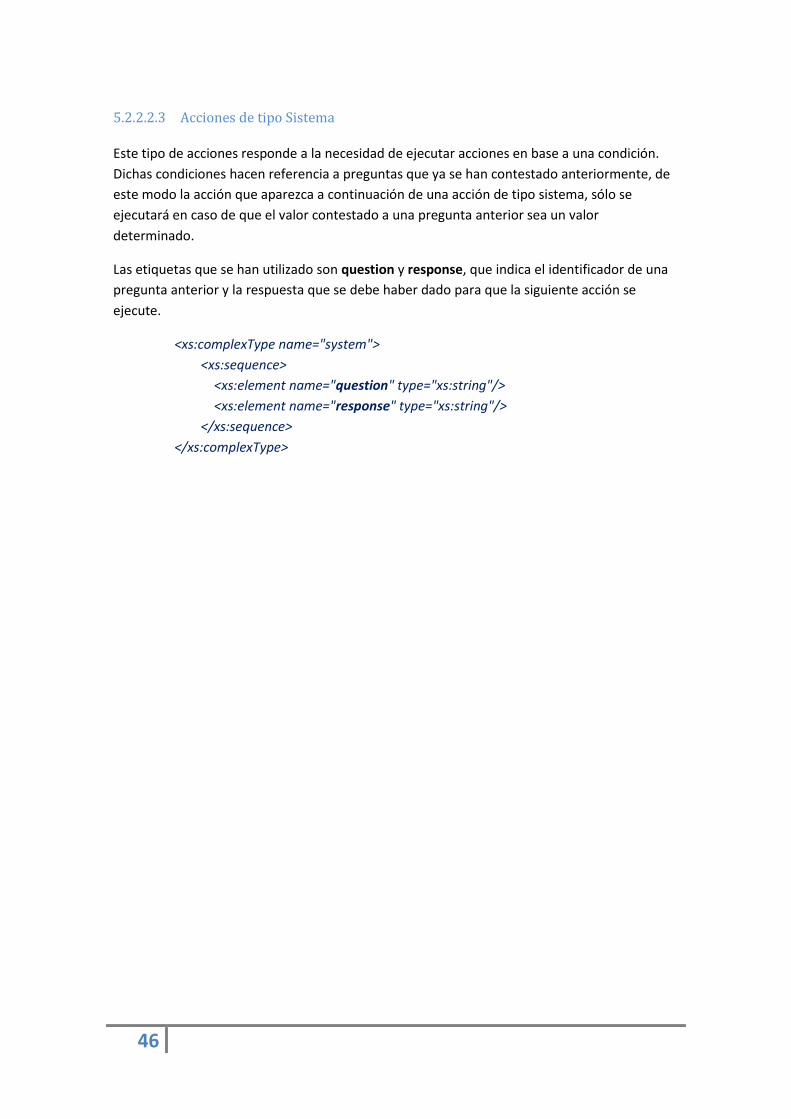
5.2.2.2.3 Acciones de tipo Sistema
Este tipo de acciones responde a la necesidad de ejecutar acciones en base a una condición.
Dichas condiciones hacen referencia a preguntas que ya se han contestado anteriormente, de
este modo la acción que aparezca a continuación de una acción de tipo sistema, sólo se
ejecutará en caso de que el valor contestado a una pregunta anterior sea un valor
determinado.
Las etiquetas que se han utilizado son question y response, que indica el identificador de una
pregunta anterior y la respuesta que se debe haber dado para que la siguiente acción se
ejecute.
<xs:complexType name="system">
<xs:sequence>
<xs:element name="question" type="xs:string"/>
<xs:element name="response" type="xs:string"/>
</xs:sequence>
</xs:complexType>

47
5.2.2.2.4 Acciones de tipo Diseño
Este tipo de acciones hacen referencia al manejo de los modelos de diseño en el sistema.
Puesto que pueden realizarse diferentes tipos de acciones de diseño en función de a qué
modelo afecte, una acción de diseño nos permitirá elegir entre los siguientes sub-tipos:
Añadir Clase: añade una clase al diagrama de clases del patrón con el que se está
trabajando.
Añadir Método: añade un método a una clase determinada.
Añadir Atributo: añade un atributo a una clase determinada.
Añadir Relación: añade una relación entre dos clases.
Añadir Caso de Uso: añade un caso de uso al diagrama de casos de uso del patrón con
el que se está trabajando.
Eliminar Petición: elimina una petición de un diagrama de interacción determinado.
Modificar Petición: modifica los atributos de una petición de un diagrama de
interacción determinado.
Añadir Diagrama: añade un diagrama de interacción al sistema.
<xs:complexType name="diseno">
<xs:choice>
<xs:element name="anadirClase" type="tns:anadirClase"/>
<xs:element name="anadirMetodo" type="tns:anadirMetodo"/>
<xs:element name="anadirAtributo" type="tns:anadirAtributo"/>
<xs:element name="anadirRelacion" type="tns:anadirRelacion"/>
<xs:element name="anadirCasoUso" type="tns:anadirCasoUso"/>
<xs:element name="eliminarPeticion" type="tns:eliminarPeticion"/>
<xs:element name="modPeticion" type="tns:modPeticion"/>
<xs:element name="anadirDiagrama" type="xs:string"/>
</xs:choice>
</xs:complexType>
Puesto que cada uno de estos elementos está compuesto por varios tipos de información, en
los siguientes apartados se mostrará una descripción completa de los mismos. Para una
mejor comprensión, los agruparemos en función del modelo de diseño al que hagan
referencia: modelo de clases, modelo de casos de uso y modelo de interacción.

48
5.2.2.2.4.1 Modelo de clases
5.2.2.2.4.1.1 Acción Añadir Clase
A la hora de añadir una clase al diagrama de clases, necesitaremos los valores típicos de una
clase. Pasamos directamente a describirlos:
Nombre de la clase:
<xs:complexType name="anadirClase">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
Atributos de la clase, es importante mencionar que podrá aparecer un número
indeterminado de atributos:
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="atributo" type="xs:string"/>
</xs:sequence>
Métodos de la clase, a su vez, podremos encontrar un número indeterminado de
métodos:
<xs:sequence minOccurs="0" maxOccurs="unbounded">
<xs:element name="metodo" type="xs:string"/>
</xs:sequence>
Relaciones de la clase con otras clases. Puesto que existen diferentes tipos de
relaciones y cada una de ellas contiene diferentes tipos de datos se ha creado una
etiqueta para cada una de ellas.
o Dependencias: Representa un tipo de relación muy particular, en la que una
clase es instanciada (su instanciación es dependiente de otro objeto/clase). El
uso más particular de este tipo de relación es para denotar la dependencia que
tiene una clase de otra.
<xs:element name="dependency" type="tns: associationType " minOccurs="0" maxOccurs="unbounded"/>
o Asociaciones: Indica relaciones de mandato bidireccionales. Conlleva
dependencia semántica y no establece una dirección de dependencia. Tienen
cardinalidad.
<xs:element name="association" type="tns: associationType " minOccurs="0" maxOccurs="unbounded"/>
o Composiciones: Es un tipo de relación estática, en donde el tiempo de vida del
objeto incluido está condicionado por el tiempo de vida del que lo incluye.
<xs:element name="composition" type="tns:comp_aggr" minOccurs="0" maxOccurs="unbounded"/>
o Agregaciones: Es un tipo de relación dinámica, en donde el tiempo de vida del
objeto incluido es independiente del que lo incluye.
<xs:element name="aggregation" type="tns:comp_aggr" minOccurs="0" maxOccurs="unbounded"/>

49
o Generalizaciones: Indica que una subclase hereda los métodos y atributos
especificados por una Super Clase, por ende la Subclase además de poseer sus
propios métodos y atributos, poseerá las características y atributos visibles de
la Super Clase
<xs:element name="generalization" type="tns:generalization" minOccurs="0" maxOccurs="unbounded"/>
Los tipos de datos que se manejarán se han agrupado en tres grupos en base al contenido que
manejarán:
Tipo asociación(associationType): Este tipo se utilizará tanto para relaciones de
dependencia como para relaciones de asociación.
<xs:complexType name="associationType">
<xs:sequence>
Se caracteriza por tres elementos:
o association-class: indicará el nombre de la clase con la que se relaciona
<xs:element name="association-class" type="xs:string"/>
o association-multiplicity: de forma opcional se podrá indicar la multiplicidad de
la relación. Los valores que podrá tener son: “optional”, “one” o “many”.
<xs:element name="association-multiplicity" type="tns:multiplicityVal" minOccurs="0"
maxOccurs="1"/>
o role-name: de forma opcional se podrá indicar la etiqueta que llevará la
relación.
<xs:element name="role-name" type="xs:string" minOccurs="0" maxOccurs="1"/>
Tipo composición/agregación(comp_aggr): Este tipo se utilizará tanto para relaciones
de composición como para relaciones de agregación.
<xs:complexType name="comp_aggr">
<xs:sequence>
En este caso, este tipo complejo de datos contiene dos etiquetas:
o association-class: indicará el nombre de la clase con la que se relaciona
<xs:element name="association-class" type="xs:string"/>
o role-name: de forma opcional se podrá indicar la etiqueta que llevará la
relación.
<xs:element name="role-name" type="xs:string" minOccurs="0" maxOccurs="1"/>
Tipo generalización(generalization): Este tipo se utilizará únicamente para el tipo de
relaciones de generalización.
<xs:complexType name="generalization">
<xs:sequence>
En este caso, este tipo complejo de datos contiene una etiqueta:
o Class-name: indicará el nombre de la clase con la que se relaciona.
<xs:element name="class-name" type="xs:string"/>

50
5.2.2.2.4.1.2 Acción Añadir Método
Este tipo de acciones responde a la necesidad de añadir métodos a clases concretas. Por tanto
las etiquetas que manejará este tipo de acciones son methodName, para indicar el nombre del
método que se añadirá y clase, que muestra el nombre de la clase a la que se le añadirá el
método antes indicado.
<xs:complexType name="anadirMetodo">
<xs:sequence>
<xs:element name="methodName" type="xs:string"/>
<xs:element name="clase" type="xs:string"/>
</xs:sequence>
</xs:complexType>
5.2.2.2.4.1.3 Acción Añadir Atributo
Del mismo modo que se podrán añadir métodos, el sistema nos permitirá añadir atributos a
alguna clase determinada. Para ello, se han definido las siguientes etiquetas: attributeName
para apuntar el nombre del atributo y clase para indicar a qué clase habrá que añadir el
atributo.
<xs:complexType name="anadirAtributo">
<xs:sequence>
<xs:element name="attributeName" type="xs:string"/>
<xs:element name="clase" type="xs:string"/>
</xs:sequence>
</xs:complexType>
5.2.2.2.4.1.4 Acción Añadir Relación
Este tipo de acciones resuelve la necesidad de añadir relaciones entre clases que no existieran.
Como se ha explicado anteriormente existen varios tipos de relaciones y puesto que ya se han
definido como tipos de datos, en este punto las etiquetas que se manejarán son origen, para
indicar la clase de la que parte la relación y como destino podremos elegir un tipo de relación,
dentro de ese tipo de relación se asignará entre otros atributos la clase destino.
<xs:complexType name="anadirRelacion">
<xs:sequence>
<xs:element name="origen" type="xs:string"/>
<xs:choice>
<xs:element name="dependency" type="tns:association"/>
<xs:element name="association" type="tns:association"/>
<xs:element name="composition" type="tns:comp_aggr"/>
<xs:element name="aggregation" type="tns:comp_aggr"/>
<xs:element name="generalization" type="tns:generalization"/>

51
5.2.2.2.4.2 Modelo de casos de uso
En cuanto al modelo de casos de uso, encontraremos dos tipos de acciones: Añadir Caso de
Uso y Añadir Relación UC.
5.2.2.2.4.2.1 Acción Añadir Caso de Uso
En el caso de añadir caso de uso, necesitaremos la información típica de un casos de uso;
nombre del mismo y las relaciones que posee con otros casos de uso. Se han definido 3 tipos
de relaciones posibles: asociación, inclusión y extensión.
<xs:complexType name="anadirCasoUso">
<xs:sequence>
<xs:element name="nombre" type="xs:string"/>
<xs:element name="associationUC" type="tns:relationUC" minOccurs="0"
maxOccurs="unbounded"/>
<xs:element name="include" type="tns:relationUC" minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="extend" type="tns:relationUC" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
5.2.2.2.4.2.2 Acción Añadir Relación UC
El contenido de las relaciones para los casos de uso se simplifica en dos etiquetas: origen(source) de la
relación, que indica el nombre del caso de uso del que se parte y destino(target) que indica el nombre del
caso de uso de destino.
<xs:complexType name="relationUC">
<xs:sequence>
<xs:element name="target" type="xs:string"/>
<xs:element name="source" type="xs:string" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
</xs:complexType>
Puesto que este tipo de datos se utiliza para tanto para definir las relaciones dentro de la
creación un caso de uso como para añadir un relación individual, la etiqueta source será
opcional ya que si estamos creando un caso de uso nuevo el origen ya es conocido.

52
5.2.2.2.4.2.3 Modelo de interacción
Por último hablaremos de las acciones referentes al modelo de interacción. Puesto que los
modelos de interacción introducidos en el sistema son completos, contienen todas las
peticiones posible, existen tres tipos de acciones: eliminar peticiones de un diagrama,
modificar peticiones o añadir diagramas completos, en este punto es necesario una
explicación.
Como se ha indicado, los diagramas de interacción son completos, por tanto se ha definido
incluir todos los diagramas durante la precarga con una variable que indicará si están activos,
es decir si en base a las responsabilidades definidas se aplican a la particularización del
usuario, o si por el contrario no estarán habilitados.

53
5.2.2.2.4.3 Acción Eliminar Petición
Este tipo de acciones define la información necesaria para eliminar una petición de un
diagrama, para ello serán necesarias las siguientes etiquetas: diagrama, que indica el nombre
del diagrama al que hace referencia la acción, y objetoEmisor, objetoReceptor y
methodName(nombre del método) para localizar la petición concreta que será eliminada.
xs:complexType name="eliminarPeticion">
<xs:sequence>
<xs:element name="diagrama" type="xs:string"/>
<xs:element name="objetoEmisor" type="xs:string"/>
<xs:element name="objetoReceptor" type="xs:string"/>
<xs:element name="methodName" type="xs:string"/>
</xs:sequence>
</xs:complexType>
5.2.2.2.4.4 Acción Modificar Petición
Modificar una petición, al igual que el apartado anterior, pasa por localizar la petición que
quiere modificarse y por indicar los parámetros de la misma.
Para ello se han definido las siguientes etiquetas: diagrama, que indica el nombre del
diagrama al que hace referencia la acción; objetoEmisor, objetoReceptor y
methodName(nombre del método) para localizar la petición concreta, y parámetros(param)
que contendrá la información que desea modificarse.
<xs:complexType name="modPeticion">
<xs:sequence>
<xs:element name="diagrama" type="xs:string"/>
<xs:element name="objetoEmisor" type="xs:string"/>
<xs:element name="objetoReceptor" type="xs:string"/>
<xs:element name="methodName" type="xs:string"/>
<xs:element name="param" type="xs:string" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
5.2.2.2.4.5 Acción Añadir Diagrama
Por último, la acción de añadir un diagrama se traduce en activarlo, para lo cual únicamente
será necesario indicar el nombre del diagrama que se ha de habilitar.
<xs:element name=" anadirDiagrama " type="xs:string"/>

54
5.3 Ofrecer modelos reusables
Este apartado describe el proceso mediante el cual el usuario del sistema obtiene la
documentación generada por el sistema. Como anteriormente hemos hablado, esta
documentación se estructura en diferentes formatos, pero en este apartado nos centraremos
únicamente en el formato de diseño UML y sus representaciones.
Figura 16: proceso de obtención de modelos reusables
La figura 16 explica el proceso de obtención de modelos reusables, es decir, de qué manera
trasformamos la información que tenemos en el sistema (en objetos) en algún tipo de
información que pueda ser reutilizada por otro programa, es este caso de diseño.
Lo cierto es que la investigación que realizamos para lograr este objetivo fue la más compleja y
la que duró más tiempo, de hecho podemos hablar de una primera aproximación sobre la cual
tuvimos que desechar el proceso que se había definido, y una segunda aproximación que nos
permitió llegar al resultado final. De este modo el desarrollo del apartado se divide en dos
grupos, Primera y Segunda aproximación.

55
5.3.1 Primera aproximación
Una vez que sabemos de qué forma introduciremos en el sistema el conocimiento (guía de
diseño y guía de elicitación) y cómo se manipularán los modelos de diseño genéricos dentro
del sistema a través de acciones, debemos realizar un estudio sobre las posibilidades que
tenemos para ofrecer un resultado reutilizable.
El resultado a ofrecer debe seguir un estándar, como se ha indicado el estándar de diseño
software es UML y por tanto el fin de este estudio es transformar los objetos que se han
creado en el sistema y que representan diagramas de clases, casos de uso e interacción, en
diagramas UML.
En esta primera aproximación realizaremos dividiremos el proceso en dos partes:
1. Transformar de objetos a XML
2. Transformar de XML a UML
La figura explica de manera gráfica dicha división:
Figura 17: división del proceso de ofrecer modelos reusables

56
5.3.1.1 XML Data Binding
El término XML data binding se refiere al proceso para representar información de un
documento XML en objetos en memoria de un computador y viceversa. En nuestro caso
particular, debemos generar documentos XML a partir de los objetos java del sistema.
Para ello, encontramos Castor XML, un framework para realizar XML Data Binding. A diferencia
de las principales APIs para XML: DOM (Document Object Model) y SAX (Simple API for XML),
que se ocupan de la estructura de un documento XML, Castor permite hacer frente a los datos
definidos en un documento XML a través de un modelo de objetos que representa esos datos.
Castor XML puede hacer Marshalling y Unmarshalling de objetos Java y de XML. En la mayoría
de los casos, el marco de marshaling usa un conjunto de ClassDescriptors y FieldDescriptors
para describir como un objeto de base mapeado y viceversa desde un XML.
Figura 18: Marshalling & Unmarshalling
Para aquellos no familiarizados con los términos "marshal" y "unmarshal", es simplemente el
acto de convertir una secuencia de bytes desde y hacia un objeto.
El acto de "Marshall" consiste en convertir un objeto en un documento XML, y "unmarshalling"
de un documento XML a un objeto.
El mapeo a XML que proporciona Castor es una manera de simplificar la unión entre objetos
Java con un documento XML. Castor permite transformar los datos contenidos en un modelo
de objetos Java en un documento XML siguiendo los estándares fijados por el W3C.
A pesar de que es posible confiar en el comportamiento por defecto que Castor realiza al pasar
de objetos Java a un documento XML, puede ser necesario tener más control sobre este
comportamiento. Por ejemplo, si un modelo de objetos de Java ya existe, el mapeo Castor XML
puede ser utilizado como un puente entre el documento XML el modelo de objetos de Java.
Castor permite definir algunas de sus formas de realizar los procesos de marshalling y
unmarshalling utilizando un archivo de configuración. Este archivo le proporciona información
explícita a Castor sobre la forma de un documento XML dado y un conjunto dado de objetos
Java que se relacionan entre sí.

57
Un archivo de configuración de Castor es una buena manera de disociar los cambios en la
estructura de un modelo de objetos Java desde los cambios en el formato del documento XML
correspondiente.
5.3.1.1.1 Descripción general
La información del mapeo se especifica mediante un documento XML. Este documento está
escrito desde el punto de vista del objeto de Java y describe cómo las propiedades del objeto
se traducen en XML. Un obstáculo para el archivo de configuración es que Castor debe ser
capaz de deducir sin ambigüedades de qué modo un elemento/atributo XML dado tiene que
traducirse en el modelo de objetos durante el proceso de marshalling.
El archivo de configuración para cada objeto describe cómo cada uno de sus campos tiene que
ser transformado a XML. Un campo es una abstracción de una propiedad de un objeto. Se
puede corresponder directamente a una variable de clase pública o indirectamente a una
propiedad a través de algunos métodos de acceso (getters y setters).
Es posible utilizar el mapping y el comportamiento por defecto de Castor: cuando Castor tiene
que manejar un objeto o un conjunto de datos XML, pero no se puede encontrar información
sobre él en el archivo de configuración, su comportamiento se basará en la configuración que
tiene por defecto. Castor utiliza el API de Java para inspeccionar los objetos de Java y
determinar qué hacer con ellos.

58
5.3.1.1.2 Aplicación de Castor al sistema
Ahora que sabemos que Castor puede realizar de forma automática el mapping a XML
siguiendo los estándares del W3C tan sólo nos queda construir el archivo de configuración en
formato XML en el que se apoye Castor para realizar el proceso de marshalling.
Figura 19: aplicación de castor al sistema
Para realizar el mapeo de una clase Java a XML debemos especificar todos y cada uno de los
elementos de los que se compone una clase, es decir, que si en una clase tenemos un atributo
que es a su vez otra clase (o un elemento que sea de un tipo complejo o que no esté
predefinido como tipo estándar) deberemos definirlo en el archivo de configuración.

59
A continuación veremos un ejemplo para el diagrama de clases:
La clase ClassDiagram tiene 2 campos, el primero será el nombre traducido como un String y el
segundo campo será una colección del tipo ClassType, es decir, se trata de otra clase.
<mapping>
<class name="Diagram.ClassDiagram">
<map-to xml="Diagram"/>
<field name="name" type="java.lang.String">
<bind-xml name="Name" node="attribute"/>
</field>
<field name="classes" type="Diagram.ClassType" collection="arraylist">
<bind-xml name="Class" node="element"/>
</field>
</class>
La clase ClassType está compuesta por:
<class name="Diagram.ClassType">
<map-to xml="Class"/>
<field name="name" type="java.lang.String">
<bind-xml name="Name" node="attribute"/></field>
Name: nombre que se traduce en String
<field name="methods" type="java.lang.String" collection="arraylist">
<bind-xml name="Method" node="element"/></field>
methos: métodos que se traducen en una lista de Strings
<field name="attributes" type="java.lang.String" collection="arraylist">
<bind-xml name="Attribute" node="element"/></field>
atributes: atributes que se traducen en una lista de Strings
<field name="associations" type="Diagram.RelationType" collection="arraylist">
<bind-xml name="Association" node="element"/></field>
associations: asociaciones que se traducen en una lista de tipo
RelationType.
<field name="compositions" type="Diagram.RelationType" collection="arraylist">
<bind-xml name="Composition" node="element"/></field>
compositions: asociaciones que se traducen en una lista de tipo
RelationType.
<field name="aggregations" type="Diagram.RelationType" collection="arraylist">
<bind-xml name="Aggregation" node="element"/></field>
aggregations: asociaciones que se traducen en una lista de tipo
RelationType.

60
<field name="generalizations"type="Diagram.RelationType"collection="arraylist">
<bind-xml name="Generalization" node="element"/></field>
generalizations: asociaciones que se traducen en una lista de tipo
RelationType.
<field name="dependencies" type="Diagram.RelationType" collection="arraylist">
<bind-xml name="Dependency" node="element"/></field>
dependencies: asociaciones que se traducen en una lista de tipo
RelationType.
Por último la clase RelationType se traducirá de la siguiente manera:
<class name="Diagram.RelationType">
<field name="multiplicity" type="java.lang.String">
<bind-xml name="Multiplicity" node="element"/></field>
multiplicity: mutiplicidad de la relacion que se traduce en String.
<field name="RelationTarget" type="java.lang.String">
<bind-xml name="RelationTarget" node="element"/></field>
RelationTarget: nombre del destino de la relación que se traduce en String.
<field name="roleName" type="java.lang.String">
<bind-xml name="RoleName" node="element"/></field>
roleName: nombre que se le da a la relación que se traduce en String.

61
5.3.1.2 De XML a UML
Llegados a este punto, tenemos unos documentos XML que contienen los modelos de diseño.
Puesto que la salida deben ser modelos de diseño, éstos se representan en UML y UML está
representado en XML, el siguiente paso se centra en hacer que los documentos XML sigan el
estándar de UML con el fin de que una herramienta CASE pueda representar su contenido en
diagramas gráficos.
La figura 20 refleja de forma gráfica el punto donde nos encontramos explicado
anteriormente.
Figura 20: de XML a UML
Por tanto, debemos realizar una búsqueda para comprobar si existe algún tipo de aplicación ya
construida o librería que nos permita pasar de XML a UML. Es muy difícil pensar que a partir
de un XML construido de forma personalizada pueda existir una librería que pueda
estandarizarlo a UML, pero podríamos encontrar alguna otra librería que a partir de algún paso
previo o a través de la librería Castor sea capaz de realizar esta conversión.
Si nos fijamos en cómo es un documento UML por dentro, observamos que su estructura es la
de un documento de XML pero además, el propio programa que lo ha generado introduce
ciertas etiquetas que solamente él puede entender.
Debemos dar un paso atrás y replantearnos si debemos continuar con la misma estructura
interna que maneja los objetos (maneja y crea), porque a partir del mapeo no conseguimos
estandarizar nada, simplemente vemos líneas futuras a través de la construcción de otra
herramienta que traduzca el XML obtenido (aunque esté basado en el W3C) en UML. De
manera ilustrativa, en la figura 21 se muestra el proceso fallido.
Figura 21: fallo al pasar de XML a UML

62
5.3.1.3 Reflexiones de la primera aproximación
Llegados a un punto donde se proporciona una salida válida pero no óptima, debemos
plantearnos hasta qué punto debemos optimizar el producto obtenido.
Partimos de que ya tenemos un documento generado en XML, y que además sigue un
estándar fijado por una organización que se dedica a crear y difundir estándares. Pero, ¿es
realmente lo que nosotros queremos en una herramienta de este estilo? ¿Hasta qué punto
vamos a ser exigentes con el resultado final?
Puesto que el deseo inicial de toda la investigación siempre fue obtener algo que pueda ser
usado y no solo conformarnos con algo que en un futuro puede ser transformado para ser
usado, debemos dar un paso atrás hasta el punto que veamos necesario.
En un principio el retroceso en la investigación/desarrollo no debería tener un gran impacto
puesto que la mayor parte de los objetivos están cubiertos, por lo que tenemos que centrarnos
en la obtención de un formato estándar, que puede seguir o no la estandarización XML pero
que alguna herramienta CASE, o simplemente un editor de imágenes pueda entender.
Así pues, volvemos al punto de tener ya un patrón personalizado en objetos y necesitamos de
alguna manera hacer una persistencia de ellos de forma que otra aplicación (relacionada con
diseño software) pueda entenderlo.

63
5.3.2 Segunda aproximación
La situación de la investigación a esta altura nos obliga a plantearnos nuevos caminos para
conseguir el único objetivo aún no resuelto, la confección de los diseños específicos.
Partiendo de nuevo de la necesidad de poder obtener el resultado en un formato estándar que
pueda ser entendido por una herramienta, de nuevo nos plantea las líneas futuras o presentes
del proyecto. ¿Es necesaria una representación portable? La respuesta es simple, no, pero
entonces el trabajo no estará terminado, orientando el resultado a unas líneas nuevas de
desarrollo de una aplicación que soporte la representación ya alcanzada.
Otra necesidad inducida por el trabajo terminado es la representación gráfica. Es posible que
estemos pasando por alto la existencia de algo tan evidente como una representación gráfica
a través de una manipulación de objetos y que puedan facilitar una salida en formato de
imagen.
Si de alguna manera pudiéramos combinar estos aspectos tendríamos un proyecto cerrado y
habremos satisfecho todos los objetivos iniciales propuestos para este proyecto. La
combinación de todos es conocido que es posible y ya existe, es decir, la representación que
ofrecen las herramientas CASE que están en el mercado. Estas herramientas por un lado
permiten el almacenamiento de archivos propios de la herramienta con una extensión propia,
y por otro, suelen permitir una exportación a una imagen de forma que pueda ser utilizada
para otros fines.
De manera que un nuevo enfoque o visión de las líneas de investigación podría consistir en
analizar internamente una herramienta de edición de diseño y en alguna manera existente de
intercambio de información entre ellas. De este nuevo enfoque surge el concepto XMI,
explicado en el punto 4.6 XMI.
5.3.2.1 XMI
El concepto XMI nace como fruto de investigar la posibilidad de intercambio de información
entre herramientas CASE.
Este estándar XML debería aportarnos al proyecto un alto nivel de portabilidad de modo que la
salida facilitada por el sistema pudiera no solo ser interpretada por otras herramientas, sino
puede ser editada, facilidad que sería aportada al proyecto de modo adicional.
Es decir, podríamos crear un proyecto de diseño nuevo a partir de las inclusiones de elementos
que se han realizado a través de una importación en XMI o bien, usar estos elementos para un
proyecto ya creado.
A continuación describiremos de qué manera aplicaremos el estándar XMI en el proyecto.

64
5.3.2.2 Aplicación de XMI en el proyecto
Este nuevo concepto de cara al proyecto, tiene muchas utilidades por lo que debemos conocer
de qué manera nos será útil en su aplicación. Puesto que XMI ya es un estándar extendido y
usado por muchos programas y aplicaciones, lo ideal sería encontrar una librería que nos
proporcionara una forma de representación de UML en objetos, y que además, sea capaz de
transcribirlos en formato XMI.
La aplicación de XMI en el proyecto además supondrá evitarnos un paso intermedio puesto
que no necesitaremos transformar información a UML sino que la representación de XMI, aún
siendo un formato XML, nos permite ofrecer los modelos de manera que sea reusables por
otras aplicaciones externas. La figura 22 nos muestra este único proceso.
Figura 22: aplicación de XMI en el proyecto

65
5.3.2.3 UMLGraph
UMLGraph permite la especificación declarativa y el dibujo de diagramas casos de uso, de
clase y diagramas de secuencia en UML. La especificación primeramente se hace en formato
de texto, para luego ser transformarlo en la representación gráfica apropiada.
Los diseñadores suelen crear sus diagramas de modelo utilizando un editor de dibujo. Sin
embargo, todos los editores de dibujo realizan una manipulación exigente y tediosa a la hora
de dibujar formas en el lienzo. El esfuerzo y las habilidades de coordinación motora necesaria
para esta actividad son en su mayoría irrelevantes para el resultado final: a diferencia de los
modelos de arquitectura e ingeniería mecánica, la aparición de modelos de un sistema
software están sólo marginalmente relacionados con la calidad del diseño de software
representados. Lo ideal sería una mezcla de ambas teorías, puesto que, son teorías
complementarias.
El nivel de abstracción de una librería como esta debe ser muy elevada, puesto que la
construcción interna de los diferentes modelos aceptados debe ser trivial para el programador,
es decir, la construcción del sistema deberá hacerse a través de métodos fachada.
La apuesta inicial en esta librería se basa en su capacidad para representar a nivel de objeto
todos los tipos de diagramas que necesitamos para nuestro fin (casos de uso, clases e
interacción).
Como elemento adicional, UMLGraph proporciona unos métodos de representación en
formato gráfico, muy útiles a la hora de poder realizar un depurado de los modelos
construidos, pudiendo componer una salida gráfica de hasta tres tipos de formatos: JPG, SVG y
PNG.
La importación de XMI se realiza de forma inmediata a través de un método único a modo de
fachada. Sin embargo, la exportación a XMI, que se realiza a través de otro método único de
forma análoga a la importación, pero en este caso tan solo soporta la exportación del modelo
de clases.
De manera que, aunque sea una librería muy completa en cuanto a posibilidades gráficas, no
lo es en cuanto a exportación de sus componentes en XMI. Por lo tanto, no es una librería
válida para aplicar en el proyecto.

66
5.3.2.4 Otras librerías parecidas
La búsqueda por la red de proyectos ya acabados y documentados prosiguió por encontrar una
librería que se adaptara de forma total a nuestro objetivo. El hecho de conseguir mapear
objetos en XMI es algo que no es nuevo, muchas herramientas CASE lo hacen sin ningún tipo
de complejidad, por lo que la nueva búsqueda deberá estar dirigida a librerías usadas en estas
herramientas CASE.
Ejemplos de librerías son las que nos presenta Novosoft:
NS MDF Library
NS UML library
Estas librerías con las empleadas en una famosa herramienta CASE construida en Java,
ArgoUML, y puesto que la aplicación final estará escrita en Java, podría sernos de gran utilidad.
El problema que arrastran estas librerías es la escasa documentación de su API, por lo que la
evaluación el tiempo de comprensión de las librerías debe ser medido de forma muy precisa
para las posibles decisiones futuras.
Existen algunos plugins para ciertas herramientas IDE de desarrollo, por lo que también nos
hace pensar que podríamos conducir la investigación hacia la comprensión de la
documentación de estos plugins orientados al desarrollo y no al diseño, es decir, obtener de
algún modo el código fuente de los plugins.
Llegados a este punto, llega una toma de decisiones que afectará al resto del proyecto en
cuanto a tiempo se refiere. Podemos seguir buscando algo que se ajuste a lo que necesitamos,
o bien, evaluar el tiempo de desarrollo que podría suponer construir una librería de este tipo
para el proyecto. Si tenemos en cuenta que existen muchas herramientas de desarrollo que
proporcionan un plugin llamado “ingeniería inversa”, es deducible que no suponen un esfuerzo
excesivamente grande llevar a cabo su construcción.
Analizando cuidadosamente el tiempo que podría conllevar la especialización en una
herramienta ya construida, sin apenas información, notamos que sería un tiempo muy
parecido a la construcción propia de la herramienta, pero con una ventaja importante para la
construcción; conocemos el producto porque lo hemos realizado nosotros mismos. Por lo que
si hubiera cualquier problema en la integración con la aplicación final, encontraríamos más
fácilmente como solventarlo.

67
5.3.2.5 Construcción de una librería
Una vez tomada la decisión de construir nuestra propia librería, debemos saber cómo
comenzar su creación. La línea lógica de investigación está compuesta por los estándares
propuestos y las aplicaciones y/o API’s que los contemplan e implementan.
5.3.2.6 XMI & StarUML
Partiendo de que XMI es un estándar creado por la OMG, accederemos a los estándares
publicados por esta organización, y realizaremos un estudio sobre las consideraciones y
recomendaciones que nos ilustran estos documentos.
La documentación de los estándares de XMI los podemos encontrar en la página
http://www.omg.org/spec/XMI/2.1.1/ . En esta página existen varias versiones y éstas en
varios formatos de archivos (PDF, PS etc.), pero básicamente todas ellas disciernen en
pequeñas puntualizaciones. Todas ellas nos hablan del esquema a seguir y de las distintas
formas de representación que dispone XMI, por lo que no es suficiente para la confección de la
librería.
Una forma de complementar esta documentación es examinar una herramienta CASE que
permita la exportación a XMI, que tenga licencia de libre distribución y que además, podamos
obtener su código fuente. Una de estas herramientas es StarUML.
StarUML es una herramienta de diseño (CASE) escrita en Pascal y que proporciona un interfaz
cómodo y sencillo. Además, entre sus opciones de importación y exportación se encuentra la
opción de importar/exportar desde/a XMI por lo que es idónea para nuestro propósito. El
código fuente encontrado se encuentra en un repositorio de desarrollo donde podremos
descargar todo el proyecto. El fin de su publicación es tener la posibilidad de incorporar
algunas mejoras y realizar correcciones de posibles bugs. Este repositorio se encuentra en dos
formatos de control de versiones: SVN (subversion) y CVS (Concurrent version system).
svn co https://staruml.svn.sourceforge.net/svnroot/staruml staruml para SVN
cvs -d:pserver:[email protected]:/cvsroot/staruml login
cvs -z3 -d:pserver:[email protected]:/cvsroot/staruml co -P
modulename para CVS
De modo que a través de las salidas provocadas por las exportaciones a XMI de StarUML, junto
con las especificaciones declaradas en los estándares que propone la OMG, obtenemos una
representación en XML (XMI) para los 3 tipos de diagramas UML que necesitamos representar.
Cabe destacar que una familiarización con el manejo de la herramienta, facilita enormemente
el trabajo de construcción de la representación, ya que cada variable de cada atributo XMI que
veremos a continuación es modificable a través de la propia herramienta y es visible tanto de
forma gráfica como de forma textual.

68
5.3.2.7 Representación XMI
Vamos a explicar cuál es la representación de cada tipo de diagrama UML y sus componentes.
Explicaremos el significado de cada atributo de XMI en la representación UML, es decir,
realizaremos una traducción partiendo del formato gráfico hasta llegar al formato de texto
XML (XMI). Deberemos entender previamente que cada elemento expresado en un formato
XML, requiere el uso de atributos XML y de Nodos hijos que nos servirán para ir explicando el
hecho de que un elemento puede contener varios elementos relacionados directamente con él
(namespaces), de tal forma que iremos explicando desde la capa más externa a la más interna.
Empezaremos con el formato que debe tener el documento.
5.3.2.7.1 Formato general
Antes de comenzar a definir la representación XMI de UML, debemos mencionar brevemente
el formato que debe seguir el documento. Deberá tener dos partes diferenciadas:
Cabecera: irá siempre al principio del documento y deberá contener información
adicional al documento. Estos datos informativos serán:
o Versión XMI
o Fecha
o Propietario.
o Contacto
o Exportador
o Versión del exportador
o Otra información de interés
Ej:
<XMI xmi.version="1.1" timestamp="Thu Oct 28 14:16:25 2010">
<XMI.header>
<XMI.documentation>
<XMI.owner/>
<XMI.contact/>
<XMI.exporter>TxemaAlex</XMI.exporter>
<XMI.exporterVersion>1.0</XMI.exporterVersion>
<XMI.notice/>
</XMI.documentation>
<XMI.metamodel xmi.name="UML" xmi.version="1.3"/>
</XMI.header>
Cuerpo: contendrá el resto de la información XMI asociada al proyecto que queramos
representar.
A continuación describiremos todo el posible contenido del cuerpo del documento XMI.

69
5.3.2.7.2 Representación de un proyecto
El proyecto simboliza todo el conjunto de diagramas que se van a detallar en el mismo
documento XMI. Para ello, deberemos definir una serie de etiquetas padre o nodos raíz de las
cuales todas las demás etiquetas dependan. Esto expresado en formato XMI (XML) será:
<XMI.content>
Comenzaremos el documento con una etiqueta XMI.content que será nuestro nodo raíz de
todo el documento.
<UML:Model xmi.id="UMLProject.1">
A continuación deberemos escribir el proyecto con la etiqueta UML:Model seguida por el
atributo id que expresará el identificador anteriormente comentado.
<UML:Namespace.ownedElement>
Por último abriremos la etiqueta UML:Namespace.ownedElement a partir de la cual
escribiremos el contenido del proyecto.

70
5.3.2.7.3 Representación de un modelo
En el estándar UML existen muchos tipos de modelos de los cuales nos quedaremos tan sólo
con 3 de ellos: los diagramas o modelos de casos de uso, los diagramas o modelos de clases y
los diagramas o modelos de secuencia/interacción. La representación del modelo pues,
significara crear el nodo padre que contendrá todo nuestro diagrama. De tal forma que para
representar en XMI cualquiera de los diagramas anteriormente citados tendremos que añadir:
<UML:Model xmi.id="undoUseCase" name="undoUseCase" visibility="public"
isSpecification="false" namespace="DUPP" isRoot="false" isLeaf="false" isAbstract="false">
Donde:
id: identificador único en todo el fichero. En caso de solo existir un solo modelo, podría
coincidir con el nombre dado al modelo.
name: nombre que se le quiera dar al modelo.
visibility: tipo de visibilidad del modelo. Puede ser:
o public: publico.
o private:privado.
o protected:protegido.
o package:paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al proyecto.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
Después de la declaración de cada diagrama, deberemos introducir la etiqueta
“<UML:Namespace.ownedElement>” exactamente de la misma manera que para el proyecto,
indicando así que a continuación introduciremos los elementos relacionados con el diagrama
en cuestión.
Cada modelo tendrá a partir de aquí una representación interna diferente, por lo que iremos
explicando poco a poco cada uno de los modelos.

71
5.3.2.7.4 Representación del modelo de casos de uso
Dividiendo el modelo de casos de uso en elementos/componentes podemos dividir éstos en 3
grandes grupos: actores, casos de uso y relaciones. XMI por su lado también hace esta
diferenciación de tal modo que directamente dentro del nodo padre del modelo se distinguen
actores, casos de uso y todo tipo de relaciones diferenciadas por su carácter en UML: include,
extend, association y generalization. Explicaremos de qué manera se representan todos estos
componentes internos.
Para visualizar de forma gráfica se presenta a continuación y pequeño esquema de la
organización del modelo de casos de uso en XMI. Este esquema correspondería a la jerarquía
interna del XML, es decir, si navegáramos de izquierda a derecha, iríamos de la etiqueta padre
(raíz) a las etiquetas hijas (hojas). La simbología representada es la estándar en cuanto a
cardinalidades:
num: cardinalidad obligatoria.
num1..num2: cardinalidad variable (de num1 a num2)
*: cardinalidad variable (de 0 a infinito)
Figura 23: esquema modelo casos de uso

72
5.3.2.7.4.1 Actor
Especifica un rol jugado por un usuario o cualquier otro sistema que interactúa con el sujeto.
Ejemplo:
<UML:Actor xmi.id="UMLActor.3" name="actor" visibility="public" isSpecification="false"
namespace="UMLModel.2" isRoot="false" isLeaf="false" isAbstract="false"
participant=" UMLAssociationEnd.7 UMLAssociationEnd.15"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al actor. Aparecerá como nombre en UML
visibility: tipo de visibilidad del actor. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
participant: es una lista separada por espacios en blanco que representan las
relaciones que tiene con los casos de uso.
También tiene la posibilidad de incluir otros atributos propios de los casos de uso, pero no
tienen sentido, como por ejemplo un include o un extend, por lo que no se especificarán en el
apartado del actor.

73
5.3.2.7.4.2 UseCase
Técnica para la captura de requisitos potenciales de un nuevo sistema o una actualización de
software. Cada caso de uso proporciona uno o más escenarios que indican cómo debería
interactuar el sistema con el usuario o con otro sistema para conseguir un objetivo específico.
Ejemplo:
<UML:UseCase xmi.id="UMLUseCase.4" name="caso1" visibility="public"
isSpecification="false" namespace="UMLModel.2" isRoot="false" isLeaf="false"
isAbstract="false" participant="UMLAssociationEnd.8" extend2="UMLExtend.11"
include="UMLInclude.9"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al caso de uso. Aparecerá como nombre en UML
visibility: tipo de visibilidad del caso de uso. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
participant: lista separada por espacios en blanco que representan las relaciones que
tiene (asociaciones).
include: lista separada por espacios en blanco que representan las relaciones
“include”que tiene (como origen).
include2: lista separada por espacios en blanco que representan las relaciones
“include” que tiene (como destino).
extend: lista separada por espacios en blanco que representan las relaciones “extend”
que tiene (como origen).
extend2: lista separada por espacios en blanco que representan las relaciones
“extend” que tiene (como destino).
generalization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como origen).
specialization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como destino).
En el caso del ejemplo, el caso de uso “caso1”, tiene visibilidad pública y 3 relaciones. Una de
ellas es una asociación de la cuál es destino, una include de la cuál es origen y una extend de la
cuál es destino también. Los atributos de los tipos de relaciones no.

74
5.3.2.7.4.3 Association
Relación (asociación) entre un actor y un caso de uso que denota la participación del actor en
dicho caso de uso.
Ejemplo:
<UML:Association xmi.id="UMLAssociation.6" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2">
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación. Normalmente suele ir vacio al no
llevar nombre la relacion
visibility: tipo de visibilidad de la relacion. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
La relación en XMI tiene un nodo hijo <Association.connection> que a su vez tiene dos nodos
hijos <AssociationEnd>. El primero de ellos estará relacionado con el origen de la relación, y el
segundo con el destino.

75
5.3.2.7.4.4 AssociationEnd
Indica el elemento destino de una relación. Cada “AssociationEnd” tiene todos los atributos
necesarios para expresar en una relación UML:
<UML:AssociationEnd xmi.id="UMLAssociationEnd.7" name="" visibility="public"
isSpecification="false" isNavigable="false" ordering="unordered" aggregation="none"
targetScope="instance" changeability="changeable" association="UMLAssociation.6"
type="UMLActor.3"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación. Normalmente suele ir vacio. No tiene
relevancia.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
isNavigable: es un booleano que determina si es el origen (false) o el destino (true). En
caso de que la relación no tenga sentido de navegación, los dos AssociationEnd
tendrán que ser true.
ordering: indica si es una relación que tiene orden (ordered) o no (unordered).
targetScope: nos muestra el ámbito del objetivo. Puede ser:
o instance : instancia.
o classifier: clase.
changeability: puede ser:
o changeable: que puede ser modificado.
o frozen: no editable.
o addonly: solo se puede añadir pero no borrar.
association: siempre será el identificador de la “Association” padre.
type: en cada caso, será el identificador del extremo al que está ligado, es decir, si este
“AssociationEnd” representa al origen, el id que deberá contener este campo será el id
del origen.

76
5.3.2.7.4.5 Include
Relación de dependencia entre dos casos de uso que denota la inclusión del comportamiento
de un escenario en otro.
Ejemplo:
<UML:Include xmi.id="UMLInclude.9" name="" visibility="public" isSpecification="false"
namespace="UMLModel.2" base="UMLUseCase.4" addition="UMLUseCase.5"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación include.
visibility: tipo de visibilidad de la relación include. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
base: identificador de un caso de uso que representa el origen de la relación.
addition: identificador de un caso de uso que representa el destino de la relación.
Deberán aparecer tantos elementos UML:Include como relaciones include existan en el
modelo, detallando de esta forma la relación de forma distinguida.

77
5.3.2.7.4.6 Extend
Relación de dependencia entre dos casos de uso que denota que un caso de uso es una
especialización de otro.
<UML:Extend xmi.id="UMLExtend.11" name="" visibility="public" isSpecification="false"
namespace="UMLModel.2" base="UMLUseCase.4" extension="UMLUseCase.10"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación extend.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
base: identificador de un caso de uso que representa el destino de la relación.
extension: identificador de un caso de uso que representa el origen de la relación.
Deberán aparecer tantos elementos UML:Extend como relaciones extend existan en el
modelo, detallando de esta forma la relación de forma distinguida. Nótese que en este caso, el
atributo “base” es el caso de uso destino y el atributo “extensión” el origen, puesto que, el
sentido de la relación por su semántica debería ser así.

78
5.3.2.7.4.7 Dependency
Relación entre dos casos de uso que refleja que el origen depende del destino.
<UML:Dependency xmi.id="UMLDependency.12" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2" client="UMLActor.3"
supplier="UMLUseCase.5"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación dependency.
visibility: tipo de visibilidad de la realción. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
base: identificador de un caso de uso que representa el destino de la relación.
extension: identificador de un caso de uso que representa el origen de la relación.
Deberán aparecer tantos elementos UML:Extend como relaciones extend existan en el
modelo, detallando de esta forma la relación de forma distinguida. Nótese que en este caso, el
atributo “base” es el caso de uso destino y el atributo “extensión” el origen, puesto que, el
sentido de la relación por su semántica debería ser así.

79
5.3.2.7.4.8 Generalization
Relación que denota una especificación de un caso de uso en otro.
<UML:Generalization xmi.id="UMLGeneralization.13" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2" discriminator="" child="UMLUseCase.5"
parent="UMLUseCase.10"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación generalization.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
discriminator: nombre que se le puede asignar a la relación para distinguirlo de otra.
child: identificador de un caso de uso que representa el origen de la relación.
parent: identificador de un caso de uso que representa el destino de la relación.
Deberán aparecer tantos elementos UML:Extend como relaciones extend existan en el
modelo, detallando de esta forma la relación de forma distinguida. Nótese que en este caso, el
atributo “base” es el caso de uso destino y el atributo “extensión” el origen, puesto que, el
sentido de la relación por su semántica debería ser así.

80
5.3.2.7.4.9 Stereotype
Además de los elementos de los que hemos hablado anteriormente, en XMI, se describe un
estereotipo para la representación de datos aún no contemplados. Estos estereotipos sirven
para añadir información a un elemento sobre el modelo, es decir, proporcionan información
complementaria pero no absoluta. Un ejemplo de estereotipo podría ser añadir a una relación
la información de que se realiza una suscripción (incorporado en UML como suscribe) o bien
definir un estereotipo propio que tenga sustancialmente información.
<UML:Stereotype xmi.id="X.18" name="useCaseModel" extendedElement="UMLModel.2"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al estereotipo.
extendedElement: es el nombre que se haya puesto al modelo de casos de uso.

81
5.3.2.7.5 Representación del modelo de clases
Dividiendo el modelo de clases en elementos/componentes podemos dividir éstos en 2
grandes grupos: clases y relaciones. XMI por su lado también hace esta diferenciación de tal
modo que directamente dentro del nodo padre del modelo se distinguen clases y todo tipo de
relaciones diferenciadas por su carácter en UML: association, generalization y dependency.
Explicaremos de qué manera se representan todos estos componentes internos.
Para visualizar de forma gráfica se presenta a continuación y pequeño esquema de la
organización del modelo de clases en XMI. Este esquema correspondería a la jerarquía interna
del XML, es decir, si navegáramos de izquierda a derecha, iríamos de la etiqueta padre (raíz) a
las etiquetas hijas (hojas). La simbología representada es la estándar en cuanto a
cardinalidades:
num: cardinalidad obligatoria.
num1..num2: cardinalidad variable (de num1 a num2)
*: cardinalidad variable (de 0 a infinito)
Figura 24: esquema modelo de clases

82
5.3.2.7.5.1 Class
Es la unidad básica que encapsula toda la información de un Objeto (un objeto es una instancia
de una clase). A través de ella podemos modelar el entorno en estudio.
<UML:Class xmi.id="UMLClass.4" name="clase1" visibility="public" isSpecification="false"
namespace="UMLModel.3" isRoot="false" isLeaf="false" isAbstract="false"
clientDependency="UMLDependency.46 UMLRealization.47"
supplierDependency="UMLDependency.31" generalization="UMLGeneralization.45"
specialization="UMLGeneralization.57" participant="UMLAssociationEnd.22" isActive="false">
id: identificador único en el modelo.
name: nombre que se le quiera dar a la clase.
visibility: tipo de visibilidad de la clase. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de clases.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
clientDependency: lista separada por espacios en blanco que representan las
relaciones “dependency”que tiene (como origen).
supplierDependency: lista separada por espacios en blanco que representan las
relaciones “dependency” que tiene (como destino).
generalization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como origen).
specialization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como destino).
participant: lista separada por espacios en blanco que representan las relaciones que
tiene (asociaciones).
isActive: booleano que determina si está activo. Por defecto es “false”.
Como hemos podido observar en el esquema gráfico, cada “Class” puede tener incluido
“Attribute” y “Operation”. Para delimitar su contenido, se utilizará la etiqueta
“<UML:Classifier.feature>”.

83
5.3.2.7.5.2 Attribute
Un atributo representa alguna propiedad de la clase que se encuentra en todas las instancias
de la clase:
<UML:Attribute xmi.id="UMLAttribute.4" name="Attribute1" visibility="private"
isSpecification="false" ownerScope="instance" changeability="changeable"
targetScope="instance" type="" owner="UMLClass.3"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al atributo.
visibility: tipo de visibilidad del atributo. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
ownerScope: es nos muestra el ámbito del nodo padre. Puede ser:
o instance: instancia.
o classifier: clase.
changeability: puede ser:
o changeable: que puede ser modificado.
o frozen: no editable.
o addonly: solo se puede añadir pero no borrar.
targetScope: nos muestra el ámbito del objetivo. Puede ser:
o instance : instancia.
o classifier: clase.
o
type: tipo del atributo.
owner: es el identificador de la clase a la que pertenece.

84
5.3.2.7.5.3 Operation
Un método u operación es la implementación de un servicio de la clase, que muestra un
comportamiento común a todos los objetos. En resumen es una función que le indica a las
instancias de la clase que hagan algo.
<UML:Operation xmi.id="UMLOperation.6" name="Operation1" visibility="public"
isSpecification="false" ownerScope="instance" isQuery="false" concurrency="sequential"
isRoot="false" isLeaf="false" isAbstract="false" specification="" owner="UMLClass.3"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la operación (método).
visibility: tipo de visibilidad de la operación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
ownerScope: es nos muestra el ámbito del nodo padre. Puede ser:
o instance: instancia.
o classifier: clase.
isQuery: es un booleano que determina si es una query sql.
concurrency: indica la concurrencia de la operación. Puede ser:
o sequential: secuencial.
o guarded: intermedio entre secuencial y concurrente (comedido).
o concurrent: concurrente.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
specification: especificación. Por defecto tiene el valor “” (vacío).
owner: es el identificador de la clase a la que pertenece.

85
5.3.2.7.5.4 Interface
Una Interfaz es una especificación para las operaciones externas visibles de una clase,
componente u otra entidad (incluyendo unidades globales como los paquetes), pero siempre
sin especificar la estructura interna.
<UML:Interface xmi.id="UMLInterface.16" name="inter1" visibility="public"
isSpecification="false" namespace="UMLModel.2" supplierDependency="UMLRealization.29"
isRoot="false" isLeaf="false" isAbstract="false" participant="UMLAssociationEnd.32">
id: identificador único en el modelo.
name: nombre que se le quiera dar al interfaz.
visibility: tipo de visibilidad del interfaz. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
clientDependency: lista separada por espacios en blanco que representan las
relaciones “dependency”que tiene (como origen).
supplierDependency: lista separada por espacios en blanco que representan las
relaciones “dependency” que tiene (como destino).
generalization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como origen).
specialization: lista separada por espacios en blanco que representan las relaciones
“generalization” que tiene (como destino).
participant: lista separada por espacios en blanco que representan las relaciones que
tiene (asociaciones).
isActive: booleano que determina si está activo. Por defecto es “false”.
Como hemos podido observar en el esquema gráfico, cada “Class” puede tener incluido
“Attribute” y “Operation”. Para delimitar su contenido, se utilizará la etiqueta
“<UML:Classifier.feature>”.

86
5.3.2.7.5.5 Association
Relación (asociación) entre dos clases con o sin direccionalidad.
Ejemplo:
<UML:Association xmi.id="UMLAssociation.6" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2">
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación. Normalmente suele ir vacio al no
llevar nombre la relacion
visibility: tipo de visibilidad de la Association. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de clases.
La relación en XMI tiene un nodo hijo <Association.connection> que a su vez tiene dos nodos
hijos <AssociationEnd>. El primero de ellos estará relacionado con el origen de la relación, y el
segundo con el destino. Cada “AssociationEnd” tiene todos los atributos necesarios para
expresar en una relación UML.

87
5.3.2.7.5.6 AssociationEnd
Indica el elemento destino de una relación. Cada “AssociationEnd” tiene todos los atributos
necesarios para expresar en una relación UML:
<UML:AssociationEnd xmi.id="UMLAssociationEnd.7" name="" visibility="public"
isSpecification="false" isNavigable="false" ordering="unordered" aggregation="none"
targetScope="instance" changeability="changeable" association="UMLAssociation.6"
type="UMLActor.3"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación. Normalmente suele ir vacio. No tiene
relevancia.
visibility: tipo de visibilidad de la AssociationEnd. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
isNavigable: es un booleano que determina si es el origen (false) o el destino (true). En
caso de que la relación no tenga sentido de navegación, los dos AssociationEnd
tendrán que ser true.
ordering: indica si es una relación que tiene orden (ordered) o no (unordered).
targetScope: nos muestra el ámbito del objetivo. Puede ser:
o instance : instancia.
o classifier: clase.
changeability: puede ser:
o changeable: que puede ser modificado.
o frozen: no editable.
o addonly: solo se puede añadir pero no borrar.
association: siempre será el identificador de la “Association” padre.
type: en cada caso, será el identificador del extremo al que está ligado, es decir, si este
“AssociationEnd” representa al origen, el id que deberá contener este campo será el id
del origen.

88
5.3.2.7.5.7 Dependency
Relación entre dos clases que refleja que el origen depende del destino.
<UML:Dependency xmi.id="UMLDependency.12" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2" client="UMLActor.3"
supplier="UMLUseCase.5"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación include.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
base: identificador de un caso de uso que representa el destino de la relación.
extension: identificador de un caso de uso que representa el origen de la relación.
Deberán aparecer tantos elementos UML:Dependency como relaciones dependency existan en
el modelo, detallando de esta forma la relación de forma distinguida. Nótese que en este caso,
el atributo “base” es el caso de uso destino y el atributo “extensión” el origen, puesto que, el
sentido de la relación por su semántica debería ser así.

89
5.3.2.7.5.8 Generalization
Relación que denota una especificación de una clase en otra.
<UML:Generalization xmi.id="UMLGeneralization.13" name="" visibility="public"
isSpecification="false" namespace="UMLModel.2" discriminator="" child="UMLUseCase.5"
parent="UMLUseCase.10"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la relación generalization.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de casos de uso.
discriminator: nombre que se le puede asignar a la relación para distinguirlo de otra.
child: identificador de un caso de uso que representa el origen de la relación.
parent: identificador de un caso de uso que representa el destino de la relación.
Deberán aparecer tantos elementos UML:Generalization como relaciones generalization
existan en el modelo, detallando de esta forma la relación de forma distinguida.

90
5.3.2.7.5.9 Stereotype
Como hemos comentado para los casos de uso estereotipos sirven para añadir información a
un elemento sobre el modelo.
<UML:Stereotype xmi.id="X.18" name="classModel" extendedElement="UMLModel.2"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al estereotipo.
extendedElement: es el nombre que se haya puesto al modelo de clases.

91
5.3.2.7.6 Representación del modelo de interacción
Define el principio mediante el cual se diseña la interacción en el interfaz.
Este modelo es un enfoque holístico de las acciones y funcionalidades de la herramienta, por
lo que indica de forma general como se diseñan los comportamientos del sistema frente a las
distintas acciones.
Para visualizar de forma gráfica se presenta a continuación y pequeño esquema de la
organización del modelo de interacción en XMI. Este esquema correspondería a la jerarquía
interna del XML, es decir, si navegáramos de izquierda a derecha, iríamos de la etiqueta padre
(raíz) a las etiquetas hijas (hojas). La simbología representada es la estándar en cuanto a
cardinalidades:
num: cardinalidad obligatoria.
num1..num2: cardinalidad variable (de num1 a num2)
*: cardinalidad variable (de 0 a infinito)
Figura 25: esquema modelo de interacción

92
5.3.2.7.6.1 Collaboration
Expresa que se va a declarar un modelo de colaboración.
<UML:Collaboration xmi.id="UMLCollaborationInstanceSet.3"
name="CollaborationInstanceSet1" visibility="public" isSpecification="false">
id: identificador único en el modelo.
name: nombre que se le quiera dar a la colaboración.
visibility: tipo de visibilidad de la colaboración. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
Para conocer el alcance de la colaboración, se indica a través de una etiqueta
<UML:Collaboration.interaction> con su correspondiente cierre de etiqueta al final de la
colaboración.

93
5.3.2.7.6.2 Interaction
Esta etiqueta engloba una interacción dentro de una colaboración específica.
<UML:Interaction xmi.id="UMLInteractionInstanceSet.4" name="InteractionInstanceSet1"
visibility="public" isSpecification="false" context="UMLCollaborationInstanceSet.3">
id: identificador único en el modelo.
name: nombre que se le quiera dar a la interaccion.
visibility: tipo de visibilidad de la interacción. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
context: es el nombre que se haya puesto a la colaboración a la que pertenece.

94
5.3.2.7.6.3 Message
Es el mensaje o estímulo provocado para la comunicación entre dos objetos.
<UML:Message xmi.id="UMLStimulus.5" name="llamada1" visibility="public"
isSpecification="false" sender="UMLObject.7" receiver="UMLObject.8"
interaction="UMLInteractionInstanceSet.4">
id: identificador único en el modelo.
name: nombre que se le quiera dar al mensaje, es decir, el nombre del método a
ejecutar con sus parámetros.
visibility: tipo de visibilidad del mensaje. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
sender: identificador del objeto emisor.
receiver: identificador del objeto receptor.
interaction: identificador de la interacción a la que pertenezca.
Además, para cada mensaje deberemos especificar la acción (el tipo de estímulo) con la
etiqueta <UML:Message.action> y su correspondiente etiqueta de cerrado al final de la acción
del mensaje.

95
5.3.2.7.6.4 Action
Las acciones son diferentes dependiendo del tipo de estímulo pudiendo ser:
Call: llamada (estímulo estándar)
Send: envío (se espera una respuesta)
Response: respuesta.
Create: estímulo de creación de un objeto nuevo.
Destroy: estímulo de destrucción de un objeto.
Estas posibilidades irán incluidas de forma implícita en la especificación escrita es decir, irá
dentro del tipo de etiqueta “UML:tipoAction”. El siguiente ejemplo nos muestra una llamada
estándar.
<UML:CallAction xmi.id="UMLCallAction.6" name="" visibility="public" isSpecification="false"
isAsynchronous="false" stimulus="UMLStimulus.5"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la acción, no tiene relevancia.
visibility: tipo de visibilidad de la relación. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
isAsynchronous: es un booleano que determina si es una llamada asíncrona o no.
stimulus: identificador del estímulo al que pertenece.

96
5.3.2.7.6.5 ClassifierRole
ClassifierRole representa a un objeto dentro de un modelo de colaboración Este objeto debe
pertenecer obligatoriamente a una clase determinada que también deberá ir en el contenido
de la etiqueta. Para delimitar el ámbito de las clases (ClassifierRole) se especifica una etiqueta
al comienzo del tipo <UML:Namespace.ownedElement> y otra correspondiente al cierre de
etiquetas en XML al final de su ámbito.
<UML:ClassifierRole xmi.id="UMLObject.7" name="Object1" visibility="public"
isSpecification="false" base="UMLClass.9" message2="UMLStimulus.5" isRoot="false"
isLeaf="false" isAbstract="false">
id: identificador único en el modelo.
name: nombre que se le quiera dar al objeto.
visibility: tipo de visibilidad del objeto. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
base: es el identificador de la clase a la que pertenece.
message2: lista de los identificadores de los estimulos que recibe separados por
espacios en blanco.
message: lista de los indentificadores de los esimulos que envía separados por
espacios en blanco.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
Ademas debemos especificar una serie de etiquetas (con sus correspondientes etiquetas de
cierre) que expresan la multiplicidad del objeto:
<UML:ClassifierRole.multiplicity>
<UML:Multiplicity xmi.id="X.12">
id: identificador único en el modelo.
<UML:Multiplicity.range>
<UML:MultiplicityRange xmi.id="X.13" lower="1" upper="1" multiplicity="X.12"/>
id: identificador único en el modelo.
lower: mínima cardinalidad.
upper: máxima cardinalidad.
multiplicity: identificador de la etiqueta multiplicity padre.

97
5.3.2.7.6.6 Class
Es la unidad básica que encapsula toda la información de un Objeto (un objeto es una instancia
de una clase). A través de ella podemos modelar el entorno en estudio.
<UML:Class xmi.id="UMLClass.9" name="clase1" visibility="public" isSpecification="false"
namespace="UMLModel.2" isRoot="false" isLeaf="false" isAbstract="false" isActive="false"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar a la clase.
visibility: tipo de visibilidad de la clase. Puede ser:
o public: público.
o private: privado.
o protected: protegido.
o package: paquete.
isSpecification: es un booleano que determina si es una especificación. Por defecto
debe ser “false”.
namespace: es el nombre que se haya puesto al modelo de interacción.
isRoot: booleano que determina si es nodo raíz. Por defecto es “false”.
isLeaf: booleano que determina si es nodo hoja. Por defecto es “false”.
isAbstract: booleano que determina si es abstracto. Por defecto es “false”.
isActive: booleano que determina si está activo. Por defecto es “false”.

98
5.3.2.7.6.7 Stereotype
Al igual que en los anteriores modelos, también podremos crear estereotipos.
<UML:Stereotype xmi.id="X.18" name="interactionModel" extendedElement="UMLModel.2"/>
id: identificador único en el modelo.
name: nombre que se le quiera dar al estereotipo.
extendedElement: es el nombre que se haya puesto al modelo de interación.

99
5.3.2.8 Representación en objetos
Una vez que tenemos definida la representación de los modelos UML en XMI, es muy sencillo
explicar la jerarquía de clases que debemos crear para poder definir todos los datos
anteriormente representados.
Para ello basta con crear una clase por cada elemento citado (modelos y sus elementos hijos)
teniendo en cuenta todos los atributos que también deberán formar parte de las clases como
atributos. En cuanto a la jerarquía, tan solo debemos seguir el esquema gráfico inicial de cada
modelo y tendremos la estructura completa.
Para su representación escrita, una buena metodología sería conseguir en un método una
llamada sucesiva a todos sus elementos, de forma que estos elementos hijos realicen a su vez
dicha llamada a sus elementos hijos y que cada elemento obtenga su representación escrita de
forma organizada.
En cuanto a la instanciación de objetos, deberemos tener un objeto padre que sea el modelo
(diseño), y que a través de él se realicen tanto las instanciaciones nuevas, como las
asociaciones o modificaciones de datos, de este modo, centralizaremos el comportamiento del
modelo a través de su objeto modelo a modo de fachada. Con este modelado interno
aportamos un nivel alto de abstracción en su uso posterior.
La persistencia del modelo construido solo tiene sentido en un formato de texto plano y por
tanto tan solo deberemos permitir la exportación a fichero. El fichero o ficheros finales
conformarán uno de los objetivos primarios del proyecto satisfecho a través de la exportación
a XMI de los diagramas UML ya personalizados.

100
5.3.3 Reflexiones de la segunda aproximación
A través de la exportación a XMI no solo conseguimos una estandarización de los documentos
generados sino que nos aporta la potencia de un estándar para el intercambio de
metamodelos, es decir, no son solo modelos completos de diseño, sino que queda a la elección
del diseñador software como usar sus elementos dentro de un proyecto.
La estandarización conseguida está demostrada en varias herramientas que aceptan XMI como
una de sus opciones de importación. Su destino es la portabilidad de metamodelos por lo que
el hecho de la creación de un nuevo proyecto de diseño que incluya estos metamodelos limita
el proyecto a la herramienta que se use para su creación, en otras palabras, podemos usar los
metamodelos en todas las herramientas que queramos pero teniendo en cuenta que los
proyectos UML de cada herramienta son únicos por cada una de ellas.

101
6 Desarrollo
Una vez que hemos tomado las decisiones hasta llegar a una solución final, hablaremos de la
implementación en sí de la aplicación. Como procedimiento a esta explicación, primero
realizaremos una visión de análisis de la aplicación, donde veremos los requisitos que vamos a
desarrollar. Más adelante, veremos algunos matices en la etapa de diseño. Por último,
mostraremos un prototipo de interfaz de usuario donde se explicará de forma detallada en
qué consiste la aplicación y de qué manera satisface los requisitos analizados. Es decir,
seguiremos los pasos definidos en el proceso unificado.
6.1 Especificación de Requisitos Software
Primero realizaremos un análisis de los requisitos que incluirá el sistema. Los objetivos
principales que esta aplicación debe satisfacer son todos aquellos que están relacionados
directamente con el rol de cliente. Es decir, la aplicación partiendo del sistema experto ya
constituido especificado en el estándar XML definido en el apartado x.x.x, el usuario aportará
sus decisiones en relación a las características de usabilidad a tratar para finalmente obtener
un diseño y responsabilidades específicas para cada patrón.
DUPP (Deployment Usability Patterns Project) tiene los siguientes requisitos:
Req (1): Ambigüedad en el sistema
Deberá ser un sistema completamente abierto de forma que por un lado obtenga la
base de conocimiento de varios ficheros organizados por patrón, y, por otro lado, debe
tener la posibilidad de integrar más patrones de una manera sencilla e independiente
de la compilación.
Req (2): Estandarización de documentos de entrada (guía de elicitación)
La guía de elicitación constará de un fichero por patrón con extensión y formato XML.
Este fichero deberá seguir el esquema explicado en el apartado x.x.x.
Req (3): Estandarización de documentos de entrada (guía de diseño)
La guía de diseño constará de un fichero por patrón con extensión y formato XML. Este
fichero deberá seguir el esquema explicado en el apartado x.x.x.

102
Req (4): Patrones de usabilidad necesarios
Al menos, el sistema experto deberá contener los siguientes patrones de usabilidad:
o Undo/Redo
o System Status Feedback
o System Progress Feedback
o Abort
o Warning
o Multilevel Help
o Commands Aggregation
o Step by Step
o Favorites
o Personal Object Space
o Preferences
Req (5): Modelos de diseño
Por cada patrón, se deberá facilitar al menos un diagrama de cada tipo, siendo los
tipos:
o Diagrama de Casos de Uso
o Diagrama de Secuencia
o Diagrama de Clases
Req (6): Resultados obtenidos
El fichero de salida deberá ser un fichero comprimido que contenga los patrones
personalizados de los cuales se haya contestado alguna pregunta. En cada carpeta de
cada patrón deberán aparecer 3 tipos de archivos:
o PDF: contendrá el resumen de las respuestas aportadas por el usuario.
o XLS: serán las tablas Excel con las responsabilidades a medida de cada patrón.
o XMI: serán los diagramas de casos de uso, clases e interacción específicos del
patrón escritos en este estándar.
Req (7): Idioma
La aplicación estará escrita de forma íntegra en inglés.
Req (8): Autenticación
El sistema no requiere ningún tipo de verificación de identidad ni de seguridad, por lo
que podrá ser usado por cualquier usuario. El usuario para el que está destinado esta
aplicación es un usuario especializado en ingeniería del software.

103
Req (9): Inclusión de nuevos patrones
El fichero que contiene los nombres de los patrones deberá incluir una descripción a
modo de ayuda que deberá ser mostrada cuando el ratón se posicione encima de cada
patrón. Este fichero seguirá el esquema siguiente:
<patterns>
<pattern>
<name>Nombre de patron</name>
<helpText>Texto de ayuda<helpText/>
</pattern>
*…+
<pattern>
<name>…</name>
<helpText>…<helpText/>
</pattern>
</patterns>
Cualquier etilo que se le quiera aplicar, deberá estar escrito en HTML no directo, es
decir, utilizar una representación HTML para mostrar en una página HTML. Por
ejemplo, la representación HTML del símbolo “<” es “>”
Req (10): Usabilidad-Multilevel Help
El formulario que represente la guía de elicitación deberá presentar un esquema visual
que facilite la comprensión de las posibles bifurcaciones del patrón.
Req (11): Usabilidad-Status feedback
El formulario que represente la guía de elicitación deberá presentar un esquema visual
que facilite la comprensión de las posibles bifurcaciones del patrón.
Req (12): Usabilidad-Undo
La aplicación deberá admitir la posibilidad de poder volver a responder una pregunta
ya pasada a modo de “deshacer” o atrás.
Req (13): Entorno distribuido
Se realizará una aplicación web de modo que se centralice el conocimiento en una
única instancia.

104
6.2 Diseño
Al seguir el proceso unificado, se ha seguido un proceso iterativo e incremental por lo que se
ha dividido el diseño e implementación en 2 ciclos claramente diferenciados.
En el primero ciclo, se ha afrontado todo lo referente a funcionalidad y por tanto todo lo
relativo con el modelo o lógica de negocio y con la vista (Requisitos 1, 2, 3, 4, 5, 7, 8, 10, 11, 12
y 13).
El segundo ciclo está destinado a añadirle ciertas funcionalidades fuera de una planificación
inicial. Estas funcionalidades son:
1. La aplicación de ambigüedad a la hora de introducir cambios o nuevos patrones al
sistema (Req (9): Inclusión de nuevos patrones).
2. Establecer una estandarización abierta para el formato de entrega de los documentos
generados (Req (6): Resultados obtenidos, XMI).
1. Añadir mejoras visuales (look & feel).
Primero realizaremos un estudio de los casos de uso que se obtienen de a partir de los
requisitos del sistema.
6.2.1 Casos de uso
Aunque se disponga de varios requisitos, esta aplicación deberá contemplar dos casos de uso.
Ilustración 1: diagrama de casos de uso
El primer caso de uso es suficientemente importante como para albergar él solo una aplicación
puesto que conforma el grueso de la aplicación. Este caso de uso englobaría todos los
requisitos anteriormente especificados.
El segundo caso de uso aporta una funcionalidad que va implícita en una aplicación web, es
decir, realizar una exportación del trabajo realizado.
Explicaremos estos casos de uso en formato completo:

105
Caso de uso CU01: Personalizar patrón
Actores Cliente
Propósito
El cliente tiene la intención de obtener un diseño y unas responsabilidades específicas a través de la respuesta a las preguntas que vaya formulando el sistema.
Resumen
El sistema irá formulando preguntas y a partir de las respuestas del actor, deberá realizar internamente una personalización del patrón.
Tipo Primario y esencial
Referencias cruzadas
Curso Normal de los eventos
1.El cliente una vez ha accedido al sistema elige un patrón que quiera realizar la especificación.
3.El cliente contestará con texto en caso de ser una pregunta que necesite una respuesta textual o bien elegirá una de las opciones en caso de que sea una pregunta bifurcativa. (los pasos 2 y 3 se repetirán hasta que no existan más preguntas)
2.El sistema mostrará una pregunta. 4.El sistema regresará a la pantalla principal
Curso Alternativo
3a.El cliente quiere volver a la pregunta anterior.
3a.El sistema mostrará la pregunta anterior eliminando las respuestas de las preguntas actual y anterior.

106
Caso de uso CU02: Descargar los documentos específicos
Actores Cliente
Propósito
El cliente tiene la intención de descargar los patrones personalizados a los que ha contestado alguna pregunta.
Resumen
El sistema mostrará una ventana de descarga donde se proporciona un archivo con los documentos comprimidos en él.
Tipo Primario y esencial
Referencias cruzadas
Curso Normal de los eventos
1.El cliente decide descargar los patrones personalizados.
3.El cliente guardará el archivo
2.El sistema mostrará una ventana de descarga con el archivo comprimido.
Curso Alternativo
1a.El cliente cierra el explorador de internet
1a.El sistema al no tener una sesión activa ni identificativa desecha las respuestas del cliente.

107
6.2.2 Clases
Una vez vistos los casos de uso, mostraremos las partes más relevantes de los diagramas de
clases. Puesto que es una aplicación que contiene partes muy diferenciadas, dividiremos el
diagrama de clases final en varios diagramas dependiendo de su funcionalidad y además
eliminaremos los métodos get/set de estos diagramas para facilitar su lectura y comprensión.
Para la división de la aplicación en varios diagramas de clases, iremos recorriendo el flujo
básico del caso de uso “CU01: Personalizar patrón”.
El cliente al seleccionar un patrón lanzará una petición en el servidor que hará que se cargue la
guía de elicitación a través de un parser que se encargue de leer el fichero XML externo. Como
se ha explicado anteriormente, el fichero XML deberá seguir un esquema específicamente
creado para la elicitación, por lo que para realizar su lectura y procesado a nivel de objetos,
deberemos crear un parser a medida, aunque internamente este parser utilice algunas clases
ya definidas en el lenguaje de programación elegido.
A través de una clase llamada “FormController”, podemos leer el fichero e ir creando la guía de
elicitación en objetos. Será la encargada de controlar el acceso al fichero y por tanto de la
creación de todos los objetos relacionados con la lectura.
Una vez que tenemos ya introducidos la base de conocimiento en la aplicación, el usuario irá
respondiendo a las preguntas que el sistema va planteando. Estas respuestas tienen impacto
en los documentos que son generados a su vez, por lo que deberemos realizar acciones
internas transparentes al usuario.
La guía elicitación se conforma por una serie de preguntas donde cada una de ellas llevará
asociada una serie de acciones dependiendo de la respuesta del usuario. Estas acciones podrán
ser o acciones de diseño o acciones de escritura en fichero de respuestas o podrán ser
acciones sobre una tabla Excel.
El diagrama de clases que se especifica a continuación, explica a nivel de diagrama de clases de
qué manera se realiza esa lectura.

108
Diagrama de clases 1: parser XML

109
Además de importar la guía de elicitación del patrón en cuestión, se realiza una carga inicial de
la guía de diseño, es decir, los elementos invariantes de los modelos a construir a modo de
simplificar la elicitación. Esta importación también se realiza a través de un fichero XML pero
puesto que sigue un esquema diferente, el parser deberá ser diferente.
De forma análoga a la importación anterior, se muestra un diagrama de clases específico.
Diagrama de clases 2: guía de diseño
La diferencia con la elicitación es principalmente como transformamos la información del
fichero XML, es decir, pasar esta información a objetos.
A partir de aquí nos centramos precisamente en el data binding, es decir, realizar el mapeo de
XML a objetos. Al tener que representar en objetos 3 tipos de diagramas de diseño y a modo
de facilitar la comprensión de los modelos, se presentan los 3 tipos de diagramas en 3
diagramas de clases diferentes.

110
Diagrama de clases 3: casos de uso

111
Diagrama de clases 4: clases

112
Diagrama de clases 5: secuencia

113
6.3 Implementación
En la implementación el primer paso a dar es seleccionar el lenguaje de programación que se
va a utilizar en el desarrollo. En este caso, la elección ha sido Java.
A partir de esta decisión y siguiendo los requisitos, debemos realizar una aplicación en entorno
distribuido por lo que no solo utilizaremos el lenguaje Java, sino J2EE, es decir, todos los
lenguajes y metodologías relacionadas con una aplicación web para Java (JSP, Servlets,
Javascript, HTML etc.).
Como ayuda adicional se ha introducido un framework llamado “struts”. Este framework
facilita a través de unos ficheros en formato XML la configuración del entorno web. Por otro
lado y de forma automática, realiza la separación entre las capas de modelo, vista y
controlador, es decir, que implícitamente se usa el patrón software modelo-vista-controlador.
Además de este patrón mencionado, y gracias a la diversidad de estilos de HTML se han de
introducir algunos patrones de usabilidad estudiados a lo largo de la tesis. Esta usabilidad
comprende principalmente tres de estos patrones:
3. Necesitamos incluir una descripción a modo de resumen de cada patrón para que un
usuario no experto en el uso de la aplicación pueda entender perfectamente de que se
trata el patrón (Status feedback).
4. En caso de responder a una pregunta de forma errónea, el sistema deberá aportar una
forma de deshacer esta respuesta (Undo).
5. En todo momento dentro de un formulario debemos conocer que preguntas se nos
han hecho, cuales nos quedan por contestar y en qué situación nos encontramos
(status feedback).
Teniendo en cuenta estas premisas, procederemos a mostrar una versión terminada de esta
aplicación.

114
La pantalla de inicio muestra todos los patrones introducidos a través del fichero
“patterns.xml”.
Ilustración 2: pantalla inicial
Si somos un usuario que no conoce en profundidad los patrones mostrados, y quisiéramos
saber de qué se trata (resumen), bastará con poner el ratón (sin hacer click en él) sobre uno de
los botones que ilustran los patrones.
Ilustración 3: Multilevel Help
Una vez que hayamos seleccionado un patrón, se nos mostrará un formulario de este tipo:

115
Ilustración 4: formulario
En él, tendremos dos tipos diferentes de preguntas. Una es una pregunta donde se mostrará
un área de texto donde podremos escribir la respuesta en un formato de párrafo. El otro tipo
de pregunta se trata de la elección frente a una pregunta que debemos contestar si o no.
Ilustración 5: bifurcación
Como algo excepcional, algunos patrones incorporan algunas preguntas que se salen del
estándar de preguntas. Este es el caso de usar una lista anterior para separarla en dos listas
diferentes.

116
Ilustración 6: dos listas
Además de todo lo mostrado, en cualquier momento podemos movernos hacia delante o hacia
atrás para contestar de nuevo a la pregunta que queramos utilizando los botones “Anterior” y
“Siguiente”.
Ilustración 7: anterior y siguiente
Una vez finalizado el uso de esta herramienta, podremos descargarnos en un fichero
comprimido todos los patrones que hayamos respondido alguna pregunta separados en
carpetas nombradas por el nombre del patrón en cada caso.

117
Ilustración 8: descarga1
Ilustración 9: descarga2

118
6.4 Instalación
La instalación de esta aplicación requiere instalar otras aplicaciones para que ésta funcione.
Explicaremos los pasos y programas necesarios para que la aplicación funcione correctamente.
1. Instalación de servidor Apache Tomcat.
Para instalar el servidor Apache Tomcat, primero deberemos descargarlo de forma
totalmente gratuita de la página web oficial de Apache http://tomcat.apache.org/ para
el sistema operativo que queramos instalar. Después deberemos seguir los pasos para
su instalación a través de las guías de la página web.
2. Instalación de los documentos/ficheros que componen la base de conocimientos.
Los ficheros que componen la base de conocimientos deberán ir separados en 3
grupos.
Por un lado irán todos los ficheros que compongan la guía de elicitacion. Estos
documentos irán alojados en el directorio de instalación del servidor Tomcat
concretamente en la ruta: path_de_instalacion_Tomcat/webapps/elicitation.
De forma análoga, los documentos que conforman la guía de diseño deberán ir
instalados en la ruta: path_de_instalacion_Tomcat/webapps/design.
Las tablas de responsabilidades deberán tener también su localización específica.
Deberán estar en la ruta: path_de_instalacion_Tomcat/webapps/tables.
Los patrones de diseño que se vayan a introducir siguiendo el esquema definido en el
requisito “Req (9): Inclusión de nuevos patrones” deberán alojarse bajo la ruta:
path_de_instalacion_Tomcat/webapps/patterns.
3. Arranque del servidor.
Una vez instalada la base de conocimiento, deberemos arrancar el Tomcat. Para ello
deberemos tener configurado el Tomcat para arrancar en un puerto específico. Por
defecto, Apache Tomcat está configurado para arrancar en el puerto 8080. Por ello, si
deseamos que arranque en ese puerto tan solo deberemos ejecutar el archivo
“startup” (.bat si estamos en un sistema operativo Windows o .sh si estamos en un
Unix).
4. Uso de la aplicación.
Para acceder a la aplicación, abriremos un explorador de internet (la aplicación
funciona para los exploradores más comunes como son internet explorer, firefox,
safari, opera…) y en la barra de direcciones tendremos que introducir la dirección IP o
bien el nombre simbólico si tenemos configurado DNS y a continuación dos puntos y el
puerto donde se encuentre corriendo el Tomcat.

119
7 Resultados
El resultado que debemos destacar por encima de todo es una especialización en cuanto a
generación y obtención de documentos que sigan estándares fijados por organizaciones tan
importantes como la W3C.
Hoy en día, desde los datos que viajan en internet para ser mostrados en una página web,
hasta la codificación interna que manejan los programas orientados a su uso en oficina (office),
internamente tienen una codificación estándar, y ésta suele ser algún lenguaje derivado de
XML. Es por esto que conocer y comprender como generarlos podemos considerar un
resultado muy positivo.
A través de lo demostrado en la investigación podemos ver que la personalización de un
patrón a partir de unos documentos en papel puede resultar algo muy sencillo si miramos a
través de una aplicación de este estilo.
Aunque inicialmente el propósito era construir una aplicación a medida, el hecho de aportar
ambigüedad al sistema dejando abierta la base de conocimiento nos conduce a una aplicación
real de un ámbito no imaginable desde una visión poco madura.
El resultado obtenido además es portable a grandes herramientas que hoy en día resultan
imprescindibles en el mundo del diseño software. Esta portabilidad del resultado hace augurar
investigaciones futuras siguiendo por la línea de la exportación XMI.

120
8 Conclusiones y trabajos futuros
Como conclusión debemos mencionar que las investigaciones y los desarrollos se han basado
en un entorno muy concreto y pese a que se ha buscado aportarle la mayor ambigüedad
posible, probablemente se puedan mejorar ciertos aspectos, pero como hemos mencionado,
ligados al ámbito del entorno en el que se ha construido.
A grandes rasgos y partiendo de que la implementación de las aplicaciones demostradas se
han basado en un patrón modelo-vista-controlador, podríamos cambiar la vista por cualquier
otra, incluso llegando al extremo de la creación de una aplicación para teléfonos móviles.
Puesto que la construcción de una librería a partir de un modelo ya implementado es
extremadamente sencilla, los consiguientes trabajos futuros estarán ligados estrechamente
con su uso de esta herramienta en otras aplicaciones.
Una línea futura de este proyecto podría consistir en realizar una implementación interna en
una de las herramientas CASE, es decir, a partir del modelo construido, usarlo a modo de
librería para crear un plugin dentro de la herramienta. Este trabajo incorporaría en una
herramienta la posibilidad de partir de un diseño donde tendríamos precargados una serie de
elementos editables dependiendo de un patrón o patrones que deseemos incluir en nuestro
proyecto.
Otras líneas futuras podrían estar dirigidas a realizar una versión mejorada en cuanto al
desarrollo. Puesto que la investigación ha sido donde más esfuerzo se ha invertido, podríamos
conseguir un producto final con mejor resultado visual, o bien, con un entorno más intuitivo.
En el caso de quisiéramos dirigir el resultado final a otros ámbitos como pueden ser los
servicios distribuidos, dado que el desarrollo se ha realizado bajo un lenguaje de alto nivel que
se adapta a los cambios más actuales, tampoco resultaría ningún coste excesivo en cuanto a
esfuerzo se refiere.
Al igual que existen algunas librerías que realizan un dibujo de forma intuitiva sobre ciertos
diagramas, se podría desarrollar una herramienta que a través de los documentos en formato
XMI, pudieran realizar un esquema inicial de lo que se representa en XMI, es decir, una pre
visualización del código en formato de imagen.
Quizá en un futuro podría realizarse otro tipo de aplicación relacionada con los patrones de
usabilidad, pero esta vez partiendo de los diagrama en XMI, para que se pudiera generar un
único diagrama por cada tipo que incluyera todos los patrones que se desean incluir, de forma
que con cambiar el nombre a las clases, obtuviéramos el diseño personalizado y completo.

121
9 Bibliografía
UML For W3C XML Schema Design:
http://www.xml.com/pub/a/2002/08/07/wxs_uml.html
HiperModel 3.0:
http://xmlmodeling.com
Mapping UML Diagrams To XML:
http://uml2xml.tripod.com/sitebuildercontent/sitebuilderfiles/utx_doc.pdf
Design XML schemas using UML:
http://www.ibm.com/developerworks/library/x-umlschem/
Check out the site on XML modeling which discusses many applications of UML-to-XML
modeling.
Delve into Dave Carlson's excellent book Modeling XML Applications with UML:
Practical e-Business Applications.
Read Dave Carlson's three-part series of articles on "Modeling XML Vocabularies with
UML."
Explore Will Provost's article on XML.com, "UML for W3C Schema Design."
Download and review the XMI specification by the Object Management Group (OMG).
Learn how one organization uses UML and XMI to create software in "XMI and UML
combine to drive product development" by Cameron Laird (developerWorks, October
2001).
Check out Granville Miller's developerWorks column, "Java modeling,"as it covers a
range of issues related to UML beginning with an introduction to sequence
diagramming (May 2001).
Read about using an object-oriented framework to design XML schemas that are
extensible, flexible, and modular in the author's "Create flexible and extensible XML
schemas" (developerworks, October 2002).
Find more XML resources on the developerWorks XML zone.
IBM trial software for product evaluation: Build your next project with trial software
available for download directly from developerWorks, including application
development tools and middleware products from DB2®, Lotus®, Rational®, Tivoli®,
and WebSphere®.
Find out how you can become an IBM Certified Developer in XML and related
technologies.
Libro de O’reilly “XML Schema”
Una extensión de UML para representar XML Schemas:
http://www.dlsi.ua.es/webe02/articulos/3.pdf

122
Using XML and SVG to Generate Dynamic UML Diagrams
http://www.cwu.edu/~gellenbe/docs/xmltouml/xmltechnicalreport.html
XMI
http://es.wikipedia.org/wiki/XML_Metadata_Interchange
XMI of OMG
http://www.omg.org/spec/XMI/2.1.1/
StarUML
http://staruml.sourceforge.net/en/
StarUML repository
svn co https://staruml.svn.sourceforge.net/svnroot/staruml staruml
cvs -d:pserver:[email protected]:/cvsroot/staruml

123
Anexo 1. Patrones de usabilidad-Undo
USABILITY-ENABLING GUIDELINE
Identification
Name Undo Family Undo/Cancel
Aliases Multi-Level Undo [Tidwell, 2002]; Undo [Welie, 2003]; Global Undo / Object-Specific Undo [Laasko, 2003]; Allow Undo [Brighton, 1998]
Intent
Undo provides a way for the user to revert the effects of a previously executed action or series of actions within an application.
Problem
Users may need to undo certain actions they perform for a variety of reasons: They could have been exploring new functionality, have made a mistake or simply have changed their minds about what they have just done.
Context
Undo should be considered when developing highly interactive applications where users may perform sequences of steps, or execute actions that have tangible consequences.
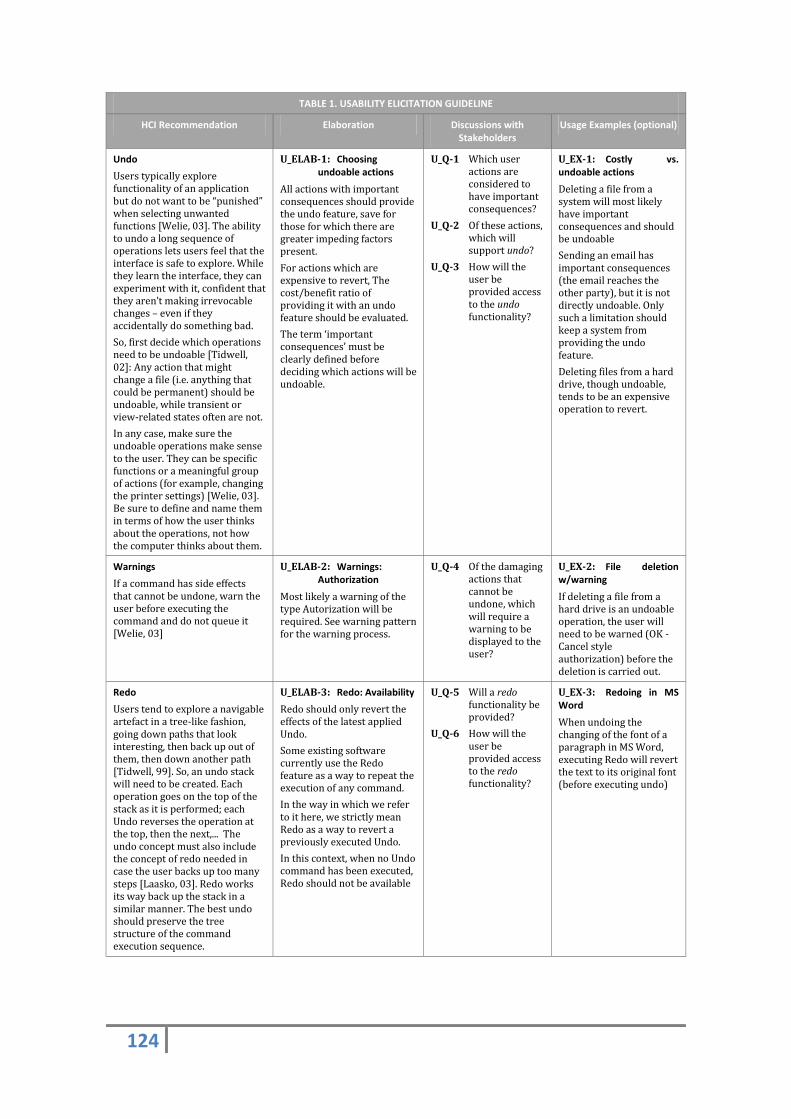
124
TABLE 1. USABILITY ELICITATION GUIDELINE
HCI Recommendation Elaboration Discussions with Stakeholders
Usage Examples (optional)
Undo
Users typically explore functionality of an application but do not want to be “punished” when selecting unwanted functions [Welie, 03]. The ability to undo a long sequence of operations lets users feel that the interface is safe to explore. While they learn the interface, they can experiment with it, confident that they aren’t making irrevocable changes – even if they accidentally do something bad.
So, first decide which operations need to be undoable [Tidwell, 02]: Any action that might change a file (i.e. anything that could be permanent) should be undoable, while transient or view-related states often are not.
In any case, make sure the undoable operations make sense to the user. They can be specific functions or a meaningful group of actions (for example, changing the printer settings) [Welie, 03]. Be sure to define and name them in terms of how the user thinks about the operations, not how the computer thinks about them.
U_ELAB-1: Choosing undoable actions
All actions with important consequences should provide the undo feature, save for those for which there are greater impeding factors present.
For actions which are expensive to revert, The cost/benefit ratio of providing it with an undo feature should be evaluated.
The term ‘important consequences’ must be clearly defined before deciding which actions will be undoable.
U_Q-1 Which user actions are considered to have important consequences?
U_Q-2 Of these actions, which will support undo?
U_Q-3 How will the user be provided access to the undo functionality?
U_EX-1: Costly vs. undoable actions
Deleting a file from a system will most likely have important consequences and should be undoable
Sending an email has important consequences (the email reaches the other party), but it is not directly undoable. Only such a limitation should keep a system from providing the undo feature.
Deleting files from a hard drive, though undoable, tends to be an expensive operation to revert.
Warnings
If a command has side effects that cannot be undone, warn the user before executing the command and do not queue it [Welie, 03]
U_ELAB-2: Warnings: Authorization
Most likely a warning of the type Autorization will be required. See warning pattern for the warning process.
U_Q-4 Of the damaging actions that cannot be undone, which will require a warning to be displayed to the user?
U_EX-2: File deletion w/warning
If deleting a file from a hard drive is an undoable operation, the user will need to be warned (OK - Cancel style authorization) before the deletion is carried out.
Redo
Users tend to explore a navigable artefact in a tree-like fashion, going down paths that look interesting, then back up out of them, then down another path [Tidwell, 99]. So, an undo stack will need to be created. Each operation goes on the top of the stack as it is performed; each Undo reverses the operation at the top, then the next,... The undo concept must also include the concept of redo needed in case the user backs up too many steps [Laasko, 03]. Redo works its way back up the stack in a similar manner. The best undo should preserve the tree structure of the command execution sequence.
U_ELAB-3: Redo: Availability
Redo should only revert the effects of the latest applied Undo.
Some existing software currently use the Redo feature as a way to repeat the execution of any command.
In the way in which we refer to it here, we strictly mean Redo as a way to revert a previously executed Undo.
In this context, when no Undo command has been executed, Redo should not be available
U_Q-5 Will a redo functionality be provided?
U_Q-6 How will the user be provided access to the redo functionality?
U_EX-3: Redoing in MS Word
When undoing the changing of the font of a paragraph in MS Word, executing Redo will revert the text to its original font (before executing undo)

125
TABLE 1. USABILITY ELICITATION GUIDELINE
HCI Recommendation Elaboration Discussions with Stakeholders
Usage Examples (optional)
History
Often users want to reverse several actions instead of just the last action [Welie, 03]. So, the stack should be at least 10 to 12 items long to be useful, and longer if you can manage it. Long-term observation or usability testing may tell you what your usable limit is (Constantine and Lockwood assert that more than a dozen items is usually unnecessary, since “users are seldom able to make effective use of more levels”. Expert users of high-powered software might tell you differently. As always, know your users.
Most desktop applications put Undo/Redo items on the Edit menu. Show the history of commands so that users know what they have done [Wellie, 03]. Undo is usually hooked up to Ctrl-Z or its equivalent
U_ELAB-4: History: Stack size and type
Ideally undo/redo should use a tree structure instead of a stack structure to keep record of the actions, however the tree structure requires an important coding effort, so have this in mind when determining which kind of structure will be needed to keep record of the actions to be undone/redone. Notice that the system may have a global stack with a concrete size, or depending on the system, the size of the stack may be different for different functionalities.
U_Q-7 How many levels of undo and/or redo will be provided?
U_Q-8 Will the user have access to the undo stack (history)?
U_Q-9 If so, how will the user be presented with the undo stack?
U_EX-4: MS Word’s undo Stack
MS Word and others provide users with a visual list (stack) of the latest opperations executed within the application. Within this stack, users can not only view the operations in the order in which they would be undone, but they can select an operation deep within the stack and undo it, along with every operation that was executed after it.
Smart Menus
The most well-behaved applications use Smart Menu Items to tell the user exactly which operation is next up on the undo stack.
U_ELAB-5: Smart Menus and History
Smart menus are tightly related to the command history (stack). If one is kept, it’s relatively simple to offer smart menus different functionalities.
U_Q-10 Will the user have information about the expected outcome of performing undo at any given time (smart menu)?
U_Q-11 If so, how will this information be provided to the user?
U_EX-5: Smart Menus in drawing program
When the last performed operation in a drawing program was “paint red”, the undo menu, or equivalent, should display “undo paint red” as opposed to the more generic “undo”
Object Specific Undo
The software system must provide the possibility for the user to easily access (for example, through the right button) the specific commands that affect such an object. One should be the undo/redo function. In this case, the system should filter the global undo stack and show only the operations that affected the state of the selected object [Laasko, 03].
U_ELAB-6: Object Specific Undo & Global Undo
Redo will only be available at object level if it is available globally. Same with undo.
U_Q-12 Which system elements will require object-specific undo/redo?
U_Q-13 How will this feature be accessed by the user?
U_EX-6: UML Design Program
In a UML design program, selecting the graphic representation of a cCass within a diagram whould should provide the option to undo the operations performed on (and only on) this particular Class.
Table 1: Undo. Usability Elicitation Guideline

126
Figure 1: Undo. Use Case Model
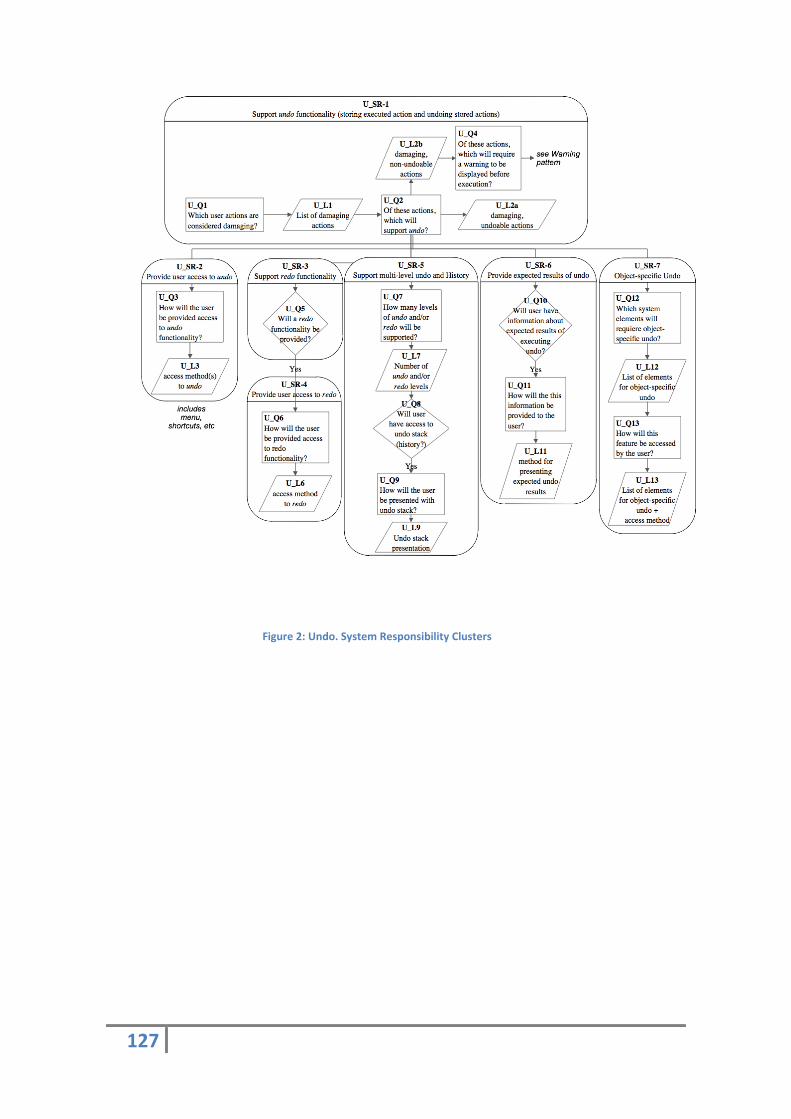
127
Figure 2: Undo. System Responsibility Clusters

128
TABLE 2. USABILITY-ENABLING DESIGN GUIDELINE: GENERIC COMPONENT RESPONSIBILITIES
System Responsibility Generic Component Responsibilities
U_SR-1 Support
Undo
functionality
(storing,
undoing)
The component responsible for handling user events (UI) must listen for calls to actions and order their execution Execution of actions is always the responsibility of the pertinent Domain Component in the application The component in charge of delegating actions (if any) should determine whether the action is undoable or not, from a pre-established list. If the action to execute is undoable, it must first be encapsulated as an instance of a Command Component, together with any pertinent state information and the necessary actions needed to revert its effects. Such an instance is then stored in a History Component, responsible for keeping a single (ordered) collection of all executed undoable actions. After encapsulation, the Domain Component is then free to execute the invoked action
The UI Component must listen for calls to the Undo action (if available) and order its execution The History Component must then retrieve the last* Command, without discarding it, and order it to ‘undo’ itself. The Command, in turn, executes the necessary actions, using the stored state information, to return the system to the state preceding its execution
U_SR-2 Provide user
access to
Undo
The UI Component is responsible for providing the mean(s) through which a user can invoke the undo feature. The Undo action should only be available when at least one undoable action has been executed during application up-time
U_SR-3 Support
Redo
functionality
The UI Component must listen for calls to the Redo action (if available) and order its execution The History Component must then retrieve the current** Command, without discarding it, and order it to ‘redo itself. The Command, in turn, executes the necessary actions, using the stored state information, to return the system to the state that follows its execution
U_SR-4 Provide user
access to
Redo
The UI Component is responsible for providing the mean(s) through which a user can invoke the redo feature. The Redo action should only be available when the Undo action has been executed at least once before during application up-time.
U_SR-5 Support
Multi-Level
Undo and
History
When only one-level undo is supported, the History component holds only the last-executed action. However, when multi-level undo is supported, History supports an ordered collection of said actions in the form of Commands, as described in “U_SR-1” The History Component is also responsible for updating (or ordering the update of) the UI every time a new Command is added to the collection or whenever the next undoable/re-doable action changes, as described in “U_SR-6”
U_SR-6 Provide
expected
results of
Undo/Redo
Whenever the Undo and/or Redo actions are available, the UI Component is responsible for showing the actions’ expected results (smart menus) The UI gets this information from the History Component, which must notify it of the current undoable/re-doable action upon every change.
U_SR-7 Allow
Object-
Specific
Undo/Redo
The UI Component must listen for calls to the Undo/Redo action over a particular object (if available) and order its execution. The History Component must then retrieve the last*/current** Command executed over that object, without discarding it, and order it to Undo/Redo itself. The Command, in turn, executes the necessary actions, using the stored state information, to return the object to the state preceding/following its execution.

129
TABLE 3. USABILITY-ENABLING DESIGN GUIDELINE: CONCRETE OBJECT RESPONSIBILITIES (MVC)
System Responsibility
Objects Fig
View Controller ConcreteCommand HistoryList DomainClass
U_SR-1 Provi
de
Undo
funct
ionali
ty
(stori
ng/un
doing
)
1. The View must listen for invocation of actions. Upon reception, it must notify the Controller of said action
2. The Controller must determine if the invoked action is undoable. In such case it must call the execute() method of the corresponding ConcreteCommand object (otherwise invocation goes directly to the DomainClass).
3. The Controller must then clone() said ConcreteCommand and add() it to the HistoryList.
4a. Upon call to its execute() method, the ConcreteCommand first stores the necessary state information in its local variables. It then calls the appropriate method in the corresponding DomainClass (what was originally invoked)
4b. The HistoryList saves the cloned ConcreteCommand atop its collection (so it can later be available to undo)
5a. The DomainClass executes the appropriate method to carry out what was originally invoked by the user through the View.
3, 4
1. The View must listen for invocation of the Undo action. Upon reception, it must notify the Controller.
2. The Controller orders the HistoryList to undo the last action.
4. Upon call to its undo() method, the ConcreteCommand calls the necessary methods in DomainClass (with any needed state information, stored upon execution) to revert its effects.
3. The HistoryList determines the ConcreteCommand to undo and calls its undo() method.
5. The DomainClass executes the methods invoked by ConcreteCommand.
3, 5
U_SR-2 Provi
de
user
acces
s to
Undo
1. The View must present the user with the mean(s) to call the Undo action (i.e. within the Edit menu, through Ctrl-Z, etc.)
3, 5
U_SR-3 Supp
ort
Redo
funct
ionali
ty
1. The View must listen for invocation of the Redo action. Upon reception, it must notify the Controller.
2. The Controller orders the HistoryList to redo the current action.
4. Upon call to its redo() method, the ConcreteCommand calls the necessary methods in DomainClass (with any needed state information, stored upon execution) to reinstate its effects.
3. The HistoryList determines the ConcreteCommand to redo and calls its redo() method.
5. The DomainClass executes the methods invoked by ConcreteCommand.
3, 6
U_SR-4 Provi
de
user
acces
s to
Redo
1. The View must present the user with the mean(s) to call the Undo action (i.e. dit menu, Ctrl-Z, etc.)
3, 6

130
TABLE 3. USABILITY-ENABLING DESIGN GUIDELINE: CONCRETE OBJECT RESPONSIBILITIES (MVC)
System Responsibility
Objects Fig
View Controller ConcreteCommand HistoryList DomainClass
U_SR-5 Supp
ort
Multi
-
Level
Undo
and
Histo
ry
3. When the View is notified of changes in the HistoryList it updates its History Displays accordingly.
1. The HistoryList stores (clones of) ConcreteCommands in a FILO-ordered collection. It keeps a ‘pointer’ of the last action that was invoked, and moves it back every time an Undo is invoked until no more ConcreteCommands exist. Invoking Redo moves the ‘pointer’ forward in a similar fashion. ConcreteCommands are never removed from the HistoryList, except when its maximum allowed size is reached (in which case the older elements will be removed in order).
2. Every time a ConcreteCommand is added to the HistoryList or the ‘pointer’ changes position (i.e. the next undoable/re-doable action is updated), the HistoryList notifies the View
3, 4, 5, 6
U_SR-6 Provi
de
expec
ted
result
s of
Undo
/Red
o
2. When the View is notified of changes in the HistoryList it updates its next undoable/redoable
1. Every time a ConcreteCommand is added to the HistoryList or the ‘pointer’ changes position (i.e. the next undoable/redoable action is updated), the HistoryList notifies the View
3, 5, 6
U_SR-7 Allo
w
Obje
ct-
Speci
fic
Undo
/Red
o
1. The View must listen for invocation of the Undo/Redo action over a specific object. Upon reception, it must notify the Controller.
2. The Controller orders the HistoryList to undo/redo the last action invoked over said object.
4. Upon call to its undo()/redo() method, the ConcreteCommand calls the necessary methods in DomainClass (with any needed state information) to revert/reinstate its effects.
3. The HistoryList determines the ConcreteCommand to undo/redo by scanning the collection for the latest/current one invoked over the object and calls its undo() method.
5. The DomainClass executes the methods invoked by ConcreteCommand.
3, 5, 6

131
Figure 3: Undo. Usability-enabling design pattern. Class diagram

132
Figure 4: Undo. Usability-enabling design pattern. Sequence Diagram “Execute Action” (U_SR-1)

133
Figure 5: Undo. Usability-enabling design pattern. Sequence Diagram “Undo Action” (U_SR-1, U_SR-2, U_SR-4, U_SR-6 and U_SR-7)

134
Figure 6: Undo. Usability-enabling design pattern. Sequence Diagram “Redo Action” (U_SR-3, U_SR-4, U_SR-5, U_SR-6 and U_SR-7)
Recommended

















