Embed Size (px)
Citation preview

CLUSTERING JERÁRQUICOGRUPO N. 3
Correa Roddy
Hidalgo Michell
Pacheco Liliana
Samaniego César
INTELIGENCIA ARTIFICIAL AVANZADA
Clustering Jerárquico – ¿Qué es?
Es un método de análisis de grupos el cual busca construir
una jerarquía de grupos.
En los métodos jerárquicos los individuos no se
particionan en clusters de una sola vez, sino que se van haciendo particiones
sucesivas a " distintos niveles de agregación o
agrupamiento ".

Clustering Jerárquico – ¿Cómo funciona?
• La técnica de clustering jerárquico construye un dendograma o árbol que representa las relaciones de similitud entre los distintos elementos. La exploración de todos los posibles árboles es computacionalmente intratable. Por lo tanto, suelen seguirse algoritmos aproximados guiados por determinadas heurísticas.

Campos de Aplicación
Las técnicas
de agrupamie
nto encuentra
n aplicación
en diversos ámbitos.
En biología para clasificar animales y plantas.
En medicina para identificar enfermedades.
En marketing para identificar personas con hábitos de compras similares.
En teoría de la señal pueden servir para eliminar ruidos.
En biometría para identificación del locutor o de caras.

Clustering Jerárquico – Tipos
• Clustering jerárquico aglomerativo: • Se comienza con tantos clústeres
como individuos y consiste en ir formando (aglomerando) grupos según su similitud.
• Clustering jerárquico de división: • Se comienza con un único clúster y
consiste en ir dividiendo clústeres según la disimilitud entre sus componentes.
Existen dos aproximaciones
diferentes al clustering jerárquico:
Clustering Jerárquico Aglomerativo – Ejemplo
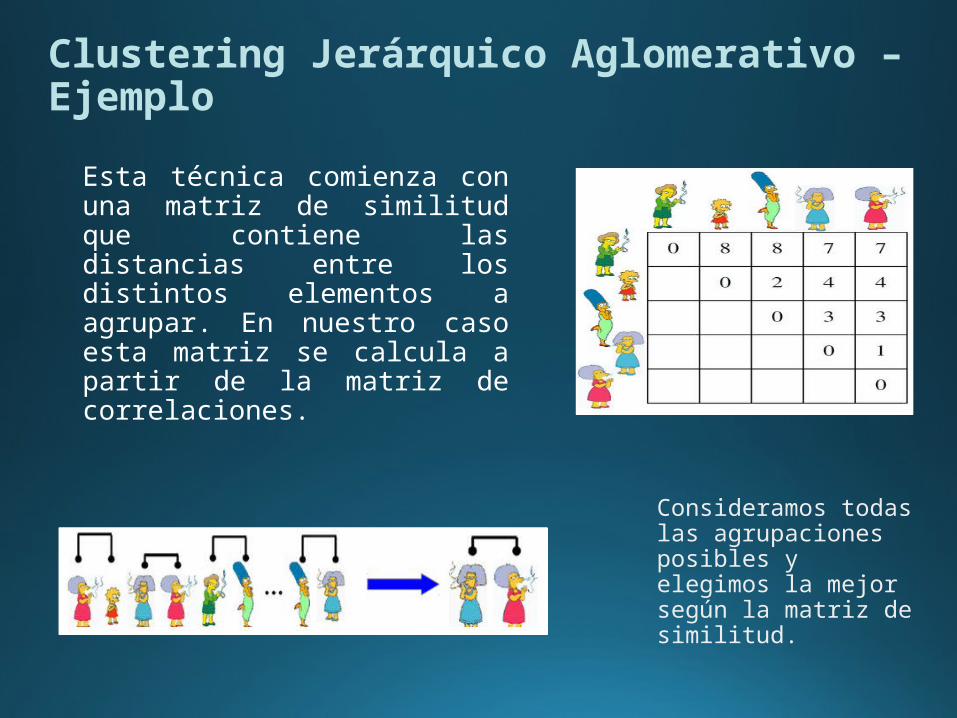
Esta técnica comienza con una matriz de similitud que contiene las distancias entre los distintos elementos a agrupar. En nuestro caso esta matriz se calcula a partir de la matriz de correlaciones.
Consideramos todas las agrupaciones posibles y elegimos la mejor según la matriz de similitud.

Clustering Jerárquico Aglomerativo – Ejemplo
• Se recalcula la matriz de similitud teniendo en cuenta el nuevo clúster formado. La distancia al nuevo clúster se calcula como la media de las distancias a los elementos que lo forman.
En el clustering jerárquico no es necesario especificar el número de clústeres a priorizar. Es posible seleccionarlo a posterioridad según un
umbral de corte. La estructura jerárquica es cercana a la intuición humana. La principal desventaja consiste en la acumulación de errores.
Errores que se comenten en un paso de agrupamiento se propagan durante el resto de la construcción del dendograma sin ser posible su
reajuste.

EJEMPLO DE CLUSTERING EN R
Variables del dataset denominado comunidades autónomas
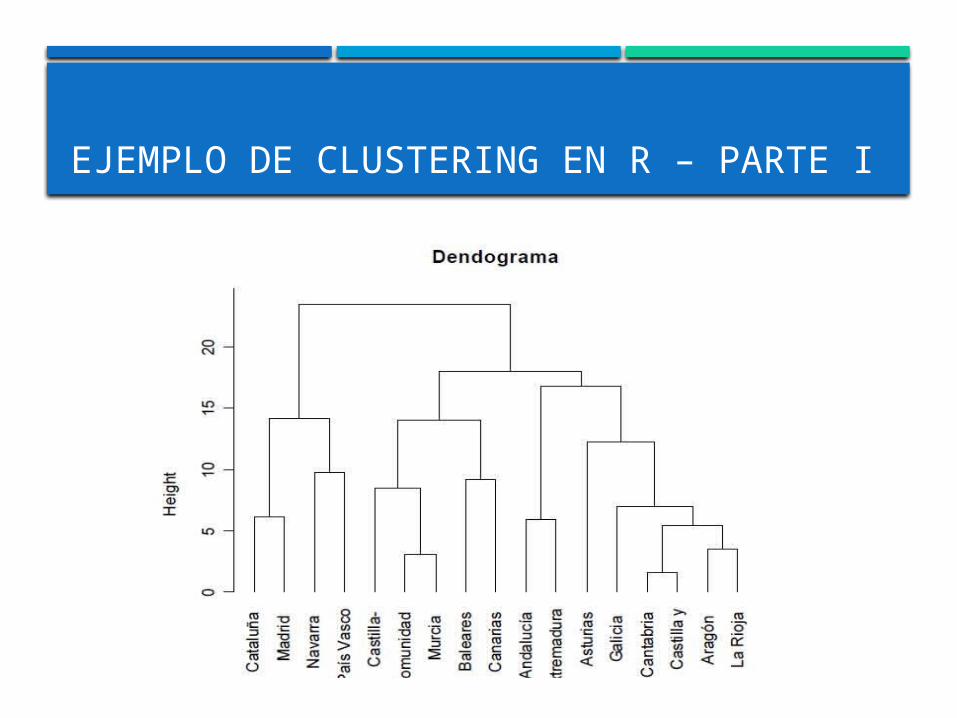
EJEMPLO DE CLUSTERING EN R – PARTE I
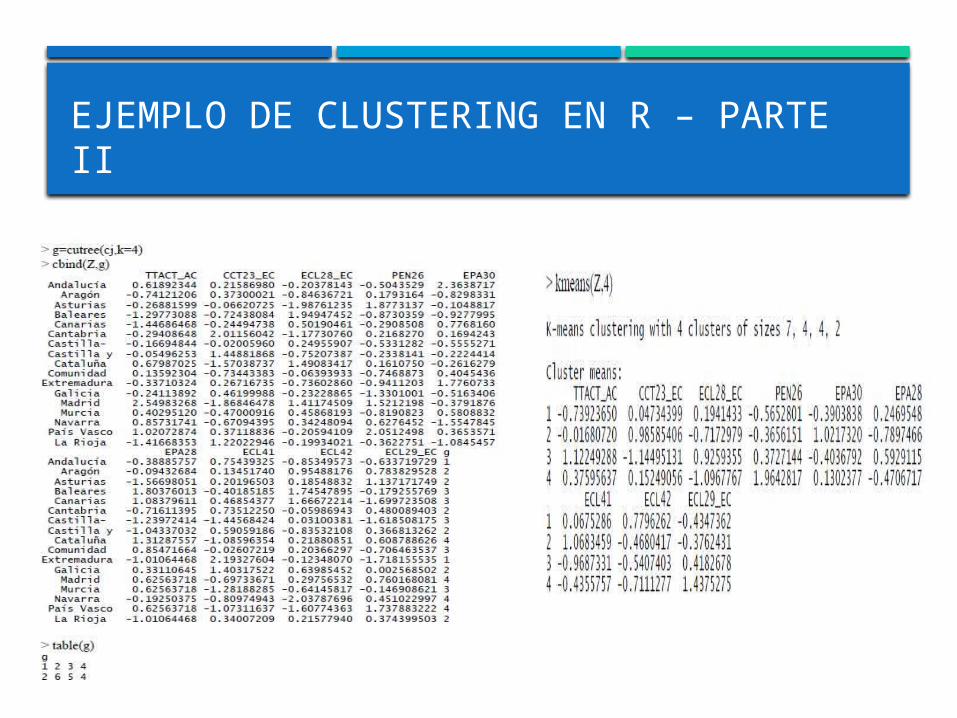
EJEMPLO DE CLUSTERING EN R – PARTE II

EJEMPLO DE CLUSTERING EN R – PARTE III
BIBLIOGRAFÍA
• Búsqueda de patrones: técnicas de clustering, recuperado de:
http://www.Cs.Us.Es/~fran/curso_unia/clustering.Html
• introducción al análisis cluster, recuperado de:
http://www.uv.es/ceaces/multivari/cluster/CLUSTER2.htm






























