Embed Size (px)
Citation preview

Tema 7: Regresión Simple y Múltiple

EJEMPLO:
Aproxima bien el número de préstamos que efectúa una biblioteca a lo largo de su primer año de vida.
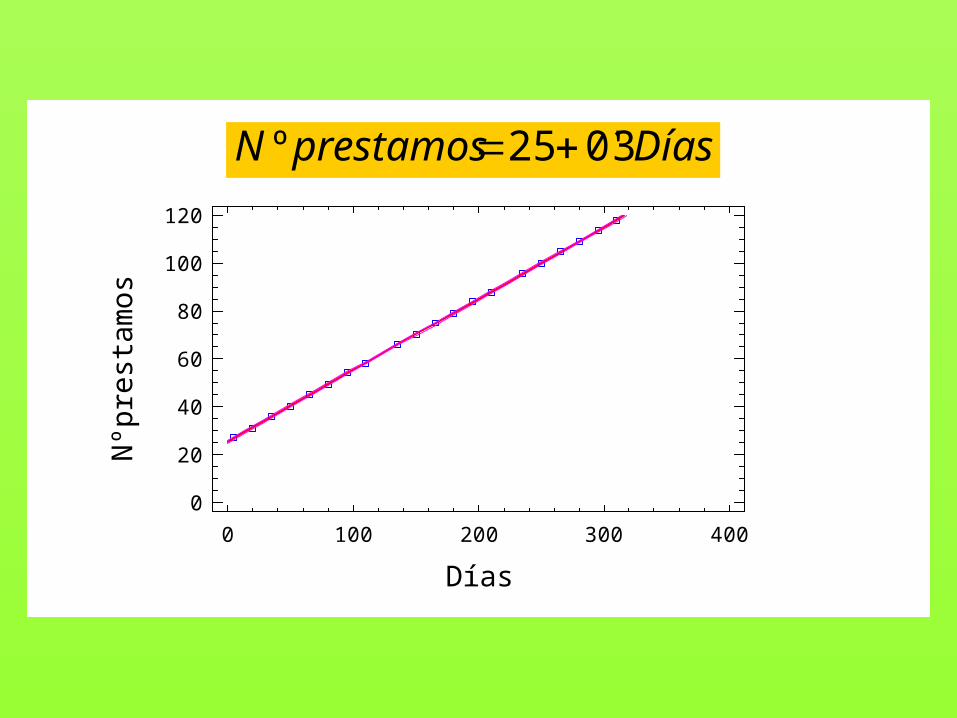
Nos dicen que la fórmula
Si damos valores a la variable Días (nº días transcurridos desde la apertura de la biblioteca…
DíasprestamosN 3'025º
0 100 200 300 400
Días
0
20
40
60
80
100
120
Nºp
rest
amos
DíasprestamosN 3'025º

Si dos variables X e Y está relacionadas mediante una expresión del tipo Y=a+bX, la gráfica que relaciona los valores de X e Y es una línea recta, y se dice que Y=a+bX es la ecuación de dicha recta; el recíproco es cierto, es decir, si la gráfica que relaciona X e Y es una recta, entre ambas existe una relación del tipo Y=a+bX. En ese caso, decimos que entre X e Y hay una relación de tipo lineal.
En la realidad, no nos encontramos fórmulas tan “redondas”, pero sí nos encontramos fenómenos que pueden aproximarse por ellas.
DíasNº
prestamos
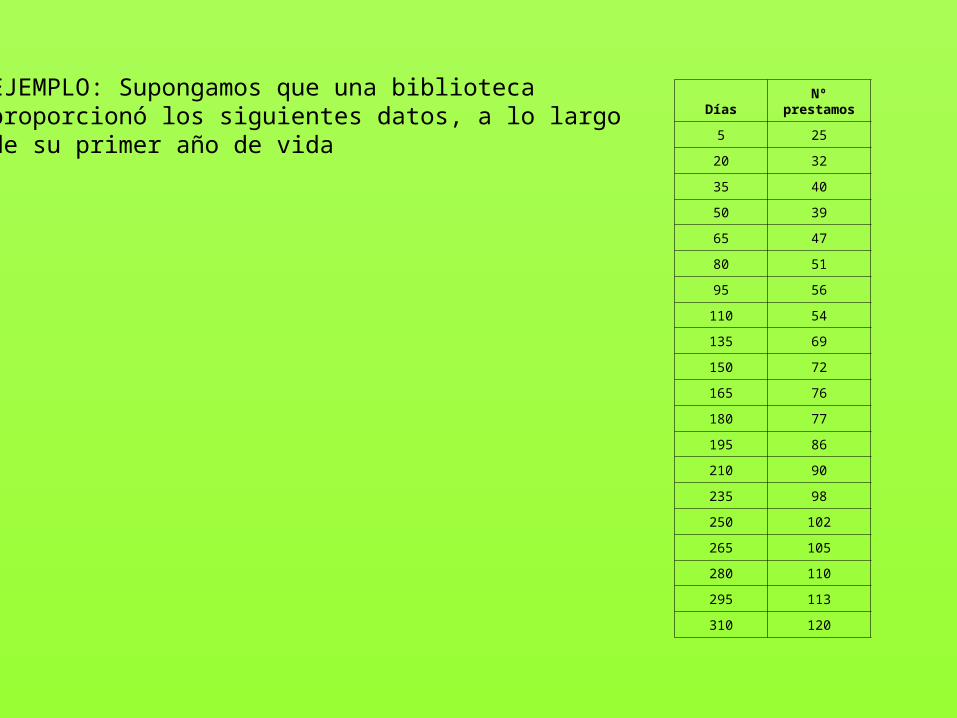
5 25
20 32
35 40
50 39
65 47
80 51
95 56
110 54
135 69
150 72
165 76
180 77
195 86
210 90
235 98
250 102
265 105
280 110
295 113
310 120
EJEMPLO: Supongamos que una bibliotecaproporcionó los siguientes datos, a lo largo de su primer año de vida
Días
Nº
pres
tam
os
0 100 200 300 4000
20
40
60
80
100
120

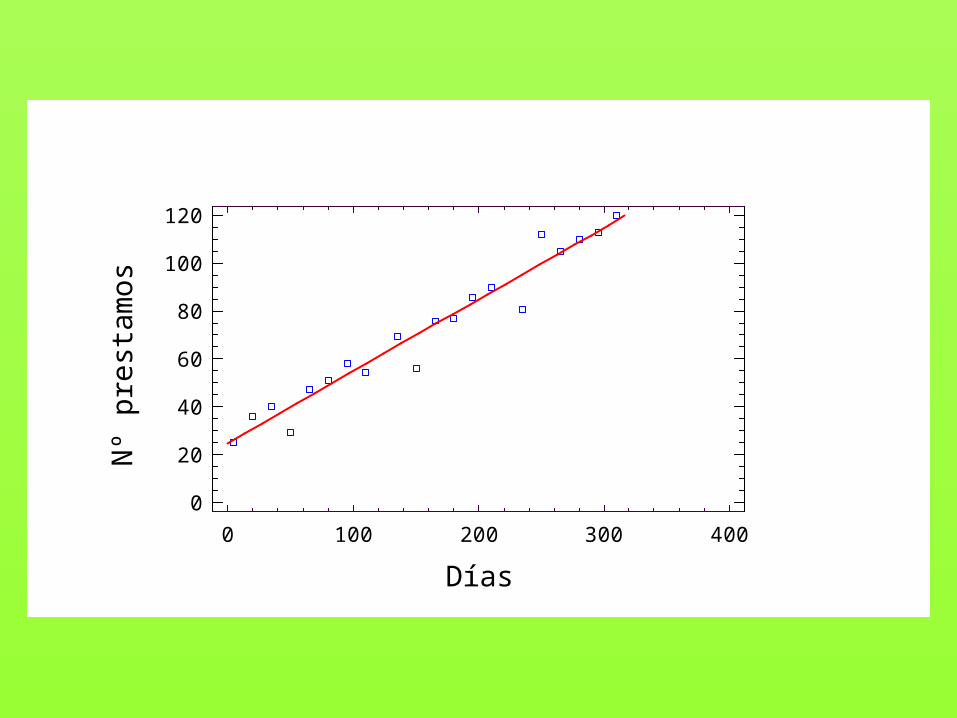
APROXIMADAMENTE,
Nº prestamos = 24,5529 + 0,301579*Días
En este caso, diríamos que las variables Nº préstamos y Días estánlinealmente correlacionadas, y que lo de arriba es la ecuación de la recta de regresión de Nº préstamos sobre Días.
¿Para qué nos sirve? (1) para conocer leyes empíricas; (2) para predecir el valor de una cierta variable

PROBLEMAS: Dadas dos variables X e Y, continuas
1.- [Correlación] ¿Existe una cierta relación entre ellas, o por el contrario son independientes? En el primer caso, hablamos de que entre X e Y hay correlación; en el segundo, decimos que son incorreladas
2.- [Correlación lineal] Suponiendo que entre X e Y hay correlación, ¿están linealmente correlacionadas, es decir, funciona suficientemente bien un modelo del tipo Y = a+bX para predecir Y a partir de X? ¿Cuáles son los “óptimos” valores para a y b, es decir, los que producen “mejores” esti- maciones?
3.- [Otros tipos de correlación] ¿Hay algún modelo mejor que el lineal que permita estimar Y a partir de X? Por ejemplo,
Cuadrático: Y=a+bX+bX2
Exponencial: Y=a bx
…
Otro ejemplo (Leyes bibliométricas)
Curva logística del crecimiento de la información

1. Distribuciones bidimensionales. Correlación.
Cuando en una población registramos simultáneamente los valores de dos variables X e Y, decimos que estamos ante una distribución BIDIMENSIONAL (PIZARRA: distribuciones marginales)
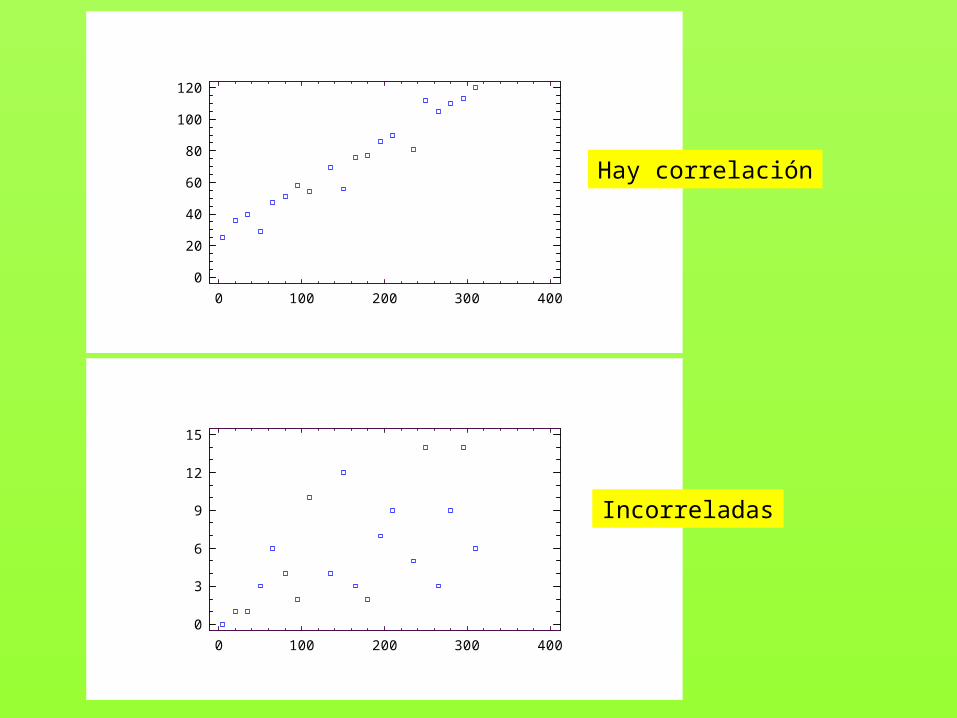
Los datos relativos a una distribución bidimensional se pueden representar gráficamente mediante una NUBE DE PUNTOS, o DIAGRAMA DE DISPERSION (PIZARRA)
Si la nube de puntos se ajusta aproximadamente a una curva, diremos que las variables están correlacionadas, es decir, que existe una cierta relación entre ellas (y buscaremos cuál es la expresión, la “fórmula” que mejor aproxima una de ellas partir de la otra); en caso contrario, decimos que las variables son incorreladas, es decir, que no tienen relación.
0 100 200 300 4000
20
40
60
80
100
120
0 100 200 300 4000
3
6
9
12
15
Hay correlación
Incorreladas

Además de la “inspección” de la nube de puntos, hay métodos más exactos para evaluar la existencia
o no de correlación.
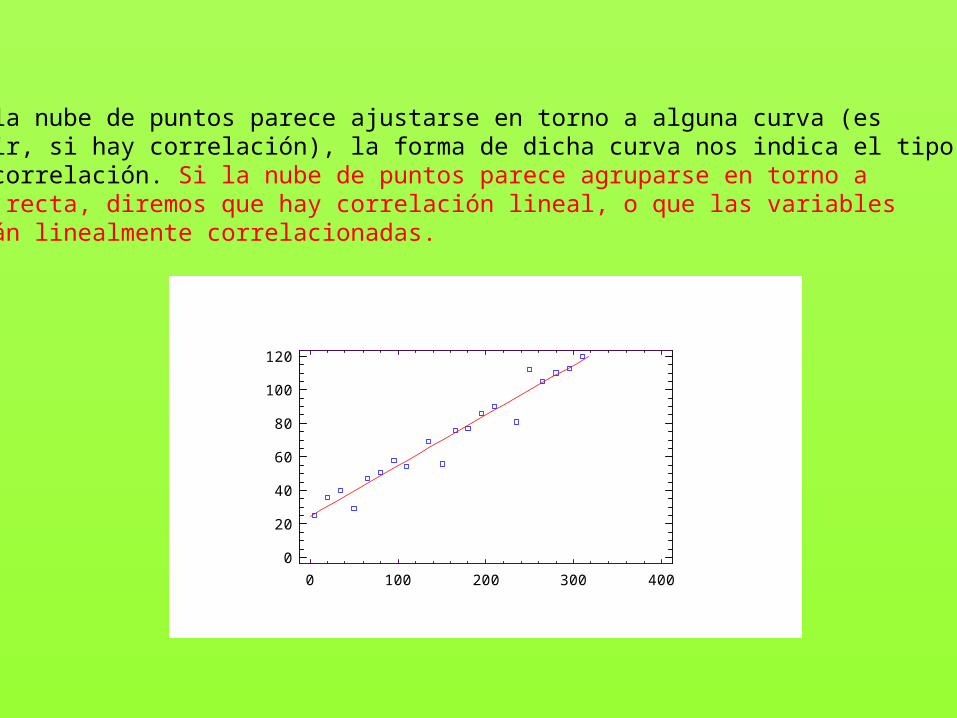
Si la nube de puntos parece ajustarse en torno a alguna curva (es decir, si hay correlación), la forma de dicha curva nos indica el tipo de correlación. Si la nube de puntos parece agruparse en torno a una recta, diremos que hay correlación lineal, o que las variables están linealmente correlacionadas.
0 100 200 300 4000
20
40
60
80
100
120

Si las variables están linealmente correlacionadas, entonces tiene sentido buscar la recta que “mejor se ajusta” a la nube de puntos, es decir, la recta que globalmente está más cerca del conjunto de puntos. Si nuestra intención al hacer eso es la de estimar Y a partirde X, entonces encontrar dicha recta es equivalente a encontrar la mejor aproximación
Y=a+bX (RECTA DE REGRESION DE Y SOBRE X)
¿Cómo tomar a, b para que la aproximación sea“óptima”?

2. Regresión lineal sobre un conjunto de puntos.
PROBLEMA 1: Dada una distribución bidimensional (X,Y), determinarsi las variables X e Y están o no linealmente correlacionadas, y la fuerza de dicha correlación lineal.
PROBLEMA 2: Suponiendo que X e Y están linealmente correlacionadas,determinar la recta de regresión de Y sobre X, es decir, a y b de modo que, aproximadamente, Y=a + bX.
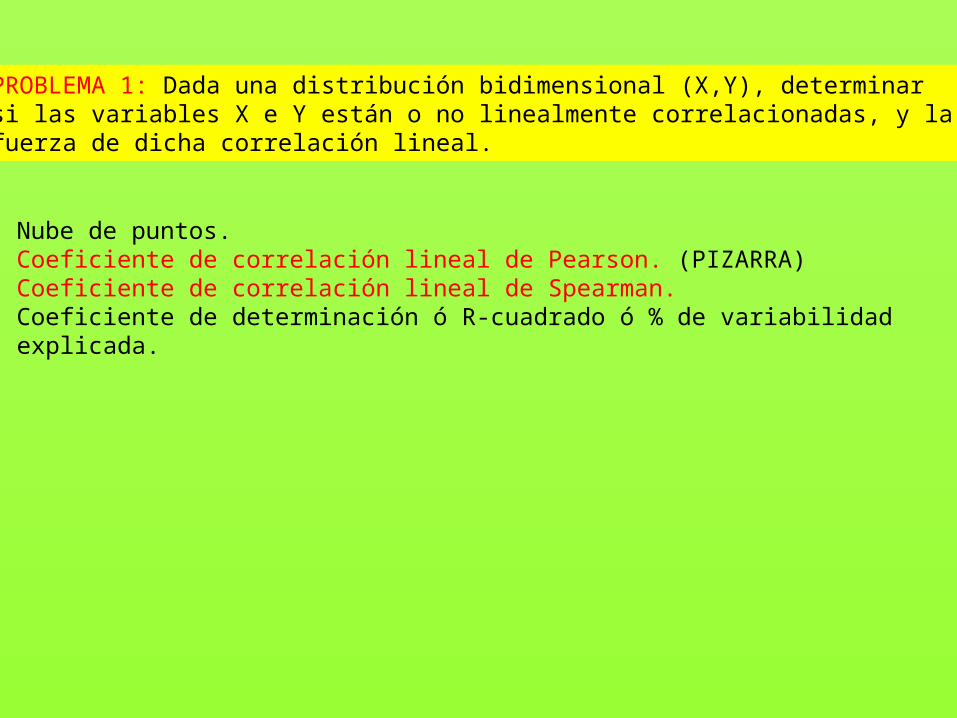
PROBLEMA 1: Dada una distribución bidimensional (X,Y), determinarsi las variables X e Y están o no linealmente correlacionadas, y la fuerza de dicha correlación lineal.
- Nube de puntos.- Coeficiente de correlación lineal de Pearson. (PIZARRA)- Coeficiente de correlación lineal de Spearman. - Coeficiente de determinación ó R-cuadrado ó % de variabilidad explicada.

PROBLEMA 2: Suponiendo que X e Y están linealmente correlacionadas,determinar la recta de regresión de Y sobre X, es decir, a y b de modo que, aproximadamente, Y=a + bX.
bXaY (Ecuación recta de regresión de Y sobre X)
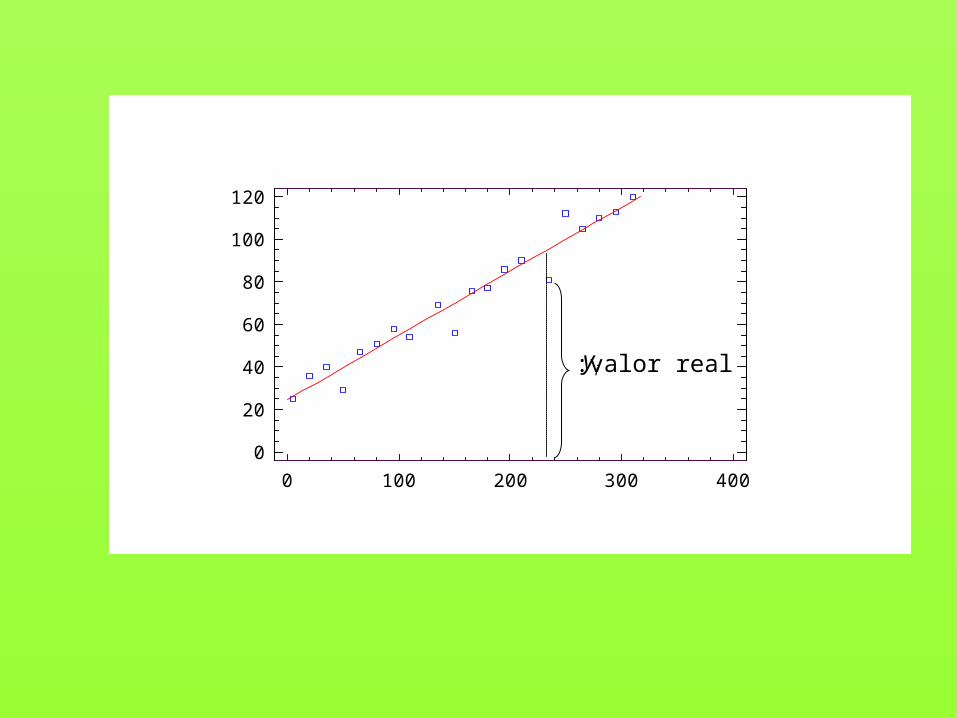
Conocida la recta de regresión, podemos estimar los valores de Ycorrespondientes a distintos valores de X.
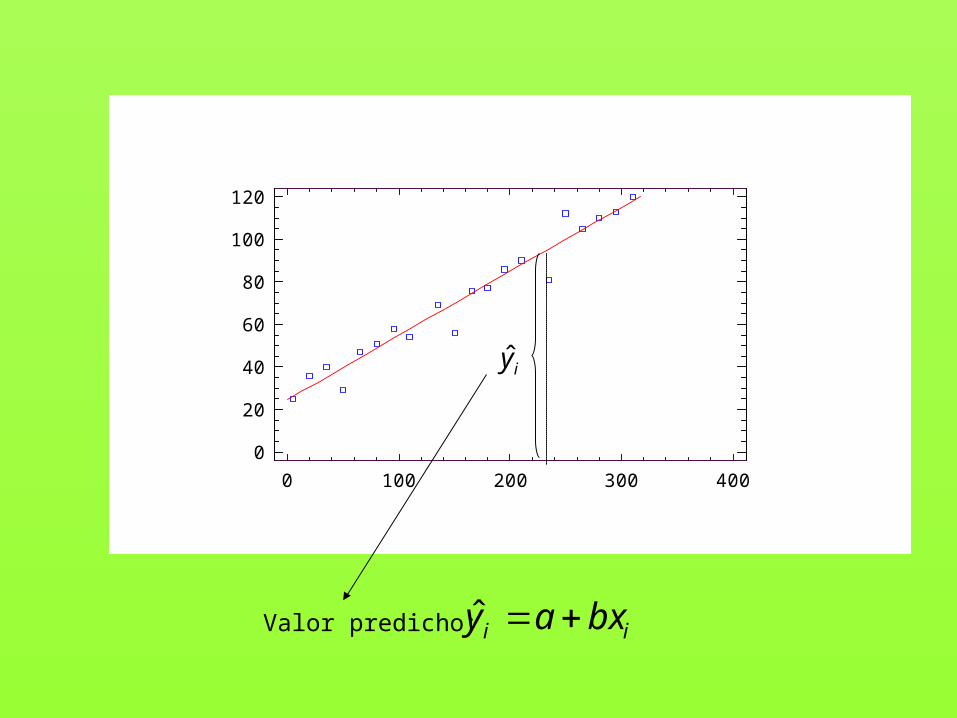
ii bxay ˆ
Valor predicho, o estimado
0 100 200 300 4000
20
40
60
80
100
120
iy :valor real
0 100 200 300 4000
20
40
60
80
100
120
iy
Valor predicho: ii bxay ˆ
0 100 200 300 4000
20
40
60
80
100
120
iy
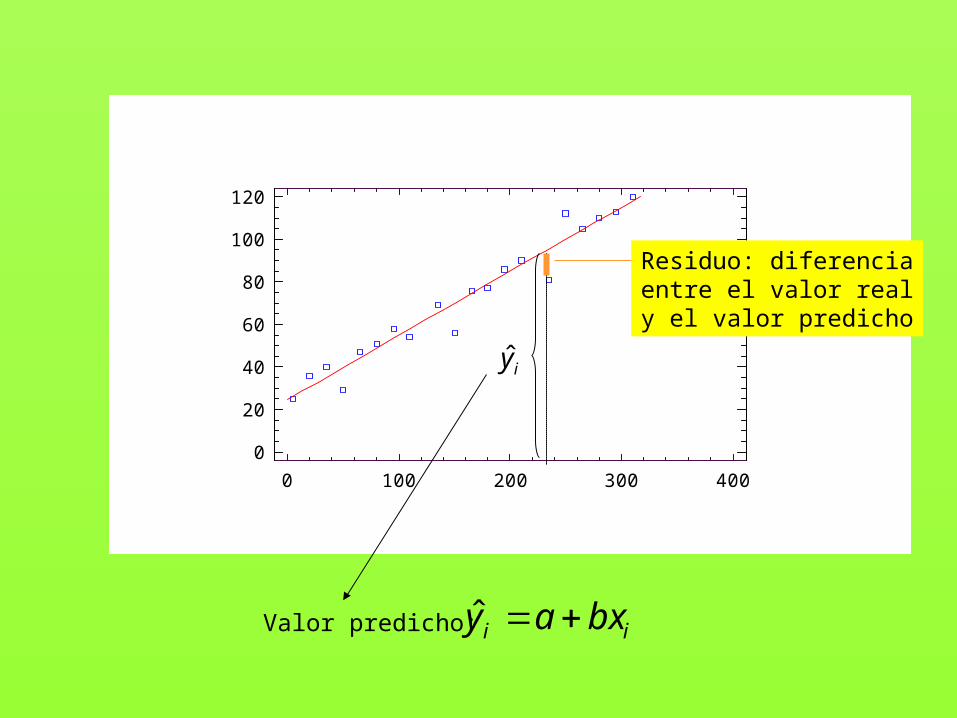
Valor predicho: ii bxay ˆ
Residuo: diferenciaentre el valor realy el valor predicho

Statgraphics
R-cuadrado ó Coeficiente de Determinación ó % de variabilidadexplicada… (PIZARRA)

3. El modelo de regresión lineal.
Sabemos decidir si, aproximadamente, un conjunto (xi,yi) de puntos(datos) se ajusta o no a Y=a+bX. Pero, teniendo en cuenta que esosdatos son una MUESTRA de una población…
¿SIGUE SIENDO “APROXIMADAMENTE” VALIDO Y=a+bX cuando tomamos
NO una muestra (xi,yi), sino cuando consideramosTODA LA POBLACION? ¿Qué queremos
decir por “aproximadamente”?

Modelo de regresión lineal:
iii bxay
Y: variable explicada X: regresor
residuo
Decimos que dos variables (poblacionales!) están linealmente correlacionadas, si:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.
2+ 4+ 5= Residuos siguen una normal N(0,σ)
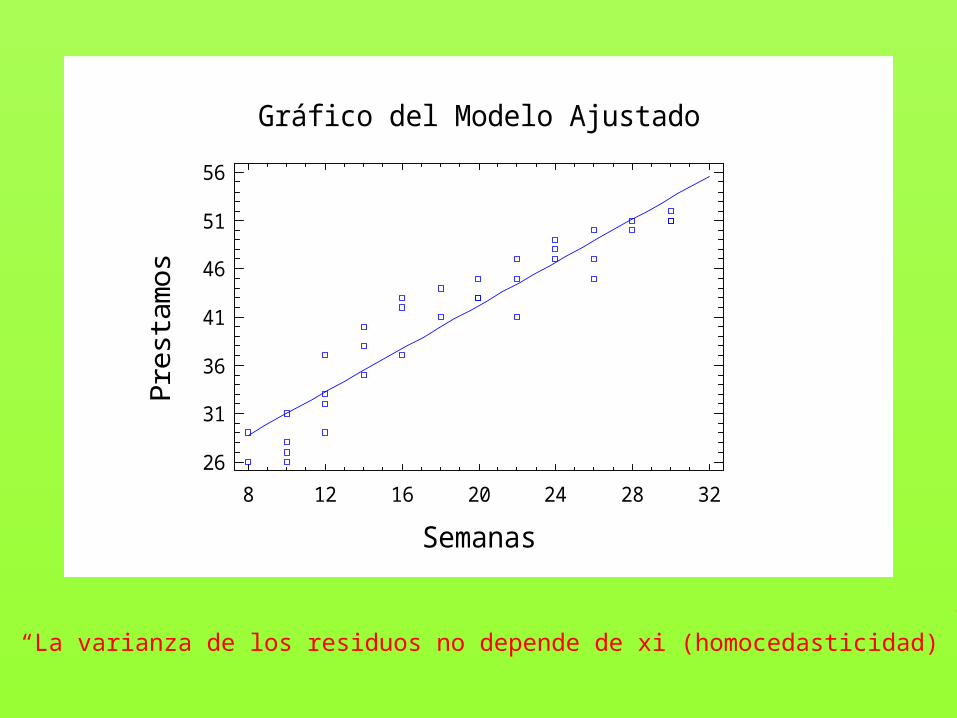
Gráfico del Modelo Ajustado
Semanas
Pre
stam
os
8 12 16 20 24 28 3226
31
36
41
46
51
56
“La varianza de los residuos no depende de xi (homocedasticidad)”

Modelo de regresión lineal:
iii bxay
Y: variable explicada X: regresor
residuo
Hipótesis básicas:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.
2, 4 y 5 pueden contrastarte guardando los residuos, y procediendocomo en otras ocasiones.

Modelo de regresión lineal:
iii bxay
Y: variable explicada X: regresor
residuo
Hipótesis básicas:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.
3 lo contrastaremos con los gráficos de residuos,y comprobando que no haya residuos atípicos.
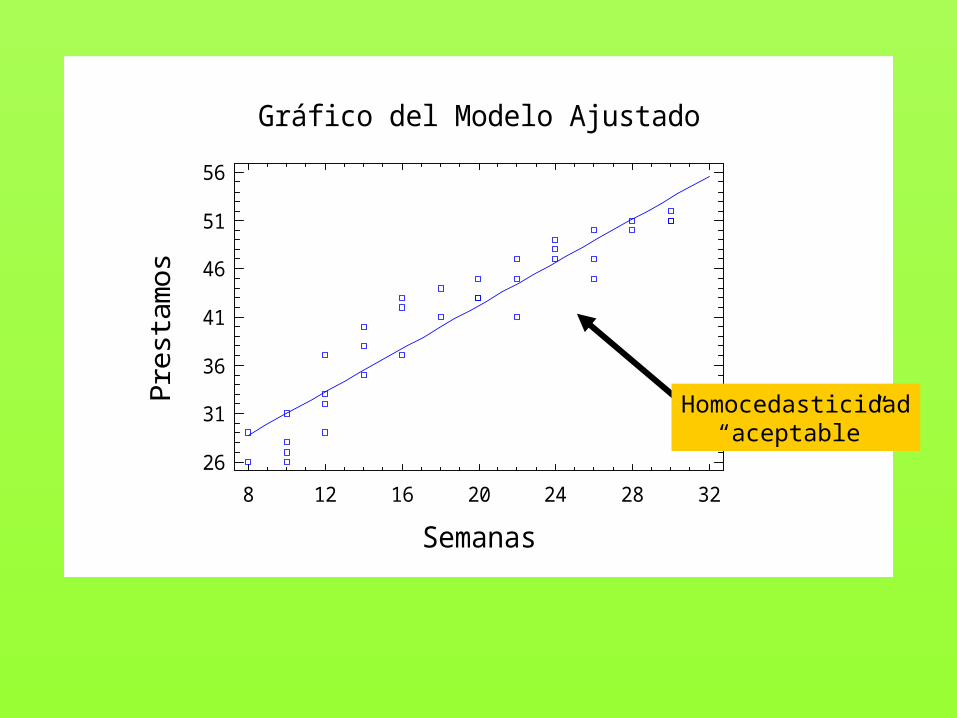
Gráfico del Modelo Ajustado
Semanas
Pre
stam
os
8 12 16 20 24 28 3226
31
36
41
46
51
56
Homocedasticidad“aceptable”

Modelo de regresión lineal:
iii bxay
Y: variable explicada X: regresor
residuo
Hipótesis básicas:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.
¿Cómo CONTRASTAR?

a.- Inspección del diagrama de dispersión, valores de los coeficientes de correlación de Pearson y Spearman (si el ajuste no funciona bien para la muestra, difícilmente lo hará para la población).
b.- Contraste tipo ANOVA sobre la existencia o no de correlación lineal. COEFICIENTE DE DETERMINACION. = Contraste sobre la pendiente de la recta de regresión.
c.- ¿Cómo podemos estar seguros de que, en la población, los coeficien- tes de Pearson y Spearman no serían 0 (en cuyo caso, no habría correlación lineal)? Contraste de hipótesis.
¿Cómo CONTRASTAR?
(Explicación: PIZARRA)

- Eliminación de parámetros (simplificación del modelo):
iii bxay
Si aceptamos el contraste H0: a=0, entonces la recta de regresiónque obtenemos es y = bx (una fórmula más sencilla): se dice entoncesque hemos simplificado nuestro modelo.

Y: variable explicada X: regresor
residuo
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.
iii bxay
¿Qué hacer si falla alguna hipótesis? (algunas ideas sobre esto…)
(APUNTES)
Statgraphics

4. El modelo de regresión múltiple.
PROBLEMA: Hemos recogido datos sobre usuarios de mediana edadde una biblioteca en la que además se realizan actividades tanto para niños como para adolescentes y adultos, y estamos interesados en analizar cuáles son las variables que determinan el nivel de satisfacción de sus usuarios; las variables recogidas son: afición a la lectura, al cine, a la música, número de hijos, renta… y, por supuesto, nivel de satisfac-ción.
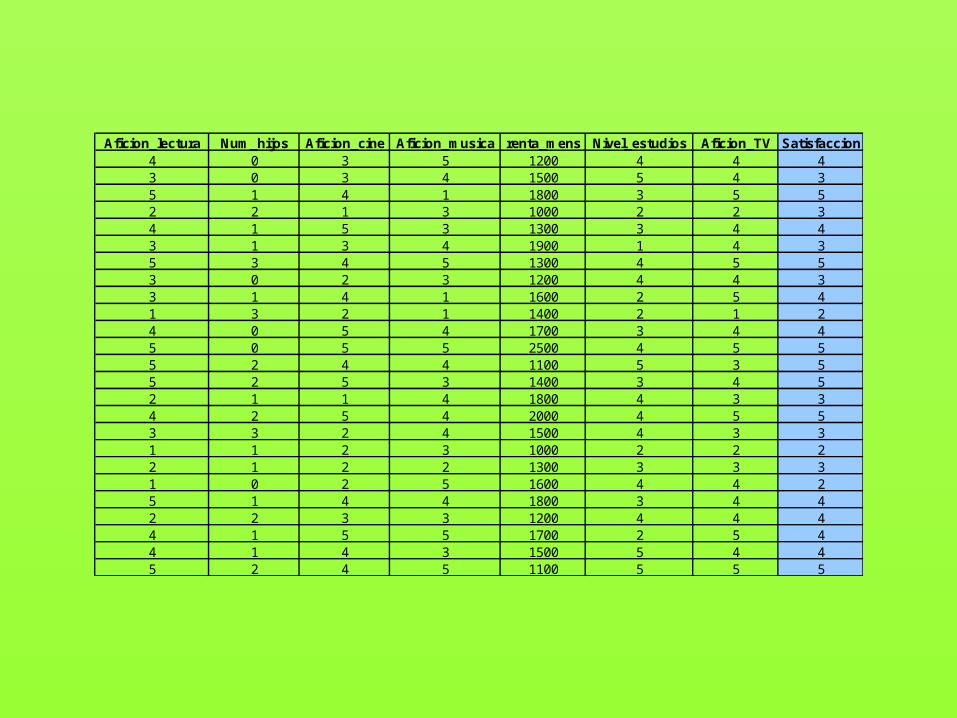
Aficion_lectura Num_hijos Aficion_cine Aficion_musica renta_mens Nivel_estudios Aficion_TV Satisfaccion4 0 3 5 1200 4 4 43 0 3 4 1500 5 4 35 1 4 1 1800 3 5 52 2 1 3 1000 2 2 34 1 5 3 1300 3 4 43 1 3 4 1900 1 4 35 3 4 5 1300 4 5 53 0 2 3 1200 4 4 33 1 4 1 1600 2 5 41 3 2 1 1400 2 1 24 0 5 4 1700 3 4 45 0 5 5 2500 4 5 55 2 4 4 1100 5 3 55 2 5 3 1400 3 4 52 1 1 4 1800 4 3 34 2 5 4 2000 4 5 53 3 2 4 1500 4 3 31 1 2 3 1000 2 2 22 1 2 2 1300 3 3 31 0 2 5 1600 4 4 25 1 4 4 1800 3 4 42 2 3 3 1200 4 4 44 1 5 5 1700 2 5 44 1 4 3 1500 5 4 45 2 4 5 1100 5 5 5
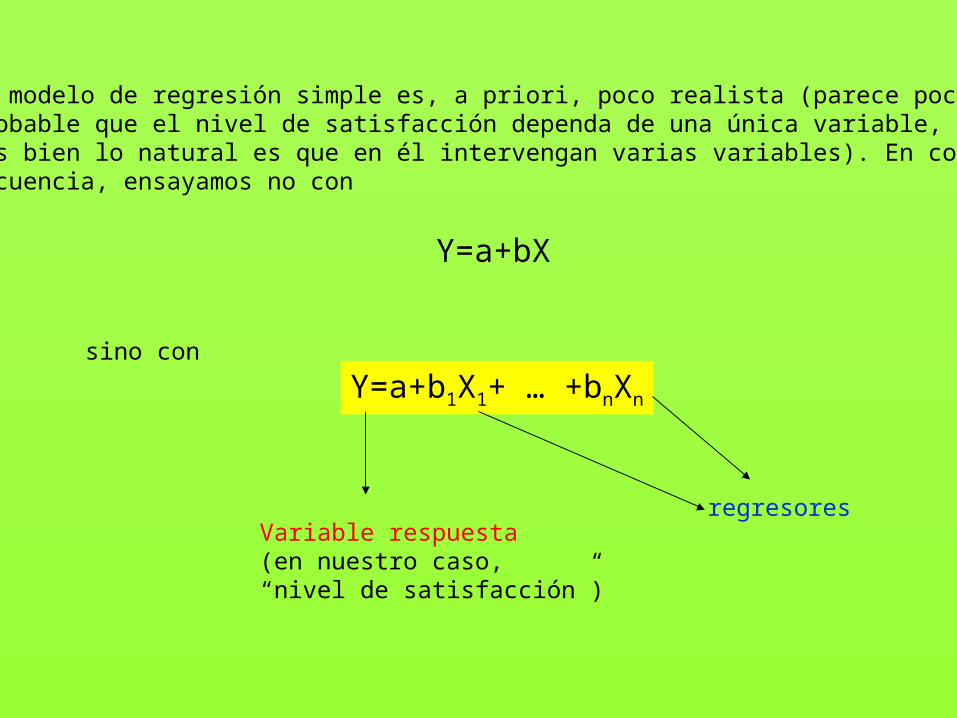
El modelo de regresión simple es, a priori, poco realista (parece poco probable que el nivel de satisfacción dependa de una única variable, más bien lo natural es que en él intervengan varias variables). En con-secuencia, ensayamos no con
sino con
Y=a+bX
Y=a+b1X1+ … +bnXn
Variable respuesta(en nuestro caso,“nivel de satisfacción”)
regresores
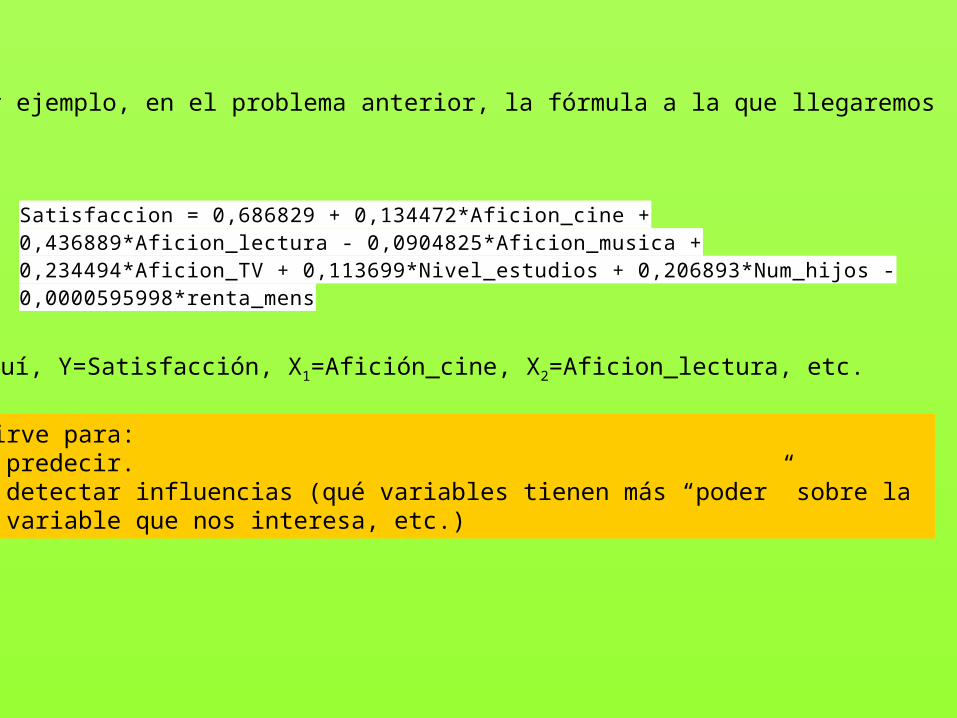
Satisfaccion = 0,686829 + 0,134472*Aficion_cine +0,436889*Aficion_lectura - 0,0904825*Aficion_musica +0,234494*Aficion_TV + 0,113699*Nivel_estudios + 0,206893*Num_hijos -0,0000595998*renta_mens
Por ejemplo, en el problema anterior, la fórmula a la que llegaremoses:
Aquí, Y=Satisfacción, X1=Afición_cine, X2=Aficion_lectura, etc.
Sirve para:- predecir.- detectar influencias (qué variables tienen más “poder” sobre la variable que nos interesa, etc.)

Modelo de regresión múltiple:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.6. Las variables x1, x2, etc. no están linealmente correlacionadas entre sí.
inni xbxbay 11
residuo

Modelo de regresión múltiple:
1.
2. Los residuos tienen media 0.3. La varianza de los residuos no depende de xi (homocedasticidad)4. Los residuos son normales.5. Los residuos son aleatorios.6. Las variables x1, x2, etc. no están linealmente correlacionadas entre sí.
2+ 4+ 5= Residuos siguen una normal N(0,σ)
inni xbxbay 11
residuo





























