Embed Size (px)
Citation preview


Sumario
INTRODUCCIÓN
La revolución del Big Data en la Sanidad1 2
13 Lo que aporta el Big Data a la industria farmacéuticaTERESA HERNANDO 60
FARMACIA
12 “El volumen de información es crítico para el desarrollo de productos”FEDERICO PLAZA 55
14 “Para el farmacéutico es clave conocer la situación de las ventas de productos”CARLOS MOCHO 64
11 Farmacia y Big DataJESÚS AGUILAR SANTAMARIA 51
TECNOLOGÍA15 Proyectos. IBM Watson/
23andme/PatientsLikeMe 69
16 Píldoras. Wearables para monitorizar la salud 73
17 Mini diccionario 76
El poder del Real World DataSALVADOR PEIRÓ
2 3
3 “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”BERNARDO VALDIVIESO 8
La hora del Big Data en SaludMIGUEL ÁNGEL MAÑEZ
414
“Analizar millones de datos en las redes sociales es muy valioso”PALOMA MARTÍNEZ
5
18
“Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”JULIO MAYOL
622
Retos futuros para los Sistemas de Información en el Entorno SanitarioJOSÉ A. GUERRERO
7
28
SALUD
PRIVACIDAD
8 Los datos son del paciente 34
10 La información de salud: motor de cambio de los sistemas sanitariosJOSEP MARIA ARGIMON 45
940
“Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”LUCIANO SAEZ AYERRA

El futuro de la Sanidad pasa por los datos. Este informe analiza lo que está aportando el Big Data en el campo de la Salud: cómo se están recogiendo, analizando y utilizando estos datos para dar un paso de gigante en las decisiones médicas que atañen a millones de pacientes.
Médicos, especialistas en Farmacia, profesionales y gestores sanitarios reflexionan en estas páginas sobre las posibilidades de la recogida masiva de información. Cómo sirve en la investigación, en la evaluación y mejora de la atención de pacientes o para predecir enfermedades; cómo ayuda en la
2
INTRODUCCIÓN
INTRODUCCIÓN: La revolución del Big Data en la Sanidad
1
La revolución del Big Data en la Sanidad
gestión de los hospitales para evaluar el coste, producción y calidad de la prestación de una asistencia o cómo se utiliza para desarrollar fármacos o para prevenir reacciones adversas de los medicamentos.
Por último, se abordan cuestiones arduas: ¿está garantizada la privacidad de los pacientes? ¿Estamos preparados tecnológicamente y profesionalmente para procesar millones de datos? ¿Podemos hablar de una auténtica “revolución” en la Medicina? ¿Cómo va a cambiar nuestra vida el Big Data?

OPINIÓN
OPINIÓN: El poder del Real World Data
2
El poder del Real World DataLa utilidad de las grandes bases de datos para mejorar la calidad de la atención sanitaria.
Salvador Peiró
Fundación para el Fomento de la Investigación Sanitaria y Biomédica de la Comunidad Valenciana (FISABIO). Red de Investigación en Servicios de Salud en Enfermedades Crónicas (REDISSEC). Valencia.
3

El término Big Data sanitario hace referencia a volúmenes de información tan grandes y heterogéneos que no pueden ser manejados con los software (y hardware) tradicionales, ni fácilmente analizados con las herramientas convencionales de gestión de datos. En atención sanitaria estamos especialmente interesados en una “pequeña” porción de este Big Data que incorpora la información de la historia clínica electrónica (incluyendo la monitorización y los datos de telemedicina), los sistemas de
4
introducción de órdenes y prescripciones médicas (prescripción electrónica, pruebas de laboratorio, derivaciones, etc.), los sistemas de ayuda a la decisión, los sistemas de almacenamiento y comunicación de imágenes, y una larga serie de bases de datos construidas con finalidades clínicas, de gestión, administrativas o estadísticas (bases de datos de aseguramiento, registros de alta hospitalaria, registros de mortalidad, de urgencias, de hospitalización a domicilio) o de reembolso (dispensación farmacéutica, facturación de diversos tipos de servicios como la diálisis, ambulancias, prótesis, conciertos, etc.) y alguna otra cosa.
A esta parte del Big Data sanitario la llamamos Real World Data (RWD) porque, a diferencia de los ensayos clínicos y otros estudios realizados bajo condiciones controladas, refleja la atención real que reciben los pacientes en cada contexto concreto, y los resultados clínicos que realmente obtienen, que no son necesariamente iguales a los que se obtuvieron en los ensayos. El RWD recoge los beneficios y efectos adversos de las decisiones médicas en la práctica clínica habitual de millones de pacientes.
OPINIÓN: El poder del Real World Data
Quizás lo más sorprendente de esta enorme fuente de información es que todavía sea percibida casi exclusivamente como un subproducto de la atención sanitaria, antes que como un elemento central para mejorar su calidad, seguridad y eficiencia. Los RWD, por un lado, permiten identificar anticipadamente los pacientes
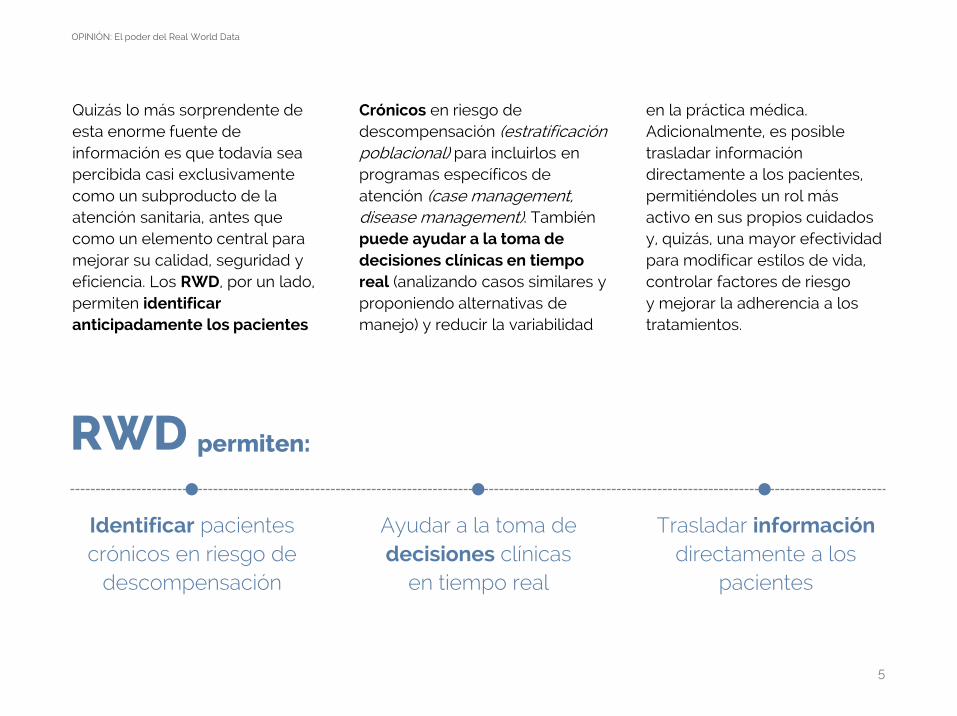
RWD permiten:
Identificar pacientescrónicos en riesgo de
descompensación
Ayudar a la toma de decisiones clínicas
en tiempo real
Trasladar información directamente a los
pacientes
5
Crónicos en riesgo de descompensación (estratificación poblacional) para incluirlos en programas específicos de atención (case management, disease management). También puede ayudar a la toma de decisiones clínicas en tiempo real (analizando casos similares y proponiendo alternativas de manejo) y reducir la variabilidad
en la práctica médica. Adicionalmente, es posible trasladar información directamente a los pacientes, permitiéndoles un rol más activo en sus propios cuidados y, quizás, una mayor efectividad para modificar estilos de vida, controlar factores de riesgo y mejorar la adherencia a los tratamientos.
OPINIÓN: El poder del Real World Data

6
OPINIÓN: El poder del Real World Data
En investigación clínica, farmacológica y epidemiológica el análisis de los RWD está suponiendo ya enormes beneficios para la población. Algunas aplicaciones, como el programa Mini-Sentinel(http://www.mini-sentinel.org) de la Agencia de Medicamentos de Estados Unidos, han permitido detectar nuevas interacciones, efectos adversos de medicamentos y otros problemas de seguridad que han llevado a la retirada de fármacos o la modificación de
sus indicaciones. Los RWD también pueden comparar distintos tratamientos para una misma condición (comparativeeffectiveness) y establecer el papel de cada uno en el manejo de los diferentes pacientes, un aspecto con importantes implicaciones en efectividad, seguridad y costes. En gestión de la atención sanitaria, los RWD permiten el desarrollo de indicadores sofisticados para comparar la calidad de la atención que reciben los pacientes atendidos en distintos centros o por diferentes médicos y desarrollar estrategias de mejora.

La utilización del Big Data para transformar la atención sanitaria no está libre de barreras y limitaciones. Entre ellas, el mantenimiento de la privacidad ocupa un lugar preeminente. Pese a que España dispone de normas legales (protección de datos, investigación biomédica, derechos de
7
pacientes) que regulan adecuadamente estos aspectos, probablemente falta mejorar la gobernanza de la gestión de datos. También existen problemas técnicos (fragmentación de los sistemas, limitada interoperabilidad), de calidad de la información y, por descontado, de desarrollo en diseños epidemiológicos y métodos de análisis estadístico que mejoren la fortaleza de los análisis causales. Pero más allá de estos problemas, que probablemente compartimos con otros países, el Sistema Nacional de Salud (SNS) afronta barreras específicas para utilizar los RWD en investigación, evaluación y mejora de la atención. Entre ellas, la precariedad y debilidad de sus estructuras investigadoras en servicios de salud y atención sanitaria, que difícilmente podrán producir ni una pequeña parte del conocimiento que el SNS precisa. También, la necesidad de mayor transparencia en la información y de accesibilidad a los datos de las organizaciones sanitarias. No olvidemos que aquí, como en otras áreas de la vida española, existe una importante opacidad que no deriva tanto de la protección de la privacidad de los pacientes, como de limitar la evaluación independiente de las políticas sanitarias públicas.
OPINIÓN: El poder del Real World Data

Bernardo Valdivieso
Director del Área de Planificación y del área de Atención Domiciliaria y Telemedicina del Hospital Universitario y Politécnico LA FE de Valencia
ENTREVISTA
ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”
3
“Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”
8

P: ¿Cómo ve el desarrollo del Big Data en España?
R: Es un campo todavía muy desconocido pero todos los que estamos trabajando en ese entorno pensamos que es una de las palancas importantes para cambiar el paradigma actual del modelo de cuidados. Aunque de momento, tanto aquí como en otros países, el Big Data supone más una oferta tecnológica que un proyecto real aplicado a la práctica clínica.
P: ¿Qué va a aportar?
R: Uno de los cambios que pretende el nuevo modelo es realizar una gestión proactiva del cuidado: no tendremos que esperar a que vengan los enfermos cuando se encuentren mal sino nosotros, de alguna manera, gestionaremos la población para preservarla sana y para mantener estables las enfermedades y que no progresen. Usar la información que estamos acumulando para predecir qué va a pasar tiene que ayudarnos a lograr esa proactividad.
9
ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”

ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”
P: ¿Se hacen las preguntas adecuadas en la recogida de datos?
R: El Big Data recoge millones de datos. Tenemos muchos demográficos -sobre todo desde que contamos con la tarjeta de identificación sanitaria implantada en todo el país-; tenemos muchos almacenados en el sistema sanitario al digitalizarse la historia clínica, con un porcentaje muy alto tanto en primaria como en hospital (casi el 70%); y tenemos bastantes que se están empezando a recoger con lo que llaman ahora el Internet de las cosas a través de smartphones, con una penetración casi universal en la población joven. Todo esto, junto con datos que se recogen en las casas o con los ambientales, nos lleva a que podamos predecir muchas cosas si somos capaces de unir esa información alrededor de la población y del individuo.
P: ¿Qué cosas?
R: Podemos detectar necesidades, gestionar mejor lo que hacemos para tomar decisiones correctas y a partir de ahí predecir, validar si lo que hemos predicho logra el resultado efectivo. La finalidad de todo es prescribir algo que evite lo que sabemos que va a pasar. Ese el camino de la medicina de precisión.
10

P: ¿Se avanza en ese camino?
R: Estamos empezando. Todo el mundo quiere desarrollar modelos predictivos para adelantarse a lo que ocurra y para eso hay que construir lo que llaman Big Data o Real World Data que es el mundo real de los datos. Hay organizaciones como la nuestra que lleva dos años intentando tener ese Real World Data para, sobre eso, generar múltiples predicciones para distintas enfermedades o para prevenir hábitos no saludables y caminar hacia la medicina de precisión. Nosotros recogemos la información alrededor de una tarjeta sanitaria: información demográfica de los ciudadanos; de movilidad a través de sus contactos con el sistema sanitario; de consumo de recursos cada vez que acuden al sistema sanitario; de sus parámetros de laboratorio cuando tienen contacto desde el punto de vista de promoción de la salud como de uso del sistema cuando están enfermos así como los datos no estructurados como la imagen radiológica. Y estamos empezando a recoger también de manera ordenada la información de las ómicas, todo lo que deriva del genoma. Con todo esto tendría uno el mundo ideal de los datos para empezar a detectar
ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”
24 MILLONESde datos
HABITANTES300.000
11
las necesidades, tomar mejores decisiones cada día de una manera proactiva y, sobre eso, construir predicciones y evaluar con esa información si lo que se hace es efectivo o no.
P: ¿A cuántas personas están estudiando?
R: En nuestro caso estamos construyendo un Real World Data sobre una población que tenemos adscrita de 300.000 habitantes. Manejamos 24 millones de datos. Tener esta información y manejarla bien tiene que servir para que los clínicos trabajemos de manera proactiva y gestionemos la población sana y también la enferma.

ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”
P: ¿Se ahorran costes?
R: Para la industria farmacéutica y para la sociedad se abre una nueva vía. Estamos acostumbrados a demostrar la eficacia de los fármacos a través de los ensayos clínicos, pero esto no deja de ser una burbuja en la que se selecciona una población muy concreta. Salir de esa burbuja solo lo puedes hacer si tienes un RWD construido para ver a qué personas les das ese fármaco y si la eficacia que tenía demostrada se comprueba en el salto a la efectividad cuando lo usas en el mundo real. Ello permite identificar si el fármaco tiene más o menos efectos adversos de los que están preestablecidos y ayudar a la industria a su investigación. También esos datos permiten detectar necesidades e incluso ayudan a determinar el target de la población que se beneficiaría de ese fármaco. El Big Data tiene que servir para investigar mejor,para centrarse más en las necesidades, para predecir a quién le va a ir mejor en la investigación que haya puesto en marcha y para evaluar la efectividad de los estudios y ver realmente el impacto social que tiene la introducción de ese nuevo fármaco.
P: ¿La administración es receptiva?
R: Sí. No hay vuelta atrás.
P: ¿Es necesario otro perfil de profesionales sanitarios?
R: El sector sanitario necesita nuevas herramientas que son las del Big Data o de inteligencia de negocio y necesita nuevas capacidades funcionales. Tenemos buenos médicos y buenos enfermeros pero, en nuestro proyecto, estamos incorporando gente que se dedica a la informática, a la estadística y al manejo de estas herramientas para sumar capacidades junto a las de nuestros profesionales sanitarios. En definitiva, nuevas herramientas y nuevos perfiles funcionales, pero con poco se puede hacer mucho.
12

P: ¿La privacidad de los pacientes está protegida?
R: En nuestro caso no hemos hecho un open data, no estamos cediendo los datos. Estamos usando los datos anonimizados dentro de la organización para identificar y predecir necesidades y actuaciones.
P: ¿El Big Data va a revolucionar la medicina?
R: Creo que sí. Va a ser el gran cambio. Somos el único sector productivo de servicios que nunca ha utilizado la información de manera adecuada para adaptar los servicios a las necesidades, para predecir expectativas o lo que demandan los usuarios y para evaluar las actuaciones.
“CUANTO MEJOR GESTIONES LA SALUDMENOS GASTARÁS”
13
P: ¿Por qué irrumpe ahora el Big Data y no antes?
R: Por un lado por la capacidad tecnológica que existe y, por otro lado por la crisis. La crisis económica ha metido en cintura al sector sanitario; ya vivíamos en crisis y en deuda desde hace bastantes años y si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión que es darle a cada uno lo que necesita. Tenemos que ser efectivos y si además somos capaces de adelantarnos a la necesidad pues vamos a evitar enfermedad y daños multiorgánicos. Está demostrado que el 5% de la población consume el 40% de los recursos; que unos pocos consumen mucho. Solamente si somos capaces de evitar deterioros multiorgánicos y de gestionar proactivamente salud y enfermedad podremos sostener el sistema actual. Cuanto mejor gestiones la salud y la enfermedad menos gastarás y mejor estará tu población. Esa nueva propuesta de valor de ser más accesible, de tener más calidad y bajar los costes, solo se consigue usando la información de manera adecuada.
ENTREVISTA: “Si queremos hacer sostenible el sistema estamos abocados a la medicina de precisión”

La hora del Big Data en Salud
OPINIÓN
OPINIÓN: La hora del Big Data en Salud
4
Hoy por hoy, la salud son datos. Bueno, quizás exageramos, ya que, evidentemente, alrededor de la salud de las personas hay mucho más: territorio, actitudes, creencias, relaciones personales, servicios sanitarios, medios de comunicación, culturas, enfermedades, medicamentos, síntomas, diagnósticos, etc. Pero estamos en la era del registro masivo de
del individuo y de la población? ¿qué posibilidades tienen todos esos datos?
Big Data no es más que la disponibilidad de un volumen masivo de datos, de gran variedad, que permiten su análisis para encontrar
Miguel Ángel Mañez
Economista, gestor sanitario y experto en entornos digitales
14
la información, las estadísticas y la historia clínica electrónica, y por ello nos encontramos con que todos esos elementos sobre los que pivota la salud pueden acabar resumidos en datos. Incluso la investigación tiene una gran base cuantitativa: ensayos, encuestas de salud, etc. La gran pregunta es: ¿utilizamos todo ese arsenal de datos para mejorar la salud

OPINIÓN: La hora del Big Data en Salud
tendencias y patrones de comportamiento.El Big Data va íntimamente ligado al concepto de liberación y reutilización de los datos, y ya el propio Consejo Asesor de Sanidad elaboró en 2014 un documento estratégico sobre esalud en el que ponía de manifiesto la necesidad de transformar los datos de salud en conocimiento, promover los bancos de datos abiertos y conseguir que la comunidad científica pueda utilizar dichos datos; todo ello en un marco regulatorio muy claro basado en la confidencialidad y la privacidad. Dado que se trata de datos personales que deben ser especialmente protegidos por la Administración, es obligatorio evitar que el tratamiento de los datos de salud permita identificar a la persona
a la que se refieren, salvo que exista consentimiento expreso. ¿Y por qué se habla de la revolución del Big Data
en el ámbito de la salud? Han coincidido en el tiempo diversos factores: existe una demanda creciente de datos por parte de los investigadores, la historia clínica electrónica permite obtener información de muchas personas y de sus patologías, las políticas de datos abiertos y de transparencia están generando muchos proyectos basados en Big Data y, obviamente, existen las herramientas adecuadas para su tratamiento. De hecho, muchas organizaciones sanitarias están clasificando a sus pacientes según su riesgo, permitiendo centrar sus actuaciones en los grupos más vulnerables.
15

Otro elemento importante son los avances en relación a la genética y a la medicina personalizada, que permiten utilizar biobancoscon datos de ADN para hacer predicciones sobre los problemas futuros de salud que podría tener una persona. Para ello, se está trabajando en complejos sistemas de análisis que por un lado estudian las relaciones entre los genes y algunas patologías (como el cáncer), y por otro, analizan el ADN de una persona para establecer la probabilidad de que pueda padecer una enfermedad concreta. Eso sí, es importante no dejar de lado otro tipo de datos esenciales para la salud como son los sociales y ambientales.
La casuística para el uso del Big Data es muy amplia. De hecho ahora que los datos empiezan a estar disponibles, es el momento de crear, de poner en marcha proyectos y de establecer alianzas con proveedores tecnológicos y desarrolladores que ayuden a encontrar la varita mágica. Hemos seleccionado algunos ejemplos de las posibilidades del Big Data en el ámbito de la salud:
OPINIÓN: La hora del Big Data en Salud
Predicción de hospitalizaciones por patologías en base a factores ambientales, poblacionales, etc.
Identificación de pacientes de alto riesgo. De hecho, en muchos servicios de salud se han puesto en marcha programas de atención a la cronicidad que, en base a los datos que constan en la historia clínica, han podido catalogar a cada paciente en un nivel de la conocida pirámide de Kaiser.
Toma de decisiones en la consulta.
Análisis del estado de salud de una población o territorio.
Seguimiento de tendencias.
16

¿Llegaremos a predecir la aparición de una enfermedad? ¿Cambiará el Big Data la forma en la que se hace la asistencia sanitaria o la prevención de enfermedades? La fiabilidad de los datos, tener las ideas claras sobre nuestro objetivo y utilizar herramientas y procesos rigurosos son nuestros compañeros de viaje.
OPINIÓN: La hora del Big Data en Salud
Efectividad de medicamentos y seguimiento de efectos adversos. ¿Cuántos pacientes han sufrido el mismo efecto adverso ante un medicamento? ¿Existe una mejora en los pacientes que utilizan el medicamento A frente a los que toman el medicamento B?.
Evaluación de servicios sanitarios. Será mucho más sencillo obtener resultados de salud y comparar y evaluar iniciativas, proyectos, unidades, etc.
Vigilancia epidemiológica.
Ensayos clínicos. En muchos casos, ya no será necesario reclutar a pacientes o revisar casi manualmente las historias clínicas, ya que los sistemas de Big Data permitirán encontrar a los pacientes para el ensayo y hacer el seguimiento de forma casi automática.
17

“Analizar millones de datos en las redes sociales es muy valioso”
ENTREVISTA
ENTREVISTA: “Analizar millones de datos en las redes sociales es muy valioso”
Paloma Martínez
Profesora del Área de Ciencias de la Computación e Inteligencia Artificial del Departamento de Informática de la Universidad Carlos III de Madrid y responsable del grupo de investigación LaBDA (Bases de Datos Avanzadas). Ha liderado el proyecto europeo TrendMinerde monitorización de temas de salud en redes sociales.
5
18

P: Han analizado más de tres millones de tuits¿Qué buscaban y qué han encontrado?
R: Buscábamos limpiar, depurar los datos de las redes sociales y convertirlos en información estructurada. Decidimos analizar millones de tuits–con la empresa tecnológica Singular Meaning-con la información que los pacientes dejaban sobre determinados medicamentos en las redes sociales. Nos dimos cuenta de que en Twitter la gente habla de todo y que podíamos obtener muchísima información, por ejemplo, de efectos adversos de medicamentos que no se resaltan en los ensayos clínicos.
ENTREVISTA: “Analizar millones de datos en las redes sociales es muy valioso”
19
P: ¿Cómo consiguen interpretar esos datos?
R: Antes de saber si un determinado paciente está informando sobre un determinado efecto adverso primero hay que entender lo que ha escrito en un comentario o en un tweet y para ello se utilizan técnicas de procesamiento del lenguaje natural que identifican qué fármacos, enfermedades y efectos se mencionan. No es fácil, hay gente que escribe mal los nombres de los medicamentos o que cuenta, por ejemplo, “me ha dejado k.odeterminada pastilla”. Tampoco suele decir que tiene cefaleas cuando le duele la cabeza. La máquina no sabe interpretar lo que se escribe, por ello hay que ser muy preciso en las clasificaciones. Los pacientes no hablan como los especialistas.El reto es transformar esos millones de datos en lenguaje natural para interpretarlos.

P: ¿Las redes sociales ayudan a los investigadores?
R: Muchísimo. En Twitter la gente habla de todo, sin ningún problema. También analizamos miles de mensajes en foros. La información ayuda a conocer mucho mejor las enfermedades y en el caso concreto de esta investigación, determinados medicamentos.
P: ¿Qué otras conclusiones les dieron esos millones de tuits?
R: En nuestro estudio vimos que la gente hablaba mucho de ansiolíticos y antidepresivos y nos centramos en ellos. Nos sirvió para conocer efectos adversos y que, en algunos casos, podían servir también para otras dolencias. Analizar millones de datos es muy valioso, por ejemplo, para conseguir más información sobre las enfermedades raras. La relación de dos cosas que se mencionan en 140 caracteres ayuda a descubrir asociaciones entre conceptos.
“ANALIZAMOS MILES DE MENSAJES. LA INFORMACIÓN AYUDA A CONOCER MUCHO MEJOR LAS ENFERMEDADES Y LOS MEDICAMENTOS”
ENTREVISTA: “Analizar millones de datos en las redes sociales es muy valioso”
20
P: Se tiende a retuitear mucho los mensajes, ¿no se distorsiona la muestra?
R: Claro, este estudio es pionero pero abre un abanico enorme de posibilidades. Hay que limar las herramientas para que para que además se pueda asegurar la veracidad de una información.Hay que escuchar a los pacientes en los sitios donde están hablando.

ENTREVISTA: “Analizar millones de datos en las redes sociales es muy valioso”
21
P: ¿El Big Data funciona?
R: Se necesitan muchísimos datos para que los estudios sean interesantes. Hay un volumen inmenso de información. Necesitamos herramientas que nos digan qué es lo que hay que mirar. En nuestro caso vamos a comenzar un proyecto con el hospital de Alcorcón para analizar el texto que hay en las historias clínicas y que a día de hoy no se procesa. Lo que escribe el médico es importante y hay que saber clasificarlo e interpretarlo. Hay que cruzar la información para potenciar la medicina personalizada. Hay mucha información -y muy valiosa-, escrita que no está estructurada en metadatos y que hay que analizar para, por ejemplo, llevar a cabo estudios epidemiológicos o personalización de tratamientos.
P: ¿Le preocupa la privacidad?
R: Hay un vacío legal que hay que resolver. Siempre con la garantía del anonimato hay que intentar acceder al mayor volumen de datos, cruzarlos con otras fuentes. Podemos predecir y descubrir gracias al Big Data; las posibilidades - siempre respetando al paciente-, son infinitas.

“Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
ENTREVISTA
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
Julio Mayol
Profesor de Cirugía de la Universidad Complutense de Madrid, director de laFundación para la Investigación Biomédica del Hospital Clínico San Carlos y codirector del Madrid-MIT MVision Consortium.
6
22
P: ¿Qué aporta a los médicos hoy en día el análisis masivo de datos?
R: Ahora mismo el Big Data no aporta nada. Es todo una hipótesis, es todo un “si utilizáramos, si hiciéramos, si cogiéramos…”. Pero realmente ahora mismo no aporta nada.
P: Lidera un estudio -Hakari (Luz)- con miles de pacientes patrocinado por Fujitsu ¿Qué están aprendiendo?
R: Hemos empezado a trabajar con Fujitsu y tenemos una herramienta de apoyo para la toma de decisiones en salud mental que todavía está en una fase muy inicial. Es una herramienta que se comercializará en el futuro -esa es la idea-, que utiliza datos clínicos y no clínicos, estructurados y noestructurados, que permiten identificar patrones de comportamiento de grupos en pacientes con problemas de salud mental pero también de otros individuos.
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
FUE
NT
ES
DE
DA
TO
S
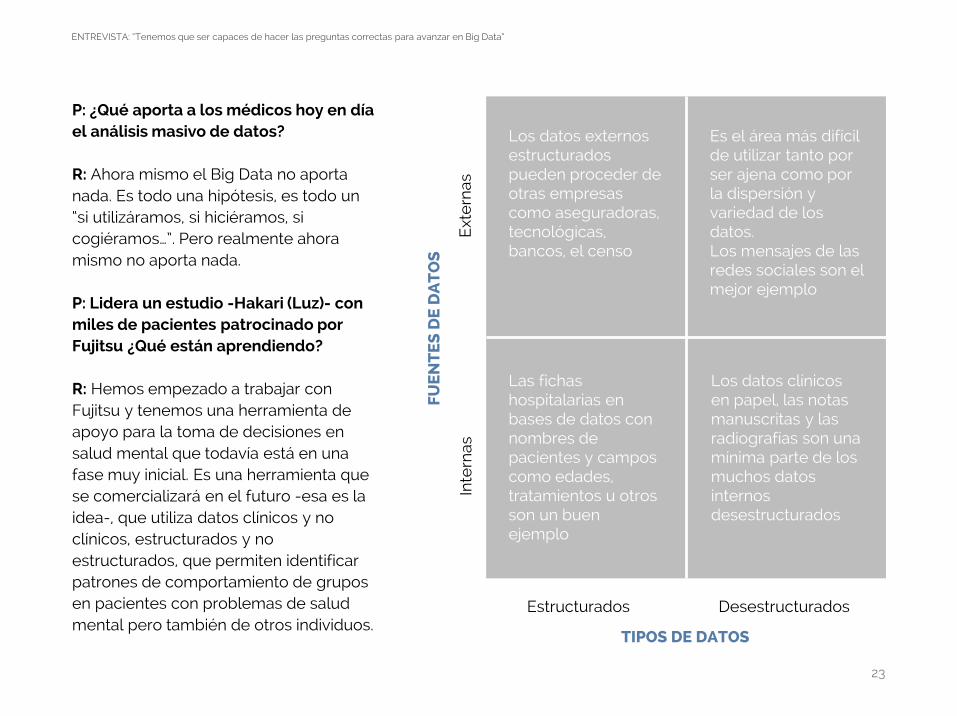
TIPOS DE DATOS
Ext
ern
asIn
tern
as
Estructurados Desestructurados
Los datos externos estructurados pueden proceder de otras empresas como aseguradoras, tecnológicas, bancos, el censo
Las fichas hospitalarias en bases de datos con nombres de pacientes y campos como edades, tratamientos u otros son un buen ejemplo
Es el área más difícil de utilizar tanto por ser ajena como por la dispersión y variedad de los datos.Los mensajes de las redes sociales son el mejor ejemplo
Los datos clínicos en papel, las notas manuscritas y las radiografías son una mínima parte de los muchos datos internos desestructurados
23

Permite generar un sistema de ayuda a la toma de decisiones: desde dónde se tienen que dedicar los recursos hasta en qué fases hay que hacerlo o qué factores del entorno pueden desencadenar un determinado aumento de la frecuencia de la enfermedad y, por lo tanto, hay que responder ante ella.
P: ¿Cuánta gente participa en el estudio?
R: Estamos en la primera fase con datos clínicos con miles de pacientes de Madrid. Son datos anonimizados y también se utilizan bases de datos del tiempo, de la meteorología, bases no estructuradas de las redes sociales. Se utilizan grandes volúmenes de datos.
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
24
“AHORA MISMO TODO EL MUNDO ESTÁ CON EL INTERNET DE LAS COSAS Y ESTÁ RECOGIENDO DATOS, DE SANOS, DE ENFERMOS, PERO REALMENTE NO SABEMOS LO QUE SIGNIFICAN”
Conseguimos demostrar que su utilización ofrece información de interés para los clínicos. Es una primera fase pero hay que demostrar que eso en la práctica clínica tiene impacto.
P: ¿El Big Data está empezando?
R: En el campo de la Salud absolutamente. Ahora mismo todo el mundo está con el Internet de las cosas y está recogiendo datos, de sanos, de enfermos, pero realmente no sabemos lo que significan. Hasta que no seamos capaces de hacer las preguntas correctas y procesar toda esa información y los datos de la manera adecuada no sabremos lo que significan y, por lo tanto, no nos aportan nada.

P: ¿Qué es necesario para conseguir resultados?
R: Requiere profesionales que sean capaces de hacerse las preguntas correctas, datos de calidad suficiente para poder ser explotados y toda una infraestructura tecnológica y de conocimiento que permita encontrar las respuestas a esas
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
25
preguntas. Requiere crear un mundo nuevo. Ahora mismo nadie está preparado para eso. Hay grupos que están trabajando en Big Data en historia clínica. Aunque demostraciones con resultadosdefinitivos que luego hay que validar, en España no hay. Nosotros estamos en ello con el estudio.
P: ¿Les preocupa la privacidad de los pacientes?
R: En el sistema público existe evidentemente confidencialidad, no es posible identificar al paciente. Las herramientas utilizadas son para investigación y apoyo a la toma de decisiones que eventualmente en el futuro se podrán utilizar para personalizar el tratamiento. Lo que hagan las aseguradoras con datos que les hemos dado (y que son públicos) es un problema que nosotros teníamos que haber pensado antes. Con la cantidad de información que damos en redes sociales, en la tarjeta del banco, en los correos electrónicos… se puede extraer información sanitaria pero no es un problema nuestro, no es un problema del sistema sanitario, al menos del público.

P: ¿No hay riesgos?
R: Siempre alguien va a estar vigilando a alguien. La personalización es buena pero también tiene una parte mala, que es que lo bueno y lo malo puede ser personalizado. Dentro del grupo como animal social nos encontramos muy cómodos pero cuando pedimos que personalicen nuestro tratamiento y nuestra manera de hacer las cosas, estamos ofreciendo un flanco.
Evidentemente hay una legislación actualmente vigente que regula de manera estricta la utilización de datos pero es cierto que la realidad suele ir por delante de la legalidad y es posible que haya muchas personas que potencialmente pudiesen ser discriminadas, pero ya lo son sin el Big Data. Hoy en día hay muchas maneras muy personalizadas de discriminar a las personas sin necesidad de recurrir a los datos.
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
26

P: ¿El panorama con respecto al Big Data en el extranjero es diferente al español?
R: Pasa lo mismo fuera. Se está en fase de investigación. En la sanidad no hay herramientas más que en fase de investigación- como Watson de IBM-, en fase de validación como nosotros con Fujitsu. Hay plataformas de investigación pero no son asistenciales. Se están haciendo estudios con volumen de datos en genómica o genética metabolómica pero todo es en el plano de la investigación, en el de aplicación clínica hay pocas cosas.
P: ¿Esos datos sirven?
R: En investigación es cierto que utilizar grandes masas de datos te permite identificar nuevas dianas terapéuticas, pero su impacto en la clínica se desconoce. Y no hay que olvidar que la genética no es el elemento determinante, citando a Ortega: “Yo soy yo y mi circunstancia”.
BIGDATA
ENTREVISTA: “Tenemos que ser capaces de hacer las preguntas correctas para avanzar en Big Data”
27
P: Si en el futuro el Big Data se convirtiese en una verdadera revolución ¿qué papel deberían jugar los médicos?
R: Con los datos, el médico hoy en día clasifica al paciente en el sitio adecuado y toma las decisiones claves en el tratamiento. Si llega el momento en el que la inteligencia artificial nos sobrepasase y analice los datos mejor que nosotros, los humanos pasaremos a otro plano. No somos imprescindibles aunque a algunos les cueste asumirlo.

Retos futuros para los Sistemas de Información en el Entorno Sanitario
OPINIÓN
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario
7
“El Big Data ayuda a encontrar las preguntas que no sabes que quieres preguntar”
José A. Guerrero
Licenciado en Matemáticas (Estadística e Investigación Operativa), postgrado en Programación Científica y Experto Universitario en Gestión Pública. Top solver en Kaggle, plataforma de referencia de modelos predictivos basados en Big Data.
28

Bajo el paradigma del Big Data se hace referencia no sólo al tamaño de los datos, sino especialmente a su heterogeneidad y a la velocidad con la que se generan. Con esta definición, los entornos sanitarios son territorio Big Data por excelencia.Desde un punto de vista productivo, un hospital es una empresa compleja en la que no existe una estructura lineal sino una intrincada malla de procesos. A esto se unen otros factores como la propia variabilidad natural, que dificulta la medición de los resultados y el elevado número de medios técnicos especializados necesarios para la atención a los usuarios.
De manera simplificada, tradicionalmente la Gestión
29
Sanitaria ha sido un equilibrio entre la voluntad de los clínicos, cuya prioridad era la prestación de la mejor asistencia posible independientemente del coste, y la de los gestores, preocupados fundamentalmente por los presupuestos. Actualmente, sin embargo, existe una profunda sensibilidad de todos los actores sobre la sostenibilidad del sistema. Dos conceptos han sido claves a la hora de entender esta evolución de la gestión sanitaria en las últimas décadas: Gestión Clínica y Medicina Basada en la Evidencia.
La Gestión Clínica viene a resolver el problema del equilibrio entre la prestación de la asistencia sanitaria y la gestión eficiente de recursos
limitados. La estrategia deltraslado de autonomía a los clínicos en aspectos que tradicionalmente no tenían, como la gestión financiera o de recursos humanos, favorece la corresponsabilidad en la gestión. El desarrollo de la Gestión Clínica se ha sustentado en cambios organizativos y en la implantación de nuevos Sistemas de Información.
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario

La historia clínica electrónica y la informatización de los procesos de flujos de pacientes han permitido pasar de sistemas de información agregados a los denominados Conjuntos Mínimos Básicos de Datos (CMBD), que han sido implantados en los diferentes ámbitos asistenciales.
Estos registros desagregados se integran en repositorios que utilizan herramientas de Business Intelligence para su explotación. Los cubos OLAP utilizan dimensiones como la estructura física, geográfica, funcional o la actividad clínica realizada, permitiendo la navegabilidad y la exportación de tablas pivotales. El Data Warehouse de las Áreas Económicas y Logísticas, como Personal, Compras, Suministros
“BUSINESS INTELLIGENCE AYUDA A ENCONTRAR RESPUESTAS A PREGUNTAS CONOCIDAS; EL BIG DATA AYUDA A ENCONTRAR LAS PREGUNTAS QUE NO SABES QUE QUIERES PREGUNTAR”Eric D. BrownConsultor en Tecnologías
30
y Almacenes se utiliza para la elaboración de presupuestos, como entrada de información de los sistemas de contabilidad analítica, para evaluar los costes por proceso y en el seguimiento de los pactos de consumo de las Unidades de Gestión.
Business Intelligence es un término que con frecuencia se suele utilizar como sinónimo de Big Data. Mucho se ha escrito sobre las diferencias entre uno y otro, pero si tuviera que quedarme con una cita lo haría con la de Eric D. Brown, Consultor en Tecnologías: “Business Intelligence ayuda a encontrar respuestas a preguntas conocidas, mientras que el Big Data ayuda a encontrar las preguntas que no sabes que quieres preguntar”.
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario

calidad de la prestación de una asistencia o en el coste asociado a la misma. El conocimiento que se extraiga con estas técnicas podrá ser aplicado en el desarrollo de simuladores avanzados que permitan, por ejemplo, decidir entre dos modalidades organizativas teniendo en cuenta coste, producción y calidad.
El otro concepto que indicábamos junto a la gestión clínica era la medicina basada en la evidencia. Este surge como necesidad de contrastar con una metodología científica y reproducible las nuevas técnicas diagnósticas y terapéuticas que, de forma exponencial, el mercado pone a disposición de nuestros clínicos.
El mayor reto actual, tras haber concluido las fases de informatización y explotación, es la exploración avanzada de los repositorios mediante Big Data para, por ejemplo, el reconocimiento de patrones que rigen la relación entre el consumo de recursos y la actividad realizada o determinar si existe una anomalía en la
31
La evaluación tecnológica y los ensayos clínicos utilizan fundamentalmente estadística multivariable clásica. Análisis de la mortalidad tras un tratamiento, análisis de la varianzas e interacción en un diseño experimental o la evaluación de una técnica de cribaje respecto a la de referencia mediante sensibilidad y especificidad son algunos casos de análisis realizados.
Recordemos que la estadística clásica se basa en una serie de hipótesis como el conocimiento de la distribución de los datos, independencia de la variables, restricciones en la variabilidad de los errores con el tiempo o con la variable a estudiar…, y que determinados artefactos, como la presencia
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario

de valores extremos o valores con información desconocida no son bien manejados por muchas de las técnicas tradicionales. A diferencia de esto, las técnicas de aprendizaje automático explotan la capacidad de cálculo de los ordenadores actuales para obviar dichas hipótesis y minimizar el impacto de los déficits de información. Cada día es más frecuente el ver estudios basados en árboles de regresión (random forest o gradient boosting), máquinas de vectores de soporte y redes neuronales, pero quedan sin duda muchos retos por delante.
El más importante, dado la gran cantidad de documentación clínica escrita en formato no estructurado, es el procesamiento del lenguaje
32
natural (NLP) y la construcción automática de ontologías que sirvan para representar el conocimiento clínico. Los modelos de representación de información clínica llevan años desarrollándose, pero su aplicación en la práctica ha sido muy reducida. SNOMED y RIM HL7 (sistema para almacenar y compartir conocimiento clínico) están bien concebidos pero su punto débil es precisamente que necesitan de un gran trabajo para la implantación y para el posterior registro de la información. La interoperabilidad de los sistemas pasa necesariamente por las técnicas de aprendizaje automático, que deben aportar los mecanismos para que la estructuración de la información sea no supervisada o, en el peor de los casos, semisupervisada.
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario

Otro campo de aplicación de técnicas semisupervisadas es la detección de observaciones extremas, que puedan servir como sucesos centinelas epidemiológicos o interacción de medicamentos.
Técnicas diagnósticas de vanguardia hace pocos años se han convertido ahora en técnicas de cribaje, siendo necesario rentabilizarlas mediante el desarrollo de modelos que infieran el diagnóstico cierto a partir del de sospecha.
Los sistemas de monitorización generan cada día más tráfico de información. El desarrollo de técnicas específicas de análisis en streaming, que generen alertas cada vez más fiables será también otro objetivo prioritario para conseguir la eficiencia.
¿Cuáles serán los proyectos de Big Data en el entorno sanitario dentro de diez años? Bien, parafraseando a Eric D. Brown, será la propia y progresiva aplicación de herramientas Big Data la que nos descubrirá las ‘preguntas’ ocultas en nuestros datos.
33
OPINIÓN: Retos futuros para los Sistemas de Información en el Entorno Sanitario

Los datos son del pacienteREPORTAJE
REPORTAJE: Los datos son del paciente
8
“El paciente es dueño de sus datos. Su consentimiento tiene que regir cualquier actuación con sus datos. No hay otro camino”. El director de la Agencia Vasca de Protección de Datos, Iñaki Pariente de la Prada, afirma que aunque no haya una regulación especial de Big Data
34
en el campo de la salud, el paciente es el que tiene que tener la última palabra cuando se utilizan sus datos sanitarios.Y detalla: “Pese a no haber una ley se prevé la obligación a las administraciones y empresas de todo el mundo que hagan tratamiento masivos de datos
de redactar un texto denominado ‘evaluación de impacto’ que tiene que elaborarse antes de la recogida o tratamientos masivos de información. En dónde se analice si se va a respetar o no la normativa de privacidad y cómo se va a hacer”.

Para Pariente de la Prada hay que respetar la ley tanto en la recogida, como en el tratamiento y en la cancelación de los datos personales.
¿Pero qué ley dado que no hay una específica para datos de Salud? La ley general de Protección de Datos es del año 1999 (traspone una directiva del 95) y engloba la protección de datos en general y no regula sectorialmente cada campo de actuación. Una ley que se hizo cuando unos pocos estaban familiarizados con Internet y el término Big Data ni existía. El director de la Agencia Vasca de Protección de Datos explica: “Hay dos principios esenciales en la recogida de datos sanitarios: información y consentimiento. Supuestamente una persona cuando da sus datos a otra tiene que
REPORTAJE: Los datos son del paciente
haber sido informada previamente de para qué se van a recoger -la finalidad-, cómo se van a utilizar, dónde se van a utilizar, en qué ficheros se van a guardar y la seguridad que van a tener. Teóricamente una vez que he informado de todo esto, la persona consiente o no dar esa información. Específicamente en los datos de salud siempre tiene que existir un consentimiento expreso y por escrito. Y si recojo datos en una página web gracias a una casilla, el sistema tiene que permitir guardar esa casilla para acreditar que se dio el consentimiento. A efectos de prueba”. Pariente de la Prada remacha: “Siempre que se recojan datos de salud el esquema es este: información y consentimiento y esto último agravado pues son datos especialmente protegidos”.
35

Está claro que cuando un paciente va a un hospital a tratarse existe un consentimiento tácito. Sus datos los puede ver todo el equipo médico pues la finalidad es curativa, paliativa-sanitaria- y existe el secreto profesional. Otro de los casos en que no se pide consentimiento es cuando se estudian millones de datos. Si es imposible contactar con los pacientes uno a uno, esa información se puede anonimizar para ser utilizada, por ejemplo, en investigaciones médicas o en la gestión de recursos sanitarios. El problema, señala otro experto en datos, Ramón Miralles, es si esa información -en principio segura- nunca va a desvelar la identidad de los pacientes. “Al igual que las técnicas de
36
REPORTAJE: Los datos son del paciente
si mañana la tecnología va a evolucionar. Pasa a ser un problema técnico.”
Europa ya ha tomado cartas en el asunto. La directiva de la Protección de Datos de 1995 creó un grupo de trabajo que reúne a todas las autoridades de protección de datos de los países miembros y ese grupo de expertos, que inicialmente
anonimización han idoevolucionando, las técnicas para cruzar bases de datos han evolucionado también. Y esos procesos pueden, en ciertas circunstancias, llegar a asociar esa información anonimizadacon alguien. La tecnología no para y al cruzar información yutilizar muchas bases de datos perdemos el control de a quién cedemos los datos”. Pariente de la Prada comparte la misma opinión: “Es un acto fe. Te dicen que técnicamente hay garantía de que no puede ser ‘reanonimizado’ pero realmente no sabes, aunque en esemomento seacierto,

se reunía de forma esporádica, ha cobrado importancia y emite cerca de cuatro dictámenes al año. El de abril de 2014 fue sobre “técnicas de anonimización” y estableció los criterios técnicos para anonimizar los datos. “Es un dictamen que marca las pautas que hay que seguir. De alguna forma es como si actualizase la ley. Trata cosas que la norma no contempló cuando nació y que hay que ir interpretando. La ley no cambia pero con estos dictámenes se actualiza, son muy importantes”, explica el experto vasco.
Uno de los puntos de mira de este grupo de expertos europeos son las empresas de tecnología que, con sus wearables, controlan hasta el último latido de un paciente
37
REPORTAJE: Los datos son del paciente
“LA LEY NO CAMBIA PERO CON ESTOS DICTÁMENES SE ACTUALIZA, SON MUY IMPORTANTES”
sano y que también estándetrás de los dispositivos de control que se instalan en las viviendas de pacientes crónicos.Como señala el director de la agencia vasca: “Los sanos que se ponen pulseras con aplicaciones en el móvil están registrando millones de datos de salud que una empresa está guardando. Hoy por hoy con una finalidad indeterminada pues todavía no tienen claro para qué los van a utilizar. Son empresas que están en Estados Unidos, que no están sujetas al derecho español, y por ello si tengo un problema no voy a poder acudir a que me tutelen o ayuden las instituciones estatales. También hay cada vez más modelos mixtos: médicos de la sanidad pública que pueden acceder a perfiles que se está generando en la
empresa privada” ¿Cómo se gestiona todo eso? “, se pregunta Iñaki Pariente de la Prada. César Rubio, coordinador del Sector de e-Health de la Federación Española de Empresas de Tecnología Sanitaria (Fenin) señala que esos datos “sirven para obtener información y transformarla en valor. Y se supone que su uso va a ser bueno”.

Ramón Miralles también refleja la misma idea y explica que los pacientes ceden en algún momento sus datos porque confían en la sanidad y que, aunque puedan ser utilizados por terceras personas, “hay que poner en una balanza si ese riesgo compensa”. “Los datos pueden pasar de ser seguros a inseguros y escapar de nuestro control.
El riesgo está presente pero también es verdad que esa información que se cede puede ser vital en la investigación médica. Hay que hacer un equilibrio entre el riesgo que presenta y los beneficios que nos puede aportar ceder nuestros datos, nadie puede decir que estos datos seguirán siendo anónimos dentro de cinco años”.
Aparte de la anonimización, en los mecanismos para salvaguardar la privacidad del paciente “se aplica una lógica que ya existía y que ya estaba en la ley de historia clínica -en la ley 41/2002- y que dice que el paciente es dueño de sus datos, señala Pariente de la Prada. La historia clínica es del paciente. Puede pedir, puede ver, y eso se ha plasmado en la generalización de las tarjetas sanitarias con las que puede consultar parte de la historia clínica y la puede gestionar. Los datos son cada vez más del paciente . Y por ello si se utilizan con otra finalidad que no sea la curativa, sólo se pueden conseguir con su consentimiento. O tirar por la anonimización. No hay un camino intermedio”, concluye.
38
REPORTAJE: Los datos son del paciente
110010101
010100100
0101010100
1010101101
0110010100
La última decisión europea en octubre de 2015 lanza un rotundo mensaje a Estados Unidos en materia de protección de datos. Una sentencia del Tribunal de Justicia de la UE sobre la que no cabe recurso señala que cualquier estado miembro podrá a partir de ahora bloquear el envío de datos personales a EE. UU. El fallo habilita a las agencias nacionales de protección de datos para que frenen las transferencias de datos de ciudadanos europeos a terceros países (incluido EE. UU.) si consideran que la empresa o el país no es de fiar. Con este dictamen, el criterio de las agencias prevalecerá sobre el de la Comisión Europea y, por ello, las empresas americanas con sede en Europa tendrán que legitimar la transferencia de datos hacia Estados Unidos recabando la voluntad inequívoca del usuario que debe ser informado y consentirlo.
39
REPORTAJE: Los datos son del paciente

ENTREVISTA
ENTREVISTA: “Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”
9
Luciano Saez Ayerra
Presidente de la Sociedad Española de Informática de la Salud
“Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”
40

P: ¿Qué reto supone el Big Data en las TIC en el sistema sanitario público?
R: Llevamos planteando muchos años la necesidad de que se utilice la cuantiosa información clínica y de salud que se encuentra disponible en las organizaciones sanitarias con el fin de generar conocimiento y asegurar una toma de decisiones basada en la información. Esto es un reto a nivel de organización sanitaria ya que esta función de explotar la información no está imbuida en nuestra cultura de una forma profesionalizada, no disponemos prácticamente en el sistema de expertos en análisis de datos. Lógicamente existen algunas experiencias e iniciativas para anonimizardatos de salud y ofrecer esta
41
información para la investigación. Por otra parte los sistemas tecnológicos actuales no están preparados en general para abordar proyectos de Big Data, será necesario hacer importantes cambios en arquitecturas y comunicaciones. Pero antes de plantearse estos cambios habrá que definir qué datos se van a utilizar, donde se van a almacenar, quien lo va a coordinar y para que se van a utilizar. Preguntas básicas para las que todavía no hay respuesta.
P: ¿Se invierte más en proyectos tecnológicos tras la aparición del denominado Big Data?
R: Según los datos de que disponemos a través del INDICE SEIS 2014, en el apartado
correspondiente a tendencias y proyectos prioritarios, no están dentro de los 10 primeros proyectos definidos como de Big Data, aunque si se va avanzando en proyectos encaminados a la utilización de la información para la toma de decisiones clínicas y de gestión.Hay que tener en cuenta que las restricciones económicas en el sistema sanitario público afectaron de forma muy importante en los últimos tres años a los proyectos TIC.
ENTREVISTA: “Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”

42
P: ¿Hacen falta más profesionales TIC especializados en salud?
R: La carencia de profesionales TIC especializados en salud es uno de los frenos más importantes que tiene el sistema sanitario. Desde la Sociedad Española de Informática de la Salud llevamos muchos años planteando a todos los niveles que este es un recurso estratégico del sistema y que no se está haciendo prácticamente nada para solucionarlo. Nosotros promovemos la existencia de profesionales dentro del sistema experto en TIC y además en el “negocio” salud, creemos que es imprescindible no solo para poder acometer los complejos proyectos de salud que la tecnología hoy en día permite. También para garantizar, mantener e implantar totalmente los proyectos que están en marcha.
Para avanzar, hace dos años firmamos un convenio con el Instituto de Salud Carlos III. Uno de los objetivos era poner en marcha un Master en Dirección de Sistemas y Tecnologías de la Información y la Comunicación en Salud, del que ya vamos a empezar la II Edición, como una titulación de ámbito nacional de la Escuela Nacional de Sanidad. Creo que al margen de que en las Universidades adecúen sus planes de estudios e incorporen estas disciplinas, debemos disponer de un conjunto de profesionales formados en TIC, con conocimientos del sistema de salud y capacidad directiva. Es imprescindible que dispongan del máximo nivel de conocimientos para que se generalice que estos profesionales estén presentes en los diferentes comités directivos de las organizaciones, sino va a ser muy difícil la innovación de nuestro sector.
ENTREVISTA: “Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”

P: ¿El paciente está protegido o sus datos corren riesgo con los mecanismos que existen actualmente en los hospitales?
R: Lo más importante es tomar conciencia de que el tratamiento masivo de datos de salud, además de entrañar grandes beneficios para la investigación y la asistencia y gestión sanitaria, supone una serie de riesgos para la privacidad y la intimidad de los pacientes. Para lidiar con estos riesgos y poder identificarlos tempranamente y adoptar las medidas necesarias para eliminarlos o, al menos, mitigarlos hasta un nivel que resulte aceptable, es necesario e imprescindible que antes de abordar estos proyectos se lleve a cabo una Evaluación de Impacto en la Protección de Datos Personales (EIPD) -una de las herramientas más útiles del paradigma de la Protección de Datos desde el Diseño- que busca que los requerimientos y obligaciones en materia de protección de datos se tengan en cuenta desde las fases iniciales de cualquier proyecto que trate datos de carácter personal.
43
¿Cómo se garantiza tecnológicamente esa protección, esa anonimización de miles de datos?
R: En relación con las EIPD, la Agencia Española de Protección de Datos ha publicado una guía para ayudar a las organizaciones y para promover el uso de esta herramienta que, como decía, es imprescindible para controlar los riesgos y tomar las medidas adecuadas para no verse sorprendidos por la materialización de los mismos durante todo el ciclo de vida de un producto o servicio.Esto es igualmente cierto cuando se llevan a cabo procesos de anonimización. En nuestros días es cada vez más difícil conseguir el total e irreversible anonimato de los datos por la cantidad de información públicamente accesible así como por la evolución tecnológica que proporciona cada vez herramientas más potentes de correlación de la información. Por lo tanto, de nuevo, la anonimizaciónha de hacerse a través de metodologías contrastadas y evaluando claramente el riesgo residual de reidentificación de las personas para reducirlo a un nivel que se considere aceptable por todos los actores y, en particular, por las autoridades de protección de datos competente.
ENTREVISTA: “Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”

P: ¿Cuáles son los retos tecnológicos a los que se enfrenta el sistema sanitario?
R: El sistema sanitario de entrada a lo que se enfrenta es al reto del cambio. Un cambio provocado por los avances científicos, los costeseconómicos, los requerimientos de los ciudadanos y naturalmente por los avances tecnológicos. Este reto supone modificar procedimientos, legislación, roles profesionales y nuevas formas de atención sanitaria. Y todos estos cambios deben ser contemplados desde la perspectiva de utilizar la tecnología disponible. Ahora bien, en lo que se refiere a retos tecnológicos, es necesario redefinir la arquitectura de las redes de comunicación y
sistemas, de forma que toda lainformación de salud de un ciudadano esté disponible allí donde se encuentre y a su disposición. En cuanto a la existencia de un Big Data sanitario efectivamente puede cambiar nuestro escenario a medio plazo de una forma importante. Es el momento de definir una clara estrategia parael sistema sanitario en su conjunto ya que el valor que aportaría el poder disponer de grandes volúmenes de información real y contrastada,sería enorme en cuanto a generación de conocimientopara mejorar la seguridad de la atención sanitaria y su eficiencia.Desde mi punto de vista, estamos traspasando elmomento adecuado para definir la estrategia y el modelo a aplicar en todo el sistema.
44
las infraestructuras tecnológicas, todo ello planteado no solo para garantizar los servicios actuales y en implantación, como por ejemplo la historia clínica, sino con la visión de lo que habrá que poner en marcha.
P: ¿Puede hacer una valoración del funcionamiento de las historias clínicas? ¿La recogida masiva de datos va a cambiar el modelo sanitario?
R: En cuanto a la historia clínica electrónica (HCE), este proyecto está muy implantado en los centros sanitarios. En Atención Primaria y Especializada se dispone de más de 45 millones de Historias, dato referido a 2014. Otro tema vital es la necesidad de la interoperabilidad de todos los
ENTREVISTA: “Hay que hacer cambios tecnológicos para abordar proyectos de Big Data”

OPINIÓN
OPINIÓN: La información de salud: motor de cambio de los sistemas sanitarios
10
“EL proyecto VISC+ trata la información de salud que se genera en Cataluña de una manera totalmente anonimizada y segura”
Josep Maria Argimon
Director de la Agènciade Qualitat i AvaluacióSanitàries de Catalunya (AQuAS)
45
La información de salud: motor de cambio de los sistemas sanitarios

OPINIÓN: La información de salud: motor de cambio de los sistemas sanitarios
Las tecnologías de la información y la comunicación (TIC) y la digitalización de contenidos están transformando las sociedades y la manera de generar conocimiento.En este contexto está aumentando la demanda de la comunidad científica nacional1 e internacional2 de disponer de grandes volúmenes de información del sistema de salud, variada, de toda la población, debidamente anonimizada y sin tener que esperar largos periodos de seguimiento, con el objetivo de acelerar las actividades de investigación y transferir más rápidamente sus resultados a la práctica clínica. Siguiendo iniciativas como las existentes en Dinamarca3 o Reino Unido4 , y dando respuesta a esta necesidad, desde la Agencia de
“LA REUTILIZACIÓN DE INFORMACIÓN DE SALUD PRESENTA MÚLTIPLES APLICACIONES”
46
Calidad y Evaluación Sanitarias de Cataluña (AQuAS) se ha impulsado el proyecto VISC+5,que consiste en relacionar la información de salud que se genera en Cataluña de una manera totalmente anonimizada y segura, para impulsar y facilitar la investigación, la innovación y la evaluación en el ámbito de las ciencias de la salud. Esta iniciativa está alineada con la estrategia de investigación e innovación de la Unión Europea6, que está enfocada a potenciar la transferencia de los resultados de la investigación a los sectores productivos.
La reutilización de información de salud presenta múltiples aplicaciones. Actúa como facilitador para la Administración a la hora de planificar y evaluar,

permite mejorar la gestión interna de las organizaciones sanitarias y facilita la transparencia de resultados y la rendición de cuentas hacia la ciudadanía. El uso de esta información puedeaumentar la calidad y asequibilidad de los servicios de salud7, reducir los errores médicos y las inequidades en salud, hacer seguimiento y vigilancia de productos (fármacos y dispositivos o
Info
OPINIÓN: La información de salud: motor de cambio de los sistemas sanitarios
47
implantes médicos) de reciente introducción, detectar interacciones y efectos adversos que losestudios clínicos habituales no hayan puesto de manifiesto, examinar posibles consecuencias tardías de intervenciones médicas, desarrollar estudios de efectividad comparada, ampliar el conocimiento sobre las enfermedades minoritarias y, en definitiva, mejorar la salud de la población y su bienestar.
Cabe tener en cuenta que no todo son ventajas en la reutilización de los datos sanitarios; también conlleva algunos riesgos que hay que mitigar. Los principales son los que pueden afectar a la privacidad de las personas y al uso malicioso que se podría hacer de estos datos. Por un lado, para evitar que se pueda afectar a la privacidad, existen técnicas como la desidentificación o la anonimización de los datos, que van mucho más allá de quitar el nombre y apellidos de las personas. Es equívoco hablar de una anonimización ilusoria: el riesgo de reidentificaciónes una cuestión de probabilidades y aunque el riesgo nunca es cero, sí se puede hacer extremadamente bajo8.

Por otra parte, igual que ocurre en los estudios clínicos, cualquier proyecto de investigación que implique la reutilización de datos sanitarios debe contar con el dictamen favorable de un Comité Ético y de Investigación Clínica. Son estos comités los que mejor pueden ponderar los beneficios sociales de la investigación y los riesgos individuales de la misma. Otro riesgo que podría afectar a la utilización de los datos sería el peligro de caer en un excesivo dato-centrismo; es decir, la creencia de que en los datos se encuentran todas las soluciones y que se puede prescindir del uso de mecanismos más imperfectos para dar respuesta a los estudios, como los valores o la experiencia. Estos aspectos son especialmente importantes en una sociedad que a menudo piensa que todas las soluciones son computables y se encuentran en un servidor.
En este contexto, la iniciativa liderada por AQuAS quiere ser la ventanilla única de acceso a los datos anonimizados del sistema sanitario catalán que permita ofrecer las máximas garantías de seguridad. Para ello, se contempla la aplicación de medidas de seguridad equivalentes a las que se emplean cuando se trata de datos personales (aunque se trate de datos anonimizados que requieren niveles inferiores)
48

OPINIÓN: La información de salud: motor de cambio de los sistemas sanitarios
y la realización de auditorías para asegurar el correcto funcionamiento y cumplimiento de estas medidas implementadas. Asimismo, en cuanto a los aspectos éticos y de privacidad del proyecto, el Comité de Bioética de Cataluña (CBC) ha manifestado la garantía de respeto a los
49
principios éticos y el cumplimiento de los aspectos relacionados con la custodia y seguridad de los datos en la implementación de este proyecto. El CBC ha concluido que esta iniciativa es una oportunidad para mejorar la calidad y la sostenibilidad del sistema público de salud, que
requiere la contribución anónima y solidaria de los ciudadanos, que son los que lo sostienen y se benefician.
Iniciativas como la descrita permiten la implicación de la Administración, las universidades y los centros de investigación aumentando la innovación, el conocimiento y la cohesión social. Así pues, sin renunciar a las máximas garantías que marcan la ley y los organismos de control respecto a la seguridad, la confidencialidad y la privacidad de los datos, ¿estamos dispuestos a renunciar a los beneficios que la reutilización de los datos puede proporcionar a la investigación, la innovación y la mejora de la salud de la población?.

Referencias
OPINIÓN: La información de salud: motor de cambio de los sistemas sanitarios
5 VISC+: més valor a la informació de salut de Catalunya [pàgina a Internet]. Barcelona: Agènciade Qualitat i Avaluació Sanitàries (AQuAS). Generalitat de Catalunya. Disponible a: http://aquas.gencat.cat/ca/projectes/visc/
6 Horizon 2020. The EU Framework Programme forResearch and Innovation. European Commission. Disponible a: https://ec.europa.eu/programmes/horizon2020/
7 Murdoch TB, Detsky AS. The inevitable applicationof Big Data to health care. JAMA. 2013;309(13):1351-2.
8 Statement on Statement of the WP29 on theimpact of the development of Big Data on theprotection of individuals with regard to theprocessing of their personal data in the EU. Belgium(Brussels): European Commission; 2014. Disponible a: http://ec.europa.eu/justice/data-protection/article-29/documentation/opinion-recommendation/files/2014/wp221_en.pdf
1 Destacats investigadors catalans donen suporta la reutilització de les dades anonimitzades en salut per a promoure la recerca [nota de premsa]. 04/06/2015 [citat juny 2015]. Disponible a: http://salutweb.gencat.cat/ca/nota-premsa/?id=283463
2 Jensen PB, Jensen LJ, Brunak S. Miningelectronic health records: towards betterresearch applications and clinical care. Nat RevGenet. 2012;13(6):395-405
3 Sortsø C, Thygesen LC, Brønnum-Hansen H. Database on Danish population-based registersfor public health and welfare research. Scand J Public Health. 2011;39(7 Suppl):17-9.
4 The Clinical Practice Research Datalink (CPRD) [pàgina a Internet]. London (United Kingdom): National Institute for Health Research (NIHR). National Health Service (NHS). Disponible a:http://www.cprd.com/intro.asp
50

Farmacia y Big DataOPINIÓN
OPINIÓN: Farmacia y Big Data
Definir patrones de comportamiento en salud, elaborar modelos predictivos, reducir riesgos potenciales asociados a la medicación; reforzar la práctica farmacéutica basada en la evidencia, revolucionar la investigación en
11
“La Farmacia está preparada, capacitada y dispuesta para la revolución del Big Data”
Jesús Aguilar Santamaria
Presidente del Consejo General de Colegios Farmacéuticos
51
Farmacia Asistencial, así como la prestación de Servicios Profesionales Farmacéuticos personalizados, ajustado a las necesidades de cada paciente y en tiempo real, son algunas de las enormes potencialidades del Big Data aplicado a la Farmacia.

OPINIÓN: Farmacia y Big Data
Cada día acceden más de 2 millones de personas a la Red Asistencial de 21.854 farmacias españolas en busca de asesoramiento y asistencia farmacéutica. Cada mes se dispensan en la Farmacia comunitaria cerca de 70 millones de recetas prescritas por los facultativos, de las cuales más del 80% se registra y realiza electrónicamente. Y cada año, los farmacéuticos realizan más de 182 millones de actuaciones sanitarias. Es evidente que la Farmacia dispone de un elevado nivel de información y cuenta con experiencia en el manejo de datos en torno a la Salud y también de la medicación del paciente. Una información, no olvidemos, que tiene la
52
consideración de sensible y especial protección; y cuyo tratamiento ha de ofrecer siempre las máximas garantías de confidencialidad, seguridad, consentimiento informado y privacidad. En este campo, el farmacéutico y la farmacia han contado con el apoyo de la Organización Farmacéutica Colegial -Colegios, Consejos Autonómicos y Consejo General- y prueba de ello son el sistema de facturación, la implantación de la Receta Electrónica o la reciente puesta en marcha del Centro de Información sobre el Suministro de Medicamentos (CISMED) destinado a detectar en tiempo real situaciones generalizadas de suministro irregular de fármacos.

OPINIÓN: Farmacia y Big Data
Ahora bien, el Big Data es un nuevo salto cualitativo y la Farmacia ha de ser consciente de lo que puede implicar: debe conocer sus potencialidades y comprender su funcionamiento para adoptar aquellos usos beneficiosos que contribuyan a mejorar la calidad asistencial de la prestación farmacéutica; pero también para poner freno y limitaciones a aquellos otros usos que puedan vulnerar los derechos fundamentales de los pacientes. McKinsey Global Instituteidentifica tres características del Big Data frente a la gestión tradicional de datos: volumen de datos estructurados y no estructurados, variedad de las fuentes y velocidad. Las denominadas tres uves, a las que el Instituto Tecnológico de Massachusetts añade una
Volumen de datos estructurados y no estructurados
Variedad de las fuentes
Velocidad
Valor obtenido de los datos
UVES:Las 3 + 1
53
cuarta uve: la del valor obtenido de los datos, es decir, su utilidad.No hay que imaginar mucho qué ventajas tendría para la asistencia sanitaria la aplicación de estas características del Big Data a millones de historias clínicas anonimizadas, a las dispensaciones de medicamentos y productos sanitarios realizadas, a la notificación de reacciones adversas, a la monitorización online de parámetros básicos de salud —índice de masa corporal, presión arterial, ritmo cardíaco, colesterol, glucosa…—, al seguimiento de las aplicaciones de salud instaladas en dispositivos móviles, o al conocimiento generado en comunidades virtuales de pacientes, entre otras muchas fuentes de información.

OPINIÓN: Farmacia y Big Data
Una minería de datos puesta al servicio de los pacientes y del sistema sanitario —con las máximas garantías de protección y confidencialidad de los datos— que supondría una auténtica revolución. Se avanzaría en el ámbito de la farmacoepidemiología, en la respuesta de los tratamientos farmacológicos según perfiles genéticos y/o estilos de vida; en la prevención y predicción de riesgos y reacciones adversas de los medicamentos; en la mejora de la adherencia a los tratamientos; y en consecuencia, un incremento exponencial de losresultados en salud.
Una revolución del Big Data en toda su extensión porque supondría, entre otros muchos aspectos, que hemos superado barreras y recelos actuales a la hora de compartir información y conocimiento entre profesionales sanitarios, trabajando de forma colaborativa, aprovechando sinergias y situando al paciente en el verdadero centro de la atención sanitaria.
La Farmacia es puerta de entrada y salida del paciente del Sistema Sanitario. La Farmacia es una importante fuente receptora y generadora de información. La Farmacia conoce el dato, sabe gestionarlo con responsabilidad y garantías de seguridad para el paciente y tiene experiencia en aportar conocimiento fruto de su análisis. Por lo que si la pregunta es averiguar si la Farmacia está preparada, capacitada y dispuesta para la revolución del Big Data, la respuesta es afirmativa.
54

ENTREVISTA12
ENTREVISTA: “El volumen de información es crítico para el desarrollo de productos”
Federico Plaza
Director de Government Affairs en Roche Pharmaceuticals.
55
“El volumen de información es crítico para el desarrollo de productos”

P: ¿Cuál es el impacto del Big Data en la industria Farmacéutica?
R: El impacto es muy grande, sobre todo de cara a las estrategias. Está presente desde que se produce el descubrimiento hasta la investigación básica y desarrollo de productos -gestionar información de millones de datos para centrar los candidatos a medicamentos, indicaciones que se han de investigar o el perfil de uso...-. Todo ese volumen de información es crítico en este momento para el desarrollo de productos. Luego hay otra parte, que es el uso del Big Data ya en pacientes reales, en la vida real, que en este caso también es crítico pero se ha avanzado bastante menos.
ENTREVISTA: “El volumen de información es crítico para el desarrollo de productos”
56
P: ¿Por qué se ha avanzado menos?
R: Se ha avanzado bastante menos porque los sistemas sanitarios todavía no están suficientemente evolucionados.
En toda la información que gestiona el sistema y que está informatizada a través, por ejemplo, de la historia clínica digital, todavía no se han definido estándares para que sea normalizada, agregable y se pueda utilizar para gestionar el uso de los medicamentos o para gestionar la calidad asistencial. Todavía no se ha dado el paso de transformar esa información bruta -que sí Çse tiene- en información inteligente o elaborada que es la que está pendiente de esa normalización.
P: ¿Quién tiene que dar ese paso?
R: Ese paso lo tiene que dar evidentemente el sistema sanitario pero en conexión con los stakeholders que tienen algo que aportar. Esa información no sólo sirve para conocer mejor en la vida real cómo se utilizan los medicamentos o mejorar la pauta de uso para que sea más eficiente, esa información también es útil para la gestión en general de una patología o para conocer la adherencia, entre otras muchas más cosas.

ENTREVISTA: “El volumen de información es crítico para el desarrollo de productos”
57
P: ¿Cuál sería su utilidad en el plano epidemiológico?
R: El Big Data es una fuente brutal desde el punto de vista epidemiológico. Cuando se desarrolla una nueva indicación los datos epidemiológicos son realmente útiles, sobre todo, cuando se avanza en necesidades que no están cubiertas todavía o enfermedades que aún no tienen tratamiento. El Big Data permite tener información epidemiológica de la vida real, conocer mejor el perfil de los pacientesy rompe la falta de información que hay hoy entre los productos que salen al mercado que vienen con toda la información de los estudios clínicos y los productos que llevan ya tiempo en el mercado, en los que que no hay ninguna información adicional y estructurada de cómo se utilizan.
P: ¿Cuáles son los planes de Roche en el campo Big Data?
R: En el plano más local, en España, tenemos claro que hay que orientar toda esta información de datos en vida real para gestionar mejor cómo se utilizan los productos. También para intentar avanzar en el pago de los medicamentos por indicaciones y no sólo simplemente por producto en sí, porque cada vez es más frecuente que un producto tenga varias o muchas indicaciones; y no todas tienen el mismo valor. Hay que intentar avanzar en el pago basado en el valor. Esto genera, por un lado, confianza en los sistemas sanitarios y, por otro, da la tranquilidad que se están utilizando correctamente los recursos.

P: ¿Qué supone tener datos en la vida real para la industria?
R: Muchísimas posibilidades. Primero conocer en la práctica el gap, la diferencia que hay entre la eficacia - que es lo que se mide en los estudios clínicos- y la efectividad - lo que pasa en la vida real-. Ver las causas de por qué se produce ese gap, ver cómo se puede corregir, pues a veces es simplemente por la pauta de uso de los productos; también ver si pueden detectar necesidades no cubiertas y orientar nuevas vías de investigación. Las aplicaciones son enormes para muchos temas pero no son singulares para la industria porque a la Administración también le interesa buscar información adicional de los productos que
ENTREVISTA: “El volumen de información es crítico para el desarrollo de productos”
58
están en la vida real para, por ejemplo, propiciar más adherencia. También le sirve para comparar entre diferentes áreas u hospitales de cara a optimizar resultados. No podemos poner una barrera entre lo que le interesa a la industria y lo que le interesa al resto del sistema.
P: ¿Cómo influye en el dato de coste-eficacia?
R: Influye muchísimo. El dato de coste-eficacia cuando se autoriza un producto es todavía teórico, basado en un estudio clínico -que se ha hecho con una muestra que es lógicamente sólida, representativa de pacientes-pero “en realidad” el coste-eficacia se tiene que medir en la vida real.
No se debe medir coste-eficacia sino coste-efectividad. La efectividad se produce cuando ya tienes pacientes en la vida real y no se corresponden todos con los pacientes de los estudios clínicos, que tienen pluripatología. Eso nos va a dar mucha más información de coste-efectividad y, sobre todo, nos lo va a dar por indicación, con lo cual nos permitirá financiar cada indicación en función de los resultados en salud que suponga.

P: ¿Les preocupa la privacidad de los pacientes?
R: Pensemos que cuando hablamos de información es información anonimizada, siempre es propiedad de los sistemas sanitarios y no tiene que salir del sistema sanitario. Una vez que se quitan los datos personales que están protegidos, esa información completamente anonimizada no tiene ningún tipo de problema en cuanto a protección de datos y es la que se tiene que utilizar. Jamás se emplearán para estos fines datos individuales de pacientes con nombres y apellidos.
ENTREVISTA: “El volumen de información es crítico para el desarrollo de productos”
59
P: ¿Cuál es el próximo reto de Roche?
R: En España el reto que tenemos -ya está recogido en los borradores de la nueva normativa de precios y financiación de medicamentos-es que en las patologías relevantes cuando se produzca un medicamento exista un registro de pacientes. De tal manera que se conozca el número de pacientes que tiene la patología, el número de pacientes que utiliza un determinado medicamento -no la identidad si no el número-para a partir de ahí empezar a medir respuestas de resultados en salud.
Esto es lo que tiene que dar lugar en un plazo que no sea muy largo -ya se está haciendo en otros países como Italia- a empezar a pagar los medicamentos en función del valor que aportan, en función de los resultados en salud más que en función de los miligramos de sustancia, de principio activo. El Biga Data es importantísimo para conseguir hacer sostenibles nuevos productos que tienen precios elevados, pues su desarrollo es costoso y van orientados a pocos pacientes. Si conseguimos conocer cuántos pacientes utilizan el producto en cada indicación y los resultados que tiene en salud, podemos conseguir que los sistemas sanitarios apliquen los recursos para financiar estos productos de forma más exigente. Y esto es un reto a corto, cortísimo plazo.

OPINIÓN13
Lo que aporta el Big Data a la industria farmacéutica
OPINIÓN: Lo que aporta el Big Data a la industria farmacéutica
La implementación de las Tecnologías de la Información y las Comunicaciones (TIC) en el ámbito sanitario, con la que se introdujo la historia clínica electrónica y la receta electrónica, junto con el desarrollo de nuevos sistemas
“Los resultados de la investigación epidemiológica realizada en bases de datos poblacionales son una pieza clave para la toma de decisiones”
Teresa Hernando
Real World Data Manager de Janssen
60
de recogida de información utilizados por pacientes, cuidadores y profesional sanitario (apps, dispositivos wearables, redes sociales…), ha supuesto la aparición de fuentes masivas de datos de salud.

OPINIÓN: Lo que aporta el Big Data a la industria farmacéutica
Esta irrupción masiva de datos médicos se ha producido en dos niveles. El primero de ellos está constituido por bases de datos de gran tamaño, como la historia clínica electrónica, la receta electrónica o los registros de enfermedades. El segundo nivel, lo que se conoce como Big Data,implica una serie de características que van más
2 NIVELES:
• historia clínica electrónica
• receta electrónica• registros de
enfermedades
1º NIVEL: Bases de datos de gran tamaño
• Las tres “v”(volumen, velocidad y variación)
2º NIVEL:‘Big-Data’
61
allá del tamaño de la base de datos y que se resumen con las, cada vez más conocidas, tres “v”: volumen (múltiples dimensiones de datos); velocidad (datos en casi tiempo real; análisis en streaming); variación (datos estructurados y datos no estructurados; diferentes formatos de datos procedentes de distintas fuentes de datos).

OPINIÓN: Lo que aporta el Big Data a la industria farmacéutica
investigación clínica de tipo observacional. La eficacia y seguridad de los medicamentos se evalúa inicialmente en muestras restringidas de pacientes y en condiciones
experimentales (ensayos clínicos) para obtener la aprobación de las autoridades sanitarias. No obstante, es en el ámbito de la práctica clínica donde se puede evaluar, por medio de estudios observacionales, el valor que los medicamentos aportan en la “vida real”. Este valor está condicionado por aspectos que son propios de la vida real (mayor espectro de población expuesta, adherencia al tratamiento, exposición a otros tratamientos, hábitos de vida de los pacientes…) y que están mitigados en la fase previa de experimentación. En JanssenEspaña, como parte de una iniciativa global de la compañía, se ha constituido un área específica de ‘Real WorldEvidence’ cuyo principal objetivo
La digitalización de los datos médicos junto con la disponibilidad de fuentes de información en tiempo real abre un nuevo marco de posibilidades para la
62

OPINIÓN: Lo que aporta el Big Data a la industria farmacéutica
63
es impulsar la investigación clínica de tipo observacional en este escenario de bases de datos de salud de gran tamaño que, en el medio-largo plazo, alcanzará dimensiones de Big Data en su totalidad. En nuestra apuesta por la integración de la investigación fármaco-epidemiológica en el nuevo ecosistema de datos, estamos trabajando en la identificación y desarrollo de nuevas capacidades metodológicas y analíticas que van a más allá de las técnicas clásicas utilizadas en bases de datos relacionales. Con ese propósito hemos
iniciado una línea de trabajo cuyo pilar común es proporcionar soluciones que aporten herramientas innovadoras que mejoren los resultados en salud y con ello la atención sanitaria y el cuidado de los pacientes (app, wearables…).
Se trata, por tanto, de contribuir al avance de la investigación clínica de la mano del desarrollo de nuevos sistemas de información. Los resultados de la investigación epidemiológica realizada en bases de datos poblacionales
son una pieza clave para la toma de decisiones eficientes, lo cual, por otro lado, supone el retorno de la inversión realizada en el desarrollo de estas grandes bases de datos. En el ámbito concreto de la fármaco-epidemiología, mejorar el conocimiento de lo que aportan realmente los diferentes tratamientos farmacológicos en la práctica clínica redundará en una optimización de la gestión de los recursos sanitarios y posibilitará un cambio progresivo hacia un modelo de atención sanitaria centrado en el paciente.

ENTREVISTA14
“Para el farmacéutico es clave conocer la situación de las ventas de productos”
ENTREVISTA: “Para el farmacéutico es clave conocer la situación de las ventas de productos”
Carlos Mocho
Director europeo de hmR
64

P: ¿Cuáles son las posibilidades del Big Data en el mercado farmacéutico?
R: Las posibilidades del Big Data en el mundo sanitario son inmensas. En concreto, en el mercado farmacéutico, un mundo muy dinámico y cambiante y muy influenciado por las medidas administrativas y regulatorias que se van adoptando, la fuerza de los datos es muy importante. No obstante, tan importante es contar con muchos datos relevantes y de confianza como que éstos sean convertidos rápidamente en información útil y clara que aporte conocimiento a los stakeholders del mercado.
ENTREVISTA: “Para el farmacéutico es clave conocer la situación de las ventas de productos”
65
P: ¿Cómo ayuda el Big Data en la comercialización de fármacos?
R: Es fundamental, al igual que en el resto de áreas de negocio y/o actividades de las compañías del sector. Una compañía farmacéutica que se dispone a comercializar un nuevo producto debe conocer las tendencias del mercado tanto en el ámbito macro, en el sentido de comportamiento y ventas de sus competidores, como en el ámbito micro desde una perspectiva territorial de los mercados. Este conocimiento es necesario como soporte directo en la toma de decisiones ante todo el ciclo de vida de un fármaco, independientemente del tipo de producto que se trate, así como en la definición estratégica de los planes de marketing y ventas.

P: ¿Cómo tratan los datos de salud?
R: hmR cuenta con una gran estructura de profesionales altamente especializados que nos garantiza total confianza en la información generada, desde el Área de Fuentes de Datos, a los de Desarrollo, Business Intelligence, Producción y Control de Calidad, todos con el soporte de la tecnología más innovadora en este apartado.
P: ¿Y las herramientas que se utilizan para garantizar la seguridad de esos datos?
R: En nuestra actividad y en nuestra filosofía empresarial, la seguridad es un imperativo y, como tal, debe estar garantizada, algo que cuidamos internamente en todos nuestros procesos. Además, realizamos auditorías externas con compañías expertas de reconocido prestigio en este ámbito.
“LA SEGURIDAD DEBE ESTAR GARANTIZADA”
ENTREVISTA: “Para el farmacéutico es clave conocer la situación de las ventas de productos”
66
P: Además de a la industria farmacéutica, ¿Qué posibilidades ofrece el Big Data a otros agentes del sector como las oficinas de farmacia?
R: Con el sistema solidario de oficinas de farmacia que existe en España, por el que contamos con farmacias en todo el territorio y todos los productos llegan a todas las oficinas, la aportación de la información y del Big Data al sector salud y sanitario puede ser inmensa, no solo para la industria farmacéutica y desde la perspectiva de mercado farmacéutico, sino desde todos los puntos de vista y para todos los agentes. Dicha aportación se entiende en el marco del papel que ha adquirido y debe adquirir la atención farmacéutica en el ámbito de la prevención sanitaria, seguimiento de pacientes, educación sanitaria y salud pública. En este apartado, los datos de las oficinas de farmacia, por ejemplo, sobre consumo de antigripales, son fundamentales para conocer en tiempo real dónde se está extendiendo una infección vírica, como la gripe, y a qué ritmo, y poder adaptar la respuesta y garantizar el stock de vacunas suficiente en aquellos lugares que lo necesiten.

Además, se puede conocer cómo influyen las medidas regulatorias en el consumo de medicamentos y si éstas son rentables.
Desde el punto de vista empresarial, para el farmacéutico es clave conocer la situación de las ventas de productos farmacéuticos en su ámbito territorial, la evolución de sus propias ventas y el comparativo con otras oficinas de farmacia, con el fin de poder gestionar y reorientar, en caso necesario, su actividad empresarial. Igualmente, el seguimiento que puede hacer en cada paciente, además de ser fundamental en la atención farmacéutica, aporta información muy valiosa para fidelizar a sus clientes.
y evolución de la venta media de las farmacias de su región, comunidad autónoma y a nivel nacional. Además, hace posible agrupar los datos por ventas totales y por segmentos de su interés, así como respecto al mes en curso o al acumulado del año. Se trata de una herramienta potente y versátil con diferentes niveles de información, desde una visión muy gráfica de la evolución de ventas a alto nivel, hasta el más detallado de los análisis. Un ejemplo muy claro de cómo convertir los datos en conocimiento.
ENTREVISTA: “Para el farmacéutico es clave conocer la situación de las ventas de productos”
67
P: ¿Tienen alguna herramienta especial?
P: hmR pone a disposición de las farmacias con las que colabora una herramienta de software, llamada ‘Pharmacy Watch’, que tiene como objetivo ayudar a los farmacéuticos en la tarea de la gestión de sus oficinas de farmacia. ‘PharmacyWatch’ permite a estos profesionales, de una forma muy intuitiva, comparar el comportamiento

P: Hablando de los planes de Big Data Salud en general, ¿cómo lo ve para los usuarios más pequeños?
R: El Big Data se utiliza cada vez más en el campo de la salud y la tendencia es emplearlo mejor, sobre todo por parte de las organizaciones sanitarias de mayor tamaño, tales como las compañías farmacéuticas, los hospitales, etcétera. Sin embargo, su uso se está generalizando, de forma que otros agentes más pequeños, como las oficinas de farmacia, harán un uso cada vez más relevante de los datos. También lo utilizarán los pacientes, como eje central del Sistema Sanitario, si tienen la información necesaria para poder elegir un servicio o producto de salud en vez de otro dependiendo de la tasa de éxito de cada uno.
ENTREVISTA: “Para el farmacéutico es clave conocer la situación de las ventas de productos”
68

IBM Watson/23andme-Google/PatientsLikeMe
PROYECTOS
PROYECTOS: IBM Watson/23andme-Google/PatientsLikeMe
IBM Watson Health. Ese el nombre de un superordenador capaz de procesar Big Data mediante un sistema cognitivo. Desde Boston y Nueva York, 2.000 profesionales entre consultores, médicos, científicos, desarrolladores e investigadores, trabajan en el desarrollo de las capacidades de IBM Watson Health. La compañía estadounidense se ha aliado conApple, Johnson & Johnson y Medtronic y con dos start-ups; Exploris, una spin-off de la Clínica Cleveland cuyos datos en 50 millones de pacientes se utilizan para detectar patrones de enfermedades, tratamientos y resultados sanitarios; y Phytel, de Dallas, fabricante de un software que gestiona la atención al paciente y reduce el ratio de readmisiones en hospitales, para dar este paso de gigante en el mundo de los datos. Simplificando mucho, el plan de IBM es que la tecnología Watson sirva como un servicio en cloud
15
Watson IBM - Sistema para la computación cognitiva
69

que permita a los hospitales, médicos, aseguradoras e incluso potenciales pacientes a aprovechar su vasto almacenamiento de datos. IBM ya ha utilizado la tecnología Watson en proyectos individuales con centros médicos líderes en EE. UU. , como el Centro Oncológico Memorial Sloan Kettering de Nueva York, la Universidad de Texas, el Centro Oncológico MD Anderson de Houston y la Clínica Cleveland. Pero con la creación de la unidad IBM Watson Health
23andme /Google
Financiada -entre otras empresas-, por Google,23andme ofrece desde su nacimiento, en 2006, test genómicos al alcance de cualquiera. 23andMe realiza pruebas genéticas a través de una muestra de saliva y asegura que un 80 % de los clientes acepta que sus datos se utilicen de forma anónima en proyectos de investigación. La empresa, que tiene una base inmensa de datos con el ADN de sus clientes, utiliza la información anónima de 900.000 personas también para el desarrollo de nuevos fármacos
PROYECTOS: IBM Watson/23andme-Google/PatientsLikeMe
70
se busca aplicar esa tecnología a toda la Sanidad. Los errores médicos son la tercera causa de muerte en Estados Unidos y Watson escapaz de leer millones de artículos médicos. Un sistema cognitivo que analiza los datos y que tiene la capacidad de encontrar conexiones en todo el conocimiento digital disponible. Watson aprende de los seres humanos a través de un lenguaje natural y por medio de algoritmos se lo pregunta todo.

gracias a acuerdos con varias empresas farmacéuticas. Aunque se ha topado con el recelo de la Administración de Alimentos y Medicamentos de Estados Unidos (FDA), que pide que se informe de manera más clara a sus clientes, y sus test están prohibidos en varios países europeos, 23andme sigue creciendo y su último gran acuerdo ha sido la venta de 14.000 perfiles genéticos de enfermos de
PatientsLikeMe
"Todas las personas tenemos el derecho a tener una copia completa de nuestros datos de salud individual, sin demora, con un mínimo o ningún coste". Ese es el lema del fundador de PatientsLikeMe, Jamie Heywood que, después de ver como a su hermano se le diagnosticaba ELA, puso en marcha la plataforma donde miles de pacientes comparten sus datos clínicos. Heywood señala que decenas de miles de vidas se pierden cada año debido a que los datos de salud no fluyen libremente y ha logrado que en PatientsLikeMe compartan información más de 125.000 personas afectadas por enfermedades
Parkison o familiares a la empresa Genentech por 60 millones de dólares. La apuesta por el Big Data de Google es firme como lo demuestra su participación también en la startup Flatiron Healthque, gracias a una plataforma en la nube que analiza datos oncológicos en tiempo real,proporciona estadísticas detalladas para hospitales y centros de investigación.
PROYECTOS: IBM Watson/23andme-Google/PatientsLikeMe
71

graves e incurables como SIDA, cáncer, diabetes o ELA. Actualmente están representadas más de 1.000 enfermedades. Los pacientes pueden, desde la web, contar la evolución de los síntomas, qué efectos tienen los tratamientos (incluso los que toman de manera irregular, sin que se los recete un médico), los trucos y el avance de la enfermedad, indicando cómo influyen los medicamentos en su bienestar físico, mental y social; las hospitalizaciones que sufren,su peso o estado de ánimo. Una información que comparten todos. Gracias a la ingente cantidad de información que maneja, la web ofrece a sus usuarios, de manera gratuita, herramientas analíticas de gran potencia que antes sólo estaban al alcance de los investigadores. Otro de los impulsores y el cerebro de PatientsLikeMe es Paul Wicks, un joven neuropsiquiatra. En cuanto al modelo de negocio, la forma de financiar el proyecto es simple: la compañía vende datos agregados, anónimos y segmentados a las compañías farmacéuticas. Y al mismo tiempo ayudan a mejorar la calidad de vida de los pacientes y dan soporte a la investigación médica.
PROYECTOS: IBM Watson/23andme-Google/PatientsLikeMe
72

‘Wearables’ para monitorizar la salud
PÍLDORAS: Wearables para monitorizar la salud
Es el seguidor de salud más popular en el mundo, el último modelo registra localizaciones, frecuencias cardiacas, duración y calidad del sueño (cómo son los despertares y sueños inquietos), gasto de calorías, pasos y tramos de escaleras subidos.
16
‘Fitbit’
73
PÍLDORAS
Un número cada vez mayor de pequeños dispositivos electrónicos registran y comunican a sus usuarios información vital sobre su salud

Reloj Apple
74
‘Propeller Health’, GPS incorporado a un inhalador
Los sensores de localización miden el tiempo y el sitio de cada uso del inhalador. Este dispositivo -que encaja en cualquier inhalador ordinario- ayuda a los pacientes con asma a seguir la pista de la medicación y comparte la información con un médico. Propeller Health ha lanzado su proyecto en Louisville (EE. UU.), donde centenares de pacientes pueden ayudar a localizar “puntos calientes” en los que es difícil respirar. Basándose en los datos obtenidos, la compañía esperar hacer recomendaciones a los planificadores urbanos para aliviar los problemas.
Equipado con un sensor de frecuencia cardiaca y acelerómetro, el reloj tiene una aplicación que dibuja gráficas con información como los minutos que estamos de pie y las calorías que quemamos. Su aplicación Workoutproporciona información sobre
las actividades físicas más duras, como el running. Y una aplicación conectada del iphone comparte esa información con científicos por el bien de todos.
PÍLDORAS: Wearables para monitorizar la salud

Lentillas inteligentesde Google X
75
Google X: nanopartículaspara buscar cáncer
Un circuito electrónico del grosor de un cabello y un microchip de baja potencia unidos a una lentilla tradicional miden los niveles de glucosa de los usuarios analizando las lágrimas, y envían la información al teléfono móvil del paciente o a otro dispositivo.(Este proyecto está en fase de desarrollo).
Las nanopartículas entran en el cuerpo al ingerir una píldora y van por el torrente sanguíneo para engancharse a células anormales como las cancerosas. El paciente lleva un dispositivo que crea un campo magnético que permite trasladar esas partículas a un lugar donde puedan ser contadas.(Este proyecto está en fase de diseño).
PÍLDORAS: Wearables para monitorizar la salud

MINI DICCIONARIO
Análisis, gracias a las nuevas herramientas tecnológicas de Big Data, de grandes conjuntos de datos en el momento en el que se están generando.
17
Analíticas en tiempo real (Real time Big Data analytics):
76
MINI DICCIONARIO
Se generan como resultado de la extracción y análisis del conocimiento histórico que se encuentra en los datos masivos. Señalan posibles patrones, resultados o tendencias futuras.
Analíticas predictivas(Predictive Big Data analytics):

MINI DICCIONARIO
Posibilidad que ofrecen las nuevas herramientas tecnológicas de Big Data para analizar grandes conjuntos de datos de forma paralela al momento en el que se están generando.
Aprendizaje computacional automático (Automatic machine learning):
77
Conjunto de datos que, por su volumen y variedad y por la velocidad a la que necesitan ser procesados, supera las capacidades de los sistemas informáticos habituales. Asimismo el conjunto de tecnologías, técnicas y herramientas que hacen posible la recogida, procesamiento y análisis de volúmenes masivos de datos, y también la visualización de los resultados.
Big Data:
Big Data sanitario:
Almacenamiento y análisis de datos estructurados y no estructurados. Transformación de los datos en información sanitaria. Organiza de forma efectiva la información de los datos estructurados ya existentes (fichas personales de los pacientes, etc) aquellos que permanecen ocultos al sistema actual de almacenamiento y sólo existen de forma analógica en poder de los pacientes (recetas de papel, registros médicos o resultados de pruebas médicas).
La Interfaz de Programación de Aplicaciones es el punto de contacto a través del cual se puede acceder a una aplicación sin necesidad de conocer su funcionamiento, usando el lenguaje informático.
Expresar un dato relativo a entidades o personas eliminando la referencia a su identidad.
Anonimizar:
API (Application Programming Interface):

MINI DICCIONARIO
Características del Big Data. Volumen. Es decir, el tamaño de los conjuntos de datos que se genera. Velocidad (y frecuencia): los datos se quedan desfasados y pierden su valor rápidamente. Variedad: pueden proceder de diferentes fuentes:
“Cuatro V”:
78
sensores de calor, de cámaras, smartphones, de nuestros pagos, de los coches, de sistemas de navegación y GPS o de las redes sociales, entre otros. Valor: la mayoría de los datos llegan son incompletos, con campos que faltan o que son incorrectos, mide la utilidad de los datos. Dato: el dato es una representación simbólica (numérica, alfabética, algorítmica, etcétera.) de un atributo o variable cuantitativa o cualitativa. Los datos describen hechos empíricos, sucesos y entidades.
Datos estructurados:
Aquellos que están almacenados en una base de datos tradicional (fichas de hospitales).
Profesionales, con habilidades en matemáticas, estadística e ingeniería informática, capaces de extraer el máximo valor de los datos, cerrando la brecha entre las necesidades del negocio y las Tecnologías de la información.
También conocido como Inteligencia de Negocio. Conjunto de procesos en el que herramientas y estrategias se enfocan en la creación y administración de conocimientos.
Business Intelligence:
Científico de datos:
Datos no estructurados:
Aquellos datos que no están organizados bajo el Modelo de Datos Relacional, definido por Edgar Codd en 1970. Algunos ejemplos comunes de

MINI DICCIONARIO
Historia Clínica Electrónica: conjunto de documentos clínicos que detallan la información de cada ciudadano a lo largo del proceso asistencial sanitario.
HCE:
79
información no estructurada son los archivos de texto, imágenes, audio y video o redes sociales.
Esta palabra hace referencia a todas las gestiones de la asistencia sanitaria que se llevan a cabo mediante internet.
Ensayos clínicos controlados aleatorizados.
ECA:
eHealth: Minería de datos(data mining):
“Ciencia” para encontrar lo valioso entre la ingente cantidad de información que se almacena. Busca patrones de información significativos.
Campo de la inteligencia artificial y la lingüística que se ocupa de investigar aplicaciones relacionadas con lenguajes naturales como la comprensión de textos, la traducción automática, el resumen automático o la generación de textos.
Lenguaje natural (NLP):
Conjunto de elementos sobre el que estamos interesados en obtener conclusiones. También se denomina universo, que es el conjunto de elementos de referencia sobre el que se realizan las observaciones.
Población:

MINI DICCIONARIO
Real World Data (RWD) se ha definido como los datos que se recogen fuera de las restricciones controladas de los ensayos clínicos aleatorizados convencionales, con el fin de poder evaluar lo que realmente está sucediendo en la práctica clínica real. Entre los RWD, se incluyen estudios observacionales de registro, datos provenientes de historias clínicas electrónicas, encuestas de salud y ensayos clínicos pragmáticos.
80
Stakeholders:
Interlocutores de la empresa. Movimiento que incorpora la tecnologías para registrar todos los datos sobre aspectos de la vida diaria de una persona. En términos de inputs(alimentos que se consumen, la calidad del aire), estados (oxígeno en la sangre), y rendimiento (físico y mental).
Quantified self:
Selftracking:
Autorastreo o autoanálisis de la actividad o datos de uno mismo. Seguimiento de los niveles de actividad, como ciclos del sueño, glucosa, presión arterial, entre otros parámetros, gracias a aplicaciones y dispositivos tecnológicos.
Telemedicina, telesalud:
Procesos médicos que se hacen a distancia.
Wearables:
Dispositivos móviles para medir constantes vitales.
Real world data(datos del mundo real):

Informe elaborado por:
Con la colaboración de:
DICIEMBRE 2015