Embed Size (px)
Citation preview

Bioestadística Dra. Iris Ethel Rentería Solís

LAS CRÓNICAS DE
HISTORIAS Y NÚMEROS SOBRE EL PELIGRO

CONZCAN A NORM. ÉL ES BASTANTE PROMEDIO. ESTA ES SU VIDA:
NORM HA NACIDO. ¡ALTO RIESGO!Es más probable morir antes de cumplir un año que durante cualquier otro año hasta los 50.
Riesgo de muerte antes de 1 año= Riesgo de recorrer 30 000 millas en una motocicleta

INFANCIA
CAMINAR A LA ESCUELA Una preocupación para muchos padres. Sin embargo, el riesgo de muerte es menos de
1/365 del riesgo diario de un adulto. Los niños menores de 15 años tienen menos probabilidad
de morir en un accidente de tránsito que cualquier otro grupo de edad.

11 AÑOS
A la edad de 11 años el peligro no es una opción, es un juego con reglas…

ADOLESCENTE ¡NORM CONSIGUE UNA NOVIA!

ADOLESCENTE ¡NORM CONSIGUE UNA NOVIA!
SEXO
Las posibilidades de embarazo durante el sexo sin protección son de 15-30% por ciclo

ADULTO JOVEN
DROGAS
1 en 3 adultos han probado drogas ilegales a lo largo de su vida.

ADULTO JOVEN
DEPORTES EXTREMOSPor cada 25 personas que alcanzan la cumbre del Everest, 1 persona muere. Saltar en paracaídas es riesgoso, pero depende del sitio donde
se haga.
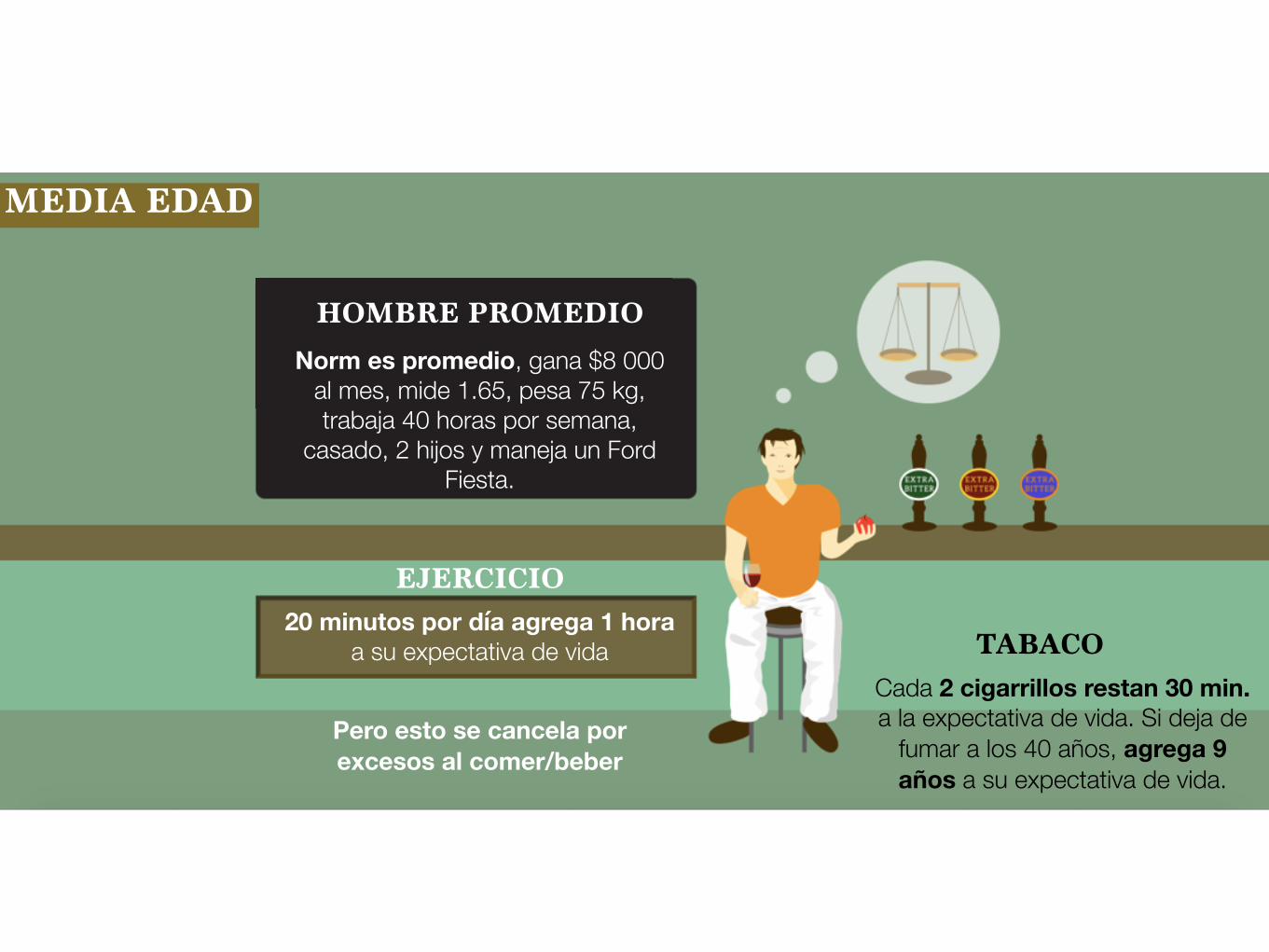
MEDIA EDAD
HOMBRE PROMEDIO
Norm es promedio, gana $8 000 al mes, mide 1.65, pesa 75 kg, trabaja 40 horas por semana,
casado, 2 hijos y maneja un Ford Fiesta.
TABACOCada 2 cigarrillos restan 30 min. a la expectativa de vida. Si deja de
fumar a los 40 años, agrega 9 años a su expectativa de vida.
20 minutos por día agrega 1 hora a su expectativa de vida
EJERCICIO
Pero esto se cancela por excesos al comer/beber

VEJEZEVENTOS VIOLENTOS
El riesgo de crimen violento para un mayor de 65 años es menos del 10% que para un adulto joven.
Ser aplastado por un asteroide es extremadamente improbable (una
vez en 77 000 000 de años)

MUERTE
CERTEZA
100% de riesgo de muerte. ¡Así que disfrute la vida mientras aún la tiene!

Las estadísticas forman parte de nuestra vida…

Pero si las estadísticas son la respuesta…
¿Cuál es la pregunta?

Estadística
• Ciencia que se encarga de recolectar, resumir y analizar datos de una población o muestra.
• Realizar inferencias y extraer conclusiones de la información recolectada.
Metodología de la investigación, bioestadística y bioinformática en ciencias médicas y de la salud García García JA. 2a edición. México: Mc Graw Hill 2014

Estadísticas
Que describen
Que explican o predicen
(Estadística descriptiva)
(Estadística inferencial)
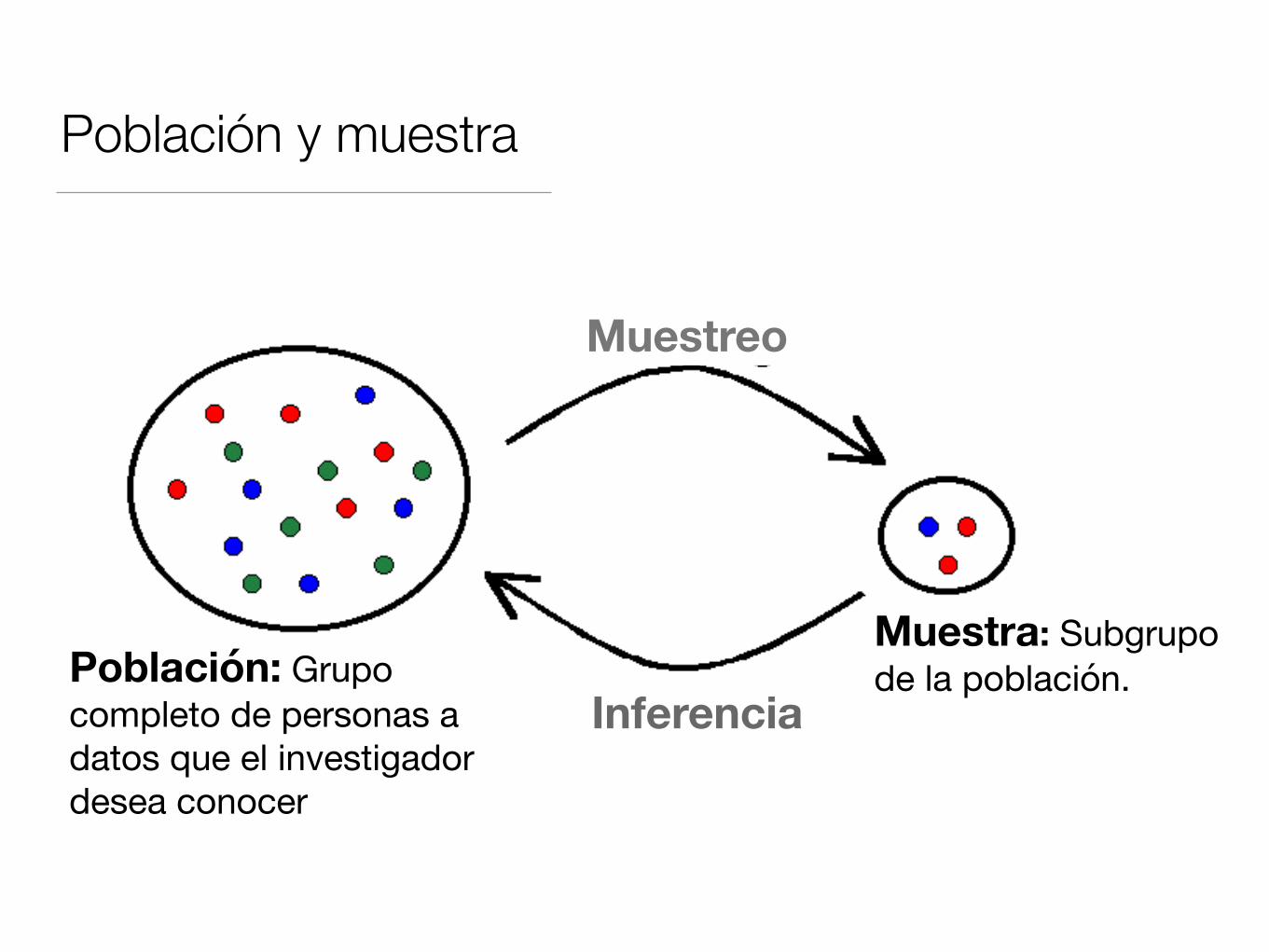
Población y muestra
Población: Grupo completo de personas a datos que el investigador desea conocer
Muestra: Subgrupo de la población.
Muestreo
Inferencia

Fuentes potenciales de error al estimar la distribución de una población usando muestra
Error de muestreo
Incluso cuando una muestra es seleccionada de forma aleatoria, siempre existe una variabilidad natural que no refleja precisamente el promedio de la población.
La forma de reducirlo es incrementando el tamaño de la muestra.
Muestra no representativa
Método inadecuado de
muestreo
Error en cuestionario o en
mediciones
Efectos conductuales

Sesgo de Selección
El investigador no ha seleccionada la muestra de forma aleatoria, sino con un
sesgo hacia característica(s) particular(es).
Ej. voluntarios, invitación telefónica.

Sesgo de Selección
Con una selección sesgada, las conclusiones serán erróneas y no se corrigen al aumentar el tamaño de la muestra.

Imprecisión vs. Sesgo (inexactitud)
Resultado preciso pero sesgado (inexacto)
El investigador seleccionó una muestra que tiene poca variación natural pero no representa a la población. (sesgo
de selección).

Imprecisión vs. Sesgo (inexactitud)
Resultado impreciso no sesgado
El investigador seleccionó una muestra aleatoria representativa pero hay una gran variación natural dentro de la
misma (error de muestreo).

Imprecisión vs. Sesgo (inexactitud)
Resultado impreciso e inexacto (sesgado)
Muestra aleatoria no representativa y con gran variación natural dentro de la misma (error de muestreo y sesgo
de selección).
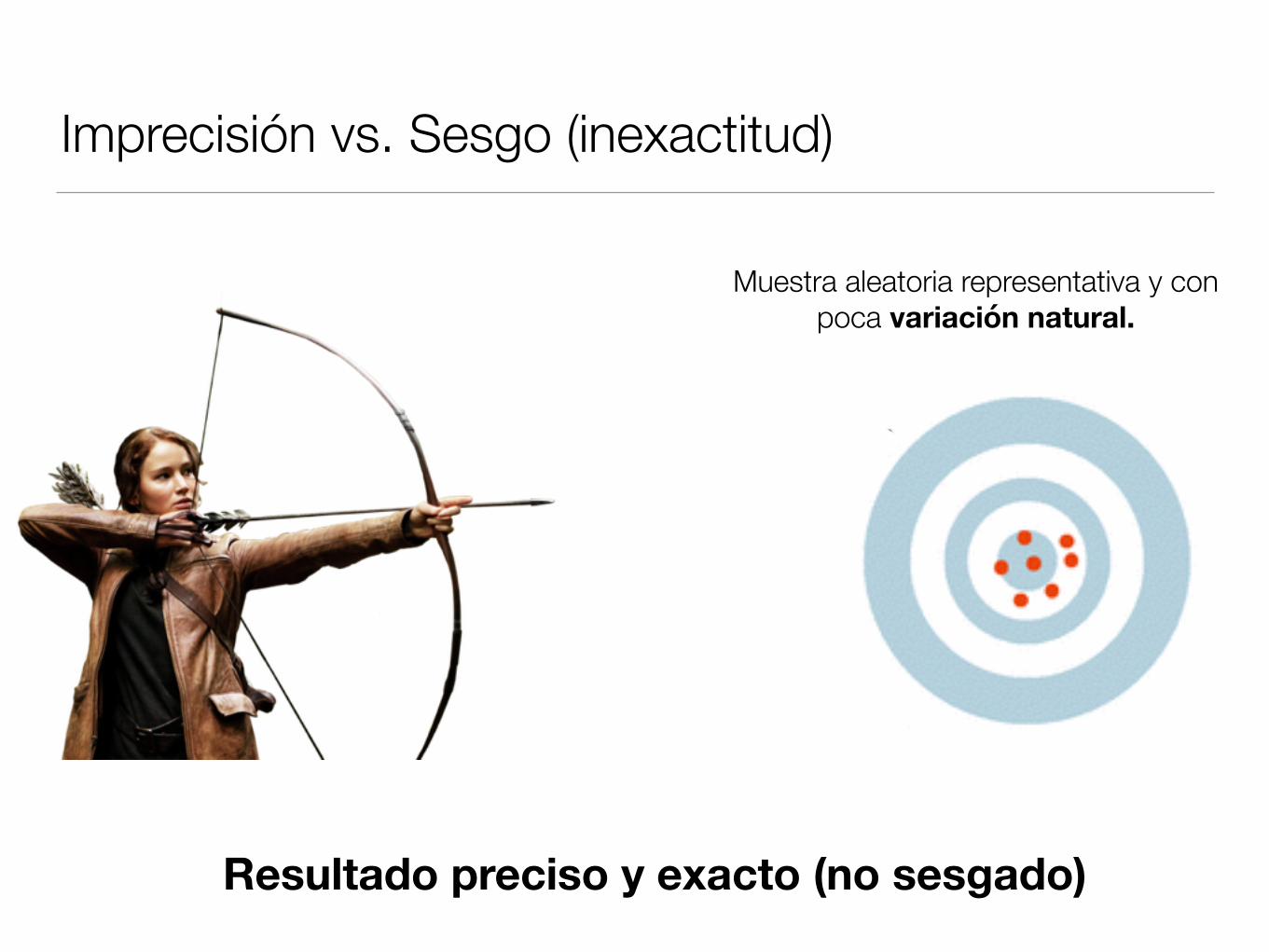
Imprecisión vs. Sesgo (inexactitud)
Resultado preciso y exacto (no sesgado)
Muestra aleatoria representativa y con poca variación natural.

Validez vs. Confiabilidad
Validez: Exactitud de un test o instrumento para obtener el resultado a estudiar.
Confiabilidad: Qué tan reproducible es un test.
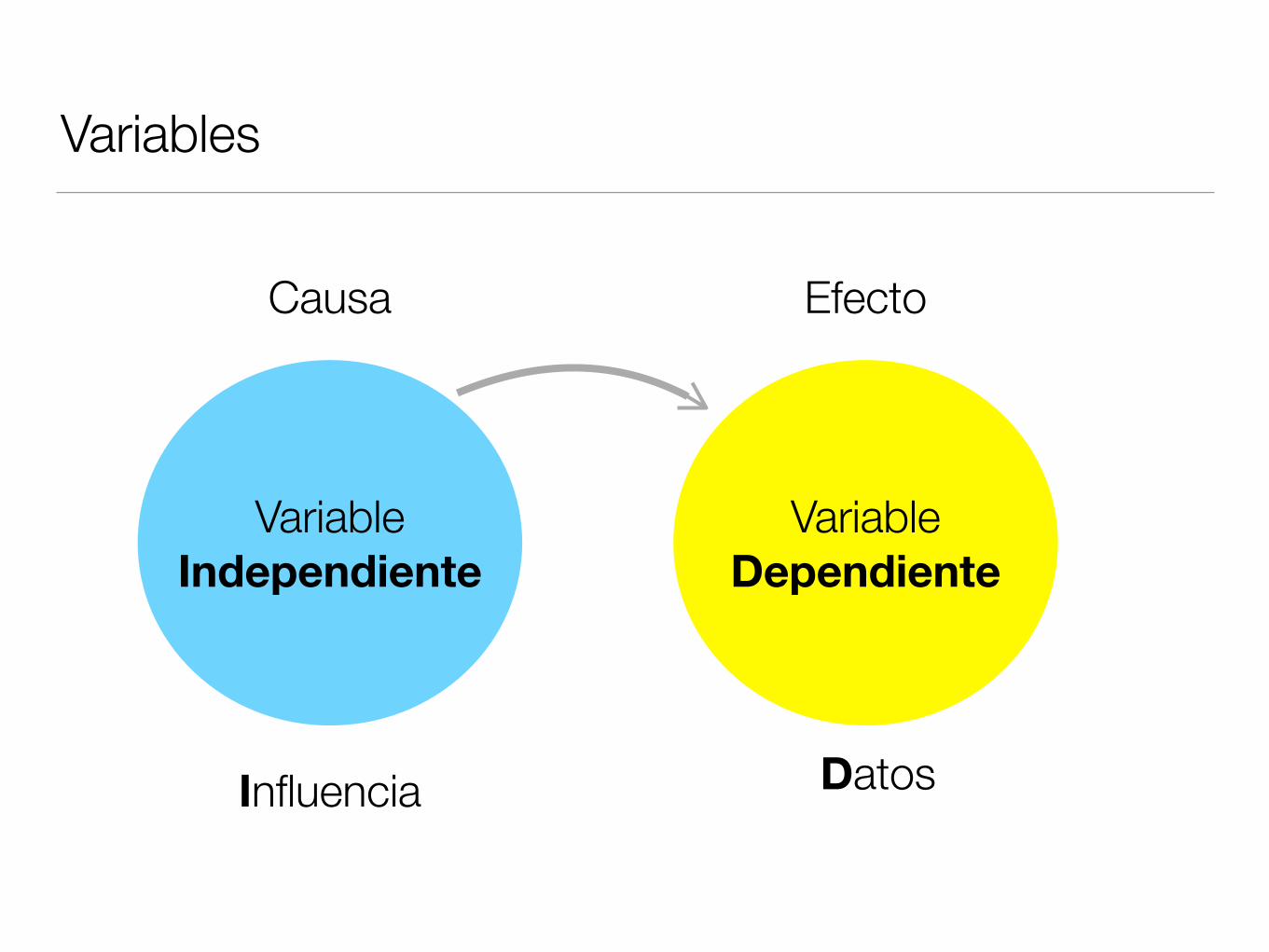
Variables
Variable Independiente
Variable Dependiente
Causa Efecto
Influencia Datos
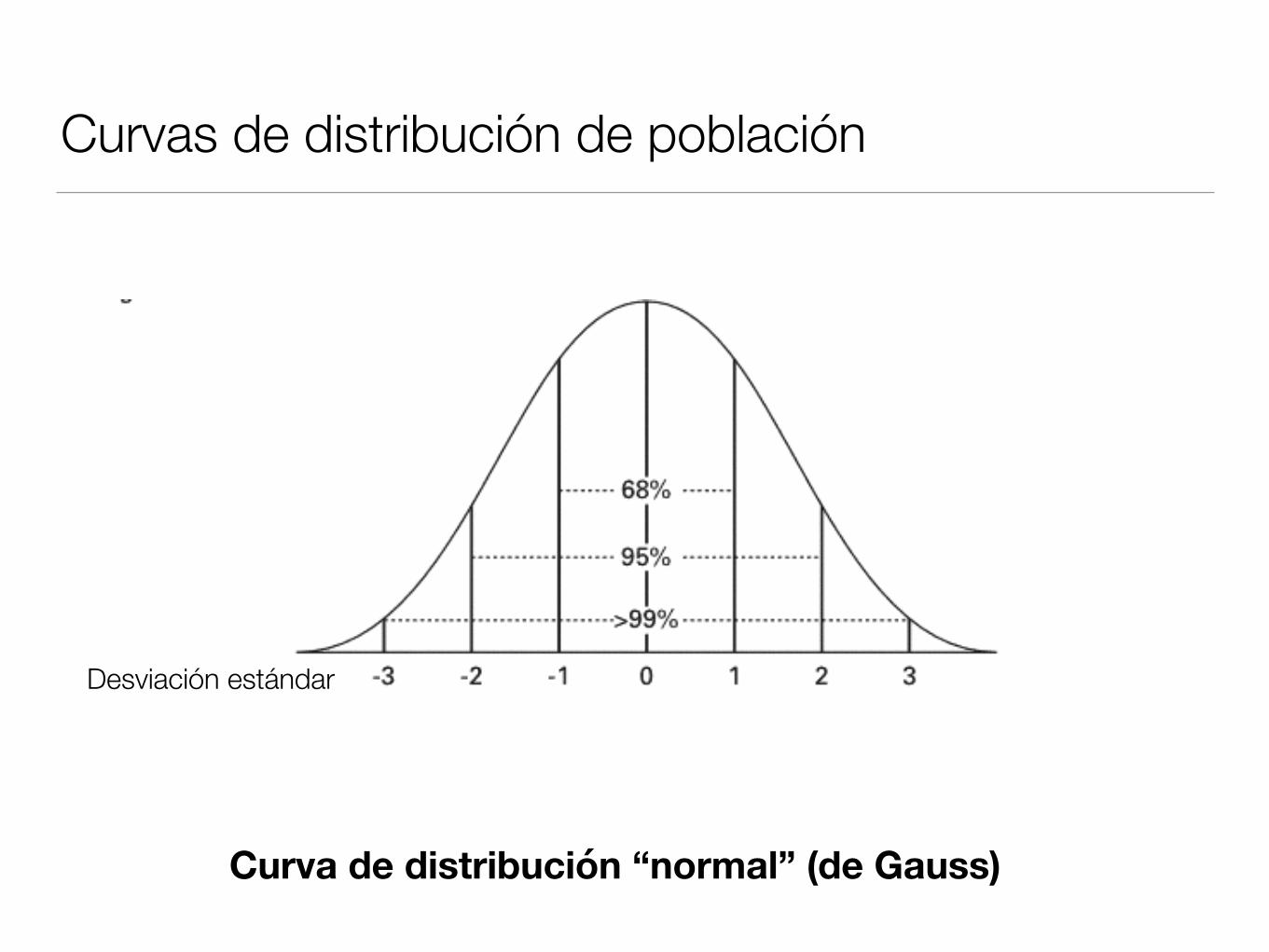
Curvas de distribución de población
Desviación estándar
Curva de distribución “normal” (de Gauss)

Curvas de distribución de población
Normal (simétrica)
Asimetría negativa
Asimetría positiva

Curvas de distribución de población
Asimetría positiva

Curvas de distribución de población
Asimetría negativa

Curvas de distribución de población
Curtosis: Grado de aplanamiento de la curva
Leptocúrtica Mesocúrtica (Normal)
Platicúrtica

Significancia Estadística vs. Significancia Clínica

Anormalidad Estadística vs. Anormalidad Clínica

Estadísticas que describen

Estadística descriptiva
• Se caracteriza por resumir y explorar la información.
• Presenta los datos de forma que sobresalga su estructura.
• Permite detectar las características más destacadas de la población o muestra.

Frecuencias y Porcentajes
Frecuencia: Número de veces que ocurre un evento. Porcentaje: Proporción o escala para comparar la frecuencia.
Un consultorio registró el número de fumadores entre sus pacientes con diabetes. Hicieron lo mismo después de una campaña para dejar de fumar
con duración de un año.
48 49
300 326
16% 15%
Número de diabéticos fumadores
Número de pacientes diabéticos
Porcentaje de pacientes diabéticos que fuman

Rango
Diferencia entre el valor más alto y el valor más bajo.

Media y Desviación Estándar
Media aritmética: Se obtiene sumando los valores y dividiendo entre el número total de valores (N)
1, 10, 20, 30, 40, 47, 47, 50
(1 + 10 + 20 + 30 + 40 + 47+ 47+ 50)8
= 30.63
Desviación Estándar: Representación de la variación de los valores respecto de la media.

Desviación Estándar
Menor variación respecto de la media (población con poca
variación natural)
Mayor variación respecto de la media (población con mayor
variación natural)

Media y Desviación Estándar
Niveles de colesterol total en 2 grupos de 100 pacientes
Media: 5.8 mmol/L SD: 0.49 mmol/L
Media: 6.2 mmol/L SD: 0.2 mmol/L
Media y Desviación Estándar
Se utilizan preferentemente cuando los datos tienen una distribución normal.

Mediana
Mediana: Número central en la secuencia ordenada de datos individuales.
1, 10, 20, 30, 40, 47, 47, 50
35 Cuando N es par se toma el promedio entre los 2 números centrales
1, 10, 20, 30, 40, 47, 47, 50, 52

Moda
Moda: Número que más se repite en la secuencia de datos individuales.
1, 10, 20, 30, 40, 47, 47, 50, 52
Usualmente se utiliza cuando tenemos variables nominales.
También puede usarse cuando no hay un valor promedio único (curva bimodal)

Moda
Unimodal Bimodal

Mediana y moda
Normal (simétrica)
Asimetría negativa
Asimetría positiva
Se utilizan para representar el promedio cuando los datos no son simétricos, por ejemplo en las poblaciones que no presentan
distribución normal.

Asimetría negativa
Media, mediana y moda

Media, mediana y moda
Asimetría positiva


Análisis de Supervivencia o Evolución
Representan el tiempo hasta que ocurre un evento (muerte, alta, curación, etc.)
El método más común es la representación de Kaplan Meier

Análisis de Supervivencia o Evolución

Registro de los pacientes
Diagrama CONSORT (Consolidated Standards of
Reporting Trials)
Presenta el número de pacientes que se reclutan, permanecen o salen del estudio en cada etapa

Estadísticas que predicen
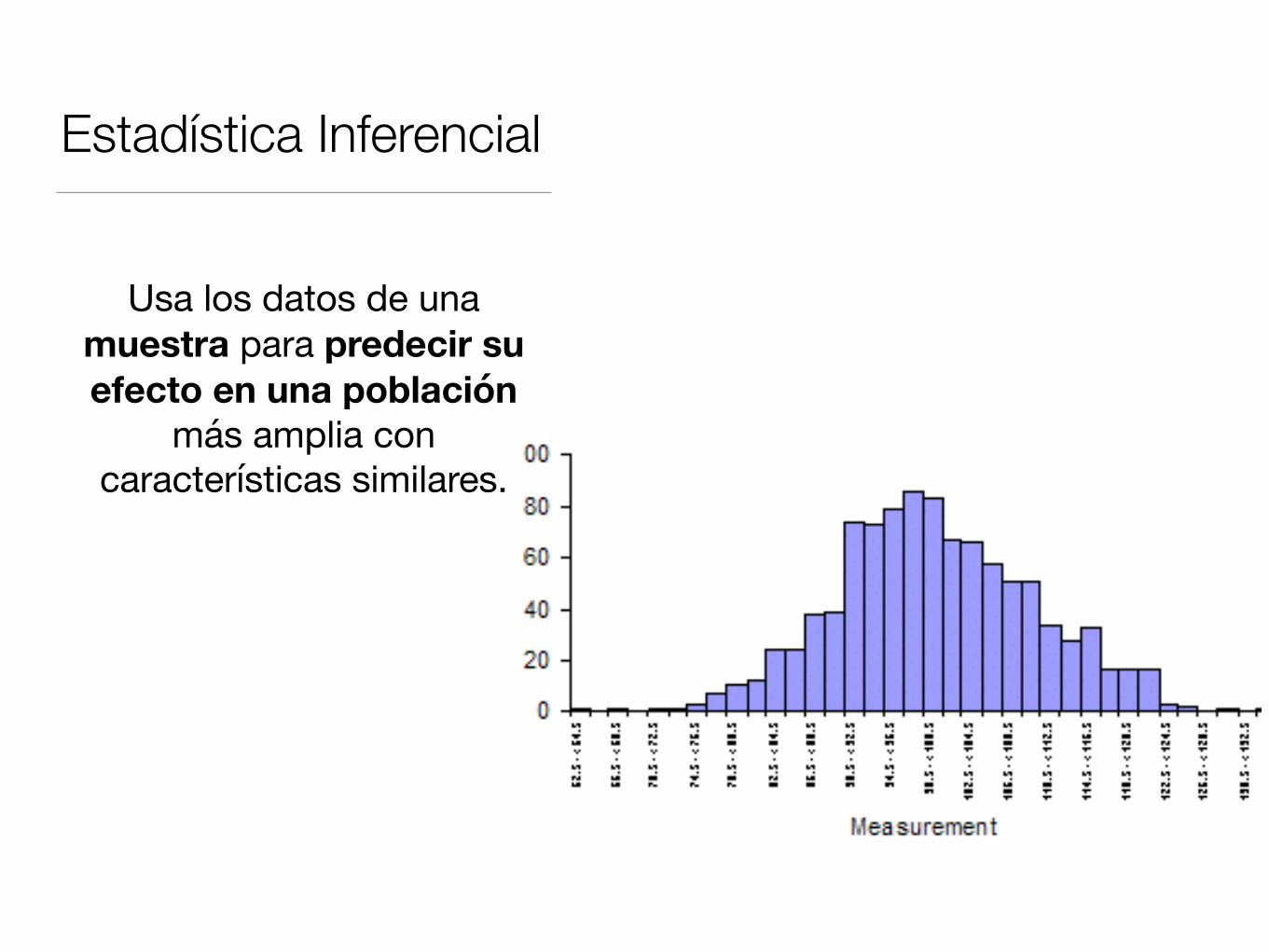
Estadística Inferencial
Usa los datos de una muestra para predecir su efecto en una población
más amplia con características similares.

Estadística Inferencial
Población
Muestra
InferenciaMuestra aleatoria
Media de la población
Media de la muestra

Probando una hipótesis• Se propone una hipótesis de trabajo
(H1) y se calcula qué tan probable es que ésta sea verdadera.
• Se plantea una hipótesis nula (H0), es decir, se propone que no existe una diferencia entre ambos grupos a comparar.
• El valor de P (significancia estadística) es la probabilidas de que la diferencia sea verdadera y no debida al azar.

El valor de P
Probabilidad de que una diferencia observada haya ocurrido por casualidad.
P= 0.5 significa que la probabilidad de que una diferencia haya ocurrido por casualidad es de 0.5 en 1, ó 50%.
P= 0.05 significa que la probabilidad de que una diferencia haya ocurrido por casualidad es de 0.05 en 1, ó 5%. Nivel suficiente para rechazar la
hipótesis nula.
Entre menor sea el valor de P, es menos probable que la diferencia haya ocurrido por casualidad.

Errores en los resultados

Pruebas Paramétricas
Niveles de colesterol total en 2 grupos de 100 pacientes
Media: 5.8 mmol/L SD: 0.49 mmol/L
Media: 6.2 mmol/L SD: 0.2 mmol/L
Prueba T de Student p<0.001

Pruebas No Paramétricas
• Son aquellas que se usan para poblaciones con distribución asimétrica.
• Datos típicos: ordinales o nominales


Intervalos de confianza
• Estimado del rango que contiene el valor verdadero para la población





























