Embed Size (px)
Citation preview

11: Ordenar 2
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 3
Definiciones
Se desea ordenar un set de estructuras, que contienen información, de acuerdo al valor de un campo de la estructura denominado clave.
Ordenamiento interno, es aquel que ordena un arreglo de estructuras; y externo es aquel que ordena un archivo de estructuras.
Ordenamiento in situ, es aquel que no requiere espacio adicional (se ordena en el mismo arreglo o archivo).

11: Ordenar 4
Definiciones II
Suelen tenerse dos medidas de eficiencia: C(n) el número de comparaciones de claves, y M(n) el número de movimientos de datos, necesarios para lograr el ordenamiento.
Los métodos mas simples de ordenamiento suelen ser de complejidad O(n2).
Suelen ser el punto de partida de los métodos más elaborados que suelen ser O(n*log2(n)).

11: Ordenar 5
Definiciones III
En los diversos algoritmos de ordenamiento es importante considerar su complejidad en el peor caso y en promedio.
Si se requiere un ordenamiento ascendente, cada vez que en el arreglo se tenga: i < j con a[i] > a[j] se tiene una inversión.
Los algoritmos de ordenamiento eliminan todas las inversiones.

11: Ordenar 6
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 7
Selección
Algoritmo Selection sort: Repetir hasta que quede un arreglo de un elemento:
Seleccionar el elemento de la última posición del arreglo. Sea j su cursor. Buscar el elemento con la mayor clave en el resto del arreglo. Intercambiar el elemento de la última posición del arreglo con el de mayor clave. Disminuir el rango del arreglo en uno.

11: Ordenar 8
Selección: tipos
Los siguientes tipos que serán usados en las funciones: typedef int Tipo; /* tipo de item del arreglo */ typedef int Indice; /* tipo del índice */
Ordenaremos ascendentemente: desde Inf hasta Sup.

11: Ordenar 9
Selección: códigovoid selectsort(Tipo a[], Indice Inf, Indice Sup) { Indice i, j, max; Tipo temp;
for (j=Sup; j>Inf; j--) { max=j; temp=a[j]; // Selecciona el ultimo: a[j] for(i=j-1; i>=Inf; i--) { // Busca el mayor entre los
if (a[i]>temp) { // otros elementosmax=i; temp=a[i];
} }
a[max]=a[j]; // Intercambia el mayor con a[j] a[j]=temp; }
}

11: Ordenar 10
Selección: ejemplos Ejemplos: aleatorio y peor caso de datos de entrada

11: Ordenar 11
Selección: complejidad El for interno se realiza: (n-1)+(n-2) +…+ 1 veces. Ya que la primera vez hay que buscar el mayor en un subarreglo de (n-1) componentes; la segunda vez se busca el mayor en un subarreglo de (n-2) componentes; y así sucesivamente. Suma que tiene por resultado: n*(n-1)/2. A esto se debe agregar la selección, que es O(1), y el intercambio (que también es O(1)); acciones que se repiten (n-1) veces. La complejidad es T(n) = n*(n-1)/2 +(n-1) y entonces O(n2). Otra forma de calcular la complejidad es la observación de que el algoritmo se rige por la relación de recurrencia: T(n) = T(n-1) + (n-1) con T(0) = 0, ya que cada vez se reduce el tamaño del arreglo en uno, pero con un costo para reducirlo de (n-1) operaciones O(1). Se logra igual resultado que el anterior: O(n2).

11: Ordenar 12
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 13
Intercambio
Se comparan e intercambian pares adyacentes de ítems, hasta que todos estén ordenados.
Los mas conocidos son bubble y shakesort. Son algoritmos muy poco eficientes, estan aqui solo para ilustrar.
Algoritmo Bubblesort: Comenzar con i=0; Repetir hasta que quede arreglo de tamaño uno:
Efectúa una pasada hacia arriba, hasta la última posición: if (a[i] > a[i+1])
swap (a[i], a[i+1]); // intercambiar el mayor hacia arribai++;
Disminuir en uno el tamaño del arreglo partiendo por arriba.

11: Ordenar 14
Bubblesort: código#define SWAP(a, b) { t=a; a=b; b=t; } #define compGT(a, b) (a > b) /* Ordena ascendente. Desde indice Inf hasta Sup */ void bubbleSort( Tipo a[], Indice Inf, Indice Sup ) {
Indice i, j; Tipo t; //temporal for(i=Inf ; i<= Sup; i++) { // Recorre el arreglo con i
for(j=Inf+1; j<=(Sup-(i-Inf)); j++) { // Recorre con j, compara y
if( compGT( a[j-1], a[j] ) ) // ordena por intercambio
SWAP(a[j-1], a[j]); // el mayor queda arriba.}
} } El for interno se realiza: (n-1)+(n-2) +…1. Entonces es O(n2).

11: Ordenar 15
Bubblesort: complejidad
Algoritmo shakesort o bubblesort de dos pasadas (ambos son O(n2)):Comenzar con i=0; Repetir hasta que quede arreglo de tamaño uno: Efectúa una pasada hacia arriba, hasta la última posición:
if (a[i] > a[i+1]) swap (a[i], a[i+1]); i++; (más pesado en última posición)
Disminuye en uno el tamaño del arreglo (por arriba) Efectúa una pasada hacia abajo, hasta el inicio del arreglo:
if (a[i-1] > a[i]) swap (a[i], a[i-1]); i--; (más liviano en primera posición)
Acorta en uno el tamaño del arreglo (por abajo).

11: Ordenar 16
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 17
Inserción
Algoritmos Inserción:En la etapa i-ésima se inserta a[i] en su lugar correcto entre: a[0], a[1],…, a[i-1] que están previamente ordenados. Hay que desplazar los elementos previamente ordenados, uno a uno, hasta encontrar la posición donde será insertado a[i].
En el peor caso: si a[0] es mayor que a[i] hay que efectuar i copias.
En el mejor caso si a[i-1] es menor que a[i], no hay desplazamientos.
Si existen claves repetidas, éstas conservan el orden original, se dice que el algoritmo de ordenamiento es estable.

11: Ordenar 18
Inserción: código
typedef int Tipo; /* tipo de item del arreglo */ typedef int Indice; /* tipo del índice */ #define compGT(a, b) (a > b) void InsertSort(Tipo *a, Indice inf, Indice sup) {
Tipo t; Indice i, j; /*Ordena ascendentemente */ for (i = inf + 1; i <= sup; i++) {
t = a[i]; //se marca el elemento que será insertado. /* Desplaza elementos hasta encontrar punto de inserción */
for (j = i-1; j >= inf && compGT(a[j], t); j--) a[j+1] = a[j];
a[j+1] = t; /* lo inserta */ }
}

11: Ordenar 19
Inserción: ejemplos Ejemplos: aleatorio y peor caso de datos de entrada

11: Ordenar 20
Inserción: complejidad En el peor caso, el for interno se efectúa: 1 + 2 + 3 +…+(n-1). Esto en caso que el arreglo esté previamente ordenado en forma
descendente. En el primer recorrido del for interno hay que mover un elemento; en la segunda pasada, hay que mover dos elementos; y así sucesivamente, hasta mover (n-1) para dejar espacio en la primera posición, para insertar el último.
Esto tiene complejidad T(n) = n*(n-1)/2 + (n-1) = O(n2). Se agregan (n-1) movimientos por el almacenamiento del elemento que será insertado, más la escritura para la inserción; ambas son O(1).
En el mejor de los casos con un arreglo previamente ordenado en forma ascendente, el for interno no se realiza nunca; ya que no son necesarios los desplazamientos que éste efectúa; el lazo externo debe efectuarse (n-1) vez. Este caso es de complejidad: T(n) = O(n). Mientras más ordenado parcialmente esté el arreglo, mejor será el comportamiento del algoritmo de inserción.

11: Ordenar 21
Inserción Binaria Una posible mejora del algoritmo es la consideración de que el
subarreglo en el cual se insertará el elemento está previamente ordenado.
En este caso, en lugar de efectuar una búsqueda secuencial de la posición de inserción, se puede realizar una búsqueda binaria. Sin embargo esto disminuye el número de comparaciones y no el de movimiento de los datos (que suele ser de mayor costo).

11: Ordenar 22
Inserción Binaria: códigoint BinaryInsertSort(Tipo *a, Indice inf, Indice sup){ int op=0; Tipo t; Indice i, j, right, left, m; for (i = inf + 1; i <= sup; i++) { t = a[i]; left=inf ; right=i-1; while (left<=right) { m=(left+right)/2; if ( t <a[m]) right=m-1; else left=m+1; }
// Desplazar elementos for (j = i-1; j >= left ; j--) { a[j+1] = a[j]; op++; } /* inserte */ a[left] = t; op++; } return(op);}

11: Ordenar 23
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 24
Shellsort Es uno de los algoritmos más rápidos para ordenar
arreglos de algunas decenas de componentes. Es una generalizacion del Insertion sort.
Es un método adaptivo que funciona mejor si los arreglos están casi ordenados. El análisis de su complejidad es difícil.
Algoritmo Shellsort:Se ordenan elementos que están a una distancia h entre ellos en
pasadas consecutivas.Al inicio h es un valor elevado y disminuye con cada pasada.Sea hk cuando la distancia de comparación es k. La pasada se
denomina fase hk. El algoritmo termina con h1.

11: Ordenar 25
Shellsort II Después de la fase hk los elementos que están a distancia hk entre
ellos están ordenados: a[i] < a[i + hk] < a[i + 2hk ] < a[i + 3hk] < … para todo i.
El ordenamiento burbuja ordena en fase h1. Necesariamente shellsort tiene que llegar a ordenar la fase h1, pero su ventaja es que el número de intercambios en la fase h1 es menor que los intercambios necesarios en inserción o por burbuja.
La razón de esto es que si a una lista ordenada de fase hk se la somete a un ordenamiento de fase hk-1 sigue hk ordenada.

11: Ordenar 26
Shellsort: código// El algoritmo original hace que hk sea el anterior dividido por dos.void shellsortShell(Tipo a[], Indice n){ Indice h, i, j; Tipo temp; for (h=n/2; h>0; h=h/2) { for (i=h; i<n; i++) { //aplica inserción a partir de h temp=a[i]; for (j=i-h; j>=0 && a[j]>temp; j-=h) { a[j+h]=a[j]; } a[j+h]=temp; //inserta } }}

11: Ordenar 27
Shellsort: complejidad La selección adecuada de la secuencia hk genera un menor costo. La secuencia original de Shell (1959): 1 2 4 8 16… tiene costo O(n2).
La secuencia hi = 4i+1 + 3*2i + 1 con i >= 0 , (h0 = 8, h1 = 23, h2=77, ...)genera: 1 8 23 77 281 1073 4193 16577…con complejidad O(n4/3)
La secuencia propuesta por Knuth (1998 ): hi+1 = 3hi + 1, con h1 = 1genera: 1 4 13 40… tiene complejidad O(n (log n) 2).
Luego nuevas optimizaciones de Knuth permiten complejidades de O(n1.25) y O(n1+1/sqrt(log n)).

11: Ordenar 28
Shellsort Knuth: códigoint shellsortKnuth(Tipo a[], Indice n){ Indice h,i,j; Tipo temp; for (h=1; h<=n/9; h=h*3+1) ; //inicia h for ( ; h>0; h=h/3) { /* h = 1, 4, 13, 40, 121, 364... 3*h+1 */ for (i=h; i<n; i++) { //pasada por inserción temp=a[i]; for (j=i-h; j>=0 && a[j]>temp; j-=h) { a[j+h]=a[j]; } a[j+h]=temp; } }}

11: Ordenar 29
Shellsort Ciura Ciura (2001) conjetura que su secuencia es óptima para grandes
valores de n. Se almacenan los números de la secuencia en un arreglo local
denominado incs. Se escoge el valor inicial de la secuencia tal que sea menor que
0.44n. Por ejemplo si n=1000, el primer h será 301 generando 7 fases
de ordenamiento.

11: Ordenar 30
Shell sort Ciura: códigoint shellsortCiura(Tipo a[], Indice n){ Indice h,i,j,t; Tipo temp; int incs[18] = { 2331004, 1036002, 460445, 204643, 90952, 40423,
17965, 7985, 3549, 1577, 701, 301, 132, 57, 23, 10, 4, 1 }; for (t=0; t<18; t++) { h=incs[t]; if (h > n*4/9) continue; for (i=h; i<n; i++) { //Inserción. temp=a[i]; for (j = i-h; j >= 0 && p[j] > temp; j -= h) { a[j+h]=a[j]; } a[j+h]=temp; } }}

11: Ordenar 40
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 41
Quicksort Quicksort es un algoritmo de tipo comparison sort de ordenamiento
desarrollado por C.A.R. Hoare en 1960. Es una elaboración sofisticada del método de intercambio
(comparison sort), utiliza una estrategia de dividir para conquistar al dividir una lista en dos sub listas.
Algoritmo Quicksort:Elegir un elemento llamado pivote de la listaReordenar la lista para que todos los elementos menores que el pivote estén antes que el y todos los mayores después. Al final de esta operación el pivote esta en su posición final.Recursivamente ordenar la lista de elementos menores y la lista de elementos mayores.

11: Ordenar 42
Quicksort: complejidad Mejor caso: T(n) = 2*T(n/2) +c*n donde c es el costo de dividir en
dos partes. La solución de esta relación es: c*n*( log(2)+log(n) ) la que es O(n*log(n)).
El núcleo del algoritmo es el ordenamiento de una partición respecto de un pivote.
Ej: valor_piv=a[piv];do {
while ( a[i] < valor_piv) //encuentra uno mayor o igual que i++; //el valor del pivote
while( valor_piv < a[j]) // al salir apunta a uno menor o igual j--; // que el pivote
if( i<=j) {swap(i, j) ; i++; j—;} // swap intercambia a[i] por a[j] } while( i <= j );

11: Ordenar 43
Quicksort: códigovoid qsort(int l, int r) { // asume que arreglo a[ ] es global
int i=l, j=r; int piv=(l+r)/2; int valor_piv=a[piv];
do { while ( a[i] < valor_piv) i++;
while( valor_piv < a[j]) j--;
if( i<=j){swap(i, j) ; i++; j--;}
} while(i<=j); if( l < j)
qsort( l, j); if( i< r )
qsort( i, r); }

11: Ordenar 45
11-Ordenar
11.1 Definiciones11.2 Selección11.3 Intercambio11.4 Inserción11.5 Shellsort11.6 Quicksort11.7 Mergesort

11: Ordenar 46
Mergesort Mergesort (Von Neumann, 1945) es usado para unir (merge); la idea
es combinar dos estructuras ordenadas en una sola. Suele emplearse para ordenamiento externo; es decir para ordenar
archivos, pero también puede usarse para ordenamiento interno. En mergesort en forma recursiva se ordenan la parte izquierda y
derecha, y finalmente se mezclan (merge) las dos partes en una sola ordenada y mayor.
Algoritmo Merge:Dado dos arreglos ordenados a, b y un arreglo destino c.Se recorren los arreglos a, b y se escoge el menor valor entre a[i] y b[j] . Se inserta ese elemento en c[k], ajustando los índices Si uno de los arreglos se agota, insertar los elementos restantes del otro en c.
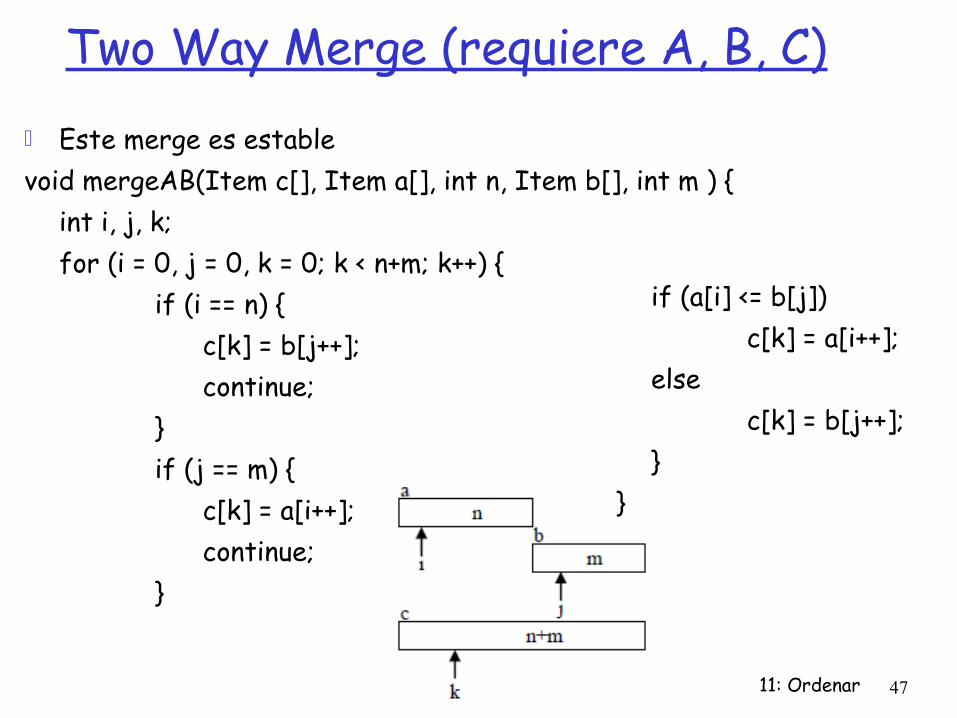
11: Ordenar 47
Este merge es establevoid mergeAB(Item c[], Item a[], int n, Item b[], int m ) {
int i, j, k; for (i = 0, j = 0, k = 0; k < n+m; k++) {
if (i == n) { c[k] = b[j++]; continue;
} if (j == m) {
c[k] = a[i++]; continue;
}
Two Way Merge (requiere A, B, C)
if (a[i] <= b[j]) c[k] = a[i++];
else c[k] = b[j++];
} }

11: Ordenar 48
Este merge es inestablevoid mergeI(Item a[], int left, int mitad, int right) {
int i, j, k; static Item aux[maxN]; for (i = mitad+1; i > left; i--)
aux[i-1] = a[i-1]; //copia parte izquierda desde m a left for (j = mitad; j < right; j++)
aux[right+mitad-j] = a[j+1]; // copia en orden inverso //se tienen: i=left, j= right for (k = left; k <= right; k++) //se mezcla en arreglo a
if (aux[j] < aux[i]) a[k] = aux[j--];
else a[k] = aux[i++];
}
In Situ Merge

11: Ordenar 49
Mergesort: complejidad La complejidad del merge es O(n). La complejidad del mergesort es la suma de dos llamadas
recursivas mas la operación de merge. Su relación de recurrencia: T(n) = 2T(n/2) + n con T(1)=0.
Es O(nlog(n)) en peor caso, y es estable; es decir mantiene el orden original de los elementos repetidos. Los algoritmos heapsort y quicksort no son estables.
Sus desventajas son que requiere un espacio adicional proporcional a n y que su complejidad de mejor caso también es O(nlog(n)).
Su principal tradicional aplicación es mezclar un archivo ordenado de grandes dimensiones (el maestro) con uno pequeño (transacciones diarias), pero desordenado. Se ordena el pequeño por alguno de los métodos avanzados, y luego se efectúa la mezcla.

11: Ordenar 50
void mergesort(Item a[], int left, int right) { int m = (right+left)/2; if (right <= left)
return; mergesort(a, left, m); mergesort(a, m+1, right); mergeI(a, left, m, right);
}
Mergesort: código





























