Embed Size (px)
Citation preview

El análisis discriminanteJoaquín Aldás Manzano1
Universitat de ValènciaDpto. de Dirección de Empresas “Juan José Renau Piqueras”
1 Estas notas son una selección de aquellos textos que, bajo mi punto de vista, mejor abordanel tema analizado. Sus autores aparecen citados al principio de cada epígrafe, y a ellos hayque referirse cuando se citen los contenidos de estas notas. Mi única tarea ha sido la de selec-cionar, ordenar y, en algunos casos traducir los textos originales.

El análisis discriminante
1. ¿Qué es el análisis discriminante?(Uriel, 1997)
El análisis discriminante se utiliza para clasificar a distintos individuos engrupos o poblaciones alternativos a partir de los valores de un conjunto devariables sobre los individuos a los que se pretende clasificar. Imaginemos, amodo de ejemplo, que un director de una sucursal bancaria necesita estableceralgún criterio que para conceder o no los préstamos que le son solicitados. Sumisión es detectar si el solicitante pertenecerá en el futuro al grupo de los quedevuelven los préstamos o si, por el contrario, será de aquellos que no lo hacen.
Supongamos que ese director tiene el historial de todos aquellos individuos que,en el pasado, solicitaron préstamos. En ese historial figura, evidentemente, sifinalmente el préstamo fue devuelto o no, es decir, el director tiene clasificadosa los individuos en solventes e insolventes. Lo que se plantea ahora es si sepuede obtener algún tipo de función que le permita, ante una nueva solicitud,predecir a cuál de los dos grupos va a pertenecer el solicitante.
Para esto sirve el análisis discriminante. Dada una población, que tenemosdividida en grupos, el análisis discriminante encuentra una función quepermite, con un determinado grado de acierto, explicar esa división en grupos(visión explicativa). Una vez obtenida, puede utilizarse para clasificar a nuevosindividuos en alguno de los grupos en que está dividida la población (visiónpredictiva).
2. Visión geométrica del análisis discriminante(Uriel, 1997)
Intentaremos ofrecer una intuición geométrica del análisis discriminante quenos servirá, además, para introducir algunos conceptos necesarios. Supongamosque tenemos una población que puede dividirse en dos grupos. Siguiendo con elejemplo inicial del director de banco: clientes solventes e insolventes. Suponga-mos, también, que queremos ser capaces de explicar esa clasificaciónatendiendo a una única variable, por ejemplo, el nivel de ingresos del cliente.Como el director del banco tiene el historial de los créditos pasados que conce-
Joaquín Aldás ManzanoAnálisis discriminante2

dió, sabe qué nivel de ingresos tenían los solventes y los insolventes. De estainformación podría obtenerse fácilmente la figura 1.
Figura 1. Funciones de distribución hipotéticas de dos grupos
Grupo IISolventes
X
Distr
ibució
n de f
recu
encia
s
IIXIX
Miembros del grupo IIincorrectamente clasificadoscomo del grupo I
Miembros del grupo Iincorrectamente clasificadoscomo del grupo II
C
Grupo IInsolventes
Nivel de ingresos
Un criterio que podría adoptar el director de banco para conceder o no unpréstamo, podría ser calcular la media de ingresos de los dos grupos. La mediade ambas medias (C) sería un buen punto de corte como se ilustra en la figura1. Si el nuevo solicitante tiene unos ingresos (X) superiores a C, se le concede elpréstamo y si los tiene inferiores no se le concede:
2I IIX XC +=
es decir, si X>C al individuo se le clasifica en el grupo de los solventes y siX<C en el de los probables insolventes.
Este criterio, como también se observa en la figura 1, no es infalible, dado queen la base de datos del director del banco hay clientes con unos ingresosinferiores a C que sí que devolvieron sus créditos y, por el contrario, hay clien-tes que tenían ingresos superiores a esa cantidad y que acabaron siendo insol-ventes. La misión del análisis discriminante es obtener un criterio de clasifica-ción que reduzca ese error. Es decir, encontrar una función discriminante quesepare lo mejor posible las dos poblaciones.
Joaquín Aldás ManzanoAnálisis discriminante3

La figura 2, ilustra el caso anterior cuando utilizamos no una variable explica-tiva (los ingresos), sino dos, por ejemplo, los ingresos y la edad del solicitante.
Figura 2. Análisis discriminante con dos variables explicativas
2,IIX2,IX
1, IIX
1,IX
IID
ID
1C
2C
C
D
2X
1X
1X
2X
En esta figura 2, se intenta ilustrar cómo, si en lugar de utilizar para clasificaruna de las dos variables X1 y X2 por separado, se utiliza una combinación deambas D, el área que recoge el error, es mucho menor. En síntesis, el análisisdiscriminante pretende encontrar aquella función discriminante:
1 1 2 2 k kD u X u X u X= + + +…
que menor error de clasificación produzca, donde X1...Xk son las k variablesexplicativas y u1...uk son coeficientes de ponderación.
Cuando a los individuos se les quiera clasificar en dos grupos, bastará con unafunción discriminante D, pero si se les quiere clasificar en tres grupos, haránfalta dos funciones discriminantes. En general serán necesarias G-1 funcionesdiscriminantes donde G es el número de grupos en que se divide la población(figura 3).
Joaquín Aldás ManzanoAnálisis discriminante4

Figura 3. Ilustración del caso de tres grupos1X
2X
3. Un ejemplo de aplicación del análisis discriminante para elcaso de dos grupos(Hair, Anderson, Tatham y Black, 1995; Uriel, 1997)
Paso 1. Objetivos del análisis discriminante
Para ilustrar la aplicación de un análisis discriminante con dos grupos, utiliza-remos el caso de la empresa HATCO como en temas anteriores. Se recordaráque una de las variables que describían a los clientes de HATCO, era el nivelde utilización de los servicios de HATCO que cada cliente hacía, medido comoporcentaje del total de sus compras de maquinaria que le hacen a HATCO.Parece razonable que HATCO desee explicar porqué unas empresas recurrencon más intensidad que otras a ella como proveedora.
Paso 2. Desarrollo del plan de análisis
En primer lugar es necesario determinar qué variables serán las independientesy cuál la dependiente. Dado que la variable dependiente indica la pertenencia aun grupo u otro, deberá ser no métrica, mientras que las independientes debenser métricas.
La variable dependiente, puede ser dicotómica (dos grupos) o politómica (másde dos grupos), pero en todo caso, los grupos deben ser excluyentes. Un indivi-duo no puede pertenecer a más de un grupo. Las variables independientes, porsu lado, deben ser seleccionadas partiendo de estudios previos que confirmen
Joaquín Aldás ManzanoAnálisis discriminante5

que pueden ejercer algún tipo de influencia sobre la pertenencia a los grupos.En todo caso el investigador ha de sustituir la ausencia de estos trabajos consu propio sentido común.
En nuestro ejemplo, la variable nivel de utilización de los servicios (X9), talcomo se ha definido, es una variable métrica, y en un discriminante la variabledependiente tiene que ser no métrica, dado que sólo indica si se pertenece a ungrupo u a otro. Por ello HATCO divide a sus clientes en dos grupos, los que lecompran por encima de la media de todos los clientes, y los que le compran pordebajo de esa media. Estos son los dos grupos cuya pertenencia quiere explicar.
En cuanto a las variables independientes, parece lógico que se utilicen aquellasque miden la percepción que de HATCO tienen sus clientes. Un cliente esprobable que mantenga una relación más intensa con HATCO si valora positi-vamente su rapidez del servicio (X1), su nivel de precios (X2) y así hasta lacalidad de sus productos. Serán por tanto las variables X1 a X7 las que se utili-zarán como explicativas.
En cuanto al tamaño de la muestra, hay que indicar que el análisis discrimi-nante es bastante sensible al número de casos por cada variable independiente.La mayoría de trabajos sugieren un ratio de 20 observaciones por cada predic-tor. Aunque no siempre es posible llegar a esta cifra, el investigador debe serconsciente de que los resultados pueden volverse inestables cuando se baja deesta cifra. Esta consideración hay que hacerla también no sólo para el conjuntode la muestra, sino también en cada uno de los grupos en que se divide lapoblación. Como guía, no deberían haber menos de 20 observaciones en cadagrupo. Además debe analizarse también los tamaños relativos de los grupos, sihay grandes diferencias de tamaño entre ellos, el análisis puede verse afectadoal aumentar desproporcionadamente la probabilidad de pertenencia a los másgrandes, llegando a recomendarse un muestreo aleatorio de casos de los gruposmás grandes para equilibrar la muestra.
En nuestra base de datos, disponemos de 100 observaciones y de 7 variablesindependientes, lo que da un ratio de 15 a 1, no muy alejado de la cifraóptima. Asimismo, como se observa en el cuadro 1, en cada uno de los dosgrupos hay el mismo número de casos, no siendo necesario equilibrar lamuestra.
Joaquín Aldás ManzanoAnálisis discriminante6
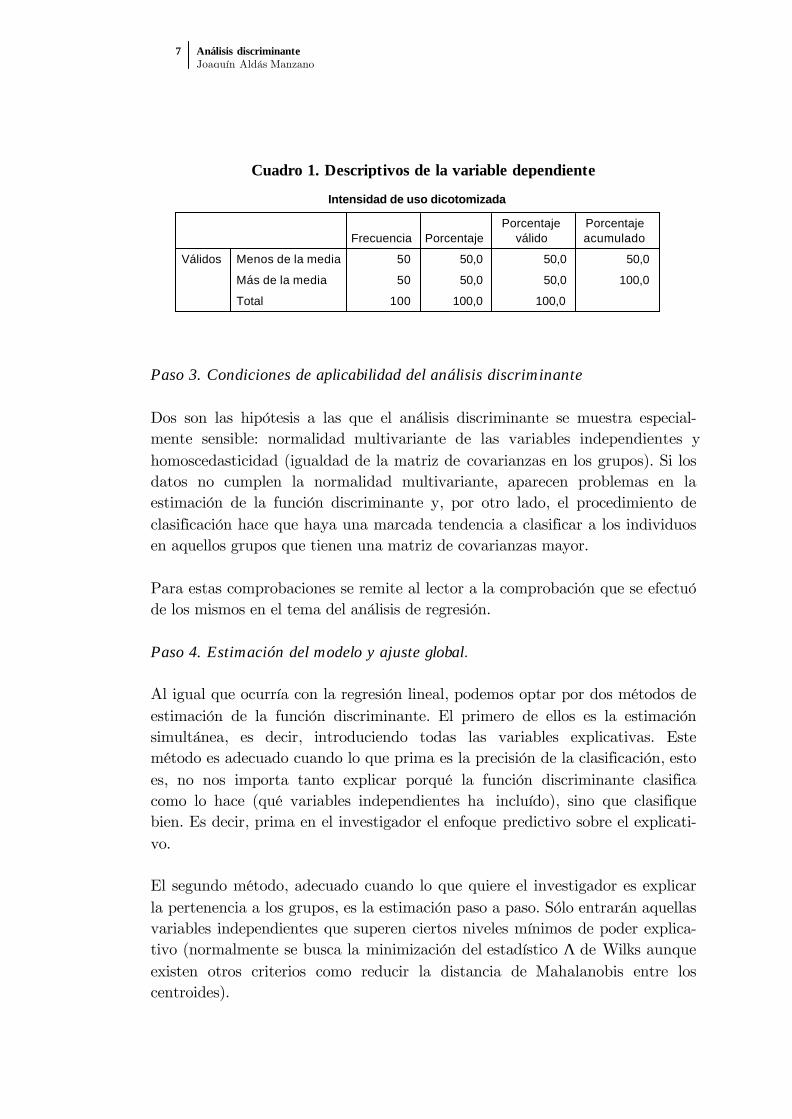
Cuadro 1. Descriptivos de la variable dependienteIntensidad de uso dicotomizada
50 50,0 50,0 50,0
50 50,0 50,0 100,0
100 100,0 100,0
Menos de la media
Más de la media
Total
Válidos
Frecuencia PorcentajePorcentaje
válidoPorcentajeacumulado
Paso 3. Condiciones de aplicabilidad del análisis discriminante
Dos son las hipótesis a las que el análisis discriminante se muestra especial-mente sensible: normalidad multivariante de las variables independientes yhomoscedasticidad (igualdad de la matriz de covarianzas en los grupos). Si losdatos no cumplen la normalidad multivariante, aparecen problemas en laestimación de la función discriminante y, por otro lado, el procedimiento declasificación hace que haya una marcada tendencia a clasificar a los individuosen aquellos grupos que tienen una matriz de covarianzas mayor.
Para estas comprobaciones se remite al lector a la comprobación que se efectuóde los mismos en el tema del análisis de regresión.
Paso 4. Estimación del modelo y ajuste global.
Al igual que ocurría con la regresión lineal, podemos optar por dos métodos deestimación de la función discriminante. El primero de ellos es la estimaciónsimultánea, es decir, introduciendo todas las variables explicativas. Estemétodo es adecuado cuando lo que prima es la precisión de la clasificación, estoes, no nos importa tanto explicar porqué la función discriminante clasificacomo lo hace (qué variables independientes ha incluído), sino que clasifiquebien. Es decir, prima en el investigador el enfoque predictivo sobre el explicati-vo.
El segundo método, adecuado cuando lo que quiere el investigador es explicarla pertenencia a los grupos, es la estimación paso a paso. Sólo entrarán aquellasvariables independientes que superen ciertos niveles mínimos de poder explica-tivo (normalmente se busca la minimización del estadístico Λ de Wilks aunqueexisten otros criterios como reducir la distancia de Mahalanobis entre loscentroides).
Joaquín Aldás ManzanoAnálisis discriminante7

Dado que a nosotros nos interesa tanto obtener una función discriminante conun buen poder clasificatorio, como saber qué variables determinan la pertenen-cia a los grupos, mostraremos la solución del método paso a paso.
En el procedimiento paso a paso puede entrar, y también salir, aquella variableque cumpliendo el requisito mínimo (Valor mínimo de F para entrar o Valormáximo de F para salir), tenga un valor más pequeño del estadístico Λ deWilks. Antes de comenzar la aplicación del procedimiento es necesario fijar unavalor mínimo de F para entrar y un valor máximo de F para salir. Nosotrostomaremos los valores por defecto del programa (3’84 y 2’71 respectivamente).El valor F para entrar debe ser mayor que el de salida, pues de no ser así unavariable podría estar entrando y saliendo de forma indefinida en la selección.
En el cuadro 2 se observa como, inicialmente, todas las variables son candida-tas a entrar en la función discriminante, salvo el nivel de precios (F = 0’697 <3’84).
Cuadro 2. Variables que pueden entrarPruebas de igualdad de las medias de los grupos
,682 45,687 1 98 ,000
,993 ,697 1 98 ,406
,692 43,681 1 98 ,000
,970 2,999 1 98 ,086
,650 52,688 1 98 ,000
,970 3,016 1 98 ,086
,950 5,106 1 98 ,026
Rapidez de servicio
nivel de precios
flexibilidad de precios
Imagen del fabricante
Servicio
Imagen de losvendedores
Calidad del producto
Lambdade Wilks F gl1 gl2 Sig.
Como se observa en el cuadro 2, la variable que tiene un valor Λ de Wilks máspequeño (consecuentemente un F asociado al mismo más grande) es el corres-pondiente con la variable servicio que será la que entrará en primer lugar,como se señala en el cuadro 3. En el paso 0 todas las variables están fuera delanálisis, el programa calcula la Λ de Wilks y la correspondiente F. Comoprimera candidata a entrar se encuentra la mencionada servicio por losmotivos señalados. Como su F supera el valor mínimo para entrar, es laconsiderada.
Joaquín Aldás ManzanoAnálisis discriminante8

Cuadro 3. Resumen de los pasos del discriminanteVariables no incluidas en el análisis
1,000 1,000 45,687 ,682
1,000 1,000 ,697 ,993
1,000 1,000 43,681 ,692
1,000 1,000 2,999 ,970
1,000 1,000 52,688 ,650
1,000 1,000 3,016 ,970
1,000 1,000 5,106 ,950
,825 ,825 10,820 ,585
,668 ,668 10,818 ,585
,848 ,848 67,688 ,383
,939 ,939 ,003 ,650
,970 ,970 ,149 ,649
,991 ,991 5,714 ,614
,588 ,542 1,037 ,379
,460 ,460 1,420 ,377
,908 ,820 1,247 ,378
,960 ,835 ,873 ,380
,836 ,715 ,514 ,381
Rapidez de servicio
nivel de precios
flexibilidad de precios
Imagen del fabricante
Servicio
Imagen de losvendedores
Calidad del producto
Rapidez de servicio
nivel de precios
flexibilidad de precios
Imagen del fabricante
Imagen de losvendedores
Calidad del producto
Rapidez de servicio
nivel de precios
Imagen del fabricante
Imagen de losvendedores
Calidad del producto
0
1
2
Paso
ToleranciaTolerancia
mín.F que
introducirLambdade Wilks
Para que una variable entre, no sólo basta con que su F supere el valor mínimopara entrar, también se le exige una segunda condición. El método paso a pasofija un nivel llamado de tolerancia. La tolerancia es una medida de la asocia-ción lineal entre las variables independientes. Para la variable i la tolerancia sedefine como 1-ri
2 donde ri2 es el coeficiente de determinación entre la variable i
y el resto de variables explicativas que figuran en el modelo. Cuando la tolera-cia de la variable i es muy pequeña significa que dicha variable está muy corre-lacionada con el resto de las variables explicativas, lo que puede crear probe-mas en la estimación. El programa establece un nivel mínimo de tolerancia de0,001, con lo que las variables con tolerancia menor que ese límite son excluídasdel análisis. En el paso 0, la tolerancia es 1, dado que el estadístico no secalcula en esa iteración.En el paso 1, como se ha indicado, ha entrado la variable servicio. El programaentonces evalúa las variables restantes y comprueba que de las que superan elvalor mínimo de la F para entrar, el que tiene un valor de la Λ de Wilks más
Joaquín Aldás ManzanoAnálisis discriminante9

baja (F más alta) se corresponde con la variable flexibilidad de precios, siendoésta la que entrará en el paso 2, dado que también cumple el requisito de latolerancia. Finalmente, como se observa en el cuadro 3, ninguna variable escandidata para entrar, pues tienen un valor de F demasiado pequeño.
Pero, como se ha indicado, en cada paso, no sólo hay que determinar quévariable puede entrar, sino si las que han entrado debe salir. Para ello hay quecomprobar que superan el valor máximo de F para salir que las haría ser excluí-das. El programa toma por defecto el valor 2,71. En el cuadro 4 se compruebacomo, las dos variables que han entrado superan ese valor y no deben serexcluídas.
Cuadro 4. Valores de F para salirVariables en el análisis
1,000 52,688
,848 78,157 ,692
,848 67,688 ,650
Servicio
Servicio
flexibilidad de precios
1
2
Paso
Tolerancia F que eliminarLambdade Wilks
El cuadro 5 resume las variables que se incorporan a la función discriminante.Es interesante destacar cómo en las notas al pie 2 y 3 del cuadro, aparecen losvalores máximo y mínimo de F que se han señalado como por defecto delprograma con anterioridad.
Cuadro 5. Variables de la función discriminanteVariables introducidas/eliminadas1,2,3,4
Servicio ,650 1 1 98,000 52,688 1 98,000 ,000
flexibilidadde precios
,383 2 1 98,000 78,114 2 97,000 ,000
1
2
Paso
Introducidas Estadístico gl1 gl2 gl3 Estadístico gl1 gl2 Sig.
F exacta
Lambda de Wilks
En cada paso se introduce la variable que minimiza la lambda de Wilks global.
El número máximo de pasos es 14.1. La F parcial mínima para entrar es 3.84.2. Maximum partial F to remove is 2.71.3. El nivel de F, la tolerancia o el VIN son insuficientes para continuar los cálculos.4.
Una vez calculada la función discriminante, se determina si esta es globalmentesignificativa (no si cada una de las variables que han entrado deberían haberlohecho). Para ello se plantea la hipótesis nula de si las medias poblacionales
Joaquín Aldás ManzanoAnálisis discriminante10

difieren significativamente en los dos grupos considerados. En el caso de que larespuesta fuera negativa, carecería de interés continuar con el análisis, ya quesignificaría que las variables introducidas como variables clasificadoras notienen capacidad discriminante significativa. Como se comprueba en el cuadro7, el estadístico χ2 que se utiliza para contrastar la hipótesis nula de igualdadde los vectores de medias (χ2 = 93,080) tiene una significatividad asociada de0, lo que permite rechazar la hipótesis nula y afirmar la significatividad de lafunción discriminante.
Cuadro 7. Significatividad global de la función discriminanteLambda de Wilks
,383 93,080 2 ,0001Contraste de
las funciones
Lambdade Wilks Chi-cuadrado gl Sig.
Una vez estimada la función discriminante, la segunda fase en este paso esestablecer la capacidad predictiva del análisis efectuado, es decir, medir labondad del ajuste del modelo. Para ello el programa ofrece la llamada matrizde confusión. Dado que en nuestra muestra sabemos a qué grupo pertenecende verdad las empresas (si compran por debajo o por encima de la media), loque hace la matriz de confusión es cruzar la clasificación real con la estimadamediante la función discriminante. Cuantos más casos hayan sido correcta-mente clasificados, más probable es que acertemos a la hora de utilizar lafunción con fines predictivos o, bajo otra perspectiva, más seguros estaremos deque las variables que han entrado son las que realmente determinan la clasifica-ción. El cuadro 8 muestra la matriz de confusión de nuestro ejemplo.
Cuadro 8. Matriz de confusiónResultados de la clasificación1
43 7 50
3 47 50
86,0 14,0 100,0
6,0 94,0 100,0
Menos de la media
Más de la media
Intensidad de usodicotomizada
Menos de la media
Más de la media
Intensidad de usodicotomizada
Recuento
%
Original
Menos dela media
Más de lamedia
Grupo de pertenenciapronosticado
Total
Clasificados correctamente el 90,0% de los casos agrupados originales.1.
Joaquín Aldás ManzanoAnálisis discriminante11

Puede comprobarse como, de haber utilizado la función discriminante paraclasificar a nuestra población, caso de no saber a qué grupo pertenecían lasemrpesas, hubiéramos acertado en el 90% de los casos. El acierto es ligeramentemayor para predecir la pertenencia al grupo de compradores por encima de lamedia (94%) que para predecir la pertenencia al grupo que compra por debajode la media (86%).
Otro indicador de la bondad de ajuste es el coeficiente η2 que es el coeficientede correlación obtenido al realizar la regresión entre la variable dicotómica queindica la pertenencia al grupo y las puntuaciones discriminantes. A la raízcuadrada de este coeficiente, que es la que aparece en la salida (cuadro 9) se ladenomina correlación canónica, pudiéndose calcular también en función delautovalor λ que minimiza el valor de la Λ de Wilks del siguiente modo:
2
1,611 0,7851 1 1,6110,61
lh lh
= = =+ +=
Cuadro 9. Indicador ηη 2 de bondad de ajusteAutovalores
1,6111 100,0 100,0 ,7851Función
Autovalor % de varianza % acumuladoCorrelación
canónica
Se han empleado las 1 primeras funciones discriminantes canónicas en elanálisis.
1.
Paso 5. Interpretación de los resultados
Si, como ocurre en nuestro ejemplo, la función discriminante es significativa, yla bondad del ajuste aceptable, el investigador se centrará en interpretar losresultados. Este proceso pasa por examinar las funciones discriminantes obteni-das para establecer la importancia relativa de cada variable independiente a lahora de discriminar entre los grupos. Existen tres métodos para ello: los coefi-cientes estandarizados de las funciones discriminantes, la matriz de estructuray el F univariante.
El enfoque más habitual es interpretar el signo y magnitud de los coeficientesestandarizados de la función discriminante. Si hacemos caso omiso del signo,cada coeficiente representa la contribución relativa de su variable asociada a la
Joaquín Aldás ManzanoAnálisis discriminante12

función. Las variables independientes con coeficientes más grandes contribuyenmás al poder discriminante de la función que las variables con coeficientes máspequeños. El signo solo indica el sentido de la contribución.
La interpretación de estos coeficientes es análoga a la de los coeficientes estan-darizados de una regresión y sujeta por ello a las mismas críticas. Por ejemplo,un coeficiente pequeño indica tanto que la variable asociada es irrelevante en larelación como que ha sido eliminada por un alto grado de multicolinealidad.
El cuadro 10 muestra los coeficientes estandarizados de las dos variables queentraron en la función. Puede observarse que la contribución de las dos varia-bles es similar y, en ambos casos, incrementos en las mismas favorecen la inten-sidad de la relación comercial entre las empresas.
Cuadro 10. Coeficientes estandarizadosCoeficientes estandarizados de lasfunciones discriminantes canónicas
,886
,924
flexibilidad de precios
Servicio
1
Función
En los últimos años se utilizan cada vez con más frecuencia las puntuacionesdiscriminantes para interpretar los resultados del análisis, debido a las deficien-cias señaladas del método anterior. Las puntuaciones discriminantes, queaparecen bajo la etiqueta de matriz de estructura (cuadro 11), miden la corre-lación simple entre cada variable independiente y la función discriminante.Reflejan la varianza que la variable independiente comparte con la funcióndiscriminante y pueden interpretarse como las puntuaciones factoriales de unanálisis factorial. En nuestro caso, si nos fijamos solamente en las correlacionesde las variables que han entrado en la función, se confirma que ambas variablestienen contribuciones parejas.
Joaquín Aldás ManzanoAnálisis discriminante13

Cuadro 11. Matriz de estructuraMatriz de estructura
,639
,578
,526
-,265
-,039
,019
,000
Rapidez de servicio1
Servicio
flexibilidad de precios
Calidad del producto1
nivel de precios1
Imagen de losvendedores
1
Imagen del fabricante1
1
Función
Correlaciones intra-grupo combinadas entrelas variables discriminantes y las funcionesdiscriminantes canónicas tipificadas Variables ordenadas por el tamaño de lacorrelación con la función.
Esta variable no se emplea en el análisis.1.
Finalmente, cuando se utiliza el método paso a paso para estimar la funcióndiscriminante, también pueden utilizarse los estadísticos F univariantes queaparecían en el cuadro 2 para interpretar el poder discriminante relativo decada variable independiente. Esto se logra analizando el tamaño del estadísticoy ordenándolos por él. Valores de F elevados indican mayor poder discriminan-te. En la práctica las ordenaciones que se obtienen con los F son las mismasque cuando se utilizan los coeficientes, pero tienen la ventaja de tener asocia-dos un valor de significatividad.
No podemos olvidar, sin embargo, que la utilización del análisis discriminantese ha planteado con dos finalidades. Una explicativa, para lo que sirven loscomentarios anteriores. Pero otra predictiva, es decir, pretendemos clasificar anuevas empresas en uno de los dos grupos establecidos. Veamos cómo procedeel análisis discriminante para clasificar mediante la función discriminante a lasempresas de nuestra base de datos en los dos grupos establecidos y, de aquí,derivaremos cómo clasificaríamos a una empresa nueva.
El programa calcula las llamadas funciones discriminantes lineales de Fisher,una para cada uno de los grupos. A partir de la información que aparece en elcuadro 12, estas funciones serían:
Joaquín Aldás ManzanoAnálisis discriminante14

51 3
52 3
44,23 7,87 12,5170,52 9,79 16,33
F X XF X X
= − + ⋅ + ⋅= − + ⋅ + ⋅
Cuadro 12. Salida de SPSS para las funciones de FisherCoeficientes de la función de clasificación
7,873 9,795
12,519 16,331
-44,239 -70,524
flexibilidad de precios
Servicio
(Constante)
Menos dela media
Más de lamedia
Intensidad de usodicotomizada
Funciones discriminantes lineales de Fisher
A continuación se calcula la llamada probabilidad a posteriori o Pr(g/D), quees la probabilidad de que, dado que la puntuación discriminante de un indivi-duo ha sido D, pertenezca al grupo g (en nuestro caso, al grupo 1 o al grupo2). Esto se hace del siguiente modo:
( )1 2
Pr / 1,2gF
F Feg D ge e= =+
Pues bien, el individuo se clasificará en aquel grupo para el que tenga unaprobabilidad a posteriori mayor. Si nos fijamos en la empresa 1 de la base dedatos HATCO, las variables X3 flexibilidad de precios y X5 servicio, tomanrespectivamente los valores 6’9 y 2’5, luego sus funciones discriminantes linealesde Fisher tomarán los valores:
1
2
44,23 7,87 6,9 12,51 2, 4 40,1370,52 9,79 6,9 16,33 2,4 36,25
FF
= − + ⋅ + ⋅ == − + ⋅ + ⋅ =
y las probabilidades a posteriori:
( )
( )
40,1340,13 36,25
36,2540,13 36,25
Pr 1/ 0,98
Pr 2/ 0,02
eg D e eeg D e e
= = =+= = =+
Joaquín Aldás ManzanoAnálisis discriminante15

luego a la empresa 1 se la clasificará en el grupo 1 que, en este caso, coincidecon el grupo real al que pertenece. Para clasificar a una nueva empresa bastarácon repetir los pasos señalados pero teniendo en cuenta la valoración quehagan de X3 y X5.
Paso 6. Validación de los resultados.
El último paso del análisis discriminante pasa por validar los resultados. Lamejor forma de hacerlo consiste en reservar parte de la muestra cuando seestima la función discriminante. Una vez obtenida esta, se clasifica mediante elprocedimiento que acaba de describirse a los individuos que no se utilizaronpara estimarla. Si el porcentaje de acierto es similar al de la muestra de estima-ción, el análisis sería válido.
4. Un ejemplo de aplicación del análisis discriminante para elcaso de tres grupos(Hair, Anderson, Tatham y Black, 1995; Uriel, 1997)
Vamos a ilustrar la aplicación del análisis discriminante para el caso de tresgrupos. Dado que la mayoría de los pasos anteriores son idénticos, nos centra-remos, sobre todo, en la interpretación de las funciones discriminantes, que esel elemento novedoso, al haber más de una.
El problema que analizamos es el mismo que en el caso anterior, con la diferen-cia de que la población aparece ahora dividida en tres grupos: el tercio de lasempresas que menos compran a HATCO, el tercio intermedio y el tercio quemás intensa relación mantienen con esta empresa. El objetivo es el mismo:establecer los determinantes de este uso y predecir a qué grupo perteneceránnuevas empresas.
El proceso es el mismo. Así, el cuadro 13 nos permite determinar que las varia-bles que se han incluído en las funciones discriminantes son las mismas que enel caso anterior: el servicio y la flexibilidad de precios. Obviamos el detalle delproceso paso a paso por ser análogo al anterior
Joaquín Aldás ManzanoAnálisis discriminante16

Cuadro 13. Variables de las funciones discriminantesVariables introducidas/eliminadas1,2,3,4
Servicio ,550 1 2 97,000 39,735 2 97,000 ,000
flexibilidadde precios ,316 2 2 97,000 37,446 4 192,000 ,000
1
2
Paso
Introducidas Estadístico gl1 gl2 gl3 Estadístico gl1 gl2 Sig.
F exacta
Lambda de Wilks
En cada paso se introduce la variable que minimiza la lambda de Wilks global.
El número máximo de pasos es 14.1. La F parcial mínima para entrar es 3.84.2. Maximum partial F to remove is 2.71.3. El nivel de F, la tolerancia o el VIN son insuficientes para continuar los cálculos.4.
Como en el caso de dos grupos, el cuadro 14, muestra que las dos funcionesdiscriminantes obtenidas son, también, globalmente significativas.
Cuadro 14. Significatividad global de la función discriminante
Lambda de Wilks
,316 111,300 4 ,000
,903 9,850 1 ,002
1 a la 2
2
Contraste de lasfunciones
Lambdade Wilks Chi-cuadrado gl Sig.
La mayor importancia de la primera función a la hora de separar los grupos,queda evidenciada por el hecho de que explica por sí misma más del 94% de lavarianza. Los indicadores η2 de bondad de ajuste (cuadro 15) conducen aconclusiones análogas.
Cuadro 15. Indicador ηη 2 de bondad de ajusteAutovalores
1,8611 94,5 94,5 ,807
,1071 5,5 100,0 ,312
1
2
Función
Autovalor % de varianza % acumuladoCorrelación
canónica
Se han empleado las 2 primeras funciones discriminantes canónicas en elanálisis.
1.
Joaquín Aldás ManzanoAnálisis discriminante17

Finalmente, la matriz de confusión, evidencia que la capacidad clasificatoria delas funciones obtenidas es menor que en el caso de dos grupos, al clasificaradecuadamente sólo al 77% de la muestra, siendo especialmente falible en elgrupo de uso intermedio.
Cuadro 16. Matriz de confusiónResultados de la clasificación1
27 7 0 34
4 21 9 34
0 3 29 32
79,4 20,6 ,0 100,0
11,8 61,8 26,5 100,0
,0 9,4 90,6 100,0
menor uso
uso intermedio
mayoruso
nivel deuso tresniveles
menor uso
uso intermedio
mayoruso
nivel deuso tresniveles
Recuento
%
Original
menor usouso
intermedio mayoruso
Grupo de pertenencia pronosticado
Total
Clasificados correctamente el 77,0% de los casos agrupados originales.1.
El último paso, una vez establecida la significatividad y precisión del proceso,es interpretar las funciones discriminantes. Ya hemos señalado la mayor impor-tancia relativa de la primera función a la hora de separar los grupos. Pues bien,como se comrpueba en los cuadros 17 y 18, ya utilizando el criterio de los coefi-cientes estandarizados, ya el de la matriz de estructura, son las variables flexi-bilidad de precios y servicio quienes determinan la función con pesos muyparecidos. La segunda función viene también explicada por estas variables, conla única diferencia de que el servicio tiene signo negativo
Cuadro 17. Coeficientes estandarizadosCoeficientes estandarizados de las funciones
discriminantes canónicas
,833 ,688
,952 -,511
flexibilidad de precios
Servicio
1 2
Función
Joaquín Aldás ManzanoAnálisis discriminante18

Cuadro 18. Matriz de estructuraMatriz de estructura
,612* -,040
,473 ,881*
,637 -,771*
,029 -,696*
-,286 -,299*
-,100 -,262*
-,049 -,174*
Rapidez de servicio1
flexibilidad de precios
Servicio
nivel de precios1
Calidad del producto1
Imagen del fabricante1
Imagen de losvendedores
1
1 2
Función
Correlaciones intra-grupo combinadas entre lasvariables discriminantes y las funcionesdiscriminantes canónicas tipificadas Variables ordenadas por el tamaño de lacorrelación con la función.
Mayor correlación absoluta entre cada variable ycualquier función discriminante.
*.
Esta variable no se emplea en el análisis.1.
Finalmente, para clasificar a los individuos se procede del mismo modo que enel caso de dos grupos, con la salvedad de que ahora se dispone de tres funcio-nes lineales de Fisher (cuadro 19). Se ilustra la clasificación de la empresanúmero 1 de la base de datos de HATCO.
Joaquín Aldás ManzanoAnálisis discriminante19

Cuadro 19. Funciones de FisherCoeficientes de la función de clasificación
7,924 8,895 10,367
13,118 16,855 18,622
-44,135 -61,370 -79,354
flexibilidad de precios
Servicio
(Constante)
menor usouso
intermedio mayoruso
nivel de uso tres niveles
Funciones discriminantes lineales de Fisher
Las funciones discriminantes son, pues:
51 3
52 3
53 3
44,13 7,92 13,1161,37 8,89 16,8579,35 10,36 18,62
F X XF X XF X X
= − + ⋅ + ⋅= − + ⋅ + ⋅= − + ⋅ + ⋅
y como para la primera empresa X3 = 6,9 y X5 = 2,4, estas funciones tomanlos valores:
1
2
3
44,13 7,92 6,9 13,11 2, 4 42,0261,37 8,89 6,9 16,85 2,4 40,4579,35 10,36 6,9 18,62 2,4 36,87
FFF
= − + ⋅ + ⋅ == − + ⋅ + ⋅ == − + ⋅ + ⋅ =
De tal modo que las probabilidades a posteriori serán:
( )
( )
( )
42,0242,02 40,45 36,87
40,4542,02 40,45 36,87
36,8742,02 40,45 36,87
Pr 1/ 0,82
Pr 2/ 0,17
Pr 3/ 0,01
eg D e e eeg D e e eeg D e e e
= = =+ += = =+ += = =+ +
con lo que la empresa ha sido clasificada en el grupo 1, correspondiente a aqueltercio que menos uso hace de los servicios de HATCO. Esta clasificaciónmediante la función discriminante coincide, en este caso, con la real. Cualquiernueva empresa podría clasificarse con una probabilidad calculable, sin más queconocer sus valoraciones de X3 y X5.
Joaquín Aldás ManzanoAnálisis discriminante20

Referencias bibliográficasHair, J.F.; Anderson, R.E.; Tatham, R.L. y Black; W.C. (1995): Multivariate
Data Analysis. 4ª edición. Englewood Cliffs, NJ: Prentice Hall.
Uriel, E. (1997): Análisis de datos. Series temporales y análisis multivariante.Madrid: AC.
Joaquín Aldás ManzanoAnálisis discriminante21





























