Embed Size (px)
Citation preview

Notas para un curso de Probabilidad y EstadısticaBorradores: Variables aleatorias (2)
Momentos
29 de marzo de 2010
Denme un punto de apoyo y movere el mundo
(Arquımedes de Siracusa)
1

Indice
1. Esperanza 21.1. Definicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2. Propiedades y calculo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3. Dividir y conquistar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2. Varianza 152.1. Definicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2. Propiedades y calculo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3. Algunas desigualdades 183.1. Cauchy-Schwartz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2. Chebyshev . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4. Covarianza y varianza de sumas 214.1. Covarianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.2. Varianza de sumas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5. La ley debil de los grandes numeros 24
6. Distribuciones particulares 27
7. Bibliografıa consultada 34
1. Esperanza
La informacion relevante sobre el comportamiento de una variable aleatoria esta con-tenida en su funcion de distribucion. En la practica, es util disponer de un numero repre-sentativo de la variable aleatoria que resuma toda esa informacion.
Motivacion Se gira una rueda de la fortuna varias veces. En cada giro se puede obteneralguno de los siguiente numeros x1, x2, . . . , xk -que representan la cantidad de dinero quese obtiene en el giro- con probabilidades p(x1), p(x2), . . . , p(xk), respectivamente. Cuantodinero se “espera” obtener como recompensa “por cada giro”. Los terminos “espera” y“por cada giro” son un tanto ambiguos, pero se pueden interpretar de la siguiente manera.
Supongamos que la rueda se gira n veces y que n(xi) es la cantidad de veces que seobtiene xi. Entonces, la cantidad total de dinero recibida es
∑ki=1 n(xi)xi y la cantidad
media por giro es µ = 1n
∑ki=1 n(xi)xi. Si n es suficientemente grande e interpretamos las
probabilidades como frecuencias relativas, obtenemos que la cantidad de dinero que se
2

“espera” recibir “por cada giro” es
µ =1
n
k∑
i=1
xi n(xi) =k∑
i=1
xin(xi)
n≈
k∑
i=1
xi p(xi).
Esta motivacion es suficiente para introducir la siguiente definicion.
1.1. Definicion
Definicion 1.1 (Esperanza de una variable discreta). Sea X una variable aleatoria disc-reta. La esperanza de X, denotada por E[X], es el promedio ponderado
E[X] :=∑
x∈A
xP(X = x), (1)
donde A = x ∈ R : F (x) − F (x−) > 0 es el conjunto de todos los atomos de la funciondistribucion de X.
La esperanza como centro de gravedad. La nocion de esperanza es analoga a lanocion de centro de gravedad para un sistema de partıculas discreto.
1 3 6 10
c
Figura 1: Interpretacion de la esperanza como centro de gravedad. Se considera un sis-tema de cuatro “partıculas” de pesos pi proporcionales a las areas de los cırculos de radio1/3, 2/3, 3/3, 4/3 centrados en los puntos xi = 1, 3, 6, 10, respectivamente. No se pierdegeneralidad si se supone que el peso total del sistema es la unidad. El centro de gravedaddel sistema se encuentra en el punto c =
∑4i=1 xipi = 227/30 = 7.56 . . .
Se consideran n partıculas ubicadas en los puntos x1, . . . , xn cuyos pesos respectivos sonp(x1), . . . , p(xn). No se pierde generalidad si se supone que
∑ni=1 p(xi) = 1. El centro de
gravedad, c, del sistema es el punto respecto de la cual la suma de los momentos causadospor los pesos p(xi) es nula. Observando que
k∑
i=1
(xi − c) p(xi) = 0 ⇔ c =k∑
i=1
xip(xi)
resulta que el centro de gravedad del sistema coincide con la esperanza de una variablealeatoria X a valores en x1, . . . , xn tal que P(X = xi) = p(xi).
3

La esperanza como promedio. Sea X una variable aleatoria discreta que toma valoresx1, x2, . . . , xn con igual probabilidad, P(X = xi) = 1/n, i = 1, . . . , n. Por definicion,
E[X] =n∑
i=1
xiP(X = xi) =1
n
n∑
i=1
xi.
Ejemplo 1.2 (Dado equilibrado). Sea X el resultado del lanzamiento de un dado equi-librado. X es una variable aleatoria discreta tal que P(X = x) = 1/6 para todo x ∈1, 2, 3, 4, 5, 6. De acuerdo con la definicion 1.1, la esperanza de X es
E[X] =6∑
x=1
xP(X = x) =1
6
6∑
x=1
x =21
6=
7
2.
Ejemplo 1.3 (Uniforme discreta). La variable aleatoria del Ejemplo 1.2 es un caso par-ticular de una variable aleatoria discreta X uniformemente distribuida sobre el “intervalo”de numeros enteros 1, 2, . . . , n. Para ser mas precisos, X es una variable aleatoria tal que
P(X = x) =1
n1x ∈ 1, 2, . . . , n.
Por definicion, la esperanza de X es
E[X] =n∑
x=1
xP(X = x) =1
n
n∑
x=1
x =1
n
(
n(n + 1)
2
)
=1 + n
2.
Ejemplo 1.4 (Moneda equilibrada). Sea N la cantidad de veces que debe lanzarse unamoneda equilibrada hasta que salga cara. N es una variable aleatoria discreta tal queP(N = n) = (1/2)n, n = 1, 2, . . . . De acuerdo con la definicion 1.1, la esperanza de N es
E[N ] =∞∑
n=1
nP(N = n) =∞∑
n=1
n
(
1
2
)n
.
Derivando ambos lados de la igualdad∑∞
n=0 xn = (1−x)−1, que vale para |x| < 1, se deduceque
∑∞n=0 nxn−1 = (1 − x)−2 y de allı resulta que
∑∞n=1 nxn = x(1 − x)−2. Evaluando en
x = 1/2 se obtiene que
E[N ] =∞∑
n=1
n
(
1
2
)n
=
(
1
2
)(
1
2
)−2
= 2.
Proposicion 1.5 (Esperanza de la funcion indicadora). Sea (Ω,A, P) un espacio de prob-abilidad. Cualquiera sea el evento A ∈ A vale que
E[1ω ∈ A] = P(A). (2)
4

Demostracion. Por definicion, E[1ω ∈ A] = 0 · (1 − P(A)) + 1 · P(A).
La nocion de esperanza se puede extender a variables aleatorias absolutamente continuas
cambiando en (1) la suma por la integral y la funcion de probabilidades P (X = x), x ∈ A,por la densidad de probabilidades de la variable X.
Definicion 1.6 (Esperanza de una variable absolutamente continua). Sea X una variablealeatoria absolutamente continua con densidad de probabilidades fX(x). La esperanza de
X, denotada por E[X], se define por
E[X] :=
∫ ∞
−∞xfX(x)dx. (3)
Ejemplo 1.7 (Fiabilidad). Sea T el tiempo de espera hasta la primer falla de un sistemaelectronico con funcion intensidad de fallas de la forma λ(t) = 2t1t > 0. La funcion dedistribucion de T es FT (t) = (1 − exp (−t2))1t > 0. En consecuencia, T es una variablealeatoria absolutamente continua con densidad de probabilidad fT (t) = 2t exp (−t2)1t >0. De acuerdo con la definicion 1.6, la esperanza de T es
E[T ] =
∫ ∞
−∞tfT (t)dt =
∫ ∞
0
t2t exp(−t2)dt =
∫ ∞
0
exp(−t2)dt =
√π
2.
La tercera igualdad se deduce de la formula de integracion por partes aplicada a u = t yv′ = 2t exp(−t2) y la cuarta se deduce de la identidad
∫∞0
exp(−x2/2)dx =√
2π/2 mediante
el cambio de variables t = x/√
2.
Extendiendo la nocion a variables mixtas. La nocion de esperanza para variablesmixtas se obtiene combinando adecuadamente las nociones anteriores.
Definicion 1.8 (Esperanza de una variable mixta). Sea X una variable aleatoria mixtacon funcion de distribucion FX(x). La esperanza de X, denotada por E[X], se define de lasiguiente manera:
E[X] =∑
x∈A
xP(X = x) +
∫ ∞
−∞xF ′
X(x)dx, (4)
donde A = x ∈ R : FX(x) − FX(x−) > 0 es el conjunto de todos los atomos de FX(x) yF ′
X(x) es una funcion que coincide con la derivada de FX(x) salvo en el conjunto de puntos
A ∪
x ∈ R : 6 ∃ lımh→0
FX(x + h) − FX(x)
h
.
Ejemplo 1.9 (Mixtura). Sea X una variable aleatoria mixta cuya funcion de distribuciones FX(x) =
(
2x+58
)
1−1 ≤ x < 1 + 1x ≥ 1. De acuerdo con formula (4), la esperanzade X es
E[X] = −1 · P(X = −1) + 1 · P(X = 1) +
∫ 1
−1
F ′X(x)dx = −3
8+
1
8+
∫ 1
−1
2
8dx =
1
4.
5

Nota Bene. En todas las definiciones anteriores, se presupone que las series y/o inte-grales involucradas son absolutamente convergentes.
Ejemplo 1.10 (Distribucion de Cauchy). Sea X una variable aleatoria con distribucion de
Cauchy. Esto es, X es absolutamente continua y admite una densidad de probabilidadesde la forma
f(x) =1
π(1 + x2).
Debido a que∫ ∞
−∞|x|f(x)dx =
∫ ∞
−∞
|x|π(1 + x2)
dx = ∞,
X no tiene esperanza.
1.2. Propiedades y calculo
Proposicion 1.11.(a) Si X es una variable positiva, entonces E[X] > 0.(b) E[1] = 1;(c) E[aX + b] = aE[X] + b, para todo a, b ∈ R.
Demostracion. Para evitar dificultades tecnicas supondremos que X es una variablediscreta.
(a) Si la variable es positiva, su esperanza no es otra cosa que una suma de cantidadespositivas, por lo tanto es positiva.
(b) 1 puede ser visto como una variable discreta que asume solamente el valor 1. Tienepor lo tanto, distribucion de probabilidades P(X = 1) = 1 y P(X = x) = 0 para x 6= 0, elresultado es consecuencia inmediata de la definicion (1).
(c)
E[aX + b] =∑
y∈aA+b
yP(aX + b = y) =∑
x∈A
(ax + b)P(X = x)
= a∑
x∈A
xP(X = x) + b∑
x∈A
P(X = x) = aE[X] + b.
Ejemplo 1.12 (Uniforme discreta). La variable aleatoria del Ejemplo 1.3 es un caso par-ticular de una variable aleatoria discreta X uniformemente distribuida sobre un “intervalo”de numeros enteros a, a + 1, . . . , b, donde a y b son dos enteros tales que a < b. Para sermas precisos, X es una variable aleatoria tal que
P(X = x) =1
b − a + 11x ∈ a, a + 1, . . . , b.
6
Notando que la distribucion de X coincide con la de la variable X∗ + a − 1, donde X∗
esta uniformemente distribuida sobre 1, . . . , b − a + 1, resulta que
E[X] = E[X∗] + a − 1 =1 + (b − a + 1)
2+ a − 1 =
a + b
2.
Teorema 1.13. Sea X una variable aleatoria no negativa (i.e., FX(x) = P(X ≤ x) = 0para todo x < 0). Vale que
E[X] =
∫ ∞
0
[1 − FX(x)] dx. (5)
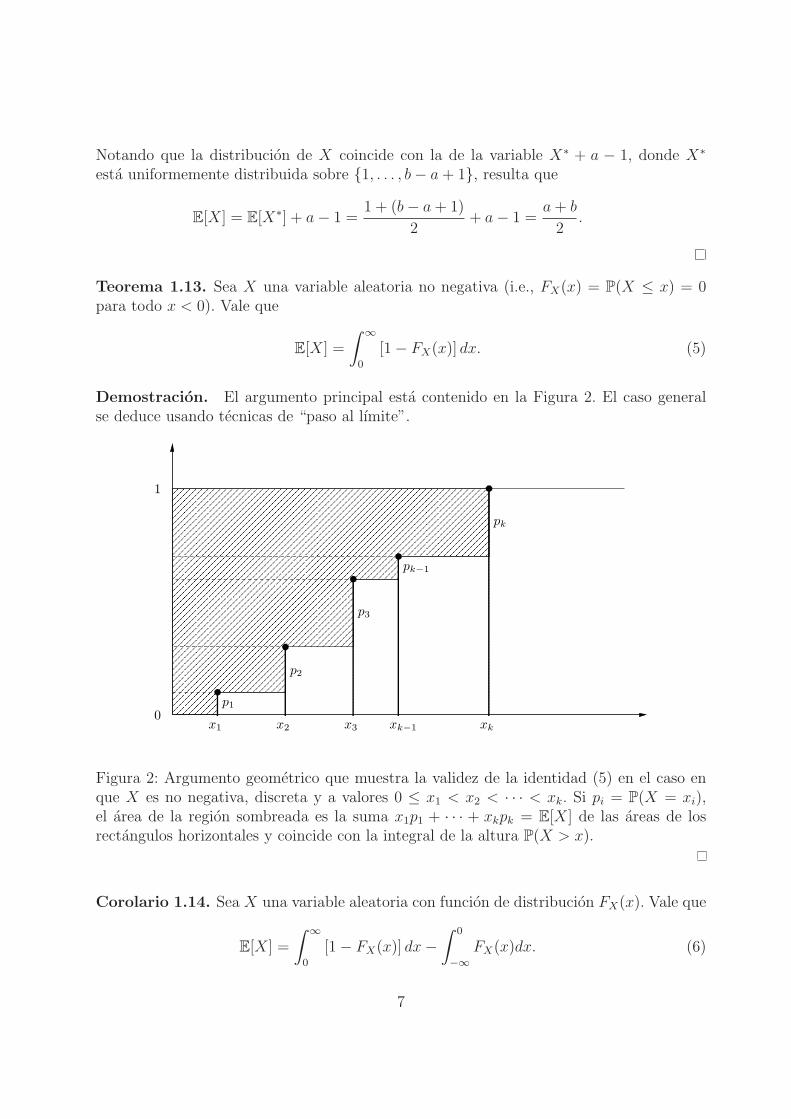
Demostracion. El argumento principal esta contenido en la Figura 2. El caso generalse deduce usando tecnicas de “paso al lımite”.
p2
p3
pk
1
x1
p1
pk−1
x2 x3 xk−1 xk0
Figura 2: Argumento geometrico que muestra la validez de la identidad (5) en el caso enque X es no negativa, discreta y a valores 0 ≤ x1 < x2 < · · · < xk. Si pi = P(X = xi),el area de la region sombreada es la suma x1p1 + · · · + xkpk = E[X] de las areas de losrectangulos horizontales y coincide con la integral de la altura P(X > x).
Corolario 1.14. Sea X una variable aleatoria con funcion de distribucion FX(x). Vale que
E[X] =
∫ ∞
0
[1 − FX(x)] dx −∫ 0
−∞FX(x)dx. (6)
7

Demostracion. Ejercicio.
Nota Bene. Las identidades (5) y (6) son interesantes porque muestran que la paracalcular la esperanza de una variable aleatoria basta conocer su funcion de distribucion.De hecho, la identidad (6) ofrece una definicion alternativa y unificada de la nocion deesperanza.
Ejemplo 1.15. Una maquina fue disenada para prestar servicios en una instalacion pro-ductiva. La maquina se enciende al iniciar la jornada laboral y se apaga al finalizar lamisma. Si durante ese perıodo la maquina falla, se la repara y en esa tarea se consume elresto de la jornada.
(a) Si se supone que la funcion intensidad de fallas de la maquina es una constanteλ > 0 (y que el tiempo se mide en jornadas laborales), cual es el maximo valor de λ quepermite asegurar que la maquina prestara servicios durante una jornada laboral completacon probabilidad no inferior a los 2/3?
(b) Para ese valor de λ, hallar (y graficar) la funcion de distribucion del tiempo, T , defuncionamiento de la maquina durante una jornada laboral y calcular el tiempo medio defuncionamiento, E[T ].
Solucion.(a) Si T1 es el tiempo que transcurre desde que se enciende la maquina hasta que ocurre
la primer falla, el evento “la maquina funciona durante una jornada laboral completa” sedescribe mediante T1 > 1. Queremos hallar el maximo λ > 0 tal que P(T1 > 1) ≥ 2/3.Debido a que la funcion intensidad de fallas es una constante λ se tiene que P(T1 > t) =e−λt. En consecuencia, P(T1 > 1) ≥ 2/3 ⇐⇒ e−λ ≥ 2/3 ⇐⇒ λ ≤ − log(2/3). Por lotanto,
λ = − log(2/3).
En tal caso, P(T > 1) = 2/3.(b) El tiempo de funcionamiento de la maquina durante una jornada laboral es
T := mınT1, 1.
Para t > 0 vale que
FT (t) = P(T ≤ t) = 1 − P(T > t) = 1 − P(mınT1, 1 > t)
= 1 − P(T1 > t)11 > t = 1 − elog(2/3)t1t < 1=
(
1 − elog(2/3)t)
10 ≤ t < 1 + 1t ≥ 1.
8
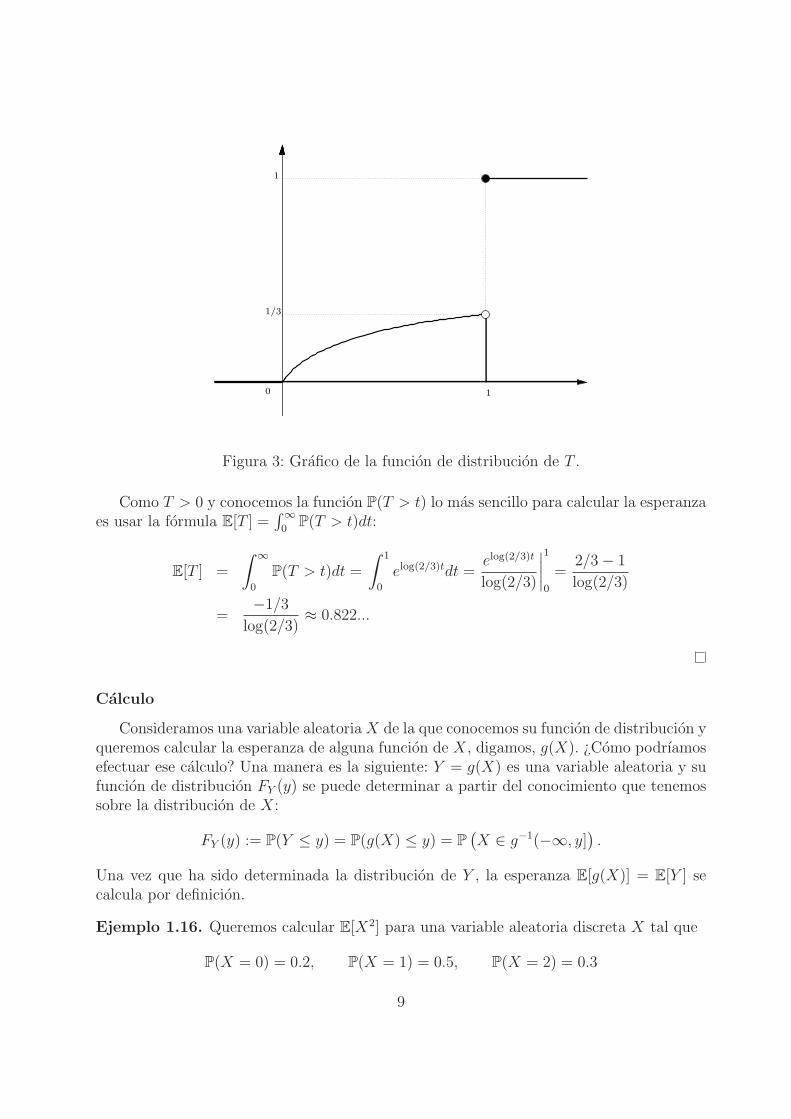
0
1/3
1
1
Figura 3: Grafico de la funcion de distribucion de T .
Como T > 0 y conocemos la funcion P(T > t) lo mas sencillo para calcular la esperanzaes usar la formula E[T ] =
∫∞0
P(T > t)dt:
E[T ] =
∫ ∞
0
P(T > t)dt =
∫ 1
0
elog(2/3)tdt =elog(2/3)t
log(2/3)
∣
∣
∣
∣
1
0
=2/3 − 1
log(2/3)
=−1/3
log(2/3)≈ 0.822...
Calculo
Consideramos una variable aleatoria X de la que conocemos su funcion de distribucion yqueremos calcular la esperanza de alguna funcion de X, digamos, g(X). ¿Como podrıamosefectuar ese calculo? Una manera es la siguiente: Y = g(X) es una variable aleatoria y sufuncion de distribucion FY (y) se puede determinar a partir del conocimiento que tenemossobre la distribucion de X:
FY (y) := P(Y ≤ y) = P(g(X) ≤ y) = P(
X ∈ g−1(−∞, y])
.
Una vez que ha sido determinada la distribucion de Y , la esperanza E[g(X)] = E[Y ] secalcula por definicion.
Ejemplo 1.16. Queremos calcular E[X2] para una variable aleatoria discreta X tal que
P(X = 0) = 0.2, P(X = 1) = 0.5, P(X = 2) = 0.3
9

Poniendo Y = X2 obtenemos una variable aleatoria a valores en 02, 12, 22 tal que
P(Y = 0) = 0.2, P(Y = 1) = 0.5, P(Y = 4) = 0.3
En consecuencia,E[X2] = E[Y ] = 0(0.2) + 1(0.5) + 4(0.3) = 1.7
Ejemplo 1.17. Sea X una variable aleatoria con distribucion uniforme sobre el intervalo(0, 1). Queremos calcular E[X3].
Ponemos Y = X3 y calculamos su funcion de distribucion. Para cada 0 < y < 1,
FY (y) = P(Y ≤ y) = P(X3 ≤ y) = P(X ≤ y1/3) = y1/3.
Derivamos FY (y) y obtenemos la densidad de probabilidad de Y
fY (y) =1
3y−2/310 < y < 1.
En consecuencia,
E[X3] = E[Y ] =
∫ ∞
−∞yfY (y)dy =
∫ 1
0
y1
3y−2/3dy =
1
3
∫ 1
0
y1/3dy =1
3
3
4y4/3
∣
∣
∣
∣
1
0
=1
4.
Existe una manera mucho mas simple para calcular la esperanza de Y = g(X) que norecurre al procedimiento de determinar primero la distribucion de Y para luego calcularsu esperanza por definicion. La siguiente proposicion muestra como hacerlo.
Teorema 1.18. Sea X una variable aleatoria con funcion de distribucion FX(x) y seag : R → R una funcion tal que g(X) es una variable aleatoria.
(a) Si X es discreta con atomos en el conjunto A, entonces
E[g(X)] =∑
x∈A
g(x)P(X = x). (7)
(b) Si X es continua con densidad de probabilidad fX(x) y g(X) es continua, entonces
E[g(X)] =
∫ ∞
−∞g(x)fX(x)dx. (8)
(c) Si X es mixta,
E[g(X)] =∑
x∈A
g(x)P(X = x) +
∫ ∞
−∞g(x)F ′
X(x)dx, (9)
donde A es el conjunto de todos los atomos de FX(x) y F ′X(x) es un funcion que coincide
con la derivada de FX(x) en todos los puntos donde esta derivada existe y vale cero en otrolado.
10

Ejemplo 1.19. Aplicando la parte (a) de la Proposicion 1.18 al Ejemplo 1.16 se obtiene
E[X2] = 02(0.2) + 12(0.5) + 22(0.3) = 1.7
Ejemplo 1.20. Aplicando la parte (b) de la Proposicion 1.18 al Ejemplo 1.17 se obtiene
E[X3] =
∫ 1
0
x3dx =1
4
Demostracion del Teorema 1.18.(a) La demostracion se obtiene agrupando todos los terminos que tienen el mismo valor
g(x). Sea Y = g(X), por definicion,
E[g(X)] = E[Y ] =∑
y∈g(A)
y P(Y = y) =∑
y∈g(A)
y P(g(X) = y)
=∑
y∈g(A)
y P(
X ∈ g−1(y))
=∑
y∈g(A)
y∑
x∈g−1(y)
P (X = x)
=∑
y∈g(A)
∑
x∈g−1(y)
y P (X = x) =∑
y∈g(A)
∑
x∈g−1(y)
g(x) P (X = x)
=∑
x∈A
g(x) P (X = x)
pues A =⋃
y∈g(A)
g−1(y)
.
(b) Para simplificar la prueba vamos a suponer que g ≥ 0. De acuerdo con el Teorema1.13
E[g(X)] =
∫ ∞
0
P(g(X) > y)dy =
∫ ∞
0
(∫
x: g(x)>yf(x)dx
)
dy.
Intercambiando el orden de integracion obtenemos
E[g(X)] =
∫ ∞
−∞
(
∫ g(x)
0
dy
)
f(x)dx =
∫ ∞
−∞g(x)f(x)dx.
(c) Se obtiene combinando adecuadamente los resultados (a) y (b).
Nota Bene. Como consecuencia del Teorema 1.18 se deduce que
E
[
n∑
k=0
akXk
]
=n∑
k=0
akE[Xk]. (10)
11

Teorema 1.21 (Calculo de Esperanzas). Sea X un vector aleatorio y sea g : Rn → R una
funcion tal que g(X) es una variable aleatoria. Si la variable aleatoria g(X) tiene esperanzafinita, entonces
E[g(X)] =
∑
xg(x)pX(x) en el caso discreto,
∫
Rn g(x)fX(x) dx en el caso continuo,
donde, segun sea el caso, pX(x) y fX(x) son la funcion de probabilidad y la densidadconjunta del vector X, respectivamente.
Demostracion. Enteramente analoga a la que hicimos en dimension 1.
Sobre el calculo de esperanzas. El Teorema 1.21 es una herramienta practica paracalcular esperanzas. Su resultado establece que si queremos calcular la esperanza de unatransformacion unidimensional del vector X, g(X), no necesitamos calcular la distribucionde g(X). La esperanza E[g(X)] puede calcularse directamente a partir del conocimiento dela distribucion conjunta de X.
Corolario 1.22. Si la media µXi:= E[Xi] de la variable Xi existe, se puede calcular de la
siguiente manera
µXi=∑
x
xipX(x), (11)
en el caso discreto; y
µXi=
∫
Rn
xifX(x)dx, (12)
en el caso continuo.
Corolario 1.23 (Linealidad de la esperanza). Si X1, X2, . . . , Xn son variables aleatoriascon media finita y a1, a2, . . . , an son n constantes, entonces
E
[
n∑
i=1
aiXi
]
=n∑
i=1
aiE[Xi] (13)
Corolario 1.24 (Monotonıa). Si las variables X e Y tienen esperanza finita y satisfacen
que X ≤ Y , entonces E[X] ≤ E[Y ].
Corolario 1.25 (Regla del producto independiente). Si las variables X1, . . . , Xn son inde-pendientes con esperanza finita, entonces el producto tiene esperanza finita y coincide conel producto de las esperanzas:
E
[
n∏
i=1
Xi
]
=n∏
i=1
E[Xi]. (14)
12

1.3. Dividir y conquistar
Teorema 1.26 (Esperanza de una variable truncada). Sea X una variable aleatoria defini-da sobre un espacio de probabilidad (Ω,A, P). Sea A ⊂ R un conjunto tal que X ∈ A =X−1(A) = ω ∈ Ω : X(ω) ∈ A ∈ A y tal que P(X ∈ A) > 0. Entonces
E[X|X ∈ A] =1
P(X ∈ A)E[X1X ∈ A] (15)
Demostracion. Para simplificar la exposicion vamos a suponer que la variable aleatoriaX es discreta. En ese caso la funcion de probabilidad de X|X ∈ A adopta la forma
pX|X∈A(x) =P(X = x)
P(X ∈ A)1x ∈ A.
En consecuencia, la esperanza de la variable truncada X|X ∈ A es
E[X|X ∈ A] =∑
x∈X(Ω)
xP(X = x)
P(X ∈ A)1x ∈ A
=1
P(X ∈ A)
∑
x∈X(Ω)
x1x ∈ AP(X = x)
=1
P(X ∈ A)E[X1X ∈ A].
La ultima igualdad es consecuencia del Teorema 1.18.
Ejemplo 1.27 (Dado equilibrado). Sea X el resultado del tiro de un dado equilibrado ysea A = 2, 4, 6. De acuerdo con (15) la esperanza de X|X ∈ A es
E[X|X ∈ A] =1
P(X ∈ A)E[X1X ∈ A] =
1
1/2
(
2
6+
4
6+
6
6
)
= 4.
Resultado que por otra parte es intuitivamente evidente.
Motivacion. El resultado siguiente es una version general del resultado que permitecalcular el promedio de una muestra de n + m valores x1, . . . , xn, xn+1, . . . , xn+m a partirde los promedios de las submuestras, x1, . . . , xn y xn+1, . . . , xn+m.
Si
x1,n =1
n
n∑
i=1
xi, xn+1,n+m =1
m
m∑
j=1
xn+j
son los promedios de las submuestras x1, . . . , xn y xn+1, . . . , xn+m, respectivamente y
x1,n+m =1
n + m
n+m∑
i=1
xi
13

es el promedio de la muestra x1, . . . , xn+m. Entonces, el promedio x1,n+m es igual al prome-dio ponderado de los promedios parciales, x1,n y xn+1,n+m:
xn+m = xn
(
n
n + m
)
+ xm
(
m
n + m
)
.
Teorema 1.28 (Formula de probabilidad total). Sea X una variable aleatoria. Si A1,A2, . . . , An es una particion medible de R tal que P(X ∈ Ai) > 0, i = 1, . . . , n. Entonces,
E[X] =n∑
i=1
E[X|X ∈ Ai]P(X ∈ Ai). (16)
Demostracion. Descomponer la variable X en una suma de variables (dependientes dela particion) X =
∑ni=1 X1X ∈ Ai. Usar la linealidad de la esperanza para obtener
E[X] =n∑
i=1
E[X1X ∈ Ai]
y usar que
E[X|X ∈ Ai] =1
P(X ∈ Ai)E[X1X ∈ Ai].
Nota Bene. Sea g : R → R una funcion tal que g(X) es una variable aleatoria. Bajo lashipotesis del Teorema 1.28 tambien vale que
E[g(X)] =n∑
i=1
E[g(X)|X ∈ Ai]P(X ∈ Ai). (17)
La formula (17) se puede extender sin ninguna dificultad al caso multidimensional.
Ejemplo 1.29 (Dividir y conquistar). Todas las mananas Lucas llega a la estacion delsubte entre las 7:10 y las 7:30 (con distribucion uniforme en el intervalo). El subte llega ala estacion cada quince minutos comenzando a las 6:00. Calcular la media del tiempo quetiene que esperar hasta subirse al subte.
Sea X el tiempo de llegada de Lucas a la estacion del subte. El tiempo de espera hastasubirse al subte es
T = (7.15 − X)1X ∈ [7 : 10, 7 : 15] + (7 : 30 − X)1X ∈ (7 : 15, 7 : 30].Ahora bien, dado que X ∈ [7 : 10, 7 : 15], la distribucion de T es uniforme sobre el intervalo[0, 5] minutos y dado que X ∈ (7 : 15, 7 : 30] la distribucion de T es uniforme sobre elintervalo [0, 15] minutos. De acuerdo con (17)
E[T ] =5
2
(
5
20
)
+15
2
(
15
20
)
= 6.25.
14

2. Varianza
2.1. Definicion
La esperanza de una variable aleatoria X, E[X], tambien se conoce como la media oel primer momento de X. La cantidad E[Xn], n ≥ 1, se llama el n-esimo momento de X.Si la esperanza E[X] es finita, la cantidad E[(X − E[X])n] se llama el n-esimo momento
central.La segunda cantidad en orden de importancia, despues de la esperanza, para resumir
el comportamiento de una variable aleatoria X es su segundo momento central tambienllamado la varianza de X.
Definicion 2.1 (Varianza). Sea X una variable aleatoria con esperanza, E[X] finita. Lavarianza de X se define por
V(X) := E[
(X − E[X])2]
. (18)
En otras palabras, la varianza de X es la esperanza de la variable aleatoria (X−E[X])2.Puesto que (X −E[X])2 solo puede tomar valores no negativos, la varianza es no negativa.
La varianza de X es una de las formas mas utilizadas para medir la dispersion de losvalores de X respecto de su media. Otra medida de dispersion es el llamado desvıo estandar
de X, que se define como la raız cuadrada de la varianza y se denota σ(X):
σ(X) :=√
V(X). (19)
A diferencia de la varianza, el desvıo estandar de una variable aleatoria es mas facil deinterpretar porque tiene las mismas unidades de X.
Nota Bene: Grandes valores de V(X) significan grandes variaciones de los valores de Xalrededor de la media. Al contrario, pequenos valores de V(X) implican una pronunciadaconcentracion de la masa de la distribucion de probabilidades en un entorno de la media.En el caso extremo, cuando la varianza es 0, la masa total de la distribucion de probabil-idades se concentra en la media. Estas afirmaciones pueden hacerse mas precisas y serandesarrolladas en la seccion 3.
2.2. Propiedades y calculo
Proposicion 2.2. Para todo a, b ∈ R
V(aX + b) = a2V(X). (20)
Demostracion. Debido a que la esperanza es un operador lineal, E[aX +b] = aE[X]+b.En consecuencia, aX + b − E[aX + b] = a(X − E[X]). Por lo tanto,
V(aX + b) = E[(aX + b − E[aX + b])2] = E[a2(X − E[X])2] = a2V(X).
15

Calculo
Una manera “brutal” de calcular V(X) es calcular la funcion de distribucion de la vari-able aleatoria (X −E[X])2 y usar la definicion de esperanza. En lo que sigue mostraremosuna manera mas simple de realizar este tipo calculo.
Proposicion 2.3 (Expresion de la varianza en terminos de los momentos). Sea X unavariable aleatoria con primer y segundo momentos finitos, entonces
V(X) = E[X2] − E[X]2. (21)
En palabras, la varianza es la diferencia entre el segundo momento y el cuadrado del primermomento.
Demostracion. Desarrollar el cuadrado (X −E[X])2 y usar las propiedades de la esper-anza. Poniendo (X − E[X])2 = X2 − 2XE[X] + E[X]2 se obtiene
V(X) = E[X2] − 2XE[X] + E[X]2 = E[X2] − 2E[X]2 + E[X]2 = E[X2] − E[X]2.
Ejemplo 2.4 (Dado equilibrado). Sea X el resultado del lanzamiento de un dado equili-brado. Segun lo visto en el Ejemplo 1.2, E[X] = 7
2. Por otra parte
E[X2] =6∑
x=1
x2P(X = x)
= 12
(
1
6
)
+ 22
(
1
6
)
+ 32
(
1
6
)
+ 42
(
1
6
)
+ 52
(
1
6
)
+ 62
(
1
6
)
=91
6.
Por lo tanto, de acuerdo con la Proposicion 2.3, la varianza de X es
V(X) =91
6−(
7
2
)2
=32
12.
Ejemplo 2.5 (Uniforme discreta). Sean a y b dos numeros enteros tales que a < b y seaX una variable aleatoria discreta con distribucion uniforme sobre el “intervalo” [a, b] :=a, a + 1, . . . , b. Para calcular la varianza de X, consideramos primero el caso mas simpledonde a = 1 y b = n.
Por induccion en n se puede ver que
E[X2] =1
n
n∑
k=1
k2 =(n + 1)(2n + 1)
6.
16

La varianza puede obtenerse en terminos de los momentos de orden 1 y 2:
V(X) = E[X2] − E[X]2 =(n + 1)(2n + 1)
6− (n + 1)2
4
=(n + 1)[2(2n + 1) − 3(n + 1)]
12=
n2 − 1
12.
Para el caso general, notamos que la variable aleatoria uniformemente distribuida sobre[a, b] tiene la misma varianza que la variable aleatoria uniformemente distribuida sobre[1, b − a + 1], puesto que esas dos variables difieren en la constante a − 1. Por lo tanto, lavarianza buscada se obtiene de la formula anterior sustituyendo n = b − a + 1
V(X) =(b − a + 1)2 − 1
12=
(b − a)(b − a + 2)
12.
Ejemplo 2.6 (Fiabilidad). Sea T el tiempo de espera hasta la primer falla de un sistemaelectronico con funcion intensidad de fallas de la forma λ(t) = 2t1t > 0. Segun lo vistoen el Ejemplo 1.7, E[T ] =
√π/2. Por otra parte,
E[T 2] =
∫ ∞
−∞t2f(t)dt =
∫ ∞
0
t22t exp(−t2)dt =
∫ ∞
0
xe−xdx = 1.
La tercera igualdad se obtiene mediante el cambio de variables t2 = x y la cuarta se deduceusando la formula de integracion por partes aplicada a u = x y v′ = e−x.
Por lo tanto, de acuerdo con la Proposicion 2.3, la varianza de T es
V(T ) = 1 −(√
π
2
)2
= 1 − π
4.
Proposicion 2.7 (Varianza de la funcion indicadora). Sea (Ω,A, P) un espacio de proba-bilidad. Cualquiera sea el evento A ∈ A vale que
V(1ω ∈ A) = P(A)(1 − P(A)). (22)
Demostracion. Observar que 1ω ∈ A2 = 1ω ∈ A y usar la identidad (21) combi-nada con la identidad (2): V(1ω ∈ A) = P(A) − P(A)2 = P(A)(1 − P(A)).
Error cuadratico medio. Una manera de “representar” la variable aleatoria X medi-ante un valor fijo c ∈ R es hallar el valor c que minimice el llamado error cuadratico medio,E[(X − c)2].
Teorema 2.8 (Pitagoras). Sea X una variable aleatoria con esperanza y varianza finitas.Para toda constante c ∈ R vale que
E[(X − c)2] = V(X)2 + (E[X] − c)2.
En particular, el valor de c que minimiza el error cuadratico medio es la esperanza de X,E[X].
17

Demostracion. Escribiendo X − c en la forma X − E[X] + E[X] − c y desarrollandocuadrados se obtiene (X − c)2 = (X − E[X])2 + (E[X] − c)2 + 2(X − E[X])(E[X] − c). Elresultado se obtiene tomando esperanza en ambos lados de la igualdad y observando queE[X − E[X]] = 0.
3. Algunas desigualdades
3.1. Cauchy-Schwartz
Teorema 3.1 (Cauchy-Schwartz).
E[|XY |] ≤ (E[X2]E[Y 2])1/2 (23)
Demostracion. Observar que para todo t ∈ R:
0 < E[(t|X| + |Y |)2] = t2E[X2] + 2tE[|XY |] + E[Y 2].
Como la cuadratica en t que aparece en el lado derecho de la igualdad tiene a lo sumo unaraız real se deduce que
4E[|XY |]2 − 4E[X2]E[Y 2] ≤ 0.
Por lo tanto,
E[|XY |]2 ≤ E[X2]E[Y 2].
Corolario 3.2. Sea X una variable aleatoria tal que E[X2] < ∞ y a < E[X]. Entonces
P(X > a) ≥ (E[X] − a)2
E[X2].
Demostracion. De la desigualdad X1X > a ≤ |X1X > a| y de la propiedad demonotonıa de la esperanza se deduce que
E[X1X > a] ≤ E[|X1X > a|]. (24)
Aplicando la desigualdad de Cauchy-Schwartz a |X1X > a| se obtiene que
E[|X1X > a|] ≤ (E[X2]E[1X > a2])1/2 = (E[X2]P(X > a))1/2 (25)
Observando que X = X1X > a + X1X ≤ a y que X1X ≤ a ≤ a se deduce que
E[X] = E[X1X > a] + E[X1X ≤ a] ≤ E[X1X > a] + a
18

y en consecuencia,
E[X] − a ≤ E[X1X > a]. (26)
Combinando las desigualdades (26), (24) y (25) se obtiene que
E[X] − a ≤ (E[X2]P(X > a))1/2
y como E[X] − a > 0, elevando al cuadrado, se concluye que
(E[X] − a)2 ≤ E[X2]P(X > a).
El resultado se obtiene despejando.
3.2. Chebyshev
Teorema 3.3 (Desigualdad de Chebyshev). Sea ϕ : R → R tal que ϕ ≥ 0 y A ∈ B(R).Sea iA := ınfϕ(x) : x ∈ A. Entonces,
iAP(X ∈ A) ≤ E[ϕ(X)] (27)
Demostracion. La definicion de iA y el hecho de que ϕ ≥ 0 implican que
iA1X ∈ A ≤ ϕ(X)1X ∈ A ≤ ϕ(X)
El resultado se obtiene tomando esperanza.En lo que sigue enunciaremos algunos corolarios que se obtienen como casos particulares
del Teorema 3.3.
Corolario 3.4 (Desigualdad de Markov). Sea X una variable aleatoria a valores no neg-ativos. Para cada a > 0 vale que
P(X ≥ a) ≤ E[X]
a. (28)
Demostracion. Aplicar la desigualdad de Chebyshev usando la funcion ϕ(x) = x re-stringida a la semi-recta no negativa [0,∞) y el conjunto A = [a,∞) para obtener
aP(X ≥ a) ≤ E[ϕ(X)] = E[X].
y despejar.
Corolario 3.5. Sea a > 0. Vale que
P(X > a) ≤ 1
a2E[X2]. (29)
19

Demostracion. Aplicar la desigualdad de Chebyshev usando la funcion ϕ(x) = x2 y elconjunto A = (a,∞) para obtener
a2P(X > a) ≤ E[X2]
y despejar.
Corolario 3.6 (Pequena desigualdad de Chebyshev). Sea X una variable aleatoria devarianza finita. Para cada a > 0 vale que
P(|X − E[X]| ≥ a) ≤ V(X)
a2. (30)
Demostracion. Debido a que (X−E[X])2 es una variable aleatoria no negativa podemosaplicar la desigualdad de Markov (poniendo a2 en lugar de a) y obtenemos
P(
(X − E[X])2 ≥ a2)
≤ E[(X − E[X])2]
a2=
V(X)
a2.
La desigualdad (X − E[X])2 ≥ a2 es equivalente a la desigualdad |X − E[X]| ≥ a. Por lotanto,
P (|X − E[X]| ≥ a) ≤ V(X)
a2.
Lo que concluye la demostracion.
Nota Bene. Grosso modo la pequena desigualdad de Chebyshev establece que si lavarianza es pequena, los grandes desvıos respecto de la media son improbables.
Corolario 3.7. Sea X una variable aleatoria con media µ y varianza σ2, entonces paracada λ > 0
P(|X − E[X]| ≥ ασ(X)) ≤ 1
α2. (31)
El resultado se obtiene poniendo a = ασ(X) en la pequena desigualdad de Chebyshev.
Ejemplo 3.8. La cantidad X de artıculos producidos por un fabrica durante una semanaes una variable aleatoria de media 500.
(a) ¿Que puede decirse sobre la probabilidad de que la produccion semanal supere los1000 artıculos? Por la desigualdad de Markov,
P (X ≥ 1000) ≤ E[X]
1000=
500
1000=
1
2.
20

(b) Si la varianza de la produccion semanal es conocida e igual a 100, ¿que puede decirsesobre la probabilidad de que la produccion semanal se encuentre entre 400 y 600 artıculos?Por la desigualdad de Chebyshev,
P (|X − 500| ≥ 100) ≤ σ2
(100)2=
1
100.
Por lo tanto, P (|X − 500| < 100) ≥ 1 − 1100
= 99100
, la probabilidad de que la produccionsemanal se encuentre entre 400 y 600 artıculos es al menos 0.99.
Las desigualdades de Markov y Chebyshev son importantes porque nos permiten de-ducir cotas sobre las probabilidades cuando solo se conocen la media o la media y lavarianza de la distribucion de probabilidades.
El que mucho abarca poco aprieta. Es muy importante tener en cuenta que lasdesigualdades de Markov y de Chebyshev producen cotas universales que no dependende las distribuciones de las variables aleatorias (dependen pura y exclusivamente de losvalores de la esperanza y de la varianza). Por este motivo su comportamiento sera bastanteheterogeneo: en algunos casos produciran cotas extremadamente finas, pero en otros casossolamente cotas groseras.
4. Covarianza y varianza de sumas
4.1. Covarianza
Sean X e Y dos variables aleatorias definidas sobre el mismo espacio de probabilidad(Ω,A, P). Entonces, X + Y y XY son variables aleatorias. El objetivo de esta seccion escalcular, cuando exista, V(X + Y ). Para ello se introduce la nocion de covarianza.
Observando que |xy| ≤ 12(x2 + y2), se deduce que si las esperanzas E[X2] y E[Y 2] son
finitas, entonces tambien lo es la esperanza del producto E[XY ]. En tal caso, tambienexisten las esperanzas E[X], E[Y ] y las variables X − E[X] y Y − E[Y ] tienen esperanzacero. La esperanza de su producto (X − E[X])(Y − E[Y ]) se puede calcular distribuyendoterminos y usando la linealidad de la esperanza
E[(X − E[X]) (Y − E[Y ])] = E[XY − E[Y ]X − E[X]Y + E[X]E[Y ]]
= E[XY ] − E[Y ]E[X] − E[X]E[Y ] + E[X]E[Y ]
= E[XY ] − E[X]E[Y ].
Definicion 4.1 (Covarianza). Sean X e Y dos variables aleatorias de varianzas finitasdefinidas sobre el mismo espacio de probabilidad (Ω,A, P). La covarianza de X e Y sedefine por
Cov(X,Y ) := E[(X − E[X]) (Y − E[Y ])] = E[XY ] − E[X]E[Y ]. (32)
21

Sobre la esperanza del producto. Si se conoce la covarianza y la esperanza de lasmarginales, la identidad (32) puede ser util para calcular la esperanza del producto:
E[XY ] = E[X]E[Y ] + Cov(X,Y ).
Nota Bene. Si X e Y son independientes, entonces por el Corolario 1.25 resulta queCov(X,Y ) = 0. Pero la recıproca no es cierta.
Ejemplo 4.2. Sea (Ω,A, P) un espacio de probabilidad y sean A ∈ A y B ∈ A doseventos de probabilidad positiva. Consideremos las variables aleatorias X = 1ω ∈ A eY = 1ω ∈ B. Entonces,
Cov(X,Y ) = E[XY ] − E[X]E[Y ]
= P(XY = 1) − P(X = 1)P(Y = 1)
= P(X = 1, Y = 1) − P(X = 1)P(Y = 1). (33)
La segunda y la tercera igualdad se obtienen de (2) observando que XY es una variable avalores 0 o 1 que vale 1 si y solo si X e Y son ambas 1.
De (33) vemos que
Cov(X,Y ) > 0 ⇐⇒ P(X = 1, Y = 1) > P(X = 1)P(Y = 1)
⇐⇒ P(X = 1, Y = 1)
P(X = 1)> P(Y = 1)
⇐⇒ P(Y = 1|X = 1) > P(Y = 1). (34)
Esto es, la covarianza de X e Y es positiva si y solamente si el resultado X = 1 hace quesea mas probable que Y = 1.
Ejemplo 4.3. En una urna hay 6 bolas rojas y 4 bolas negras. Se extraen 2 bolas al azarsin reposicion. Consideramos los eventos
Ai = sale una bola roja en la i-esima extraccion, i = 1, 2,
y definimos las variables aleatorias X1 y X2 como las funciones indicadoras de los eventosA1 y A2 respectivamente. De acuerdo con el Ejemplo anterior es intuitivamente claro queCov(X1, X2) < 0. (¿Por que? )
Cov(X1, X2) = P(X1 = 1, X2 = 1) − P(X1 = 1)P(X2 = 1)
= P(A1 ∩ A2) − P(A1)P(A2)
=6
10× 5
9− 6
10
(
5
9× 6
10+
6
9× 4
10
)
= − 2
75= −0.02666....
22

Nota Bene. En general se puede mostrar que Cov(X,Y ) > 0 es una indicacion de queY tiende a crecer cuando X lo hace, mientras que Cov(X,Y ) < 0 es una indicacion de queY decrece cuando X crece.
Ejemplo 4.4 (Dos bolas en dos urnas). El experimento aleatorio consiste en ubicar dosbolas en dos urnas. El espacio muestral puede representarse de la siguiente manera
Ω =
|b1b2| − |; | − |b1b2|; | b1 | b2 |; | b2 | b1 |
Sean N la cantidad de urnas ocupadas y Xi la cantidad de bolas en la urna i.La funcion de probabilidad conjunta de N y X1 se muestra en el Cuadro 1
N \ X1 0 1 2 pN
1 1/4 0 1/4 1/22 0 1/2 0 1/2
pX11/4 1/2 1/4
Cuadro 1: Funcion de probabilidad conjunta de (N,X1).
La esperanza del producto NX1 se calcula usando el Teorema 1.21
E[NX1] =2∑
n=1
3∑
x1=0
nx1pN,X1(n, x1) =
2∑
n=1
3∑
x1=1
nx1pN,X1(n, x1)
= 1 · 1 · pN,X1(1, 1) + 1 · 2 · pN,X1
(1, 2) + 2 · 1 · pN,X1(2, 1) + 2 · 2 · pN,X1
(2, 2)
= 1 · 0 + 2 · 1/4 + 2 · 1/2 + 4 · 0 = 3/2.
Es facil ver que E[N ] = 3/2 y E[X1] = 1. Por lo tanto, Cov(N,X1) = 0. Sin embargo, esclaro que las variables N y X1 no son independientes.
Lema 4.5 (Propiedades). Para variables aleatorias X,Y, Z y constantes a, valen las sigu-ientes propiedades
1. Cov(X,X) = V(X),2. Cov(X,Y ) = Cov(Y,X),3. Cov(aX, Y ) = aCov(X,Y ),4. Cov(X,Y + Z) = Cov(X,Y ) + Cov(X,Z).
Demostracion. Ejercicio.
4.2. Varianza de sumas
Usando las propiedades de la covarianza enunciadas en Lema 4.5 se puede demostrarque
Cov
(
n∑
i=1
Xi,
m∑
j=1
Yj
)
=n∑
i=1
m∑
j=1
Cov(Xi, Yj) (35)
23

En particular, se obtiene que
V
(
n∑
i=1
Xi
)
= Cov
(
n∑
i=1
Xi,
n∑
j=1
Xj
)
=n∑
i=1
V(Xi) + 2n∑
i=1
∑
j<i
Cov(Xi, Yj). (36)
Finalmente, si las variables son independientes
V
(
n∑
i=1
Xi
)
=n∑
i=1
V(Xi). (37)
5. La ley debil de los grandes numeros
Teorema 5.1 (Ley debil de los grandes numeros para variables aleatorias i.i.d.). Sea
X1, X2, . . . una sucesion de variables aleatorias independientes identicamente distribuidas,
tales que V(X1) < ∞. Sea Sn, n ≥ 1, la sucesion de las sumas parciales definida por
Sn :=∑n
i=1 Xi. Entonces, para cualquier ǫ > 0
lımn→∞
P
(∣
∣
∣
∣
Sn
n− E[X1]
∣
∣
∣
∣
> ǫ
)
= 0.
Demostracion. Se obtiene aplicando la desigualdad de Chebyshev a la variable aleatoriaSn/n. Usando que la esperanza es un operador lineal se obtiene que
E [Sn/n] =1
nE
[
n∑
i=1
Xi
]
=1
n
n∑
i=1
E[Xi] = E[X1].
Como las variables X1, X2, . . . son independientes tenemos que
V (Sn/n) =1
n2V
(
n∑
i=1
Xi
)
=1
n2
n∑
i=1
V(Xi) =V(X1)
n.
Entonces, por la desigualdad de Chebyshev, obtenemos la siguiente estimacion
P
(∣
∣
∣
∣
Sn
n− E[X1]
∣
∣
∣
∣
> ǫ
)
≤ V(X1)
nǫ2. (38)
Como V(X1) < ∞ el lado derecho de la ultima desigualdad tiende a 0 cuando n → ∞.
Nota Bene. La ley debil de los grandes numeros establecida en el Teorema 5.1 sirve comobase para la nocion intuitiva de probabilidad como medida de las frecuencias relativas. Laproposicion “en una larga serie de ensayos identicos la frecuencia relativa del evento A seaproxima a su probabilidad P(A)” se puede hacer teoricamente mas precisa de la siguientemanera: el resultado de cada ensayo se representa por una variable aleatoria (independiente
24

de las demas) que vale 1 cuando se obtiene el evento A y vale cero en caso contrario. Laexpresion “una larga serie de ensayos” adopta la forma de una sucesion X1, X2, . . . devariables aleatorias independientes cada una con la misma distribucion que la indicadoradel evento A. Notar que Xi = 1 significa que “en el i-esimo ensayo ocurrio el evento A” yla suma parcial Sn =
∑ni=1 Xi representa la “frecuencia del evento A” en los primeros n
ensayos. Puesto que E[X1] = P(A) y V(X1) = P(A)(1 − P(A)) la estimacion (38) adoptala forma
P
(∣
∣
∣
∣
Sn
n− P(A)
∣
∣
∣
∣
> ǫ
)
≤ P(A)(1 − P(A))
nǫ2. (39)
Por lo tanto, la probabilidad de que la frecuencia relativa del evento A se desvıe de su
probabilidad P(A) en mas de una cantidad prefijada ǫ, puede hacerse todo lo chica que se
quiera, siempre que la cantidad de ensayos n sea suficientemente grande.
Ejemplo 5.2 (Encuesta electoral). Se quiere estimar la proporcion del electorado quepretende votar a un cierto candidato. Cual debe ser el tamano muestral para garantizarun determinado error entre la proporcion poblacional, p, y la proporcion muestral Sn/n?
Antes de resolver este problema, debemos reflexionar sobre la definicion de error. Habit-ualmente, cuando se habla de error, se trata de un numero real que expresa la (in)capacidadde una cierta cantidad de representar a otra. En los problemas de estimacion estadıstica,debido a que una de las cantidades es una variable aleatoria y la otra no lo es, no es posibleinterpretar de un modo tan sencillo el significado de la palabra error.
Toda medida muestral tiene asociada una incerteza (o un riesgo) expresada por un mod-elo probabilıstico. En este problema consideramos que el voto de cada elector se comportacomo una variable aleatoria X tal que P(X = 1) = p y P(X = 0) = 1 − p, donde X = 1significa que el elector vota por el candidato considerado. Por lo tanto, cuando se habla deque queremos encontrar un tamano muestral suficiente para un determinado error maximo,por ejemplo 0.02, tenemos que hacerlo con una medida de certeza asociada. Matematica-mente, queremos encontrar n tal que P
(∣
∣
Sn
n− p∣
∣ ≤ 0.02)
≥ 0.9999 o, equivalentemente,queremos encontrar n tal que
P
(∣
∣
∣
∣
Sn
n− p
∣
∣
∣
∣
> 0.02
)
≤ 0.0001.
Usando la estimacion (39) se deduce que
P
(∣
∣
∣
∣
Sn
n− p
∣
∣
∣
∣
> 0.02
)
≤ p(1 − p)
n(0.02)2.
El numerador de la fraccion que aparece en el lado derecho de la estimacion depende de py el valor de p es desconocido. Sin embargo, sabemos que p(1−p) es una parabola convexacon raıces en p = 0 y p = 1 y por lo tanto su maximo ocurre cuando p = 1/2, esto esp(1 − p) ≤ 1/4. En la peor hipotesis tenemos:
P
(∣
∣
∣
∣
Sn
n− p
∣
∣
∣
∣
> 0.02
)
≤ 1
4n(0.02)2.
25

Como maximo estamos dispuestos a correr un riesgo de 0.0001 y en el peor caso ten-emos acotada la maxima incerteza por (4n(0.02)2)−1. El problema se reduce a resolver ladesigualdad (4n(0.02)2)−1 ≤ 0.0001. Por lo tanto,
n ≥ ((0.0001)4(0.02)2)−1 = 6250000.
Una cifra absurdamente grande!! Mas adelante, mostraremos que existen metodos massofisticados que permiten disminuir el tamano de la muestra.
26

6. Distribuciones particulares
Para facilitar referencias posteriores presentaremos tablas de esperanzas y varianzasde algunas distribuciones importantes de uso frecuente y describiremos el metodo paraobtenerlas.
Discretas
No. Nombre Probabilidad Soporte Esperanza Varianza
1. Bernoulli px(1 − p)1−x x ∈ 0, 1 p p(1 − p)
2. Binomial(
nx
)
px(1 − p)n−x 0 ≤ x ≤ n np np(1 − p)
3. Geometrica (1 − p)x−1p x ∈ N 1/p (1 − p)/p2
4. Poisson λx
x!e−λ x ∈ N0 λ λ
Cuadro 2: Esperanza y varianza de algunas distribuciones discretas de uso frecuente.
Continuas
No. Nombre Densidad Soporte Esperanza Varianza
1. Uniforme 1b−a
x ∈ [a, b] (a + b)/2 (b − a)2/12
2. Exponencial λe−λx x > 0 1/λ 1/λ2
3. Gamma λν
Γ(ν)xν−1e−λx x > 0 ν/λ ν/λ2
4. Beta Γ(ν1+ν2)Γ(ν1)Γ(ν2)
xν1−1(1 − x)ν2−1 x ∈ (0, 1) ν1
ν1+ν2
ν1ν2
(ν1+ν2)2(ν1+ν2+1)
5. Normal 1√2πσ
e−(x−µ)2/2σ2
x ∈ R µ σ2
Cuadro 3: Esperanza y varianza de algunas distribuciones continuas de uso frecuente.
27

Cuentas con variables discretas
1. Distribucion Bernoulli.
Sea p ∈ (0, 1). Se dice que la variable aleatoria X tiene distribucion Bernoulli de
parametro p, y se denota X ∼ Bernoulli(p), si X es discreta y tal que
P(X = x) = px(1 − p)1−x, donde x = 0, 1.
Por definicion,
E[X] = 0 · P(X = 0) + 1 · P(X = 1) = 0 · (1 − p) + 1 · p = p.
Por otra parte,
E[X2] = 02 · P(X = 0) + 12 · P(X = 1) = p.
Por lo tanto,
V(X) = E[X2] − E[X]2 = p − p2 = p(1 − p).
2. Distribucion Binomial.
Sean p ∈ (0, 1) y n ∈ N. Se dice que la variable aleatoria X tiene distribucion Binomial
de parametros n y p, y se denota X ∼ Binomial (n, p), si X es discreta y tal que
P(X = x) =
(
n
x
)
px(1 − p)n−x, donde x = 0, 1, . . . , n.
Por definicion,
E[X] =n∑
x=0
xP(X = x) =n∑
x=0
x
(
n
x
)
px(1 − p)n−x
=n∑
x=1
xn!
(n − x)!x!px(1 − p)n−x =
n∑
x=1
n!
(n − x)!(x − 1)!px(1 − p)n−x
= np
n∑
x=1
(n − 1)!
(n − x)!(x − 1)!px−1(1 − p)n−x = np
n−1∑
y=0
(
n − 1
y
)
py(1 − p)n−1−y
= np(p + (1 − p))n−1 = np.
Analogamente puede verse que
E[X2] = np((n − 1)p + 1).
Por lo tanto,
V(X) = E[X2] − E[X]2 = np((n − 1)p + 1) − (np)2
= np((n − 1)p + 1 − np) = np(1 − p).
28

3. Distribucion Geometrica.
Sea p ∈ (0, 1). Se dice que la variable aleatoria X tiene distribucion Geometrica de
parametro p, y se denota X ∼ Geometrica(p), si X es discreta y tal que
P(X = x) = (1 − p)x−1p, donde x ∈ N = 1, 2, 3, . . . .Por definicion,
E[X] =∞∑
x=1
xP(X = x) =∞∑
x=1
x(1 − p)x−1p
= p
∞∑
x=1
x(1 − p)x−1.
La serie se calcula observando que x(1 − p)x−1 = − ddp
(1 − p)x y recordando que las seriesde potencias se pueden derivar termino a termino:
∞∑
x=1
x(1 − p)x−1 = − d
dp
∞∑
x=1
(1 − p)x = − d
dp
(
p−1 − 1)
= p−2.
Por lo tanto,
E[X] = p
(
1
p2
)
=1
p.
Para calcular V(X) usaremos la misma tecnica: derivamos dos veces ambos lados de laigualdad
∑∞x=1(1 − p)x−1 = p−1 y obtenemos
2p−3 =d2
dp2p−1 =
d2
dp2
∞∑
x=1
(1 − p)x−1
=∞∑
x=1
(x − 1)(x − 2)(1 − p)x−3 =∞∑
x=1
(x + 1)x(1 − p)x−1
=∞∑
x=1
x2(1 − p)x−1 +∞∑
x=1
x(1 − p)x−1.
Multiplicando por p los miembros de las igualdades obtenemos, 2p−2 = E[X2] + E[X] =E[X2] + p−1. En consecuencia,
E[X2] =2
p2− 1
p.
Por lo tanto,
V(X) = E[X2] − E[X]2 =2
p2− 1
p− 1
p2
=1
p2− 1
p=
1 − p
p2.
29

4. Distribucion de Poisson.
Sea λ > 0. Se dice que la variable aleatoria X tiene distribucion de Poisson de intensidad
λ, y se denota X ∼ Poisson(λ), si X es discreta y tal que
P(X = x) =λx
x!e−λ, donde x ∈ N0 = 0, 1, 2, . . . .
Por definicion,
E[X] =∞∑
x=0
xP(X = x) =∞∑
x=0
xλx
x!e−λ
= λe−λ
∞∑
x=1
xλx−1
x!= λe−λ
∞∑
x=1
λx−1
(x − 1)!
= λe−λeλ = λ.
Derivando termino a termino, se puede ver que
E[X2] =∞∑
x=0
x2P(X = x) =
∞∑
x=0
x2λx
x!e−λ
= λe−λ
∞∑
x=1
x2λx−1
x!= λe−λ
∞∑
x=1
xλx−1
(x − 1)!
= λe−λ d
dλ
∞∑
x=1
λx
(x − 1)!= λe−λ d
dλ
(
λeλ)
= λe−λ(
eλ + λeλ)
= λ + λ2.
Por lo tanto,
V(X) = E[X2] − E[X] = λ + λ2 − λ2
= λ.
Cuentas con variables continuas
1. Distribucion uniforme.
Sean a < b. Se dice que la variable aleatoria X tiene distribucion uniforme sobre el
intervalo [a, b], y se denota X ∼ U[a, b], si X es absolutamente continua con densidad deprobabilidades
f(x) =1
b − a1x ∈ [a, b].
30

Por definicion,
E[X] =
∫ ∞
−∞xf(x)dx =
∫ ∞
−∞x
1
b − a1x ∈ [a, b] dx
=1
b − a
∫ b
a
x dx =1
b − a
(
b2 − a2
2
)
=a + b
2.
Por otra parte,
E[X2] =
∫ ∞
−∞x2f(x)dx =
1
b − a
∫ b
a
x2 dx
=1
b − a
(
b3 − a3
3
)
=a2 + ab + b2
3.
Finalmente,
V(X) = E[X2] − E[X]2 =a2 + ab + b2
3−(
a + b
2
)2
=a2 − 2ab + b2
12=
(b − a)2
12.
2. Distribucion exponencial.
Sea λ > 0. Se dice que la variable aleatoria X tiene distribucion exponencial de inten-
sidad λ, y se denota X ∼ Exp(λ), si X es absolutamente continua con funcion densidadde probabilidades
f(x) = λe−λx1x ≥ 0.El calculo de E[X] y V(X) se reduce al caso X ∼ Exp(1). Basta observar que Y ∼ Exp(λ)si y solo si Y = λ−1X, donde X ∼ Exp(1) y usar las identidades E[λ−1X] = λ−1
E[X] yV(λ−1X) = λ−2
V(X). En lo que sigue suponemos que X ∼ Exp(1).Integrando por partes se obtiene,
E[X] =
∫ ∞
−∞xf(x)dx =
∫ ∞
−∞xe−x1x ≥ 0
=
∫ ∞
0
λxe−xdx = −xe−x
∣
∣
∣
∣
∞
0
+
∫ ∞
0
e−xdx
= 1.
Por otra parte,
E[X2] =
∫ ∞
−∞x2f(x)dx =
∫ ∞
0
x2e−xdx
= −x2e−x∣
∣
∞0
+
∫ ∞
0
2xe−xdx = 2.
31

Por lo tanto,
V(X) = E[X2] − E[X]2 = 2 − 1 = 1.
3. Distribucion gamma.
La funcion gamma se define por
Γ(t) :=
∫ ∞
0
xt−1e−xdx t > 0.
Integrando por partes puede verse que Γ(t) = (t − 1)Γ(t − 1) para todo t > 0. De aquı sededuce que la funcion gamma interpola a los numeros factoriales en el sentido de que
Γ(n + 1) = n! para n = 0, 1, . . .
Sean λ > 0 y ν > 0. Se dice que la variable aleatoria X tiene distribucion gamma de
parametros ν, λ, , y se denota X ∼ Γ(ν, λ), si X es absolutamente continua con funciondensidad de probabilidades
f(x) =λν
Γ(ν)xν−1e−λx1x > 0.
El calculo de E[X] y V(X) se reduce al caso X ∼ Γ(ν, 1). Para ello, basta observar queY ∼ Γ(ν, λ) si y solo si Y = λ−1X, donde X ∼ Γ(ν, 1) y usar las identidades E[λ−1X] =λ−1
E[X] y V(λ−1X) = λ−2V(X). En lo que sigue suponemos que X ∼ Γ(ν, 1)
E[X] =
∫ ∞
0
xf(x) dx =
∫ ∞
0
1
Γ(ν)xνe−xdx
=1
Γ(ν)Γ(ν + 1) = ν.
Del mismo modo se puede ver que
E[X2] = (ν + 1)ν = ν2 + ν.
Por lo tanto,V(X) = E[X2] − E[X]2 = ν.
32

4. Distribucion beta
Sean ν1 > 0 y ν2 > 0. Se dice que la variable aleatoria X tiene distribucion beta de
parametros ν1, ν2, y se denota X ∼ β(ν1, ν2), si X es absolutamente continua con funciondensidad de probabilidades
f(x) =Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)xν1−1(1 − x)ν2−11x ∈ (0, 1.
Por definicion,
E[X] =
∫ ∞
−∞xf(x)dx =
∫ ∞
−∞x
Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)xν1−1(1 − x)ν2−11x ∈ (0, 1 dx
=Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)
∫ 1
0
xν1(1 − x)ν2−1 dx =Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)
Γ(ν1 + 1)Γ(ν2)
Γ(ν1 + ν2 + 1)
=ν1
ν1 + ν2
Por otra parte,
E[X2] =
∫ ∞
−∞x2f(x)dx =
Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)
∫ 1
0
xν1+1(1 − x)ν2−1 dx
=Γ(ν1 + ν2)
Γ(ν1)Γ(ν2)
Γ(ν1 + 2)Γ(ν2)
Γ(ν1 + ν2 + 2)=
ν1(ν1 + 1)
(ν1 + ν2)(ν1 + ν2 + 1)
Finalmente,
V(X) = E[X2] − E[X]2 =ν1(ν1 + 1)
(ν1 + ν2)(ν1 + ν2 + 1)−(
ν1
ν1 + ν2
)2
=ν1ν2
(ν1 + ν2)2(ν1 + ν2 + 1).
5. Distribucion normal.
Sean µ ∈ R y σ > 0. Se dice que la variable aleatoria X tiene distribucion normal de
parametros µ, σ2, y se denota X ∼ N (µ, σ2), si X es absolutamente continua con funciondensidad de probabilidades
f(x) =1√2πσ
e−(x−µ)2/2σ2
.
El calculo de E[X] y V(X) se reduce al caso X ∼ N (0, 1). Para ello, basta observarque Y ∼ N (µ, σ2) si y solo si Y = σX + µ, donde X ∼ N (0, 1) y usar las identidadesE[σX+µ] = σE[X]+µ y V(σX+µ) = σ2
V(X). En lo que sigue suponemos que X ∼ N (0, 1)y denotamos su densidad mediante
ϕ(x) =1√2π
e−x2/2
33

Es evidente que E[X] = 0. En consecuencia,
V(X) = E[X2] =
∫ ∞
−∞x2ϕ(x)dx
Observando que ϕ′(x) = −xϕ(x) e integrando por partes se obtiene,
V(X) =
∫ ∞
−∞x(xϕ(x))dx = −xϕ(x)
∣
∣
∣
∣
∞
−∞+
∫ ∞
−∞ϕ(x)dx = 0 + 1.
7. Bibliografıa consultada
Para redactar estas notas se consultaron los siguientes libros:
1. Bertsekas, D. P., Tsitsiklis, J. N.: Introduction to Probability. M.I.T. Lecture Notes.(2000)
2. Billingsley, P.: Probability and Measure. John Wiley & Sons, New York. (1986)
3. Durrett, R. Elementary Probability for Applications. Cambridge University Press,New York. (2009)
4. Feller, W.: An introduction to Probability Theory and Its Applications. Vol. 1. JohnWiley & Sons, New York. (1957)
5. Kolmogorov, A. N.: The Theory of Probability. Mathematics. Its Content, Methods,and Meaning. Vol 2. The M.I.T. Press, Massachusetts. (1963) pp. 229-264.
6. Ross, S.: Introduction to Probability and Statistics for Engineers and Scientists.Academic Press, San Diego. (2004)
7. Ross, S.: Introduction to Probability Models. Academic Press, San Diego. (2007)
8. Soong, T. T.: Fundamentals of Probability and Statistics for Engineers. John Wiley& Sons Ltd. (2004)
34




![07 - Bernoulli e Hiper to print2 [Modo de compatibilidad]materias.fi.uba.ar/6109R/clases_teoricas/07-Bernoulli_e_Hiper.pdf · Bernoulli permite (transformación mediante) describir](https://img.pdfslide.es/doc/110x75/60d6d16bee3783581c76c8dd/07-bernoulli-e-hiper-to-print2-modo-de-compatibilidad-bernoulli-permite-transformacin.jpg)










![05 - Transformaciones to print [Modo de compatibilidad]materias.fi.uba.ar/6109R/clases_teoricas/Teorica05.pdf · Desigualdad de Chebyshev Ley de los Grandes Números Covarianza](https://img.pdfslide.es/doc/110x75/5a8d8d6e7f8b9afe568c9ea3/05-transformaciones-to-print-modo-de-compatibilidad-de-chebyshev-ley-de-los.jpg)













